The Pinnacle Architecture: Reducing the cost of breaking RSA-2048 to 100 000 physical qubits using quantum LDPC codes
Abstract: The realisation of utility-scale quantum computing inextricably depends on the design of practical, low-overhead fault-tolerant architectures. We introduce the \textit{Pinnacle Architecture}, which uses quantum low-density parity check (QLDPC) codes to allow for universal, fault-tolerant quantum computation with a spacetime overhead significantly smaller than that of any competing architecture. With this architecture, we show that 2048-bit RSA integers can be factored with less than one hundred thousand physical qubits, given a physical error rate of $10{-3}$, code cycle time of $1$ \textmu s and a reaction time of $10$ \textmu s. We thereby demonstrate the feasibility of utility-scale quantum computing with an order of magnitude fewer physical qubits than has previously been believed necessary.

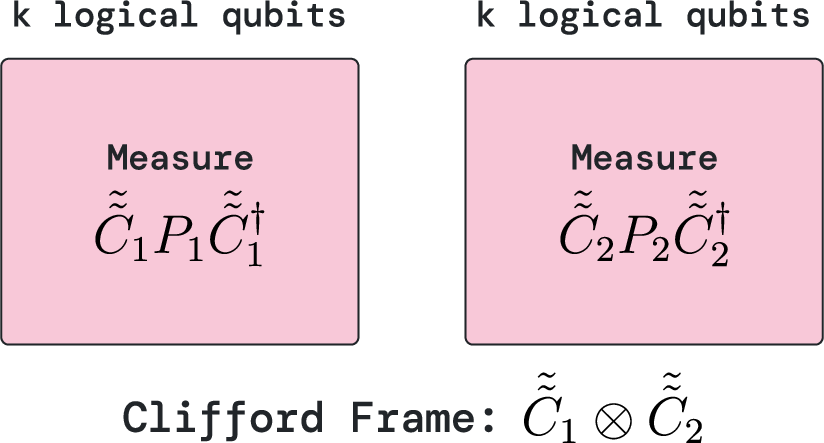

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to build a large, reliable quantum computer, called the Pinnacle Architecture. Its big promise is doing powerful quantum tasks—like breaking RSA-2048 encryption—with far fewer physical qubits than people previously thought were needed. The authors show how to protect fragile quantum information from errors, organize the machine into simple modules, and run programs efficiently, all while keeping the hardware requirements realistic.
What questions are the authors trying to answer?
In simple terms, the paper asks:
- How can we build a fault-tolerant (error-resistant) quantum computer that doesn’t need millions of physical qubits?
- Can we design an architecture that’s practical for real hardware and supports complex algorithms like RSA factoring?
- Is there a way to both reduce the number of qubits and keep the runtime reasonable?
How did they approach the problem?
The authors combine clever error-correcting codes with a modular machine design and an efficient way of running quantum programs.
Here are the key ideas, explained with everyday analogies:
- Quantum LDPC codes (QLDPC): Think of error-correcting codes as safety nets that catch errors. “LDPC” means the net is sparse—each rope ties only to a few others—so it’s lightweight but still strong. Unlike the popular “surface code,” which usually protects one logical qubit per block at high cost, QLDPC codes can protect many logical qubits in a single block, saving lots of space.
- Processing units: Imagine teams of workers (processing units) each holding several protected logical qubits. They can perform one “joint check” (a special measurement across their qubits) each cycle to move the computation forward. Multiple units can be bridged to work together when needed.
