- The paper presents a novel training framework that integrates action-aware supervised fine-tuning with conservative KL-regularized RL to improve GUI agents' reasoning and action execution.
- It introduces action-aligned data curation and adaptive gradient scaling to mitigate reward ambiguity and preserve spatial grounding accuracy in long-horizon tasks.
- Experimental results demonstrate significant gains in task completion and step accuracy across multiple benchmarks, validating the method's practicality and reproducibility.
GUI-Libra: Action-Aware Data-Efficient Training of Native GUI Agents with Reasoning and Partially Verifiable RL
Motivation and Background
The development of native GUI agents—end-to-end vision-LLMs (VLMs) mapping user instructions and observations to executable actions—has been propelled by recent open-source advances in visual grounding and elementary action execution. However, open-source models lag behind closed systems in long-horizon navigation, which requires nuanced reasoning coupled with precise stepwise actions. Two primary bottlenecks constrain the open ecosystem: a deficit of high-quality, action-aligned reasoning data and the direct transplantation of generic post-training pipelines that neglect the distinctive challenges imposed by GUIs.
GUI navigation diverges from classical RL for LLMs (RLVR): step-wise rewards are only partially verifiable since multiple actions at a given state can be valid, while offline supervision typically checks just a single demonstration. This introduces reward ambiguity, undermines training stability, and renders offline metrics poor predictors of online task completion. Standard supervised fine-tuning (SFT) on long chain-of-thought (CoT) traces further degrades grounding accuracy, creating a persistent tension between reasoning and correct spatial localization.
Methodology: GUI-Libra Training Framework
GUI-Libra systematically addresses these challenges, integrating action-aware SFT and conservative RL on an open-source foundation. The design pivots on three core modifications:
Action-Aligned Reasoning Data Curation
A scalable data construction and filtering pipeline was introduced, aggregating and augmenting trajectories from public datasets (e.g., AndroidControl, GUI-Odyssey, AMEX, AGUVIS). Reasoning traces are enriched via careful prompt engineering and generator selection (notably GPT-4.1, outperforming GPT-4o and o4-mini in controlled studies), yielding granular rationales that couple semantic intent to executable actions. Noisy or ambiguous entries are filtered using action re-prediction and bounding-box verification, improving action–reasoning alignment and reducing label noise.

Figure 1: GUI-Libra-81K data samples contain rich context and split outputs: chain-of-thought reasoning and structured executable actions, facilitating downstream learning and evaluation.
Action-Aware Supervised Fine-Tuning (ASFT)
ASFT mitigates grounding degradation induced by verbose reasoning. It mixes supervision modalities—reasoning-then-action and direct-action—and applies token-level reweighting (αa, αg) to emphasize action and spatial grounding tokens in the loss. This approach strengthens action prediction, preserves grounding accuracy even with longer CoT outputs, and enables flexible inference with or without explicit reasoning.
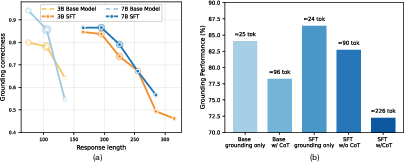
Figure 2: Grounding accuracy deteriorates as response length increases; action-aware SFT alleviates this, preserving spatial localization under long reasoning.
Conservative RL with KL Regularization and Success-Adaptive Negative Gradient Scaling
Unlike standard RLVR, KL regularization is crucial in GUI navigation. It limits distribution shift (occupancy mismatch coefficient C(π)) and controls the off-demo validity mass ηˉπ, stabilizing offline–online performance alignment. Reward ambiguity from partial verifiability is further attenuated with success-adaptive negative gradient scaling (SNGS): negative policy gradients are downweighted adaptively based on empirical group success rates, constraining over-penalization of valid but uncredited actions.
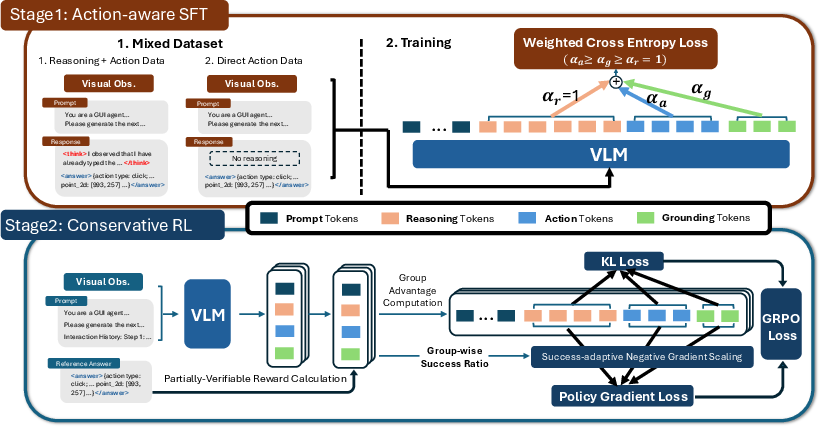
Figure 3: GUI-Libra’s two-stage training—action-aware SFT followed by KL-regularized RL with adaptive gradient scaling—drives consistent improvements.
