SignScene: Visual Sign Grounding for Mapless Navigation
Abstract: Navigational signs enable humans to navigate unfamiliar environments without maps. This work studies how robots can similarly exploit signs for mapless navigation in the open world. A central challenge lies in interpreting signs: real-world signs are diverse and complex, and their abstract semantic contents need to be grounded in the local 3D scene. We formalize this as sign grounding, the problem of mapping semantic instructions on signs to corresponding scene elements and navigational actions. Recent Vision-LLMs (VLMs) offer the semantic common-sense and reasoning capabilities required for this task, but are sensitive to how spatial information is represented. We propose SignScene, a sign-centric spatial-semantic representation that captures navigation-relevant scene elements and sign information, and presents them to VLMs in a form conducive to effective reasoning. We evaluate our grounding approach on a dataset of 114 queries collected across nine diverse environment types, achieving 88% grounding accuracy and significantly outperforming baselines. Finally, we demonstrate that it enables real-world mapless navigation on a Spot robot using only signs.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching robots to find their way in places like malls, hospitals, train stations, and campuses by using the same signs people use. Instead of relying on a big pre-made map, the robot reads a nearby sign, looks around, and figures out which path to take. The system is called SignScene. It helps a robot “understand” the symbols and words on a sign, link that meaning to real things in the scene (like corridors, stairs, or escalators), and then choose a concrete direction to move.
What questions did the researchers ask?
They focused on four simple questions:
- How can a robot read and understand real navigational signs, including text and icons?
- How can it match what the sign says (like “take the stairs to B4” or “turn right to the library”) to actual paths and objects in the scene?
- What kind of simple map helps an AI reason well about space and directions?
- Does this approach work in many different places, and can a real robot navigate using only signs?
How did they do it?
They built a step-by-step system. Here are the main parts, explained with everyday language:
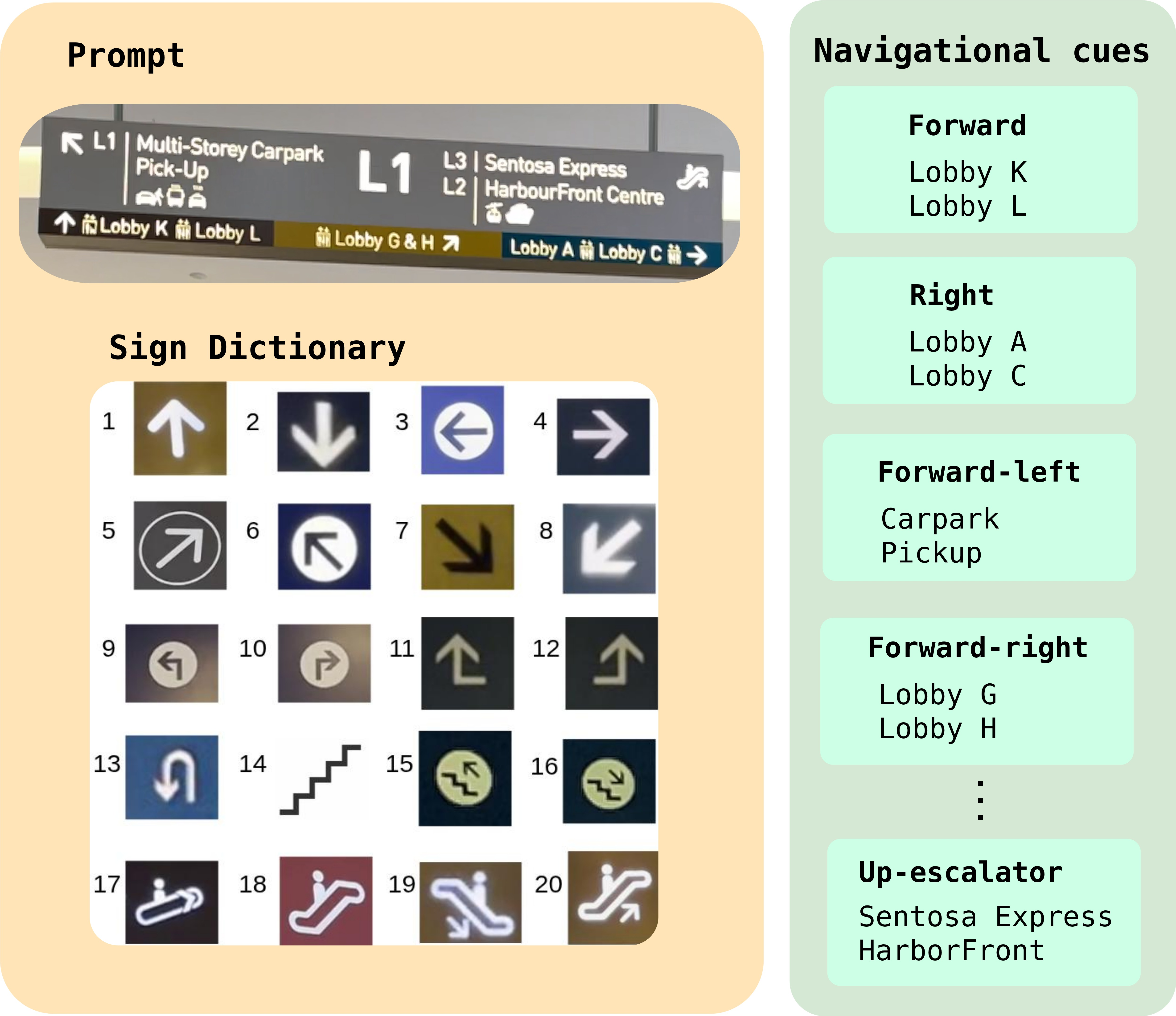
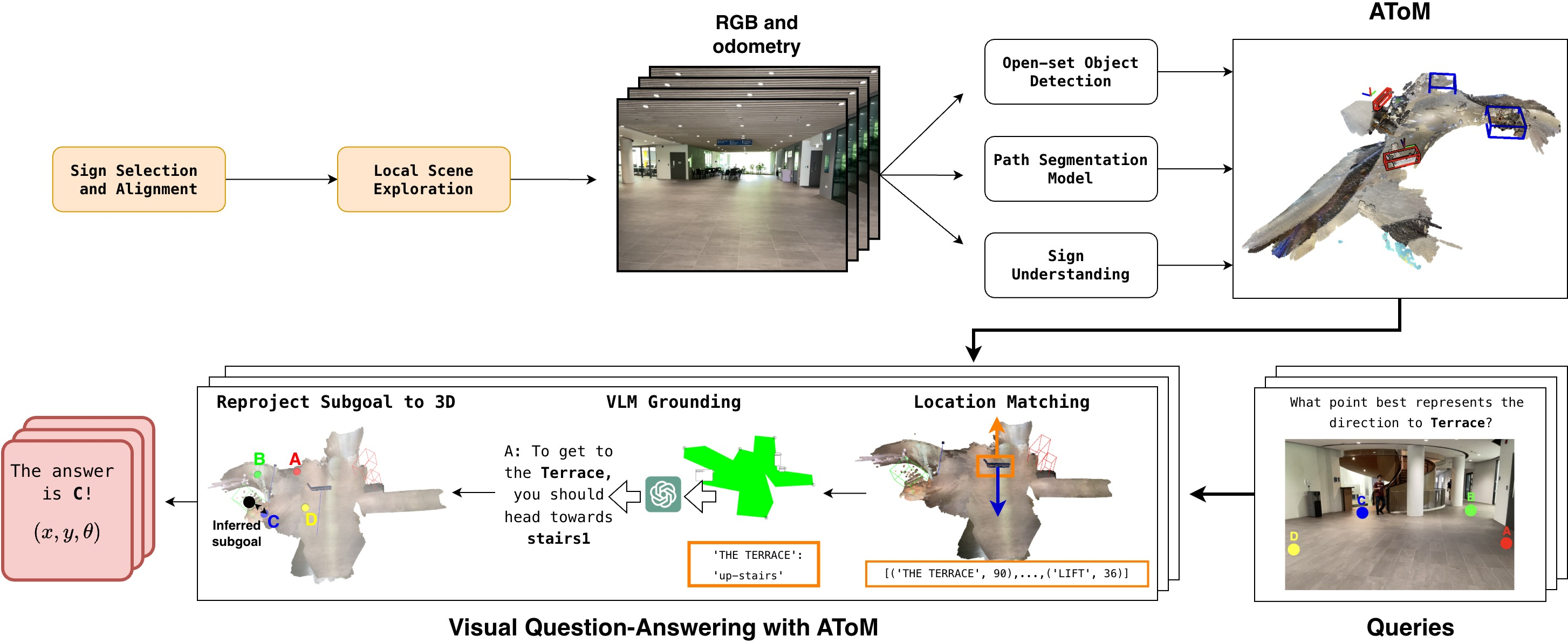
1) Understanding signs
The robot uses an AI that can “see and read” (a vision-LLM, or VLM). This AI looks at a picture of a sign and finds pairs like “Location: Direction.” Examples:
- “Library: left arrow”
- “Medical Centre (Exit C): ←”
- “B4: take the down escalator”
To make the AI better at recognizing different icons and layouts, the team gave it a small “dictionary” of example sign symbols in the prompt. This is like reminding someone: “Here are common sign pictures and what they mean.”
