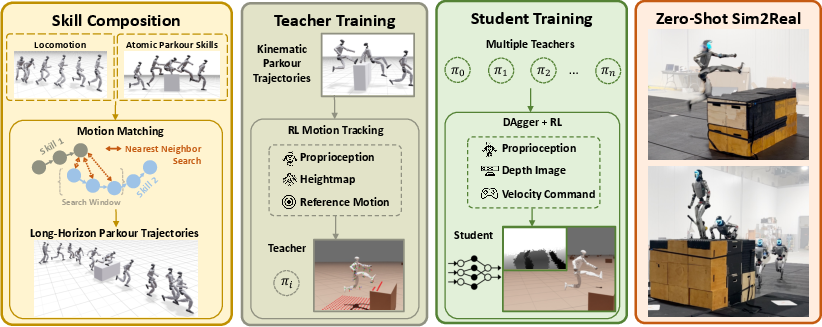
Perceptive Humanoid Parkour: Chaining Dynamic Human Skills via Motion Matching
Abstract: While recent advances in humanoid locomotion have achieved stable walking on varied terrains, capturing the agility and adaptivity of highly dynamic human motions remains an open challenge. In particular, agile parkour in complex environments demands not only low-level robustness, but also human-like motion expressiveness, long-horizon skill composition, and perception-driven decision-making. In this paper, we present Perceptive Humanoid Parkour (PHP), a modular framework that enables humanoid robots to autonomously perform long-horizon, vision-based parkour across challenging obstacle courses. Our approach first leverages motion matching, formulated as nearest-neighbor search in a feature space, to compose retargeted atomic human skills into long-horizon kinematic trajectories. This framework enables the flexible composition and smooth transition of complex skill chains while preserving the elegance and fluidity of dynamic human motions. Next, we train motion-tracking reinforcement learning (RL) expert policies for these composed motions, and distill them into a single depth-based, multi-skill student policy, using a combination of DAgger and RL. Crucially, the combination of perception and skill composition enables autonomous, context-aware decision-making: using only onboard depth sensing and a discrete 2D velocity command, the robot selects and executes whether to step over, climb onto, vault or roll off obstacles of varying geometries and heights. We validate our framework with extensive real-world experiments on a Unitree G1 humanoid robot, demonstrating highly dynamic parkour skills such as climbing tall obstacles up to 1.25m (96% robot height), as well as long-horizon multi-obstacle traversal with closed-loop adaptation to real-time obstacle perturbations.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper shows how a human-shaped robot (a humanoid) can do parkour—fast, agile moves like vaulting over obstacles and climbing tall walls—by seeing the world with its own camera and choosing the right skills on the fly. The team built a system called Perceptive Humanoid Parkour (PHP) that lets one robot “brain” smoothly chain many human-style moves together and adapt to obstacles it sees in front of it.
What did the researchers want to find out?
They wanted to make humanoid robots:
- Move with human-like agility, not just walk or step slowly.
- Decide which skill to use (step, climb, vault, roll) based on what the robot’s camera sees.
- Stitch many short, dynamic moves into a long, smooth run without awkward pauses.
- Learn in simulation and then work in the real world without extra fine-tuning.
How did they do it?
The approach combines ideas from animation, teaching, and trial-and-error learning. Here’s the recipe, explained in everyday terms.
Teaching the robot human moves with “motion matching”
- Think of “motion matching” like editing a highlight reel: you have a library of short human motion clips (tiny video-like snippets of specific skills), and you pick the next clip that best fits what you’re doing now and where you want to go.
- The robot uses this to plan long, smooth sequences: run → do a parkour skill → run again. Running acts like a universal “connector” between skills.
- Even if the original human recordings are short and scarce, motion matching mixes and stitches them into many different transitions (for example, entering a vault from different speeds or foot positions). This gives the robot lots of practice examples with varied approaches and timings.
Training “expert teachers,” then a single “student”
- First, they trained several “expert” controllers in simulation—each expert focuses on tracking one composed motion extremely well (like a perfect coach for climbing or vaulting). These experts get extra state information that the real robot wouldn’t have; this is called “privileged” info.
- Next, they taught one “student” controller that works with the robot’s actual sensors (a depth camera) to imitate the experts across all skills.
- They used two learning styles together:
- Imitation learning (DAgger): the student copies the experts’ actions, like following a teacher’s demonstrations.