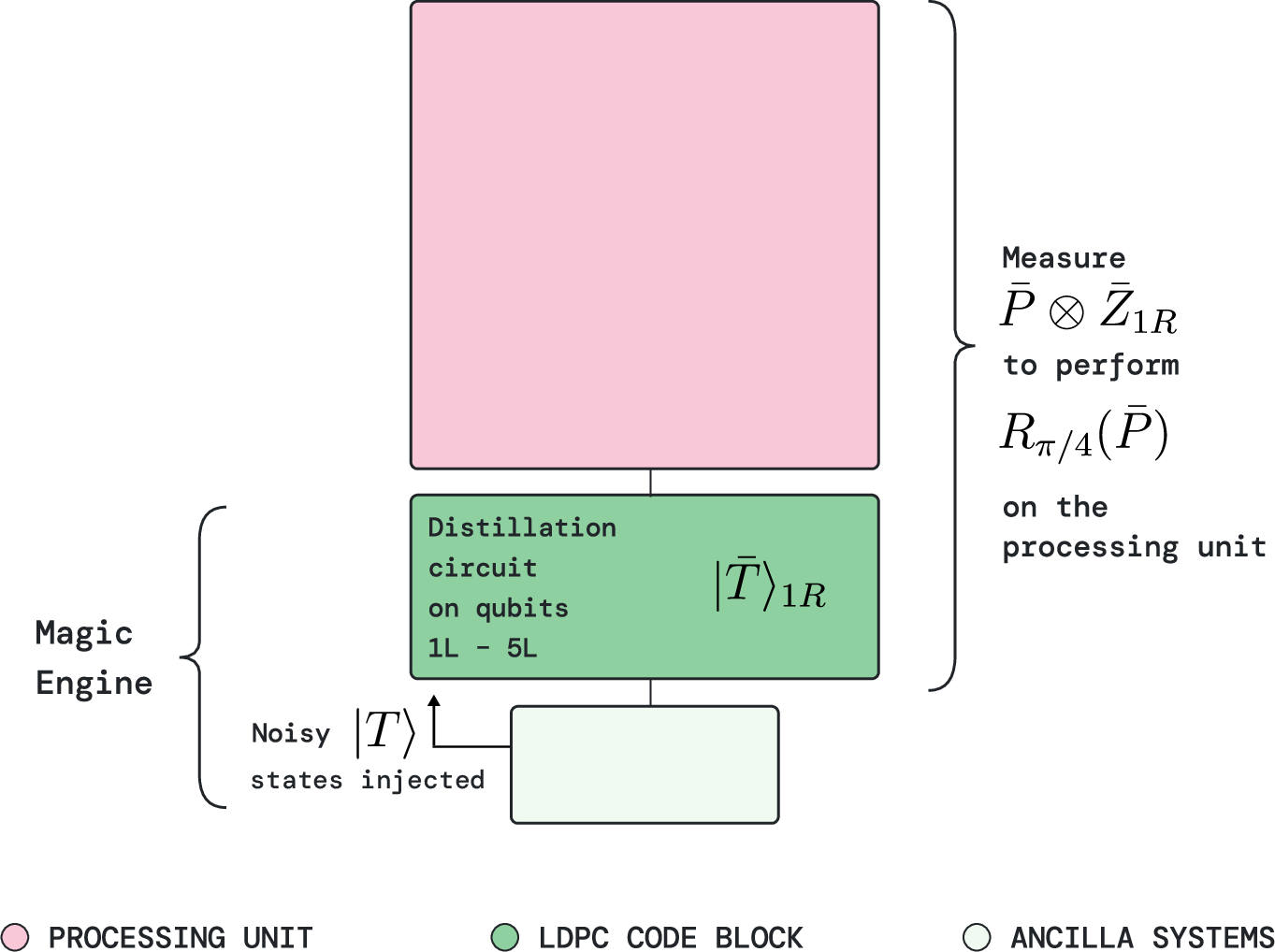
- Magic engines: Some quantum gates (the really powerful, non-Clifford ones) need special ingredients called “magic states.” A magic engine is like a factory that distills noisy magic states into clean, high-quality ones, then delivers one fresh magic state every cycle to its paired processing unit. It produces while it consumes—so throughput stays constant.
- Pauli-based computation: Instead of applying gates one by one, this method turns the circuit into a planned sequence of measurements of Pauli operators (think: measuring particular combinations of X, Y, Z behaviors). It’s like solving a puzzle by asking a series of yes/no questions, each carefully chosen to equal the effect of the original gates. This approach works very well with QLDPC codes and the gadget system the authors use.
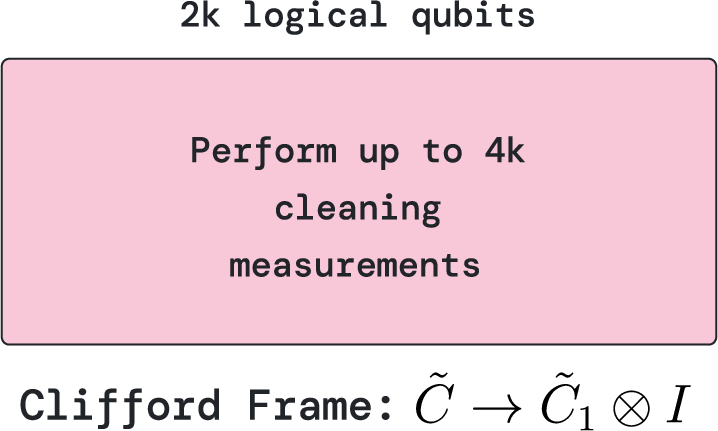
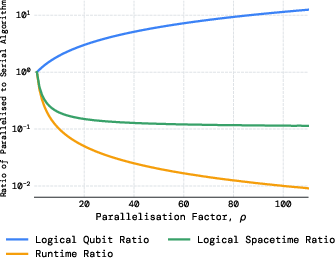
- Clifford frame cleaning: When different teams collaborate, their instructions can get tangled. “Cleaning” is a quick tidy-up step that reorders the instructions so teams can resume working independently in parallel. It costs a small number of extra measurement steps but allows flexible parallelism without needing to physically do every entangling gate.
- Memory with ports and windows: Think of a shared library of qubits (memory), split into windows you can read from. A “port” lets a processing unit read a selected window without disturbing the others. Multiple units can read different parts in parallel, like several students referencing different sections of the same book at once.
- Limited connectivity: The architecture only needs short-range connections—the parts that need to talk are physically close. That’s good for real hardware because long-range links are harder and less reliable.
- Timescales: A code cycle is one round of error checks. Several code cycles make a logical cycle (enough checks to be confident). Reaction time is the delay the classical controller needs before it can choose the next measurement based on the last result. The authors pick hardware-friendly numbers: error rate about 0.1% (1e−3), code cycle about 1 microsecond, and reaction time about 10 microseconds.
They also show a concrete version using “generalized bicycle (GB) codes,” a family of QLDPC codes with simple, repeatable structure. In this setup, they use a standard 15-to-1 magic state distillation routine inside the magic engine to produce reliable magic states.
What did they find, and why is it important?
