Rethinking ANN-based Retrieval: Multifaceted Learnable Index for Large-scale Recommendation System
Abstract: Approximate nearest neighbor (ANN) search is widely used in the retrieval stage of large-scale recommendation systems. In this stage, candidate items are indexed using their learned embedding vectors, and ANN search is executed for each user (or item) query to retrieve a set of relevant items. However, ANN-based retrieval has two key limitations. First, item embeddings and their indices are typically learned in separate stages: indexing is often performed offline after embeddings are trained, which can yield suboptimal retrieval quality-especially for newly created items. Second, although ANN offers sublinear query time, it must still be run for every request, incurring substantial computation cost at industry scale. In this paper, we propose MultiFaceted Learnable Index (MFLI), a scalable, real-time retrieval paradigm that learns multifaceted item embeddings and indices within a unified framework and eliminates ANN search at serving time. Specifically, we construct a multifaceted hierarchical codebook via residual quantization of item embeddings and co-train the codebook with the embeddings. We further introduce an efficient multifaceted indexing structure and mechanisms that support real-time updates. At serving time, the learned hierarchical indices are used directly to identify relevant items, avoiding ANN search altogether. Extensive experiments on real-world data with billions of users show that MFLI improves recall on engagement tasks by up to 11.8\%, cold-content delivery by up to 57.29\%, and semantic relevance by 13.5\% compared with prior state-of-the-art methods. We also deploy MFLI in the system and report online experimental results demonstrating improved engagement, less popularity bias, and higher serving efficiency.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
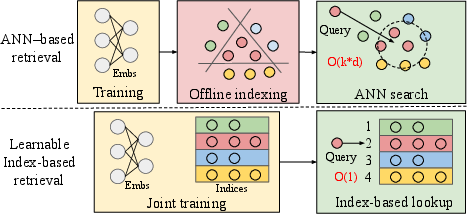
This paper is about making big recommendation systems (like those used by social media or video apps) faster and smarter at finding the right items to show you. These systems usually rely on a technique called “approximate nearest neighbor” (ANN) search to quickly find items similar to what you like. The authors propose a new way called MultiFaceted Learnable Index (MFLI) that learns both the “item representations” and the “indices” (think: how items are grouped and looked up) together, and then uses those learned indices directly at serving time—so it no longer needs ANN search during live requests.
What questions does the paper ask?
In simple terms, the paper tries to answer:
- Can we learn the “lookup system” for items at the same time as we learn what items mean, so we match users better?
- Can we avoid running expensive ANN searches for every single user request and still retrieve good recommendations?
- Can we keep the system fresh as new items arrive (like new videos), and handle huge scales (billions of users and millions of items)?
- Can we reduce bias toward only the most popular items and improve variety and relevance?
How does the method work? (Everyday explanation)
Think of a giant library with billions of books (items). You want to quickly find books a reader will enjoy based on the books they liked before.
- Item embeddings: Each item gets a “digital fingerprint” (a vector) that represents what it’s about—like topic, style, or appeal.
- Facets: Instead of one fingerprint, MFLI gives each item multiple “facets,” like viewing items from different angles: engagement (what gets clicks/views), relevance (topic match), freshness (recent content), etc.
- Indices: Imagine shelves in the library. A good index is like a smart way of assigning books to shelves so similar books end up together, making them easy to fetch.