- Reinforcement learning (PPO): the student also gets rewards for success, pushing it to do what actually works, not just what looks close to the expert.
- Why both? Copying alone can make the student too cautious. Rewards help it commit to powerful, well-timed actions (like the brief, strong pull needed to climb a wall) that make the move succeed.
Giving the robot “eyes” and making it transfer to reality
- The robot uses a depth camera, which measures how far things are—like a dot-based 3D view of obstacles.
- They carefully simulated the camera’s position, noise, and delay to match the real hardware, so the student trained in simulation could work on the real robot “zero-shot” (without extra fine-tuning).
What did they discover?
The system worked on a real Unitree G1 humanoid robot and achieved strong results:
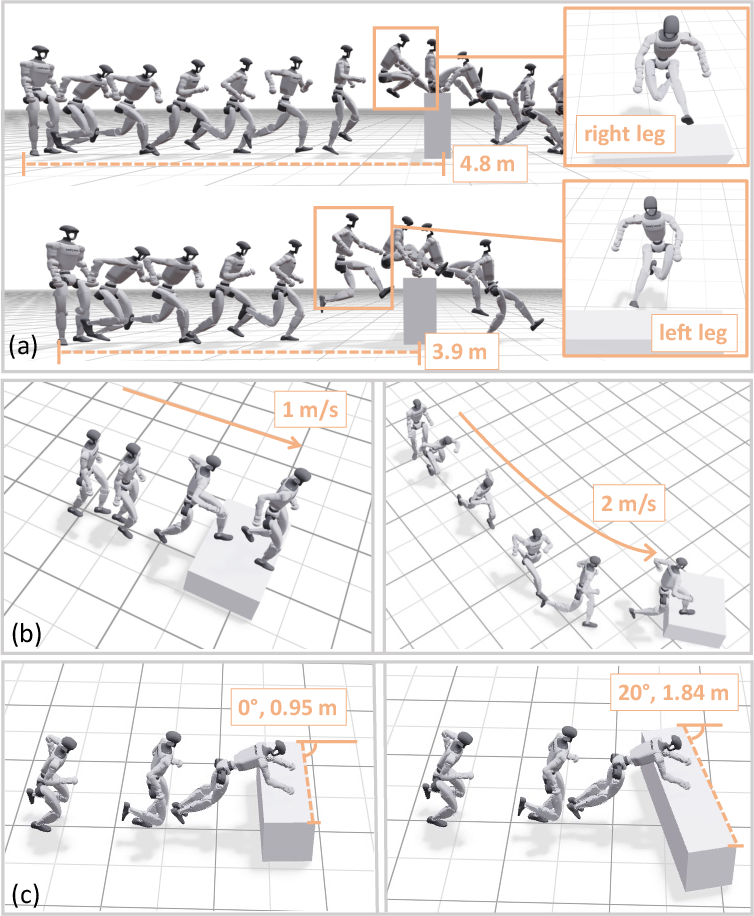
- Human-level agility on a tall wall:
- The robot climbed onto a 1.25 m wall (about 96% of its height) in about 3.6 seconds from takeoff—comparable timing to a trained human doing the same sequence.
- High-speed vaults and dynamic moves:
- The robot performed vaults at roughly 3 m/s, clearing obstacles quickly while keeping forward speed for continued running.
- Long, continuous runs with smooth transitions:
- It completed a 48–60 second parkour course with multiple obstacles, switching skills smoothly while running.
- Real-time adaptation:
- If obstacles were moved mid-run (about 0.5 m shifts), the robot adjusted its approach and timing and continued the traversal.
- Strong performance compared to baselines in simulation:
- Methods that relied only on reward shaping or only on raw motion clips struggled on higher obstacles.
- The PHP approach had very high success rates across different heights and speeds, especially on the most dynamic skills (vaults and climbs).
Why does this matter?
This research shows a practical path to truly agile humanoid movement:
- It solves a common data problem: dynamic human motion clips are short and scarce. Motion matching turns them into many usable, long, varied sequences without needing massive new datasets.
- It blends perception and decision-making: the robot doesn’t just run a script; it sees obstacles and chooses the right skill in the moment.
- It scales to many skills: combining expert “teachers” with a single “student” controller means one brain can do many complex moves smoothly.
- It transfers from simulation to reality: careful camera modeling and training design make the jump to hardware possible without extra fine-tuning.
