- The paper introduces an extension to the Puzzle NAS framework that supports heterogeneous MoE expert pruning and selective window attention to optimize GPT-OSS inference.
- It employs detailed performance metrics using AA-LCR benchmarks and FP8 KV-cache quantization, yielding up to 1.63× throughput improvement and 1.29× request-level efficiency.
- The methodology combines reinforcement learning for policy restoration with targeted distillation, resulting in a significantly compressed model that retains or improves accuracy despite a 27% parameter reduction.
Extending Puzzle for Mixture-of-Experts Reasoning Models with Application to GPT-OSS Acceleration
Introduction
This work presents an extension of the Puzzle neural architecture search (NAS) and compression framework to support Mixture-of-Experts (MoE) reasoning models, specifically targeting inference optimization of the GPT-OSS-120B model. The methodology results in an accelerated, deployment-efficient variant, gpt-oss-puzzle-88B, which achieves substantial improvements in throughput and request-level efficiency while preserving, and sometimes surpassing, the accuracy of the parent model. The research addresses critical challenges in scaling reasoning-centric LLMs by synergistically optimizing expert pruning, attention mechanisms, KV-cache quantization, and post-hoc policy restoration via knowledge distillation and reinforcement learning.

Figure 1: NVIDIA logo.
Methodology: Puzzle-based NAS for MoE and Long-Context Execution
The Puzzle framework performs layerwise NAS post-training to synthesize deployment-optimized model variants under rigorous hardware and scenario constraints. For models employing MoE layers, Puzzle is extended to support heterogeneous per-layer expert removal, evaluated under expert-parallel execution constraints. The core mechanisms include:
Policy Restoration and Reinforcement Learning
After blockwise architecture search and composition, knowledge distillation is employed to restore inter-block compatibility and mitigate any accuracy loss. The distillation phase is followed by reinforcement learning (RL) leveraging multi-task reasoning datasets: two complementary variants are trained—one focusing on high reasoning effort and one on a balanced mix of effort levels. Averaging their checkpoints yields a model striking an optimal accuracy-length trade-off, maintaining controllability of reasoning trace verbosity without excessive generation or cost inflation.
KV-Cache Optimization via FP8 Quantization
To reduce KV-cache memory and bandwidth, a post-hoc FP8 quantization scheme is applied on the cache with per-layer, max-calibrated scales, rounded to the nearest subunit power-of-two. This scheme enables up to 2× greater sequence capacity and enhanced throughput, particularly in long-context decoding regimes. Empirical ablations demonstrate that scale calibration is critical to preserving accuracy under aggressive quantization.
Empirical Results
Inference Efficiency—Architectural and Request-Level
gpt-oss-puzzle-88B achieves 1.22× throughput improvement in short-context, and 1.63× in long-context scenarios on 8×H100 nodes. On a single H100 GPU, speedup factors reach 2.82× for long-context, primarily due to expert pruning and memory footprint reduction via window attention, which unlock much larger batch sizes per device.
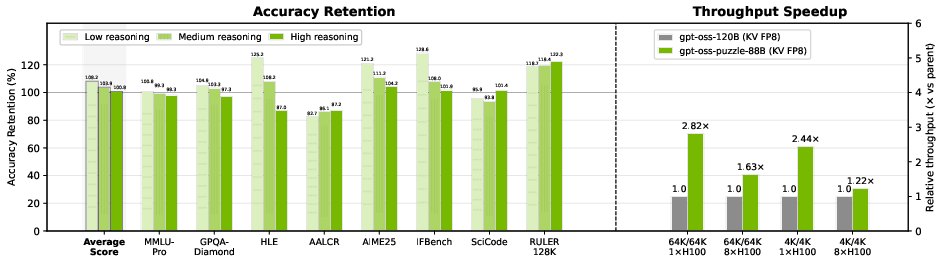
Figure 3: Comparison of accuracy and throughput of gpt-oss-puzzle-88B and gpt-oss-120B in KV FP8 mode.
