SLA2: Sparse-Linear Attention with Learnable Routing and QAT
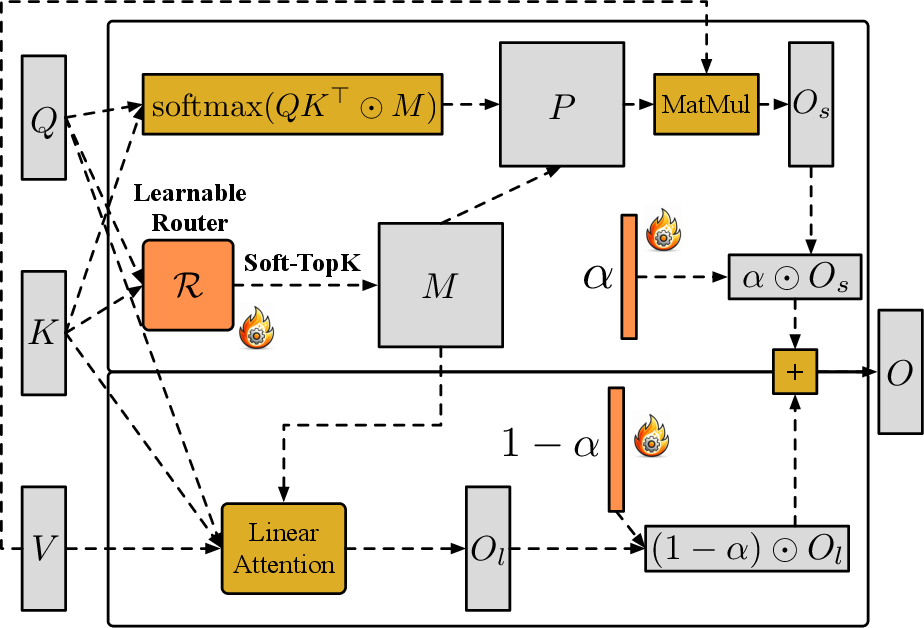
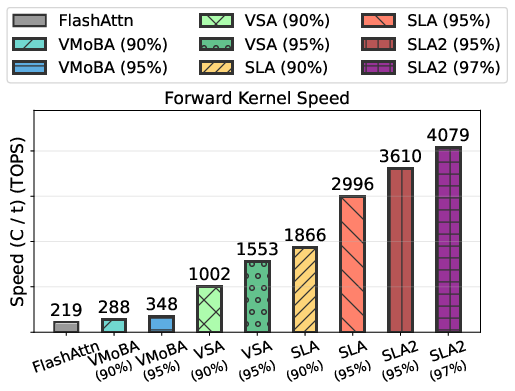
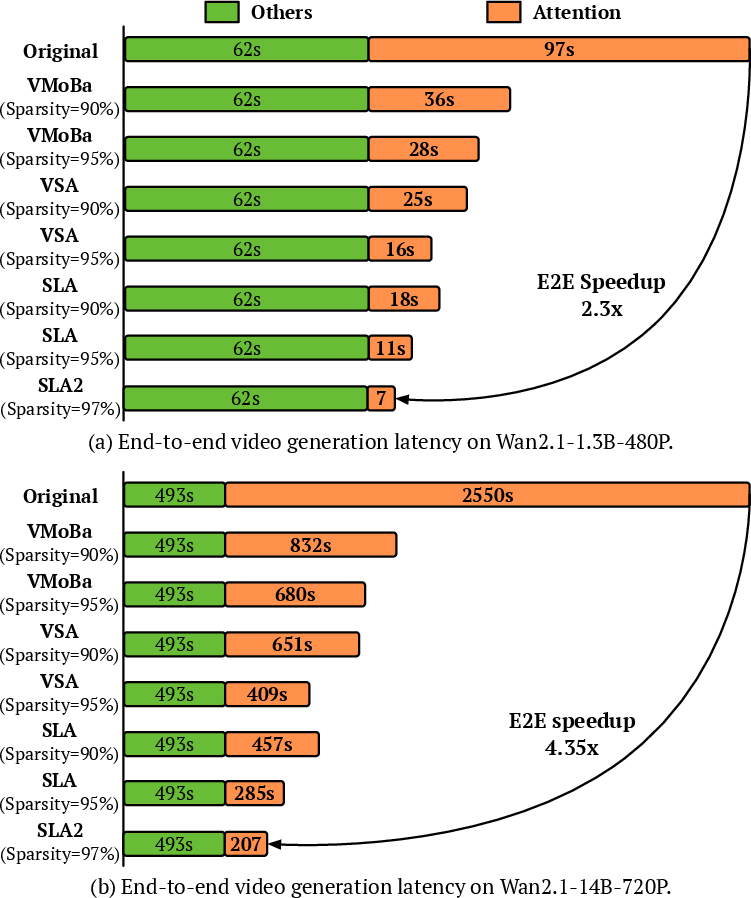
Abstract: Sparse-Linear Attention (SLA) combines sparse and linear attention to accelerate diffusion models and has shown strong performance in video generation. However, (i) SLA relies on a heuristic split that assigns computations to the sparse or linear branch based on attention-weight magnitude, which can be suboptimal. Additionally, (ii) after formally analyzing the attention error in SLA, we identify a mismatch between SLA and a direct decomposition into sparse and linear attention. We propose SLA2, which introduces (I) a learnable router that dynamically selects whether each attention computation should use sparse or linear attention, (II) a more faithful and direct sparse-linear attention formulation that uses a learnable ratio to combine the sparse and linear attention branches, and (III) a sparse + low-bit attention design, where low-bit attention is introduced via quantization-aware fine-tuning to reduce quantization error. Experiments show that on video diffusion models, SLA2 can achieve 97% attention sparsity and deliver an 18.6x attention speedup while preserving generation quality.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper is about making video‑generation AI models faster without hurting their quality. These models often use a tool called “attention,” which is powerful but slow and expensive. The authors introduce a new method, called SLA2, that speeds up attention by smartly combining two faster types of attention and training the model to use them in the best way.
Think of attention like searching a huge library:
- Sparse attention = only checking a few books that seem most relevant.
- Linear attention = using a quick summary tool that’s fast but less detailed. SLA2 teaches the model when to use each one and how to mix them so the final answer is both fast and accurate.
What questions does the paper try to answer?
The paper focuses on three simple questions:
- How can we split the attention work between “check a few important things” (sparse) and “use a fast summary” (linear) in a smarter way?
- How can we combine the results from these two branches so the final answer matches what full (slow) attention would produce?
