When and How Much to Imagine: Adaptive Test-Time Scaling with World Models for Visual Spatial Reasoning
Abstract: Despite rapid progress in Multimodal LLMs (MLLMs), visual spatial reasoning remains unreliable when correct answers depend on how a scene would appear under unseen or alternative viewpoints. Recent work addresses this by augmenting reasoning with world models for visual imagination, but questions such as when imagination is actually necessary, how much of it is beneficial, and when it becomes harmful, remain poorly understood. In practice, indiscriminate imagination can increase computation and even degrade performance by introducing misleading evidence. In this work, we present an in-depth analysis of test-time visual imagination as a controllable resource for spatial reasoning. We study when static visual evidence is sufficient, when imagination improves reasoning, and how excessive or unnecessary imagination affects accuracy and efficiency. To support this analysis, we introduce AVIC, an adaptive test-time framework with world models that explicitly reasons about the sufficiency of current visual evidence before selectively invoking and scaling visual imagination. Across spatial reasoning benchmarks (SAT, MMSI) and an embodied navigation benchmark (R2R), our results reveal clear scenarios where imagination is critical, marginal, or detrimental, and show that selective control can match or outperform fixed imagination strategies with substantially fewer world-model calls and language tokens. Overall, our findings highlight the importance of analyzing and controlling test-time imagination for efficient and reliable spatial reasoning.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “When and How Much to Imagine: Adaptive Test-Time Scaling with World Models for Visual Spatial Reasoning”
Overview: What is this paper about?
This paper looks at how AI systems think about space in pictures or videos. Sometimes, to answer a question about a scene, the AI needs to “imagine” what the scene would look like from another angle, or after turning or moving. The authors study when this imagination actually helps, when it doesn’t, and how to control it so the AI stays accurate and efficient. They introduce a method called AVIC that lets an AI choose whether to imagine and how much to imagine, instead of always imagining a lot every time.
Key questions the paper asks
To make the topic clearer, here are the main questions the paper explores:
- When should an AI “imagine” new views of a scene to answer a question?
- How much imagination (how many new views) is helpful, and when does it become too much?
- Can controlling imagination make the AI both smarter and faster?
How did the researchers approach this? (Methods explained simply)
Think of the AI like a person standing in a room with a camera. A question might be: “If you turn left, will you see a door?” If the camera only shows what’s straight ahead, the AI might need to imagine turning the camera to see the door.
Some important ideas:
- Multimodal LLMs (MLLMs): These are AIs that understand both text and images.
- World model: A tool that can generate new, imagined views, like a smart video generator that simulates what the camera would see after moving.
- Test-time scaling: Giving the AI extra thinking power while it’s solving a problem (without retraining it).
Instead of always imagining lots of views, the authors designed AVIC, which uses four simple steps:
- Decide if imagination is needed: A small “policy” module checks if the current image is enough. If yes, it skips imagination. If not, it continues.
- Plan small actions: If imagination is needed, the AI plans a short sequence of moves (like “turn 30° left” or “look down a bit”) that would reveal useful views.
- Imagine the views: The world model generates those new views as if the camera performed the planned moves.
- Pick the best imagined sequence: A “verifier” looks at the imagined sequences and selects the most helpful one, then the AI answers the question using both the original and the selected imagined views.
Analogy: It’s like deciding whether to peek around a corner. If you can already see what you need, don’t peek. If you do peek, take only one or two careful looks, not ten random ones.
Main findings: What did they discover, and why does it matter?
The authors tested their ideas on several benchmarks that involve tricky questions about space:
- SAT and MMSI: Datasets that ask questions about relationships between objects, viewpoints, or what happens after certain actions.
- R2R navigation: A task where an AI follows instructions to move through an indoor space.
Here’s what they found:
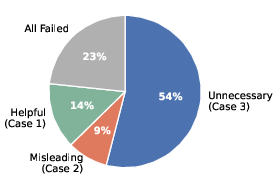
- Always imagining is wasteful: In most cases, imagination isn’t needed. Sometimes it even hurts by adding confusing or wrong details.
