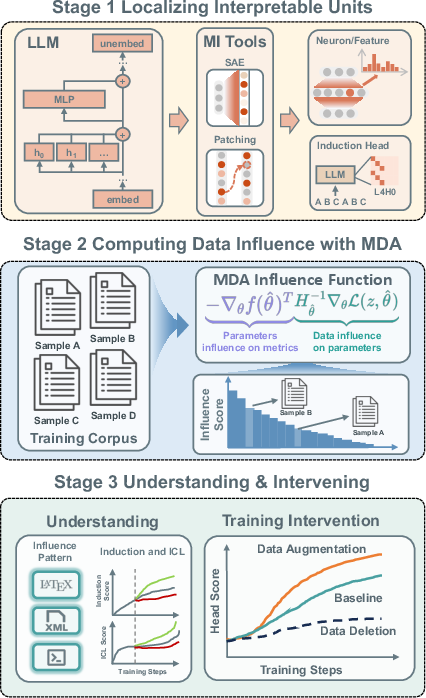
Mechanistic Data Attribution: Tracing the Training Origins of Interpretable LLM Units
Abstract: While Mechanistic Interpretability has identified interpretable circuits in LLMs, their causal origins in training data remain elusive. We introduce Mechanistic Data Attribution (MDA), a scalable framework that employs Influence Functions to trace interpretable units back to specific training samples. Through extensive experiments on the Pythia family, we causally validate that targeted intervention--removing or augmenting a small fraction of high-influence samples--significantly modulates the emergence of interpretable heads, whereas random interventions show no effect. Our analysis reveals that repetitive structural data (e.g., LaTeX, XML) acts as a mechanistic catalyst. Furthermore, we observe that interventions targeting induction head formation induce a concurrent change in the model's in-context learning (ICL) capability. This provides direct causal evidence for the long-standing hypothesis regarding the functional link between induction heads and ICL. Finally, we propose a mechanistic data augmentation pipeline that consistently accelerates circuit convergence across model scales, providing a principled methodology for steering the developmental trajectories of LLMs.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple but important question: which pieces of training data “build” specific parts inside a LLM? The authors create a method called Mechanistic Data Attribution (MDA) to trace how particular training examples cause certain internal units—like attention heads that do copy‑and‑paste style pattern matching—to form during training. They then test this by removing or repeating those key pieces of data and show they can speed up or slow down the growth of these units. Finally, they use what they learn to design data that helps models learn useful mechanisms faster.
Key Objectives
To make this easy to follow, here are the main goals in everyday terms:
- Find a way to link specific training examples to specific “units” inside an LLM (like small teams inside the model that do particular jobs).
- Check if changing those training examples (deleting or repeating them) really changes how those units grow—so we know the data is the cause, not just a coincidence.
- Discover what kinds of data most strongly build these units (for example, repetitive text patterns).
- See if boosting these units also improves a well-known skill called in-context learning (ICL), where a model can learn from patterns shown inside the prompt.
- Use these insights to design a practical, reusable data recipe that speeds up the formation of helpful mechanisms during training.
How the Researchers Did It (Methods in Simple Language)
Think of an LLM as a huge team where different groups do different jobs. Two such groups are:
- Induction heads: attention heads that spot a pattern like “A → B” earlier in the text and then, when they see “A” again, predict “B” next. This is like a copy‑and‑paste helper for patterns.
- Previous-token heads: attention heads that focus on copying the immediate last token—simpler and more local.
The authors’ method, MDA, works in two steps:
- Find the unit and measure its behavior
- They use a score (like a “pattern match score”) to locate and track the strength of a specific unit (for example, an induction head).
- They set up a probing task that checks how well that unit does its job on a small, well-chosen test set.
- Measure which training samples most affect that unit
- They use “influence functions,” a statistical tool that estimates how much changing a single training example would change a measured behavior (here, the unit’s probe score).
- Calculating this exactly for huge models is super expensive, so they use a smart shortcut called EK‑FAC (a fast math approximation) to estimate the needed quantities efficiently.