The results are striking:
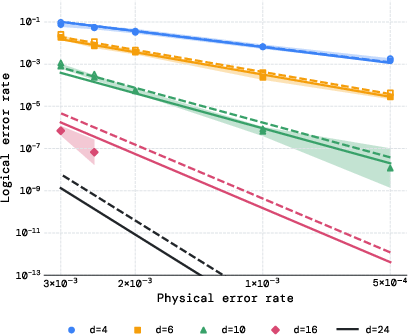
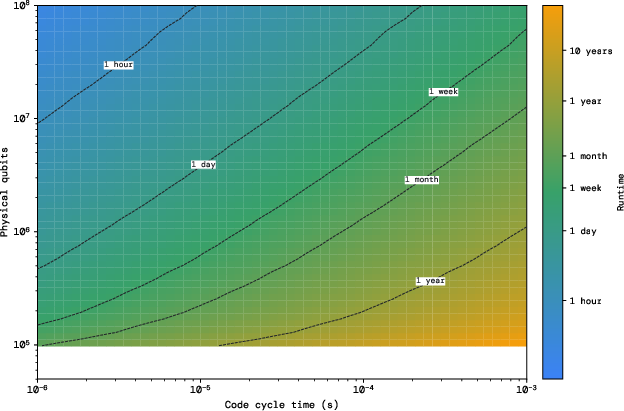
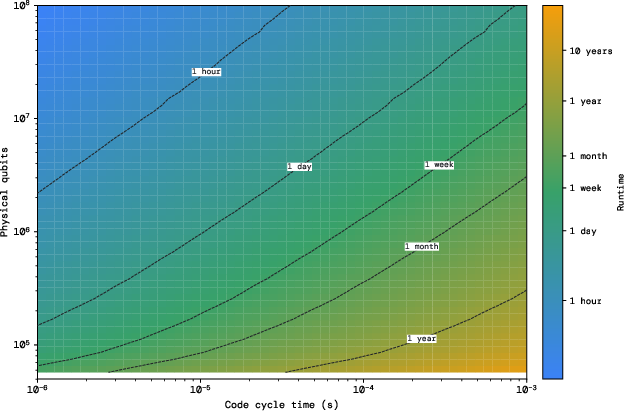
- Breaking RSA-2048 with fewer than 100,000 physical qubits: Earlier best estimates suggested close to 1 million qubits using surface-code-based designs. With Pinnacle, under standard assumptions (error rate ≈ 1e−3, 1 μs code cycle, 10 μs reaction time), they show that factoring a 2048-bit RSA number is possible with under 100k qubits. That’s about a 10× reduction.
- Flexible space–time trade-offs: If the hardware is slower (for example, 1 millisecond code cycles), the architecture can add more processing units to keep runtime reasonable. They chart options across different error rates and cycle times, showing feasible paths under various hardware regimes.
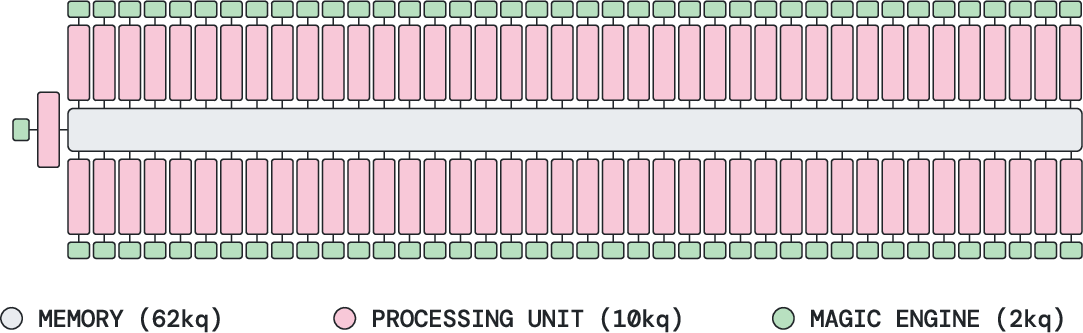
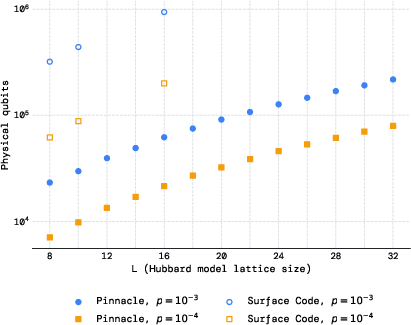
- Big savings for scientific simulations: For finding the ground-state energy of the Fermi–Hubbard model (a physics benchmark), they report order-of-magnitude reductions in qubits compared to prior end-to-end estimates. For a 16×16 lattice, they need about 62k qubits at 1e−3 error rate (vs ~940k before), and only ~22k at 1e−4.
- Practicality: The design is modular, needs only short-range connections, and supports parallelism. That matches how many real quantum platforms are likely to be built: as clusters of modules rather than giant all-to-all devices.
In short, the Pinnacle Architecture lowers the “entry ticket” for utility-scale quantum computing, making powerful applications look more reachable.
What’s the potential impact?
If these ideas are built and validated on real machines, the impact could be large:
- The timeline to useful quantum computers could accelerate: Needing 100k qubits instead of a million is a huge hardware simplification.
- Cryptography planning needs updates: RSA-2048 is widely used. While actual, practical quantum attacks still depend on many engineering details and stable low error rates, resource estimates like these help governments and companies plan for post-quantum security sooner.
- Better fit for real hardware: The architecture’s limited connectivity, modular structure, and parallel-friendly scheduling make it more likely to work across different platforms (superconducting qubits, trapped ions, neutral atoms, etc.).
- More science with fewer resources: The same approach benefits quantum chemistry and materials science, potentially enabling important simulations with tens of thousands of qubits rather than hundreds of thousands or millions.
