Real-time Rendering with a Neural Irradiance Volume
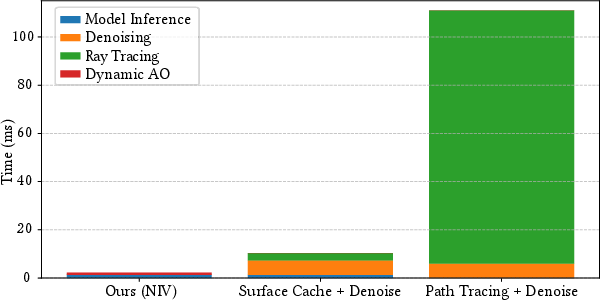
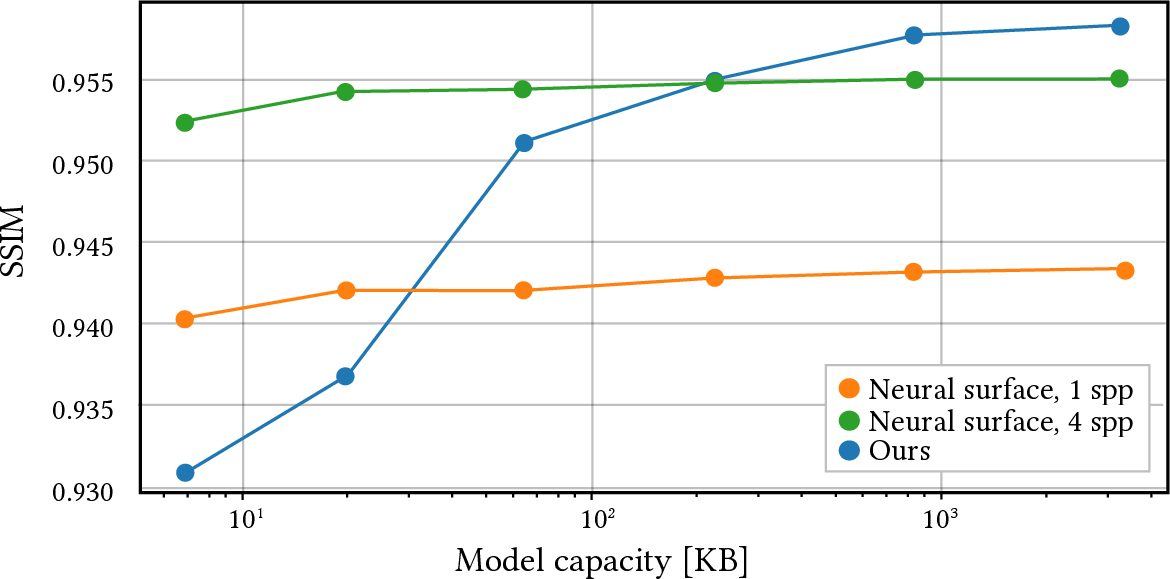
Abstract: Rendering diffuse global illumination in real-time is often approximated by pre-computing and storing irradiance in a 3D grid of probes. As long as most of the scene remains static, probes approximate irradiance for all surfaces immersed in the irradiance volume, including novel dynamic objects. This approach, however, suffers from aliasing artifacts and high memory consumption. We propose Neural Irradiance Volume (NIV), a neural-based technique that allows accurate real-time rendering of diffuse global illumination via a compact pre-computed model, overcoming the limitations of traditional probe-based methods, such as the expensive memory footprint, aliasing artifacts, and scene-specific heuristics. The key insight is that neural compression creates an adaptive and amortized representation of irradiance, circumventing the cubic scaling of grid-based methods. Our superior memory-scaling improves quality by at least 10x at the same memory budget, and enables a straightforward representation of higher-dimensional irradiance fields, allowing rendering of time-varying or dynamic effects without requiring additional computation at runtime. Unlike other neural rendering techniques, our method works within strict real-time constraints, providing fast inference (around 1 ms per frame on consumer GPUs at full HD resolution), reduced memory usage (1-5 MB for medium-sized scenes), and only requires a G-buffer as input, without expensive ray tracing or denoising.















Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Real-time Rendering with a Neural Irradiance Volume — Explained Simply
What is this paper about?
This paper introduces a new way to draw realistic lighting in real time for video games and interactive graphics. It focuses on “indirect diffuse lighting,” which is the soft glow you see when light bounces off walls, floors, and objects and spreads around a room. The authors present a technique called Neural Irradiance Volume (NIV) that makes this kind of lighting fast, memory‑efficient, and high quality—even when new, moving objects are added to a mostly static scene.
What problem are they trying to solve?
Realistic lighting isn’t just about direct light from lamps or the sun. It’s mostly about the indirect light that bounces around. Calculating those bounces on the fly is slow. A common shortcut is to “bake” light into a 3D grid of points (called probes). That works fast, but:
- It takes a lot of memory if you want good detail.