- Can we make things even faster by using smaller numbers (low‑bit math) without hurting quality, and if so, how should we train for that?
How do they do it? (Explained simply)
Key ideas in everyday terms
- Learnable router: Imagine a traffic controller that decides, for each piece of information, whether it should go to the detailed checker (sparse) or the quick summary (linear). Instead of using a simple rule, the router is trained to make better decisions based on the data.
- Learnable mixing ratio (α): When you combine results from the two branches, you need the right balance. SLA2 adds a learnable “mixing slider” between 0 and 1 for each row of attention. This fixes a hidden scaling problem in older methods and removes the need for extra correction layers.
- Low‑bit attention with QAT: Using smaller numbers (like 8‑bit instead of 16‑bit) makes computation faster, but can cause errors—like rounding prices to whole dollars. Quantization‑aware training (QAT) is like practicing with rounded prices during training so the model learns to handle those small errors at test time.
What does “attention” and “routing” mean here?
- Attention scores decide how much each token (like a time step or patch in a video) should “look at” others. Full attention looks at everything, which is slow.
- Routing chooses which positions are handled by:
- Sparse attention: checks only a few top‑priority positions.
- Linear attention: processes the rest with a faster, approximate method.
- SLA2 trains a small module (the router) to make this choice efficiently by first compressing the inputs in blocks (like grouping nearby frames or patches) so routing is cheap but still smart.
Training approach
The authors use two stages:
- Warm‑up the router and the mixing slider α using data from attention layers so they learn to mimic full attention well. During this stage, they use a “soft” top‑k selector (a smooth, trainable version of “pick the top entries”) so gradients can flow.
- Fine‑tune the whole video model end‑to‑end with the SLA2 attention in place. Here they switch to the “hard” top‑k selection used at test time, so training matches inference behavior.
They also apply QAT so the model learns to be accurate even when using faster, low‑bit math in the attention computations.
What did they find, and why is it important?
- Very high sparsity: SLA2 skips about 97% of attention calculations while keeping accuracy. That means it only does the truly important work most of the time.
