- The paper’s main contribution is the SHARP framework, which uses Shapley value approximations for fine-grained, causal credit attribution in hierarchical multi-agent LLM systems.
- It decomposes rewards into global, marginal, and tool process components, enabling precise agent coordination and accelerated convergence.
- Empirical results show significant performance gains, scalability improvements, and enhanced planner-worker synergy compared to existing baselines.
Shapley Credit-Based Optimization in Multi-Agent LLM Systems: The SHARP Framework
Introduction and Motivation
The advancement of multi-agent LLM systems, particularly those integrated with external tools, has catalyzed new paradigms for compositional reasoning, planning, and complex problem-solving. However, effective optimization of these multi-agent reinforcement learning (MARL) architectures is fundamentally impeded by the credit assignment problem: existing methods typically distribute terminal or broadcast rewards indiscriminately across all participating agents, thus obfuscating the causal contribution of individual agents. This inefficiency results in poorly shaped learning signals, slow convergence, and suboptimal policies, especially in hierarchical planner–worker configurations typical of tool-augmented LLMs.
To address this, "Who Deserves the Reward? SHARP: Shapley Credit-based Optimization for Multi-Agent System" (2602.08335) proposes SHARP (Shapley-based Hierarchical Attribution for Reinforcement Policy), a mathematically principled framework for fine-grained credit attribution via the marginal causal contributions of individual agents, operationalized through Shapley value approximations. The SHARP framework delivers a tripartite decomposed reward scheme, supports flexible parameter-sharing via role prompts, and demonstrates substantial empirical gains across a spectrum of benchmarks.
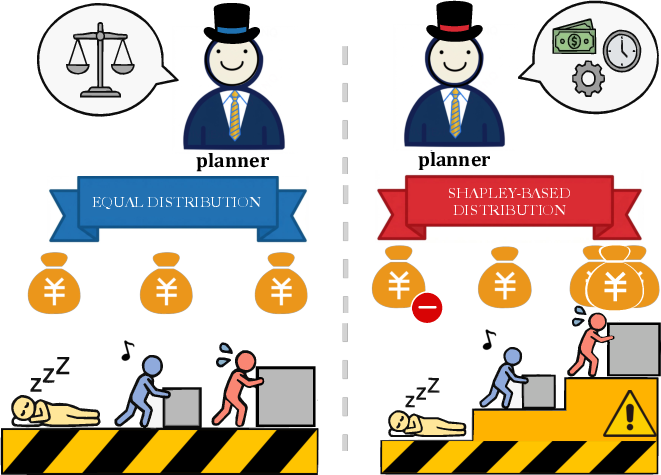
Figure 1: Existing credit assignment policy for all agents (left) and the precise strategy of SHARP for each individual agent (right).
Architectural Foundation: Hierarchical Multi-Agent Role Instantiation
SHARP instantiates both planners and workers from a shared parameter policy πθ, with each agent's role defined by context-dependent system prompts. The planner agent executes high-level task decomposition, generating coherent subtask queries, which are delegated to worker agents responsible for tool-oriented execution. This paradigm ensures maximal parameter sharing and policy generalization, minimizing redundancy while supporting specialization through role-adaptive conditioning.
The system models the execution trajectory as a hierarchical sequence τ=(τ0,τ1,...,τT), where τ0 is the planner's trace and each τt is the corresponding worker's execution. Crucially, SHARP's optimization does not differentiate between agents at the backbone level, but relies on the reward mechanism to structure specialization and coordination.
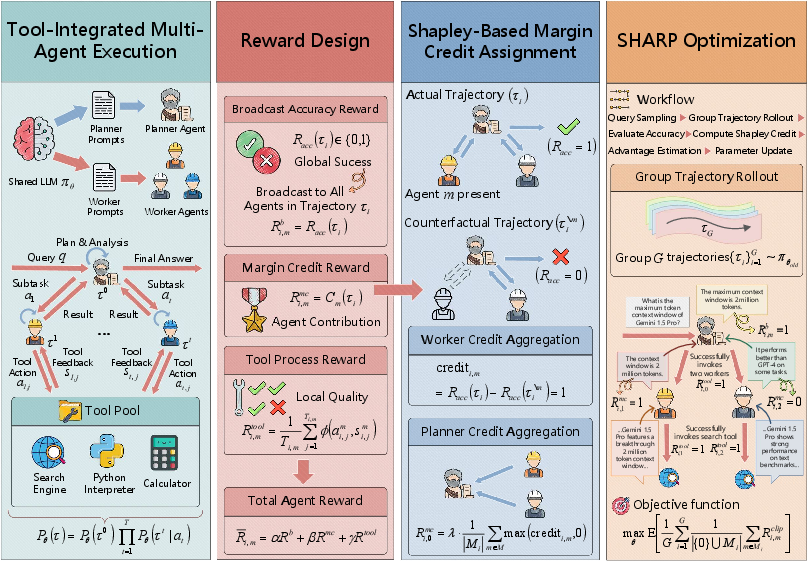
Figure 2: Overview of SHARP: hierarchical interaction, decomposed rewards, Shapley-based marginal credit, and workflow for group-relative policy alignment.