Overall, the Pinnacle Architecture provides a clear blueprint for building a fault-tolerant quantum computer that’s both scalable and efficient. It shows that powerful quantum tasks can be done with far fewer qubits than expected, which could move the field forward faster.
Knowledge Gaps
Below is a single, consolidated list of concrete knowledge gaps, limitations, and open questions that remain unresolved in the paper. Each point is phrased to guide actionable follow-up research.
- Prove or disprove the conjectured parameters of the specific GB code family used (e.g., exact ), and quantify finite-size scaling and thresholds under realistic noise.
- Specify and benchmark decoders for the chosen QLDPC codes (algorithm, complexity, accuracy), including latency and throughput at scale, and verify that decoding fits within the assumed reaction-time and code-cycle budgets for microsecond- and millisecond-speed hardware.
- Quantify how adding measurement gadgets and bridges alters check weights/qubit degrees locally and globally, how this impacts threshold and decoder performance, and what ancillary resources are needed to keep degrees low without eroding gains.
- Provide a detailed, hardware-informed noise model (beyond i.i.d. depolarizing), including gate-dependent, correlated, crosstalk, leakage, and erasure errors for long-range/bridging operations and SWAP-based memory reordering; reassess logical error rates under these models.
- Validate the assumption that “rearrangement during a code cycle is negligible” for memory cyclic shifts by characterizing additional error from SWAPs, scheduling overhead, and decoder load during rearrangements.
- Establish end-to-end error budgets for benchmarks (RSA-2048, Fermi-Hubbard): target overall failure probability, apportionment among logic, distillation, memory, and measurement steps, and confirm that claimed parameters meet these budgets with margin.
- Characterize the reaction-time requirement () with concrete classical-processing pipelines (syndrome decoding, Pauli frame updates, cleaning logic, inter-unit coordination) to show feasibility on proposed hardware scales and across many concurrent blocks.
- Detail the decoding and control-network bandwidth needed for simultaneous, repeated joint Pauli measurements across many bridged blocks, and assess bottlenecks when scaling to hundreds of processing units.
- Quantify the performance of the “Clifford frame cleaning” method beyond the stated upper bound of at most measurements: prove tightness, analyze failure propagation under noise, and provide empirical benchmarks on representative circuits.
- Develop compiler strategies that decide when to join/separate units and where to invoke cleaning, and measure the net savings vs. (i) fully serial execution and (ii) physically implementing all inter-unit CNOTs; provide case studies with real circuits.
- Analyze limits to simultaneous, parallel Pauli measurements within a block: characterize maximal commuting sets for the chosen gadgets/GB codes, the resulting check-degree blow-up, and decoder/threshold implications for different degrees of parallelism.
- Provide a complete magic-engine specification: required input fidelity, ancilla code distances , expected reject rate , and resulting logical error per injected ; show that a single engine per processing unit sustains required throughput for reported applications.
- Explore buffering strategies for the magic engine (e.g., preparing multiple states ahead) to mitigate stochastic stalls from post-selection; characterize throughput, qubit overhead, and optimal buffer depth vs. and target algorithmic failure rates.
- Evaluate alternative distillation protocols (e.g., higher-yield or erasure-tailored variants, cultivation, multi-level protocols) for regimes with different physical error rates and code cycle times; map their footprint/latency trade-offs within the magic engine.
- Examine how often cleaning must be invoked in typical large-scale circuits (e.g., modular exponentiation, phase estimation) and quantify its amortized overhead on T-count–limited schedules; include sensitivity to variability and inter-unit gate density.
- Assess the read-only memory model’s algorithmic sufficiency: identify workloads requiring write/update operations; design and analyze low-overhead, fault-tolerant write mechanisms and their impact on ports, gadgets, and degree/threshold.
- Quantify error and overhead from memory-windowing and multi-port access: maximum number of parallel ports per memory block that maintains acceptable check degrees, decoder performance, and read latency.
- Provide floorplans and routing for concrete hardware (superconducting, trapped-ion, neutral-atom, modular photonic links) that realize the “constant-scale” connectivity claim; include realistic link fidelities/latencies for bridges and inter-module joins.
- Reassess RSA-2048 factoring estimates under tighter hardware models (e.g., leakage-prone platforms or inter-module photonic links with erasures), and report how many qubits/runtime are needed when using erasure-aware decoders and more realistic control latencies.
- Analyze idling error accumulation in memory and processing units during stalls (e.g., magic-state rejections, cleaning pauses), including bias between dephasing/relaxation and how that impacts code choice and syndrome cadence.
- Provide the full schedule for syndrome extraction and gadget operations within a logical cycle for each module (processing blocks, magic engines, memory), and demonstrate that resource contention (gadget shifts, bridges, SWAPs) does not violate cycle-time or calibration constraints.
- Compare fairly to state-of-the-art surface-code and prior QLDPC architectures across identical assumptions (noise model, reaction time, classical overheads) and report sensitivity analyses showing when Pinnacle’s advantage narrows or widens.
- Investigate robustness to heterogeneous device performance across blocks/modules (varying , ), including adaptive code distances or rate-matching between faster/slower units and its effect on scheduling and cleaning overhead.
- Specify how leakage detection/mitigation integrates with the architecture (e.g., LRUs, mid-circuit resets) and quantify the impact on gadgets, bridges, memory shifts, and decoders.
- Clarify how intermediate, non-Pauli measurements or classically controlled branching (beyond standard PBC) are compiled and scheduled without becoming reaction-limited; provide examples and overheads.
