Learning Human-Like Badminton Skills for Humanoid Robots
Abstract: Realizing versatile and human-like performance in high-demand sports like badminton remains a formidable challenge for humanoid robotics. Unlike standard locomotion or static manipulation, this task demands a seamless integration of explosive whole-body coordination and precise, timing-critical interception. While recent advances have achieved lifelike motion mimicry, bridging the gap between kinematic imitation and functional, physics-aware striking without compromising stylistic naturalness is non-trivial. To address this, we propose Imitation-to-Interaction, a progressive reinforcement learning framework designed to evolve a robot from a "mimic" to a capable "striker." Our approach establishes a robust motor prior from human data, distills it into a compact, model-based state representation, and stabilizes dynamics via adversarial priors. Crucially, to overcome the sparsity of expert demonstrations, we introduce a manifold expansion strategy that generalizes discrete strike points into a dense interaction volume. We validate our framework through the mastery of diverse skills, including lifts and drop shots, in simulation. Furthermore, we demonstrate the first zero-shot sim-to-real transfer of anthropomorphic badminton skills to a humanoid robot, successfully replicating the kinetic elegance and functional precision of human athletes in the physical world.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching a human-shaped robot (a “humanoid”) to play parts of badminton in a smooth, natural, and useful way. The big idea is to help the robot move like a skilled human player and also hit a fast, tiny shuttlecock at the right time and place. The researchers created a learning process that starts with copying human movements and gradually shifts to practicing real hits in a physics-based world, then transfers those skills to a real robot—without extra training on the hardware.
What questions did the researchers ask?
The team focused on simple, clear questions:
- How can a robot learn to move like a human athlete and still hit a fast-moving shuttlecock precisely?
- Can we turn “motion copying” (looking human-like) into “real interaction” (successful hitting) without losing the natural style?
- Is it possible to train these skills in simulation and use them on a real robot right away (called “zero-shot” transfer)?
