Forget Superresolution, Sample Adaptively (when Path Tracing)
Abstract: Real-time path tracing increasingly operates under extremely low sampling budgets, often below one sample per pixel, as rendering complexity, resolution, and frame-rate requirements continue to rise. While super-resolution is widely used in production, it uniformly sacrifices spatial detail and cannot exploit variations in noise, reconstruction difficulty, and perceptual importance across the image. Adaptive sampling offers a compelling alternative, but existing end-to-end approaches rely on approximations that break down in sparse regimes. We introduce an end-to-end adaptive sampling and denoising pipeline explicitly designed for the sub-1-spp regime. Our method uses a stochastic formulation of sample placement that enables gradient estimation despite discrete sampling decisions, allowing stable training of a neural sampler at low sampling budgets. To better align optimization with human perception, we propose a tonemapping-aware training pipeline that integrates differentiable filmic operators and a state-of-the-art perceptual loss, preventing oversampling of regions with low visual impact. In addition, we introduce a gather-based pyramidal denoising filter and a learnable generalization of albedo demodulation tailored to sparse sampling. Our results show consistent improvements over uniform sparse sampling, with notably better reconstruction of perceptually critical details such as specular highlights and shadow boundaries, and demonstrate that adaptive sampling remains effective even at minimal budgets.







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper is about making real-time, realistic graphics (called path tracing) look good even when a computer can only afford a tiny number of light samples per pixel—sometimes less than one per pixel. Instead of upscaling a low-resolution image (“superresolution”), the authors show how to be smart about where to spend those few samples (“adaptive sampling”), then clean up the result with a denoiser. Their method learns to place samples where your eyes are most likely to notice problems, so important details like sharp shadows and shiny highlights look right.
The main questions the paper asks
Here are the simple questions the authors set out to answer:
- If we have very few samples, can we place them more cleverly across the image so the final picture looks better to human eyes than with uniform sampling or superresolution?
- Can we train a neural network to decide where to place those samples—even though the choice “sample here or not” is a yes/no (discrete) decision?
- Can we make the training care about what people actually see (perception), not just raw pixel errors?
- What kind of denoiser works best when most pixels have no sample at all?
How they approached the problem
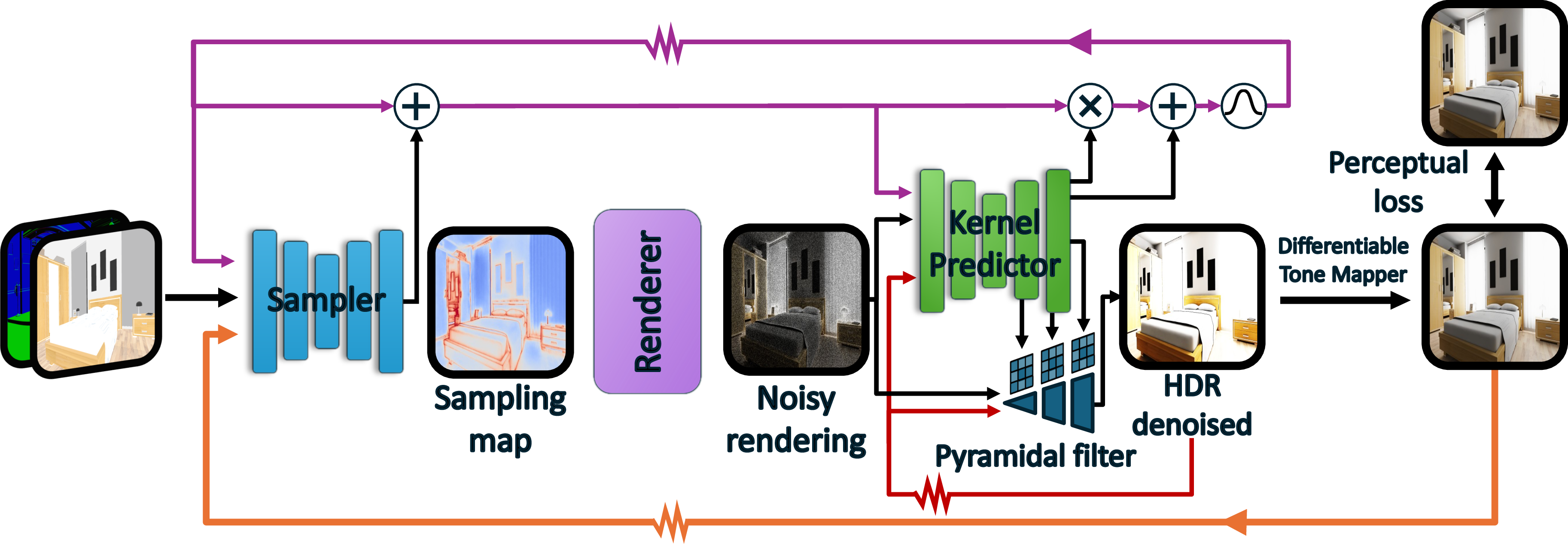
Think of rendering like painting a giant mural with only a handful of brush strokes. You want to put those strokes on the most noticeable parts—edges, shiny spots, and moving shadows—so the whole mural looks convincing. The authors built an end-to-end system that learns to do exactly that.
