Step 3.5 Flash: Open Frontier-Level Intelligence with 11B Active Parameters
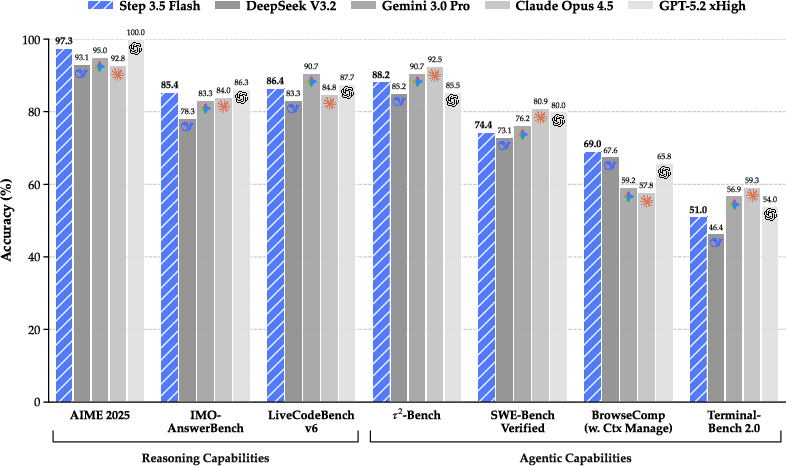
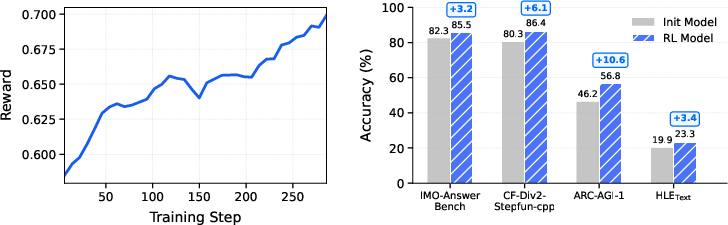
Abstract: We introduce Step 3.5 Flash, a sparse Mixture-of-Experts (MoE) model that bridges frontier-level agentic intelligence and computational efficiency. We focus on what matters most when building agents: sharp reasoning and fast, reliable execution. Step 3.5 Flash pairs a 196B-parameter foundation with 11B active parameters for efficient inference. It is optimized with interleaved 3:1 sliding-window/full attention and Multi-Token Prediction (MTP-3) to reduce the latency and cost of multi-round agentic interactions. To reach frontier-level intelligence, we design a scalable reinforcement learning framework that combines verifiable signals with preference feedback, while remaining stable under large-scale off-policy training, enabling consistent self-improvement across mathematics, code, and tool use. Step 3.5 Flash demonstrates strong performance across agent, coding, and math tasks, achieving 85.4% on IMO-AnswerBench, 86.4% on LiveCodeBench-v6 (2024.08-2025.05), 88.2% on tau2-Bench, 69.0% on BrowseComp (with context management), and 51.0% on Terminal-Bench 2.0, comparable to frontier models such as GPT-5.2 xHigh and Gemini 3.0 Pro. By redefining the efficiency frontier, Step 3.5 Flash provides a high-density foundation for deploying sophisticated agents in real-world industrial environments.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper introduces Step 3.5 Flash, an open-source AI LLM designed to be both very smart and very fast. It aims to reach “frontier-level” intelligence (the kind you see in top commercial models) while keeping the cost and waiting time low, especially for long, multi-step tasks like coding with tools, solving math problems, or browsing the web to answer questions.
Think of it like building a top student who’s not only great at thinking through hard problems but also answers quickly and doesn’t waste time.
Key Questions: What were the researchers trying to do?
The team focused on three big goals:
- Can we make a model that reasons well (math, code, planning) but still responds fast?
- Can we keep the model efficient during long tasks that involve many steps and big documents?
- Can we train the model to improve itself in a stable way, even when it uses a special “team of experts” design?
Methods: How did they build and train it?
The model’s design uses simple but powerful ideas. Here are the main tricks, described in everyday language:
- Mixture-of-Experts (MoE): Imagine a team of 289 specialists (288 routed experts + 1 shared expert). For each word the model reads or writes, it only calls on 8 of them—the ones most relevant. This gives the model huge total knowledge (196 billion “parameters,” which are like settings or brain cells) but keeps only about 11 billion active at a time, so it stays fast.
- Hybrid Attention (Sliding Window + Full Attention, in a 3:1 ratio): Attention is how the model decides what to focus on in the text.
- Sliding-Window Attention is like carefully reading the last few paragraphs (window size 512 tokens) to keep things speedy.
- Full Attention is like occasionally stepping back to look at the whole document to avoid missing important context.
- By using three “local” layers for speed and one “global” layer for thoroughness, the model stays quick without getting lost.
- Head-wise Gated Attention: Each “attention head” is like a small spotlight. Gating lets each spotlight decide how much to shine (or dim) depending on the input. This prevents the model from over-focusing on unhelpful parts and helps keep quality high with little extra cost.