With this setup, they analyze several sizes of the Pythia family of LLMs (14M, 31M, 70M, 160M parameters). Then they do “causal validation”: they retrain the models while either removing the most influential samples (to see if unit formation slows down) or repeating them (to see if it speeds up). They compare this to random removals or repeats to make sure the effects aren’t just due to changing the amount of data.
Main Findings and Why They Matter
Here are the core results, explained plainly:
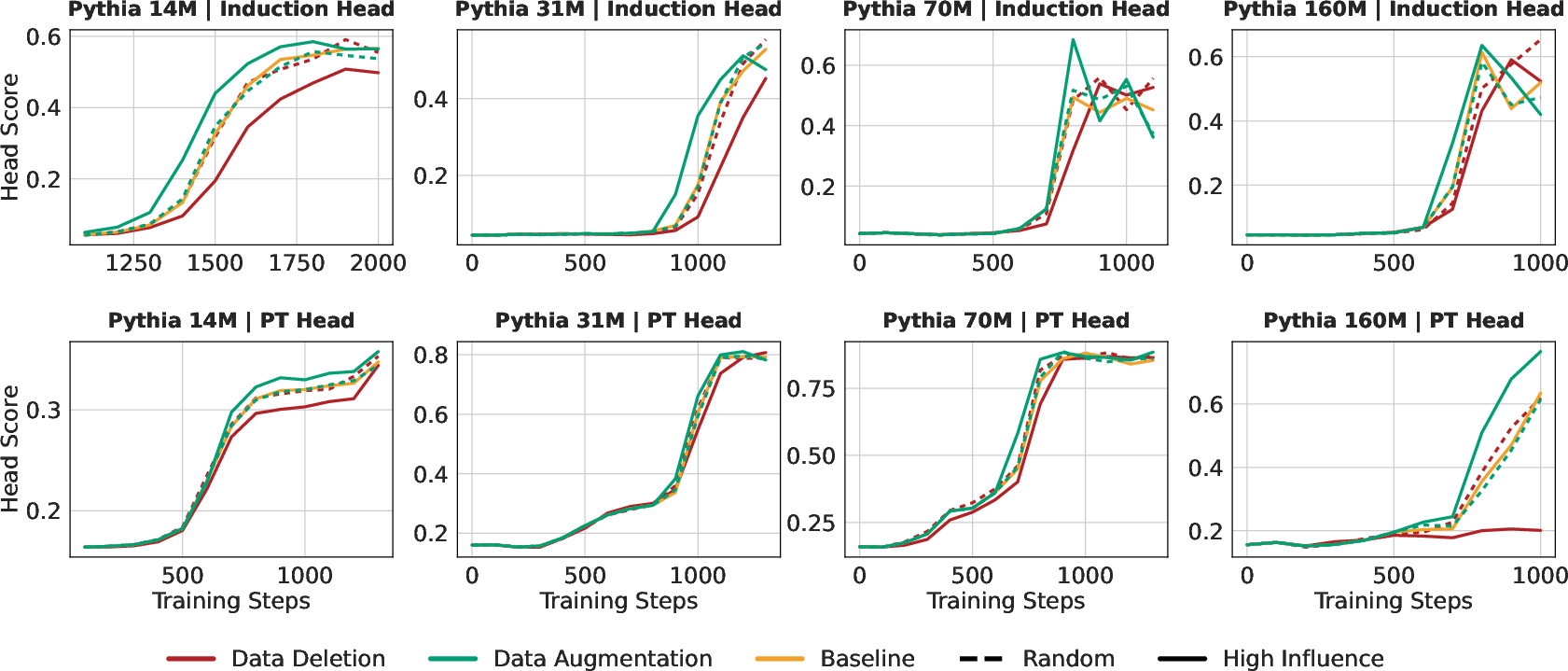
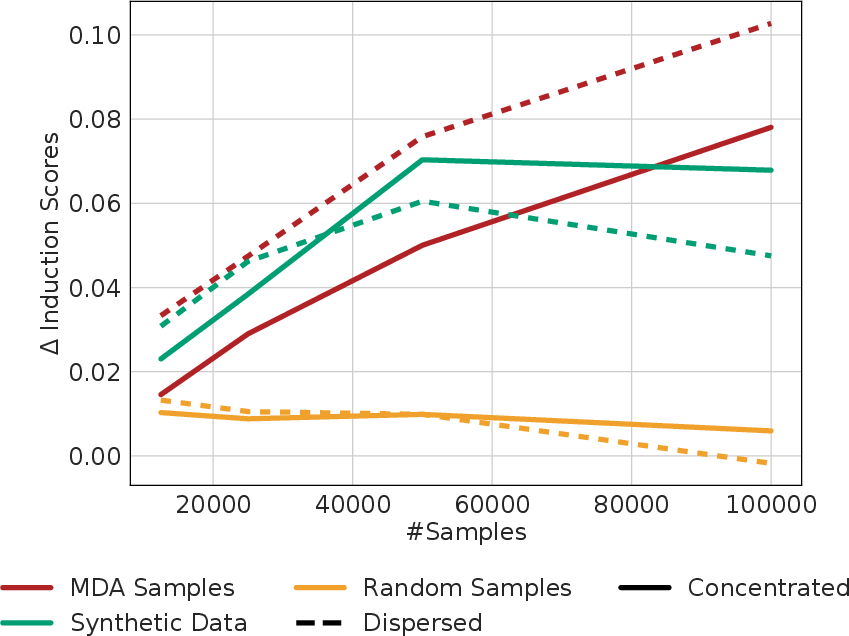
- Targeted data changes really modulate unit growth
- Deleting just a small fraction (up to 10%) of the most influential training samples slows or delays the formation of induction heads and previous-token heads.