Experimental Evaluation
Experiments across offline (AndroidControl-v2, MM-Mind2Web-v2) and online benchmarks (AndroidWorld, WebArena-Lite-v2, Online-Mind2Web) demonstrate robust gains. GUI-Libra outperforms base models and several larger parameter counterparts, both open and proprietary, in stepwise accuracy and task completion, with pronounced improvements at modest model scales (e.g., 4B/8B).
Numerical Highlights:
- On AndroidWorld, GUI-Libra-4B/8B increase success rates by 15.6%/12.2% over their base models.
- On Online-Mind2Web, they achieve +4.0%/+8.7% improvements.
- On WebArena-Lite-v2, +12.5%/+11.3% gains are observed.
GUI-Libra’s training correlates offline and online metrics more tightly than prior pipelines: KL-regularized RL achieves Pearson/Spearman correlations up to $0.89/0.83$ between step accuracy and task completion, validating theoretical predictions and practical robustness.
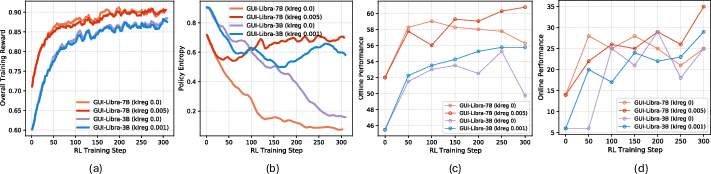
Figure 4: Training and evaluation metrics with/without KL regularization; KL stabilizes reward optimization, policy entropy, and offline–online performance alignment.
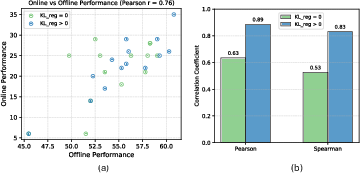
Figure 5: Empirically, KL regularization strengthens the correlation between offline and online evaluation, supporting reliable benchmarking.
Ablations reveal that both SFT and RL-stage filtering consistently boost performance (especially Pass@4), action-aware SFT outperforms naive SFT or direct-action variants, and SNGS further enhances online generalization. Mixing direct grounding data into RL improves single-step visual localization but reduces navigation performance, highlighting a trade-off between spatial grounding and long-horizon reasoning.
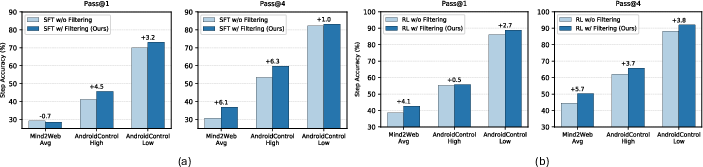
Figure 6: Data filtering at both SFT and RL stages yields reliable gains across benchmarks.
Analysis: Practical and Theoretical Implications
GUI-Libra establishes that competitive, reasoning-capable GUI navigation is attainable using moderate-scale models and open-source trajectories, when action-centric data curation and tailored post-training are employed. The pipeline avoids costly online interaction, improves data efficiency, and fosters reproducible agent evaluation.