- It can produce visible errors like blurry shadows or light leaks.
- It requires careful, scene‑specific setup (placing lots of probes just right).
The paper asks: Can we keep the speed of probe grids but get better quality and use much less memory, without relying on scene‑specific tricks?
How does their method work?
Think of lighting like sound in a room: sound doesn’t just come straight from the speaker; it bounces and fills the space. If you wanted to know how loud it is at any spot and in any direction, you could measure it at many points. But storing all that raw data takes up huge space.
NIV compresses this “how much light reaches here, from this direction” information into a small, trained neural network. Here’s the idea in everyday terms:
- Irradiance Volume: This is a field that tells you, for any 3D position and surface direction (the way a surface faces), how much indirect light lands there. That’s a 5D function: 3 numbers for position, 2 for direction.
- Pre‑integration: Instead of learning raw incoming light rays (which would require lots of sampling during rendering), the network learns the already‑averaged “brightness from all directions” at a spot. That makes the signal smooth and avoids noise, so the network can answer quickly and cleanly.
- Neural Compression: The network is small and uses a clever input encoding (a multi‑level hash grid), which is like storing more detail where it matters and less where it doesn’t. Think of a city map that uses high detail for busy downtown streets and fewer details for empty fields. Collisions (two places sharing an entry) are handled during training, so the most important areas still come out right.
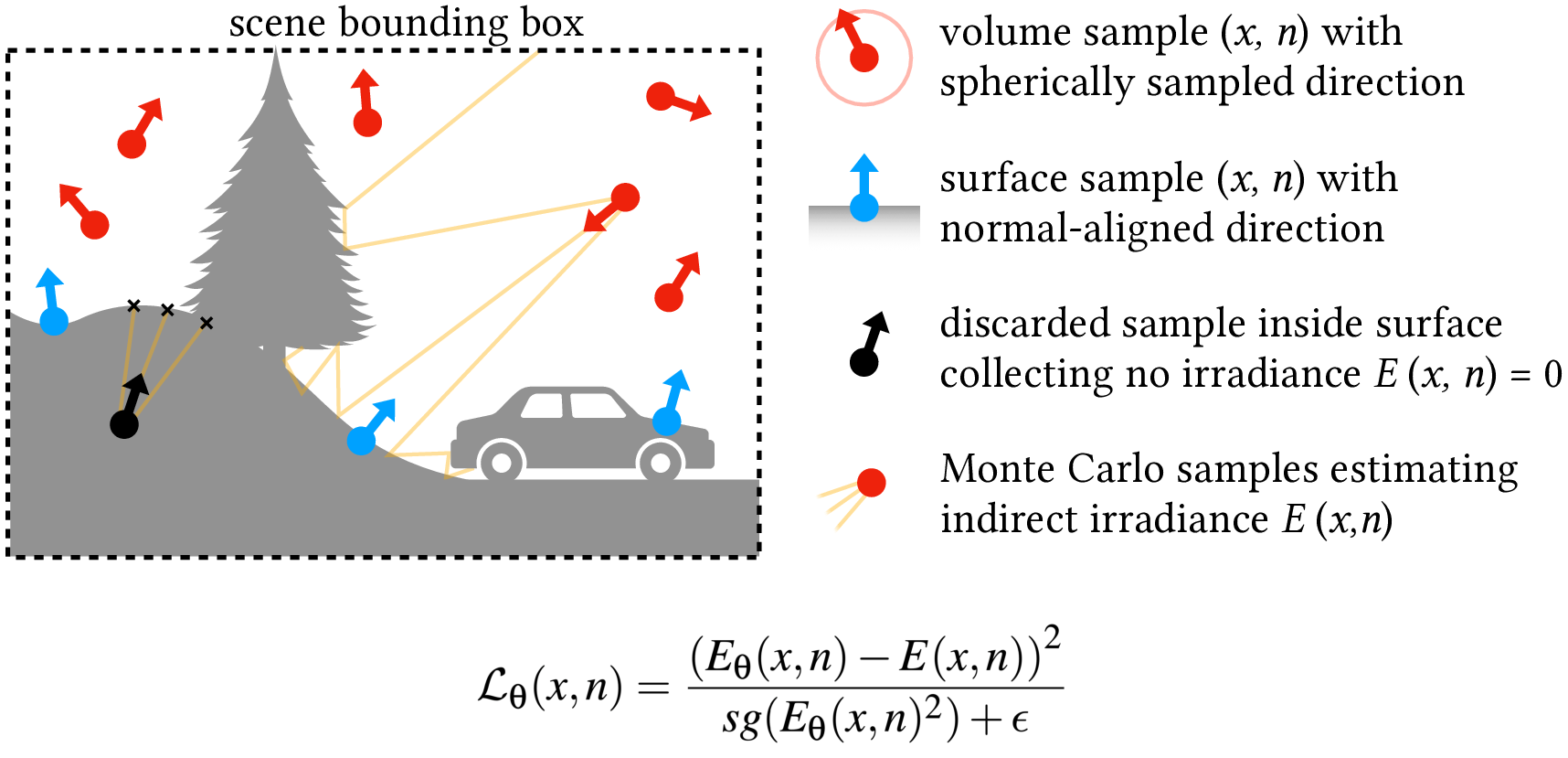
- Training: Before you run the game, they create lots of examples by path tracing (a very accurate but slow lighting method) to find the true indirect light at many positions and directions. The network learns to predict those values. They also:
- Avoid training on points inside solid objects (not useful at runtime).