Their approach has four key ideas:
- Stochastic (probability-based) sampling decisions:
- Problem: Choosing which pixels to sample is a yes/no choice, which is hard to train with standard “smooth” math.
- Idea: Instead of saying “sample this pixel if its score ≥ 0.5,” treat the score like a probability. For example, a score of 0.3 means a 30% chance you’ll sample that pixel this frame.
- Why this helps: This turns a hard switch into a “lottery,” which lets gradients (the training signals) flow and the network learn where samples pay off the most.
- They also design a “relaxed” version of this lottery that’s fast to train and closely matches the real behavior at test time.
- Perception-aware training with tone mapping:
- Screens don’t show raw light; they tone-map it to fit what we see. The team builds a differentiable (trainable) film-like tone-mapper into training.
- They measure errors using a modern perceptual metric (MILO) that focuses on what people actually notice—like visible noise, blur, and color shifts—rather than treating every pixel equally.
- The sampler also looks at the previous frame’s tone-mapped image, so it can learn where viewers are likely to notice artifacts over time.
- A gather-based pyramidal denoiser:
- Denoisers often either “scatter” each sample’s influence outward or “gather” nearby samples into each output pixel.
- When samples are very sparse, gathering is more stable: every output pixel reaches out to collect whatever nearby information exists.
- They use a multi-scale (pyramidal) gather filter, predicting small per-pixel kernels at several scales to reconstruct clean detail without ringing or oversharpening.
- Learned demodulation (to keep textures vivid):
- High-frequency textures (like fabrics or logos) can lose color and crispness if you only average neighbors.
- Classic methods divide out “albedo” (base color) before filtering and multiply it back after. But getting perfect albedo is hard in modern renderers with complex materials.
- Their denoiser instead learns its own per-pixel “demodulation map” from scene buffers (like albedo and material hints), preserving rich textures and even picking up useful shading cues (like subtle darkening in corners).
What they found and why it matters
The authors tested their method at extremely low sampling budgets (even below 1 sample per pixel) and compared it to strong baselines, including modern superresolution pipelines.
Main findings:
- Sharper important details at minimal cost:
- Crisp shadow edges, small specular highlights, and fine metal details survive better than with uniform sampling or state-of-the-art upscalers.
- Their sampler learns to “budget” samples where the denoiser needs them most.
- Robust learning at very low sample rates:
- Thanks to the probability-based (stochastic) sampling and the relaxed estimator, the system remains trainable and stable even when many pixels don’t get sampled for several frames.
- Fewer wasted samples in places you won’t notice:
- By training with tone mapping and a perceptual loss, the system avoids overspending samples in dark or extremely bright areas where errors are barely visible.
- A denoiser that suits sparse data:
- The gather-based pyramid and learned demodulation reduce artifacts (like ringing) and keep saturated textures looking natural.
In short, the result is better-looking images where it counts, using the same tiny sample budget—often outperforming superresolution-based approaches in path-traced scenes.
Why this work is important
- Better real-time path tracing: Games and interactive apps can reach higher frame rates and resolutions while keeping the “wow” factors—shadows, reflections, and tiny highlights—looking right.
- Smarter use of GPU time: Instead of blurring everything evenly (as superresolution often does), the renderer concentrates effort where your eyes care the most.
- Plays nicely with modern pipelines: The tonemapper-aware training and learned demodulation fit today’s complex materials and post-processing stacks.