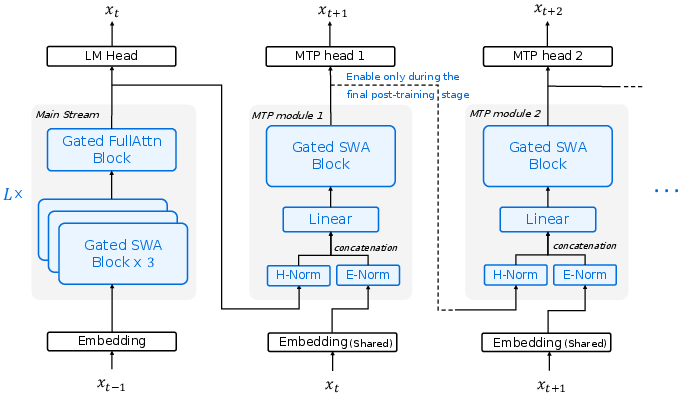
- Multi-Token Prediction (MTP-3): Instead of thinking one word at a time, the model predicts several words ahead (like thinking in short phrases). This speeds up typing without sacrificing accuracy.
- Hardware-friendly design: The attention is set up to match common 8-GPU servers, making memory and speed more efficient. In simple terms, the model’s parts are arranged to fit the computer’s “shape,” so it runs faster.
- Training Stability Tools: Training giant models can blow up (numerical errors, a few experts taking over, or “dead experts” not learning).
- They built a lightweight monitoring system to watch millions of signals during training without slowing it down.
- They fixed numerical issues in the optimizer (Muon) and used activation “clipping” (capping extreme values) to stop explosions.
- They balanced the workload across GPUs so no single GPU slows everyone down.
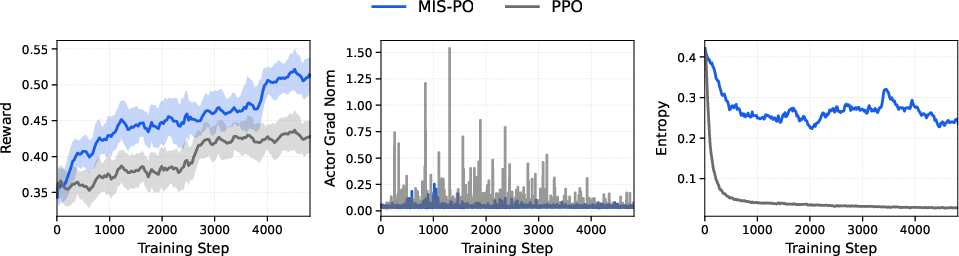
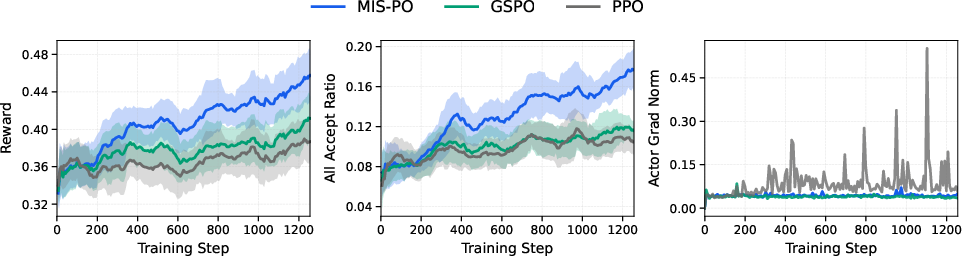
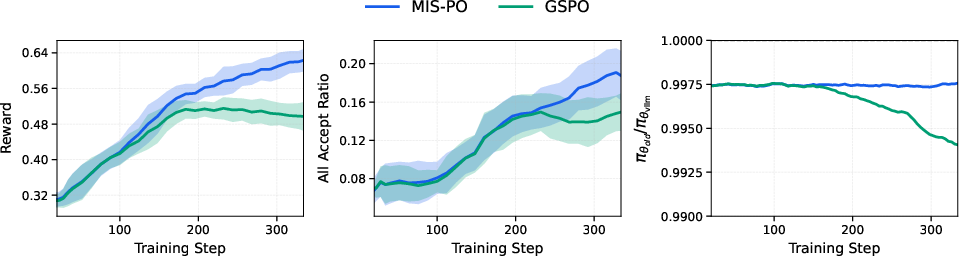
- Scalable Reinforcement Learning (RL) with MIS-PO: RL means the model practices and gets feedback. MIS-PO filters out unstable or too-different examples so learning stays steady. It’s like a coach choosing practice problems that are challenging but not wildly off-topic, so the player improves without getting confused.