Here’s the key idea:
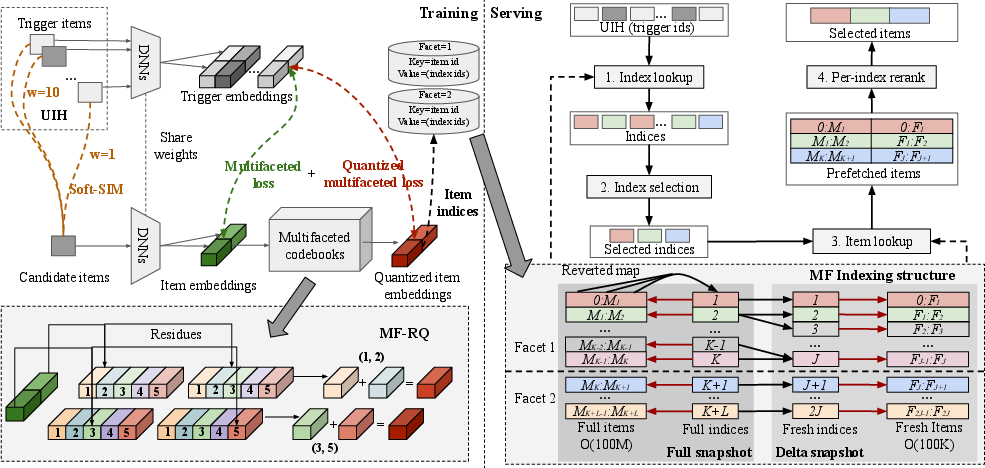
- MFLI builds a “codebook” (like a multi-part address system) for each facet using residual quantization. Residual quantization is like writing an address in steps: first a big region, then a smaller area inside it, then a specific shelf—each step refines where the item belongs.
- During training, the system learns both:
- The item fingerprints (embeddings), and
- The codebook (addresses/shelves),
- so they match each other perfectly.
Because the addresses are learned, at serving time the system doesn’t need to run an ANN search. It directly looks up the shelves (indices) that match the user’s recent likes and fetches items on those shelves.
To make this work at industrial scale, the paper solves several practical challenges:
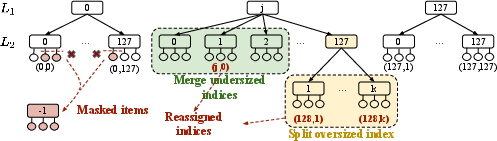
- Balanced shelves: Some shelves might get too many items (crowded) or too few (almost empty). They use:
- “Delayed start” (warm up embeddings before codebooks),
- A regularizer to avoid overusing popular codewords,
- A “split-and-merge” step: split oversized shelves into smaller ones and merge undersized shelves together. This keeps shelf sizes in healthy ranges.
- Efficient storage and lookup: They unify the multi-step addresses into simple numbers and keep two fast maps:
- Item-to-index (which shelves an item belongs to),
- Index-to-item (which items are on a shelf).
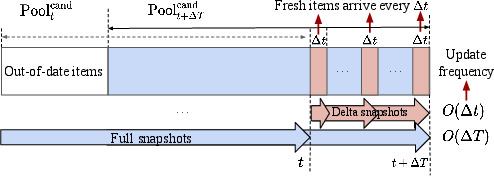
- Real-time updates: They publish two snapshots:
- A full snapshot (updated less frequently, like every ~30 minutes),
- A delta snapshot (updated very frequently, like every ~1 minute) for newly arrived “fresh” items.
- When serving, they fetch from both and merge results, so new items can be recommended quickly.
What happens when you make a request?
When a user opens the app, the system:
- Takes a few items they recently engaged with (triggers).
- Looks up the indices (shelves) tied to those triggers across multiple facets.
- Selects the best K indices using strategies like:
- Multi-interest extraction (sample more from frequently hit shelves),
- Recent-interest boosting,
- Long-tail exploration (include neighboring shelves for users with little history).
- Fetches all items from those K indices (from both full and delta snapshots).
- Reranks within each index (per-index reranking) and picks the top items, then merges them for the final list.
Main findings (Why this matters)
Using real-world data (billions of users), MFLI showed:
- Better recall (finding items people actually engage with): up to about 11.8% improvement.
- Much better for new/cold items (items without much history): up to about 57% improvement.
- Better semantic relevance (topics match more closely): around 13.5% improvement over strong baselines; in broader tests, the paper reports even larger gains in topic match rates.
- Faster serving: because it avoids running ANN search for every request, it increases throughput compared to multi-ANN setups.
- Less popularity bias: the system retrieves diverse items across facets and indices, so it doesn’t only push the most popular content.
