- The paper presents a three-stage hierarchical framework that decomposes motion tracking, latent-space skill distillation, and competitive LS-NFSP training for autonomous humanoid boxing.
- The paper demonstrates significant improvements in tactical performance and physical stability, evidenced by superior metrics such as offensive landing and engagement rates.
- The paper validates its approach through rigorous ablation studies and successful sim-to-real transfer experiments on Unitree G1 humanoid platforms.
Hierarchical Latent-Space Decision-Making for Autonomous Humanoid Boxing: Analysis of RoboStriker
Framework Overview and Motivation
The RoboStriker framework introduces a modular, three-stage hierarchy for competitive humanoid boxing, addressing two outstanding challenges in embodied MARL: (1) the conflict between physically feasible motor control and non-stationary strategic exploration and (2) the instability from policy co-evolution in high-dimensional physical domains. Existing approaches either isolate skill tracking via imitation (e.g., DeepMimic, AMP) or directly explore competitive strategies (e.g., fictitious play/NFSP in abstract games), but none resolve the entanglement of balance, maneuver diversity, and opponent adaptation intrinsic to humanoid multi-agent tasks.
RoboStriker decomposes the problem: Stage I pretrains a universal motion tracker—a DeepMimic-styled policy—capable of high-fidelity replication of a large corpus of human boxing maneuvers. Stage II distills these expert demonstrations into a compact latent space, regularized by a hyperspherical constraint, which is key: it bounds agent exploration to a strictly physically plausible manifold, preventing catastrophic failures from out-of-distribution motor actions and facilitating smooth, compositional skill transitions. Stage III introduces curriculum-guided competitive training: warmup against static opponents to ensure tactical proficiency and balance, followed by Latent-Space Neural Fictitious Self-Play (LS-NFSP), leveraging NFSP dynamics within the latent strategy manifold. Agents thus learn tactical co-adaptation with embedded physical priors, addressing both the cold-start and non-stationarity issues.
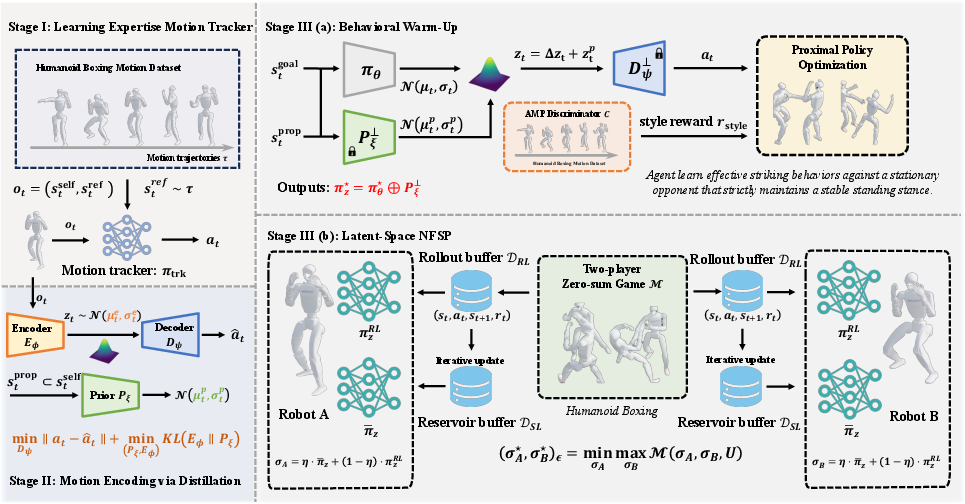
Figure 1: The three-stage architecture of RoboStriker, from generative motion pretraining to bounded latent compression and competitive multi-agent self-play in the latent space.
Latent Space Structuring and Skill Distillation
A critical innovation is the projection of motion primitives onto a normalized, bounded latent manifold. The student–teacher architecture uses a Gaussian encoder, state-conditioned prior, and decoder to produce a 32D structured latent code for each observed behavior. The latent space is regularized by both KL-divergence to the prior and normalization onto a unit hypersphere, yielding theoretical guarantees of compactness and strategy set boundedness. This facilitates the existence of mixed-strategy Nash equilibria and avoids skill collapse during policy optimization.
The topology of the learned latent space is empirically shown, via t-SNE embedding visualizations, to exhibit semantic clustering of boxing primitives (Move, Strike, Move+Strike). Transitional regions offer compositional skill mixing, supporting fluid behavioral switching (navigation plus attack) crucial for dynamic boxing.
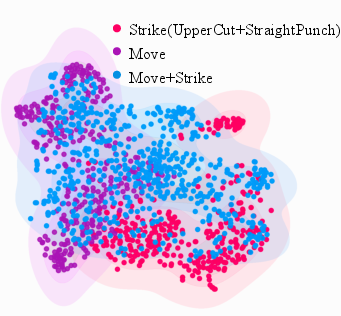
Figure 2: t-SNE of the 32D latent space, showing semantic clusters and smooth topological bridges between movement and striking skills used in hierarchical decision-making.