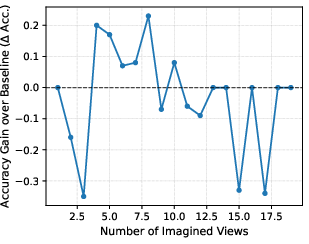
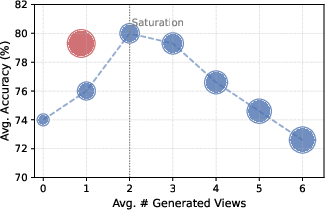
- A little imagination goes a long way: One or two well-chosen imagined views often help, but adding many more can actually reduce accuracy.
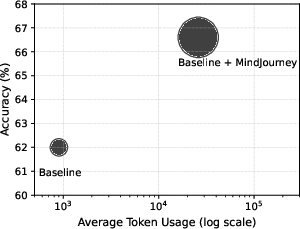
- AVIC is both smart and efficient: It matched or beat methods that always imagine lots of views, while using far fewer world-model calls and language tokens (less compute).
- Imagination helps most for action-based questions: If the question is “What will I see after turning?” or “What happens if I move forward?”, imagination is very useful. If the answer can be found in the current image, imagination isn’t necessary.
In simple terms: The AI should imagine only when the question depends on moving or changing viewpoints—and even then, only a little bit.
Implications: Why is this research important?
This research shows that careful, selective imagination makes AI:
- More reliable: It avoids distracting, misleading imagined views.
- More efficient: It uses less time and computing power.
- More practical: It works better for real tasks like robot navigation, AR/VR assistants, or apps that help people explore spaces.
Big picture: Instead of “more is better,” the paper argues for “smart is better”—use imagination only when it’s needed, and just enough to solve the problem. This idea could guide the design of future AI systems that think about the physical world more like humans do: looking when they need to, and saving energy when they don’t.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide follow-up research:
- Lack of a formal, decision-theoretic criterion for “when to imagine”: no cost–benefit model (e.g., value of information) that jointly optimizes answer utility against imagination cost (tokens, latency, WM calls).
- No calibration analysis of the gating policy’s uncertainty: majority voting with M samples is used, but sensitivity to M, adaptive sampling, and stopping rules are not studied.
- Potential circularity and shared failure modes: the same base MLLM is used for gating, trajectory verification, and final answering; the impact of a separate, independently trained verifier/gating model is not evaluated.
- Verifier design is under-specified and unvalidated: the trajectory-level verifier V is prompt-based, with no comparison to learned verifiers, geometric/consistency metrics, or human-validated scoring criteria.
- No robustness analysis to world-model quality: dependence on a single world model (SVC) is strong; effects of fidelity, hallucination rates, temporal drift, and camera-control errors on downstream reasoning remain unquantified.
- Missing cross-world-model generalization: how AVIC performs with alternative controllable video/world models (e.g., different priors, training data, or control interfaces) is not explored.
- No mechanisms to detect or mitigate misleading imagination: beyond avoiding overuse, there is no automatic hallucination detection, inter-view consistency check, or geometry-informed filtering.
- Limited action space and control granularity: planning appears restricted to discrete, low-level egocentric rotations; the benefits of translations, zoom, tilt, continuous control, or environment-aware macro-actions are untested.
- Short-horizon planning only: how performance scales with longer trajectories, compounding world-model errors, and dynamic re-planning policies is not analyzed.
- No learning-based training for the policy or verifier: the paper relies on zero-shot prompting; supervised, reinforcement learning, or bandit methods to optimize accuracy–compute trade-offs are not investigated.
- Oracle “selective imagination upper bound” is unrealistic: practical approximations (e.g., learned predictors of imagination utility or confidence-calibrated gating) are not developed or evaluated.
- Limited evaluation scope: benchmarks are SAT-Real, MMSI, and R2R; generalization to outdoor/egocentric video, 3D-heavy domains (e.g., CLEVR mental rotation, MM-Spatial), or robotic tasks with real-time constraints is untested.
- Multiple-choice assumption: AVIC is not evaluated for open-ended generation, structured outputs, or spatial descriptions where answer verification and scoring are harder.
- Domain robustness is unstudied: performance under challenging conditions (low light, motion blur, heavy clutter, dynamic scenes, sensor noise) and across domain shifts is not assessed.