In the future, this could help humanoid robots handle complex, cluttered spaces—like warehouses, disaster zones, or construction sites—where fast, whole-body agility and smart, perception-driven decisions are essential. Adding better sensors and grippers, or even language guidance, could expand to more advanced climbing and richer scene understanding, bringing robots closer to human-level movement in the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, framed as concrete questions or limitations to guide future research:
- Limited semantic understanding: the policy relies on depth-only geometry without semantic reasoning (e.g., distinguishing edges, rails, bars, or affordances). How to integrate semantics (segmentation, affordance detection) or language-conditioned goals to drive skill selection and style?
- Short-range, narrow-FOV perception at high speeds: obstacles may not be visible early enough for safe commitment. What perception stacks (multi-camera, panoramic fisheye, stereo/LiDAR fusion, event cameras) and look-ahead planners are needed to increase preview distance?
- No global mapping or memory: decisions are based on instantaneous frames; there is no SLAM or temporal memory to reason about occlusions or future landing zones. Can memory-augmented policies or map-based planning improve long-horizon decision-making?
- Hardware limitations in hands/grippers: current end-effectors limit edge-, rail-, or bar-based maneuvers (e.g., hangs, dynos, over-height climbs). What gripper designs and controllers enable reliable high-force, high-rate hand contacts?
- Generalization beyond the motion library: the skill set is limited to a few parkour primitives and retargeted clips. How to scale to dozens or hundreds of skills, and to unseen obstacles and tasks not represented in the library?
- Manual annotation burden: skill start/end frames and pre-skill “entry windows” are manually specified. Can automated phase/contact detection learn entry/exit points and windows from data?
- Hand-crafted motion-matching features: nearest-neighbor retrieval uses designed features and fixed windows. Would learned embeddings, differentiable retrieval, or terrain-conditioned retrieval improve transition quality and coverage under sparse data?
- Composition via locomotion only: transitions are constrained to “locomotion → skill → locomotion.” How to enable direct transitions between non-locomotion skills (e.g., vault → climb) without requiring locomotion interludes?
- Terrain fitting for references: references are generated by placing terrain relative to the motion clip; real-world obstacles won’t match this placement. How to perform on-the-fly trajectory fitting/warping to sensed geometries with contact-consistency guarantees?
- Limited terrain randomization: geometry perturbations are small (±5 cm, yaw ±45°) and widths capped; slippery, compliant, deformable, or uneven surfaces are not considered. How to broaden randomization and validate on OOD terrains?
- Sensor artifact modeling: depth noise is injected but excludes motion blur and realistic outdoor artifacts (e.g., sunlight interference, multipath, rolling shutter). How to robustify to real sensor degradation and environment-specific artifacts?
- Sim-to-real contact fidelity: contact modeling (friction, compliance, hand-surface interactions) is not deeply analyzed. What physical parameters most affect transfer, and can tactile feedback or online adaptation reduce mismatch?
- Success vs. style: human-like expressiveness is claimed but not quantified; trade-offs between task success and motion style are not measured. What metrics (e.g., style classifiers, kinematic similarity) or constraints can enforce expressiveness?
- Real-world evaluation scope: hardware results are qualitative with limited task diversity and no success-rate statistics or failure breakdowns across environments. Establish standardized benchmarks and report quantitative performance (success, recovery, falls, energy, impact forces).
- Safety and risk management: fall detection, impact mitigation, and safe recovery behaviors are not discussed. How to integrate risk-aware control, safety envelopes, and certified recovery policies at high speeds?
- Latency and onboard compute: real-time inference rates, latency budgets, and compute platforms are not detailed. What model compression or scheduling is needed to guarantee bounded end-to-end latency at higher speeds?
- Sample efficiency and compute cost: training uses 16,384 environments and large networks; time-to-train and data budgets are not reported. Can offline RL, dataset aggregation, or distillation-efficient methods reduce compute?
- DAgger–RL curriculum sensitivity: the weighting schedule between imitation and RL is hand-tuned; stability and convergence are not theoretically grounded. Can uncertainty-aware or adaptive weighting strategies reduce tuning burden?
- Handling multimodality and symmetry: left/right mirrored executions are addressed by relaxed termination but not modeled explicitly. Would symmetry-aware objectives, latent-mode policies, or mixture-of-experts improve stability and coverage?
- Continual learning of new skills: the impact of adding skills over time (catastrophic forgetting, interference) is not studied. How to support modular expansion, incremental distillation, or skill-slotting without retraining from scratch?