How did they do it?
Think of how a person learns badminton:
- copy a coach’s moves,
- learn when and how to hit,
- practice maintaining good form,
- then hit real shuttlecocks at different spots and times.
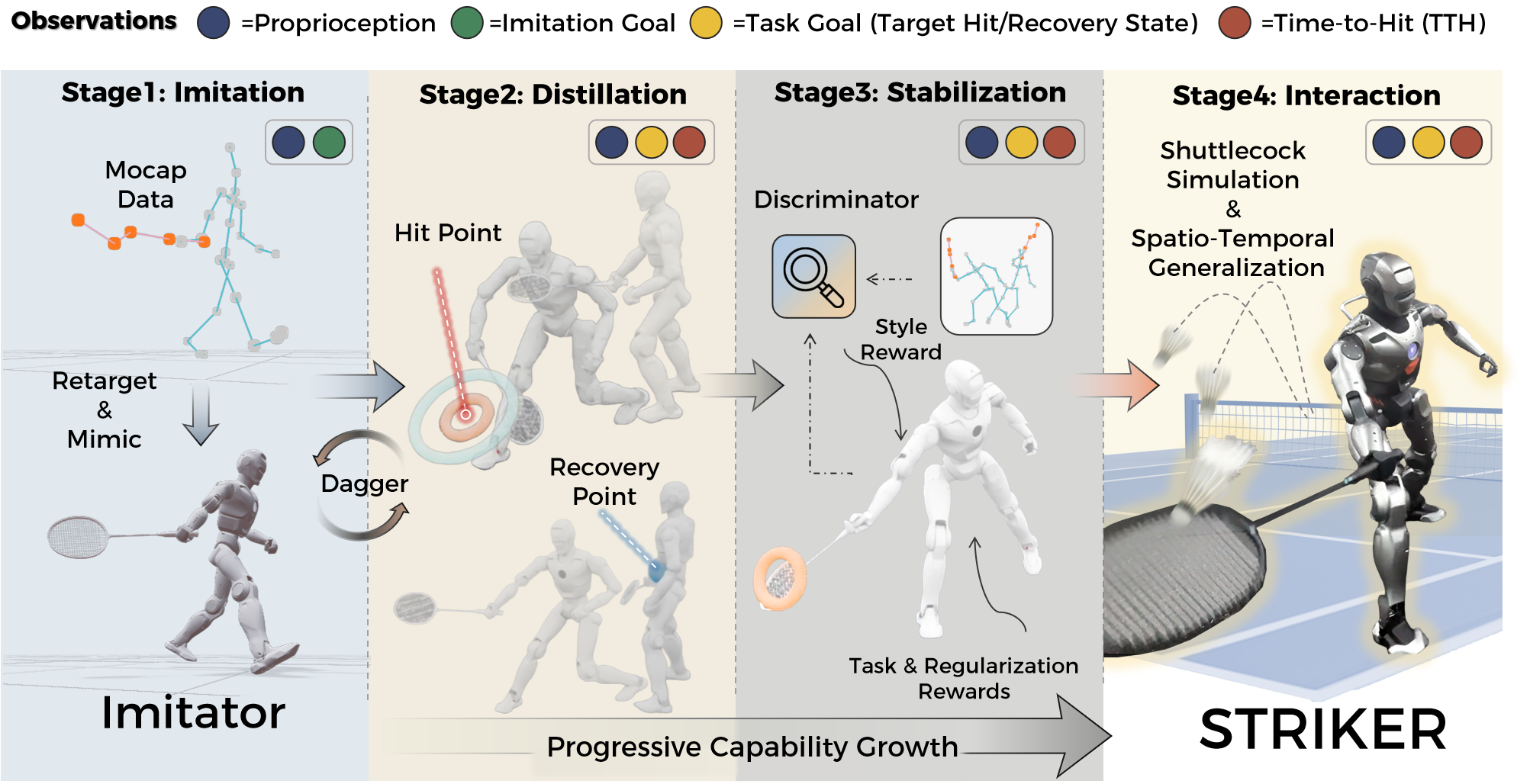
The researchers built a four-step training pipeline that works the same way.
Step 1: Imitation (learning from humans)
- They recorded expert badminton motions using motion capture (like the tech used for movies and games).
- A “teacher” controller learned to follow these motions closely, like a student copying a coach’s footwork and swings.
- They adjusted the human motions to fit the robot’s body, so poses stayed natural and balanced.
Step 2: Distillation (turning imitation into a goal-focused skill)
- They trained a “student” controller to learn from the teacher but with a simpler, more practical set of inputs.
- The key idea: Time-to-Hit (TTH), which is like a countdown to when the racket should meet the shuttlecock. The student focuses on:
- What to look like at the moment of impact (the “hit” target), and
- How to stand/recover right after the hit (the “recovery” target).
- This helps the robot switch from “copying a full routine” to “doing what’s needed for a good hit.”
Step 3: Stabilization (keeping the motion human-like)
- They used a “style judge” (called Adversarial Motion Priors, or AMP). Imagine a judge that scores whether the robot’s movements look human.
- This judge encourages the robot to keep good form while it fine-tunes its hitting accuracy, so it doesn’t drift into stiff or weird motions.
Step 4: Interaction (practicing with a simulated shuttlecock)
- Now the robot practices hitting a virtual shuttlecock with realistic physics (air drag, bounce, etc.).
- “Manifold expansion”: Instead of only practicing the few hit points seen in the human data, they generated many more possible strike locations and times. Think of turning a few dots into a cloud of practice targets, so the robot learns to hit across a wide area and timing range.
- The robot gets rewards when the shuttlecock lands in the right place and has good speed, not just when the pose looks right.
Extra details that helped:
- Domain randomization: Training in slightly different conditions (weights, friction, small delays, etc.) so the robot is ready for real-world messiness.
- Simulation with Isaac Sim, then testing on a real humanoid robot (EngineAI PM01).