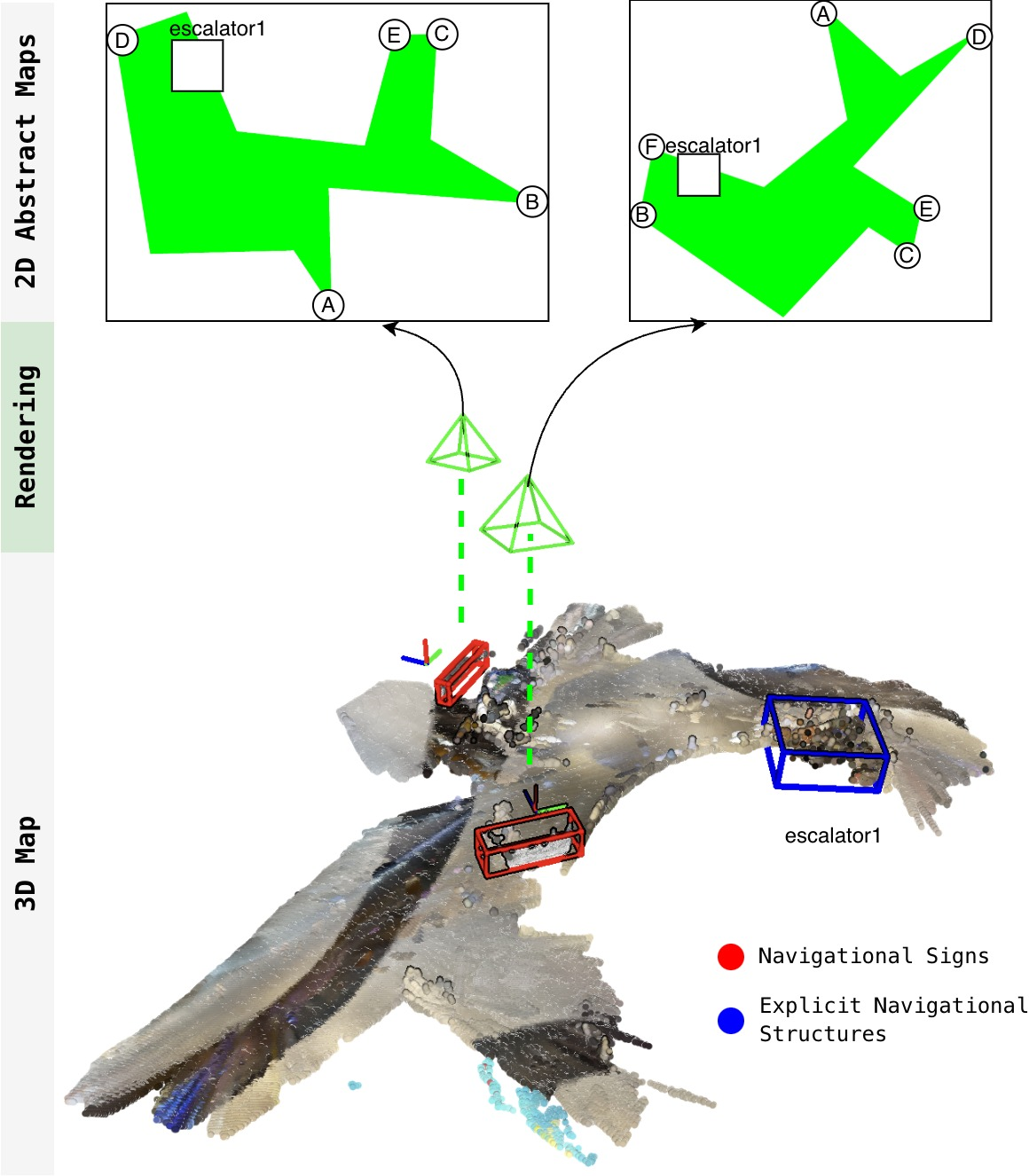
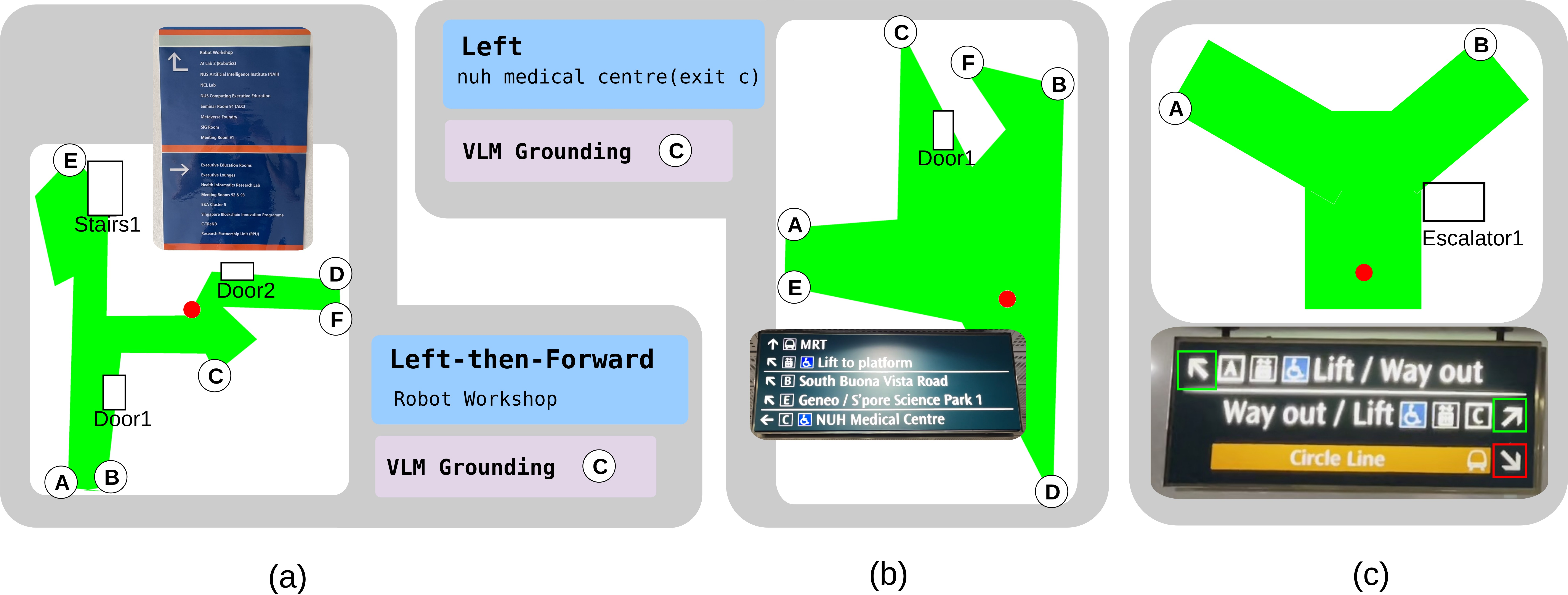
2) Building a simple, sign-centered map
Real scenes are 3D and messy, but the AI thinks better with clean, simple pictures. So the robot creates a very basic top-down sketch centered on the sign, where “up” on the sketch means “facing the sign.” Think of it like drawing a mini floor plan around the sign.