- End-to-end visuomotor training: the end-to-end baseline underperforms but leaves open whether better exploration (e.g., curriculum, demonstrations, diffusion-guided exploration) can rival expert-distilled policies without per-skill teachers.
- Cross-robot transfer and morphology: results are limited to a Unitree G1; portability to other humanoids with different dimensions, actuation, or torque limits is untested. What normalization/retargeting strategies enable zero-shot cross-morphology transfer?
- Dynamic/moving obstacles: only small, manual obstacle displacements are tested; reactive parkour with moving obstacles or crowds is unexplored. How to integrate prediction and online re-timing for moving environments?
- Long-duration robustness: demonstrations up to ~60 s leave open questions about drift, thermal limits, battery, and cumulative error over minutes. What mechanisms (re-localization, periodic re-synchronization) maintain performance over extended runs?
- Depth-only dependence: failure modes with transparent/reflective materials, low-texture surfaces, or depth dropouts are unaddressed. How to fuse RGB, IMU, proprioception, and possibly tactile to recover under depth failures?
- Hyperparameter and design choices: action scaling, termination thresholds, and motion-tracking reward compositions are fixed; ablations are limited. What principled methods choose these automatically for new skills?
- Benchmarking against alternative kinematic generators: comparisons to diffusion-based trajectory generators (e.g., MDM) or AMP-style multi-skill controllers are limited. Rigorous head-to-head comparisons could clarify when motion matching is preferable.
- Reference-timing generalization: performance hinges on dense approach-distance coverage during motion matching; generalizing contact timing from sparse data remains open. Can timing policies be learned to extrapolate beyond observed approach conditions?
- Interpretability and monitoring: the unified policy implicitly selects skills; there is no explicit skill label stream for introspection or safety monitoring. How to expose interpretable skill/phase estimates during execution?
- Reproducibility and community benchmarks: the motion library, composition tools, and datasets are not stated as publicly available. Open-sourcing standardized libraries and test suites would enable fair comparisons and rapid progress.
Practical Applications
Immediate Applications
The following applications can be deployed now in controlled or semi-structured environments, leveraging the paper’s motion-matching skill composition and depth-based, multi-skill policy with zero-shot sim-to-real transfer.
- Humanoid parkour showcase and experiential demos
- Sector: entertainment, marketing, education
- Use case: Deploy Unitree G1 or similar humanoids to perform dynamic, long-horizon demonstrations (vaults, climbs, sustained multi-obstacle runs) at trade shows, theme parks, campus open houses, and public STEM events.
- Potential tools/products/workflows: “Parkour Demo Pack” with precomposed motion-matching trajectories and a unified student policy; simple velocity teleoperation UI; safety geofencing tooling; standard obstacle course configurations with documented dimensions.
- Assumptions/dependencies: Controlled courses and crowd management; obstacle geometries within trained ranges (e.g., up to ~1.25 m wall, specific widths/yaws); adequate actuator power and battery capacity; liability coverage and emergency stop procedures.
- Humanoid mobility in cluttered industrial testbeds
- Sector: robotics, manufacturing/logistics
- Use case: Traverse low platforms, pallets, shallow ledges, or ad-hoc obstacles in test environments to evaluate mobility readiness (e.g., stepping onto low platforms or short climbs), without task-side manipulation.
- Potential tools/products/workflows: ROS-integrated “Perceptive Teleop Assist” (operator sends 2D velocity; policy autonomously selects step/climb/vault); motion-matching trajectory generator tailored to facility mock-ups; rapid camera calibration and depth-noise modeling toolkit for sim-to-real.
- Assumptions/dependencies: Operation in fenced test areas; depth camera field-of-view and latency calibrated per paper’s WARP-based pipeline; obstacles within policy’s trained shape/pose perturbations; no human cohabitation during high-energy maneuvers.
- Search-and-rescue (SAR) training grounds evaluation
- Sector: public safety, emergency response
- Use case: Evaluate humanoids’ ability to traverse rubble-like obstacle courses (low-height climbs, narrow platforms) for mobility baselining in SAR training fields.
- Potential tools/products/workflows: Parkour-style mobility benchmark and evaluation rubric; course setup guide with randomized obstacle yaw/width; unified student policy with adaptive timing under obstacle displacement.