- Repeating those same samples speeds up the formation of those heads.
- Doing the same amount of random deletion or repetition barely changes anything—so the identified samples are special.
- The strongest “builder” data looks repetitive
- High-influence samples often come from LaTeX, XML, code, or even “noisy” strings with lots of repeated patterns.
- This makes sense: induction heads are good at spotting and continuing repeated patterns.
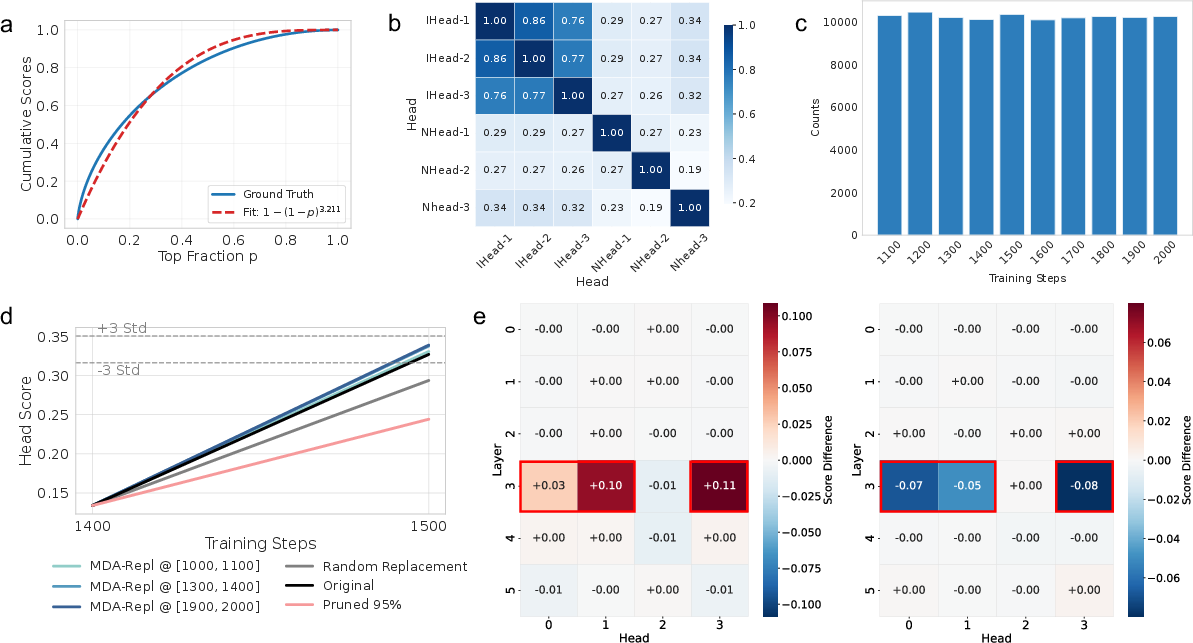
- Influence is concentrated in a few samples
- The influence scores follow a power-law: a small portion of samples account for a big chunk of total influence. In other words, some training examples matter a lot, while most matter a little.