- A foundation for future systems: The probabilistic sampling trick and stable, sparse-friendly denoiser design can inspire next-gen real-time rendering methods, especially as scenes, effects, and neural materials get more complex.
Overall, the paper’s message is simple: when every sample is precious, don’t upsample uniformly—place your samples adaptively and denoise with perception in mind.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list summarizes what remains missing, uncertain, or unexplored based on the paper’s current scope and disclosures. Each point is intended to be concrete and actionable for future work.
- Inference-time performance and scalability: No end-to-end runtime breakdown (ms/frame) is provided for the sampler + denoiser at target resolutions and frame rates; the feasibility on current GPU tiers (desktop, console, mobile) and memory footprint of the 15M-parameter setup are not quantified.
- Budget split sensitivity: The choice to fix 1/8 of the budget uniformly and 7/8 adaptively is empirical; the impact of different splits across scenes, budgets, and resolutions remains unexplored and unoptimized.
- Ultra-sparse limits: Although the estimator is claimed robust down to ~0.01 spp, training and evaluation are reported for 0.11–4 spp; behavior and quality below 0.1 spp remain untested.
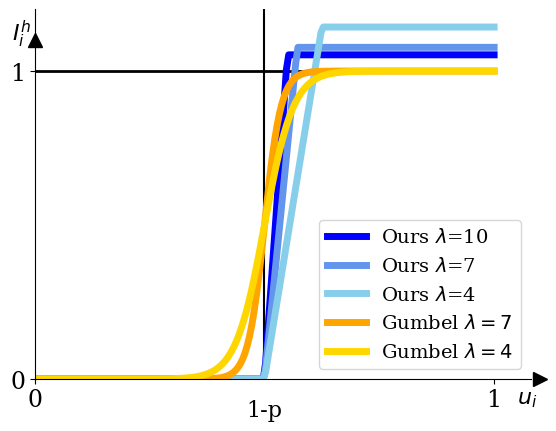
- Gradient estimator bias/variance: The relaxed stochastic rounding introduces a temperature λ and scaling factor h; the bias/variance trade-off, convergence properties, and sensitivity to λ across datasets and architectures lack a theoretical and comprehensive empirical analysis.
- Temporal sampling correlations: The paper does not specify how per-pixel random variates u_i (and blue-noise dithering) are temporally correlated; the impact on flicker, temporal stability, and motion-induced patterns is not systematically evaluated.
- Train–test mismatch for stochastic rounding: While a test-time replication is described, rare “tail” cases and long-horizon stability under different random seeds or deterministic seeding strategies are not studied.
- Interaction with modern spatiotemporal sampling (e.g., ReSTIR): How the learned sampler integrates with or complements reservoir-based reuse, spatiotemporal reuse, or light-sampling algorithms is not addressed.
- Generalization to difficult light transport: The approach’s robustness on participating media, subsurface scattering, caustics, strong glossy interreflections, neural/learned materials, and measured BRDFs is unproven given the training set and reported results.
- Learned demodulation interpretability and failures: The demodulation map can encode shading-like effects (e.g., AO); risks of leaking illumination into textures, inducing view/dependence artifacts, or causing color shifts are not quantified; constraints or regularization to maintain physical plausibility are not explored.
- Dependence on GBuffer quality: Robustness to aliased/noisy auxiliary buffers (normals, albedo, motion vectors), multi-layer compositing (translucency), motion blur, and depth-of-field is not rigorously benchmarked.
- Tonemapper generalization: Training uses a family of differentiable filmic operators; generalization to production TMOs outside this family, auto-exposure pipelines, local tone mapping, HDR display transfer functions (PQ/HLG), and color grading workflows is untested.
- Loss-function reliance: The use of MILO as a primary perceptual loss is not stress-tested against out-of-distribution distortions or content; comparisons with other perceptual objectives (e.g., VDPs, LPIPS variants) and human studies are missing to validate alignment with subjective quality in interactive content.
- Perception vs fidelity trade-offs: Optimizing for perceptual metrics may hallucinate or over-smooth certain details; a fidelity analysis against unbiased references (e.g., MSE/PSNR) and application-specific acceptability thresholds is absent.
- Temporal loss limitations: Training on two-frame windows does not address long-range temporal consistency, drift, and error accumulation across longer sequences or under scene cuts and rapid viewpoint changes.
- Cold-start behavior: The first-frame (or post-teleport/scene-load) sampling quality and recovery time are not characterized, despite relying on previous-frame feedback for both sampler and denoiser.