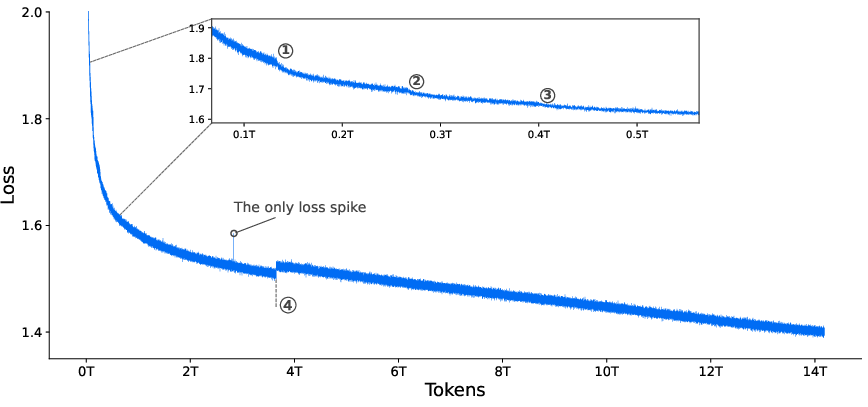
- Training Curriculum: The model was trained in stages:
- Pre-training: General knowledge, then more code and software data, and longer contexts (from 4k tokens to 32k).
- Mid-training: Even longer contexts (up to 128k tokens), plus tasks that strengthen tool use and long reasoning.
- Post-training: Build “expert” models for specific skills (math, code, tools), then distill them back into one strong generalist and finish with scalable RL.
Main Findings: What did they achieve?
The model reaches high scores on tough tests while staying efficient:
- Math and reasoning: 85.4% on IMO-AnswerBench (an advanced math problem set) and 88.2% on τ²-Bench (long reasoning tasks).
- Coding: 86.4% on LiveCodeBench-v6 (2024.08–2025.05), which checks real-world coding ability.
- Tool-using agents: 69.0% on BrowseComp (web browsing tasks with context management) and 51.0% on Terminal-Bench 2.0 (command-line tasks).
These results are comparable to frontier models like GPT-5.2 xHigh and Gemini 3.0 Pro—even though only 11B parameters are active at any moment. The model also runs fast: about 170 tokens per second on common high-end GPUs, which helps for chat-like, multi-turn work.
In short, the model is both smart and snappy.
Why It Matters: What’s the impact?
- Faster, cheaper AI: Because the model uses only a portion of its “brain” at a time, it’s more affordable to run while still being very capable. This makes advanced AI more practical for companies and developers.
- Better long tasks: The design helps with long documents and multi-step tasks (like coding with tools, browsing for answers, or debugging software), which are common in real-world work.
- Open-source progress: It narrows the gap between open models and top commercial ones, encouraging innovation everyone can build on.
- Stable training roadmap: The paper shows how to keep massive models safe and steady during training, which helps other teams avoid common pitfalls.
Overall, Step 3.5 Flash shows that you don’t need to choose between “smart” and “fast.” With the right architecture and training, you can get both—making AI agents more useful in everyday, real-world tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions the paper leaves unresolved. Each point is framed to be directly actionable for future researchers.
- Reproducibility of reported performance: Precise inference settings, test-time compute budgets, prompt variants, and context-management strategies (e.g., BrowseComp “with context management,” PaCoRe deep-think) are not fully specified, hindering fair replication and comparison against baselines.
- Benchmark comparability: No standardized evaluation protocol ensuring equal tool access, API latency, or environment versions across models (especially vs. closed-source baselines), making “frontier-level” claims hard to validate.
- Data contamination risks: The paper does not detail contamination audits for pretraining/SFT corpora against evaluation sets (e.g., MMLU, GPQA, SimpleQA, LiveCodeBench, IMO-AnswerBench), nor provide contamination rates or mitigation procedures.
- Dataset governance and licensing: The legal status, licensing compliance, and provenance of StepCrawl and PR/Issue/Commit datasets (especially relaxed filter policies) are not documented.
- Safety and alignment: No quantitative safety evaluation (e.g., toxicity, jailbreak, tool-abuse, data exfiltration) or alignment protocol is provided for agentic behaviors in real deployments.
- Tool reliability and robustness: The paper does not analyze failure modes in tool-use (search, terminal, code execution), error recovery strategies, or agent reliability under tool/API outages and noisy environments.
- MIS-PO RL details and theory: The proposed Metropolis Independence Sampling-Filtered Policy Optimization lacks algorithmic specifics (acceptance criteria, trust-region definition, filtering thresholds), theoretical guarantees (bias/variance analysis), and ablations versus PPO/GRPO in long-horizon off-policy regimes.
- RL reward design: Sources and quality of verifiable signals and human preference feedback are not described (annotation protocols, inter-rater reliability, domain coverage, and bias audits).
- RL scalability to MoE: Quantitative evidence of MIS-PO stability for MoE routing (gradient variance, off-policy divergence, expert drift) is missing, as are analyses across context lengths and domains.
- Expert-to-generalist distillation: The self-distillation process lacks detail on sampling distributions, rejection filters, diversity preservation, and trade-offs (e.g., loss of niche expert competencies) when consolidating multiple expert models.
- Activation clipping specifics: Threshold selection, schedules, per-layer application, and side-effects on expressivity and generalization are not provided; alternative mitigations (e.g., adaptive clipping, spectral norm constraints, SwiGLU variants) remain unexplored.
- Expert collapse monitoring and mitigation: While metrics are proposed (max-to-median ratios), there is no automated intervention pipeline (e.g., early warnings → router retuning → targeted regularization) or evidence that these measures prevent collapse during RL or SFT.
