Multi-Vector Index Compression in Any Modality
Abstract: We study efficient multi-vector retrieval for late interaction in any modality. Late interaction has emerged as a dominant paradigm for information retrieval in text, images, visual documents, and videos, but its computation and storage costs grow linearly with document length, making it costly for image-, video-, and audio-rich corpora. To address this limitation, we explore query-agnostic methods for compressing multi-vector document representations under a constant vector budget. We introduce four approaches for index compression: sequence resizing, memory tokens, hierarchical pooling, and a novel attention-guided clustering (AGC). AGC uses an attention-guided mechanism to identify the most semantically salient regions of a document as cluster centroids and to weight token aggregation. Evaluating these methods on retrieval tasks spanning text (BEIR), visual-document (ViDoRe), and video (MSR-VTT, MultiVENT 2.0), we show that attention-guided clustering consistently outperforms other parameterized compression methods (sequence resizing and memory tokens), provides greater flexibility in index size than non-parametric hierarchical clustering, and achieves competitive or improved performance compared to a full, uncompressed index. The source code is available at: github.com/hanxiangqin/omni-col-press.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Multi-Vector Index Compression in Any Modality”
Overview: What is this paper about?
This paper is about making search engines for text, images, and videos faster and smaller without losing much accuracy. Today’s best search systems break each document (like a web page, a scanned PDF, or a video) into many little pieces and store a lot of numbers for each piece. That makes search accurate, but the index (the “catalog” the search engine looks through) becomes huge—especially for videos and images.
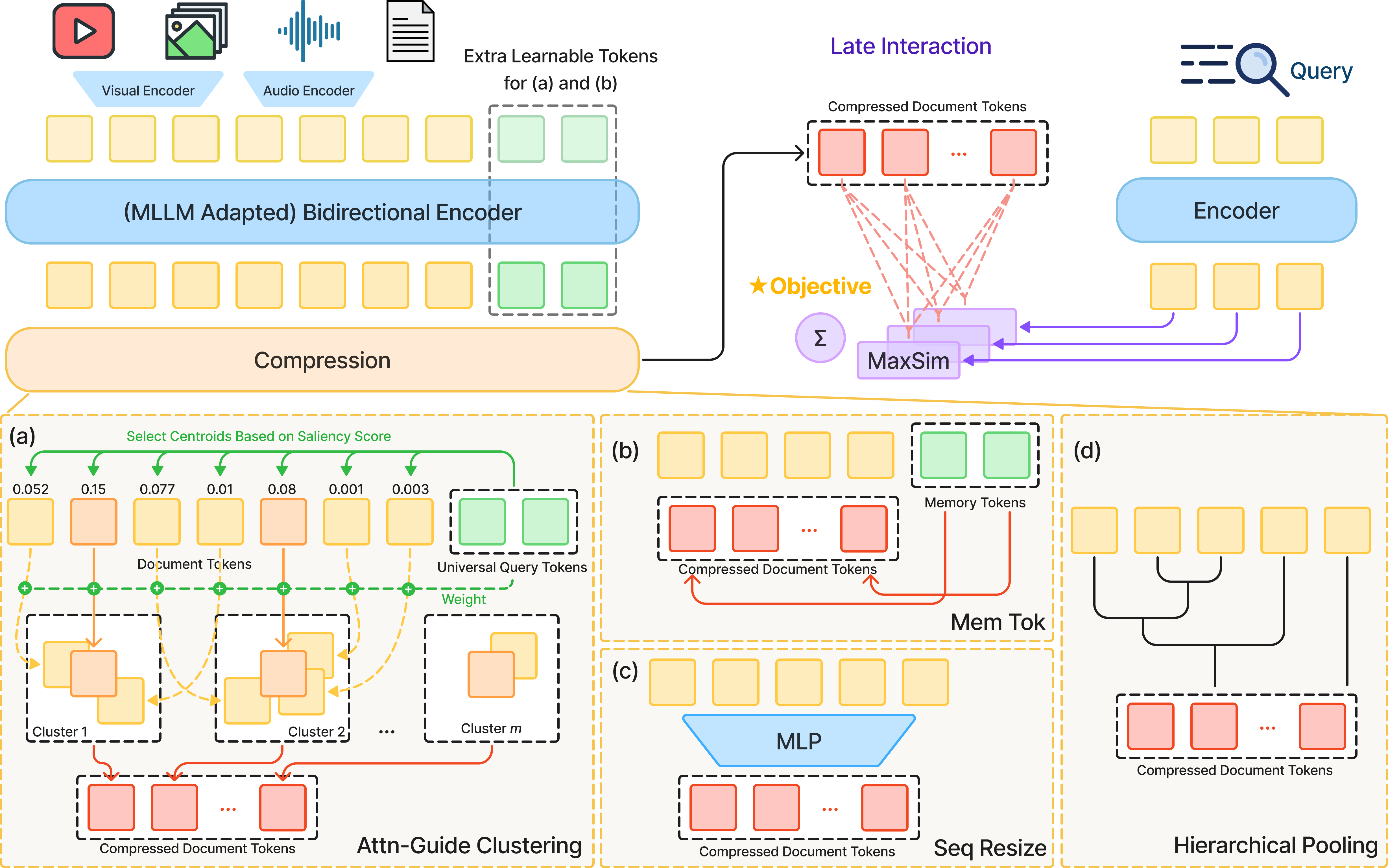
The authors propose ways to “compress” these multi-piece (multi-vector) document representations so each document uses a small, fixed number of pieces, no matter how long it is. Their new method, called Attention-Guided Clustering (AGC), keeps the most important information while cutting out redundant or noisy parts. It works for any type of data (text, images, and videos).