- Real-world tracking used motion capture + a filter to predict the shuttlecock’s flight, so the robot knows where and when to swing.
What did they find, and why does it matter?
Here are the main outcomes:
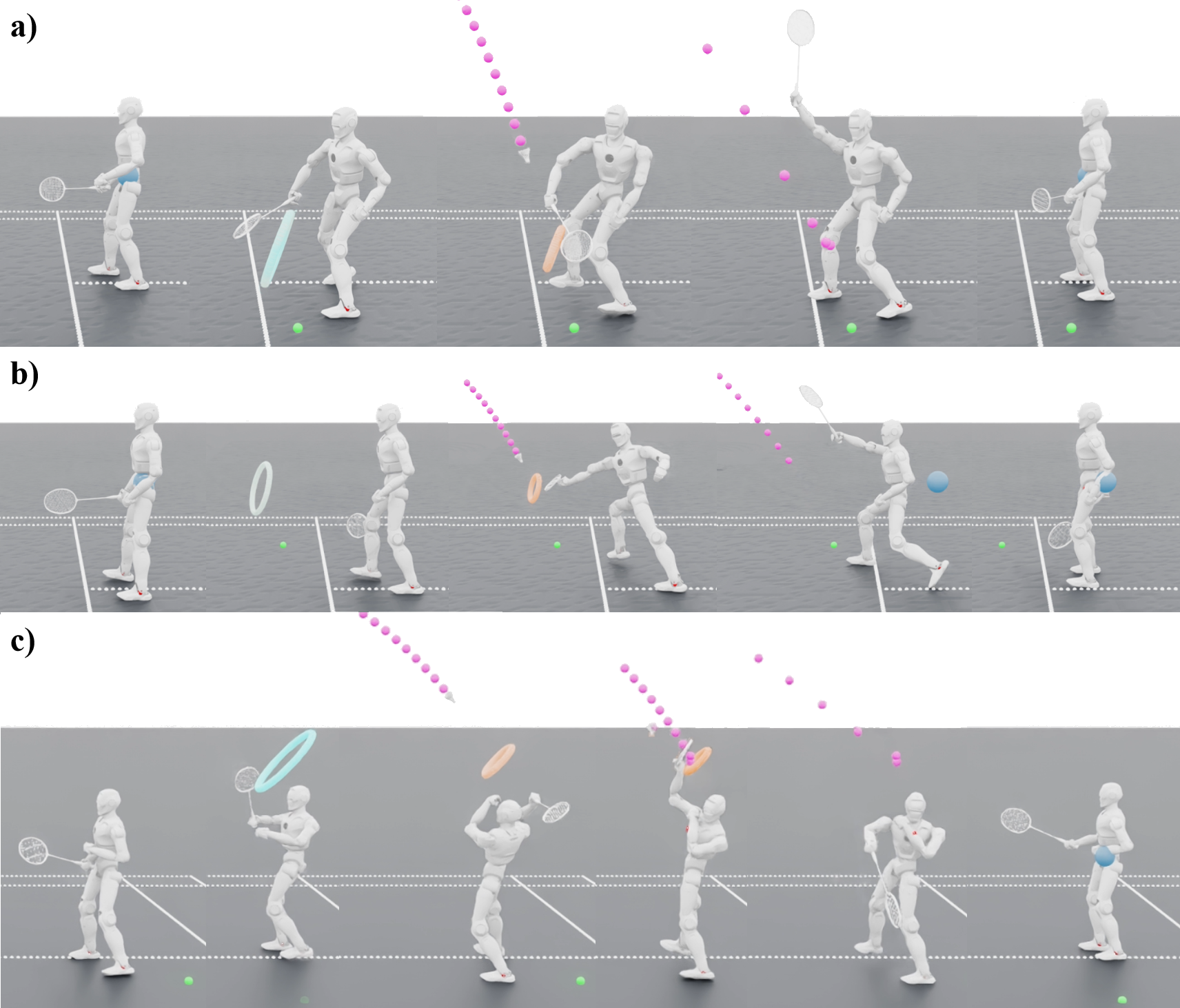
- The robot learned multiple badminton skills in simulation, including forehand and backhand lifts and drop shots, with smooth, human-like whole-body coordination.