Throughput scaling with batch size directly shows superior utilization, with the parent model quickly bottlenecked by memory. These patterns persist on B200 hardware, albeit with a slightly dampened (but still prominent) speedup on large memory systems. Latency/throughput trade-off curves favor the optimized model, with up to 1.5× higher throughput at fixed generation latency.
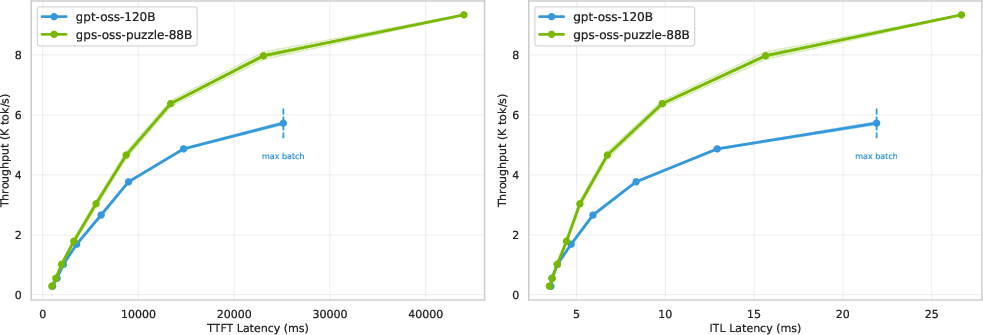
Figure 4: Latency vs throughput for 64K/64K scenario, quantifying improved trade-offs after NAS-guided optimization.
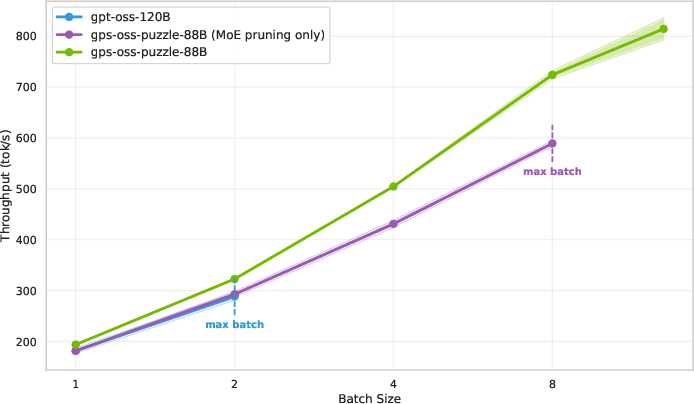
Figure 5: Single H100 throughput as a function of batch size in the 64K/64K scenario, showcasing significantly improved scaling and memory efficiency after Puzzle optimization.
Request-Level Efficiency
Since reasoning effort influences token counts per request, per-token measures alone are misleading for user-facing efficiency. Normalized request-level metrics—combining throughput with generation length—place gpt-oss-puzzle-88B as strictly dominant across the accuracy-efficiency frontier, with up to 1.29× higher request-level efficiency than the parent, robustly maintained across reasoning effort levels and benchmarks.