To make this sketch, the robot:
- Uses its camera and a depth estimator to figure out distances. Depth is like knowing how far things are, not just what they look like.
- Detects important navigational structures, such as stairs and escalators, with an object detector.
- Finds walkable paths (corridors, sidewalks, trails) using a “path segmentation” model that colors pixels that belong to paths the robot should prefer. This is like highlighting the ground area people usually walk on.
- Marks likely entrances to different paths along the boundary of the walkable area with simple labeled points (A, B, C, …).
- Draws boxes for objects like “stairs” with clear labels.
This sketch is kept minimal on purpose—no clutter—so the AI can focus on the directions.
3) Exploring nearby (when needed)
From straight in front of the sign, the robot can’t always see everything. So it:
- Spins in place to look around.
- Visits likely path entrances (those bumps or “protrusions” on the ground area) to gather more information. This helps the robot fill out the simple map so the AI can make a good choice.
4) Reasoning to pick a path
Now the AI gets:
- The target location from the sign (for example, “TERRACE”).
- The instruction attached to that location (like “take the stairs” or “go left”).
- The simple top-down map image centered on the sign.
It then chooses the path entrance or the specific structure (like a stairway) that best matches the instruction for the target. The robot converts that choice into a real position to move toward—like a waypoint it can navigate to next.
What did they find, and why is it important?
The team tested SignScene in 9 kinds of places (hospitals, malls, campus buildings, train stations, airport, and outdoors), with 114 grounding questions like “Which option matches the direction to the library?” The system:
- Got the right answer about 88% of the time, which was much better than a recent baseline system.
- Worked across many different environments and sign styles, not just simple “up/down/left/right” cases.
- Ran on a real robot (Boston Dynamics Spot). The robot started outside a building with no map, found relevant signs, explored a bit, built the simple sketch, and correctly chose to take the stairs to reach “TERRACE.”
Why this matters:
- Robots can navigate unfamiliar places without expensive mapping ahead of time.
- Signs are everywhere in human spaces; learning to use them makes robots more practical and safer for the real world.
- A clean, sign-centered sketch helps the AI reason about directions much better than cluttered 3D data.
Implications and potential impact
This approach could make service robots, delivery robots, and assistive robots more flexible:
- They could enter new buildings and find destinations by following signs, like people do.
- It reduces the need for detailed maps or heavy sensors.
- It’s a step toward robots understanding “human-centric” directions, not just pure geometry.
There are still challenges:
- Reading complex, multi-step signs (like “go straight, then take the down escalator to B4”) can confuse the AI.
- Detecting certain objects (like escalators) isn’t perfect yet.
- Reasoning can be slow and sometimes makes mistakes. But overall, SignScene shows a promising, human-like way for robots to navigate using the signs already designed for us.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concise list of what remains missing, uncertain, or unexplored in the paper, phrased to guide actionable future work.
- Limited benchmark scale and diversity: only 36 sequences and 114 queries across nine sites; lacks statistical power, rare corner cases (e.g., multi-floor hub signage, airports with complex wayfinding, construction detours), and systematic coverage of sign conventions.
- Multiple-choice evaluation may overestimate grounding performance: success is defined among four annotated options; open-world, free-form grounding and continuous subgoal selection remain unevaluated.
- Generalization across languages and sign conventions: parsing is demonstrated primarily with English and a small in-context symbol set; robustness to multilingual text, non-Latin scripts, regional iconography, and mixed-language signs is untested.
- Compound, multi-step, and hierarchical instructions: current VLM parsing struggles with compositions (e.g., “forward then down escalator to B4”) and vertical transitions; no formal representation or parsing strategy for ordered action sequences and level changes.
- Ambiguity and disambiguation across multiple signs: when several signs reference the same goal with differing instructions or outdated info, there is no mechanism for conflict resolution, temporal consistency, or trust calibration.
- Uncertainty modeling and propagation: the system lacks probabilistic fusion of detection, parsing, depth, and VLM reasoning uncertainties; no confidence-aware decision-making or fallback behaviors.
- Heuristic frontier/path proposal: discrete path candidates are extracted via convex protrusion heuristics on a polygonal ground mask; failure modes in non-convex junctions, plazas, roundabouts, or cluttered indoor hubs remain unaddressed.
- Dependence on monocular depth for 3D geometry: accuracy and scale consistency of Metric3Dv2 in large indoor halls, glass/reflective surfaces, and outdoors are not quantified; no comparison to stereo/LiDAR or sensor fusion.