- Zero-shot transfer: The same controller worked on a real robot without extra training. In 10 test tries, the robot succeeded about 90% of the time for forehand lifts and 70% for backhand lifts.
- The robot showed athletic behaviors seen in real players:
- Torso rotation to “whip” power into the swing,
- Aggressive lunges to reach far shots and quick recovery,
- Natural follow-through after hitting to stay balanced and reduce stress on joints.
- In simulation tests, the method had a very high success rate and precise hits across “easy” and “hard” difficulty settings, outperforming other approaches that either:
- trained everything end-to-end from scratch (which struggled to explore all useful poses), or
- used hierarchical “skill libraries” (which lacked the fine control needed for small, fast targets).
Why it matters:
- It shows that mixing imitation (for human-like style) with interaction learning (for real, physics-based tasks) can produce athletic, natural, and effective movements—something robots usually struggle to balance.
- It’s a step toward robots that can handle quick, precise actions in dynamic environments, not just slow or pre-scripted motions.
What’s the impact and what’s next?
This research suggests a general recipe for teaching robots tricky, timing-based skills:
- Start by copying expert motions to get the “feel” right,
- Then refocus on goals and real physics so the motions work in practice.
Potential impact:
- Sports training robots that move naturally,
- Robots that can interact safely and accurately with fast-moving objects (e.g., in factories, warehouses, or home environments),
- Better, more lifelike animation and control for entertainment or rehab robotics.
Limitations and next steps:
- Balancing three things—looking human-like, staying stable, and hitting accurately—is hard and still needs careful tuning.
- The current system focuses on single hits in a local area. Future work aims for longer rallies and full-court movement, plus smarter control that adapts to changing conditions even better.
Overall, this work is a big step toward robots that don’t just “look” athletic but can actually play like it—confidently, gracefully, and on time.
Knowledge Gaps
Below is a concise, actionable list of the paper’s unresolved knowledge gaps, limitations, and open questions to guide future research.
- Onboard perception and autonomy: Real-world experiments rely on external motion capture for robot/base pose and shuttlecock tracking; integrating onboard vision (e.g., multi-view RGB-D, stereo, event cameras) and inertial sensing with robust, low-latency fusion remains unaddressed.
- Uncertainty-aware perception-to-action: The hitting-point predictor (EKF) presumes reliable, low-latency mocap; policies that reason over perception uncertainty, occlusions, and delayed/noisy measurements are not developed.
- Real-world task scope: Only forehand/backhand lifts are demonstrated on hardware with 10 trials per skill; drop shots and other strokes are not tested on the robot, and the sample size is too small for statistical significance.
- Continuous rallies: The system handles single-shot interception in a localized area; continuous, closed-loop rallies with alternating hits (including opponent returns) are not addressed.
- Full-court coverage: Locomotion and footwork for traversing an entire court (including rapid transitions and split steps) are not realized; integration of high-speed whole-body locomotion with striking is left open.
- Multi-skill unification: It is unclear whether a single policy robustly covers multiple strokes; a unified, goal- or context-conditioned controller that selects/combines strokes online is not demonstrated.
- Game strategy and decision-making: There is no opponent modeling or strategic shot selection (e.g., targeting open court, exploiting opponent position); planning and control remain stroke-level without tactical reasoning.
- Real-court constraints: Real-world tests do not report the presence of a regulation net/court; validation against net clearance, court boundaries, and rally rules under real constraints is missing.
- Return quality metrics in real: Real-world evaluation reports only success rates; landing accuracy, trajectory control (height, angle), net-clearance margin, and rally-viability are not quantified.