Tripartite Reward Design: Global, Marginal, and Process-Level Attribution
A central contribution of SHARP is the decomposition of reinforcement signals into three mutually orthogonal components:
- Global broadcast accuracy reward: Binary task success signal (Racc) aligning all agents towards terminal trajectory outcome.
- Marginal credit reward: For each agent m, the reward is Ri,mmc=Racc(τi)−Racc(τi∖m); this reflects the causal effect of perturbing (ablating) agent m on the outcome, closely approximating that agent’s Shapley value.
- Tool process reward: For agents involved in tool execution, Ri,mtool records the fraction of valid interactions over all tool invocations, incentivizing precise and correct usage patterns.
The final surrogate reward for each agent combines these signals via tunable weights (α,β,γ).
This mechanism satisfies three key properties: (i) global effectiveness, (ii) faithful attribution, and (iii) operational validity, constructing a precisely targeted learning signal and avoiding reward dilution.
Shapley Marginal Credit Assignment and Group-Relative Optimization
SHARP operationalizes marginal credit through computationally tractable Shapley-value approximations. For each trajectory, counterfactual rollouts are generated by masking agent-specific actions and computing the resultant change in terminal reward—a methodology rooted in cooperative game theory and aligned with causality.
For optimization, SHARP employs Group Relative Policy Optimization (GRPO) [shao2024deepseekmath], where the per-agent advantage is normalized across each mini-batch to ensure low-variance policy gradients:
A^i,m=(Rˉi,m−μm)/(σm+δ)
and parameter updates are driven by a clipped surrogate objective, maintaining stability in highly multi-agent, sparse reward regimes.
Empirical Results