- Assumptions/dependencies: Non-deployed evaluation only; obstacle sizes matched to the trained distribution; limited environmental variability (lighting/weather); remote operation with emergency stop.
- Academic benchmarking for long-horizon skill chaining
- Sector: academia, research
- Use case: Standardize evaluation of multi-skill chaining and sim-to-real transfer for humanoid control, comparing motion-matching vs. learned kinematics vs. reward-shaped RL.
- Potential tools/products/workflows: Open-sourced motion-matching dataset synthesis scripts; “atomic skill” libraries with entry windows; teacher-student distillation code (DAgger+PPO curriculum); WARP-based depth rendering for high-throughput simulation.
- Assumptions/dependencies: Access to compute (≥16k envs ideal); retargetable human motion data and terrain assets; Unitree G1 or similar platform for hardware trials.
- Robotics education modules
- Sector: education
- Use case: Course labs teaching motion retargeting, motion matching, expert tracking, and hybrid DAgger+RL distillation for multi-skill policies.
- Potential tools/products/workflows: Modular teaching kit (OmniRetarget → motion matching → expert RL → distillation → sim-to-real); calibrated depth camera emulator; scaffolded assignments on ablations (dataset density, reward designs).
- Assumptions/dependencies: Simulation-first delivery; optional hardware extension for advanced cohorts; curated datasets of safe skills.
- Tooling for sim-to-real depth perception and calibration
- Sector: software, robotics
- Use case: Adopt camera extrinsic randomization, depth noise injection, and latency modeling across robot projects to close perception gaps without costly photorealistic rendering.
- Potential tools/products/workflows: “Depth Transfer Toolkit” (WARP rendering, ROI-based self-visibility matching, latency randomization, artifact injection); automated calibration scripts.
- Assumptions/dependencies: Known sensor model; consistent mounting; validation poses; developer familiarity with Python/CUDA workflows.
Long-Term Applications
These applications require additional research, scaling, and engineering, particularly in perception (long-range sensing, semantics), manipulation (strong hands/grippers), safety-certification, and reliability for unstructured environments.
- Urban search-and-rescue deployment in real incidents
- Sector: public safety
- Use case: Autonomous traversal over rubble, collapsed structures, and complex 3D obstacles (climb-ups, vaults, drops) to reach victims or carry sensors.
- Potential tools/products/workflows: Robust multi-sensor perception stack (depth + LiDAR + stereo + thermal); semantic scene understanding; fall risk estimation; procedural skill guardrails; “mission policy” blending mobility with situational heuristics.
- Assumptions/dependencies: Strong hands or grippers for edge support and ladder climbing; weatherproofing; reliability under dust/smoke; human–robot teaming protocols; certification and incident command integration.
- Construction and industrial maintenance mobility
- Sector: construction, energy, industrial inspection
- Use case: Navigating scaffolding, platforms, and irregular plant architectures; climbing onto mezzanines; negotiating obstacles to reach inspection points.
- Potential tools/products/workflows: “Mobility Skill Graph” composer integrating parkour skills with compliant manipulation (rail grabs, bar hangs); state estimation under occlusions; route planning with skill-aware timing; fall-arrest systems and tethering.
- Assumptions/dependencies: Higher-actuation strength and endurance; grasping/hooking capabilities; rigorous safety compliance; risk assessment and site-specific training.
- Logistics and facilities operations in complex buildings
- Sector: logistics, warehousing
- Use case: Multi-floor access without standard infrastructure (stairs, ad-hoc hurdles), emergency deliveries, or traversal during outages.
- Potential tools/products/workflows: Language-conditioned high-level task control (e.g., “deliver to floor 3 via west stairwell”), semantic mapping, human-aware navigation and speed-governing, multi-skill motion planning under traffic and clutter.
- Assumptions/dependencies: Safety certification for operation near workers; broader perception coverage; operational policies for dynamic maneuvers; battery management and thermal constraints.
- Multi-skill loco-manipulation for complex tasks
- Sector: robotics, software
- Use case: Combine parkour-like mobility with whole-body manipulation (opening doors, ladder ascent, rail support) for full-scene task execution.
- Potential tools/products/workflows: Extended motion library via OmniRetarget for interaction-heavy maneuvers; motion-matching over heterogeneous skill families; hierarchical teacher-student distillation; “skill composer” SDK with semantic preconditions.
- Assumptions/dependencies: Force-aware hands, compliant control, rich scene semantics; co-training perception and control; model-based safety checks.