- Provide variance and tail analyses for total runtime in parallel operation with post-selection (distribution of stalls across many units), and propose scheduling policies to avoid straggler-dominated makespan.
- Detail the cost of verifying success for large computations (e.g., repeat runs, cross-checks, or certified subroutines) and its integration with the architecture’s parallel and memory models.
- Quantify energy, thermal, and control-resource implications of the proposed constant-scale but dense intra-block connectivity and repeated gadget actuation at high duty cycles.
- Explore extensions beyond Pauli-based computation where advantageous (e.g., transversal gadgets for specific non-Clifford rotations) within the QLDPC framework, and assess whether such hybrids can further reduce the time penalty from cleaning or post-selection.
- Provide open-source tooling (compiler, scheduler, resource-estimation code) and datasets enabling independent replication of the reported qubit counts and runtimes, and to test alternative code/gadget/distillation choices.
Practical Applications
Practical Applications Derived from the Paper
Below we distill actionable, real-world applications arising from the Pinnacle Architecture (QLDPC-based processing units, magic engines, memory ports, and Clifford frame cleaning), and from the paper’s end-to-end resource analyses (RSA-2048 factoring and Fermi–Hubbard simulation). Each application is categorized as an Immediate Application (deployable now in R&D, planning, prototyping, or software) or a Long-Term Application (requiring further research, scaling, or development).
Immediate Applications
- Bold roadmap and risk re-assessment for post-quantum migration (Cybersecurity, Policy)
- What: Update organizational threat models and migration timelines in light of an order-of-magnitude reduction in qubits needed to factor RSA-2048 (<100k physical qubits at p=1e-3, tc=1 μs, tr=10 μs).
- Potential tools/products/workflows: Crypto-agility roadmaps; “harvest-now, decrypt-later” risk dashboards; procurement checklists for PQC-compliant hardware/software; sector-specific migration playbooks (finance, healthcare, government, telecom).
- Assumptions/dependencies: The paper’s resource estimates hold under realistic noise, decoder performance, and control latencies; industry/government acceptance of updated risk timelines; PQC standards (e.g., NIST) already available.
- Pinnacle-aware compilation and scheduling research (Software, Academia, Cloud)
- What: Implement Pauli-based computation (PBC) flows with “Clifford frame cleaning” to enable flexible parallelism; optimize for magic-engine throughput; schedule joint logical measurements across bridged processing blocks; implement read-only memory port access.
- Potential tools/products/workflows: Transpiler passes in Qiskit/tket/Cirq; PBC schedulers that decide when to join/separate units; T-count/T-depth optimizers; frame-cleaning cost models; measurement-basis routing and gadget reconfiguration planners.
- Assumptions/dependencies: Availability of device or high-fidelity simulators supporting mid-circuit measurement and adaptive control; correctness of the frame-cleaning lemmas; measurable reaction times (tr ≈ 10 tc).
- Resource-estimation platforms and benchmarks (Industry, Academia, Policy)
- What: Offer interactive dashboards to explore spacetime trade-offs vs. physical error rates p, code cycle times tc, reaction time tr, and number of processing units for canonical workloads (RSA-2048, Fermi–Hubbard).
- Potential tools/products/workflows: Public calculators; DOE/EC roadmapping studies; investor due-diligence tools; standards-track benchmark suites reporting T-count, logical cycles, and reaction-time sensitivity.
- Assumptions/dependencies: Validity of hardware-agnostic error models; accessible parameters for platform-specific tc and p (superconducting, ions, neutral atoms, photonics).
- Early experimental demonstrations of QLDPC gadgets and bridging (Quantum hardware, Academia)
- What: Prototype small-distance generalized bicycle (GB) codes, demonstrate gadget-enabled arbitrary logical Pauli product measurements, and test bridging between processing blocks.
- Potential tools/products/workflows: Test chips with seed-operator gadgets; low-distance code demonstrations of joint logical measurements; calibration/verification pipelines for gadget qubits.
- Assumptions/dependencies: Platforms offering quasi-local non-nearest-neighbor interactions; mid-circuit measurement/reset; reliable decoders for GB codes; manageable check weights and degrees with parallel gadgets.
- Magic engine prototyping at low code distances (Quantum hardware, Academia)
- What: Build a “magic engine” that simultaneously distills and injects magic states (even/odd-cycle two-sector operation) at modest distances, validating throughput, reject rate pr, and control.
- Potential tools/products/workflows: 15-to-1 distillation with auto-corrected π/8 rotations; zero-level/pre-distillation feeding; cultivation for improved inputs; throughput telemetry and pr estimation.
- Assumptions/dependencies: Availability of small encoded ancilla blocks; synchronized joint logical measurements; sufficient input |T⟩ fidelity; decoder performance under realistic noise.
- Memory port and read-only access emulation (Software/Hardware-in-the-loop)
- What: Emulate windowed QRAM-like read-only access via ports; validate cyclic block shifts and fan-out/fan-in controls that commute; test multi-tenant parallel port access.
- Potential tools/products/workflows: Memory-window schedulers; port-gadget libraries supporting Z-type measurements in parallel; simulators with bounded-distance connectivity constraints.
- Assumptions/dependencies: Memory is read-only; bounded-distance swap networks complete within a code cycle; error budgets remain favorable during cyclic shifts.