These results suggest the system is both effective (shows better stuff) and efficient (does it faster and cheaper).
Why it’s important and what it could change
- More relevant recommendations: Multi-faceted views help match what the user wants now (e.g., topic relevance) and what they tend to engage with (e.g., watch time), improving satisfaction.
- Faster and cheaper systems: Direct index lookup replaces costly ANN search at serving time, which is crucial at massive scale.
- Better for new content and creators: Real-time updates and semantic grouping help new items get discovered sooner, reducing cold-start pain.
- Fairer and more diverse feeds: Split-and-merge plus multi-interest selection limit the dominance of a few popular items and broaden what users see.
- Practical deployment: The design handles the messy realities of big production systems—scale, freshness, consistency, and GPU-friendly parallelism—making it suitable for live platforms.
In short, MFLI rethinks how to retrieve items in recommendation systems by learning the “addresses” and “meanings” of items together, then using those addresses directly to serve results. This makes recommendations more accurate, fresher, and faster at huge scale.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper. Each point is framed to enable concrete follow-up by future researchers.
- Differentiability of index assignment: The paper asserts end-to-end differentiable training while using nearest-codeword assignments via argmin, but does not specify the mechanism (e.g., straight-through estimators, soft assignments, Gumbel-Softmax). Quantify how different differentiable approximations affect stability, convergence, and retrieval quality.
- Theoretical guarantees: No formal analysis links residual quantization error and index assignment to retrieval recall, precision, or semantic coherence. Derive bounds or theoretical guarantees that relate codebook granularity, residual depth, and quantization distortion to retrieval performance.
- Memory and compute footprint at billion-scale: The item-to-index and index-to-item tensors’ space/time complexity is stated in big-O terms but lacks concrete sizing (GB/TB), cache behavior, and inference-time IO costs for multi-facet, multi-layer codebooks. Provide detailed profiling on GPU/CPU, memory usage per billion items, and end-to-end throughput at P50/P95/P99.
- Online A/B experiment transparency: Claims of improved engagement, reduced popularity bias, and higher serving efficiency are not quantified (metrics, deltas, statistical significance, duration). Report comprehensive online A/B results (CTR, dwell time, coverage/diversity, bias indices, latency/throughput distributions) with significance tests.
- Freshness vs. consistency trade-offs: The delta/full snapshot update cadence (e.g., 1 min vs. 30 min) is not studied. Conduct sensitivity analyses of refresh intervals on recall, semantic relevance, long-tail coverage, and index consistency (including race conditions and mixed-snapshot conflicts).
- Delta snapshot rebalancing: Fresh items in the delta stream bypass split-and-merge, potentially skewing index sizes or semantics. Measure drift introduced by unbalanced fresh indices and evaluate lightweight incremental rebalancing or adaptive thresholds for the delta pipeline.
- Duplicate/collision handling across snapshots: The merging of full and delta snapshot candidates may introduce duplicates or inconsistent index mappings. Specify and evaluate de-duplication and conflict-resolution strategies, and their impact on latency and quality.
- Generalization across domains and modalities: Experiments focus on video recommendation; applicability to other verticals (e.g., ads, e-commerce, search) and multi-modal content (text/image/audio) is untested. Validate MFLI on diverse corpora and modality-rich tasks.
- Cold-start and never-exposed items: The paper customizes a facet for semantic relevance and cold items but does not detail detection criteria or embedding sources for items never seen in training (e.g., content-only embeddings). Compare strategies for cold-start detection and initialization, and measure their impact.
- Sparse-history and new-user handling: Long-tail users with limited interaction history rely on neighbor-index inclusion, but the efficacy, risks of topic drift, and optimal neighbor selection are not evaluated. Benchmark retrieval quality for sparse users vs. ANN baselines and content-driven triggers.
- Index selection strategies: Multinomial sampling, recent-interest boosting, and neighbor inclusion are described but not systematically compared. Explore advanced strategies (e.g., bandits, reinforcement learning, constrained optimization) with diversity/fairness objectives and quantify trade-offs.