Competitive Learning via LS-NFSP
RoboStriker formalizes competitive boxing as a two-player zero-sum Markov game in the latent action space. LS-NFSP instantiates fictitious play dynamics in the latent space, with independent best-response reinforcement learning (via PPO) and explicit average policy networks per agent. Empirical action histories are managed via a reservoir buffer, ensuring representative averaging and mitigating cycling. The mixture parameter η modulates exploration versus exploitation, and competitive reward shaping is tightly coupled with style reward via an AMP discriminator to ensure both tactical efficiency and physical authenticity.
The theoretical analysis, under the latent space’s compactness and bounded payoffs, establishes convergence guarantees to ϵ-Nash equilibria for the learning dynamics. Approximate best response and average policy mixing, proved under bounded error rates, ensure that the agents’ empirical policies converge to theoretically sound, non-exploitable strategies.
Quantitative Results and Ablations
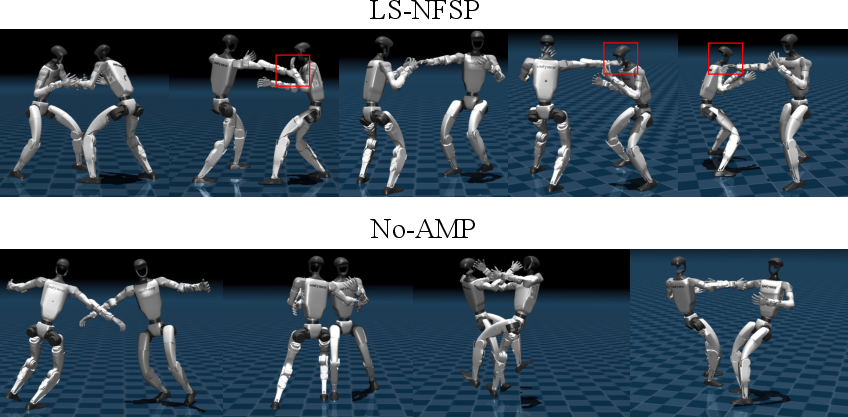
RoboStriker outperforms all baselines in both tactical and physical performance metrics. Key metrics include Offensive Landing Rate (ηhit=0.685), Engagement Rate (ER=0.824), Base Orientation Stability (BOS=0.942), and Torque Smoothness (TSτ=0.930). The LS-NFSP policy decisively dominates direct joint-space self-play (100% win rate), naive self-play, and PPO-only policies, substantiating the necessity of the latent-space decomposition and curriculum warmup for robust competitive learning. Strong empirical effects are observed: competitive policies trained directly in the raw 29-DoF joint space suffer nearly entire collapse (offensive landing rate $0.142$, ER=0.315), whereas those in latent space reliably execute complex contact-rich boxing maneuvers and rhythmic defense.
Ablations further clarify contributions:
Sim-to-Real Transfer and Stylistic Authenticity
Zero-shot transfer experiments on Unitree G1 humanoids show that the LS-NFSP-trained agent, using only simulated domain randomization, can execute high-momentum, contact-rich boxing strategies in real environments subject to hardware constraints, confirming the robustness of the latent manifold and curriculum design. Visual qualitative analysis demonstrates stylistic authenticity: the emergent behaviors include slips, counters, and reactive footwork consistent with professional boxing, without collapse into degenerate policies or unnatural postures.

Figure 4: Real-world implementation: agile, physically plausible boxing maneuvers by the RoboStriker-trained agent, with defense and attack strategies under real hardware limitations.
Implications and Future Directions
The hierarchical latent-space formulation and competitive self-play architecture of RoboStriker constitute a scalable recipe for embodied tactical intelligence. The theoretical convergence and empirical robustness in high-DOF, contact-rich domains suggest generalized applicability to other multi-agent physical tasks beyond boxing—team sports, autonomous confrontation scenarios, or human–robot mixed adversarial settings.
Key future research directions include:
- Extension of latent-space regularization to multi-modal or cross-domain motion encodings for broader task generalization.
- Integration of further game-theoretic learning dynamics (e.g., meta-population best response, double oracle) with latent representations.
- Exploration of co-adaptive curriculum scheduling in real environments, using feedback from hardware sensory streams for finer sim-to-real alignment.
- Investigation into multi-agent negotiation, alliance formation, and non-zero-sum physical games under hierarchical latent controllers.
- Fusion of generative motion foundation models with adversarial multi-agent training protocols to broaden the behavioral envelope and robustness.
Conclusion
RoboStriker demonstrates that hierarchical decomposition—combining motion tracking, topological skill distillation, and latent-space competitive self-play—resolves the contradictions of multi-agent learning in high-dimensional physical spaces. LS-NFSP exploits structured latent manifolds for both tactical diversity and physical stability, achieving superior performance, provable equilibrium convergence, and real-world transfer. This research sets a foundation for principled, scalable multi-agent learning in physically instanced robotics (2601.22517).