The framework is validated across MuSiQue, GAIA-text, WebWalkerQA, FRAMES, and DocMath-Eval benchmarks, with comprehensive ablations and scaling studies.
Quantitative outcomes highlight:
- SHARP achieves an average improvement of 23.66% over single-agent and 14.05% over multi-agent state-of-the-art baselines.
- On MuSiQue, SHARP attains 50.76 (absolute), a 14.41-point gain over single-agent approaches at scale.
- The ablation studies identify that simultaneous planner and worker credit assignment yields super-additive gains, confirming the necessity of coordinated, tripartite reward structure.
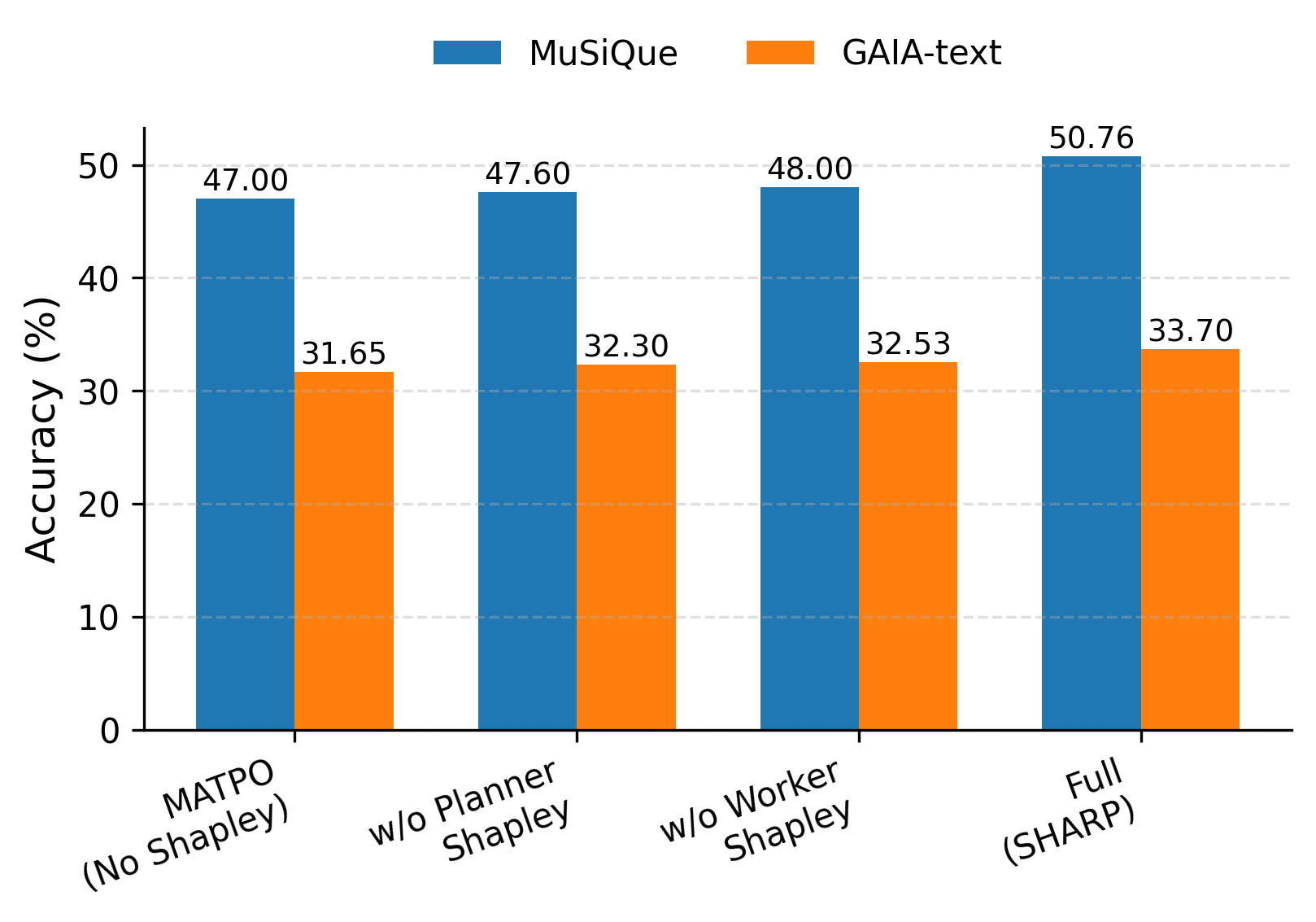
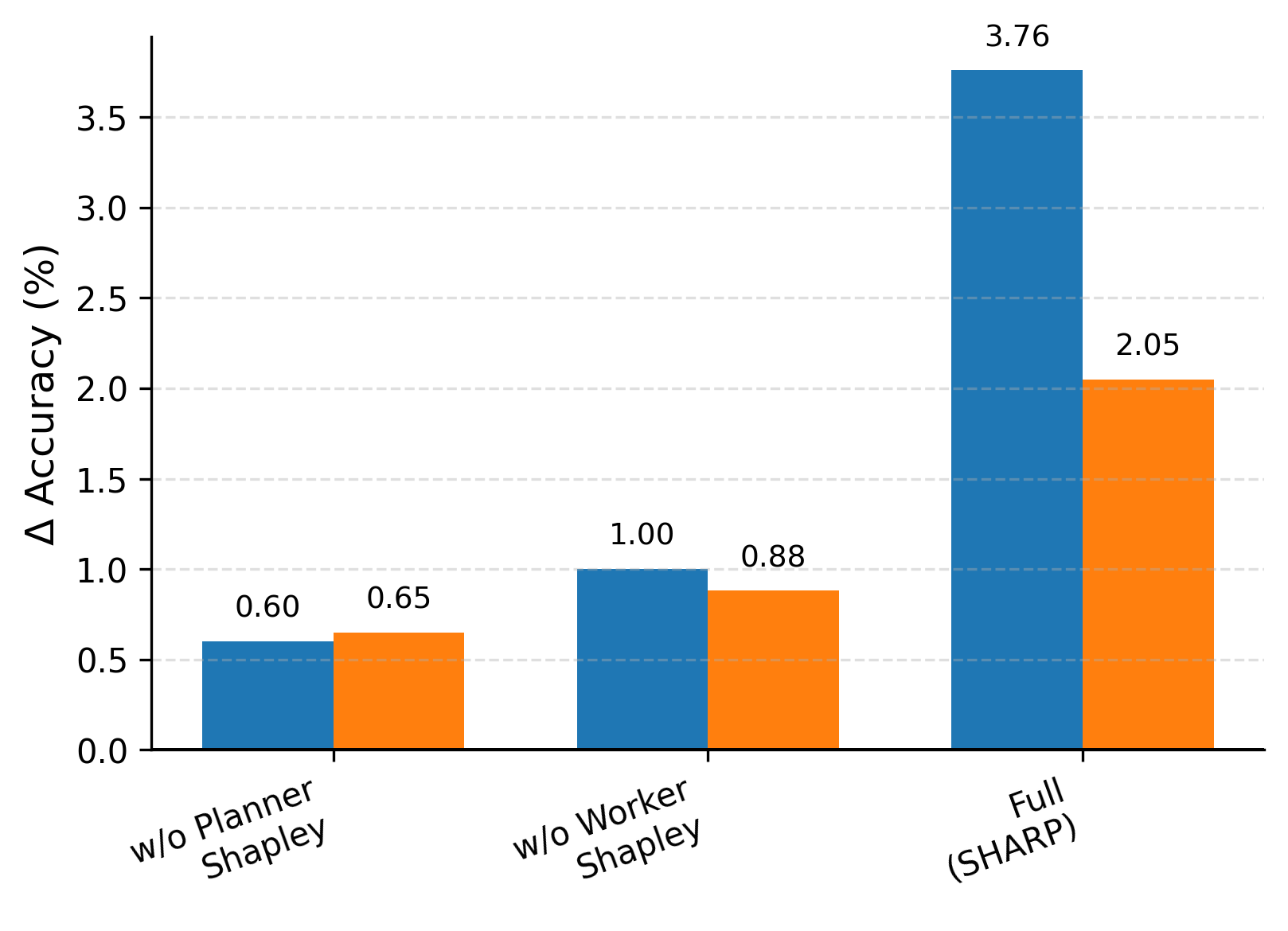
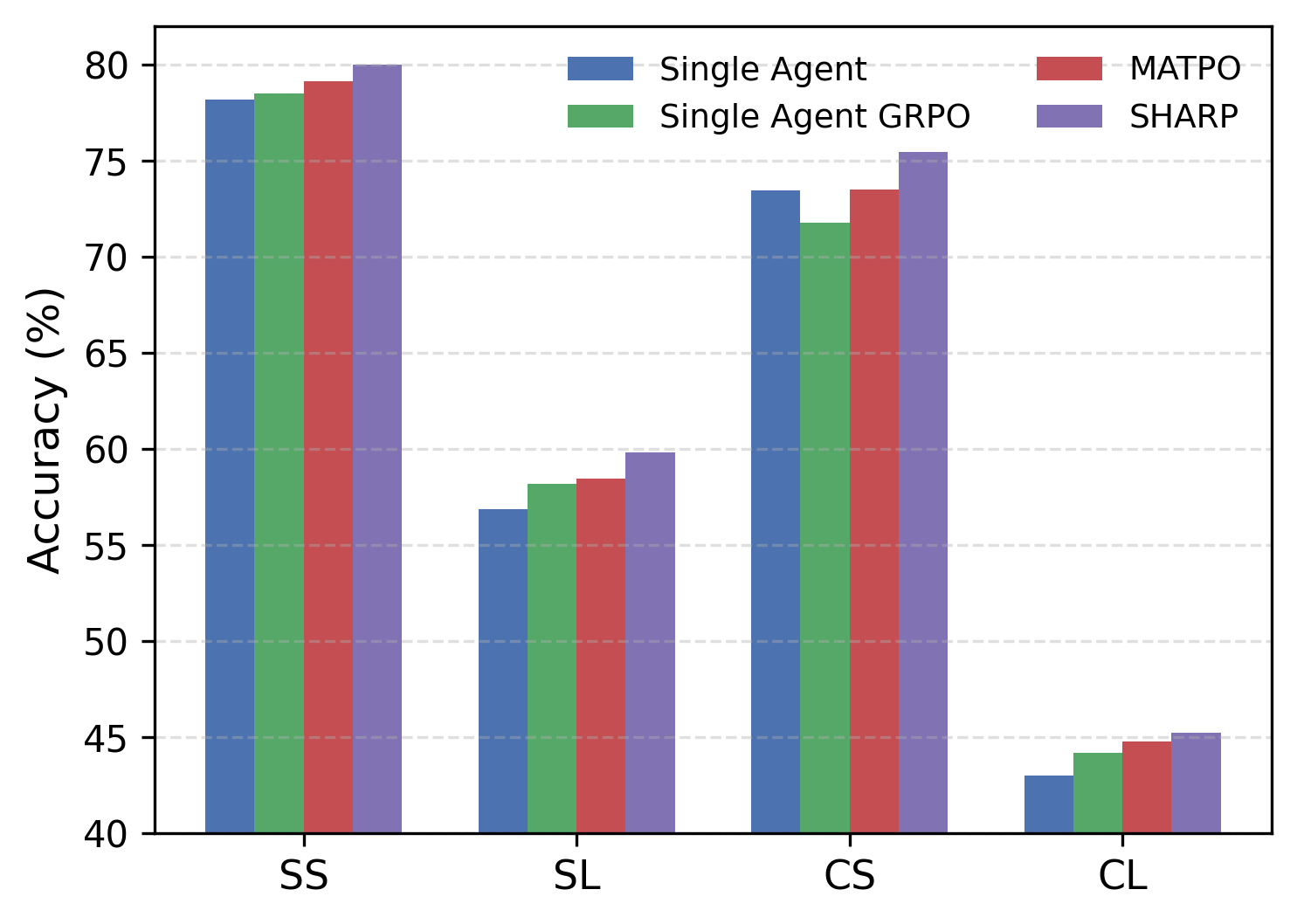
Figure 3: Left: Full SHARP vs. variants without planner/worker-level Shapley credit. Middle: Δ Accuracy vs. no-Shapley baselines. Right: Generalization to DocMath-Eval settings.