- Diversity and fairness metrics: While multi-interest coverage is claimed, no explicit diversity/fairness measurements (e.g., item/topic coverage, Gini/entropy, demographic parity) are reported. Introduce and optimize for diversity/fairness alongside engagement.
- Popularity bias quantification: “Less popularity bias” is claimed without metrics. Define bias measures (e.g., exposure skew, long-tail share, novelty) and document how index balancing, split-and-merge, and per-index reranking affect them.
- Hard negative mining: SSM uses random negatives; hard/semi-hard negatives are not explored. Compare negative sampling schemes and their effect on codebook quality, index purity, and final retrieval performance.
- Facet/task design and scaling: The paper uses 2–3 facets with specific task assignments; systematic methods to select the number of facets, allocate tasks per facet, and dynamically adapt facets over time are missing. Investigate auto-configuration (e.g., NAS/AutoML) and task-to-facet assignment algorithms.
- Adaptive codebook sizing: Codebook size and depth are tuned empirically; no mechanism exists to grow/shrink layers or codewords online. Develop adaptive codebook strategies (split/merge at codeword level, elastic capacity) and measure stability/performance impacts.
- Robustness to distribution shifts: No evaluation under major content/user-behavior shifts (e.g., events, trends). Stress-test MFLI under synthetic and real distribution shifts and document recovery mechanisms (warm starts, reweighting, reset policies).
- Security/abuse resistance: The system may be susceptible to adversarial content that clusters to dominate indices or exploit index selection. Design and evaluate safeguards (spam detection, index-level caps, anomaly detection in assignment distributions).
- Consistency and caching across serving tiers: As indices evolve, cache invalidation, stale pointers, and cross-shard consistency are not addressed. Provide a distributed serving design (sharding, replication, cache coherence, rollback) and quantify failure modes.
- Impact on downstream reranking calibration: Changing retrieval to index-based may shift candidate distributions. Evaluate how this affects reranker calibration, feature drift, training pipelines, and end-to-end ranking performance.
- Handling multi-topic items: Items with diverse semantics may be fragmented across facets/indices. Study multi-index assignment policies, consolidation rules, and cross-facet blending to prevent over-fragmentation or over-concentration.
- K-means split parameterization: Split-and-merge depends on k-means over residuals but lacks guidance on k selection, initialization, and termination criteria. Compare alternative splitting methods (e.g., X-means, density-based clustering) for stability and speed.
- Parameter thresholds for index sizes: Bounds B_low and B_upper are central yet chosen heuristically. Perform systematic tuning and sensitivity analyses of these thresholds on latency, recall, diversity, and semantic purity.
- Human-grounded semantic evaluation: Topic match rates (T1/T2) may not reflect user-perceived relevance. Incorporate human judgments or user studies to validate semantic coherence within indices and perceived retrieval quality.
- Compatibility with user-to-item retrieval: The paper centers on item-to-item retrieval. Compare MFLI to state-of-the-art user-to-item retrieval and hybrid approaches in both offline and online settings.
- Detailed latency breakdown: Apart from a throughput claim, the paper lacks breakdowns for index lookup, selection, item fetch (full/delta), de-duplication, and per-index reranking. Provide granular latency profiling and bottleneck analysis.
- Reproducibility of regularization: The index-balancing regularization is referenced to the appendix but not specified in the main text. Release precise formulations, ablation results, and hyperparameter ranges for reproducibility.
- Open-source and deployment guidelines: No reference implementation or deployment playbook is provided. An open-source prototype with benchmarks, configs, and ops guidance would accelerate adoption and scrutiny.
Practical Applications
Immediate Applications
Below are specific, deployable use cases that can be implemented now using the paper’s MFLI framework and system designs.
- Large-scale feed and product recommendation (software, media, e-commerce)
- Replace IVF/HNSW/graph-based ANN in candidate generation with MFLI to eliminate online ANN search, cut latency, and increase throughput (reported up to 60%).