- Big speedups: SLA2 delivers about an 18.6× speedup in attention computation on video diffusion models, measured on both medium‑size (1.3B) and large (14B) models.
- Quality preserved or improved: Even with 97% sparsity, SLA2 matches or beats other methods that use much less sparsity (like 90% or 95%) and can even rival or exceed full attention in overall video quality after fine‑tuning.
Why this matters:
- Faster generation: Videos can be produced much more quickly.
- Lower cost: Less compute means cheaper runs and less energy.
- Bigger reach: It becomes more practical to run large or higher‑resolution models.
What is the impact of this research?
SLA2 shows a practical path to make heavy video models both fast and good:
- Smarter computation: A learned router and a learned mixing ratio help the model spend time only where it matters.
- Hardware‑friendly: Low‑bit attention with QAT makes it even faster on real GPUs.
- Scalable: The method works on both mid‑size and very large video diffusion models, suggesting it can benefit many future systems.
In short, SLA2 turns attention from a bottleneck into a flexible, optimized component—helping video AI run faster without sacrificing quality. This can enable smoother workflows for creators, researchers, and apps that need real‑time or high‑resolution video generation.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues, uncertainties, and unexplored directions left by the paper that future researchers could address.
- Router training vs inference inconsistency: Stage 2 is described as fine-tuning “without R,” yet inference uses a hard Top-k router; it is unclear whether the router is frozen, discarded, or partially used during end-to-end fine-tuning. Clarify the training-time role and update status of the router and quantify the impact of this mismatch on final quality and stability.
- α mixing ratio granularity and dynamics: The paper alternates between α being per-row () and per-block (). Specify whether α is per-head, per-layer, per-token, or per-block, and whether it is dynamic (input-dependent) or static after training. Evaluate how α’s granularity and dynamism affect accuracy and speed.
- Relation of learned α to true masked probability mass: The formulation suggests α should equal the row-sum of masked probabilities (), but SLA2 learns α instead of computing it. Test whether learned α recovers this quantity and whether derivation or calibration of α from the mask at inference further reduces error.
- Missing backward kernel details: The text references Algorithm bwd for backward but does not provide it. Release or document the backward kernel and gradient paths (especially through SoftTop-k and low-bit ops) to enable reproducibility and independent verification.
- Router objective optimality: The router is trained via MSE against full-attention outputs. Investigate alternative objectives that explicitly promote a low-rank residual (e.g., spectral norm, nuclear norm, or rank-aware losses), or directly minimize a decomposition error bound for .
- Theoretical error guarantees: Provide conditions and bounds under which the approximation closely matches full attention, including how mask selection and α estimation interact with the low-rank structure of .
- Activation/kernel choice for linear attention: SLA2 sets to softmax but does not compare with other kernels (e.g., elu+1, ReLU-based kernels, gated kernels). Study sensitivity to and whether different kernels improve quality or stability, especially at very high sparsity.
- Quantization scope and specification: The bit format(s), granularity (per-tensor/per-block/per-thread), rounding, and scaling rules are not fully specified. Report detailed quantization settings (INT8/FP8/FP4, scales) and assess their impact on accuracy and speed across heads, layers, and branches.
- QAT methodology completeness: Forward uses low-bit attention while backward is entirely FP16 without straight-through estimators or gradient-through-quantization. Evaluate whether using fake quantization in backward or STE improves adaptation and final low-bit accuracy.
- Quantization limited to sparse branch: Only the sparse branch () appears quantized. Explore quantizing the linear branch (), router computations, and KᵀV accumulation to unlock additional speedups and measure the accuracy trade-offs.
- Memory footprint and bandwidth: The work reports FLOPs and latency but omits VRAM usage and memory bandwidth profiling (especially with low-bit quantization and mask routing). Provide memory analyses across models and GPUs to guide deployment.
- Hardware generalization: Results are on RTX5090 with offloading for 14B. Evaluate across diverse accelerators (A100/H100, consumer GPUs, Apple M-series, NPUs) to quantify portability of speedups and identify hardware-specific bottlenecks.
- Per-layer/per-head sparsity schedules: SLA2 uses fixed k% values. Investigate adaptive per-layer/per-head sparsity schedules (or learned schedules) and their impact on quality and speed, especially across timesteps in diffusion.