- Blue-noise pattern artifacts: The interaction of blue-noise dithering with camera motion and repetitive textures, and its potential to introduce structured artifacts or popping, is not examined; mitigation via spatiotemporal blue noise or scrambling strategies is not discussed.
- Resolution dependence: Claims that higher resolutions aid sample placement are not quantified; how the sampler scales across resolutions (including dynamic resolution) and tile-based GPUs remains open.
- Fair comparisons to super-resolution: Comparisons emphasize quality, but compute parity (or total frame budget parity) with DLSS/FSR/XeSS pipelines and hybrid pipelines (denoising + super-resolution) is not established.
- Hybrid strategies: Whether combining adaptive sampling with super-resolution (e.g., adaptive sampling at a lower internal resolution) yields better compute–quality trade-offs is not investigated.
- Dataset scope and domain gap: Training uses Falcor/Noisebase; the coverage of lighting/material/camera distributions, and generalization to production engines (different renderers/shaders/post-pipelines), is unclear.
- Pre-rendered training samples: The practice of composing arbitrary budgets from powers-of-two pre-rendered samples may not match the spatiotemporal noise characteristics of a live path tracer; the impact on learned policies at inference time is unknown.
- Robustness to dynamic content: Systematic evaluation under rapid lighting changes, highly dynamic geometry, heavy occlusion/disocclusions, and aggressive camera motion is limited to qualitative examples without comprehensive failure analysis.
- Allocation granularity and fairness: The softmax normalization allocates budget globally, but constraints such as per-tile budgets, GPU scheduling constraints, or variable-rate shading are not modeled; fairness/stability under such constraints is an open integration question.
- Denoiser design limits: The gather-based pyramidal filter shows qualitative gains, but sensitivity to kernel sizes, receptive field limits, and robustness to very sparse neighborhoods (e.g., isolated samples) needs quantification and comparison with alternative architectures.
- Energy conservation and bias after denoising: While the stochastic estimator is unbiased in expectation before denoising, the combined adaptive sampling + denoising pipeline’s bias (energy conservation, color shifts) is not measured across scene types.
- Practical deployment and training: Retraining/fine-tuning costs (5 days on H100) for new content domains, incremental learning strategies, and model compression/pruning for real-time deployment are not addressed.
- Reproducibility and ablations: The paper promises code/data release upon acceptance; until then, ablations on key components (e.g., demodulation on/off, temporal kernels, TMO variants, different λ, different uniform/adaptive splits) and result reproducibility remain difficult to verify.
Practical Applications
Immediate Applications
The following applications can be deployed now or in the near term by integrating the paper’s adaptive sampling and denoising pipeline into existing rendering stacks. They leverage the method’s stochastic differentiable sampler, gather-based pyramidal denoiser, and tonemapper-aware training with perceptual loss (MILO).
Industry
- Interactive path-traced rendering in game engines (software/gaming)
- Use case: Replace uniform sampling or reliance on super-resolution for path-traced effects with the proposed adaptive sampler + gather-based denoiser to preserve shadow boundaries, specular highlights, and fine details at sub-1-spp.
- Workflow: Integrate as an engine plugin (e.g., Unreal/Unity or Falcor-based stacks), feed GBuffer + previous-frame tonemapped output to the sampler, render stochastically discretized sample map, reconstruct with gather pyramid, tonemap, and loop.
- Dependencies/assumptions:
- Real-time path tracing available (RT cores and GPU drivers).
- Access to GBuffer (depth, normals, albedo/tints), temporal reprojection, and tonemapper output.
- A minimal uniform sampling floor (e.g., 1/8 budget) to stabilize learning.
- Pretrained model suitable for engine materials and tonemapper; MILO loss used during training.
- Potential tools/products: SDK or engine plugin (Adaptive Sampler + Gather Denoiser), presets tuned for popular tonemappers, optional co-existence with DLSS/FSR/XeSS.
- DCC look-dev and VFX interactive viewport (media/entertainment)
- Use case: Faster, more faithful previews with limited spp; better texture saturation via learned demodulation without renderer-side albedo decomposition.
- Workflow: Adopt gather pyramid and learned demodulation in interactive viewport; feed tonemapped output from previous frame for perceptual alignment.
- Dependencies/assumptions: Existing path-tracing in DCC tools (e.g., Arnold, RenderMan, Cycles), stable GBuffer extraction even under motion blur/DOF.