- Tools/workflows: multifaceted residual quantization (MF-RQ), unified item-to-index and index-to-item tensors, split-and-merge index rebalance, index-frequency histogram selection, per-index reranking.
- Assumptions/dependencies: reliable user interaction history for triggers, GPU-friendly tensor ops, a production reranker, periodic full snapshots plus minute-level delta snapshots.
- Cold-start retrieval and fresh content delivery (media, marketplaces)
- Use a semantic relevance facet to group new items and customize the candidate pool so fresh or cold-start items are retrievable immediately and semantically coherent.
- Tools/workflows: facet-specific auxiliary relevance loss, facet-level item pruning (invalid index for excluded pools), delta snapshots every minute.
- Assumptions/dependencies: accessible semantic labels or relevance model, consistent item metadata, robust snapshot orchestration.
- Serving cost and efficiency reduction (cloud infrastructure, energy)
- Eliminate per-request ANN scanning; leverage direct index lookups to decrease memory and compute footprint at scale.
- Tools/workflows: GPU-parallelized index lookup, batched tensor reads, bounded candidate sizes via split-and-merge.
- Assumptions/dependencies: in-memory storage for index tensors, careful capacity planning to avoid memory fragmentation, monitoring for index balance.
- Popularity-bias mitigation and diversity control (policy, trust & safety, product)
- Preserve multi-interest coverage via per-index reranking and multinomial sampling over index-frequency histograms; balanced clusters reduce dominance of popular items.
- Tools/workflows: index-selection strategies (multi-interest extraction, recent-interest boosting, neighbor augmentation for long-tail users), index-size constraints (B_low/B_up).
- Assumptions/dependencies: clear KPIs balancing engagement and diversity, ongoing monitoring dashboards, guardrails to prevent extreme sparsity or over-fragmentation.
- Real-time freshness for rapidly evolving inventories (social video, news)
- Deliver newly uploaded items within minutes using delta snapshots while preserving global consistency using periodic full snapshots.
- Tools/workflows: full snapshot cadence (e.g., every 30 minutes), delta snapshot cadence (e.g., every 1 minute), mapping from fine-tuned (split/merge) indices to original indices for consistency.
- Assumptions/dependencies: reliable snapshot generation pipeline, consistency checks, background jobs for split-and-merge only on full snapshots.
- Multi-interest recommendation mining (media, e-commerce)
- Extract multiple user interests via per-facet index mappings from several trigger items, enabling exploration and coverage across interests.
- Tools/workflows: index-frequency histogram per facet, multinomial sampling for top-K indices, neighbor augmentation for users with sparse history.
- Assumptions/dependencies: trigger-item selection policy, robust facet definitions aligned with business objectives.
- Advertising retrieval and sponsored content matching (ads, marketing tech)
- Assign a facet specialized for CTR/conversion signals; customize candidate pools and per-index reranking to optimize revenue while maintaining relevance.
- Tools/workflows: multi-task training with ad-specific objectives, facet-level pool customization, per-index rerank with ad auction features.
- Assumptions/dependencies: high-quality labels (clicks/conversions), compliance guardrails (brand safety), alignment with auction pipeline.
- Operational index governance (platform ops)
- Maintain bounded index sizes in production via split-and-merge: split oversize clusters using k-means on last-layer residuals; merge undersized clusters under shared upper-level indices.
- Tools/workflows: scheduled rebalance jobs, index-size thresholds, monitoring of index-size distributions and usage over time.
- Assumptions/dependencies: scalable k-means jobs on residuals, safe rollouts, consistency between training and serving snapshots.
- Safety and compliance controls via facet-level pruning (trust & safety)
- Exclude restricted categories (e.g., age-gated content) from particular facets by assigning them to an “invalid index,” preventing retrieval along specific pathways.
- Tools/workflows: classification pipelines feeding facet-level masks, invalid-index routing, audit logs for exclusion decisions.