- Shuttlecock physics fidelity: The aerodynamic and contact parameters used in simulation are not identified or validated against high-speed measurements; skirt deformation, orientation-dependent drag, and contact compliance are simplified.
- Sim-to-real calibration of impact: The mapping between racket kinematics at contact and post-impact shuttlecock flight is not calibrated with real data; contact parameter identification is missing.
- Manifold expansion validity: Expanded strike targets are generated heuristically around sparse MoCap samples without explicit dynamic reachability checks; sampling may include kinematically or dynamically infeasible targets.
- Reachability-aware curriculum: No mechanism ensures curriculum progression from easy to hard strike points based on robot reachability/stability; automatic curriculum design is an open avenue.
- Goal representation limitations: Time-to-hit (TTH) is clipped to [-2, 2] seconds and recovery timing is omitted from the observation; effects on long-horizon sequencing, anticipation, and timing policy are not analyzed.
- Phase inference and timing: The policy relies on TTH sign for phase; learning phase timing (when to initiate/prep/hit/recover) directly from observations, or inferring recovery timing, remains open.
- Stability–agility–precision trade-offs: Balancing human-like style, stability, and interception accuracy requires manual tuning; principled multi-objective or constrained RL formulations (with adaptive weights or Lagrangian constraints) are not explored.
- Style preservation and evaluation: AMP-based style control is included, but there is no systematic study of style-weight sensitivity, discriminator features, or objective naturalness metrics (e.g., jerk, cadence, human ratings).
- Hardware safety and limits: Joint torque, impact loads, thermal limits, and long-term wear from repetitive strikes are not modeled or constrained; compliant control and impact-aware safety mechanisms need investigation.
- Robustness profiling: Sensitivity to unmodeled real-world factors (joint friction/backlash, floor compliance, sensor dropout) is not quantified; online adaptation (e.g., residual learning, system identification) is an open direction.
- Latency-aware control: Randomizing latency helps, but no explicit latency compensation (e.g., predictive models, Smith predictors) is incorporated or evaluated.
- Policy memory: The policy appears feed-forward; recurrent architectures or temporal belief models for better prediction and timing under partial observability are not examined.
- Baselines and fairness: Underperforming baselines (ASE/VQ) may reflect tuning deficits; stronger baselines (e.g., expert-tuned MPC, hybrid MPC+RL, teleoperation imitation) and matched-tuning comparisons are needed.
- Training efficiency: Sample complexity, compute time, and data efficiency are not reported; methods to reduce training cost (e.g., offline RL, model-based RL, better warm starts) remain open.
- Cross-morphology transfer: Validation is on a single humanoid (PM01) with 5-DoF arms; generalization across different humanoids (varying mass, limb lengths, wrist DoFs) and retargeting scalability is untested.
- Equipment variability: Robustness to different rackets (mass, inertia, string tension) and shuttlecock types is not evaluated.
- Court-aware footwork planning: Coupling footprint selection, balance, and hitting under court geometry constraints (e.g., avoiding line faults) is unaddressed.
- Energy and thermals: Energy efficiency, heat buildup during rallies, and fatigue management (for motors and policy) are not measured or optimized.
- Failure mode taxonomy: The paper lacks a detailed analysis of failure causes (timing errors, reachability, misorientation, perception faults) and targeted remedial strategies.
- Safe real-world learning: All learning is offline in simulation; safe RL or shielded online fine-tuning on hardware (with safety monitors and fail-safes) is not explored.
- Reward design for rally readiness: Recovery is tracked, but no explicit metric for “time-to-ready” or readiness for the next shot is reported; optimizing for rally continuation is an open area.
- Data and reproducibility: Details of the MoCap dataset, network architectures, hyperparameters, training curves, and whether code/data will be released are lacking; reproducibility remains uncertain.
Practical Applications
Immediate Applications
The following applications can be deployed or prototyped now by leveraging the paper’s policy design, training pipeline, and sim-to-real practices.