- Architectural visualization and CAD walkthroughs (design/engineering)
- Use case: High-detail path-traced walkthroughs at 60–120 fps with sparse sampling, retaining crisp edges and reflective detail where users look or move.
- Workflow: Integrate pipeline into archviz/CAD viewers; leverage perceptual loss to prioritize visually critical regions under tight budgets.
- Dependencies/assumptions: Support for temporal reprojection and motion vectors; real-time path tracing; tuned tonemapper profiles.
- Cloud gaming and remote rendering (software/infrastructure)
- Use case: Reduce server-side GPU utilization per frame by concentrating samples on perceptually important regions; keep frame quality at low spp.
- Workflow: Deploy pretrained models across heterogeneous content; monitor perceptual quality (MILO or similar) and energy-per-quality metrics.
- Dependencies/assumptions: Model generalizes across diverse titles; compatible tonemapper feedback; sufficient telemetry to evaluate perceptual outcomes.
- Virtual production LED volumes and digital twins (media/industry simulation)
- Use case: Real-time path-traced backgrounds and environments with higher perceptual fidelity under strict frame budgets.
- Workflow: Incorporate sampler-denoiser loop as a rendering profile for virtual stages; tune demodulation to complex materials/neural BRDFs.
- Dependencies/assumptions: Stable temporal data; consistent tonemapping; robust model to illumination changes and volumetrics.
Academia
- Differentiable discrete decision training for rendering (computer graphics / ML)
- Use case: Adopt the stochastic rounding relaxation for end-to-end training of discrete sampling decisions (e.g., pixel selection at sub-1-spp).
- Workflow: Use paper’s estimator (temperature λ ~ 8–12) to backpropagate through sampling; compare against straight-through and finite difference baselines.
- Dependencies/assumptions: Access to pre-rendered multi-spp datasets; Falcor pipeline or equivalent; MILO loss for perceptual alignment.
- Perception-aware training protocols (vision / graphics)
- Use case: Benchmark losses in tone-mapped sRGB, using differentiable filmic curves and perceptual metrics (MILO) vs SMAPE/Log-L1.
- Workflow: Experiment with TMO parameter distributions; ablate perceptual gains in sparse regimes; quantify visibility weighting and masking effects.
- Dependencies/assumptions: License/access to MILO; datasets covering varying luminances and distortions; robust TMO generalization.
Policy
- Energy efficiency targets for real-time rendering (sustainability)
- Use case: Encourage adoption of perceptual adaptive sampling to lower GPU time-per-quality; establish “quality-per-watt” reporting.
- Workflow: Define measurement protocols using perceptual metrics (MILO/SSIM variants) alongside power draw telemetry.
- Dependencies/assumptions: Industry buy-in; standardized test scenes; transparent reporting frameworks.
Daily Life
- Better ray-traced visuals on mid-tier hardware (consumer computing)
- Use case: Sharper path-traced shadows/reflections at playable frame rates on laptops and consoles.
- Workflow: Shipping games enable adaptive sampling presets; provide “eco/perceptual” modes in graphics settings.
- Dependencies/assumptions: Game engine integration; chipset driver support; optional updates to upscalers and tonemappers.
Long-Term Applications
These applications are feasible but require further research, engineering, or scaling, including robustness across content, hardware support, and extensions to new domains.
Industry
- Hardware–software co-design for stochastic sample placement (semiconductors / software)
- Use case: Expose GPU-level primitives for blue-noise–based stochastic discretization and fast gather filters; driver-level support for probabilistic sample allocation.
- Workflow: Vendor APIs for per-pixel sample probabilities; firmware scheduling; RT core synergy with adaptive sampling.
- Dependencies/assumptions: GPU vendor collaboration; standardized resource scheduling; validation across diverse scenes.
- Hybrid pipelines: adaptive sampling + super-resolution (software/gaming)
- Use case: Combine perceptual adaptive sampling with upscalers (DLSS/FSR/XeSS) to further reduce cost while preserving path-traced details where they matter most.
- Workflow: Joint tuning of sampling maps and SR settings; cross-stage perceptual loss; dynamic resolution informed by sampler’s density map.
- Dependencies/assumptions: Avoid conflict between SR’s uniform upscaling and adaptive sample allocation; robust temporal stability.