- Assumptions/dependencies: accurate content classifiers, governance policies, transparency tooling for audits.
- A/B testing and measurement modernization (industry, academia)
- Use recall@1000, topic match rates (coarse T1 and fine T2), and throughput metrics to evaluate retrieval effectiveness and semantic coherence; perform ablations on index selection, split-and-merge, delayed start.
- Tools/workflows: experiment platform, logging and dashboards, controlled ramp-ups, reproducible pipelines.
- Assumptions/dependencies: stable offline and online datasets, comparable serving configurations across arms.
- GPU-friendly candidate generation pipeline (software/HPC)
- Move away from graph/tree methods that are hard to parallelize on GPUs to tensor-based lookups and parallel MF-RQ assignment.
- Tools/workflows: CUDA-optimized ops for index lookup and codeword selection, batched tensor reads/writes.
- Assumptions/dependencies: GPU capacity and memory bandwidth, profiling and tuning for hot paths.
- Improved user experience (daily life)
- Faster, more relevant, and more diverse recommendations: better recall for engagement tasks, higher semantic topic match, and fresher content surfaces.
- Tools/workflows: incorporate recent-interest boosting, per-index reranking to preserve diversity, bounded candidates for timely delivery.
- Assumptions/dependencies: product telemetry to track perceived quality, feedback loops for tuning K, N per index, and facet mix.
Long-Term Applications
Below are use cases that benefit from the paper’s innovations but likely require further research, scaling, or integration work.
- Retrieval-Augmented Generation (RAG) without per-request ANN (software, LLMs)
- Learn document indices and a multifaceted codebook for text embeddings (facets for recency, factuality, domain) to perform direct lookups in RAG systems.
- Tools/workflows: MF-RQ on text embeddings, snapshot-and-delta indexing for evolving corpora, per-index reranking guided by query relevance.
- Assumptions/dependencies: robust text relevance labels, adaptation to token-level or passage-level semantics, alignment with LLM latency constraints.
- Cross-modal recommendation with facets per modality (media, e-commerce)
- Extend MFLI to jointly index videos, images, audio, and products; learn facets for engagement, semantic coherence, and time-spent across modalities.
- Tools/workflows: multimodal embedding training, unified or modality-specific codebooks, item-to-index mappings spanning modalities.
- Assumptions/dependencies: high-quality multimodal representations, consistent cross-modal labels, careful capacity planning to avoid memory blowup.
- On-device personalized indexing and retrieval (mobile, edge)
- Store compact codebooks and index tensors on-device for privacy-preserving, low-latency retrieval; sync delta updates over the air.
- Tools/workflows: quantized tensors, background delta sync, local per-index reranking tuned to device constraints.
- Assumptions/dependencies: strict memory/compute budgets, privacy and security requirements, fallback paths when local indices are stale.
- Federated and privacy-preserving index learning (healthcare, finance, education)
- Train codebooks and embeddings across silos; publish consistent indices without centralizing raw data.
- Tools/workflows: federated learning for MF-RQ, differential privacy for index publishing, secure mapping synchronization.
- Assumptions/dependencies: federated orchestration, DP budgets, legal compliance.
- Policy-aware exposure and fairness controls (platform governance)
- Introduce algorithmic knobs for exposure targets (e.g., long-tail promotion) at the facet and index level; dynamically adjust split-and-merge guided by policy signals.
- Tools/workflows: fairness/dissimilarity metrics tied to indices, real-time controls for index selection/rerank, policy audits.
- Assumptions/dependencies: clear governance frameworks, measurable fairness objectives, continuous monitoring.
- Open-source MFLI SDK and reference pipelines (software ecosystem)
- Package MF-RQ, unified indexing structures, split-and-merge rebalance, and delta snapshot orchestration into reusable libraries.
- Tools/workflows: API for item-to-index mapping, ingestion and snapshot services, experiment tooling.
- Assumptions/dependencies: community adoption, cross-hardware support (CPU/GPU), documentation and benchmarks.
