- The paper introduces the ASQ dataset and a methodological framework for analyzing synthetic agentic search behaviors in IR systems.
- It employs Markov chain analysis to compare agentic query reformulation patterns with traditional human search sessions.
- Implications for IR system design are discussed, addressing challenges in query preprocessing, caching strategies, and workload management.
Agentic Search: Characterizing Synthetic User Behavior in IR
Introduction
As information retrieval (IR) systems increasingly serve queries issued not just by humans but also by autonomous agents—typically LLMs acting in a reasoning-augmented capacity—a fundamental paradigm shift is underway. The paper "A Picture of Agentic Search" (2602.17518) addresses this critical transition, arguing that traditional IR models, assumptions, and evaluation techniques, which are predominantly human-centered, are rapidly becoming outdated as the volume of “synthetic” queries from agentic systems eclipses organic human traffic.
This work introduces both a methodological framework and the ASQ (Agentic Search Queryset) dataset, specifically designed to capture, analyze, and benchmark the search behaviors of automated agentic RAG systems. The study provides systematic comparison of agent versus human query reformulation patterns, assesses the implications for IR system optimization, and discusses the practical and theoretical consequences of the observed divergence.
Methodology and Dataset Construction
The approach centers around tracing the sequence of actions (agentic runs, or "aruns") taken by reasoning-augmented agents as they process initial user queries, decompose them into synthetic sub-queries, retrieve knowledge, and iteratively reason towards a final answer. Central abstractions include "frames", which capture per-iteration agent decisions, and "traces", the ordered collections of frames tied to a single arun.
To support both rigorous evaluation and extensibility, the dataset logs unaltered agent interactions across multiple agents (Search-R1 and AutoRefine), different generative model capacities (Qwen2.5-3B, Qwen2.5-7B), and retrieval pipelines (BM25, MonoElectra re-ranking). It leverages established IR benchmarks—HotpotQA, Researchy Questions, and MS MARCO—providing a strong backbone of diverse, relevance-judged queries.
Intrinsic dataset properties include completeness, chronological traceability, and integrity of unperturbed agent behavior. Extrinsically, the methodology is designed for reproducibility, interoperability, and extensibility. Each trace is stored as a bundle of artifact files (synthetic queries, retrieved document lists, reasoning “thoughts”, and answers), enabling per-trace or aggregate analysis without unnecessary data transfer.
Analysis of Agentic Search Behavior
Statistical Divergence and System Load
Analysis of the ASQ collection supports several key findings:
- Model Capacity and Query Behavior: Larger generative models (Qwen-7B) issue a greater number and variety of search calls (up to +265% relative to Qwen-3B), leading to longer traces, increased system workload, and less predictable resource usage. Small models, while more predictable, occasionally fall into long, unproductive loops. These divergent patterns introduce both scalability and efficiency challenges for production IR systems.
- Trace Length and Reformulation: Agents can produce extremely long search traces, sometimes spanning over 100 iterations, while humans typically abandon sessions after a small number of reformulations, as previously documented [lucchese2013searchsession]. This persistent synthetic querying behavior can significantly burden backend retrieval services.
A probabilistic analysis, modeled as discrete-state Markov chains, enables direct comparison between human and agentic session evolution:
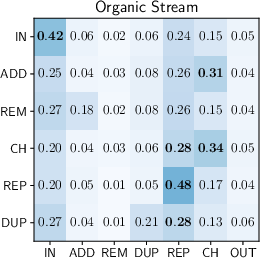
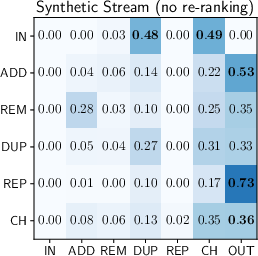
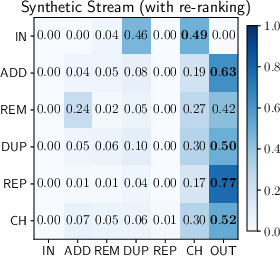
Figure 1: Transition probability matrices representing human (left) and agent search behaviours (centre, right). Rows correspond to current state and columns to next state.