- Spend about 20% of training on exact surface points with their true normals, so the network captures crisp contact shadows and detailed surface effects.
- Rendering: During gameplay, the engine already knows, per pixel, where the surface is and which way it faces (this is in a standard “G‑buffer”). NIV takes that position and normal and instantly returns the indirect light. The engine multiplies that by the surface color, then adds direct light and any glow the object emits to make the final image.
This design means you don’t need to shoot rays or denoise during gameplay, which saves time.
What did they find?
The authors tested NIV against popular methods and report:
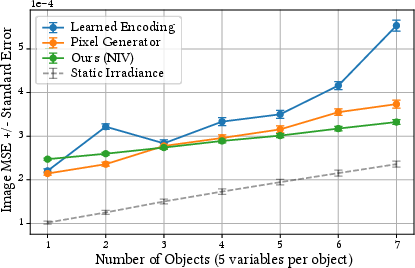
- Much better quality per megabyte: At the same memory budget, NIV gives about 10× lower error compared to traditional probe grids. It captures fine details like contact shadows and avoids light leaks.
- Very small memory use: Around 1–5 MB for medium‑sized scenes.
- Very fast: About 1 millisecond per frame at full HD on a consumer GPU. Even faster at half resolution, with only minor visual changes thanks to the smoothness of indirect light.
- Works with dynamic objects: Even if the network was trained only on a static scene, you can drop in new moving objects at runtime and NIV shades them realistically with the precomputed irradiance field.
- No runtime ray tracing or denoising: That’s a big win for real-time performance and stability.
They also show NIV can be extended to handle simple scene changes—like a moving sun for time‑of‑day—by giving the network a small extra input (such as the light angle) during training. That lets you change those parameters at runtime without retraining.
To handle small missing interactions from dynamic objects (like a character slightly blocking bounced light on a wall), they add a lightweight “dynamic ambient occlusion” pass. It’s a fast way to mimic local shadowing from moving objects without full global updates.
Why is this important?
- Better visuals with less memory: Games and real-time apps can show softer, more realistic lighting and shadows using tiny memory budgets.
- Consistent and fast: No noisy images, no waiting for denoisers, and no expensive ray-tracing during play.
- Simpler setup: Unlike classic probe grids, you don’t need to hand-tune where probes go or how dense they should be. The neural network learns where detail is needed.
- Scales to dynamic scenes: New objects can be shaded convincingly without retraining or re-baking.
What does this mean for the future?
- Game development: NIV can make high-quality global illumination practical in fast-paced games and VR, where performance and memory are critical.
- Flexible lighting changes: Common features like time‑of‑day cycles can be pre-learned into the network so they run smoothly during gameplay.
- Fewer artifacts: The unified approach captures both surface detail and volume lighting, reducing the need for multiple caches and special-case code.
A few limitations remain:
- Direct lighting from many complex lights still needs efficient runtime solutions (like shadow maps or clustered lighting). NIV focuses on indirect diffuse lighting.
- Very complex dynamic interactions (for example, big moving objects that strongly change the whole scene’s bounced light) are outside its main assumption set. The method assumes the scene is mostly static and dynamic objects are relatively small.
Overall, NIV is a practical, fast, and memory-friendly step toward bringing high-quality, realistic indirect lighting to real-time graphics without the usual headaches.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper; each item is framed to be actionable for future research.
- Missing dynamic GI from moving objects: The method assumes dynamic objects do not significantly affect global light transport; only a lightweight dynamic ambient occlusion pass is applied. Quantify when this approximation breaks, and develop mechanisms (e.g., sparse online updates, hybrid caches) to capture inter-reflections and shadowing from large or many dynamic objects.
- Direct illumination scalability: NIV excludes direct illumination from the learned model and assumes it can be computed cheaply at runtime. Benchmark and integrate many-lights solutions, shadowing, and complex light types (area/IES lights) within tight budgets, or explore training a unified cache that includes direct diffuse to reduce runtime passes.
- Non-diffuse materials: The approach is restricted to diffuse BRDFs. Investigate extensions for glossy/rough specular and view-dependent effects (e.g., higher-dimensional conditioning on outgoing/view direction, factorized representations, or split-sum approximations) while maintaining real-time performance.
- Participating media and volumetric effects: The method does not address media scattering/absorption. Explore whether NIV can be extended to represent volumetric irradiance fields (conditioning on medium density/phase function) and the performance/accuracy consequences.