Parameter and training step scalability analysis show monotonic improvements—SHARP not only outpaces baselines at small model sizes but the margin increases with backbone scale.
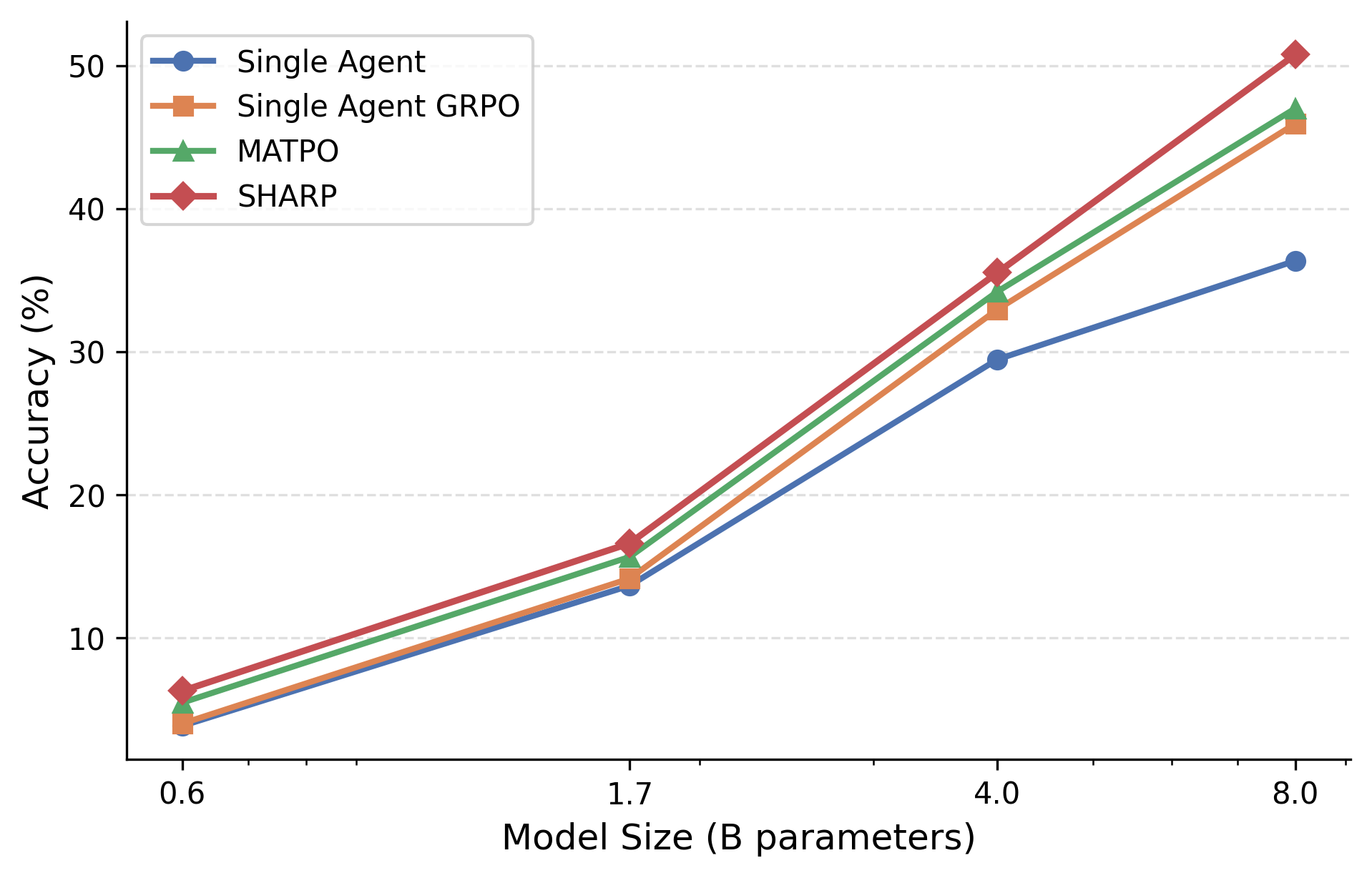
Figure 4: SHARP parameter scalability on MuSiQue—wider margins against baselines as model size increases.