- Integration with geometric representations is absent: comparisons with, or integration into, SLAM/NeRF/3D-GS pipelines for physically grounded, view-consistent imagination are missing.
- No analysis of failure attribution across modules: how much error comes from gating, planning, world-model synthesis, verification, or final QA is not disentangled.
- Incomplete ablations: effects of verifier removal, different action-space discretizations, number/length of candidate plans, and gating thresholds are not systematically reported.
- Compute and efficiency metrics are narrow: beyond tokens/WM calls/runtime, there is no accounting of energy use, memory footprint, or hardware variability; fairness of compute budgets across baselines is unclear.
- R2R gains lack deeper analysis: step-wise latency, per-decision improvements, and ablations across instruction types (e.g., long vs short, ambiguous vs clear) are not presented; results on additional VLN benchmarks (e.g., RxR, REVERIE, VLN-CE) are missing.
- Annotation methodology for error types is under-specified: sample size, inter-annotator agreement, and reproducibility of the manual error taxonomy are not reported.
- Safety and trust concerns are unaddressed: how to prevent spurious imagined content from overriding reliable evidence, and how to convey uncertainty about imagined views to users, remains open.
- Possible benchmark contamination risk: proprietary models (GPT-4o/4.1/o1) may have seen similar data; safeguards against leakage and reproducibility with strictly open models are not discussed.
- No explicit treatment of multi-modal sensing: potential gains from depth, IMU, or audio for gating/planning/verification are unexplored.
- Caching and re-use of imagined views are not considered: policies for memory management, deduplication, and view re-use over multi-step tasks are absent.
- Scheduling and early-exit policies for imagination are not studied: adaptive stopping based on marginal utility of additional views is not implemented.
- Multi-agent or interactive settings are not covered: how AVIC scales to collaborative tasks or human-in-the-loop adjustments remains unknown.
Glossary
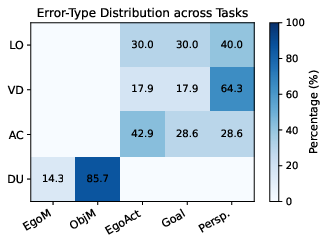
- Action-conditioned reasoning: Reasoning that depends on predicted changes in the scene after hypothetical actions or viewpoint shifts. "world models are most beneficial for action-conditioned spatial reasoning, where answers depend on how a scene would evolve under specific movements or viewpoint changes"
- Adaptive test-time scaling: Dynamically allocating additional computation at inference to improve performance based on instance difficulty. "adaptive test-time scaling achieves SoTA or competitive performance while requiring substantially fewer extra language tokens and world-model calls"
- Allocentric: Describing representations or reasoning relative to the environment or objects (world-centered) rather than the observer (ego-centered). "Allocentric Perspective tasks primarily suffer from viewpoint Dependence errors"
- Always-on imagination: A strategy that invokes the world model for every instance regardless of necessity. "Different cases in always-on visual imagination."
- Beam search: A heuristic search that explores a fixed number of promising candidates at each step to generate or select sequences. "select individual imagined views as keyframes during beam search"
- Chain-of-thought prompting: Prompting that elicits intermediate reasoning steps to improve problem solving. "While recent efforts aim to enhance spatial capabilities through scaling training data ... or chain-of-thought prompting ..., they fundamentally process visual information as static 2D snapshots."
- Controllable video generation: Video generation conditioned on explicit controls (e.g., actions or camera parameters) to simulate specific outcomes. "the emergence of controllable video generation, which allows for action-conditioned simulation"
- Counterfactual actions: Hypothetical actions used to reason about what would happen under alternative choices. "questions involving counterfactual actions (e.g., âwhat if I turn left by 90°?â)"
- Egocentric: Relating to the observer’s viewpoint; first-person perspective. "where is the current egocentric observation, which might include one or multiple egocentric images/views"
- Egocentric action space: A set of low-level actions defined relative to the agent’s current viewpoint (e.g., turn-left, move-forward). "each is drawn from a fixed, low-level egocentric action space"
- Embodied navigation: Navigation tasks where an agent moves and perceives within an environment to follow instructions or reach goals. "and an embodied navigation benchmark (R2R)"
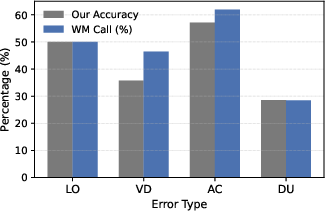
- Limited Observability (LO): Failure mode where needed information is not visible due to scene or viewpoint limitations. "Limited Observability (LO). This category includes cases where the required information is not directly observable from the current view due to occlusion, limited field of view, or truncation."