- The influential data generalizes across similar units
- The most influential samples for one induction head also help other induction heads, but not unrelated heads. This suggests the data is building a general “induction” mechanism rather than just one specific unit.
- Mechanism growth is steady, then flips
- These influential samples are spread across the training timeline—they aren’t all clustered at the moment the mechanism appears. The model seems to gradually accumulate signal until it hits a threshold and the unit’s score “phase-transitions” upward.
- Even if you mask 95% of samples in a window, the mechanism can still grow, just more slowly—supporting the idea of steady accumulation.
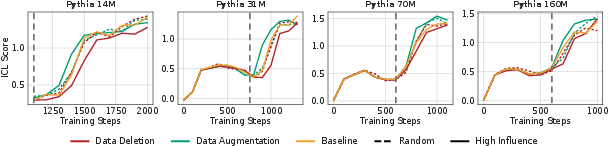
- Direct causal link to in-context learning (ICL)
- When the authors slowed induction head growth (by deleting top samples), ICL got worse.
- When they sped up induction head growth (by repeating top samples), ICL got better.
- This provides causal evidence that induction heads are a key driver of ICL, not just correlated with it.
- A practical data recipe that scales
- They build a pipeline to synthesize “mechanistic” data:
- 1) Use MDA to pick top-influence samples.
- 2) Ask a strong LLM to extract pattern templates from those samples (like JSON schemas describing the repetitive structure).
- 3) Generate lots of new synthetic data using those templates.
- Adding this synthetic data during training consistently accelerates induction head formation across different model sizes.
- Interestingly, templates learned from the smallest model (14M) work well—even better than those learned from larger models—suggesting that the structural “curriculum” is scale‑invariant and you can use small models to design data for big ones.
Implications and Potential Impact
This research shows that we can understand not just what an LLM’s internal parts do, but also which training data made them that way. That opens several useful doors:
- Better control during training
- Want a model to learn certain helpful mechanisms faster (like induction for ICL)? Add synthetic data with the right patterns at the right time.
- Want to prevent certain mechanisms (that might be risky or biased)? Remove or downweight the data that builds them.
- Efficiency and sustainability
- If a small portion of data has outsized influence, we can target those patterns to reduce training time and compute, cutting costs and carbon footprint.
- Transparency and safety
- Tracing mechanisms back to their data origins can help audit and governance efforts. It makes it easier to steer, unlearn, or fix behaviors at the source, instead of relying only on post‑hoc filtering.
Overall, MDA turns a black box into a more understandable and steerable system: it connects internal circuits to their training data causes and offers practical tools to guide how LLMs develop.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a consolidated list of concrete gaps and open questions that remain unresolved and could guide future research:
- Scalability and validity of EK-FAC-based influence functions at larger scales: quantify error bounds, runtime/memory costs, and stability for 1B–70B+ models; compare against alternative IHVP methods (LiSSA, Hutchinson, K-FAC variants).
- Generalization beyond induction and previous-token heads: apply MDA to other interpretable units (MLP neurons, SAE features, safety/knowledge/reasoning circuits) and verify causal effects with unit-specific probes.
- Cross-architecture and training regime robustness: evaluate MDA on different model families (LLaMA, GPT-NeoX, Mix-of-Experts, RWKV/Mamba), instruction-tuned, RL-fine-tuned, and multilingual models to test mechanism invariance.
- Sensitivity to emergence-window selection: systematically vary to assess whether attribution results and causal effects depend on window boundaries; test contributions from very early/late training phases.