- Router overhead and scalability: Measure the router’s compute/latency overhead (pooling, projections, Top-k/SoftTop-k) and its scaling with sequence length. Provide a breakdown of where SLA2 gains or loses time relative to baselines.
- Block-size sensitivity: b_q=128 and b_kv=64 are fixed. Perform sensitivity analyses over block sizes to understand the trade-offs between routing fidelity, kernel efficiency, and video quality.
- Mask “skip” design: SLA earlier allowed skipping a portion (k_l%) while SLA2 routes all non-masked entries to linear attention. Explore whether reintroducing a skip region (explicit zeros) yields further speed or quality gains.
- Applicability beyond video diffusion: SLA2 is evaluated only on Wan2.1 T2V models. Test on image diffusion transformers (e.g., SDXL, SVD), multimodal diffusion, and non-diffusion transformers (LLMs, ViTs) to assess generality.
- Attention type coverage: Clarify whether SLA2 replaces both self-attention and cross-attention, and evaluate differential effects. Cross-attention may have different sparsity/low-rank properties that inform router design.
- Robustness across prompts, lengths, and timesteps: The dataset (3k videos with auto captions) is limited, and variability across prompts, video lengths, and diffusion timesteps is not analyzed. Conduct broader, controlled studies to assess robustness.
- Evaluation rigor: Quality is measured via automated metrics (VBench, VisionReward) on a small private dataset; there is no human evaluation, uncertainty estimates, or statistical significance testing. Add human studies and report variance/confidence intervals.
- End-to-end bottleneck analysis: Provide a detailed latency breakdown (attention vs non-attention components) to show where end-to-end gains arise and identify remaining bottlenecks in the generation pipeline.
- Numerical stability analysis: The mixture formulation enforces row normalization, but stability under low-bit quantization and extreme sparsity is not analyzed. Characterize failure modes (overflow/underflow, softmax saturation) and mitigation strategies.
- Parameter overhead and training cost: SLA2 adds router projections and α parameters. Quantify parameter increase, training time/memory overhead, and convergence behavior compared to baselines.
- Rank characterization of the residual: Empirically measure the rank (or effective rank) of across layers/timesteps to validate the low-rank assumption and guide router thresholds.
- Generalization of stage-wise training: Two-stage training uses SoftTop-k then hard Top-k. Study whether single-stage training with straight-through Top-k (or alternative differentiable selections) can match or exceed SLA2’s results and simplify the pipeline.
- Mask reliability across distribution shifts: Assess how the learned router behaves under distribution shifts (new datasets, resolutions, camera motions) and whether fallback heuristics or uncertainty-aware routing are needed.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage SLA2’s learnable routing, decomposition-consistent sparse+linear mixing, and quantization-aware low-bit attention to accelerate diffusion models while maintaining quality.
- Cloud video generation serving and cost reduction
- Sectors: software, media/entertainment, advertising, gaming
- What: Replace full attention in production text-to-video pipelines with SLA2 to cut attention FLOPs by ~96.7% and achieve up to ~18.6× kernel speedups while preserving or improving visual quality.
- Tools/workflows:
- Drop-in SLA2 attention module (FlashAttention-style kernel) in inference stacks (e.g., custom CUDA/Triton kernel integrated with PyTorch).
- Two-stage fine-tuning: (1) pretrain the router and α with SoftTop‑k on cached Q/K/V; (2) end-to-end fine-tune with hard Top‑k.
- Quantization-aware fine-tuning (QAT) for low-bit forward pass in sparse attention (INT8/FP8) with FP16 backward.
- Assumptions/dependencies: Availability of SLA2 kernels (FlashAttention-style), representative fine-tuning data, access to GPU hardware supporting mixed-precision, and alignment with deployment model architectures (e.g., Wan 1.3B/14B-like DiTs).
- Faster batch content generation for marketing and design studios
- Sectors: media/entertainment, advertising, design
- What: Use SLA2 at 90–97% sparsity to increase throughput for generating multiple variants (A/B concepts, storyboards) with near full-attention quality.
- Tools/workflows: Batch scheduler that sets per-job sparsity (k%) and toggles QAT, with SLA2 metrics to auto-tune k%.
- Assumptions/dependencies: Fine-tuned router/α must generalize to target prompts and style; speedups depend on prompt length and resolution.
- Accelerated diffusion-based video editing and effects
- Sectors: creative software, VFX, post-production
- What: Integrate SLA2 into diffusion-based editing (e.g., inpainting, style transfer, motion retargeting) to shorten preview and render times.