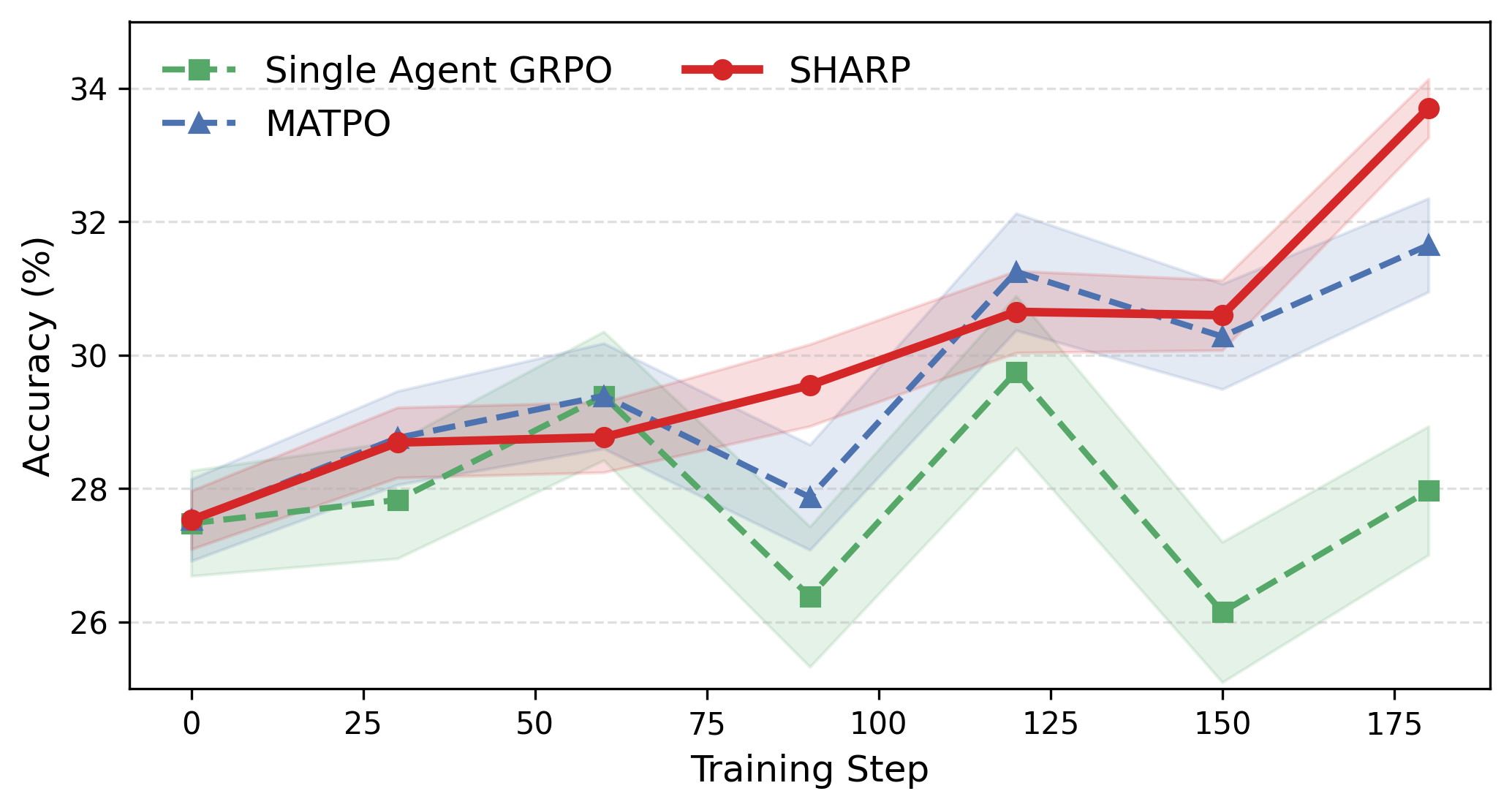
Figure 5: Training-step scalability on GAIA-text—steady improvement and reduced instability versus baseline.