- Training data generation details: The paper does not specify the number of samples per point, per-bounce configurations, or sampling strategies for ground-truth irradiance. Analyze how estimator noise, spp, and sampling distributions affect convergence, bias, and final quality, and propose variance-reduction or reuse strategies to cut precomputation time.
- Large-scale/outdoor scenes: Evaluation focuses on medium indoor scenes. Characterize memory/quality/runtime scaling for large, open environments and long-range transport (e.g., daylight). Investigate tiling, streaming, and out-of-core training/inference for very large domains.
- Hash-grid collision tuning: The chosen hash table size (T=217) and levels are fixed across scenes. Provide a principled method to select hash parameters per scene (or learn them) and assess generalization across diverse geometries, scales, and frequency content; explore per-level adaptive table sizes or occupancy-guided encodings.
- Directional representation choices: Directions are fed directly to the MLP; no specialized directional encoding is studied. Compare spherical encodings (e.g., SH/SN), learned angular features, or factorizations to improve modeling of directional irradiance while keeping inference cost low.
- Half-resolution rendering and upsampling: The paper notes slight aliasing and suggests generic upsampling. Evaluate temporal stability, ghosting, and detail retention with modern spatio-temporal upsamplers (FSR/DLSS-like) tailored to irradiance signals, and quantify perceptual benefits.
- Hardware portability: Reported timings target an RTX 4090. Provide performance profiles on mid-range GPUs, consoles, and mobile SoCs (with varied tensor-core support), and assess precision/quantization schemes (FP16/FP8/int8) to meet platform constraints.
- Temporal consistency: While NIV is noise-free, temporal stability under moving cameras/objects is not analyzed. Measure flicker/temporal artifacts and investigate temporal losses or recurrent conditioning to guarantee stable sequences.
- Scaling higher-dimensional fields: Training with more than 1–2 scene variables degrades quality. Explore architectures (conditional networks, mixture-of-experts, LoRA-style adapters, factorized encodings) that scale to many dynamic parameters without prohibitive inference costs.
- Unseen lighting changes and continual learning: NIV is trained once for a static irradiance field or a limited set of parameters. Study fast, low-cost fine-tuning/continual learning that updates NIV when lights change, without ray tracing or denoising at runtime.
- Training sample culling near thin/complex geometry: The heuristic to discard samples inside geometry may misclassify near thin shells or complex meshes. Develop robust visibility tests and boundary-aware sampling to avoid artifacts near thin structures.
- Error metrics and perceptual validation: Evaluation uses MSE and FLIP; no user studies or perceptual assessments over motion are provided. Conduct perceptual studies and include temporal perceptual metrics to establish production viability.
- Interaction with high-frequency albedo textures: NIV multiplies smooth irradiance by full-resolution albedo, but the impact of extreme texture contrast on perceived contact shadows and light bleed is not quantified. Analyze failure cases and propose texture-aware post-processing.
- Memory/quality budgeting guidelines: The paper shows trade-offs but lacks practical recipes for choosing model size and hash parameters per scene. Provide automatic capacity selection and scene-aware budgeting tools to hit target error/performance constraints.
- Physical constraints in training: The model does not enforce non-negativity or energy conservation. Investigate constrained losses or parameterizations that preserve physical plausibility (e.g., positivity clamps, monotonicity, energy bounds).
- Robustness to dynamic occluders: The higher-dimensional application demonstrates a moving occluder with doubled hash size, but quantitative error against path-traced references is not reported. Systematically evaluate accuracy across occluder sizes/speeds and parameter budgets.
- Fairness and breadth of baselines: Comparisons target DDGI-like probes and specific neural caches; advanced probe variants (e.g., visibility cones, hybrid caches) and modern upsamplers/denoisers are not exhaustively covered. Extend benchmarks to a wider set of baselines and scene types.
- Reproducibility and release: Implementation details (training pipeline, dataset sizes, spp, renderer configs) and code/models are not provided. Release assets and scripts to enable independent verification and broader adoption.
Practical Applications
Immediate Applications
Below are deployable, concrete uses that can leverage Neural Irradiance Volume (NIV) as described (1–5 MB per scene, ~1 ms/1080p on consumer GPUs, precompute in minutes, G-buffer input, diffuse indirect only).
- Gaming/Interactive Entertainment: Drop-in replacement for irradiance probe grids (DDGI)
- Sector: Software (games), XR
- What: Replace probe volumes with a compact NIV asset to render high-quality diffuse global illumination for static levels with moving characters/props. Eliminates probe placement heuristics and light leaking, captures contact shadows on static surfaces, and shades unseen dynamic objects.
- How/Tools: Engine plugin for Unreal/Unity using deferred shading G-buffers; FP16 inference on Tensor Cores/DirectML/Vulkan cooperative matrices/Metal; optional half-resolution inference with joint-bilateral upsampling; optional dynamic AO pass for self-occlusion of dynamic actors. Export NIV as an ONNX/engine-native asset from a bake tool that uses path-traced irradiance (e.g., Mitsuba, Cycles).