- EP-group balancing loss: The proposed rank-level loss formulation (using p_g, f_g) lacks justification, sensitivity analyses (coefficients, schedules), and empirical throughput gains (tail-latency reduction, straggler mitigation) in deployment.
- Sparse MoE routing hyperparameters: No ablations on top-k routing (k=8), number of experts (288), shared expert contribution scaling, or router temperature/bias schedules at the 196B total-parameter scale.
- Hybrid attention design space: The paper fixes SWA window W=512 and GQA-8 but does not explore dynamic windowing, larger/variable W, alternate interleave patterns (beyond S1F1/S3F1), or layout adaptation across layers and tasks.
- Head-wise gated attention generalization: Gating vs. sink tokens is only studied in a 100B model pretraining slice; effects across 128k contexts, different domains, and under RL/post-training are not reported.
- RoPE selective scaling: The selective scaling choices (θ_full vs. θ_SWA) are not justified with empirical long-context drift/aliasing analyses or alternatives (e.g., NTK-aware scaling across attention types).
- MTP integration and gains: End-to-end speedups (acceptance rates, speculative depth, wall-clock reductions) from MTP-3 and speculative decoding are not quantified across context lengths and hardware; training only MTP-1 then cloning MTP-2/3 is untested against training all heads jointly.
- Speculative decoding mechanics: The paper asserts SWA compatibility but does not detail draft-tree generation/verification strategies, batching policies, or failure modes (e.g., verification bottlenecks, cache thrashing) in long contexts.
- Latency and throughput profiling: Reported ~170 tokens/s on Hopper GPUs lacks breakdowns by context size, batch size, MTP-enabled vs. disabled, agent loop overheads, and EP straggler impacts; no wall-clock task-level speed studies for real agents.
- Kernel fusion validation: Fusing QK normalization with RoPE and grouped GEMM for MoE is not accompanied by numerical accuracy checks, gradient fidelity tests, or cross-vendor portability analyses.
- Fine-grained checkpointing trade-offs: Memory savings vs. recompute overheads are not measured across submodule toggles; guidance on optimal policies for different deployment constraints is missing.
- Muon optimizer precision handling: Casting Polar Express iteration to FP16 (vs. BF16) is presented without robustness analyses across hardware/software stacks, nor comparisons to alternative orthogonalization schemes or damping strategies.
- Mid-training router freezing: Freezing routers during mid-training is not justified; alternative strategies (partial/unfreezing schedules, bias annealing, curriculum-aware routing) and their effects on specialization and stability remain unexplored.
- Generalization under scale: Key ablations (attention layouts, gating, EP balancing) are reported at 30B/100B but not at the full 196B MoE configuration; scale-dependent behaviors and regressions could be unaccounted for.
- Failure analysis on agentic benchmarks: No qualitative or quantitative breakdown of errors (e.g., Terminal-Bench 2.0 at 51%) to guide targeted improvements in tools, planning, or environment handling.
- Compute and energy transparency: Training cost (GPU-hours, energy use) and efficiency metrics (tokens/$, tokens/kWh) are not reported, limiting cost-aware comparisons and sustainability assessments.
- Portability across hardware topologies: Design choices tuned for 8-GPU nodes (GQA-8, KV-cache sharding) may not generalize; there is no guidance for 4/16-GPU nodes or consumer hardware configurations.
- Deployment robustness: The paper lacks stress tests for dynamic workloads (variable tool latencies, network jitter), memory pressure (KV-cache growth), and resilience strategies (backpressure, adaptive batching) in production agent systems.
Practical Applications
Immediate Applications The following applications can be deployed now using the Step 3.5 Flash model and its supporting infrastructure, either via the released checkpoints (GitHub/HuggingFace) or cloud API (e.g., OpenRouter). Each item includes sector mapping, potential tools/products/workflows, and feasibility notes. - Autonomous code repair and CI/CD assistants - Description: End-to-end software engineering agents that read issues, localize faults, propose patches, generate tests, and open PRs—leveraging the curated PR/Issue/Commit dataset and strong performance on LiveCodeBench and Terminal-Bench. - Sectors: Software, DevOps - Tools/products/workflows: GitHub App that runs in CI; “Issue→Patch→PR” pipeline; VSCode/JetBrains plugin for inline refactoring and test generation; secure build/test sandbox. - Assumptions/dependencies: Access to repos and tests; guardrails for credential/secrets handling; deterministic build environments; policy for auto-merge/human review. - Low-latency developer copilots with long-context awareness - Description: IDE copilots that can ingest up to ~128k tokens (project-wide files, architecture docs, logs) and respond with minimal latency due to the 3:1 SWA/Full attention design and MTP-3 speculative decoding. - Sectors: Software, Data Engineering - Tools/products/workflows: “Flash Copilot” plugin; project-wide code navigation and reasoning; cross-file refactoring; log triage; deep-think mode (PaCoRe) for complex changes. - Assumptions/dependencies: GPU-backed inference or efficient quantization; memory budgets (~128 GB for full capacity); standard tool adapters (linters, formatters, test runners). - Web research assistants for literature synthesis and citation management - Description: Browsing agents that manage multi-tab contexts, collect sources, and produce structured, cited memos—aligned with BrowseComp and τ²-Bench results. - Sectors: Academia, Journalism, Intelligence & Policy Analysis - Tools/products/workflows: Browser extension or research desk app; “topic→plan→collect→synthesize” workflow; export to markdown/LaTeX; citation QA. - Assumptions/dependencies: Trusted browsing environment; access to publisher APIs; content licensing; prompt templates for reproducible citation behavior. - Terminal-savvy ops agents for routine automation - Description: CLI-capable agents for routine DevOps tasks (log parsing, backup checks, service restarts) with dry-run/approval flows, reflecting strong Terminal-Bench performance. - Sectors: Cloud/IT Operations, Cybersecurity - Tools/products/workflows: “OpsAgent” that runs playbooks; preflight verification; RBAC integration; change tickets with audit trails. - Assumptions/dependencies: Strict privilege separation; sandboxed execution; audit logging; policy constraints (e.g., no production writes without human approval). - Enterprise knowledge-base assistants with long-document comprehension - Description: Assistants that ingest legal, policy, compliance, or product manuals (PDF/ePub) and answer queries reliably across large contexts. - Sectors: Enterprise Support, Legal/Compliance, Public Sector - Tools/products/workflows: “Policy QA” bot; RAG over internal repositories; answer-attribution and uncertainty flags; escalation to human SMEs. - Assumptions/dependencies: Secure retrieval connectors; document deduplication/sanitization; controlled vocabularies; governance for sensitive content. - Education and tutoring in math, programming, and STEM reasoning - Description: Step-by-step explanations, curriculum-aligned problem solving, and code tutoring—supported by strong math/code benchmarks and test-time scaling via PaCoRe for difficult problems. - Sectors: Education, EdTech - Tools/products/workflows: “Flash Tutor” for math and CS; scaffolding prompts; skill-level adaptation; homework integrity settings; classroom dashboards. - Assumptions/dependencies: Age-appropriate content filters; teacher oversight; local curricular mapping; safety alignment for classroom deployment. - Model-serving efficiency upgrades for AI platform teams - Description: Drop-in inference optimizations—hybrid attention (S3F1), increased SWA heads, GQA-8, and MTP-3—to reduce latency and cost on 8-GPU nodes. - Sectors: AI Infrastructure, Cloud - Tools/products/workflows: “FlashServing” profiles; KV-cache sharding aligned to 8-way tensor parallel; speculative decoding trees; throughput dashboards. - Assumptions/dependencies: Hopper-class GPUs or comparable; careful kernel and cache tuning; verification of latency gains in real workloads. - High-throughput, lightweight training telemetry for large-scale ML - Description: Asynchronous metrics server and micro-batch logging to monitor expert routing, gradient norms, and activation stability with negligible training overhead. - Sectors: AI/ML R&D, MLOps - Tools/products/workflows: Metrics server deployment; per-expert norm dashboards; off-path reduction/persistence; alerting for “dead experts” and activation blow-ups. - Assumptions/dependencies: Reliable RPC/IPC channels; scalable storage; integration with training frameworks (PyTorch/Megatron). - Stability best-practices for large MoE training - Description: Actionable mitigations—Polar Express precision adjustment for Muon, activation clipping in deeper MoE layers, EP-group balanced routing—to prevent collapse/instability. - Sectors: AI/ML R&D - Tools/products/workflows: “MoE Stability Kit” recipes; per-layer max-to-median activation ratios; router loss-free balancing; staged context scaling (4k→32k→128k). - Assumptions/dependencies: Access to training code; tuning for the specific optimizer/model; periodic replay to manage distribution shifts. - Data curation pipelines for agentic workloads - Description: StepCrawl-like harvesting and sanitized corpora; modified OpenCoder for code; PR/Issue/Commit curation for real SWE workflows; tool-use synthetic tasks. - Sectors: Data Engineering, AI Content Ops - Tools/products/workflows: Crawl+filter+tag+dedup pipeline; repository selection; program repair templates; long-context sample generation. - Assumptions/dependencies: Legal review and licensing; robust quality filters; benchmark deduplication; ongoing corpus maintenance. ## Long-Term Applications These applications require further research, development, safety validation, or scaling before routine deployment. They build on the paper’s methods (MoE design, hybrid attention, MTP, scalable RL with verifiable signals) and infrastructure innovations. - Safe, scalable RL frameworks for high-stakes agentic systems (MIS-PO) - Description: Adoption of Metropolis Independence Sampling–Filtered Policy Optimization to limit off-policy variance in long-horizon reasoning, yielding safer and more stable training signals for complex agents. - Sectors: Finance, Healthcare, Autonomous Systems, Public Sector - Tools/products/workflows: “SafeRL for Agents” SDK; verifiable reward signals; trust-region filtering; preference feedback pipelines. - Assumptions/dependencies: Robust reward definitions; domain-specific verification; extensive red-teaming; regulatory approval for critical domains. - Autonomous SWE teams (continuous maintenance and modernization) - Description: Persistent agents that manage backlogs, refactor legacy codebases, update dependencies, and maintain documentation—operating like virtual teams. - Sectors: Software, Enterprise IT - Tools/products/workflows: Roadmap planning agents; large-scale dependency upgrade orchestration; refactor campaigns; compliance-aware code changes. - Assumptions/dependencies: High reliability thresholds; change-management policies; legal/IP constraints; human oversight loops. - Edge or single-GPU deployments of frontier-level agentic models - Description: Distillation/quantization/pathwise compression to run 11B-active MoE variants on constrained hardware (workstations or embedded edge servers). - Sectors: Robotics, Industrial IoT, Field Services - Tools/products/workflows: “Flash-Edge” model variants; on-device tool-use; offline long-context processing; intermittent cloud sync. - Assumptions/dependencies: Advanced compression research for MoE; memory footprint reduction; real-time constraints; safety for physical-world actions. - Scientific discovery and knowledge synthesis at scale - Description: Agents that ingest massive literatures, reconcile conflicting claims, and propose hypotheses—using long-context specialization and deep-think inference. - Sectors: Pharma, Materials Science, Climate Science, Academia - Tools/products/workflows: “Auto-Review” and “Hypothesis Builder”; multi-database RAG; reproducible evidence chains; lab automation integration. - Assumptions/dependencies: Data licensing; structured experiment ontologies; rigorous validation and reproducibility checks; human-in-the-loop review. - Regulatory compliance and policy analysis assistants - Description: Assistants that read and harmonize thousands of pages of regulations, monitor changes, and generate compliance checklists and impact summaries. - Sectors: Finance, Healthcare, Energy, Public Sector - Tools/products/workflows: “RegOps Agent”; monitoring of regulatory feeds; delta analysis across versions; audit-ready reports with citations. - Assumptions/dependencies: Domain tuning; legal review; secure data handling; traceable and auditable reasoning. - Green AI infrastructure via straggler-resistant MoE routing - Description: EP-group balanced routing and communication-aware scheduling to reduce stragglers, improve cluster utilization, and lower energy per token. - Sectors: Cloud/AI Infrastructure, Energy - Tools/products/workflows: Cluster schedulers that incorporate EP-aware balancing; switch-aware rank placement; fabric-aware DP phasing. - Assumptions/dependencies: Integration with vendor toolchains; telemetry access; multi-tenant cluster policy alignment; measurement frameworks for energy impact. - Robotics and embedded systems control via terminal-like planning - Description: Agents that plan and execute shell-like commands on embedded devices (configuration, diagnostics, firmware updates) with human approvals. - Sectors: Robotics, Manufacturing, Transportation - Tools/products/workflows: “DeviceOps Agent”; safety interlocks; state estimation from logs; rollback plans; hardware-in-the-loop testing. - Assumptions/dependencies: Real-time constraints; robust fail-safes; standards compliance; extensive simulation and on-device validation. - Automated financial reporting, audit, and risk analysis over long documents - Description: Ingesting filings, prospectuses, and contracts to produce risk assessments and compliance summaries with traceable evidence. - Sectors: Finance, Audit & Assurance - Tools/products/workflows: “RiskLens Agent”; structured extraction; cross-document reconciliation; uncertainty calibration; audit trails. - Assumptions/dependencies: Domain RL with verifiable signals; strict privacy/security; legal and regulatory acceptance; human oversight. - Healthcare guideline assimilation and clinical decision support - Description: Long-context assimilation of clinical guidelines and patient records to provide decision support with transparent citations and uncertainty handling. - Sectors: Healthcare, MedTech - Tools/products/workflows: “Clinical Context Assistant”; EMR integration; guideline change monitoring; consent and privacy controls. - Assumptions/dependencies: Regulatory compliance (HIPAA/GDPR); clinical validation trials; domain fine-tuning; safety/alignment frameworks. - Standardized agent orchestration SDKs (specialize→distill→scale) - Description: Turning the paper’s unified post-training recipe into reusable SDKs to build domain experts, distill them into a generalist, and scale safely with RL. - Sectors: AI Platform, Enterprise AI - Tools/products/workflows: “Agent Foundry” SDK; specialization tracks (Math, Code, STEM, Tool-use, Long Context); distillation pipelines; preference learning interfaces. - Assumptions/dependencies: Stable data ops; compute budgets; policy for human evaluation and feedback; interoperability with enterprise tools. - Mainstream framework enhancements (Megatron/PyTorch) - Description: Incorporating decoupled parallelism, Muon ZeRO-1 resharding, fused kernels, and selective checkpointing into widely used frameworks. - Sectors: AI/ML R&D, Open-Source Software - Tools/products/workflows: PRs to upstream projects; reproducible benchmarks; migration guides; backward-compatibility layers. - Assumptions/dependencies: Community review and maintenance; hardware diversity testing; documentation and training materials. These immediate and long-term applications collectively leverage the paper’s innovations—sparse MoE architecture with 11B active parameters, hybrid attention for long contexts, MTP-3 for low-latency decoding, scalable RL with verifiable signals, and robust training/serving infrastructure—to enable practical agentic systems across software, research, policy, and everyday workflows.