- Multimodal LLM (MLLM): A large model that processes and reasons over multiple modalities, such as text and images/video. "Despite rapid progress in Multimodal LLMs (MLLMs), visual spatial reasoning remains unreliable"
- Occlusion: When objects are hidden from view by other objects, reducing visible information. "due to occlusion, limited field of view, or truncation."
- Reference-frame transformation: Converting spatial descriptions between coordinate frames (e.g., egocentric to object-centric). "indicating failures in reference-frame transformation rather than missing evidence."
- Selective Imagination Upper Bound: An oracle performance bound assuming the model only imagines when it improves correctness. "We further report a selective imagination upper bound to quantify the performance potential of selective world model usage."
- Self-consistency: An inference strategy that aggregates multiple independent reasoning samples to improve reliability. "which provides a simple yet effective form of self-consistency and reflects uncertainty in the necessity of additional visual evidence."
- Test-time scaling (TTS): Increasing inference-time computation (without retraining) to improve accuracy. "Test-time scaling (TTS) improves performance by allocating additional inference computation without retraining."
- Trajectory-level verification: Scoring and selecting whole imagined action-view sequences based on their overall usefulness and consistency. "we introduce a trajectory-level verification mechanism that selects a single, targeted imagined trajectory for downstream reasoning."
- Tree-based search: Structured exploration over branching decision paths to improve inference or planning. "including self-consistency, tree-based search, verifier-guided method, and (multimodal) CoT"
- Verifier: A component that evaluates candidate outputs (e.g., imagined trajectories) to pick the most reliable one. "our verifier evaluates the entire imagined trajectory as a coherent unit"
- Viewpoint Dependence (VD): Error type where correctness hinges on changing or transforming viewpoints. "Viewpoint Dependence (VD). These errors arise when the correct answer depends on transforming coordinates between egocentric and object-centric views."
- Visual imagination: Internally simulating novel views or outcomes to supplement limited observations. "Visual imagination reveals previously unseen viewpoints, enabling helpful spatial reasoning."
- Visual spatial reasoning: Understanding spatial relations and transformations in visual scenes to answer questions or make decisions. "visual spatial reasoning remains a persistent challenge"
- Visual world model: A generative model that predicts how the visual scene would look from new viewpoints or after actions. "an MLLM is equipped with a visual world model that can generate imagined observations from imagined views."
Practical Applications
Immediate Applications
The paper’s AVIC framework and findings enable the following deployable use cases that balance accuracy with compute efficiency:
- Robotics (Logistics and Manufacturing): Adaptive navigation controller for mobile robots
- Application: Use AVIC to decide when simulated alternative viewpoints are needed to disambiguate occlusions, turns, or perspective changes during path planning and inspection.
- Tools/products/workflows: “AVIC Navigation Controller” plugin for ROS/MoveIt; trajectory-level verifier integrated with mapping stacks (e.g., MapGPT-like workflows); per-step compute budgets and WM-call logs for MLOps.
- Assumptions/dependencies: Reliable controllable view-generation world models for indoor domains; camera calibration; real-time gating and action planning on available compute.
- Household Service Robots: Targeted imagination for object search and room traversal
- Application: Selectively imagine short rotations or reorientations when queries are action-conditioned (e.g., “what if I turn 90° toward the sink?”) to reduce unnecessary simulation and distractor views.
- Tools/products/workflows: Firmware module that gates imagination; compact policy prompts for “skip vs. call_wm” decisions; instance-level token budgets.
- Assumptions/dependencies: Stable virtual camera or similar world models tuned to domestic interiors; safe fallback to direct reasoning when imagination is uncertain.