- Probe-function dependence: assess robustness of influence rankings to alternative head metrics, probe datasets, and task-specific probes; quantify how metric choice biases “important” samples.
- Influence-function causality assumptions: test whether infinitesimal upweighting approximations hold under discrete duplication/deletion; run controlled reweighting experiments consistent with IF theory and different optimizers/schedules.
- Subspace attribution fidelity: quantify cross-subspace interactions (e.g., upstream W_Q/W_K/W_V, residual stream, MLP layers) and leakage when restricting the inverse Hessian to a head’s parameter subset; evaluate multi-head dependencies.
- Formal characterization of high-influence patterns: move beyond qualitative examples to measurable features (repetition rate, entropy, token/sequence length, nesting depth, grammar) and derive predictive thresholds/theory linking corpus statistics to circuit emergence.
- Role of negative-influence samples: identify samples that suppress mechanism formation; test whether removing them accelerates desired circuits or helps unlearning harmful ones.
- Side effects and trade-offs: measure impacts of targeted data augmentation/deletion on general capabilities (perplexity, factual recall, reasoning), safety metrics (toxicity, bias), and calibration; detect mode collapse or overfitting to structural templates.
- Baseline breadth: compare MDA-guided interventions to simpler heuristics (top-loss, gradient-norm), other data valuation methods (TracIn, Shapley), and standard data curation pipelines to ensure gains are not achievable with cheaper proxies.
- Robustness across seeds and corpora: report variance and confidence intervals for attribution rankings and intervention outcomes across random seeds, different data mixtures, and domains (code, web, scientific text).
- Synthetic data pipeline risks: quantify template diversity, coverage, and overfitting; assess long-term effects beyond the emergence window and measure domain drift introduced by synthetic structural motifs.
- Mechanistic cause of “optimization shock” and scale-dependent insertion results: analyze gradient statistics/curvature during concentrated vs dispersed insertion; provide principled guidelines for insertion schedules.
- Security and poisoning defenses: develop and evaluate training strategies that reduce single-sample leverage (e.g., robust optimization, regularization) to mitigate MDA-guided adversarial data attacks.
- Predictive accumulation models: formalize the “steady accumulation” dynamics—estimate critical thresholds for phase transitions from corpus statistics and derive scaling laws across model sizes.
- Decomposing ICL causality: isolate contributions of non-induction circuits to ICL via targeted head ablations/interventions and multi-mechanism probes; test task families where ICL relies on different internal algorithms.
- Practical compute reporting: provide detailed attribution/retraining compute budgets and memory profiles; explore online/streaming MDA during training to reduce overhead.
- Targeted unlearning demonstrations: beyond induction heads, show controlled removal of undesirable mechanisms (e.g., unsafe features) while minimizing collateral damage; develop principled data-level unlearning recipes.
- Multilingual and domain-specific structured patterns: test whether analogous high-influence motifs (JSON, YAML, HTML, code in other languages) causally drive mechanisms across languages/domains; design curricula accordingly.
- Pretraining vs fine-tuning interventions: evaluate whether MDA-guided data interventions are as effective during fine-tuning/continued pretraining; characterize differences in efficacy and side effects.
Practical Applications
Below is a structured analysis of practical, real-world applications enabled by the paper’s Mechanistic Data Attribution (MDA) framework, its causal findings on induction heads and in-context learning (ICL), and the proposed mechanistic data augmentation pipeline. Each item notes sectors, potential tools/workflows, and key assumptions or dependencies.