- Mobile and XR deployment (AR/VR)
- Use case: Low-power headsets and mobile devices perform sparse path tracing; adaptive sampling minimizes energy while preserving critical cues.
- Workflow: Distill the 15M-parameter network to lightweight real-time variants; optimize for mobile GPUs; latency-aware temporal loop.
- Dependencies/assumptions: Efficient architectures; reduced memory footprints; head-mounted display tonemapper characteristics; tight motion-to-photon constraints.
- Volumetric and complex material rendering (software/graphics)
- Use case: Extend learned demodulation and gather filters to volumes, measured BRDFs, and neural materials without clean albedo decomposition.
- Workflow: Train with richer GBuffer proxies (e.g., learned material embeddings); develop volumetric-aware kernels.
- Dependencies/assumptions: New datasets capturing volumetrics and complex optical effects; robust demodulation learning; improved temporal stability.
Academia
- Generalized differentiable allocation for Monte Carlo simulations (ML / scientific computing)
- Use case: Apply the stochastic rounding relaxation to other budgeted sampling problems (e.g., adaptive ray budgets, sensor scheduling) where discrete decisions hamper gradient flow.
- Workflow: Formulate exploration–exploitation trade-offs for sparse regimes; compare gradient estimators; integrate with RL and Bayesian methods.
- Dependencies/assumptions: Differentiable simulators or suitable surrogates; task-specific perceptual or utility losses; analytical gradient approximations.
- Perceptual standards and evaluation (graphics / HCI)
- Use case: Establish best practices for tone-mapper–aware training and evaluation with perceptual metrics tailored to ray-traced distortions.
- Workflow: Cross-dataset studies; user trials to calibrate losses (MILO/SSIM/LPIPS variants); standardized benchmarks for sparse path tracing.
- Dependencies/assumptions: Community datasets; reproducible pipelines; consensus on TMO ranges.
Policy
- Interoperability and standardization of perceptual rendering metrics (standards bodies / consortia)
- Use case: Define guidelines for perceptual quality reporting in shipping titles and tools; encourage energy-perceptual-quality certifications.
- Workflow: Industry working groups align on TMO parameter reporting, perceptual metric choices, and testing protocols.
- Dependencies/assumptions: Broad stakeholder participation; commitment to transparency; lifecycle impact assessments.
Daily Life
- Perceptual “eco modes” and accessibility profiles (consumer computing)
- Use case: Device-level profiles modulate sampling to maximize battery life while maintaining perceived quality; accessibility presets adapt sampling to user sensitivity.
- Workflow: OS-level graphics controls; per-app profiles; user-tunable tone mapping and perceptual prioritization.
- Dependencies/assumptions: OS and driver features; UI/UX for perceptual settings; diverse user testing.
Notes on Feasibility and Dependencies
- Model availability: The paper indicates dataset and code will be released upon acceptance; immediate adoption depends on access to trained models and reproducibility.
- Data and training cost: Training uses large pre-rendered datasets (up to 256 spp) and high-end GPUs (e.g., H100, ~5 days). Production adoption may require model distillation and incremental retraining per engine or content domain.
- Tonemapper variance: Inference-time TMO can differ from training; extreme mismatches may degrade sampler alignment. Teams should curate a set of representative TMOs during training.
- GBuffer quality and temporal stability: Accurate depth/normals/albedo and reliable motion vectors are critical; failure cases (DOF, motion blur, disocclusions) need careful testing and may benefit from the learned demodulation approach.
- Budget partitioning: The method assumes a uniform floor plus adaptive distribution (e.g., 1/8 uniform, 7/8 adaptive). Changing this partition may affect convergence and stability.
- Integration with existing upscalers/denoisers: Co-deployment requires tuning to avoid oversmoothing or artifacts; testing across materials, lighting, and camera motion is necessary.
Glossary
- Adaptive sampling: Dynamically distributing rendering samples across pixels based on estimated difficulty or perceptual importance to improve quality under a fixed budget. "Adaptive sampling plays a crucial role in Monte Carlo rendering, where noise in the produced images is not uniformly distributed across the entire image."
- AdamW: An optimization algorithm that decouples weight decay from gradient-based updates, improving training stability and generalization. "using the AdamW optimizer"
- Albedo: The intrinsic surface reflectance (base color) independent of illumination, often stored in rendering buffers. "depth, normals, and albedo"
- Albedo demodulation: A technique that divides out albedo before filtering and remultiplies afterward to preserve texture detail during denoising. "Prior albedo demodulation addresses this by dividing out the material's reflectance before filtering, then remodulating afterward."