Glossary
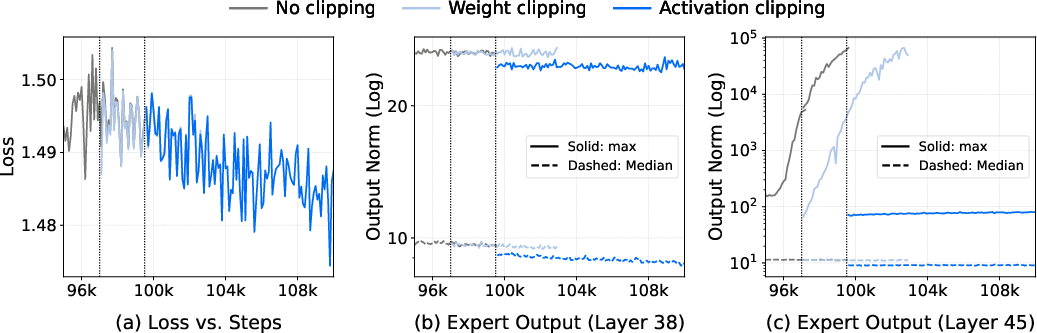
- Activation blow-up: A training instability where certain experts' activation norms grow excessively, risking numerical overflow. "localized activation blow-ups confined to a small subset of experts."
- Activation clipping: A stability technique that bounds activations by clipping values to a threshold to prevent explosions. "Activation clipping inside experts: We apply element-wise clipping directly to the MoE FFN intermediate activations prior to the output projection, as in \cite{openai2025gptoss120bgptoss20bmodel}."
- Agentic: Pertaining to models or systems that act autonomously, planning and executing multi-step tasks. "Agentic workloads typically exhibit a distinct profile: extensive context prefilling followed by prolonged, multi-turn interactive decoding."
- Annealing (data mixture): Gradually adjusting the training data distribution toward desired domains or quality. "We anneal the data mixture toward code and PR/Issue/Commit-centric sources, while increasing the share of higher-quality knowledge and reasoning-dense samples."
- Autoregressive latency: The time cost incurred when generating tokens sequentially in autoregressive models. "To further reduce autoregressive latency, we incorporate Multi-Token Prediction (MTP)..."
- Decoupled parallelization: Using separate parallel strategies and groups for different model components to improve efficiency. "we implement a decoupled parallelization scheme that allows the attention and MoE modules to use different parallelization strategies."
- EP-Group Balanced MoE Routing: A routing strategy that balances expert utilization across expert-parallel groups to avoid stragglers. "We therefore introduce an EP-Group Balanced MoE Routing strategy."
- Expert collapse: A failure mode in MoE where some experts become ineffective, receiving vanishing activations and updates. "we find that expert collapse can also manifest as an expert-side pathology even when router dispatch remains stable"
- Expert Parallelism (EP): Distributing experts across devices/ranks so different tokens route to different experts in parallel. "Expert parallelism (EP)~\cite{lepikhin2020gshardscalinggiantmodels} is utilized to enable scalable deployment."
- Frobenius norm: A matrix norm (square root of the sum of squared entries) used to quantify parameter magnitude. "parameter norms (e.g., Frobenius norms of expert projection matrices)."
- Grouped GEMM: Batched matrix-multiplication operations fused/grouped to reduce kernel overhead. "and implement a fused MoE gather/scatter with grouped GEMM, similar to SonicMoE~\cite{guo2025sonicmoeacceleratingmoeio}."
- Grouped-Query Attention (GQA): An attention variant where multiple queries share fewer key/value heads to improve memory behavior. "Hardware-Aligned Grouped-Query Attention (GQA-8). Targeting deployment on standard 8-GPU server nodes, we configure the model with eight heads (GQA-8)..."
- Head-wise gated attention: An attention mechanism that applies learnable gates per head to modulate attention outputs. "The model uses head-wise gated attention \cite{qiu2025gatedattentionlargelanguage} with a leading Full Attention layer..."
- Hybrid attention: Combining different attention types (e.g., sliding-window and full) to balance efficiency and connectivity. "we employ a hybrid attention mechanism~\cite{Beltagy2020Longformer,gemmateam2025gemma3technicalreport,openai2025gptoss120bgptoss20bmodel} to mitigate the quadratic complexity of long-context processing."
- Importance weighting: Weighting samples by their likelihood ratio in off-policy learning; here replaced by discrete filtering. "replacing continuous importance weighting with discrete, distributional filtering at both token and trajectory levels."
- KV-cache sharding: Splitting the key/value cache across devices to enable parallel inference and better memory access. "This aligns -cache sharding with 8-way tensor parallelism and improves memory access patterns."
- KV masking: Using masks over key/value positions to control which context is attended, supporting efficient verification. "SWA preserves standard attention semantics and remains inherently amenable to parallel verification via masking."
- Loss-free load balancing: Adjusting routing biases to balance expert loads without adding an explicit loss penalty. "We use loss-free load-balancing~\cite{deepseek2024deepseekv3,wang2024lossfreebalancing} to encourage global token balance across experts."