Immediate Applications
- Mechanistic curriculum design to accelerate ICL in small/medium LLMs
- Sectors: software/AI, education
- Tools/Workflow: run MDA on a small proxy model (e.g., Pythia-14M) during the emergence window; distill structural motifs (XML/LaTeX repetition, code patterns) with an LLM; synthesize diverse, dispersed inserts; monitor induction-head scores and ICL metrics
- Assumptions/Dependencies: access to training loop and data; valid IF/EK-FAC approximations; interpretable-unit localization (e.g., induction head metrics); careful mixing to avoid distribution shift or optimization shock
- Targeted unlearning of harmful or undesired circuits via data-level interventions
- Sectors: AI safety, governance, compliance
- Tools/Workflow: identify safety-relevant units (e.g., safety neurons, risky attention heads); compute unit-specific influence scores; delete or mask gradients of high-influence samples; validate via counterfactual retraining and behavioral audits
- Assumptions/Dependencies: reliable localization of harmful units; availability of training data lineage; retraining or continued training capacity; monitor for capability trade-offs
- Training efficiency and carbon footprint reduction by prioritizing high-leverage data
- Sectors: energy/sustainability, AI infrastructure
- Tools/Workflow: compute influence distributions; upweight/duplicate high-influence samples; dispersed insertion to avoid optimization shocks; track convergence speed and loss curves
- Assumptions/Dependencies: systemic gains persist beyond induction heads; comparable downstream performance; compute budget for influence estimation
- Data poisoning and anomaly detection focused on high-influence subsets
- Sectors: security, trust & safety
- Tools/Workflow: flag top-influence samples for provenance and semantic review; investigate repetitive or suspicious patterns; quarantine and retrain
- Assumptions/Dependencies: dataset access and traceability; IF stability under noisy or adversarial examples; human-in-the-loop verification
- Root-cause analysis and debugging of model misbehavior
- Sectors: enterprise AI operations, MLOps
- Tools/Workflow: when a misbehavior is observed, localize implicated units and compute MDA to trace causal training samples; adjust corpus and retrain; add regression tests (ICL score, head metrics)
- Assumptions/Dependencies: stored sample IDs/metadata; reproducible training pipelines; unit-level probes for affected mechanisms
- Cross-scale transfer: use small proxies to steer larger model training
- Sectors: AI development
- Tools/Workflow: compute high-influence motifs with 14M-31M models; synthesize structural curricula; apply to 70M–160M (and beyond) via dispersed augmentation; monitor cross-scale generalization
- Assumptions/Dependencies: structural motif invariance across scales; proxy-to-target domain similarity; alignment of emergence windows
- Mechanistic curriculum generator as a productized tool
- Sectors: ML tooling/software
- Tools/Workflow: “Mechanistic Curriculum Generator” that ingests high-influence samples, distills schemas (JSON), emits Python data synthesizers; integrates with PyTorch training; dashboard for unit metrics (prefix-matching, ICL score)
- Assumptions/Dependencies: LLM quality for pattern distillation; robust prompt design; schema diversity for generalization
- Compliance-ready circuit-level data lineage reporting
- Sectors: policy/legal, regulated industries
- Tools/Workflow: generate reports linking specific behaviors (e.g., induction heads, safety neurons) to training data subsets; document interventions and their impact; include in Model/Training Cards
- Assumptions/Dependencies: legal access to training data; standardized reporting formats; buy-in from auditors/regulators
- Domain-tailored synthetic sequence augmentation (e.g., logs, sensor data)
- Sectors: robotics, IoT, operations analytics
- Tools/Workflow: distill repetitive structural motifs from domain data (timestamp-key-value, status-event sequences); synthesize and insert dispersedly; evaluate in-context copying for long-range dependencies
- Assumptions/Dependencies: mapping of induction-head benefits to domain tasks; domain-specific probes; avoidance of narrow overfitting
- Targeted de-biasing via data attribution for sensitive domains
- Sectors: healthcare, finance, HR
- Tools/Workflow: localize biased units/features (e.g., via SAEs or attention head probes); run MDA to identify biased-signal catalysts; delete/replace and retrain; validate via fairness metrics
- Assumptions/Dependencies: reliable bias localization; risk of accuracy trade-offs; comprehensive evaluation across subpopulations
Long-Term Applications
- Scaling MDA to frontier models and full corpora
- Sectors: frontier AI labs, cloud providers