- Data-center energy and cost optimization via index learning (energy, operations)
- Leverage direct lookup to flatten compute peaks; schedule full/delta snapshots around renewable availability; quantify carbon reductions.
- Tools/workflows: capacity planning tied to snapshot cadences, energy-aware scheduling, telemetry on throughput per watt.
- Assumptions/dependencies: collaboration with infra teams, reliable energy signals, cost models.
- Hybrid learnable index with ANN fallback (platform reliability)
- Combine MFLI with a lightweight ANN path for rare edge cases or out-of-distribution items; route dynamically based on index health.
- Tools/workflows: health checks on index coverage/size, routing policies, degradation strategies.
- Assumptions/dependencies: dual-path maintenance costs, monitoring for trigger conditions.
- Integration with semantic IDs and generative retrieval (research/industry)
- Co-design semantic IDs (unique per item) with learnable indices (shared clusters) for complementary retrieval behaviors.
- Tools/workflows: mapping layer between IDs and indices, training regimes aligning generative and index-based objectives.
- Assumptions/dependencies: clear role separation (ID uniqueness vs index clustering), mitigation of collision vs coverage trade-offs.
- Real-time indexing for inventory and pricing (commerce, finance, travel)
- Use facets for recency, price sensitivity, and availability to retrieve offers quickly as inventories/price change.
- Tools/workflows: granular delta snapshots for inventory updates, per-index rerank with price/availability signals.
- Assumptions/dependencies: robust integration with transaction systems, latency-critical paths, audit requirements.
- Personalized learning content retrieval (education)
- Facets aligned with topic mastery, difficulty, and recency to retrieve learning materials; per-index reranking for pedagogical sequencing.
- Tools/workflows: student interaction triggers, topic/difficulty labels, delta updates for newly added content.
- Assumptions/dependencies: high-quality educational metadata, outcomes monitoring, privacy in student data.
- Clinical information retrieval under safety constraints (healthcare)
- Facets for safety, recency of guidelines, and condition specificity; facet-level pruning for non-approved content.
- Tools/workflows: clinically validated relevance models, audit logs, delta snapshots for guideline updates.
- Assumptions/dependencies: regulatory compliance, rigorous validation, explainability requirements.
Glossary
- Approximate nearest neighbor (ANN): A family of algorithms that find items similar to a query in high-dimensional spaces efficiently by approximating nearest neighbors. "Approximate nearest neighbor (ANN) search is widely used in the retrieval stage of large-scale recommendation systems."
- Co-engagement: A signal indicating that two items were engaged by users within related contexts or sessions, used as supervision for learning item similarity. "the -th co-engagement label between item and ."
- Codebook: A learned set of vectors (codewords) used to quantize embeddings by assigning them to discrete representations. "we construct a multifaceted hierarchical codebook via residual quantization of item embeddings and co-train the codebook with the embeddings."
- Codeword: An individual vector in a codebook selected during quantization to represent part of an embedding. "we select the nearest codeword from the -th sub-codebook at layer as:"
- Cold Content Delivery (CCD): An evaluation task focusing on retrieving relevant items for new or rarely engaged content. "we report recall@1000 on four tasks: Video View Complete (VVC), Like, Long Watch Time (LWT), and Cold Content Delivery (CCD)."
- Cold-start items: Newly created or rarely interacted items that lack historical interaction data. "which is beneficial for cold-start items."
- Delta snapshot: A frequently refreshed, small snapshot that contains indices for newly arrived or updated items. "a delta snapshot that indexes newly arrived items can be produced within "
- Delta-update strategy: A two-stream updating scheme combining fast delta snapshots with periodic full snapshots to keep indices fresh. "We develop an efficient delta-update strategy: a main stream periodically synchronizes indices for all items in the candidate pools, while a fast stream computes indices for fresh items in real time."
- Full snapshot: A periodic, comprehensive snapshot that reindexes the entire candidate pool for consistency. "a full snapshot that indexes the entire item pool is refreshed periodically."