- Assumptions/Dependencies: Mostly static environment; diffuse-only indirect; direct lighting/shadows computed separately (e.g., clustered lights + shadow maps); dynamic objects relatively small; consumer GPU with reasonable ML throughput; artist or automated pipeline to trigger NIV bake per level.
- Virtual Production and Previz: Fast, noise-free diffuse GI during blocking and look-dev
- Sector: Film/VFX, Media
- What: Prebake NIV for static sets (physical or virtual), then render actors and moving cameras with high-fidelity diffuse GI without path-tracing noise or denoising delay during live sessions.
- How/Tools: DCC-to-stage pipeline that exports a NIV asset per set; GPU renderer plugin reads NIV from G-buffer and adds direct lights. Toggle time-of-day cycles by training a small higher-dimensional NIV (angle variable).
- Assumptions/Dependencies: Set geometry static; time-of-day or 1–2 controlled light parameters; direct light/shadow handled separately.
- Architectural/Real Estate Walkthroughs and Product Configurators
- Sector: AEC, E-commerce, XR
- What: Interactive, realistic diffuse lighting with accurate color bleed for static interiors while letting users place and move furniture/products.
- How/Tools: NIV baked per interior scene; runtime integrates NIV with G-buffer; dynamic AO for placed objects; optional higher-dimensional NIV for sun angle/time-of-day. Deliver via desktop, cloud-streamed, or high-end mobile with NPU.
- Assumptions/Dependencies: Interior largely static; small count of variable parameters (e.g., sun azimuth).
- Training Simulators (Driving/Flight/Defense) with Time-of-Day
- Sector: Education/Training, Defense, Automotive/Aerospace
- What: Stable, noise-free diffuse GI for extensive static terrains/cabins with moving vehicles/agents and continuous time-of-day.
- How/Tools: NIV extended with 1–2 variables (sun angle, occluder position) trained offline; runtime inference in <1 ms/frame; dynamic AO for agent self-occlusion.
- Assumptions/Dependencies: Limit variable dimensions to 1–2 to maintain performance; direct lighting via standard techniques.
- Cloud Gaming/Interactive Streaming: Server-side cost and density gains
- Sector: Cloud, Software
- What: Replace probe grids and diffuse path tracing with NIV to cut per-stream GPU cost, reduce variance/denoising pipelines, and increase session density.
- How/Tools: Server renderer queries NIV with G-buffers; smaller memory footprint (1–5 MB/scene) reduces cache/memory pressure.
- Assumptions/Dependencies: Titles with predominantly static levels; established direct-light passes; retraining only when environments change.
- Robotics/Autonomy Simulation for Perception Data
- Sector: Robotics, Autonomous Systems
- What: Generate photometrically consistent ambient illumination for synthetic datasets, reducing noise and bake time compared to per-frame path-traced diffuse GI.
- How/Tools: Prebake NIV for static lab/urban scenes; render many sensor trajectories cheaply with consistent diffuse illumination; train detectors with improved realism for color bleed and ambient contrast.
- Assumptions/Dependencies: Static background geometry; specular/translucent effects handled separately or omitted.
- Education and Research Demos in Real-Time GI
- Sector: Academia, Education
- What: Teaching labs and benchmarks contrasting probe grids, neural caches, and NIV for diffuse GI; use NIV to demonstrate irradiance vs. radiance learning and hash-grid effects.
- How/Tools: Public scenes (Sponza, Cornell) with notebooks that train and visualize NIV; runtime plugin to compare baselines.
- Assumptions/Dependencies: GPU access for bake and inference.
- AR/Home Design and Mobile Companion Experiences (conditional)
- Sector: Consumer Apps, XR
- What: On-device or edge-assisted NIV to render realistic ambient lighting around placed virtual objects in static rooms.
- How/Tools: Capture static meshes via LiDAR/photogrammetry, bake NIV in the cloud or offline; mobile inference via Metal/NNAPI with half-res and temporal upsampling.
- Assumptions/Dependencies: Static reconstructed scene; limited on-device ML throughput; careful memory budget; direct light approximated (e.g., environment lighting + shadow maps).
Long-Term Applications
The following need further research/engineering (e.g., extending beyond diffuse, handling frequent scene changes, scaling variables, or targeting constrained hardware).
- Unified Neural Global Illumination (Diffuse + Glossy/Specular + Caustics)
- Sector: Software (engines), Film/VFX, XR
- What: Extend NIV to learn additional lobes (e.g., pre-integrated hemispherical components for rough specular, or low-rank directional bases) to cover non-diffuse GI while maintaining real-time inference.
- How/Tools: Hybrid representations (multi-lobe networks, Spherical Gaussians), clustered material-condition inputs, or cascaded caches.
- Assumptions/Dependencies: Increased model capacity and careful architecture; still avoid runtime sampling or add limited sampling with lightweight denoising.