- Embodied Navigation Systems (Campus/Enterprise): Improved indoor wayfinding with lower latency and cost
- Application: Integrate AVIC into graph-based navigation pipelines to selectively render novel views at ambiguous decision points; demonstrated gains on R2R-like tasks (higher OSR/SR/SPL, lower NE).
- Tools/products/workflows: “AVIC for MapGPT” module; step-wise action proposals; trajectory scoring and selection.
- Assumptions/dependencies: Map building/graph navigation already in place; world model outputs are consistent with the environment’s geometry.
- AR on Smartphones (Home Improvement and Real Estate): Adaptive viewpoint guidance to users
- Application: Apps for measuring rooms, planning furniture, or previewing layouts prompt users only when extra views are necessary; small imagined viewsets help teach perspective taking and framing.
- Tools/products/workflows: “Adaptive View Planner” SDK; on-device gating; lightweight imagined-view generation or instructing user movement to acquire missing evidence.
- Assumptions/dependencies: Efficient on-device or edge compute; world model approximations align with camera intrinsics and typical interiors.
- Education (Spatial Reasoning Tutoring): Cost-aware visual reasoning assistant
- Application: Tutors that decide when to show alternative viewpoints for geometry, perspective-taking, or mental rotation problems; avoid overwhelming learners with unnecessary renders.
- Tools/products/workflows: “Adaptive Imagination Tutor” for SAT/MMSI-like modules; per-problem gating; minimal trajectory renders to illustrate action consequences.
- Assumptions/dependencies: Domain-appropriate world models; align imagined views with curricula; control over token and compute costs in classroom deployments.
- Software/MLOps (Inference Cost Optimization): Adaptive test-time scaling orchestrator
- Application: A controller that caps world-model calls and language tokens per query, invoking imagination only when error types are likely action-conditioned or limited observability.
- Tools/products/workflows: Budget-aware “TTS Orchestrator” with logs for WM calls, tokens, and latency; verifier-guided selection; integration with multimodal inference gateways.
- Assumptions/dependencies: Observability into token usage and WM latency; robust uncertainty signals from the gating policy.
- Content Creation and Previsualization (Media/Design): Targeted shot planning
- Application: Previs tools that propose minimal, high-impact alternative camera angles, avoiding exhaustive view generation that slows workflows.
- Tools/products/workflows: “Adaptive Shot Planner” with trajectory-level scoring; scene-aware policy prompts for staging; studio-friendly compute profiles.
- Assumptions/dependencies: World models trained on relevant visual genres; consistency of imagined geometry with production constraints.
- E-commerce (Product Imaging and 3D Viewers): Efficient view completion for product pages
- Application: Use minimal imagined views to fill gaps in product perspectives; avoid full 360° simulation unless truly needed.
- Tools/products/workflows: “Selective View Completer” plug-in for catalog CMS; cost dashboards to keep WM calls low; A/B tests on conversion vs. compute.
- Assumptions/dependencies: Category-specific world models (e.g., furniture, footwear); guardrails against misleading renders that could affect customer trust.
Long-Term Applications
The paper’s innovations suggest future applications that will need higher-fidelity world models, more robust safety guarantees, or broader integration:
- Autonomous Vehicles (Transportation): Action-conditioned spatial reasoning for planning
- Application: Invoke imagination when lane changes or occlusions make viewpoint prediction critical; avoid continuous simulation to cut compute and latency.
- Tools/products/workflows: “AVIC Planner” within perception-planning stacks; trajectory verifier tied to risk monitors; compute budgets for safety-critical inference.
- Assumptions/dependencies: Photorealistic, physics-grounded world models with calibration to real sensors; strict certification, real-time guarantees, and failure-mode analyses.
- Surgical and Endoscopic Navigation (Healthcare): Selective viewpoint simulation to assist clinicians
- Application: Imagine alternative camera orientations in endoscopy or minimally invasive procedures when visibility is limited; reduce distractions from noisy views.
- Tools/products/workflows: “Adaptive Surgical Imagination” module; trajectory scoring aligned with clinical guidelines; audit trails for decisions.
- Assumptions/dependencies: Regulatory approval; clinically validated world models; careful handling of patient data; robust uncertainty estimates for gating.
