EvoX: Meta-Evolution for Automated Discovery
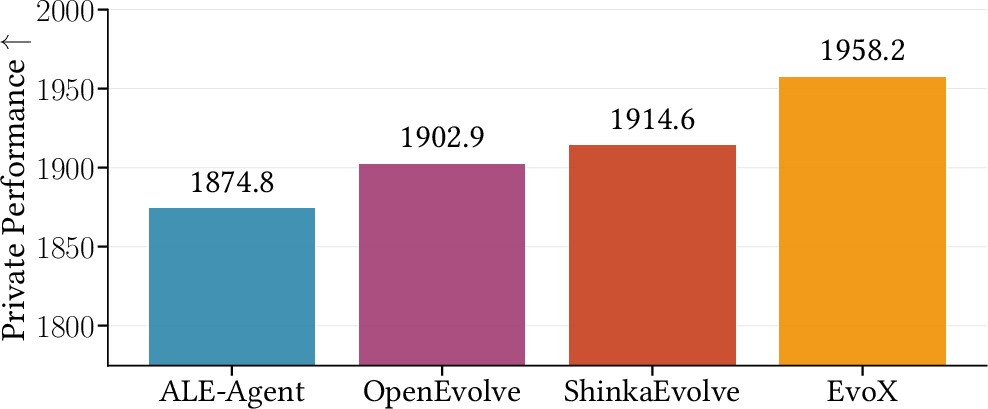
Abstract: Recent work such as AlphaEvolve has shown that combining LLM-driven optimization with evolutionary search can effectively improve programs, prompts, and algorithms across domains. In this paradigm, previously evaluated solutions are reused to guide the model toward new candidate solutions. Crucially, the effectiveness of this evolution process depends on the search strategy: how prior solutions are selected and varied to generate new candidates. However, most existing methods rely on fixed search strategies with predefined knobs (e.g., explore-exploit ratios) that remain static throughout execution. While effective in some settings, these approaches often fail to adapt across tasks, or even within the same task as the search space changes over time. We introduce EvoX, an adaptive evolution method that optimizes its own evolution process. EvoX jointly evolves candidate solutions and the search strategies used to generate them, continuously updating how prior solutions are selected and varied based on progress. This enables the system to dynamically shift between different search strategies during the optimization process. Across nearly 200 real-world optimization tasks, EvoX outperforms existing AI-driven evolutionary methods including AlphaEvolve, OpenEvolve, GEPA, and ShinkaEvolve on the majority of tasks.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new AI system called EvoX. Its main idea is simple: when you’re trying to improve something (like a piece of code, a math solution, or an algorithm), you shouldn’t just change the solution—you should also change the way you search for better solutions. EvoX does both at the same time. It “evolves” candidate solutions and also “evolves” the strategy it uses to find those solutions. This helps the system adapt as the problem changes and avoid getting stuck.
What questions does it try to answer?
The paper asks:
- Can an AI do better if it not only improves solutions but also learns how to search more effectively while it’s working?
- Will this kind of adaptive search beat older methods that use one fixed strategy?
- Does this approach work across very different problems, like math puzzles, computer systems performance, and coding challenges?
How does EvoX work?
Think of EvoX like a team playing a long game:
- The “players” are the candidate solutions the AI generates and tests.
- The “coach” is the search strategy—how the AI picks which past solutions to learn from and how to change them next.
- EvoX doesn’t stick to one playbook. It watches how the game goes and updates the playbook when progress slows.