Agents exhibit systematically different reformulation strategies:
- Reduced Session Interleaving: Suited to single-task focus, most agentic aruns do not alternate between unrelated searches as frequently as humans.
- Looping and Regression: Synthetic traces disproportionately feature transitions to "duplicate" states, where the agent regresses to earlier queries, often when stalling in long reasoning loops.
- Deviation from Repetitive Browsing: Unlike humans, agents rarely repeat queries solely to retrieve additional results pages, reducing the efficacy of traditional caching strategies.
- Reformulation Independence: Transition matrices are largely insensitive to retrieval pipeline effectiveness, suggesting that agent behavior is governed more by learned reasoning policies than by marginal improvements in retrieval relevance.
Within-Trace Dynamics
Transitions between reformulation strategies over the course of a single agentic trace further reveal an alternation between substantive query changes and fallback to prior queries. Early iterations focus on expansion or scope narrowing; later stages exhibit repetition or stalling behaviors—a pattern robust to retrieval pipeline variation.
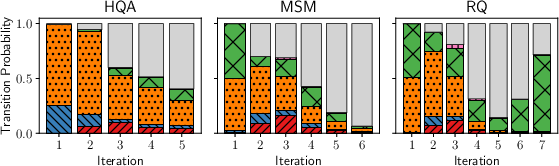
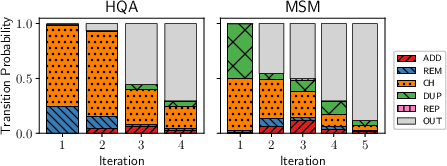
Figure 2: Qwen-7B's distribution of transition probabilities across consecutive iterations. Left: retrieval only. Right: retrieval and re-ranking. Stack i shows transition probabilities from iteration (i−1) to i; outlier iterations are omitted.
These findings highlight a key difference: agents readily exploit deep, multi-hop query reformulation, unlike humans, and do so largely irrespective of retrieval component gains or spelling/linguistic variation.
Implications for IR System Design
The transition to mixed or predominantly synthetic query streams necessitates a rethinking of canonical IR system optimizations:
- Query Preprocessing: Spelling and normalization routines, vital for noisy human input (16% error rate), incur unnecessary latency with agents (5% error).
- Query Understanding: Distributional shifts in query structure—lower WH-word frequency and a marked reduction in lexical diversity among synthetic queries—render intent classifiers and learned sparse encoders (designed for organic queries) less effective.
- Caching Strategies: Reduced intra-session repetition by agents undermines the utility of exact-match caching, while high semantic similarity among synthetic queries increases the potential for semantic caching optimizations.
- Workload Predictability: The high variance and occasional extreme length of synthetic agent traces pose challenges for system load balancing and SLA maintenance.
- Query Expansion and Refinement: Human-focused query expansion methods have limited additional utility with agents, as their queries are already well-formed and iterative expansions are intrinsic to agentic reasoning.
Limitations and Future Outlook
ASQ's current scope is constrained by the rapid pace of agentic system development, resource-intensive inference requirements, and the controlled nature of public query sets (which omit long-tail, real-world usage). The lack of sub-query relevance annotations also limits intermediate retrieval evaluation. However, the dataset's extensibility and the general methodology facilitate continuous updates to track the evolving synthetic user population.
In the broader theoretical context, these findings raise questions about the future of IR relevance modeling, reward design for agentic reasoning, and the formulation of agent-oriented benchmarks and session models. Practically, robust IR systems will need to flexibly accommodate both organic and synthetic users—potentially requiring hybrid evaluation protocols, adaptive query processing, and semantic result caching at scale.
Conclusion
This work establishes the first rigorous empirical framework and public dataset (ASQ) for analyzing and benchmarking agentic query behavior in IR systems. Strong statistical evidence validates the claim that agent and human search traces diverge significantly, impacting performance, caching, and evaluation methodologies. The observed behavioral differences motivate a critical reassessment of traditional IR assumptions and optimizations, and provide a concrete platform for further research on IR architectures suited for automated, reasoning-augmented agents. The implications span both research and operational domains, forecasting a transformative era for user modeling and system design in information retrieval.