Objectives: What questions are they trying to answer?
The paper asks:
- How can we shrink the size of search indexes for different kinds of data (text, images, video, audio) without knowing the user’s question ahead of time?
- Can we keep a fixed, small number of vectors (think “summary tiles”) per document and still get high-quality search results?
- Which compression method works best across different modalities (types of data)?
- Can compression sometimes make search even better by removing noise and redundancy?
Approach: How do they do it, in simple terms?
Think of a document or video as a big collage made of many small tiles. “Late interaction” search looks at each query word and finds the single best-matching tile in a document, then adds up those best matches. That’s accurate, but if a video has thousands of tiles, it’s slow and takes a lot of storage.
The idea here is to compress each document down to a small, fixed number of tiles (for example, 32), while keeping the most important information. They try four methods:
- SeqResize (Sequence Resizing):
- Analogy: You take a long strip of tiles and squeeze it down to a fixed number using a learned “resizer.”
- How it works: After a transformer encoder processes all tokens, an MLP (a small neural network) maps the long sequence into a shorter one.
- MemTok (Memory Tokens):
- Analogy: You add a handful of “smart sticky notes” to the document. During processing, these notes absorb important details. In the end, you keep only the sticky notes.
- How it works: Append learnable tokens to the document; after attention, keep only those tokens as the document’s representation.
- H-Pool (Hierarchical Pooling):
- Analogy: Group similar tiles together and replace each group with an average tile.
- How it works: Clusters similar vectors step by step (no extra training) and averages them to reduce the count.
- AGC (Attention-Guided Clustering) — the new method:
- Analogy: First, ask some general “What matters here?” questions to the document. Use the answers to pick the most important tiles as “centers.” Then assign nearby tiles to these centers and make a weighted average, giving more weight to tiles judged more important.
- How it works:
- Universal queries: Learn special tokens that attend to the document to find salient (important) parts.
- Centroid selection: Pick top-scoring tokens as cluster centers.