- Ambient occlusion: A shading effect that darkens crevices and corners to approximate occlusion of ambient light. "producing darkening at corners and crevices that visually resembles ambient occlusion"
- Blue noise dithering: A sampling strategy that uses blue-noise patterns to distribute samples with minimal low-frequency artifacts. "implemented using blue noise dithering"
- BRDF (Bidirectional Reflectance Distribution Function): A function describing how light is reflected at a surface for given incoming and outgoing directions. "measured BRDFs"
- Central Limit Theorem: A statistical principle stating that averages of independent random variables tend toward a normal distribution as sample count increases. "thanks to the Central Limit Theorem."
- Cosine annealing schedule: A learning-rate schedule that follows a cosine curve over time to improve convergence. "We decay the learning rate following a cosine annealing schedule"
- DLSS 4 Ray Reconstruction: A production upscaling and reconstruction method from NVIDIA for real-time graphics. "DLSS 4 Ray Reconstruction"
- Denoiser: An algorithm or neural network that reduces Monte Carlo noise to reconstruct a clean image from sparse or noisy inputs. "The denoiser receives the noisy image"
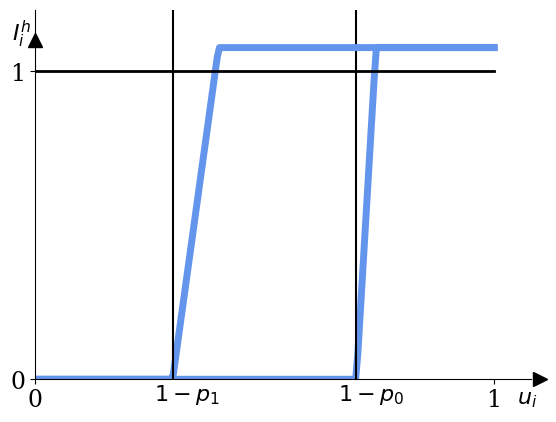
- Deterministic rounding: Converting continuous sample densities to integers via fixed thresholds or rounding, yielding zero gradients almost everywhere. "Deterministic rounding for learnable adaptive sampling was first proposed by"
- Fresnel: Angle-dependent reflectance at interfaces, influencing specular intensity and color. "specular tint, and Fresnel information"
- GBuffer: A set of per-pixel geometric and material attributes (e.g., depth, normals, albedo) used in deferred rendering and denoising. "Given GBuffer features and temporal data from the previous frame"
- Gathering kernels: Filtering kernels predicted at each output pixel that aggregate contributions from neighboring sampled inputs. "Gathering kernels (a) weigh the neighbouring sparse samples for every output pixel."
- GumbelâSoftmax relaxation: A differentiable approximation to categorical sampling that enables gradient flow through discrete choices. "Following the GumbelâSoftmax relaxation"
- HDR (High Dynamic Range): Imaging that represents a wide range of luminance levels beyond standard display capabilities. "The denoised HDR output is tonemapped for display"
- Inverse-variance weighting: Weighting samples proportionally to the inverse of their variance to improve estimator efficiency. "providing inverse-variance weighting."
- Kernel prediction: A neural denoising approach that predicts spatially varying filter kernels instead of direct pixel values. "kernel prediction techniques that learn per-pixel kernel parameters"
- Learned demodulation: A model-predicted per-pixel map used to demodulate/remodulate colors, preserving textures without relying on renderer-provided albedo decomposition. "Learned demodulation and effect of gather vs scatter pyramids."
- LPIPS: A deep-feature–based perceptual similarity metric used to evaluate visual similarity between images. "and LPIPS"
- MILO: A perceptual loss/metric trained on human opinion data that models distortion visibility and masking effects. "we adopt the MILO metric"
- Monte Carlo estimator: A statistical estimator formed from random samples to approximate integrals (e.g., radiance) in rendering. "Monte Carlo estimators do not follow such an analytic distribution at low sample counts."