- Tools/Workflow: distributed EK-FAC/Hessian approximations; layer-wise IHVP caching; subspace projections for many unit types (heads, neurons, SAE features)
- Assumptions/Dependencies: extreme compute and memory; robust approximations; access to training data and checkpoints
- Mechanism-general curricula beyond induction heads (reasoning, safety, factual recall)
- Sectors: software/AI, education, safety
- Tools/Workflow: localize additional circuits (logical reasoning, knowledge neurons); distill their data catalysts; synthesize diverse structural motifs (tables, proofs, schemas) and insert with curriculum schedules
- Assumptions/Dependencies: validated unit-specific probes/metrics; clear causal drivers; avoidance of overfitting to templates
- End-to-end Mechanistic DataOps pipelines
- Sectors: MLOps/platforms
- Tools/Workflow: continuous MDA scoring on streaming data lakes; automated curation (upweight/downweight/delete); CI/CD gates using unit-level metrics and ICL scores; incident response for harmful circuit emergence
- Assumptions/Dependencies: scalable data lineage; orchestration and governance; monitoring for unintended side effects
- Regulatory frameworks for circuit-level attribution and audits
- Sectors: policy, regulators, standards bodies
- Tools/Workflow: “Circuit Attribution Cards” standardizing data-mechanism documentation; audit procedures for harmful mechanism tracing and unlearning attestations
- Assumptions/Dependencies: consensus on definitions and probes; feasibility for closed-source models; incentives/mandates for adoption
- Robust poisoning-resilience via influence-aware training
- Sectors: security, AI safety
- Tools/Workflow: influence-based anomaly detectors; replay-protected emergence windows; adversarial-curriculum stress testing; automatic quarantining and retraining
- Assumptions/Dependencies: reliable detection thresholds; integration with red-teaming; cost-effective mitigation
- Token budget optimization for energy savings via mechanistic gain models
- Sectors: energy/sustainability, AI infra
- Tools/Workflow: predictive models of “mechanistic gain per token”; dynamic sampling to maximize emergence speed and minimize tokens; cross-model transfer of curricula
- Assumptions/Dependencies: robust forecasting; preserved downstream quality; operational constraints on data shuffling
- Personal and small-enterprise model shaping with transparent mechanism control
- Sectors: daily life, SMB software
- Tools/Workflow: lightweight training/fine-tuning kits; curated structural data packs to strengthen long-context copying or domain-specific patterns; dashboards for mechanism monitoring
- Assumptions/Dependencies: privacy-safe data handling; accessible compute; simplified tooling
- Cross-modality extensions of MDA (vision, audio, multimodal transformers)
- Sectors: robotics, autonomous systems, media AI
- Tools/Workflow: adapt IF and subspace projections to modality-specific components (vision heads, audio features); distill structural motifs (repetitive textures, rhythmic sequences) and synthesize curricula
- Assumptions/Dependencies: modality-specific probes and metrics; scalable curvature approximations for non-text models
- Mechanistic motif marketplaces and shared curricula libraries
- Sectors: ML tooling ecosystems, open-source
- Tools/Workflow: standardized schemas for structural patterns; versioned synthetic generators; community benchmarks for circuit emergence and transfer
- Assumptions/Dependencies: licensing/IP; curation quality; generalization across models and domains
- Safety alignment synergies with RLHF via mechanism-aware data shaping
- Sectors: AI safety, product LLMs
- Tools/Workflow: combine MDA-guided corpora with RLHF; suppress risky circuits and amplify helpful ones (e.g., robust induction for instruction-following); continuous post-deployment audits
- Assumptions/Dependencies: stable interaction effects; reliable safety unit localization; guardrails against capability loss
Notes on Key Cross-Cutting Assumptions and Risks
- Validity of influence function approximations (EK-FAC) at scale and for diverse unit types.
- Access to training data, emergence windows, and the ability to retrain or continue training; many production models are closed-source or data-restricted.
- Mechanistic localization quality (induction head metrics, SAE features) determines attribution accuracy.
- Risk of overfitting to structural templates; requires diversified synthesis and dispersed insertion.
- Potential capability trade-offs when removing high-influence data; rigorous evals needed (ICL scores, downstream tasks).
- Ethical considerations: attribution tools can help defend against poisoning but might be repurposed for targeted manipulation; governance and audit are essential.