- Algorithm co-design for PBC and Pinnacle (Academia, Industry)
- What: Recompile physics and cryptographic workloads to PBC, reduce T-counts, and structure circuits for join/separate unit phases (e.g., large batched T segments vs. low-entanglement phases).
- Potential tools/products/workflows: PBC-native algorithm libraries; phase-polynomial optimizers; adaptive partitioners that minimize frame-cleaning overhead; schedules that exploit constant-throughput magic engines.
- Assumptions/dependencies: Algorithm teams can access PBC-aware transpilers; cost models reflect realistic logical error and reaction-time constraints.
- Education and workforce development (Academia, Training)
- What: Update curricula to include QLDPC, gadgetized Pauli measurements, PBC, Clifford frame cleaning, and modular processing-unit design; organize hackathons around Pinnacle-aware schedulers/estimators.
- Potential tools/products/workflows: Course modules; open-source exemplar codes; small testbeds on cloud simulators/hardware.
- Assumptions/dependencies: Community adoption; availability of pedagogical tooling.
- Investment and policy prioritization (Policy, Investors, Industry)
- What: Rebalance funding toward QLDPC-friendly interconnects, decoders for GB codes, low-latency classical control, and modular multi-unit systems; update export control and standards agendas to include reaction-time and logical-cycle metrics.
- Potential tools/products/workflows: Calls for proposals focused on modular connectivity; performance baselines for tc/tr; interoperability standards for processing units and ports.
- Assumptions/dependencies: Policymaker buy-in; alignment with national strategies; industry appetite for QLDPC beyond surface-code-only plans.
Long-Term Applications
- Practical cryptanalysis of RSA/ECC at sub-million-qubit scales (Cybersecurity, Intelligence, Cloud)
- What: Offer credible capability to factor RSA-2048 and break ECC using deployments in the 0.1–3M physical qubit range, depending on tc, p, and parallelization.
- Potential tools/products/workflows: Controlled-access cryptanalysis clusters; factoring pipelines with PBC scheduling and magic-engine farms; audit/logging frameworks for lawful use.
- Assumptions/dependencies: Achieving p ≲ 10-3–10-4 with tc ≲ 1 μs (or compensating parallelism at longer tc); stable GB-code performance and decoders; robust device yields and uptime; strong governance/ethics.
- Utility-scale quantum simulation for materials and chemistry (Energy, Materials, Pharma)
- What: Use tens to hundreds of thousands of qubits to reach classically intractable targets (e.g., Fermi–Hubbard with L≈16 and beyond, correlated catalysts, novel superconductors), with order-of-magnitude fewer qubits than surface-code estimates.
- Potential tools/products/workflows: Domain-specific mappers; memory-port strategies to stream/read controls; hybrid DFT+QC workflows; validation via cross-checks on smaller instances.
- Assumptions/dependencies: Continued T-count reductions, error-budgeted Trotterization/alternatives; scalable magic factories; stable operation over minutes-to-days logical runtimes.
- Quantum cloud services based on modular processing units (Cloud, Software)
- What: Multi-tenant clusters that schedule PBC workloads across many processing units, sharing memory ports (read-only) and optimizing join/separate cycles to maximize throughput.
- Potential tools/products/workflows: “Logical cycle” SLAs; orchestration layers for magic-engine assignment; port-access schedulers that avoid contention; cost-based compilers.
- Assumptions/dependencies: Modular hardware with bounded-distance connectivity; high-yield packaging, cryo-control electronics, and inter-module links; reliable logical error monitoring.
- Hybrid workflows leveraging read-only structured memory (HPC, Finance, Scientific computing)
- What: Algorithms with large, static control datasets (e.g., batched amplitude estimation, query-based primitives) that benefit from read-only, many-reader memory windows accessed in parallel.
- Potential tools/products/workflows: Memory-window layout planners; fan-out/fan-in libraries; data staging pipelines; caching strategies to reduce port shuffles.
- Assumptions/dependencies: Practical, stable quantum memory with port gadgets; negligible time for cyclic shifts relative to code cycles in target platforms.
- Domain accelerators for T-heavy primitives (Finance, Logistics, Cryptography R&D)
- What: Specialized services for amplitude estimation, large arithmetic circuits, and zero-knowledge or FHE-parameter stress-testing that exploit PBC and magic-engine throughput.
- Potential tools/products/workflows: Pre-optimized PBC kernels; phase-gradient factory services; workload libraries with known T-counts matched to processing-unit inventories.
- Assumptions/dependencies: Demonstrated advantage vs. classical; predictable T-count scaling; affordable runtime with platform tc and p.
- Hardware and microarchitecture co-design around processing blocks (Semiconductors, Quantum hardware)
- What: Standardize processing block sizes (e.g., ~860 or ~1620 physical qubits/block), gadget placement, and bridge patterns; design on-chip networks and cryo-control meeting tc/tr budgets and bounded connectivity.
- Potential tools/products/workflows: EDA for quantum packaging and interposers; reference designs for gadget qubits; control firmware tuned to logical-cycle timing; error budgeting tools.
- Assumptions/dependencies: Fabrication yields for medium-scale modules; thermal and wiring budgets; stable non-local gate fidelities at processing-block scale.
- Full PQC transition and ecosystem hardening (Policy, IT, Consumer tech)
- What: Complete migration from RSA/ECC in critical infrastructure, IoT boot chains, browsers, and PKI; deprecation timelines that reflect accelerated quantum risk; archival data protection strategies.
- Potential tools/products/workflows: PQC HSMs; firmware rotation protocols; certificate ecosystem updates; backward-compatible protocol extensions.