- Clustering: Assign all other tokens to their nearest center (based on similarity).
- Weighted aggregation: Combine tokens within each cluster, weighting them by importance.
Key idea across all methods: compress the “sequence length” (how many vectors you store per document) to a fixed budget (like 32), so storage and search time don’t grow with document length.
Main Findings: What did they discover, and why does it matter?
They tested on:
- Text search (BEIR benchmark),
- Visual document search (ViDoRe, like retrieving PDF pages with diagrams and layout),
- Video search (MSR-VTT, and MultiVENT 2.0 for audio+video).
What they found:
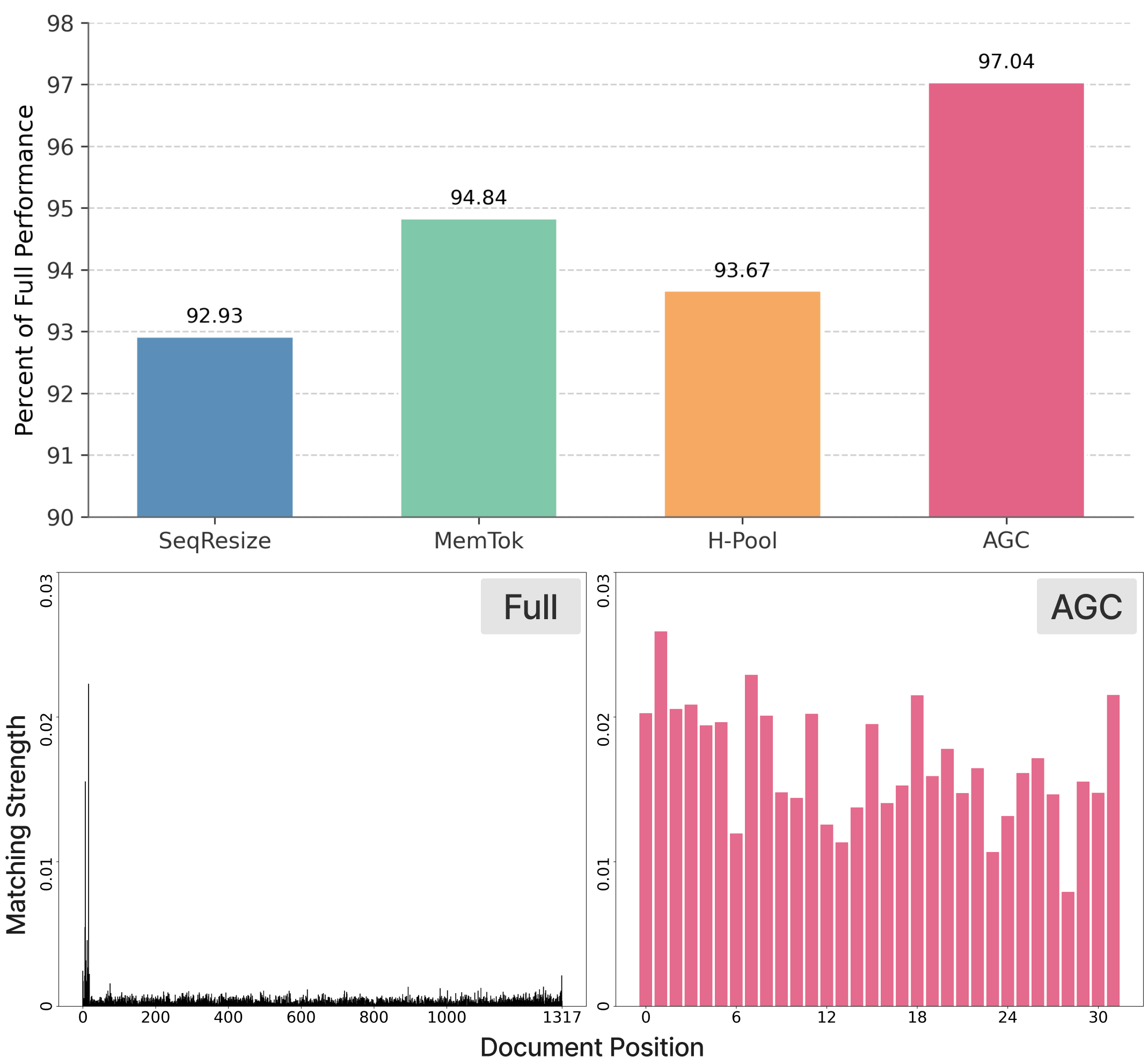
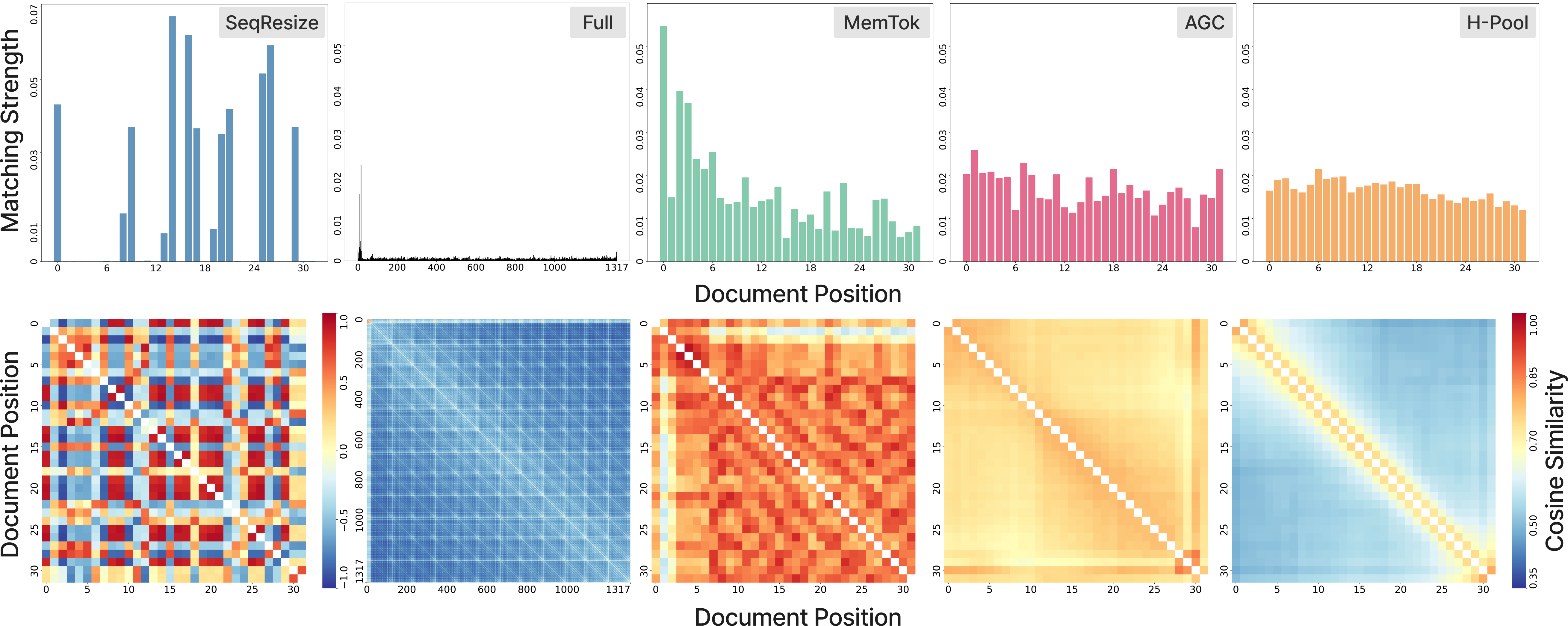
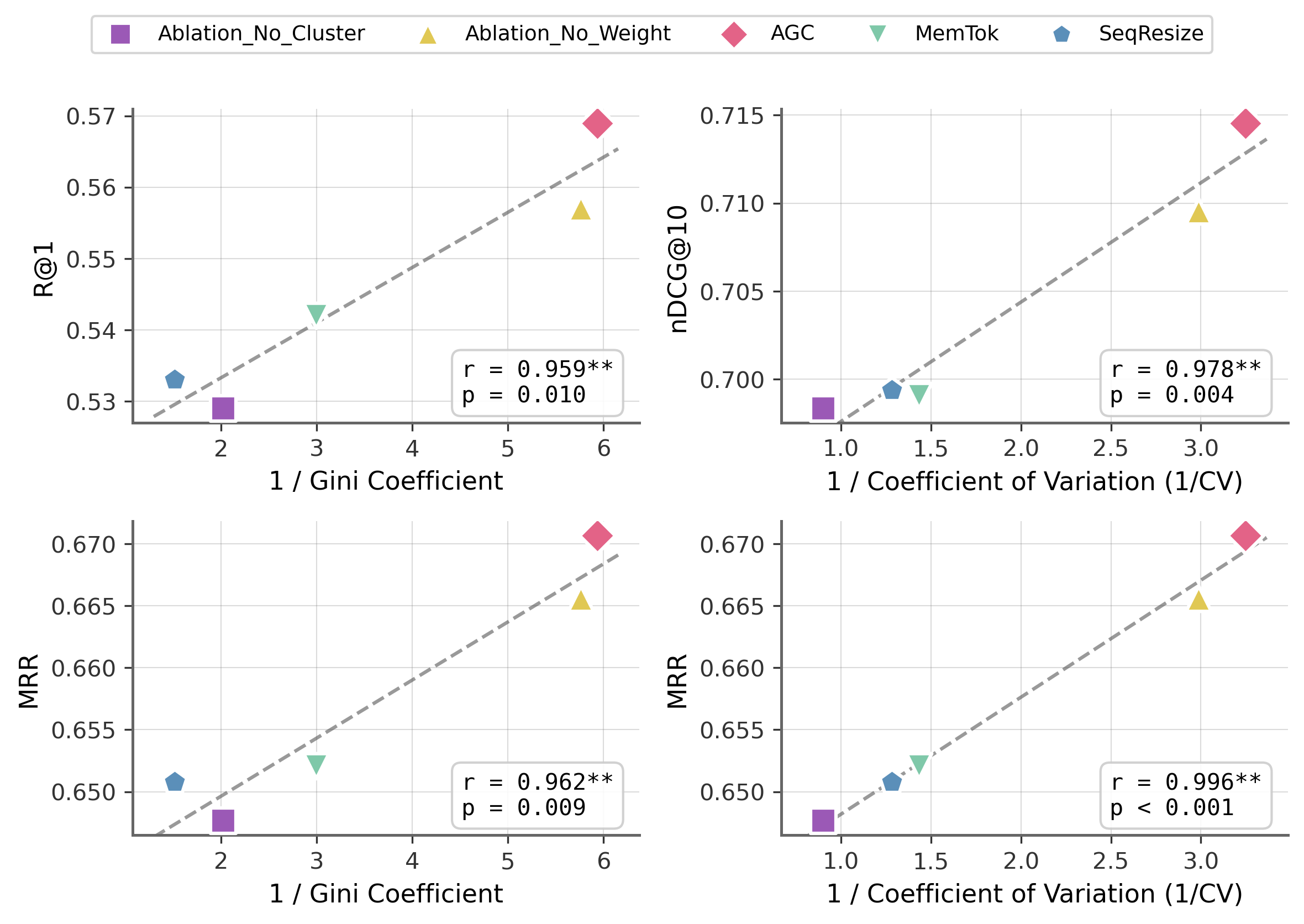
- AGC consistently beat other learned compression methods (SeqResize and MemTok) across different data types.
- AGC was also more flexible than non-learned H-Pool when changing the index size (the number of vectors kept).
- In some cases, AGC matched or even beat the full, uncompressed index. That means throwing away redundant or noisy parts can actually help accuracy.
- Big efficiency win: They show that these systems often use only about 1% of all stored vectors during scoring—so a lot of storage is wasted. Compression fixes that.
- Real-world scale matters: Indexing one video under multi-vector settings can be ~10 MB. At the scale of billions of videos, uncompressed indexes would be enormous (hundreds of petabytes). Compression is essential.
Why this matters:
- Faster, cheaper search: Smaller indexes mean quicker lookups and lower storage costs.
- Works across modalities: The same approach helps with text, images, and videos.
- Greener computing: Less storage and computation reduces energy use.
- Better than before: On some benchmarks (like MSR-VTT and ViDoRe), the compressed method reaches state-of-the-art or improved performance.
Implications: What’s the big picture and what comes next?
- Scalable multimodal search: With compact indexes, search engines can realistically index massive collections of videos, images, and documents.
- Customizable budgets: You can pick how many vectors to keep per document to fit your hardware or speed needs.
- Smarter compression helps accuracy: Training the model to compress can remove noise and highlight the most important details.
- Future directions:
- Improve audio handling to capture sound efficiently without huge memory.