- Tools/workflows: SLA2 plugin for diffusion-based editors; workflow maintains editing fidelity by moderating sparsity (e.g., 90–95%, tuned per task).
- Assumptions/dependencies: Editing operations preserve attention structure similar to training distribution; minor parameter re-tuning may be needed.
- Low-latency previews in interactive tools
- Sectors: product design, animation, UX/UXR
- What: Provide near-real-time previews for short clips or low-res drafts with SLA2 (especially on 1.3B-class models at 480p).
- Tools/workflows: UI toggle for “fast preview” mode using higher sparsity and QAT; “final render” can use lower sparsity for maximal quality.
- Assumptions/dependencies: Hardware with sufficient GPU memory; preview targets short durations/resolutions to hit interactive budgets.
- Energy and carbon footprint reduction for generative services
- Sectors: energy, sustainability, cloud operations
- What: Reduce compute energy by cutting FLOPs and kernel time, enabling greener video generation at scale.
- Tools/workflows: Integrate SLA2 into MLOps metrics dashboards; report per-request energy savings and set eco-efficiency SLAs.
- Assumptions/dependencies: Energy usage is roughly proportional to FLOPs/time on target hardware; organizational willingness to track and report.
- Research prototyping for efficient attention and routing
- Sectors: academia, industrial research
- What: Use SLA2 as a testbed to study sparse/linear decompositions, differentiable routing (SoftTop‑k), and QAT for attention.
- Tools/workflows:
- Ablation via router inputs (Q/K pooling size, projections), different activations for linear attention, and varying α parameterizations.
- Benchmarks for kernel throughput and end-to-end quality (VBench, VR).
- Assumptions/dependencies: Access to reference datasets and baselines; reproducible implementation of SoftTop‑k and FP16-only backward.
- Edge/on-device diffusion prototyping (workstations and high-end laptops)
- Sectors: software, creator tools, AR/VR prototyping
- What: Combine 1.3B-class models with SLA2 and QAT to enable shorter generation times on a single high-end GPU for demos/POCs.
- Tools/workflows: Condense pipeline (lower resolution/frames), use high sparsity + low-bit forward pass, keep FP16 backward only when fine-tuning locally.
- Assumptions/dependencies: Adequate GPU memory; acceptance of trade-offs in duration/resolution for edge feasibility.
- Accelerated training-fine-tuning loops for diffusion applications
- Sectors: software, research
- What: Use SLA2 to speed up fine-tuning or task adaptation (e.g., domain-specific video generation) by reducing attention cost in each training step.
- Tools/workflows: Insert SLA2 modules during fine-tuning; Stage 1 train router/α with reconstruction loss on Q/K/V, then end-to-end optimize diffusion loss.
- Assumptions/dependencies: Stability of sparse+linear mix during optimization; careful selection of k% to avoid optimization drift.
- Infrastructure integration and deployment tooling
- Sectors: software infrastructure
- What: Package SLA2 as a reusable attention primitive for PyTorch + Hugging Face Diffusers; provide ONNX/TensorRT plugins where viable.
- Tools/workflows:
- Operator registration for SLA2 with block-wise FlashAttention kernels.
- Configurable router pooling sizes (b_q, b_k), k%, and α export for inference.
- Assumptions/dependencies: Kernel portability across CUDA versions; testing on major GPU SKUs.
- Education and low-cost content creation
- Sectors: education, consumer apps
- What: Offer faster, cheaper AI-generated educational videos, explainers, and micro-lessons using SLA2-enabled backends.
- Tools/workflows: SLA2-backed generation endpoints with cost-based routing (e.g., higher sparsity for free tier, lower for premium).
- Assumptions/dependencies: Content policies; predictable quality under high sparsity.
Long-Term Applications
These applications require additional research, scaling, productization, or ecosystem support beyond the paper’s scope.
- General-purpose attention acceleration beyond diffusion (LLMs, multimodal transformers)
- Sectors: software, NLP, multimodal AI
- What: Adapt SLA2’s learnable router + α-mixing (sparse + linear) to language and multimodal models for inference/training speedups.
- Tools/products: “SLA2-Attn” backends in LLM serving (e.g., vLLM-like systems), multimodal video-text models, and vision-language systems.