- Standards, certification, and safety governance for high-energy humanoid motions
- Sector: policy/regulation
- Use case: Establish testing protocols and certification tiers for dynamic behaviors (vaults, climbs, drops) across public, industrial, and emergency settings.
- Potential tools/products/workflows: Standardized obstacle courses and metrics (success rate, timing, contact forces, fall risk); reporting schemas; incident logs; insurance and liability frameworks.
- Assumptions/dependencies: Cross-stakeholder collaboration (manufacturers, regulators, unions, safety engineers); public acceptance; legal clarity.
- Stunt and live-performance robots
- Sector: entertainment
- Use case: Reliable robotic performances with dynamic sequences (vault chains, wall climbs, rolls) synchronized to show cues, with contingency handling for obstacle shifts.
- Potential tools/products/workflows: Redundant sensing, preflight validation, rehearsal pipelines with motion matching; runtime monitors for energy, joint temperatures, and skill aborts; show safety standards.
- Assumptions/dependencies: High mechanical reliability; rapid recovery behaviors; liability and venue compliance.
- Exoskeleton and assistive device control inspired by motion matching and skill chaining
- Sector: healthcare, rehabilitation
- Use case: Adaptive assistance for dynamic transitions (curb steps, low platform climbs) using motion-matching features and success-aware control objectives.
- Potential tools/products/workflows: Human-in-the-loop motion feature design; patient-specific retargeting; safety envelopes; gradual RL curricula tuned to clinical constraints.
- Assumptions/dependencies: Rigorous clinical validation; fail-safes; ethical approvals; user comfort and trust.
- Digital twins and sports analytics using physically-executable skill compositions
- Sector: software, sports tech
- Use case: Generate physically plausible long-horizon motion sequences for athletes or avatars (e.g., parkour lines) to assess timing, contact strategies, and risk.
- Potential tools/products/workflows: Motion-matching sequence planner; simulation-based stress/impact estimators; coaching dashboards; integration with biomechanical models.
- Assumptions/dependencies: High-quality motion capture; validation against human performance; careful interpretation for training recommendations.
Cross-cutting assumptions and dependencies
- Motion data: Availability of curated human motion clips and accurate retargeting (e.g., OmniRetarget), including annotated entry/exit windows for each skill.
- Perception: Depth camera sufficiency in FOV, range, and latency; additional sensors needed for unstructured environments (LiDAR, IMU fusion, stereo).
- Hardware: Actuator power to deliver brief, high-magnitude actions; stronger hands/grippers for advanced climbing; heat and battery management.
- Safety: Operation in controlled areas now; future certification for human-cohabited spaces; emergency stop and geofencing; hazard-aware speed limiting.
- Scalability: Compute resources for high-throughput training (thousands of envs), domain randomization tuning, and robust sim-to-real procedures.
- Semantics and planning: Current policy relies on depth and velocity command only; broader deployment requires semantic scene understanding, higher-level planning, and language or task conditioning.
Glossary
- Action scale: A normalization factor applied to action outputs to control their magnitude during policy training and execution. "Due to challenging RL exploration, we set the action scale to 1 for all experts, instead of the heuristics used in~\cite{liao2025beyondmimic}."
- Adaptive Sampling: A training strategy that prioritizes sampling from states or segments where policies fail, to accelerate learning of difficult behaviors. "Adaptive Sampling is essential for learning difficult skills in expert training, which prioritizes sampling from regions that fail more frequently."
- Alive reward: A simple reinforcement learning reward that encourages the agent to remain operational and make progress, without detailed tracking objectives. "DAgger + RL Alive Reward. Use only an alive/progress reward, without motion-tracking terms."
- AMP: Adversarial Motion Priors; a method that learns motion-style rewards from data to guide RL in training policies that match human motion distributions. "AMP~\cite{peng2021amp} addresses this challenge by training a single policy to learn a distribution of skills, allowing transitions to implicitly emerge from RL exploration, but replaces hand-crafted rewards with a learned style reward from motion data."
- Behavior cloning: Supervised learning approach where a policy imitates expert actions given states, often used to regularize or initialize RL. "the behavior cloning objective provides a critical regularization for RL."
- Blending window: A short temporal smoothing interval applied at motion transitions to avoid discontinuities between clips or frames. "A short blending window is applied around transitions to avoid discontinuities."