- Online-Updatable NIV for Dynamic Environments
- Sector: Games, Digital Twins, Robotics
- What: Incrementally update the irradiance field when large objects move, doors open, or furniture rearranges—without full rebake.
- How/Tools: Background training thread ingesting sparse path-traced updates; confidence weights to blend old/new irradiance; streaming hash-grid updates.
- Assumptions/Dependencies: Stable training on-device; predictable update budgets; robust temporal stability.
- City/Facility-Scale Digital Twins with Hierarchical NIV
- Sector: Smart Cities, AEC, Industrial Digital Twins
- What: Tiled hierarchical NIVs covering large static zones, enabling fast, consistent diffuse lighting for multi-user simulations and monitoring.
- How/Tools: Spatial partitioning, streaming of per-tile NIV assets; LOD for hash-encodings; time-of-day variables.
- Assumptions/Dependencies: Strong asset management, streaming infrastructure; tight control over variable counts per tile.
- Capture-to-NIV Pipelines from Reality
- Sector: XR, AEC, E-commerce
- What: Turn scanned/static rooms into NIVs that power realistic relighting for AR/VR staging without environment-specific probe tuning.
- How/Tools: Neural or classic inverse rendering to derive indirect irradiance GT; bake into NIV; distribute alongside scene meshes.
- Assumptions/Dependencies: Reliable scene reconstruction and material estimation; robust GT irradiance acquisition.
- Low-Power/Mobile and Web Targets
- Sector: Mobile, Web3D
- What: Aggressive quantization/pruning/distillation for NIV to run at sub-millisecond on mobile GPUs/NPUs or browsers (WebGPU).
- How/Tools: INT8/FP8 quantization, tile-based inference, micro-networks per region; runtime schedulers.
- Assumptions/Dependencies: Vendor ML accelerators, standardized shader/ML APIs; quality maintained under tight budgets.
- Standardization and Interoperability of Neural Irradiance Assets
- Sector: Standards, Policy, Ecosystem
- What: Define an open asset format for neural GI caches (e.g., ONNX + metadata for training domain, variables, error stats) to ensure portability across engines.
- How/Tools: Khronos/industry working groups; reference conformance tests and error metrics (e.g., HDR-FLIP).
- Assumptions/Dependencies: Multi-vendor alignment; IP considerations.
- Sustainability and Policy: Energy-Aware Rendering Defaults
- Sector: Policy, Gov Tech, Cloud
- What: Establish procurement and development guidelines encouraging neural precomputation (e.g., NIV) over runtime path tracing for diffuse GI in public-facing apps, reducing energy consumption and hardware costs.
- How/Tools: Benchmarks quantifying kWh/frame and CO2 avoided; best-practice documents for public procurement and educational deployments.
- Assumptions/Dependencies: Transparent telemetry and standardized reporting; acceptance of precomputation workflows.
- Photorealistic Training for Medical/Technical VR
- Sector: Healthcare, Industrial Training
- What: Use extended NIV for stable, realistic ambient lighting in surgical/technical simulators, reducing motion sickness and training variance without heavy compute.
- How/Tools: Domain-specific assets with NIV; integration with haptics and high-FPS VR pipelines.
- Assumptions/Dependencies: Accurate materials and anatomy models; eventual specular/translucency extension.
- Foundation Models for Irradiance Fields
- Sector: Research, Software
- What: Pretrain models that generalize irradiance priors across scene categories, requiring minimal scene-specific fine-tuning to produce a high-quality NIV.
- How/Tools: Large datasets of path-traced irradiance; meta-learning; few-shot domain adaptation.
- Assumptions/Dependencies: Dataset availability; generalization across topology/materials.
- Hybrid Path Tracing + NIV Schedulers
- Sector: Engines, Cloud
- What: Dynamically select NIV vs. limited sampling+denoising based on scene novelty and camera motion to optimize quality/perf per frame.
- How/Tools: Confidence estimation of NIV outputs; on-the-fly fallbacks; adaptive sample counts.
- Assumptions/Dependencies: Reliable error estimates; robust denoising at low sample counts.
Notes on Feasibility and Dependencies (Cross-Cutting)
- Core assumptions: Scene largely static at runtime; dynamic objects do not significantly alter global light propagation; diffuse indirect only (direct and specular handled separately); a small number (1–2) of variable parameters can be encoded efficiently.
- Runtime requirements: Deferred shading G-buffers; FP16-capable GPU/accelerator; optional dynamic AO for self-occlusion; half-resolution inference acceptable with upsampling.
- Bake pipeline: Access to path-traced indirect irradiance for training (minutes per scene on modern GPUs). Retraining required when static scene geometry/materials or encoded variables change.
- Quality controls: Ensure training covers surfaces (e.g., ~20% surface samples) and culls inside-geometry points; tune hash-grid capacity for collision rate vs. memory.