Glossary
- Attention Head: A component in transformer models that computes attention weights and contributes to token-to-token interactions. "information flows via residual streams mediated by attention heads and MLP layers"
- Causal Validation: The process of empirically verifying causal relationships via targeted interventions. "Causal validation of Mechanistic Data Attribution."
- Counterfactual Retraining: Retraining under modified data conditions to assess necessity or sufficiency of specific samples. "we perform bidirectional experiments via counterfactual retraining"
- Data Ablation: Removing or masking parts of the training data to test their impact on model behavior. "data ablation and augmentation experiments during pre-training."
- Data Augmentation: Duplicating or synthesizing training samples to strengthen signals relevant to a mechanism. "Data Augmentation triggers an accelerated phase transition comparing to random insertion baselines"
- EK-FAC (Eigenvalue-corrected Kronecker-Factored Approximate Curvature): A scalable curvature approximation that enables efficient inverse-Hessian computations layer-wise. "Eigenvalue-corrected Kronecker-Factored Approximate Curvature (EK-FAC)"
- Hessian: The matrix of second derivatives of a loss function with respect to model parameters. "where is the Hessian of the loss."
- IHVP (Inverse-Hessian-Vector Product): The product of the inverse Hessian and a vector, used in influence estimation. "enabling efficient estimation of the Inverse-Hessian-Vector Product (IHVP) essential for attribution."
- In-context Learning (ICL): A model’s ability to learn and apply patterns from the provided context without parameter updates. "in-context learning~(ICL) capability."
- Induction Head: An attention head that copies patterns by attending to earlier occurrences of a token pair to predict the continuation. "``induction heads" responsible for in-context copying and pattern completion"
- Influence Functions: A statistical tool estimating how upweighting a training sample affects a test loss. "Influence Functions (IF) provide a classic statistical tool to estimate the effect of upweighting a training sample"
- Kronecker Product: A matrix operation used in EK-FAC to factor curvature into layer-wise components. "using Kronecker products of covariance matrices"
- Mechanistic Data Attribution (MDA): A framework attributing the behavior of interpretable units to specific training samples. "We introduce Mechanistic Data Attribution (MDA), a scalable framework that employs Influence Functions to trace interpretable units back to specific training samples."
- Mechanistic Interpretability (MI): The study of reverse-engineering neural networks into understandable functional circuits. "Mechanistic Interpretability (MI), a field dedicated to reverse-engineering these neural networks into human-understandable algorithms"
- Monosemantic Features: Latent features that correspond to a single interpretable concept. "monosemantic features disentangled via Sparse Autoencoders (SAEs)"
- Phase Transition: A sharp change in a model mechanism’s strength or emergence during training. "Data Augmentation triggers an accelerated phase transition comparing to random insertion baselines"
- Power-Law Distribution: A heavy-tailed distribution where a small fraction of samples contribute disproportionately to total influence. "Power-law distribution: The distribution of influence scores follows a power-law"
- Prefix-Matching Score: A metric used to identify induction heads by measuring attention to matching token prefixes. "the prefix-matching score for induction heads~\citep{olsson2022context}"
- Previous Token Heads: Attention heads that primarily attend to the immediately preceding token. "Previous Token Heads~\citep{olsson2022context}"
- Probing Function: A function designed to quantitatively evaluate a unit’s specific behavior or capability. "we then design a probing function "
- Procedural Synthesis: Programmatic generation of training data based on distilled structural patterns. "scale them up via procedural synthesis."
- Residual Stream: The pathway in transformer architectures through which layer outputs are aggregated and passed forward. "information flows via residual streams mediated by attention heads and MLP layers"
- Subspace Projection: Restricting analysis to a subset of parameters corresponding to a specific unit. "with the subspace projection "
- Training Data Attribution (TDA): Methods that attribute model behavior to training samples at a global level. "Unlike traditional Training Data Attribution (TDA) methods that typically focus on global model behavior"
- Upweighting: Increasing a training sample’s relative contribution to the objective to analyze its effect. "estimate the effect of upweighting a training sample "
Collections
Sign up for free to add this paper to one or more collections.