- Camera extrinsics: The camera’s position and orientation relative to the robot or world frame; often randomized to improve robustness to mounting variability. "we randomize camera extrinsics within 2.5 cm translation and 2.5° rotation around the calibrated value to improve robustness to viewpoint shifts and mounting variability."
- CNN: Convolutional Neural Network; a deep learning architecture particularly suited for processing image-like inputs such as depth maps. "we use a 3-layer CNN and a 5-layer MLP with hidden sizes [2048, 1024, 512, 256, 128], trained with 16,384 parallel environments."
- Closed-loop adaptation: Real-time feedback control that adapts behavior during execution in response to perceived changes or disturbances. "demonstrating highly dynamic parkour skills such as climbing tall obstacles up to 1.25\,m (96\% robot height), as well as long-horizon multi-obstacle traversal with closed-loop adaptation to real-time obstacle perturbations."
- DAgger: Dataset Aggregation; an imitation learning algorithm that iteratively trains on the learner’s state distribution with expert labels to reduce compounding errors. "and distill them into a single depth-based, multi-skill student policy, using a combination of DAgger and RL."
- Domain Randomization: Systematic randomization of simulation parameters (e.g., visual, physical) during training to improve robustness and transfer to the real world. "Rewards, Terminations, and Domain Randomization follow BeyondMimic~\cite{liao2025beyondmimic}: DeepMimic-style tracking rewards with action rate, joint limits, and collision penalties, tracking-based early termination, and lightweight randomizations."
- DoFs: Degrees of Freedom; the number of independent joint or body motions a robot can perform. "We evaluate the proposed framework through a series of simulation and real-world experiments on a Unitree G1 humanoid (1.3\,m tall with 29 DoFs)."
- Exteroception: Sensing external environmental cues (e.g., vision, depth) used to adapt motion to terrain and obstacles. "these skills must be tightly coupled with exteroception, such as vision, to enable adaptation to environmental variation and rapid reaction to unexpected perturbations."
- Feature space: A vector space of motion features (e.g., trajectories, joint positions) where similarity search (nearest neighbor) guides motion matching. "leverages motion matching, formulated as nearest-neighbor search in a feature space, to compose retargeted atomic human skills into long-horizon kinematic trajectories."
- Global tracking: Tracking a reference motion in world coordinates (not just locally), enabling recovery behaviors and alignment with terrain. "Unlike~\cite{yang2025omniretarget}, we enable global tracking with privileged observations (pelvis global position and velocity) so the expert can learn recovery behaviors."
- Height scan: A local height-map measurement (grid of terrain elevations) around the robot, used by policies to adapt to terrain variations. "We additionally provide the expert with a 0.7 m à 0.7 m height scan, allowing it to adapt to terrain randomizations."
- IsaacLab: A robotics learning framework from NVIDIA used for training and evaluating RL policies with physics simulation. "We train a humanoid to traverse terrain using IsaacLabâs \cite{mittal2025isaac} standard velocity-tracking RL pipeline."
- Kinematic trajectories: Time sequences of poses (positions and orientations of joints/root) used as motion references without modeling full dynamics. "compose retargeted atomic human skills into long-horizon kinematic trajectories."
- KL-based exploration control: Using Kullback–Leibler divergence constraints to regulate policy updates and exploration in PPO. "Finally, we enable adaptive learning rate and KL-based exploration control only when $\lambda_{\text{PPO}$ exceeds 0.1."
- Locomotion manifold: The shared space of locomotion states used to connect and transition between heterogeneous dynamic skills. "By routing all skills through a shared locomotion manifold, this formulation enables consistent transitions across heterogeneous skills without requiring specific, hand-captured transitions between every possible skill pair, and supports scalable composition of long-horizon behaviors."
- MLP: Multilayer Perceptron; a feedforward neural network commonly used for processing proprioceptive inputs and outputs actions. "we use a 3-layer CNN and a 5-layer MLP with hidden sizes [2048, 1024, 512, 256, 128], trained with 16,384 parallel environments."
- Motion matching: A data-driven motion synthesis technique that stitches motion fragments by nearest-neighbor matching of features, producing realistic transitions. "Motion matching synthesizes long-horizon motion by retrieving and stitching motion fragments via nearest-neighbor search in a designed feature space."
- Motion priors: Prior knowledge or distributions over human motion styles used to regularize or guide policy learning. "we present Perceptive Humanoid Parkour (PHP), a modular framework that integrates human motion priors, long-horizon skill composition, and perceptive control."