Theoretically, GUI-Libra's framework clarifies when and why RLVR and SFT benchmarks fail to predict online task success, providing principled bounds and empirical confirmation. The criticality of KL regularization in partially verifiable settings is formalized and validated.
For practical deployment, GUI-Libra's agentic skills generalize well to live, variable web and mobile environments, unlocking robust value from existing corpora without proprietary data or infrastructure. The reduced reliance on auxiliary planning modules (e.g., step-wise summaries) and improved policy robustness also suggest promising avenues for further research and production.
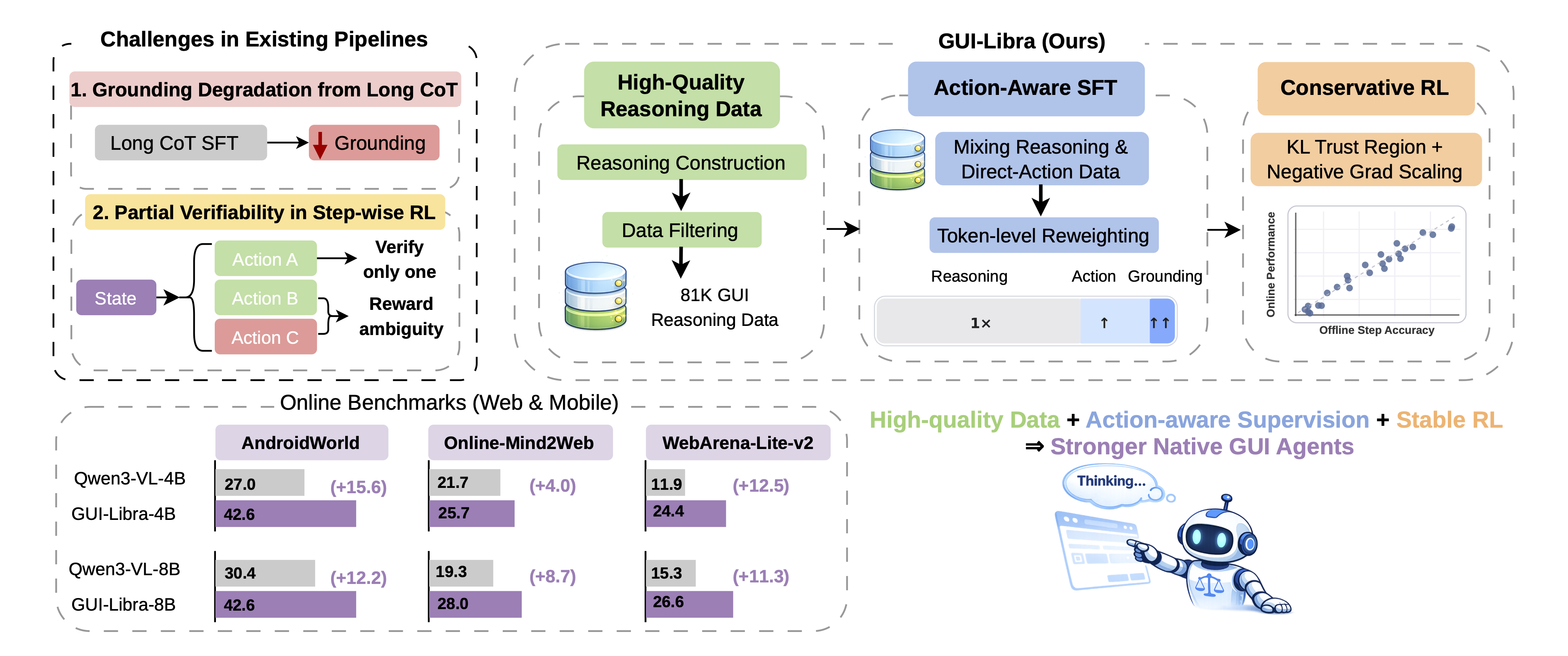
Figure 7: GUI-Libra’s conceptual workflow—action-aligned data, action-aware SFT, and conservative RL yield consistent benchmark gains.
Trajectory Case Studies
GUI-Libra-7B achieves successful long-horizon actions in AndroidWorld, overcoming iterative reasoning challenges and outperforming its base model in multi-step goal completion.
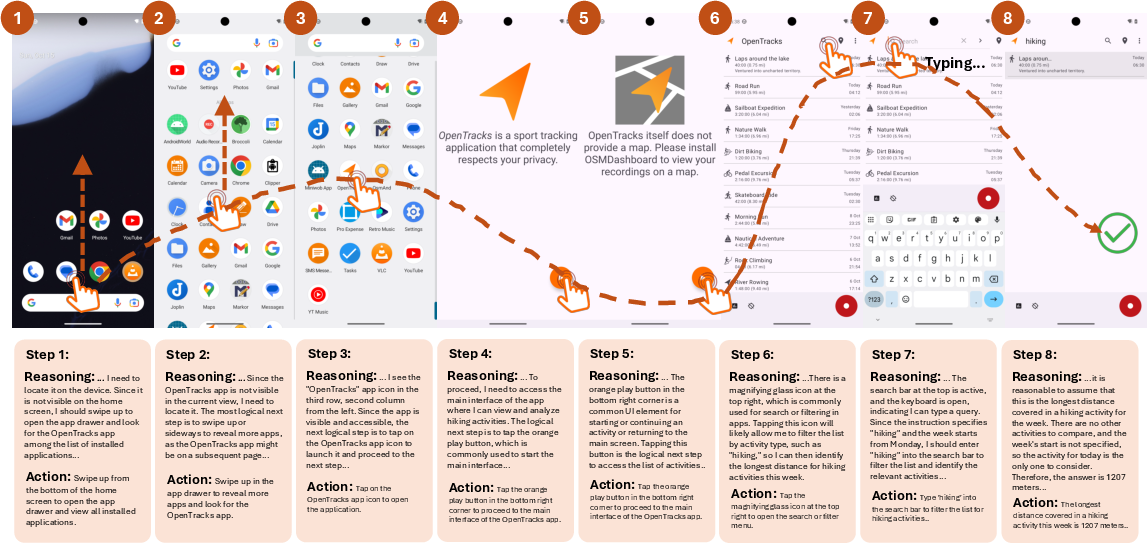
Figure 8: GUI-Libra-7B’s trajectory on AndroidWorld: sustained reasoning and precise actions enable long-horizon task success.
Future Directions
The framework’s scalability is currently limited by public data availability, with mobile trajectories dominating and high-quality web data underrepresented. Extending GUI-Libra to fully online, interactive RL is a promising direction, albeit with deployment and infrastructure challenges. As larger, more diverse datasets emerge, data-efficient post-training recipes will play a central role in pushing the frontier of generalist GUI agents.
Conclusion
GUI-Libra integrates action-aware SFT and conservative RL, reinforced by curated action-aligned reasoning data, to enable robust, reasoning-centric native GUI agents. Empirical and theoretical analyses show reliable gains and improved offline–online alignment, confirming that careful data curation and post-training design can unlock substantial agentic capabilities from existing open datasets. The released models, code, and benchmarks lay a foundation for advancing interactive GUI agent research in practical, scalable, and reproducible ways.