- Open-set detection precision/recall limitations: GroundingDINO misses or hallucinated escalators/stairs impact grounding; no detector adaptation, domain-specific finetuning, or uncertainty-aware filtering is explored.
- VLM sensitivity to prompt and visual artifacts: the representation performs worse when adding seemingly informative cues (e.g., a “red dot”); the causal factors and robust prompt/representation co-design are not systematically studied.
- Choice and training of the VLM: reliance on closed, general-purpose VLMs (GPT-5, Gemini-2.5) with hand-crafted prompts; no fine-tuning on sign-grounding tasks, chain-of-thought supervision, spatial reasoning adapters, or top-down-map pretraining is explored.
- Latency and on-board deployment: grounding queries take ~20s and parsing ~3s with off-board compute; real-time constraints, network dependence, and strategies for caching, batching, or on-device distillation remain unresolved.
- Partial observability and active perception: exploration policy is heuristic; no POMDP/active information-gain formulation, view-planning under uncertainty, or learning-based exploration optimized for sign grounding.
- Robustness in highly dynamic or crowded scenes: incomplete traversability/path masks in cluttered or dynamic environments degrade grounding; no temporal filtering of traversability, motion segmentation, or crowd-aware planning.
- Vertical navigation and 3D topology: while escalators/stairs are detected, the representation and reasoning largely operate in 2D; consistent handling of multi-level connectivity, elevation changes, and floor transitions is not formalized.
- Failure recovery and backtracking: when a chosen path is incorrect (due to parsing or reasoning error), there is no robust mechanism for detection, rollback, and re-interpretation using new evidence.
- Sign selection and alignment assumptions: success hinges on reliable sign alignment (thresholds , ); failure modes under large initial pose errors, oblique views, or partial occlusion are not quantified or mitigated.
- Handling non-directional sign types: maps, network diagrams, and complex wayfinding boards (with legends, indexes, “you are here” markers) are not supported; extending parsing to these richer artifacts is unexplored.
- Semantic drift in location matching: fuzzy string matching (Levenshtein) may conflate similarly named locations (e.g., “Exit C” vs “Clinic C”); no semantic matching with ontology or geospatial context.
- Path semantics beyond traversability: reliance on GeNIE’s path masks risks misclassifying textured floors or outdoor terrain; assessing and improving alignment between human-preferred paths and model segmentation remains open.
- Multi-step long-horizon navigation: demonstration shows local decisions; planning across chains of signs, maintaining long-term memory of visited signs, and integrating subgoal sequences into a coherent route are not evaluated.
- Adversarial or misleading signage: no strategy for detecting outdated/temporary signs, contradictory arrows, or vandalized boards; trust models and cross-checks with scene semantics are absent.
- Safety and social compliance: the system does not consider accessibility constraints (e.g., avoiding stairs when needed), no-go zones, or human-robot interaction norms while following sign-derived routes.
- Dataset and annotation transparency: hand-held data vs. on-robot data differences, annotation criteria for “correct” grounding, and reproducibility resources (code, prompts, symbol dictionaries) are not detailed.
- Cross-robot and sensor robustness: results on Spot (RGB, arm camera) only; portability to wheeled platforms, fisheye cameras, different heights/FOVs, and low-light/nighttime conditions remains untested.
- Energy and compute budgets: exploration and multiple VLM calls may be costly; no analysis of time/energy trade-offs, anytime algorithms, or budget-aware reasoning strategies.
- Ablation beyond rotation: representation design choices (e.g., level of abstraction, inclusion of the sign icon, alternative encodings like graph overlays) are not systematically compared.
- Evaluation beyond accuracy: no metrics for calibration, confidence, time-to-decision, navigation success over multi-step tasks, or human interpretability of the decisions are provided.
- Security and privacy: reliance on cloud VLMs for vision-language queries raises data privacy and operational risks; on-device alternatives and safeguards are not addressed.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging the SignScene pipeline (sign detection, sign alignment, sign parsing with VLMs, Abstract Top-view Map rendering, spatial reasoning, and subgoal navigation), as demonstrated on a Spot robot and validated across nine real-world environment types.
- Healthcare (hospitals, clinics)
- Robots perform last-50-meter wayfinding for medication delivery, specimen transport, linens, and equipment retrieval using existing navigational signage.
- Potential tools/products/workflows: ROS2 “SignScene Nav” plugin; sign-centric exploration planner; signage audit kit to test robot-readability of hospital signs; prompt templates and symbol dictionaries tuned for medical environments.
- Assumptions/dependencies: Consistent, visible signage with explicit direction semantics; RGB cameras and odometry; access to VLMs (on-device or secure cloud); acceptable parsing/grounding latency (≈3–20s per query); safe operations in moderately crowded spaces.
- Retail and malls (service, cleaning, inventory robots)
- Mapless navigation to restrooms, exits, loading bays, staff rooms, and pop-up areas that change frequently without updating global maps.
- Potential tools/products/workflows: Top-view map builder integrated with existing navigation stacks; mall-specific sign dictionary; cloud VLM gateway with caching; signage readability dashboard for facility managers.