- Limitations to manage: Many dynamic lights or highly glossy/translucent materials are out-of-scope for current NIV; large moving occluders not included unless encoded as variables; extensive variable parameter spaces require more capacity or learned encodings, increasing inference cost.
Glossary
- Albedo: The proportion of light a surface reflects under diffuse illumination. "Multiplying the latter by surface albedo results in indirect illumination"
- Ambient occlusion: A shading technique that approximates how nearby geometry occludes ambient light. "A common solution to mitigating part of these missed interactions is applying an ambient occlusion pass~\cite{shanmugam2007hardware}."
- Amortized: Refers to spreading computation or representation cost across inputs via precomputation or learning. "neural compression creates an adaptive and amortized representation of irradiance"
- Backpropagation: Gradient-based optimization technique used to train neural networks. "relying instead on backpropagation to directly optimize for reconstruction quality."
- Bidirectional Reflectance Distribution Function (BRDF): A function describing how light is reflected at a surface for given incident and outgoing directions. "the bidirectional reflectance distribution function (BRDF) can be factored out of the reflected radiance integral."
- Coordinate-based neural network: A neural network that maps input coordinates (e.g., position and direction) directly to scene quantities. "a four-layer fully connected coordinate-based neural network~\cite{muller2021real}"
- Cubic scaling: The property that memory or computation grows with the cube of spatial resolution in volumetric grids. "circumventing the cubic scaling of grid-based methods."
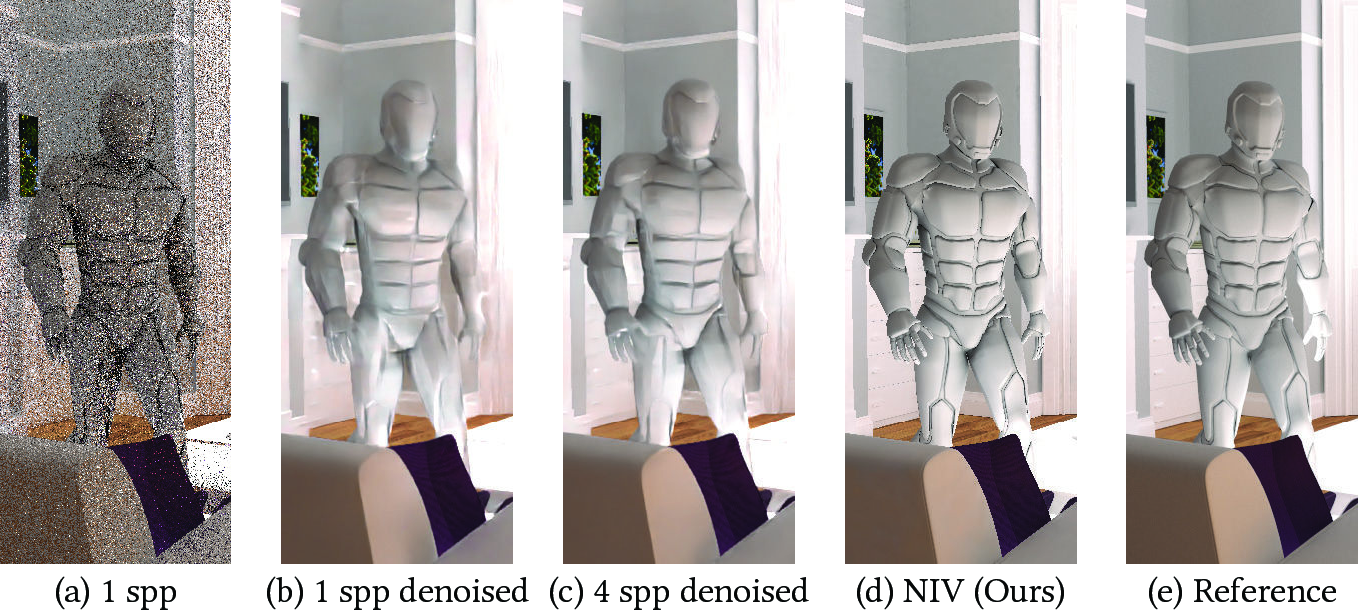
- Deferred surface lookup: A strategy that defers shading by querying a cache at a later surface intersection. "Rendering with a neural surface cache requires a single deferred surface lookup, which introduces noise (a)."
- Denoising: The process of reducing Monte Carlo noise in rendered images using filtering or neural methods. "requires additional denoising."
- Direct illumination: Light that reaches a point directly from emitters without bouncing. "Since direct illumination is comparatively inexpensive to compute"
- Emitted radiance: Radiance emitted by light sources rather than reflected. "adding direct illumination and emitted radiance results in diffuse global illumination."
- Frequency encoding: Encoding coordinates with sinusoidal functions to capture high-frequency detail. "The smaller models add frequency encoding~\cite{mildenhall2021nerf} to the input position "
- G-buffer: Screen-space buffers storing per-pixel geometry/material attributes used in deferred shading. "only requires a G-buffer as input, without expensive ray tracing or denoising."