- Combine AGC with newer, stronger backbone models (they already show it scales well).
- Explore even better ways to detect and keep the most “discriminative” (uniquely identifying) details needed for search.
In short, this paper shows a practical, general way to shrink indexes for any kind of data while keeping search results strong—and sometimes even making them better.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper. Each item is phrased to be actionable for future research.
- End-to-end efficiency not quantified: No measurements of indexing throughput, build time, memory footprint, or query-time latency across methods (SeqResize, MemTok, H-Pool, AGC), especially at web-scale corpora.
- Cost of AGC at indexing time: AGC requires running the encoder with appended universal queries and computing attention-based top-m selection; the computational overhead and asymptotic complexity vs. H-Pool and PLAID-style clustering are not reported.
- Synergy with residual quantization and dimension reduction: The paper does not explore combining sequence compression (AGC/H-Pool) with residual/product quantization or hidden-dimension down-projection to jointly optimize index size and speed.
- Two-stage retrieval pipeline impact: Effects of compressed indices on centroid-based candidate generation (e.g., PLAID/ColBERTv2) and downstream reranking quality are not evaluated.
- Statistical significance and variability: No confidence intervals, statistical tests, or seed-based variance analysis are provided for reported gains (including cases where AGC exceeds the uncompressed baseline).
- Failure case analysis: The paper lacks qualitative or quantitative characterization of queries/documents where AGC underperforms H-Pool or dense embeddings, and the specific failure modes across modalities.
- Generalization to audio-only and other modalities: Despite “any modality” framing, pure audio retrieval and other modalities (e.g., images-only, speech transcripts, code, 3D) are not evaluated.
- Cross-lingual robustness: MultiVENT is multilingual, but there is no breakdown of performance by language, nor analysis of cross-lingual transfer for compressed indices (including BEIR multilingual tasks).
- Query-agnostic compression risk: Potential loss of rare or niche information (long-tail queries) due to query-agnostic compression is not assessed; no per-query-type or difficulty-stratified analysis.