- Monte Carlo rendering: Rendering via stochastic sampling of light transport to approximate physically based images. "Adaptive sampling plays a crucial role in Monte Carlo rendering"
- Noisebase dataset: A dataset of path-traced sequences used for training and evaluating denoising and sampling methods. "We extend the Noisebase dataset"
- Path tracing: A Monte Carlo method that simulates light transport by tracing random paths through a scene. "Real-time path tracing increasingly operates under extremely low sampling budgets"
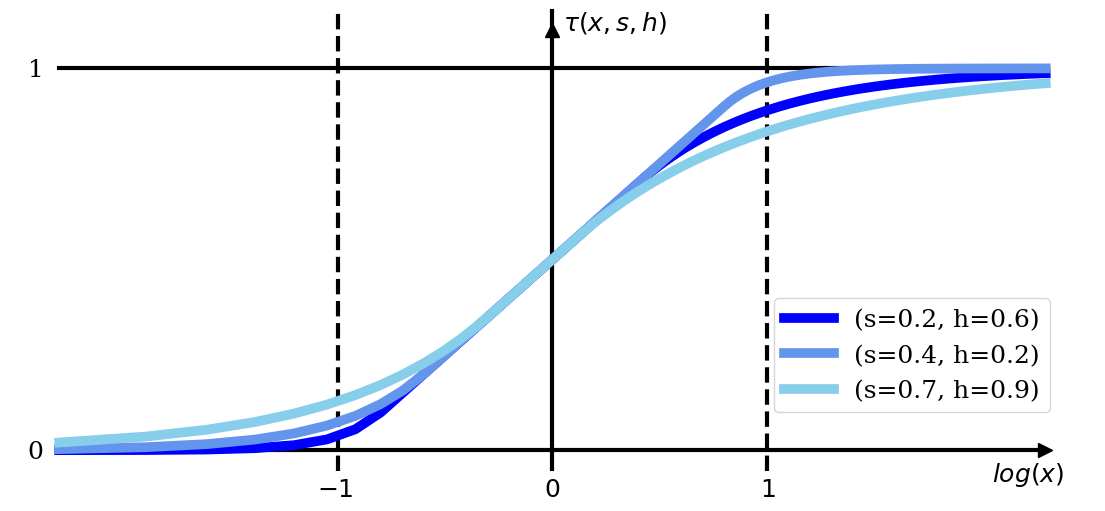
- Photographic TMO: A tone mapping operator inspired by photographic response curves applied in log space. "equivalent to Photographic TMO in log-space"
- Pyramidal gather filter: A multiscale denoising filter that gathers samples across pyramid levels for robust reconstruction under sparsity. "predicts weights for our pyramidal gather filter"
- Reinforcement learning: An optimization framework where policies are learned via rewards, applied here to sampling map optimization. "uses reinforcement learning to optimise the sampling network"
- sRGB: A standard display-referred color space used for perceptual metrics and tone-mapped evaluation. "in the sRGB domain"
- Shadow boundaries: The edges of shadows where intensity changes sharply and reconstruction is challenging. "specular highlights and shadow boundaries"
- Specular highlights: Bright reflections from shiny surfaces that require careful sampling and reconstruction. "specular highlights and shadow boundaries"
- SSIM/MS-SSIM: Structural similarity metrics for measuring image fidelity based on luminance, contrast, and structure. "SSIM/MS-SSIM"
- spp (samples per pixel): The average number of path-tracing samples computed per pixel. "sub-1-spp regime"
- Stochastic rounding: Probabilistic rounding based on the fractional part of a sample density to enable differentiable discrete decisions. "We apply the principle of stochastic rounding to the adaptive sampling setting"
- Straight-through estimator: A heuristic gradient estimator that passes gradients through non-differentiable operations unchanged. "straight-through estimator"
- Super-resolution: Upscaling images rendered at reduced resolution to full resolution, often with learned methods. "Super-resolution is an alternative method to improve performance by rendering at a reduced resolution and upscaling the result to full resolution."
- Temporal kernels: Denoising kernels that gather information from previous frames to improve temporal consistency. "we additionally predict temporal kernels"
- Tone mapping operator (TMO): A function that maps HDR values to display-referred values, often parameterized and differentiable for training. "tone mapping operators (TMO)"
- Tonemapper-aware training: Training that explicitly incorporates tone mapping and perceptual losses to align optimization with human perception. "Tonemapper aware training"
- U-Net: An encoder–decoder neural architecture with skip connections widely used in image-to-image tasks. "Both the sampler and denoiser are implemented as U-Net encoder-decoders."
Collections
Sign up for free to add this paper to one or more collections.