- Metropolis Independence Sampling-Filtered Policy Optimization (MIS-PO): An RL method that filters samples via Metropolis-style criteria to reduce variance. "we introduce Metropolis Independence Sampling-Filtered Policy Optimization (MIS-PO)~\cite{metropolis1953equation,hastings1970monte}"
- Mixture-of-Experts (MoE): A model architecture with many specialized expert sub-networks routed per token for capacity and efficiency. "a sparse Mixture-of-Experts (MoE) model"
- Multi-Token Prediction (MTP): Predicting multiple future tokens at once to accelerate generation, often used with speculative decoding. "To speedup speculative decoding on long-context agentic workloads, we attach three lightweight multi-token prediction (MTP) heads."
- Newton–Schulz (NS) iteration: An iterative method to approximate matrix inverses or orthogonal factors; used in the Muon optimizer. "Muon approximates a semi-orthogonal update direction via a Newton--Schulz (NS) iteration~\cite{bernstein2024oldoptimizernewnorm}."
- NVLink: NVIDIA’s high-bandwidth interconnect for GPU-to-GPU communication within a node. "Each node contains 8 GPUs interconnected through NVLink and NVSwitch for high-bandwidth intra-node communication."
- NVSwitch: A switch fabric enabling all-to-all high-bandwidth GPU communication within a node. "Each node contains 8 GPUs interconnected through NVLink and NVSwitch for high-bandwidth intra-node communication."
- Off-policy training: RL training on data generated by a different policy than the one being optimized. "maintaining stability during large-scale off-policy training to drive consistent self-improvement across mathematics, code, and tool use."
- Polar Express iteration: A faster-converging orthogonalization scheme adopted in Muon to improve stability. "We therefore adopt the {Polar Express}~\cite{amsel2025polarexpress} iteration and run a fixed steps to balance optimization quality and throughput."
- Prefilling: The initial phase of processing long input contexts before decoding begins. "extensive context prefilling followed by prolonged, multi-turn interactive decoding."
- Position-dependent loss reweighting: Adjusting loss weights based on prediction offset to balance near- vs. far-future token accuracy. "we adopt position-dependent loss reweighting across prediction offsets in MTP heads to prevent over-optimizing for distant-token predictions."
- Reduce-scatter: A distributed operation that reduces and scatters gradients across data-parallel ranks. "ZeRO-1~\cite{rajbhandari2020zero} reduce-scatter that shards a parameter's gradient across DP ranks."
- Reinforcement Learning (RL): Optimization via reward-driven feedback, here scaled for long-horizon reasoning and MoE. "limited scalability of Reinforcement Learning~(RL) to long-horizon reasoning for MoE models."
- RoCE: RDMA over Converged Ethernet, enabling high-speed inter-node communication. "the cluster relies on 8×200 Gbps RoCE links to maintain efficient synchronization and data exchange at scale."
- RoPE (Rotary Positional Embeddings): A positional encoding method applied to attention for long-context handling. "For RoPE~\cite{su2024roformer}, we use for both full attention and sliding window attention (SWA) during 4k training"
- RMSNorm: A normalization layer using root mean square statistics, here zero-centered. "We apply zero-centered RMSNorm \cite{gemmateam2024gemmaopenmodelsbased} throughout."
- Sliding-Window Attention (SWA): Attention constrained to a fixed local window for linear complexity and efficient decoding. "Sliding-Window Attention (SWA). We select SWA~\cite{DBLP:journals/corr/abs-1904-10509} over linear attention~\cite{10.5555/3524938.3525416,schlag2021linear} to maximize decoding efficiency."
- Sink tokens: Special tokens added as attention anchors to absorb unused attention mass within limited contexts. "introduce learnable, data-independent sink tokens into the window to address this issue."
- Speculative decoding: A generation technique that drafts multiple tokens and verifies them to accelerate inference. "we prioritize architectural compatibility with speculative decoding~\cite{10.5555/3618408.3619203}"
- Stragglers: Slow workers in distributed systems that bottleneck synchronization and throughput. "end-to-end latency can be dominated by stragglers induced by routing imbalance"
- SwiGLU: A gated linear unit variant that can produce sparse, high-magnitude activations. "This risk is exacerbated by SwiGLU~\cite{shazeer2020gluvariantsimprovetransformer}, where strong alignment between the gate and up-projection branches produces sparse activations with extreme magnitudes."
- Tensor parallelism: Splitting model tensors across devices to enable parallel computation. "This aligns -cache sharding with 8-way tensor parallelism and improves memory access patterns."
- Top-k router: The MoE mechanism selecting the k highest-scoring experts per token. "with a top- router activating experts per token."
- Trust region: A constraint on optimization updates to remain within stable distributional boundaries. "By restricting optimization to samples within a stable trust region, MIS-PO substantially reduces gradient variance..."
- Virtual pipeline stages (VPP): A technique that subdivides pipeline stages to improve utilization and overlap. "including 8-way pipeline parallelism (PP) with virtual pipeline stages (VPP)"
- ZeRO-1: A data-parallel optimization that shards optimizer states/gradients to reduce memory usage. "ZeRO-1 Data Parallelism (DP)~\cite{rajbhandari2020zero}."
Collections
Sign up for free to add this paper to one or more collections.