- Assumptions/dependencies: Clear arrows/icons and location text on signs; tolerable VLM query costs and latency; lighting and occlusion conditions suitable for open-set detection and path segmentation.
- Airports and transit hubs (mobile assistance, patrol, logistics)
- Wayfinding for mobile kiosks or patrol robots to gates, check-in counters, baggage areas, and platform exits using human-oriented signage.
- Potential tools/products/workflows: “SignScene for Transit” SDK; overhead sign alignment using robotic arms/cameras; multi-sign selection strategy for multi-goal tasks.
- Assumptions/dependencies: Security-compliant camera use; robust detection of escalators/stairs; multi-language signs supported via VLM; coordination with operations teams for safe routes.
- Corporate campuses and universities (mailroom, maintenance, visitor assistance)
- Delivery robots navigate between buildings, labs, lecture halls, and event venues based solely on posted signs.
- Potential tools/products/workflows: Campus-tailored symbol dictionaries; path segmentation tuned to outdoor sidewalks and trails; fleet dashboard for sign-aware routing.
- Assumptions/dependencies: Reliable odometry on mixed surfaces; outdoor signage readable under varying weather/lighting; signage-aligned orientation can be achieved (head-on viewing).
- Robotics software and simulation (industry and academia)
- Immediate integration of SignScene modules (open-set detection, SAM2 masks, Metric3Dv2 depth, SignScene ATM rendering) into existing stacks for evaluation and pilot deployments.
- Potential tools/products/workflows: ROS2 packages, benchmark dataset and evaluation scripts; VLM prompt engineering templates; sign parsing unit tests; digital-twin signage scenarios for pre-deployment.
- Assumptions/dependencies: Model licenses and hardware (Jetson Orin AGX class); reliable network or on-device VLM; compatibility with navigation planners (subgoal projection to SE(2)).
- Signage readiness and compliance auditing (facility management)
- Rapid assessment of how existing signs support robotic wayfinding; reporting weak spots (inconsistent arrow semantics, occluded placement, poor orientation).
- Potential tools/products/workflows: “SignAudit” toolkit that scores signs against robot-readability; simulation of top-view rendering and grounding success rates; recommendations for improvements.
- Assumptions/dependencies: Access to representative camera viewpoints; buy-in from facilities for minor signage redesigns.
- Consumer AR wayfinding (daily life)
- Smartphone app reads building signs and supplies turn-by-turn directions using a simplified top-view scene sketch created from monocular depth and short local exploration.
- Potential tools/products/workflows: Mobile VLM pipeline; sign alignment guide; on-device monocular depth and path segmentation; low-latency cloud reasoning.
- Assumptions/dependencies: Network connectivity; user privacy and data consent; adequate phone sensors; stable signage conventions.
- Event operations and temporary installations (conferences, pop-up venues)
- Short-lived signs drive mapless guidance for robots and mobile kiosks in frequently reconfigured venues.
- Potential tools/products/workflows: Quick-start “SignScene Lite” profile with tight VLM prompts and small symbol dictionaries; signage placement guidelines for robot visibility.
- Assumptions/dependencies: Staff compliance with signage guidelines; minimally crowded corridors to maintain partial observability assumptions.
Long-Term Applications
The following opportunities require further research, standardization, scaling, or engineering to reach robust production-readiness.
- Machine-readable signage standards (policy, facilities)
- Codify iconography, arrow semantics (including diagonal and compound instructions), placement, height, and orientation conventions for both human and robot readers; optionally augment with QR/NFC/digital overlays.
- Potential tools/products/workflows: Cross-industry standard (ISO/IEC) for “robot-readable signage”; design guideline handbook; facility retrofitting playbook.
- Assumptions/dependencies: Regulatory and stakeholder consensus; cost-benefit validation; accessibility alignment with human factors.
- On-device, real-time VLM reasoning (software, robotics)
- Move sign parsing and grounding fully on-board for privacy, reliability, and sub-second latency in dynamic environments (e.g., crowded stations).
- Potential tools/products/workflows: Efficient multimodal models; hardware acceleration (edge TPUs, GPUs); distillation and caching of sign prompts and symbol dictionaries.
- Assumptions/dependencies: Power and compute budgets on mobile platforms; robust thermal and energy management; continual model updates.
- Robust compound instruction understanding (academia, software)
- Accurate parsing of multi-step and context-dependent directions (e.g., “left then forward”, “take the escalator down to B4, then follow the corridor”).
- Potential tools/products/workflows: Structured sign parsers with multi-hop reasoning; training datasets of complex signage; hybrid rule-learning systems that fuse semantics with topology.
- Assumptions/dependencies: Large, diverse annotated corpora; evaluation frameworks for compositional semantics; improved prompts and grounding strategies.
- Crowded/dynamic scene grounding (robotics, safety)
- Consistent navigation amid occlusions, crowds, and moving obstacles using multi-sensor fusion and dynamic map layers beyond monocular depth.
- Potential tools/products/workflows: LiDAR/camera fusion; dynamic occupancy estimation; uncertainty-aware top-view rendering; social navigation policies.
- Assumptions/dependencies: Sensors and compute availability; safety and compliance policies; robust tracking in dense flows.
- Cross-lingual, cross-cultural signage and multimodal cues (policy, software)
- Universal grounding across languages, regional icons, and modality mixes (text + pictograms + color-coded routes + floor changes).