- Hierarchical codebook: A multi-layer organization of codewords enabling residual or progressive quantization. "MF-RQ employs a three-dimensional hierarchical codebook."
- Inverted File Index (IVF): A clustering-based ANN index that probes a subset of partitions before computing nearest neighbors within them. "the Inverted File Index (IVF) \cite{johnson2019billion}, probes a subset of nearby indices and then computes the k-nearest neighbors within those indices."
- Index-frequency histogram: A distribution counting how often indices are mapped from triggers, used to guide index selection. "we construct an index-frequency histogram per facet, which can be used for multi-user-interest mining"
- Index-rebalancing: Serving-time adjustments (e.g., split-and-merge) to bound cluster sizes and stabilize retrieval quality and efficiency. "Without index-rebalancing, the associated fresh index is simply itself."
- Index-to-item mapping: A data structure that maps each index to the contiguous range of items assigned to it. "MFLI stores the index-to-item mapping using two tensors:"
- Item-to-index mapping: A data structure that maps each item to its assigned indices (potentially one per facet). "we maintain an item-to-index mapping using (i) a dense tensor that stores the unified indices for all items with size "
- K-means clustering: An unsupervised clustering algorithm used here to split oversized indices into smaller clusters. "we independently run -means clustering on the last-layer residual item embeddings associated with that index"
- Learnable index: An indexing scheme trained jointly with embeddings to align index assignments with model objectives. "a learnable index is designed to assign a moderate number of co-engaged items to the same indices to enable effective retrieval."
- Long-tail users: Users with sparse interaction histories, requiring special handling to explore interests. "for long-tail users with limited interaction history"
- Multifaceted embeddings: Multiple embeddings (facets) per item capturing different aspects (e.g., engagement, relevance, freshness). "multifaceted embeddings can help improve recall during retrieval"
- Multifaceted residual quantization (MF-RQ): A residual quantization method applied independently per facet with a hierarchical codebook. "we first introduce multifaceted residual quantization (MF-RQ) to quantize each facet independently with an -layer hierarchical codebook"
- Multinomial sampling: A probabilistic selection method used to pick indices in proportion to their frequencies. "MFLI applies multinomial sampling over the index-frequency distribution"
- Per-index reranking: Ranking items separately within each selected index to preserve multi-interest coverage before merging. "This module performs per-index reranking using a user-to-item reranker model"
- Product quantization: A vector quantization technique that decomposes space into subspaces to compress and index high-dimensional vectors. "including k-means-based clustering and product quantization"
- Quantized embedding: The reconstructed embedding from selected codewords after quantization. "the quantized embedding is obtained by summing the selected codewords across all previous layers:"
- Residual quantization (RQ): A quantization approach that iteratively encodes the residuals of previous approximations. "via residual quantization of item embeddings"
- Reranker: A downstream model that re-scores retrieved candidates to produce a refined ranked list. "a reranker performs per-index reranking to select the top- candidates for each index and merges the results across indices."
- Sampled SoftMax (SSM): An efficient approximation of softmax used as a retrieval loss with negative sampling. "we leverage Sampled SoftMax (SSM) loss \cite{wu2024effectiveness} as the retrieval loss"
- Search-based Interest Model (SIM): A model that identifies semantically relevant items in a user's history to weight training pairs. "We use the Search-based Interest Model (SIM \cite{pi2020search} to identify semantically relevant items"
- Semantic IDs: Discrete identifiers learned to reflect item semantics, often used in generative retrieval settings. "Semantic IDs. Recent works on generative retrieval have presented different approaches based on vector quantization for building semantic IDs for items"
- User interaction history (UIH): The set of items a user has engaged with, used to form triggers and supervision. "Trigger items are previously engaged items selected from the user interaction history (UIH)"
- Vector Quantization (VQ): A technique that maps continuous vectors to discrete codewords in a codebook for compression and indexing. "constructs item indices during training using Vector Quantization (VQ) techniques"
Collections
Sign up for free to add this paper to one or more collections.