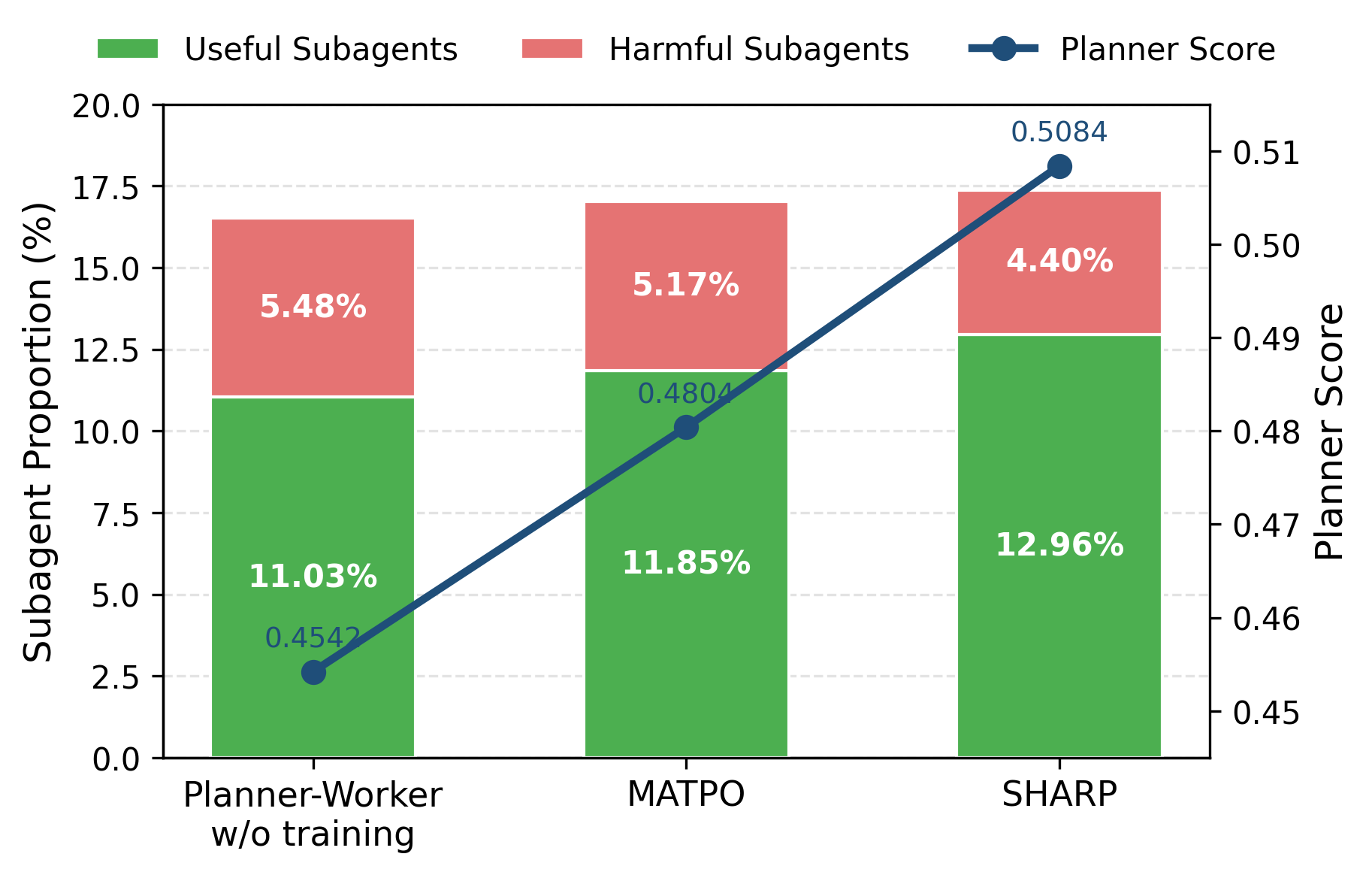
Coordination analysis based on Shapley-value-derived planner and subagent scores reveals:
Cost analysis demonstrates that increasing the frequency p of Shapley evaluation boosts final accuracy and reduces inference token cost, though at the expense of higher training compute. This establishes Shapley-based credit as a compute-for-coordination principle:
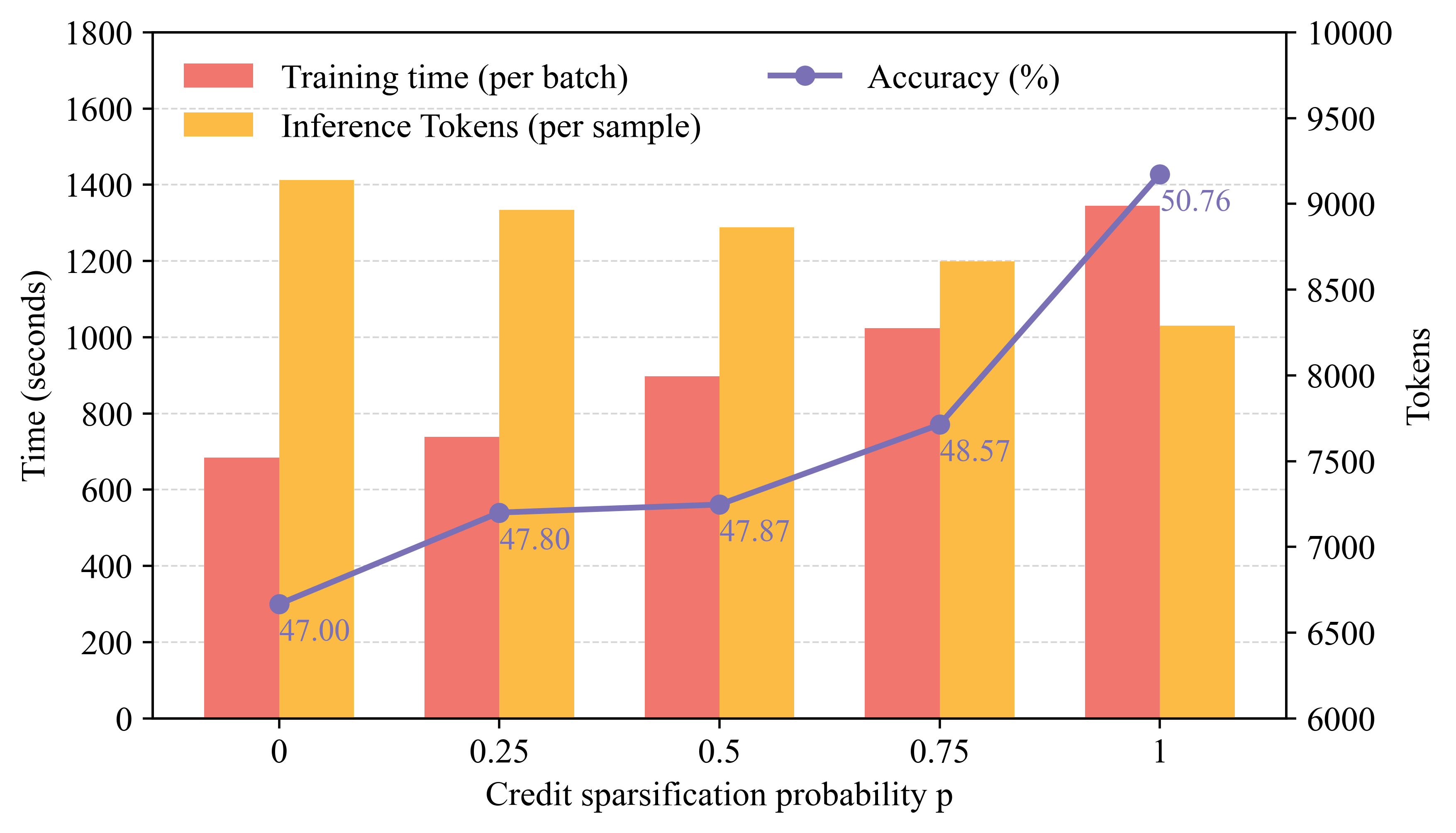
Figure 7: Trade-off between credit sparsification (training cost) and task performance/inference efficiency.
Implications and Forward Directions
Theoretical implications are twofold: (1) SHARP realizes the tractable application of Shapley values to hierarchical MARL in tool-integrated LLMs, thus providing fine-grained, rigorous causal attribution in the credit assignment bottleneck; and (2) the approach demonstrates that credit localization trumps mere architectural complexity or RL scheme selection in modern MAS optimization.
Practically, explicit marginal credit yields more robust agent coordination, faster convergence, less redundancy, and, crucially, a methodologically sound path toward scalable, interpretable multi-agent LLM deployment. The findings generalize across varying backbone scales, training regimes, and task distributions, indicating broad applicability to emergent tool-augmented agent frameworks.
However, persistent inefficiencies—such as the dominance of neutral or low-utility subagent calls—highlight the ongoing need for advances in agent pruning or meta-level policy control. Future research should address computational scaling of counterfactual analysis, hierarchical/pruned Shapley approximations, and finer integration of reward signals for systemic efficiency.
Conclusion
SHARP introduces a rigorous, Shapley-value-based decomposition of reward for multi-agent LLM optimization, delivering consistent state-of-the-art performance across demanding benchmarks. The framework's mathematical grounding in causal credit assignment stabilizes joint planner–worker training, fosters robust generalization, and reshapes coordination dynamics in collaborative MAS. These results establish SHARP as a foundation for scalable, interpretable, and compute-efficient multi-agent LLM systems with high-fidelity reward attribution (2602.08335).