- Potential tools/products/workflows: Multilingual symbol dictionaries and translation layers; culture-aware prompts; visual-text-color fusion models.
- Assumptions/dependencies: Data coverage across geographies; evaluation across diverse environments; policy alignment with accessibility norms.
- Hybrid map-lite + signage navigation at building/campus scale (robotics, logistics)
- Combine signage-based local decisions with lightweight public maps or floorplans for long-range planning and high reliability.
- Potential tools/products/workflows: “SignScene + SignLoc” hybrid; floorplan priors with top-view semantic overlays; route planners that prefer signage for local choices.
- Assumptions/dependencies: Access to partial maps; consistent floorplan-sign alignment; robust localization under drift.
- Multi-robot coordination via sign-induced policies (robotics, operations)
- Shared sign-centric top-view representations enable consistent decision-making and deconfliction in fleets (delivery, cleaning, security).
- Potential tools/products/workflows: Common signage knowledge base; subgoal arbitration; priority rules at junctions tied to sign semantics.
- Assumptions/dependencies: Communication and synchronization infrastructure; standardized sign interpretation across robots.
- AR glasses and assistive wayfinding (daily life, accessibility)
- Real-time overlays of sign-derived directions for visitors or staff, including floor-change guidance and emergency exit routes.
- Potential tools/products/workflows: AR pipeline for sign detection and top-view hints; privacy-preserving on-device processing; indoor positioning.
- Assumptions/dependencies: Comfortable, affordable AR hardware; reliable indoor positioning; clear signage design.
- Smart infrastructure with robot APIs (policy, building systems)
- Digital signs expose standardized APIs to robots for programmatic direction updates (e.g., reroutes during maintenance or emergencies).
- Potential tools/products/workflows: Building management integration; secure sign-to-robot communication protocols; automated signage consistency checks.
- Assumptions/dependencies: Cybersecurity; operational governance; backward compatibility with static signs.
- Compliance and governance for camera-based navigation (policy, risk management)
- Frameworks to address privacy, data retention, and safety when robots read signs in public and semi-public spaces.
- Potential tools/products/workflows: Risk assessment templates; consent and masking tools; audit logs for VLM queries.
- Assumptions/dependencies: Jurisdiction-specific regulations; stakeholder engagement; technical controls for data minimization.
- Energy and cost optimization (operations, sustainability)
- Reduce dependency on heavy LiDAR-based stacks by leveraging RGB + odometry + VLM, lowering capex/opex for fleet deployments.
- Potential tools/products/workflows: Cost calculators; mixed-sensor design guides; performance trade-off dashboards.
- Assumptions/dependencies: Robustness parity in target environments; acceptable failure rates with lighter sensors; careful tuning of path segmentation models.
These applications build directly on the paper’s key innovations: a sign-centric Abstract Top-view Map that simplifies and aligns spatial context for VLM reasoning; an active exploration strategy to overcome partial observability; and a robust sign understanding module augmented by symbol dictionaries and temporal fusion. Together, they open a path from human-oriented signage to practical, mapless navigation across multiple sectors.
Glossary
- Abstract Top-view Map: An abstract metric–semantic map centered and aligned to a sign, rendered as a simplified 2D diagram for spatial reasoning. "To this end, we propose the Abstract Top-view Map (), an abstract metric–semantic map that organizes navigation-relevant scene information in a frame aligned with a sign’s location and orientation, and renders it as a simplified 2D diagram."
- Bipartite matching: A matching technique between two sets, used to associate parsed locations with their navigational instructions. "and to associate them via bipartite matching to produce the final set of navigational cues C."
- Candidate frontiers: Potential exploration targets near possible path entrances inferred from local geometry. "identify candidate frontiers to visit."
- Convex protrusions: Outward convex segments of a polygon boundary used as heuristics to identify discrete path entrances. "We apply the heuristic that discrete paths are likely to appear as convex protrusions on this polygon."
- Explicit navigational structures: Discrete, semantically labeled scene elements (e.g., stairs, escalators) represented as geometric objects. "Explicit navigational structures: These are represented as oriented 3D bounding boxes, each annotated with a semantic class label and an instance identifier."
- Fuzzy matching: Approximate string matching used to link a queried location to parsed sign locations. "using fuzzy matching score based on Levenshtein distance~\cite{Levenshtein1965spd}"
- GeNIE: A traversability/path segmentation model used to segment human-preferred paths. "we use GeNIE~\cite{wang2025arxiv}, a traversability model fine-tuned on human-annotated data to segment paths preferred by humans."
- Gridmap: A 2D discretized spatial representation used to project point clouds and extract contours. "by projecting the pointcloud on a 2D gridmap and extracting the simplified border contour."
- GroundingDINO: An open-set object detector employed to detect signs and navigational structures. "We use GroundingDINO~\cite{liu2024eccv} as our open-set object detector"
- Hungarian algorithm: An assignment algorithm used to match detections to existing map objects. "where detections in frame It are matched to existing map objects O via the Hungarian algorithm."
- Implicit paths: Navigable regions defined by geometry or terrain, represented densely rather than as discrete objects. "Implicit paths: These are represented as dense pointclouds, as they may be irregularly shaped and require high resolution to fully capture."