- Humanoid badminton drill partner for labs and demos — sectors: robotics, sports tech, entertainment
- What: Use the provided Imitation-to-Interaction controller to return forehand/backhand lifts and basic drop shots in controlled courts for demonstrations, exhibitions, and internal testing.
- Tools/products/workflows: Pretrained policy + Isaac Sim environment; PM01 or similar humanoid; EKF-based shuttle tracking; shuttle trajectory predictor; domain-randomized deployment stack.
- Dependencies/assumptions: External motion capture or high-accuracy tracking sensors; flat court; safety perimeter; compliant racket mounting; robot torque and wrist DoFs may limit repertoire.
- Aerial interception benchmark suite — sectors: academia, robotics R&D
- What: Adopt the paper’s metrics (Success Rate, MSE at impact, In-Bounds Reward), tasks (easy/hard striking volumes), and pipeline for standardized benchmarking of whole-body interception on humanoids.
- Tools/products/workflows: Isaac Lab task configs; automated evaluation harness; leaderboards; ablation checklists (w/o Stab., w/o Interact., E2E-AMP).
- Dependencies/assumptions: Access to simulation infrastructure (Isaac Sim); reproducible randomization settings; agreed task volumes and court geometry.
- Motion retargeting toolkit for humanoids with limited DoF — sectors: robotics, animation/VFX, education
- What: Reuse the parallel optimization-based retargeting (global/local alignment, ee rotation, collision, limits, smoothing) to convert human MoCap into physically feasible humanoid motions.
- Tools/products/workflows: Batch retargeting scripts; contact sequence extraction; joint-limit aware solvers; style-preserving post-processing.
- Dependencies/assumptions: Quality MoCap; roughly similar morphology or scaling; known joint limits and collision models.
- Goal-conditioned controller design pattern (Time-to-Hit, Hit/Recovery targets) — sectors: robotics software, RL research
- What: Port the student policy’s state design (TTH clipping, phase-masked goals) to other timed impact tasks (e.g., table tennis returns, batting, hammering).
- Tools/products/workflows: Goal encoder module; phase-masked observation wrappers; DAgger-based distillation playbook.
- Dependencies/assumptions: Event-time estimates (from prediction or sensors); stable proprioception; synchronized clocks; calibrated phase transitions.
- AMP-stabilized athletic motion learning — sectors: animation/game engines, humanoid control stacks
- What: Apply Adversarial Motion Priors during RL finetuning to keep human-like style while improving task precision for sports or dynamic gestures in games/robots.
- Tools/products/workflows: LSGAN discriminator with temporal windows; style reward integration; curated motion banks.
- Dependencies/assumptions: Sufficient style reference data; discriminator stability (regularization); compute budget for adversarial training.
- Interaction manifold expansion for sparse demos — sectors: RL/robotics research, industrial training pipelines
- What: Use the proposed “strike manifold” enrichment to convert sparse demonstration points into dense target volumes for faster generalization in any contact/timed interaction.
- Tools/products/workflows: Target-space samplers around demo events; physics-informed augmentation; curriculum schedulers.
- Dependencies/assumptions: A usable forward model (e.g., ballistics) to sample meaningful targets; safety limits for expanded states; validation to avoid out-of-distribution drift.
- Perception and prediction for flying-object interception — sectors: sports tech, robotics labs
- What: Deploy the EKF-based shuttle state estimator and short-horizon trajectory predictor to enable anticipatory strikes in lab settings.
- Tools/products/workflows: Sensor fusion (MoCap + IMU/cameras); latency-aware prediction; target point selector feeding TTH and impact goals.
- Dependencies/assumptions: Reliable 3D tracking; known sensor latency; robust time synchronization; fallback strategies for lost tracking.
- Sim-to-real domain randomization recipes for dynamic striking — sectors: robotics industry, QA/validation
- What: Reuse the paper’s randomization ranges (mass, CoM, PD gains, latency, friction, restitution, terrains) as a starting regimen for agile, contact-rich transfer.