- Universal query tokens design choices: The number, initialization, and training of universal queries are only lightly probed; no ablations on:
- Layers used to extract attention (last vs. multi-layer aggregation),
- Heads weighting schemes,
- Alternative saliency signals (e.g., gradient-based, learned gating).
- Discrete operations training stability: Top-m centroid selection and hard assignment are non-differentiable; training stability and optimization strategies (e.g., straight-through estimators, relaxed top-k) are not described or ablated.
- Metric learning for clustering: AGC uses cosine similarity from the encoder’s last layer; there is no exploration of learned metrics, temperature scaling, or adaptive distance functions for assignment.
- Positional/temporal structure use: AGC’s clustering ignores explicit spatial/temporal structure; potential gains from motion-aware video segmentation or silence detection in audio are not tested.
- Dynamic per-document budgets: Fixed m across documents may be suboptimal; adaptive budgets based on redundancy or saliency (and corresponding index management implications) are unexplored.
- Query-length effects: Query representations are unconstrained, yet the impact of very long queries on MaxSim dynamics and compressed indices is not studied.
- Transferability boundaries: While AGC trained at one budget generalizes to others on MSR-VTT, the limits of transferability (e.g., extreme compression, cross-dataset transfer, domain shifts) are not systematically mapped.
- Robustness to noise/outliers: AGC is motivated as more robust than H-Pool to noisy multimodal tokens, but controlled stress tests (e.g., static frames, silent audio, OCR errors) are not provided.
- Interpretability of saliency: No interpretability study showing how universal-query attention maps align with human-perceived salient regions (text spans, video shots, audio segments) or how they vary by domain.
- Fairness and bias: Potential biases introduced by universal queries or compression (e.g., over-weighting visually salient but semantically irrelevant tokens) are not audited.
- Index utilization across tasks: The claim that base models use ~1% of the index is not accompanied by cross-dataset, cross-modality utilization distributions or sensitivity analysis.
- Large-scale deployment simulation: The YouTube-scale storage example motivates compression, but there is no simulation quantifying achievable savings and performance under realistic retrieval traffic and hardware constraints.
- Comparison breadth: Baselines omit modern token pruning, KV-cache–style query-agnostic compression tailored for retrieval, or recent multi-vector clustering approaches beyond H-Pool; broader comparisons are needed.
- Training objectives clarity: Loss functions and negatives (beyond BEIR MS MARCO distillation) are under-specified for vision/audiovisual settings; ablations on training losses and sampling strategies are missing.
- ViDoRe indexing choice: Using flat search for both baseline and compressed indices avoids PLAID for the baseline due to dimensionality, but loses the opportunity to quantify the practical advantage of compression (enabling ANN/PLAID) on retrieval speed.
- Audio sampling constraints: MultiVENT experiments reduce audio to 4 kHz due to memory limits; the accuracy–efficiency trade-off of different audio rates and chunking strategies is not characterized.
- Effect on reranking candidate sets: For multi-stage systems, how compression alters the recall@k candidate pool composition (e.g., diversity, hardness) for rerankers is not evaluated.
- Hyperparameter sensitivity: No sweeps reported for:
- Number of appended universal queries vs. budget (beyond limited MSR-VTT settings),
- Choice of m relative to average document length,
- Encoder layer used for clustering features.
- Ablations within AGC: Missing component ablations (centroid selection alone, hard assignment alone, weighted aggregation alone) to confirm each part’s contribution across modalities.
- Memory token collapse mitigation: MemTok’s “information collapse” is claimed but not quantified; regularizers (orthogonality, diversity, contrastive separation) or architectural variants are not tested.
- Security/adversarial robustness: How compression methods handle adversarial tokens (e.g., repetitive distractors, watermarking noise) is not explored.
- Reproducibility details: Hardware specs, seeds, and run-to-run variability are not documented; reproducibility and sensitivity to mixed-precision/bfloat16 effects remain unclear.
Practical Applications
Overview
This paper introduces practical, query-agnostic methods to compress multi-vector late-interaction indices across modalities (text, visual documents, video, audiovisual), with a new method, Attention-Guided Clustering (AGC), that consistently retains performance at high compression and sometimes surpasses uncompressed indices. The key operational benefit is a constant vector budget per document, turning storage and query-time compute from length-linear to budget-bounded, enabling scalable omni-modal retrieval.
Below are actionable applications, organized by deployment horizon, with sectors, potential tools/products/workflows, and feasibility notes.
Immediate Applications
These can be piloted or deployed today using existing late-interaction stacks (e.g., ColBERT/PLAID), current multi-modal encoders (e.g., Qwen2.5/3-VL), and the released codebase.
- Enterprise multimodal search cost-down (index right-sizing)
- Sector: software/infrastructure; enterprise knowledge management.
- What: Compress existing late-interaction indices for PDFs, slide decks, dashboards, videos, and call recordings to constant budgets (e.g., 32–128 vectors/doc) using AGC or H-Pool, reducing storage/compute while preserving nDCG/recall.
- Tools/workflow: Integrate AGC as a post-encoder compression stage in a ColBERTv2 + FastPLAID pipeline; capacity-plan by sweeping token budgets.
- Assumptions/dependencies: Support for multi-vector stores (FAISS/PLAID); fine-tuning data to train AGC; compatible encoders (e.g., Qwen-VL).
- Visual document retrieval at scale (PDFs with tables/figures)
- Sector: legal, consulting, pharma/biomed, finance/ESG.
- What: Use AGC to compress ViDoRe-like visual document indices to budgets (e.g., 64) and retain cross-page, layout-aware retrieval effectiveness.