- In-context learning: Prompting a model with examples in the prompt to improve parsing and generalization. "We use in-context learning to improve the sign understanding performance."
- Levenshtein distance: An edit-distance metric used for fuzzy string matching of locations. "using fuzzy matching score based on Levenshtein distance~\cite{Levenshtein1965spd}"
- LiDAR-based SLAM: Simultaneous localization and mapping using LiDAR measurements to build global maps. "ReasonNav builds a global map using LiDAR-based SLAM~\cite{Macenski2021joss}"
- Manhattan world assumption: The assumption that directions align to four orthogonal, cardinal axes. "essentially making a Manhattan world assumption"
- Metric–semantic map: A representation combining geometric (metric) structure with semantic labels of scene elements. "an abstract metric–semantic map that organizes navigation-relevant scene information"
- Monocular depth estimation: Predicting scene depth from single RGB images to infer 3D geometry. "we apply a monocular depth estimation model to RGB observations."
- Occupancy grid map: A gridded map where cells encode whether space is free or occupied. "such as occupancy grid maps or voxel grids."
- Odometry: Estimation of robot motion over time used for constructing spatial understanding. "from a sequence of RGB observations and odometry"
- Open-set object detector: An object detector that responds to text prompts and can detect classes beyond a fixed taxonomy. "We prompt an open-set object detector with the query “signs” to obtain bounding boxes"
- Oriented 3D bounding box: A rotated 3D box fit to an object’s point cloud, encoding its position, size, and orientation. "we estimate an oriented 3D bounding box and encode each structure in with its 3D geometry"
- Plane fitting: Estimating a planar surface from point cloud data to compute surface normals. "Normals are estimated using the plane fitting method of \cite{zhou2018arxiv}."
- Point cloud: A set of 3D points representing observed geometry from depth or multi-view fusion. "we extract 3D point cloud segments $for each detected sign" - **RGB-D sequence**: A time series of color images with aligned depth, used for detection and fusion. "temporally fuse navigational signs across an input RGB-D sequence" - **SAM2**: A segmentation model used to obtain masks for detected objects. "which are used to prompt SAM2~\cite{ravi2025iclr} for masks M." - **Scene graph**: A graph-based representation of objects and their relations used in navigation tasks. "Object goal navigation tasks were implemented using scene graphs~\cite{loo2025ijrr, maggio2024ral}." - **SE(2)**: The planar pose group comprising x, y position and heading; used to specify subgoal poses. "and project that into an SE(2) subgoal pose." - **Sign alignment module**: A component that actively aligns the robot head-on to a sign to satisfy parsing assumptions. "we integrate a sign alignment module (#1{sec:setup}) that actively aligns the robot with a detected sign to satisfy this assumption." - **Sign grounding**: Mapping navigational instructions on a sign to specific scene elements and actions. "We formalize this as sign grounding, the problem of mapping semantic instructions on signs to corresponding scene elements and navigational actions." - **Sign understanding**: Parsing a sign’s text and symbols into structured navigational cues linking locations to directions. "sign understanding, which extracts a sign’s instructions and locational information into a structured representation" - **Sign-centric coordinate frame**: A coordinate frame aligned with a sign’s pose used for consistent rendering and reasoning. "we rotate$ to align with the sign's coordinate frame, then project it to 2D."
- Sign-centric rendering: Centering and aligning the map on the sign’s viewpoint to match human-oriented directions. "First, it provides a sign-centric rendering of the scene: the map is centered on the sign and aligned such that the head-on viewing direction of the sign is fixed and consistent."
- Spatial–semantic representation: A data structure combining spatial geometry and semantic content for reasoning. "We propose SignScene, a sign-centric spatial–semantic representation that captures navigation-relevant scene elements and sign information"
- Surface normal: A unit vector perpendicular to a surface, used to assess alignment with viewing direction. "and it s surface normal n_s is aligned with the robot’s viewing direction within an angular threshold"
- Temporal fusion: Aggregating detections over time to produce stable, fused map objects and sign instances. "temporally fuse navigational signs across an input RGB-D sequence to estimate each sign’s 3D location and orientation."
- Top-down map: A 2D bird’s-eye rendering of the 3D scene used for VLM-based reasoning. "renders the 3D map into an abstract, 2D top-down map."
- Topological mapping: A connectivity-based spatial representation that abstracts away metric detail. "Topological mapping is another common spatial representation for navigation."
- Traversability model: A model that predicts navigable regions preferred by humans for safe movement. "a traversability model fine-tuned on human-annotated data to segment paths preferred by humans."
- Vision-LLM (VLM): A model that jointly processes visual and textual inputs to perform semantic reasoning. "Recent Vision-LLMs (VLMs) offer the semantic common-sense and reasoning capabilities required for this task"
- Visual grounding: The task of linking textual references to specific visual elements or locations. "Visual grounding performance for 9 different environments."
- Visual servoing: Closed-loop control using visual feedback to move toward or align with targets. "perform visual servoing to approach a detected sign"
- Visual-inertial odometry: Estimating motion by fusing visual data with inertial measurements. "sparse depth images and visual-inertial odometry."
- Voxel grid: A 3D volumetric grid representation used for dense mapping. "such as occupancy grid maps or voxel grids."
Collections
Sign up for free to add this paper to one or more collections.