- Assumptions/dependencies: Global standards and procurement alignment; performance and footprint of PQC algorithms in constrained devices; supply-chain readiness.
- Standards, certification, and reproducibility for QLDPC stacks (Standards bodies, Academia, Industry)
- What: Define and certify decoders, gadgetized syndrome extraction circuits, error models, and reporting for logical error rates and reaction-time budgets across platforms.
- Potential tools/products/workflows: Conformance tests; public datasets; cross-vendor bake-offs; reporting formats including logical-cycle counts and frame-cleaning overheads.
- Assumptions/dependencies: Community consensus; availability of comparable hardware and simulators.
- Commercial tooling built on the architecture (Software, IP cores)
- What: Pinnacle-aware SDKs, GB-code decoders, measurement-scheduling optimizers, magic-engine IP blocks, memory-port controllers, and layout planners for bounded-distance connectivity.
- Potential tools/products/workflows: Licenseable IP blocks; integration into major toolchains; support for multiple hardware backends.
- Assumptions/dependencies: Market adoption of QLDPC-based architectures; interoperable APIs; sustained support for PBC-oriented programming models.
Notes on cross-cutting assumptions and dependencies:
- Hardware performance: Achievable physical error rates (p ≈ 10-3–10-4), code-cycle times (tc ≈ 1 μs–1 ms), reaction times (tr ≈ 10 tc), and non-local operations consistent with bounded processing-block scales.
- Code properties: Conjectured GB-code distances and practical decoders; check-weight/qubit-degree increases under parallel gadgets; overheads of dt = d+2 logical cycles.
- Control stack: Fast, reliable adaptive control; frame-tracking; classical–quantum latency within reaction-time budgets.
- Noise realism: Estimates assume noise models typical in literature; correlated/crosstalk errors or slow drifts may require additional mitigation.
- Algorithm fit: PBC compiles best for T-heavy circuits; workloads with low T-count or heavy mid-circuit adaptivity may need tailored strategies.
- Governance: Cryptanalysis use cases require strong legal/ethical controls; policy responses (PQC, standards, export controls) shape deployment.
Glossary
- 15-to-1 magic state distillation: A specific distillation protocol that consumes 15 noisy T states to produce one higher-fidelity T state. "We use 15-to-1 magic state distillation on these code blocks to produce encoded $\ket{\bar{T}$ magic states"
- ancilla qubit: A helper qubit used to facilitate operations like syndrome extraction or auto-correction without carrying the logical data itself. "with the use of ancilla qubits;"
- auto-corrected Z-type π/8 rotation: A technique to implement Z-axis π/8 rotations that includes an auto-correction mechanism to handle stochastic corrections from state injection. "fifteen auto-corrected -type rotations"
- bridged processing block: A processing block connected via a physical “bridge” to another block to enable joint logical Pauli measurements across blocks. "using bridged processing blocks"
- Clifford corrections: Deterministic Pauli/Clifford operations that must be applied (or tracked) due to measurement outcomes in magic state injection circuits. "to account for Clifford corrections from the state injection"
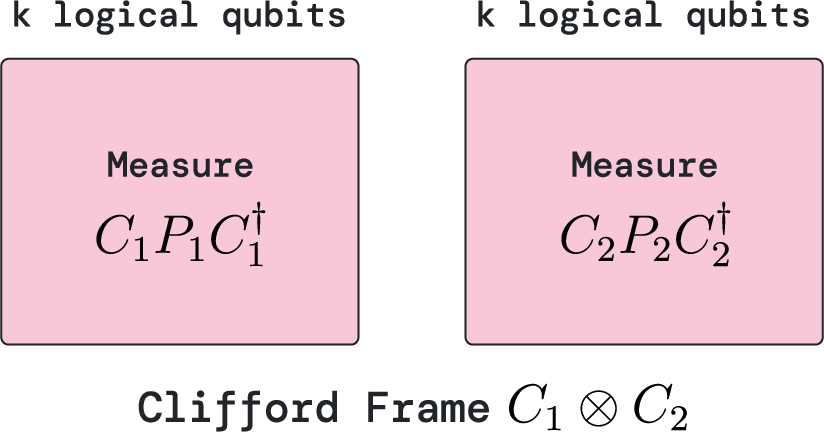
- Clifford frame: The accumulated, tracked Clifford transformation that updates how subsequent Pauli measurements and operators are interpreted. "consider the case of a Clifford frame at a given point in the circuit"
- Clifford frame cleaning: A method to physically apply Cliffords so that the tracked Clifford frame becomes trivial on a chosen subset of qubits, enabling parallelism. "we introduce Clifford frame cleaning as a new method"
- Clifford gate: A gate from the Clifford group that maps Pauli operators to Pauli operators under conjugation (e.g., H, S, CNOT). "any number of Clifford gates"
- code block: A concrete instantiation of a quantum error-correcting code that groups data and check qubits to protect logical information. "A code block is an instantiation of an quantum error-correcting code."
- code cycle time: The duration of one full round of syndrome extraction on a code block. "there is the code cycle time "
- code distance: A measure of the minimum weight of a logical operator (or smallest number of physical errors that can cause a logical error). "independent of the code distance."
- error syndrome: The set of measurement outcomes from parity checks that indicates the presence and type of errors. "collectively yield an error syndrome."
- fan-out/fan-in: Using CNOTs to copy (fan-out) control information from memory into ancilla targets and later recombine (fan-in) it back. "to fan out memory data onto the processing unit at the start of the access and fan in at the end of the access."