- Assumptions/dependencies: Sparse+low-rank decomposition must hold in new domains; router generalization; retraining cost and quality assurance.
- Real-time or near-real-time on-device video generation and effects
- Sectors: AR/VR, mobile, creative apps, social media
- What: Deliver interactive video effects and short clip generation on edge devices by pairing SLA2 with model distillation, further quantization, and hardware co-optimization.
- Tools/products: Mobile SDKs with SLA2 kernels, power-aware routing (dynamic k%), and model variants tailored for SoCs/NPUs.
- Assumptions/dependencies: Significant model-size reductions; specialized kernels/accelerators; thermal/power constraints.
- Hardware-software co-design for sparse+linear+QAT attention
- Sectors: semiconductors, systems
- What: Incorporate SLA2’s pattern into compiler graphs and accelerators (e.g., dedicated blocks for masked sparse matmuls and low-bit accumulations).
- Tools/products: ISA or runtime primitives for Top‑k routing, pooled Q/K projections, sparse block-scheduling, and INT8/FP8 attention units.
- Assumptions/dependencies: Vendor support, standardized operator definitions, robust calibration tools.
- Training-time SLA2 for large-scale pretraining of video models
- Sectors: research, foundation models
- What: Use SLA2 during pretraining to reduce cost/energy while maintaining quality, possibly with curriculum on k% and α schedules.
- Tools/workflows: Curriculum sparsity increases; self-supervised router/α objectives to maintain decomposition fidelity; co-optimization of loss and router.
- Assumptions/dependencies: Convergence stability under high sparsity; mitigation of distribution shift from pretrain to downstream tasks.
- Diffusion-based video editing and translation at consumer scale
- Sectors: creative software, consumer apps
- What: Scale SLA2-accelerated editing (e.g., instruction-driven edits, style transfer) to mobile/desktop with low-latency, high-fidelity pipelines.
- Tools/products: Consumer-facing editors with SLA2-as-default attention primitive; adaptive quality modes.
- Assumptions/dependencies: UX acceptance, content safety filters, incremental finetuning per domain.
- Generative world models for robotics and simulation
- Sectors: robotics, simulation, autonomous systems
- What: Employ SLA2 to make video world-models more computationally feasible for on-board or low-latency simulation loops.
- Tools/workflows: Pipeline combining SLA2-accelerated video generation with planning modules; adaptive routing based on context complexity.
- Assumptions/dependencies: Task-specific fine-tuning; robustness guarantees; safety validation.
- Standardization of efficient-attention primitives in ML frameworks
- Sectors: software infrastructure, standards
- What: Define SLA2-like operators (router, SoftTop‑k/Top‑k, α-combine) as first-class primitives in PyTorch/JAX/ONNX.
- Tools/products: Stable APIs, graph-level optimizations, exportable configs for deployment (e.g., ONNX/TensorRT plugins).
- Assumptions/dependencies: Community consensus, cross-hardware reproducibility.
- Policy and sustainability frameworks for generative AI efficiency
- Sectors: policy, sustainability, cloud
- What: Inform green AI policies using methods like SLA2 that deliver large computational and latency savings without quality loss.
- Tools/workflows: Emissions reporting tied to attention efficiency; procurement guidelines favoring efficient attention kernels.
- Assumptions/dependencies: Transparent measurement; alignment with regulatory and industry standards.
- Privacy-preserving and federated content creation
- Sectors: privacy, edge computing
- What: Combine SLA2 with compressed models to enable on-device generation, reducing the need to upload user data.
- Tools/products: Federated fine-tuning workflows where router/α adapt locally; privacy-preserving analytics for quality monitoring.
- Assumptions/dependencies: Local compute capability; privacy compliance; secure model update mechanisms.
Notes on Feasibility and Dependencies (Cross-Cutting)
- SLA2’s benefits hinge on:
- The attention map decomposing into sparse and low-rank components for the target task.
- Proper training of the learnable router (SoftTop‑k for Stage 1) and α; inference must switch to hard Top‑k.
- Hardware support for mixed precision and efficient sparse/low-bit kernels (FlashAttention-style).
- Sensible selection of pooling/block sizes (b_q, b_k) and sparsity (k%) per use case.
- Quality/latency trade-offs are tunable via k%; high sparsity may require careful fine-tuning and QA.