- Global illumination: Lighting that includes indirect effects from interreflections and occlusions. "Rendering diffuse global illumination in real-time is often approximated by pre-computing and storing irradiance in a 3D grid of probes."
- Hash collisions: Different inputs mapping to the same entry in a hash table, potentially reducing accuracy. "too many collisions results in a reduction of reconstruction quality."
- Indirect irradiance: The irradiance component due to indirect (multi-bounce) light. "For simplicity, we denote the indirect irradiance as , with direct illumination added at runtime."
- Irradiance: The hemispherical integral of incoming radiance weighted by the cosine of the incident angle. "This simplification reduces the formulation to the irradiance function :"
- Irradiance volume: A volumetric cache of irradiance sampled throughout a scene to enable fast shading. "forming an irradiance volume that can be queried efficiently at runtime to shade unseen objects."
- Latent vectors: Learned feature vectors produced by an encoding, used as inputs to a neural network. "This encoding maps positions in 3D space to latent vectors at multiple resolutions"
- Light-leaking artifacts: Unphysical brightening due to interpolation or incorrect visibility assumptions. "to mitigate light-leaking artifacts and reconstruction errors."
- Light probes: Sampled points in space storing local lighting for interpolation at runtime. "grid of light probes, forming an irradiance volume"
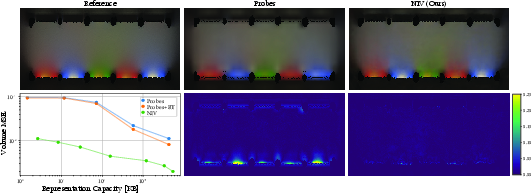
- Mean Squared Error (MSE): A common metric measuring the average squared difference between predictions and ground truth. "Allowing hash collisions mildly impacts the MSE while significantly reducing the required memory."
- Monte Carlo integration: Stochastic numerical integration technique used in rendering, often introducing variance. "the significant cost of Monte Carlo integration at runtime can be avoided."
- Multi-resolution hash encoding: A learned, multi-scale hash-grid feature encoding for spatial inputs. "augmented with a multi-resolution hash encoding~\cite{muller2022instant} with the same representational capacity as our method."
- Path tracing: A Monte Carlo algorithm that solves the rendering equation by tracing light transport paths. "regressing on path traced indirect irradiance values "
- Precomputed radiance transfer (PRT): Technique that precomputes how surfaces respond to varying lighting, often via basis functions. "precomputed radiance transfer~\cite{sloan2002PRT}"
- Pre-integrated: Refers to storing an integral (e.g., irradiance) so it need not be sampled at runtime. "Using and learning a pre-integrated and directionally smooth signal enables two important properties of our method"
- Probe grid: A regular grid of light probes used to cache irradiance in a scene. "We compare NIV against a modern probe grid, similar to DDGI~\cite{majercik2019dynamic}"
- Rasterization pass: A GPU-based pass computing primary visibility via triangle rasterization. "Primary visibility is provided to all methods using a rasterization pass and is not included in the timings."
- Ray tracing: Algorithmic technique that traces rays to compute visibility and light transport. "relying on expensive steps such as denoising and ray tracing makes them impractical under the strict runtime budgets of real-time applications."
- Relative L2 loss: A loss that normalizes MSE by prediction magnitude to stabilize training. "compute the relative L2 loss, normalizing the MSE by the squared network prediction"
- ReLU activations: The rectified linear unit function used as a nonlinearity in neural networks. "with ReLU activations applied at all but the final layer"
- Rendering equation: The integral equation that models radiative transfer in scenes. "Computing a noise-free solution to the rendering equation~\cite{kajiya1986rendering} of arbitrary scenes remains infeasible in real-time."
- Russian Roulette: Probabilistic termination of paths in Monte Carlo rendering to control computation. "which traces full-length paths with Russian Roulette."
- Spherical harmonics: Basis functions on the sphere used to represent low-frequency signals like irradiance. "second-order spherical harmonics (9 coefficients)~\cite{ramamoorthi2001efficient}"
- Stop gradient: An operation that prevents gradient updates from flowing through a value during backpropagation. "where denotes a stop gradient operation"
- Time-of-day cycle: A changing-lighting scenario achieved by rotating a directional light over time. "a rotating directional light source simulating a time-of-day cycle"
- Trilinear interpolation: Linear interpolation across three dimensions within a grid cell. "consists of simple trilinear interpolation of a few spherical harmonics coefficients."
- Upsampling methods: Techniques to reconstruct higher-resolution images from lower-resolution inputs. "could be partly resolved by using industry practice upsampling methods~\cite{kopf2007joint}."
- UV-parametrization: The mapping from 3D surfaces to 2D texture coordinates. "uv-parametrization issues."
- Variance: The randomness-induced error magnitude in Monte Carlo estimates. "increases variance in the final shading proportional to the deferred path depth."
Collections
Sign up for free to add this paper to one or more collections.