- Fermi-Hubbard model: A canonical model of interacting electrons on a lattice used to study strongly correlated materials. "determining the ground state energy of the Fermi-Hubbard model"
- generalised bicycle (GB) code: A family of QLDPC codes constructed from cyclic structures that enable many logical qubits with low-weight checks. "using the family of generalised bicycle codes"
- generalised lattice surgery: A technique for performing joint logical measurements (and thereby gates) between code blocks using measurement gadgets. "allows for generalised lattice surgery"
- lift (in GB codes): An integer parameter defining the cyclic size in the construction of generalised bicycle codes. "GB codes are defined by a lift "
- logical CNOT: A controlled-NOT implemented on encoded (logical) qubits of error-correcting codes. "logical CNOT gates"
- logical cycle: A grouping of multiple code cycles whose combined outcomes yield a reliable logical measurement. "this is referred to as a logical cycle."
- logical Pauli operator: An encoded Pauli (X, Y, or Z) acting on the logical qubits of a code. "measuring a selected Pauli logical operator of the code"
- logical sector: A designated subset (e.g., L and R halves) of the logical qubits within a code block used to organize operations. "two logical sectors ( and ) with logical qubits"
- magic engine: A module that simultaneously distills and injects magic states to provide a steady high-throughput supply for non-Clifford operations. "we introduce a new component---the magic engine---"
- magic state: A special non-stabilizer state (e.g., |T⟩) consumed to enable non-Clifford gates in fault-tolerant schemes. "a high-fidelity magic state"
- magic state cultivation: A procedure to increase the fidelity of T states using repeated rounds of operations before full distillation. "magic state cultivation"
- magic state distillation: A protocol that boosts the fidelity of noisy magic states by consuming multiple copies and post-selecting on certain measurement outcomes. "magic state distillation to prepare a high-fidelity magic state"
- magic state injection: Implementing a non-Clifford gate by consuming a magic state via a measurement-based circuit. "each gate is replaced by a magic state injection circuit"
- memory port: The measurement-gadget interface through which a processing unit can access a designated subset of memory qubits. "Memory is accessed by processing units via ports."
- memory window: A fixed-size group of memory logical qubits that a port exposes for read-only access. "we partition the logical qubits of the memory into sets of size , which we refer to as windows."
- nearest-neighbour interactions: Hardware couplings restricted to adjacent qubits on a lattice or array. "require only nearest-neighbour interactions."
- Pauli-based computation: A computation model where circuits are executed through sequences of Pauli measurements with magic state resources. "Compilation is performed via Pauli-based computation."
- Pauli product measurement: Measuring a multi-qubit operator that is a tensor product of single-qubit Pauli operators. "An arbitrary logical Pauli product measurement can be performed"
- Pauli rotation: A rotation of the form exp(iθP) about a Pauli operator P, used here with θ=π/8 for non-Clifford gates. "allow for arbitrary Pauli rotations on the processing unit."
- parity check operator: A stabilizer generator whose measurement indicates parity constraints used for error detection. "measuring a set of parity check operators"
- physical qubit: A real hardware qubit (as opposed to an encoded logical qubit) used to build error-correcting codes. "less than one hundred thousand physical qubits"
- QLDPC code (quantum low-density parity-check code): A quantum code with parity checks of bounded weight and bounded qubit degree enabling constant-depth syndrome extraction. "We assume the use of QLDPC codes."
- quasi-local connections: Hardware connectivity allowing interactions over bounded, short distances rather than long-range all-to-all links. "quasi-local connections between physical qubits"
- qubit automorphism: A permutation of qubits that maps the set of parity checks to itself, preserving code structure. "making it a qubit automorphism."
- qubit degree: The number of parity checks in which a given physical qubit participates. "parity check operator weights and qubit degrees"
- qubit-wise commutation: A condition that two multi-qubit operators commute on each qubit individually, ensuring compatible simultaneous measurements. "This qubit-wise commutation condition ensures that the check operators from different gadgets all commute."
- reaction time: The classical-control latency between a measurement and the start of any subsequent adaptively dependent measurement. "Finally, there is the reaction time "
- reaction-limited: A regime where computation speed is constrained by reaction time rather than code cycles; being “not reaction-limited” means reaction latency doesn’t bottleneck operation. "our architecture is not reaction-limited"
- rotated surface code: A variant of the surface code layout that reduces qubit count per distance compared to the unrotated form. "distance- (rotated) surface codes"
- spacetime overhead: The combined resource cost measured in both space (qubits) and time (cycles) for fault-tolerant execution. "with a spacetime overhead significantly smaller than that of any competing architecture."
- syndrome extraction circuit: The circuit that measures all parity checks in a code cycle to obtain the error syndrome. "performing a syndrome extraction circuit"
- T count: The total number of T gates in a circuit, a key metric for resource and time estimates in fault-tolerant compilation. "time cost that scales with the count."
- utility-scale quantum computing: Quantum computing at capacities sufficient to solve practically meaningful, large-scale problems. "The realisation of utility-scale quantum computing"
- processing block: A code block augmented with measurement gadgets (and bridges) that supports logical operations via Pauli measurements. "A processing block allows for logical operations to be implemented on its encoded logical qubits."
- processing unit: A module comprising multiple bridged processing blocks that can perform arbitrary logical Pauli measurements each logical cycle. "The primary modules of the architecture are processing units."
Collections
Sign up for free to add this paper to one or more collections.