- Domain shifts (e.g., moving from curated datasets to user prompts) can necessitate re-training or adaptive routing strategies.
Glossary
- Ablation study: A controlled analysis that removes or modifies components to assess their contribution to a system’s performance. "Ablation Study"
- Attention sparsity: The fraction of attention matrix entries skipped or zeroed, reducing computation by focusing on a small subset of interactions. "SLA2 achieves attention sparsity and an attention runtime speedup on both Wan2.1-1.3B and Wan2.1-14B."
- Block-wise FlashAttention-style algorithm: An efficiency-focused attention computation that tiles the sequence into blocks and fuses operations to minimize memory movement. "we implement the method efficiently on top of a block-wise FlashAttention-style algorithm."
- Diffusion models: Generative models that iteratively denoise samples to produce images or videos from noise. "Trainable sparse attention methods... have shown strong performance in diffusion models."
- FlashAttention: A GPU-optimized exact attention algorithm that is IO-aware and reduces memory bandwidth via tiling and fusion. "For , built on top of the FlashAttention Algorithm, we only perform the matmuls and for the positions where "
- FlashAttn2: A faster, improved version of FlashAttention with better parallelism and partitioning. "Full Attention (without training) implemented with FlashAttn2."
- FLOPs: A measure of computational cost counting floating-point operations. "To quantify computational cost, we use {FLOPs} (floating-point operations)."
- GPU kernel: A specialized function executed on the GPU to implement key computations (e.g., attention) efficiently. "Note that the equations above describe the mathematical computation rather than the GPU kernel implementation."
- Learnable router: A trainable module that selects which attention entries use sparse vs. linear processing via a mask. "which introduces (I) a learnable router that dynamically selects whether each attention computation should use sparse or linear attention"
- Linear attention: An attention variant that factorizes computations to achieve linear complexity in sequence length. "For the remaining entries ($1-M$), SLA applies linear attention:"
- Low-bit attention: Attention computed in reduced numerical precision (e.g., INT8/FP8) to speed up inference with minimal accuracy loss. "a sparse + low-bit attention design, where low-bit attention is introduced via quantization-aware fine-tuning to reduce quantization error."
- Low-rank: A matrix property indicating that data can be approximated by a small number of basis vectors, reducing complexity. "the attention map could be decomposed into a high-sparse part and a low-rank part "
- Mask predictor: A trainable component that predicts which attention positions are handled by the sparse branch. "a learnable sparse-attention mask predictor that supports gradient backpropagation."
- Mixture-of-Block Attention (VMoBA): A sparse attention scheme that mixes block-level patterns to accelerate video diffusion models. "VMoBA: Mixture-of-Block Attention for Video Diffusion Models"
- Post-training quantization (PTQ): Quantization performed after training, without modifying training to account for quantization effects. "Post-training quantization (PTQ) applies quantization after a model is fully trained."
- Quantization-aware training (QAT): Training that simulates quantization during forward passes so the model adapts to low-precision arithmetic. "quantization-aware training (QAT) incorporates quantization effects during training, allowing the model to adapt its parameters to the quantization error"
- Reparameterization trick: A gradient technique that enables backpropagation through stochastic or non-differentiable operations via reparameterization. "The gradient of SoftTop-k is computed using the reparameterization trick"
- SoftTop-k: A differentiable relaxation of Top-k selection that preserves row-wise mass while allowing gradient flow. "we replace the Top-k operator in Equation~\ref{equ:mask_of_sla2} with a SoftTop-k operator"
- Sparse-Linear Attention (SLA): A method that combines sparse softmax and linear attention branches to match decomposed attention components. "Sparse-Linear Attention (SLA) combines sparse and linear attention to accelerate diffusion models"
- Sparse softmax attention: Standard attention applied only to selected entries, re-normalized over the masked subset. "SLA (Sparse-Linear Attention) combines sparse softmax attention and linear attention using a heuristic sparse attention mask."
- TOPS: Trillion operations per second; a hardware throughput metric for kernels. "measured in TOPS (trillion operations per second)."
- VBench: A benchmark suite for evaluating video generation quality across multiple dimensions. "we evaluate video quality using multiple dimensions from VBench"
- Vision Reward (VR): A learned metric reflecting human preference in visual generation tasks. "In addition, we assess human preference using the Vision Reward metric ({VR})"
Collections
Sign up for free to add this paper to one or more collections.