- Tools/workflow: Qwen-VL encoder for pages; AGC compression; FastPLAID or flat search for production; RAG pipelines for downstream QA.
- Assumptions/dependencies: OCR/vision-language encoder quality; heterogeneous document layouts; GPU for training.
- Video asset management and newsroom search
- Sector: media/entertainment; broadcast; marketing.
- What: Compress per-video multi-vector indices (frames + captions) to constant budgets (5–128) for fast, low-cost retrieval across massive catalogs, with AGC often improving R@1 vs full indices on MSR-VTT-like tasks.
- Tools/workflow: Frame sampling (e.g., 24 frames), Qwen-VL encoders, AGC compression, FastPLAID for retrieval; tagless search and clip discovery.
- Assumptions/dependencies: Representative frame/audio sampling; alignment between editorial search intents and encoder coverage.
- Compliance, e-discovery, and audit retrieval
- Sector: finance, healthcare, government.
- What: Create compact, auditable indices of calls (audio), screen recordings, and visual documents; bound storage growth and enable quick scoped search.
- Tools/workflow: Audio+video pipelines with AGC; domain-tuned universal queries; policy-aligned retention tiers with budget constraints.
- Assumptions/dependencies: Data governance approvals; handling PII in embeddings; consistent audio quality.
- RAG over long multimodal documents (constant-bundle retrievers)
- Sector: software, developer tools, customer support.
- What: Replace length-linear retrievers in RAG with constant-budget multi-vector indices for PDFs, knowledge bases, and product manuals to reduce latency and cold-start costs.
- Tools/workflow: AGC-compressed doc embeddings; ColBERT MaxSim scoring; reranking; chunk expansion only on shortlisted docs.
- Assumptions/dependencies: LLM context window limits; reranker availability; balanced budget vs recall.
- Academic digital libraries and preprint search
- Sector: academia, publishing.
- What: Compress indices for visual-heavy scientific PDFs (figures/tables) to maintain retrieval quality while cutting storage for large corpora.
- Tools/workflow: ViDoRe-like setup; AGC training with limited supervision; open-source FastPLAID index.
- Assumptions/dependencies: Availability of figure/table queries; licensing of pretrained VL models.
- Non-parametric fallback compression for zero-training settings
- Sector: small/medium teams; pilots/PoCs.
- What: Apply H-Pool (hierarchical pooling) to existing indices to instantly reduce footprint without model retraining.
- Tools/workflow: Batch offline pool-merge scripts over per-document vectors; selective token protection for OCR or titles.
- Assumptions/dependencies: Acceptable variance across domains; sensitivity to outliers.
- Edge/on-device personal media search
- Sector: consumer devices; daily life.
- What: Build constant-size indices of personal photos and short videos for on-device, private semantic search.
- Tools/workflow: Lightweight VL encoders; AGC with small budgets (e.g., 5–32); local ANN search.
- Assumptions/dependencies: Mobile inference and storage constraints; privacy policies; battery/thermal limits.
- Multilingual video search in contact centers
- Sector: customer support/BPO; global enterprises.
- What: Use AGC with audiovisual encoders to compress indices for multilingual video FAQs and how-tos, enabling quick retrieval under tight budgets.
- Tools/workflow: Qwen-Omni or equivalent; 4–16 kHz audio sampling; AGC compression; fallback to rerankers.
- Assumptions/dependencies: Audio sampling trade-offs; multilingual queries; varied acoustic conditions.
- Storage and energy cost modeling for green AI
- Sector: policy, sustainability offices in tech.
- What: Adopt constant-budget indexing for multimodal corpora to set internal storage/energy targets and track gains (e.g., petabyte-scale reductions).
- Tools/workflow: Budget-vs-quality dashboards; periodic reindex with budget sweeps; energy audits.
- Assumptions/dependencies: Accurate cost telemetry; performance guardrails; stakeholder buy-in.
- Vector database feature: constant-budget, multi-vector collections
- Sector: vector DB vendors, search platforms.
- What: Offer “constant-budget multi-vector” collections with built-in AGC/H-Pool compression and FastPLAID-compatible scoring.
- Tools/workflow: New collection type; training hooks for AGC; budget-aware ingestion; metrics for utilization (e.g., token hit rates).
- Assumptions/dependencies: Product roadmap; IP/commercial terms; backward compatibility.
- Benchmarking and evaluation suites for multimodal compression
- Sector: academia/industry research labs.
- What: Add AGC and H-Pool baselines to BEIR, ViDoRe, MSR-VTT, MultiVENT evaluations; publish budget-performance curves.
- Tools/workflow: Reproducible pipelines; shared checkpoints; standardized budgets and metrics.
- Assumptions/dependencies: Access to datasets; consistent protocols.
Long-Term Applications
These require further R&D, engineering scale-out, or ecosystem support (standards, hardware, compliance), but are natural extensions of the paper’s findings.
- Web-scale multimodal search (YouTube-scale archives)
- Sector: consumer search; platforms.
- What: Use constant-budget multi-vector indices to make truly multimodal web search tractable across billions of videos and visual documents.
- Tools/workflow: Distributed AGC training pipelines; PLAID-like multi-stage retrieval; aggressive residual quantization; streaming ingestion.
- Assumptions/dependencies: Industrial-scale compute; strong domain generalization; governance for user content.
- Retrieval-first multimodal model pretraining
- Sector: foundation models; model providers.
- What: Co-train encoders with a compression objective (AGC-in-the-loop) to natively produce high-saliency, low-redundancy representations that outperform uncompressed baselines.
- Tools/workflow: Joint training curricula; universal query token banks; contrastive + late-interaction losses.