- Tools/products/workflows: DR parameter packs; perturbation injectors; regression tests for transfer robustness.
- Dependencies/assumptions: Reasonable overlap between sim and hardware envelopes; safe recovery controllers; logging/telemetry to refine DR bounds.
- Educational modules and course labs — sectors: higher education, professional training
- What: Turn the four-stage pipeline (Teacher tracking → DAgger distillation → AMP stabilization → Interaction refinement) into hands-on labs that teach imitation + RL for interaction.
- Tools/products/workflows: Stepwise assignments; ablation experiments; shared code templates in Isaac.
- Dependencies/assumptions: GPU resources; simulator licenses; curated MoCap datasets; instructor expertise in safety and RL.
Long-Term Applications
The following applications require further research in perception, locomotion, strategy, safety, or scaling beyond the paper’s current scope.
- Full-court, vision-based humanoid badminton opponent — sectors: sports tech, entertainment
- What: A robot that rallies across a regulation court using onboard vision, whole-body locomotion, and shot selection/strategy.
- Tools/products/workflows: Onboard multi-camera tracking; SLAM-based positioning; locomotion + striking co-optimization; rally-level policy.
- Dependencies/assumptions: Reliable low-latency perception without MoCap; stronger actuation/endurance; safety certification for close human-robot play.
- Personalized coaching and ball-feeding assistant — sectors: consumer fitness, coaching analytics
- What: A humanoid that returns shots with specified speed/placement to train athletes with adaptive difficulty and feedback.
- Tools/products/workflows: Placement controllers (direction/speed rewards); user models; performance dashboards; session planning.
- Dependencies/assumptions: Repeatable placement accuracy; robust human-intent interfaces; liability coverage and safe physical interaction protocols.
- High-speed timed handoffs on manufacturing lines — sectors: manufacturing, logistics
- What: Apply TTH goal-conditioning and manifold expansion to synchronize robot handoffs with moving conveyors or flying parts.
- Tools/products/workflows: Conveyor-phase encoders; event-time predictors; safety-rated handover detection; compliance control.
- Dependencies/assumptions: Millisecond timing; robust sensing of part pose; collaborative safety standards; grippers tailored to part dynamics.
- Dynamic catching and safe interception in homes — sectors: household robotics, eldercare
- What: Catch falling or thrown objects (e.g., dropping a cup) and return them safely using human-like movements.
- Tools/products/workflows: Vision-based fall detection; safe impact handling; compliant arms; household object libraries.
- Dependencies/assumptions: Reliable detection in clutter; soft-contact control; risk mitigation near people; lightweight end-effectors.
- Athletic motion library for general-purpose humanoids — sectors: robotics platforms, developer ecosystems
- What: Distributable “athletic primitives” (lunges, whips, overhead strikes) pre-trained via imitation-to-interaction for downstream tasks.
- Tools/products/workflows: Skill APIs; model zoos; cross-robot retargeting; style-preserving finetuning.
- Dependencies/assumptions: Standardized humanoid interfaces; licensing for datasets; retargeting quality across varied morphologies.
- Robotic goalkeeping and interception in other sports — sectors: sports robotics, research
- What: Extend to soccer/handball goalkeeping, baseball/tennis returns—any fast aerial interception with event-time targets.
- Tools/products/workflows: Sport-specific physics modules; multi-skill schedulers; strategic decision layers.
- Dependencies/assumptions: Domain-specific perception (ball spin, seams); stronger joints/wrists; sport venue safety and compliance.
- Time-critical tool use (hammering, riveting, stamping) — sectors: construction, fabrication
- What: Learn precise, timed impacts with tools using the TTH representation and AMP stabilization for human-like, efficient motions.
- Tools/products/workflows: Tool dynamics models; contact-rich reward shaping; vibration/impact sensing.
