Step-resolved data attribution for looped transformers
Published 10 Feb 2026 in cs.LG and cs.AI | (2602.10097v1)
Abstract: We study how individual training examples shape the internal computation of looped transformers, where a shared block is applied for $τ$ recurrent iterations to enable latent reasoning. Existing training-data influence estimators such as TracIn yield a single scalar score that aggregates over all loop iterations, obscuring when during the recurrent computation a training example matters. We introduce \textit{Step-Decomposed Influence (SDI)}, which decomposes TracIn into a length-$τ$ influence trajectory by unrolling the recurrent computation graph and attributing influence to specific loop iterations. To make SDI practical at transformer scale, we propose a TensorSketch implementation that never materialises per-example gradients. Experiments on looped GPT-style models and algorithmic reasoning tasks show that SDI scales excellently, matches full-gradient baselines with low error and supports a broad range of data attribution and interpretability tasks with per-step insights into the latent reasoning process.
The paper introduces Step-Decomposed Influence (SDI), which decomposes traditional TracIn attribution over individual recurrent steps in looped transformers.
It leverages TensorSketch for scalable, memory-efficient gradient sketching, providing theoretical guarantees on variance and enabling larger batch sizes.
The method reveals dynamic credit assignment and mechanistic insights in tasks like parity and Sudoku, informing test-time compute calibration and dataset curation.
Step-Decomposed Influence Attribution in Looped Transformers
Introduction
"Step-resolved data attribution for looped transformers" (2602.10097) introduces Step-Decomposed Influence (SDI), a method for granular attribution of training data in looped transformer architectures. Looped transformers, where a shared block is recurrently applied for τ steps, underpin recent advances in latent reasoning, length generalization, and scalable test-time compute allocation. Traditional influence estimators (e.g., TracIn) yield single scalar scores, aggregating across loop iterations and failing to resolve when training data impacts internal computation. SDI decomposes TracIn trajectory-wise, attributing influence to individual recurrent steps. The paper leverages TensorSketch for scalable, memory-efficient estimation, delivers theoretical guarantees on sketch variance, and demonstrates practical MechInterp, scaling, and memorization analyses in both algorithmic and language settings.
SDI: Formulation and Theoretical Properties
SDI builds on the observation that in looped transformers, the body gradient with respect to the shared block unrolls into a sum over recurrent iterations. Specifically, the TracIn estimator aggregates gradient dot products from training and test points over checkpoints:
TracInw(z,z′)=k=1∑Kηk∇wℓ(wk;z)⋅∇wℓ(wk;z′)
SDI decomposes this by step, defining step-localized influence:
It(z,z′)=k=1∑Kηk∇wbodyℓ(wk;z)⋅ϕt(wk;z′)
where ϕt denotes the contribution from step t within the unrolled forward pass. The conservation identity shows:
TracIn(z,z′)=t=1∑τIt(z,z′)
ensuring that SDI fully and losslessly decomposes standard TracIn.
Scalable Implementation via TensorSketch
Naïve stepwise gradient materialization is prohibitive at transformer scale. SDI adopts a sketch-during-backprop paradigm using CountSketch and TensorSketch—linear random projections that preserve inner products with controlled variance and eliminate the need for full per-example gradients. Gradients for vector parameters are CountSketched; matrix gradients, constructed as sums of outer products, are TensorSketched via convolution. Theoretical analysis yields a tight variance bound on sketch inner products:
Var[⟨X~,Y~⟩]≤(m24+m6)∥X∥F2∥Y∥F2
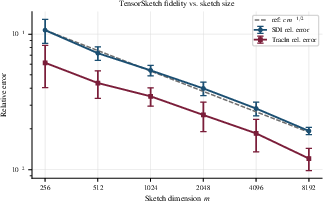
where m is the sketch dimension. Empirically, sketching enables batch sizes 10× larger with negligible runtime overhead and error scaling as O(1/m).
Figure 1: Empirical error scaling with sketch dimension m, showing SDI error decays as m increases.