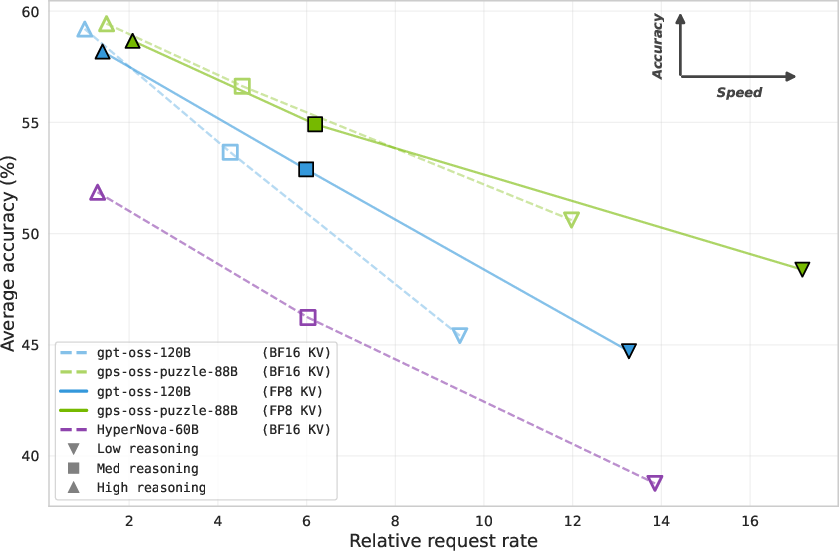
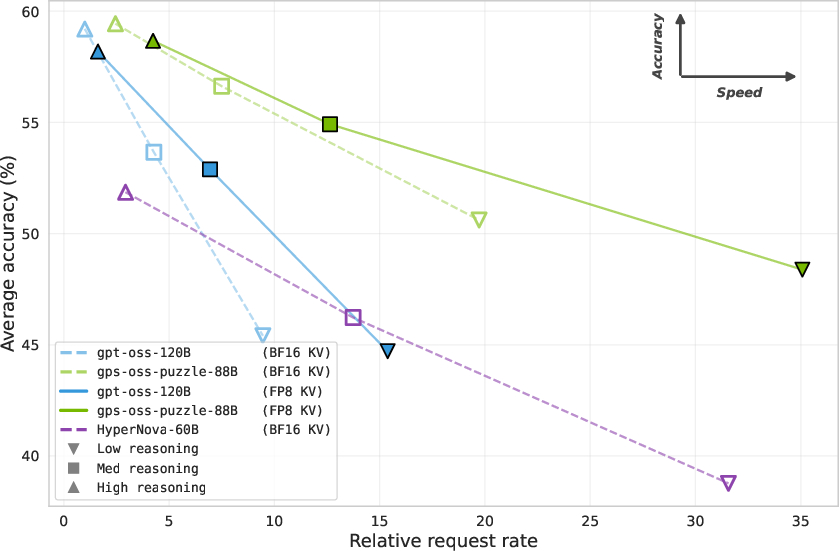
Figure 6: Accuracy-speed frontier for different deployment settings and reasoning efforts.
Accuracy Benchmarks
Despite a 27% parameter reduction, gpt-oss-puzzle-88B (with FP8 quantization) attains suite-average accuracy retention at 100.8% (high effort), 103.9% (medium), and 108.2% (low) relative to the parent. Some tasks (AALCR, RULER-128K) show minor regressions, but the gap is inverted on others (AIME25, IFBench), especially at lower effort settings. Reinforcement learning weight averaging further stabilizes effort-based controllability in verbosity/generation length.
Ablation Studies
Dedicated ablation on attention block scoring shows that AA-LCR-based signals yield superior retention for long-range tasks, compared to locality-biased activation-based MSE. The chosen attention configuration and quantization regime are validated via comprehensive performance and accuracy reporting.
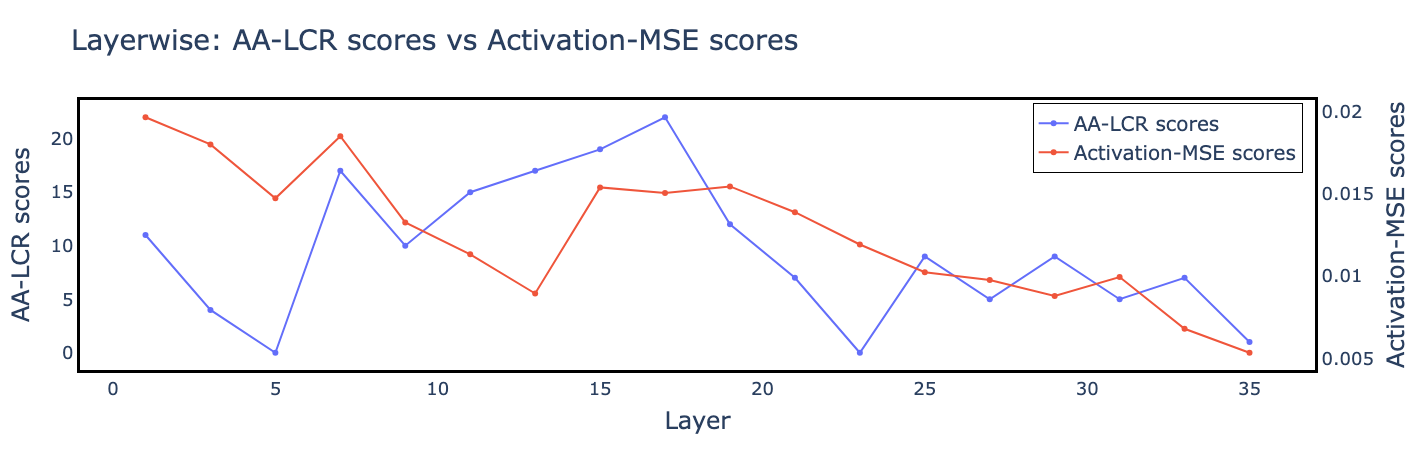
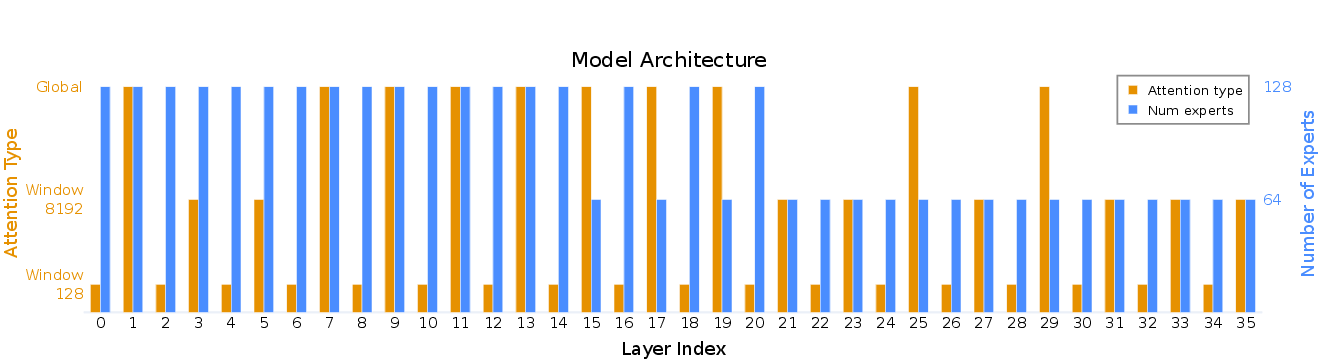
Figure 7: Layerwise AA-LCR and activation-MSE replace-1 scores, pinpointing irreplaceable layers for window attention conversion.
Discussion and Implications
This study demonstrates that post-training NAS can systematically compress and accelerate large MoE-based reasoning LLMs without loss of function on complex benchmarks. The extension to heterogeneous MoE expert pruning and context-aware attention mechanism reallocation, coupled with careful post-compression policy restoration, yields deployment variants with significantly improved cost-performance profiles. The explicit separation between per-token and request-level efficiency, and the introduction of accuracy-speed frontiers, provides a template for future evaluation and reporting in reasoning-centric LLM research.
Practically, the methodology reduces resource requirements for high-effort reasoning model serving, enabling larger batch deployments and longer-sequence tasks on commodity and enterprise hardware. Theoretically, the work underlines the importance of block-level flexibility and custom hardware-aware search spaces in the pursuit of scalable, efficient LLM deployment. The replacement of locality-biased similarity proxies for NAS with direct, task-level signals is shown to be effective, substantiating the need for carefully aligned validation tasks during the NAS phase.
Conclusion
Extending Puzzle to jointly support MoE compression, selective attention windowization, and aggressive quantization establishes a repeatable, scalable approach to LLM inference optimization. The resulting gpt-oss-puzzle-88B model sets new state-of-the-art efficiency baselines for open-weight, long-context reasoning LLMs, confirming that cost- and accuracy-aware post-training NAS can bridge the gap between architectural ambition and deployability (2602.11937).