- Assumptions/dependencies: Large curated multimodal corpora; compute budget; careful regularization to avoid collapse.
- Adaptive/dynamic budgets and elastic indices
- Sector: cloud platforms; ops/SRE.
- What: Vary budgets by document class, seasonality, or retrieval frequency (e.g., hot videos get 128, cold get 16), rebalancing costs and SLAs.
- Tools/workflow: Telemetry-driven budget assignment; nightly reindex; automated guardrails based on quality drift.
- Assumptions/dependencies: Stable quality monitoring; low-friction reindexing; predictable traffic patterns.
- Streaming and continual learning compression
- Sector: surveillance, autonomous systems, IoT.
- What: Online AGC that updates cluster centroids incrementally as new frames/audio arrive, enabling rolling compressed indices for long streams.
- Tools/workflow: Sliding-window encoders; online clustering approximations; drift detection.
- Assumptions/dependencies: Real-time compute; robustness to non-stationary data.
- Privacy-preserving and compliant indexing
- Sector: healthcare, finance, public sector.
- What: Combine constant-budget indices with differential privacy or secure enclaves to minimize sensitive content in embeddings while enabling audit.
- Tools/workflow: DP noise on per-cluster aggregation; policy-aware universal queries; consent-based retention tiers.
- Assumptions/dependencies: Legal frameworks; utility–privacy trade-offs; auditor tooling.
- Hardware acceleration for late interaction with compressed indices
- Sector: semiconductors; datacenter hardware.
- What: Specialized kernels/ASIC support for MaxSim over compact multi-vectors plus centroid residuals, exploiting cache locality and low-bit quantization.
- Tools/workflow: Vendor-optimized libraries; kernel fusion for attention-guided pooling; INT4/FP8 support.
- Assumptions/dependencies: Vendor interest; standardized operator sets.
- Query-aware expansion on demand (hybrid compression)
- Sector: search platforms.
- What: Serve compressed indices by default; for borderline scores, expand clusters (e.g., fetch original tokens within a matched cluster) to refine ranking.
- Tools/workflow: Two-tier stores (compressed + raw); latency-aware policies; partial reconstruction APIs.
- Assumptions/dependencies: Storage of provenance mapping from clusters to raw tokens; tolerable tail latency.
- Federated and domain-specialized AGC
- Sector: multi-tenant SaaS; regulated industries.
- What: Train AGC per-tenant or per-domain (e.g., radiology, legal briefs) without sharing raw data using federated learning.
- Tools/workflow: Federated updates for universal queries; secure aggregation; domain adapters.
- Assumptions/dependencies: Heterogeneous hardware; privacy-preserving protocols.
- Standards and diagnostics for multimodal index utilization
- Sector: standards bodies; observability vendors.
- What: Define metrics like token-utilization rate, inter-position redundancy, and budget-quality curves to guide procurement and SLAs.
- Tools/workflow: Open telemetry spec; dashboards; budget recommendations.
- Assumptions/dependencies: Community adoption; neutral benchmarking.
- Consumer-grade on-device multimodal RAG
- Sector: mobile/AR; education.
- What: On-device assistants that search/comprehend lectures, slides, and labs offline using constant-budget indices, enabling privacy-first study/coaching.
- Tools/workflow: Local VL encoders; AGC compression; small rerankers; context assembly to LLMs.
- Assumptions/dependencies: Efficient mobile models; energy/thermal constraints; UX for provenance.
- Content moderation and safety search at scale
- Sector: platforms; policy.
- What: Compressed multimodal indices enabling proactive detection and targeted review across video/image/audio at lower cost.
- Tools/workflow: Safety-aligned universal queries; topic/behavior filters; human-in-the-loop workflows.
- Assumptions/dependencies: Evolving policy definitions; bias and fairness evaluation.
- Domain-optimized audio handling for audiovisual retrieval
- Sector: voice/video platforms.
- What: Co-design audio sampling and AGC to preserve speech/music cues under tight budgets (e.g., beyond the 4 kHz constraint noted), improving multi-language retrieval.
- Tools/workflow: Learned audio saliency; codec-aware encoders; cross-modal alignment.
- Assumptions/dependencies: Robust audio datasets; latency budgets; multilingual ASR baselines for comparison.
Notes on Feasibility and Dependencies (Cross-Cutting)
- Model backbones: Results improve with stronger backbones (e.g., Qwen3-VL-4B > Qwen2.5-VL-3B), but most gains require only moderate-scale encoders.
- Infrastructure: Best performance uses late-interaction search (ColBERT/PLAID). Vector DBs must support multi-vector per document and MaxSim-like scoring, or provide adapters.
- Training: Parameterized methods (AGC, MemTok, SeqResize) benefit from task/domain fine-tuning; H-Pool offers a no-training fallback with lower stability.
- Budgets: Align appended universal query tokens with index budget (e.g., 32/32) for stable results; extremely low budgets (e.g., 5) still viable for some video tasks.
- Data quality: Redundancy/noise (e.g., static frames, silent audio) is common; AGC’s attention-based centroid selection helps, but domain noise can still impact utility.
- Governance: Compression can lower storage of sensitive features but does not remove privacy obligations; adopt appropriate data protection and audit mechanisms.
Glossary
- Agglomerative hierarchical pooling: A bottom-up clustering procedure that repeatedly merges similar groups based on a linkage criterion until a target number of clusters remains. Example: "agglomerative hierarchical pooling with Ward linkage"
- Attention-Guided Clustering (AGC): A compression method that selects salient centroids via learned attention and forms weighted clusters to maximize index utility under a fixed token budget. Example: "AGC uses an attention-guided mechanism to identify the most semantically salient regions of a document as cluster centroids and to weight token aggregation."