SDI in MechInterp and Algorithmic Tasks
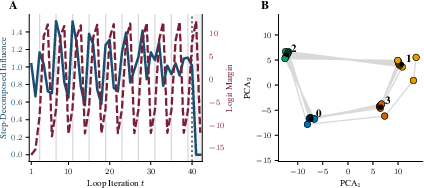
SDI's step-resolved trajectory offers mechanistic signatures elusive to scalar attribution. In the parity task, SDI reveals latent periodic computation in a looped transformer trained with curriculum on increasing sequence length. Applying SDI to a probe sequence uncovers oscillatory influence with period matching a finite-state limit cycle observed in logit dynamics and hidden state PCA.
Figure 2: SDI applied to an alternating parity probe. Stepwise influence shows sawtooth periodicity, and PCA of hidden states confirms a four-state cycle.
Discretizing latent states yields a transition graph matching the algorithmic circuit underlying parity computation, and a learned state-to-parity mapping achieves exact accuracy on held-out test inputs, including length generalization beyond the training curriculum.
Scaling Laws and Compute Sensitivity in Sudoku
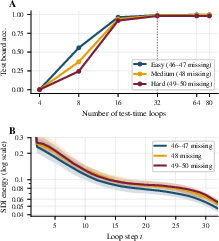
On algorithmic reasoning benchmarks (SATNet Sudoku), SDI connects test-time compute scaling with stepwise influence patterns. Looped transformers allow dynamic recursion at inference via τ; harder puzzles are highly compute sensitive, with accuracy dependent on loop count. SDI energy curves (aggregate stepwise absolute influence) show that for hard instances, late iterations retain high influence, indicating persistent saliency of additional recurrent steps when test-time compute yields marginal gains.
Figure 3: Left: Test-board accuracy vs. number of test-time loop iterations, stratified by puzzle difficulty; Right: SDI energy across loop steps.
Memorization and Depth-Coupled Influence
Cross-influence and memorization analyses in Sudoku show that harder training puzzles have systematically higher self-influence and cross-influence mass, echoing optimization-driven memorization in non-transformer networks. SDI decomposes influence timing, revealing that late loop iterations accumulate more stepwise energy from hard training examples, mirroring the role of deep layers in classic models for memorization and generalization.
Latent Progress Signaling in LLMs
SDI applied to a $330$M-parameter looped Nanochat LLM demonstrates exponential concentration of influence in late loop steps during reasoning tasks (GSM8K). Full BPTT analysis across loop horizons confirms that the majority of training-data influence is exerted within the last few recurrent steps, independently of overall τ. The model appears to encode an implicit progress counter, spontaneously localizing influential dynamics to late recursion, even absent explicit step embeddings.
Figure 4: Signed SDI share per step t for GSM8K in Nanochat, showing geometric increase of influence with depth and concentration in the last loop steps.
Practical and Theoretical Implications
SDI provides unmatched granularity for credit assignment in weight-tied looped architectures. Practically, it enables:
Calibration of test-time compute by identifying the influence horizon (where additional steps no longer matter)
Detection of signal cancellation (where opposing influence at early vs. late steps goes unseen in aggregate attribution)
Mechanistic circuit discovery, bridging MechInterp and data-centric interpretability
Theoretically, SDI reveals that looped transformers learn to represent progress and exert dynamic, depth-localized credit assignment, even when trained with truncated BPTT and stochastic horizons.
Limitations and Outlook
While TracIn and SDI are interpretable under SGD, optimizer-specific dynamics (momentum, adaptive preconditioning) reduce faithfulness to theoretical influence functions. Step indices in SDI are tied to analysis horizon and may be obfuscated by truncated BPTT or adaptive halting. Full-horizon SDI remains expensive for very long recurrences. Future extensions include:
Embedding-based nearest neighbor retrieval from sketched gradient space for scalable influence lookup and debugging
Stepwise influence analysis in alignment pipelines (RLHF) and reward-driven RL
Instance-wise stopping criteria and regularizers informed by SDI energy curves
Conclusion
SDI is a rigorous, practical framework for stepwise data attribution in looped transformers, unlocking detailed temporal trajectories of training data influence. By scaling efficiently via TensorSketch and validating across algorithmic and language domains, SDI advances interpretability both in theory and application. It enables new workflows for mechanistic insight, compute calibration, and dataset curation in recurrent architectures central to modern latent reasoning AI.