- Nearest-neighbor search: A technique to find the most similar item (frame/clip) in a feature space, used to select motion transitions. "Motion matching synthesizes long-horizon motion by retrieving and stitching motion fragments via nearest-neighbor search in a designed feature space."
- Nvidia WARP: A high-performance GPU framework used here to render depth images at scale for training. "For vision, we use depth images rendered with Nvidia WARP~\cite{warp2022} for high-throughput training."
- Observation delay: Latency between sensing and policy action due to hardware/software pipelines; often randomized in sim for robustness. "Finally, we randomize observation delay between 60 ms and 80 ms to simulate hardware latency fluctuations."
- OmniRetarget: A method to retarget human motion to robot kinematics while preserving interaction and style. "We first retarget human motion data into a library of robot-compatible atomic skills using OmniRetarget \cite{yang2025omniretarget}."
- PD targets: Proportional–Derivative controller targets for joints; actions specify desired joint positions/velocities for PD control. "Actions are joint PD targets normalized by a fixed action scale."
- Pelvis gravity vector: The gravity direction expressed in the pelvis/body frame; used as a proprioceptive signal. "The policy observes proprioception signals including pelvis gravity vector and angular velocity, joint positions and velocities, and the previous action."
- Privileged observations: State variables available in simulation (e.g., global pose) but not on real hardware; used to train teacher experts. "We then train motion-tracking expert policies with privileged observations in simulation, and finally distill them into a depth-based student policy..."
- Proprioception: Internal sensing of the robot’s own state (e.g., joint angles, velocities, body orientation). "The policy observes proprioception signals including pelvis gravity vector and angular velocity, joint positions and velocities, and the previous action."
- PPO: Proximal Policy Optimization; a stable RL algorithm that constrains policy updates to improve learning reliability. "using DAgger in combination with a PPO objective, enabling zero-shot sim-to-real deployment."
- Receding-horizon replanning: Planning over a moving short time window repeatedly during execution; computationally costly with perception. "This often requires either costly iterative co-training~\cite{xu2025parc} to recover usable motion or receding-horizon replanning~\cite{huang2025diffuse}, which is costly with perception in real time."
- RL: Reinforcement Learning; training policies via reward signals and trial-and-error interaction with environments. "we augment distillation with an RL objective that provides task-level corrective feedback, steering the student towards successful traversal and yielding a scalable recipe across many skills."
- Reward shaping: Designing specific reward components to elicit desired behaviors in RL, often used when training from scratch. "While quadrupedal parkour skills can often be trained from scratch via reward shaping, this approach scales poorly to humanoids due to high-dimensional whole-body control."
- ROI overlap: Region of Interest overlap; a metric to match visibility between simulation and hardware for camera calibration. "We calibrate the simulated camera by matching robot self-visibility across a set of poses in simulation and hardware using ROI overlap, and randomize camera extrinsics..."
- Root tracking reward: A reward focused on tracking the root (base) pose/trajectory rather than the full-body motion. "Use a root-tracking reward instead of full whole-body tracking."
- Root velocity: The linear velocity of the character’s root (base) used as a motion feature for matching. "and (iii) root velocity, all expressed in the character's local coordinate frame."
- Sim-to-real transfer: Deploying policies trained in simulation onto real hardware effectively. "Successful zero-shot sim-to-real transfer of depth-based policies on a physical humanoid robot, achieving highly dynamic parkour over various obstacles."
- Teacher-student training pipeline: A framework where expert (teacher) policies guide training of a single student policy, often via imitation and RL. "By composing various agile human skills via motion matching and a teacher-student training pipeline, we train a single multi-skill visuomotor policy..."
- Visuomotor policy: A control policy that maps visual inputs (e.g., depth) and proprioception to motor actions. "we train a single multi-skill visuomotor policy capable of complex contact-rich maneuvers..."
- Yaw randomization: Randomly perturbing obstacle orientation around the vertical axis to diversify training conditions. "Each task requires the robot to move forward at a fixed command speed (1.0\,m/s or 2.0\,m/s) and clear a single obstacle of a specified height and yaw randomization."
- Zero-shot: Deploying a model on new tasks or hardware without fine-tuning or additional training. "Successful zero-shot sim-to-real transfer of depth-based policies on a physical humanoid robot"
Collections
Sign up for free to add this paper to one or more collections.