- BEIR: A heterogeneous benchmark suite for evaluating text retrieval systems across multiple domains and tasks. Example: "Evaluating these methods on retrieval tasks spanning text (BEIR), visual-document (ViDoRe), and video (MSR-VTT, MultiVENT 2.0)"
- bfloat16 precision: A 16‑bit floating-point format with a larger dynamic range than FP16, commonly used to speed up training while preserving numeric stability. Example: "bfloat16 precision."
- Bidirectional attention: An attention mechanism where tokens can attend to both preceding and following context, typical in encoder-style transformers. Example: "We enable bidirectional attention and initialize the pretrained weights from Qwen2.5-VL-3B."
- ColBERT: A late-interaction retrieval architecture that encodes queries and documents into multi-vector representations and scores via per-token maximum similarities. Example: "we adopt ColBERT-style Late Interaction"
- ColBERTv2: An optimized version of ColBERT that introduces efficiency improvements such as two-stage retrieval with cluster centroids to reduce scoring costs. Example: "Optimizations like ColBERTv2 have improved efficiency through a two-stage retrieval pipeline that uses document cluster centroids to avoid scoring every document, enabling sub-linear scaling in collection size."
- Cosine distance matrix: A matrix of pairwise distances computed from cosine similarity, used here to guide hierarchical pooling. Example: "We compute a cosine distance matrix"
- Cosine similarity: A similarity measure between vectors based on the cosine of the angle between them, commonly used in embedding spaces. Example: "based on cosine similarity:"
- FastPlaid index: A compressed index format for late-interaction retrieval that stores cluster centroids and quantized residuals to accelerate scoring. Example: "FastPlaid index"
- Hard negatives: Non-relevant examples that closely resemble relevant ones, used to make training more discriminative. Example: "hard negatives scored by a reranker."
- H-Pool (Hierarchical Pooling): A non-parametric compression method that iteratively groups similar vectors and replaces each group with its mean. Example: "H-Pool iteratively groups similar vectors and replaces them with their mean."
- KV cache eviction: Techniques for removing key–value pairs from transformer attention caches to reduce memory and computation for long contexts. Example: "token compression via KV cache eviction."
- Late Interaction: A retrieval paradigm that defers query–document token interactions to scoring time, enabling fine-grained matching while retaining efficiency. Example: "Late interaction has emerged as a dominant paradigm for information retrieval in text, images, visual documents, and videos"
- MaxSim operation: The scoring mechanism in ColBERT that sums, over query tokens, the maximum similarity with any document token. Example: "via the MaxSim operation:"
- Memory Tokens (MemTok): Learnable tokens appended to a document that attend over its content and serve as a compressed representation. Example: "MemTok is a parameterized compression method that appends learnable "memory tokens" to a document context to use as the document representation."
- MultiVENT 2.0: A large-scale, multilingual audiovisual text-to-video retrieval benchmark with multiple relevant videos per query. Example: "MultiVENT 2.0 is a text-to-video retrieval dataset with queries that target visual and audio information."
- nDCG@10: Normalized Discounted Cumulative Gain at rank 10; a graded relevance metric emphasizing higher-ranked correct results. Example: "maintaining performance (nDCG@10) at high compression."
- OmniEmbed-7B: A single-vector embedding model used as a strong dense retrieval baseline for text-to-video tasks. Example: "outperforming the single dense vector encoder, OmniEmbed-7B"
- P-frames: Predictive video frames encoded relative to previous frames, typically more compressed than independently coded I-frames. Example: "Just as P-frames in video are compressed more heavily than I-frames"
- PLAID: An efficient late-interaction indexing approach that clusters document token vectors and stores quantized residuals for fast retrieval. Example: "Finally, index methods like PLAID cluster the document token vectors and represent each as its nearest cluster centroid plus a low-bit-quantized version of its residual."
- Query-agnostic: Methods that compress or index documents without access to the future query, ensuring representations are broadly useful. Example: "query-agnostic methods for compressing multi-vector document representations"
- Recall@k (R@k): The fraction of queries for which at least one relevant item appears in the top-k results. Example: "we report appropriate recall at k (R@k)"
- Reranker: A secondary model that re-evaluates and re-orders top retrieval candidates to improve final ranking quality. Example: "scored by a reranker."
- Sequence Resizing (SeqResize): A learned compression technique that projects the sequence length down to a fixed number of vectors via an MLP. Example: "SeqResize is a parameterized compression method that projects the output of an encoder along the sequence dimension to a compressed representation with a fixed number of tokens."
- Sub-linear scaling: Growth in computation or storage slower than linear with respect to collection size, improving scalability. Example: "enabling sub-linear scaling in collection size."
- Universal queries: Trainable tokens that attend over documents to estimate token saliency for query-agnostic compression. Example: "learned ``universal queries,'' special tokens that probe the document for significant content."
- ViDoRe v2: A visual document retrieval benchmark evaluating multimodal understanding of PDFs, including text, layout, and graphics. Example: "ViDoRe v2 is a visual document retrieval benchmark designed to evaluate systems on visually rich PDFs where information is conveyed through both text and layout (e.g., figures, tables)."
- Ward’s method: A hierarchical clustering criterion that merges clusters to minimize the increase in within-cluster squared error. Example: "Ward’s method iteratively merges the pair of clusters"
- Weighted Aggregation: A cluster pooling strategy that averages token vectors with learned saliency weights to preserve discriminative details. Example: "We therefore employ Weighted Aggregation"
Collections
Sign up for free to add this paper to one or more collections.