- Industrial Inspection Drones (Energy and Utilities): Efficient occlusion handling and viewpoint planning
- Application: Drones selectively imagine angles around turbines, solar arrays, or pipelines when sensor views are blocked; limit unnecessary renders to save battery life and compute.
- Tools/products/workflows: Fleet-level “Imagination Controller” with trajectory verification; policy prompts based on asset type; carbon-aware compute budgeting.
- Assumptions/dependencies: Environment-specific world models; physics and material consistency; integration with maintenance workflows and safety protocols.
- Warehouse Manipulation and Picking (Robotics): Viewpoint-conditioned object handling
- Application: Imagine how graspable features appear from new angles before committing to motions; invoke imagination only for hard cases.
- Tools/products/workflows: “AVIC Manipulation Assistant” for pick-and-place pipelines; closed-loop verifier; task-level compute budgets.
- Assumptions/dependencies: Physics-based world models for object dynamics; tight integration with robot control; latency constraints in high-throughput settings.
- Digital Twins and Urban Planning (Public Sector/Infrastructure): City-scale adaptive view synthesis
- Application: Generate limited, high-value alternate views to assess sightlines, pedestrian flow, or emergency egress; reduce exhaustive simulation costs.
- Tools/products/workflows: “Adaptive Twin Renderer” embedded in planning platforms; trajectory-level scoring linked to urban metrics.
- Assumptions/dependencies: Large-scale, accurate world models of built environments; governance over model use; transparency of imagined vs. real data.
- Assistive Technologies (Accessibility): Navigation aids for visually impaired users
- Application: Mobile assistants that imagine critical viewpoints (e.g., where a doorway opens) only when needed, keeping latency manageable.
- Tools/products/workflows: On-device gating; voice guidance tied to action-conditioned queries; verifier to avoid misleading directions.
- Assumptions/dependencies: Efficient on-device models; reliability across diverse environments; robust safety fallbacks.
- Education at Scale (K–12 and Higher Ed): Adaptive spatial curricula and assessments
- Application: Large-scale platforms that automatically decide when learners need alternate viewpoints to master spatial transformations and action consequences.
- Tools/products/workflows: “Spatial Reasoning Coach” with adaptive gating; learning analytics on imagination utility; cost controls for district deployments.
- Assumptions/dependencies: Content-aligned world models; equity and access considerations; institutional policies on data and compute.
- Policy and Governance (Compute, Cost, and Carbon): Standards for adaptive test-time scaling
- Application: Establish guidelines to report and cap WM calls and token usage; mandate trajectory-level verification and audit logs in public-sector AI deployments.
- Tools/products/workflows: “Adaptive TTS Policy Toolkit” for compliance; dashboards tracking accuracy–cost trade-offs; lifecycle carbon accounting.
- Assumptions/dependencies: Agreement on measurement standards; sector-specific thresholds; alignment with privacy and transparency regulations.
- Safety Certification and Assurance (Cross-Sector): Verifiable imagination pipelines
- Application: Certify that trajectory-level verification is used to prevent misleading imagined evidence; require uncertainty-aware gating and post-hoc audits.
- Tools/products/workflows: Third-party test harnesses; scenario banks for action-conditioned failures; continuous monitoring.
- Assumptions/dependencies: Standardized benchmarks and incident reporting; independent verification bodies; model cards detailing imagination behavior.
Notes on Feasibility and Dependencies
Across applications, the following factors will influence deployment:
- World model fidelity and controllability: Action-conditioned view synthesis must be geometrically consistent and domain-tuned.
- Uncertainty-aware gating: Reliable signals are needed to decide when imagination helps; sampling-based self-consistency should be bounded by latency.
- Compute, latency, and cost: Benefits hinge on reducing WM calls and language tokens; on-device or edge compute may be necessary for real-time settings.
- Safety and regulation: In healthcare, automotive, and public-sector contexts, imagination outputs require validation, auditability, and clear separation from measured data.
- Domain adaptation: World models and prompts must be calibrated to the target environment (e.g., warehouses vs. homes vs. industrial sites).
Collections
Sign up for free to add this paper to one or more collections.