- Dependencies/assumptions: Accurate contact simulation; robust tool fixtures; durability and maintenance under repetitive impacts.
- Human-robot handover with rhythmic timing — sectors: HRI, logistics, healthcare
- What: Smooth, rhythmic exchanges (medication, instruments, packages) coordinated to an agreed beat/event time for predictability.
- Tools/products/workflows: Mutual timing protocols; intent estimation; comfort/style priors via AMP.
- Dependencies/assumptions: Reliable intent signaling; user acceptance; formal safety verification for close contact.
- Policy productization on embedded compute — sectors: robotics hardware, edge AI
- What: Distill large training policies into compact controllers (student variants) running on embedded CPUs/NPUs.
- Tools/products/workflows: Quantization, pruning, and distillation toolchains; latency-aware control loops.
- Dependencies/assumptions: Deterministic real-time execution; hardware-accelerated inference; fallback safety layers.
- Standards and safety certification for dynamic humanoid sports — sectors: policy/regulation, insurance
- What: Use the benchmark tasks and metrics to define acceptance tests, operational envelopes, and insurance guidelines for public demos and venues.
- Tools/products/workflows: Test protocols (SR/MSE thresholds; net-clearance constraints); black-box safety audits; incident reporting.
- Dependencies/assumptions: Multi-stakeholder consensus (manufacturers, venues, insurers); legal frameworks for liability; standardized courts/testbeds.
Glossary
Adversarial Motion Priors (AMP): A technique used in reinforcement learning where a discriminator network is trained to distinguish between generated and ground-truth motions to enforce stylistic plausibility. Example: "Stage 3 utilizes pure trial-and-error optimization to shift the focus towards high-precision racket tracking...utilizing RL with AMP."
DAgger: A method for distilling the teacher's knowledge into a student policy, leveraging a supervised learning approach to iteratively refine the policy based on expert demonstrations. Example: "We distill the teacher's knowledge into a student policy using DAgger."
Extended Kalman Filter (EKF): An algorithm used to estimate system states in real time from noisy measurement data, often applied in robotics for sensor fusion. Example: "We implement an Extended Kalman Filter (EKF) that estimates the ball's full state (position and velocity) from the raw motion capture observations."
Least-Squares GAN (LSGAN): A version of Generative Adversarial Networks where the discriminator network uses a least-squares objective function to stabilize training. Example: "The optimization objective follows the Least-Squares GAN (LSGAN) formulation with a gradient penalty."
Proprioceptive Observation: Observations derived from sensors that measure the robot's internal state, such as joint angles and velocities. Example: "The teacher observation at timestep includes three components: proprioceptive observation."
Reinforcement Learning (RL): A machine learning paradigm where agents learn to make decisions by receiving feedback from interactions with their environment. Example: "The framework utilizes pure trial-and-error optimization using RL with AMP to refine the student's tracking stability."
Sim-to-Real Transfer: The ability to transfer a policy trained in simulation directly to a real-world robot without further training or adjustment, often facilitated by techniques like domain randomization. Example: "We achieve the first zero-shot sim-to-real transfer of whole-body badminton skills to a humanoid robot."
Task-Oriented Execution: A control strategy that focuses on achieving task-specific goals rather than replicating demonstration motions verbatim. Example: "This stage transitions the control strategy from pure tracking to task-oriented execution."
Time-to-Hit (TTH): A scalar used to indicate the remaining time until impact between the racket and the shuttlecock, facilitating the timing of actions in the context of reinforcement learning. Example: "We formulate the hitting task as a goal-conditioned task, where the goal is represented using a model-based approach... Time-to-Hit (TTH): A scalar indicating the remaining time until impact."
Zero-Shot Transfer: Transferring a model learned in one context directly to another context without additional training, testing its adaptability to new conditions or environments. Example: "Furthermore, we demonstrate the first zero-shot sim-to-real transfer of anthropomorphic badminton skills to a humanoid robot."
Collections
Sign up for free to add this paper to one or more collections.