Here’s the approach, explained with everyday ideas:
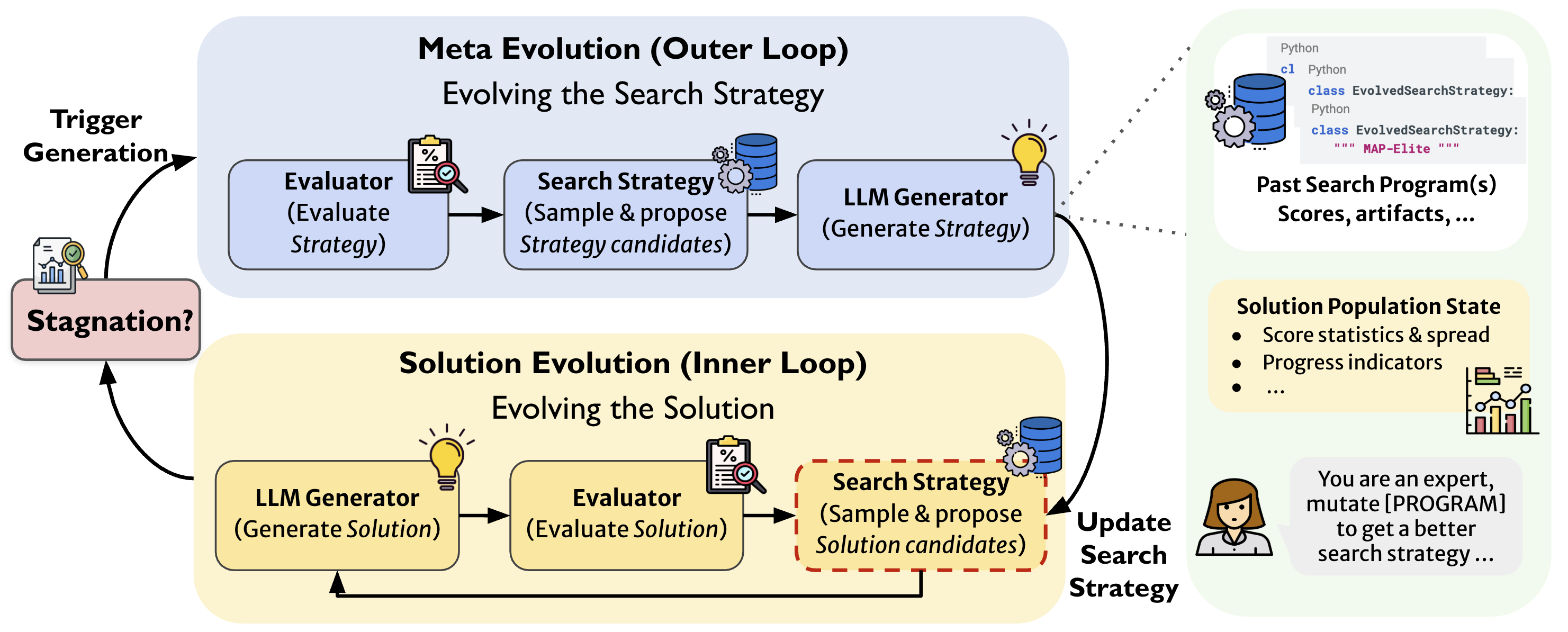
- Two loops (like two gears working together):
- Inner loop: Try new solutions. EvoX looks at past attempts, picks one or more “parents,” and asks a LLM (an AI that generates text and code) to create a new version. It then tests that version and adds the result to its memory.
- Outer loop: Evolve the search strategy. Every few steps, EvoX checks if things are improving. If progress stalls, it changes how it searches—for example, whether to make small tweaks or try big redesigns, and which past solutions to learn from.
- Variation operators (like edit styles when fixing a draft):
- Local refinement: small fixes (like fine-tuning parameters).
- Structural variation: big changes (like switching to a different algorithm design).
- Free-form variation: anything goes (the AI decides how to change it).
- Progress monitoring (like checking the scoreboard regularly):
- EvoX tracks the best score over a short window of steps. If the score isn’t improving enough, it switches strategies.
- It keeps a memory of which strategies worked well under which conditions (for example: low diversity, many similar solutions, or a plateau).
- Strategy evolution (like learning from past playbooks):
- When it switches strategies, EvoX uses the LLM to propose a new search plan, using what worked before and what the current “population” of solutions looks like.
- It validates the new strategy (makes sure it’s usable) before using it.
Analogy: Imagine you’re trying to bake the perfect cookie. At first, you try all sorts of recipes (exploration). Once you find a good one, you tweak sugar or baking time (exploitation). But if those tweaks stop helping, you might switch from cookies to blondies or try a new mixing method. EvoX makes those smart switches automatically.
What did the researchers find?
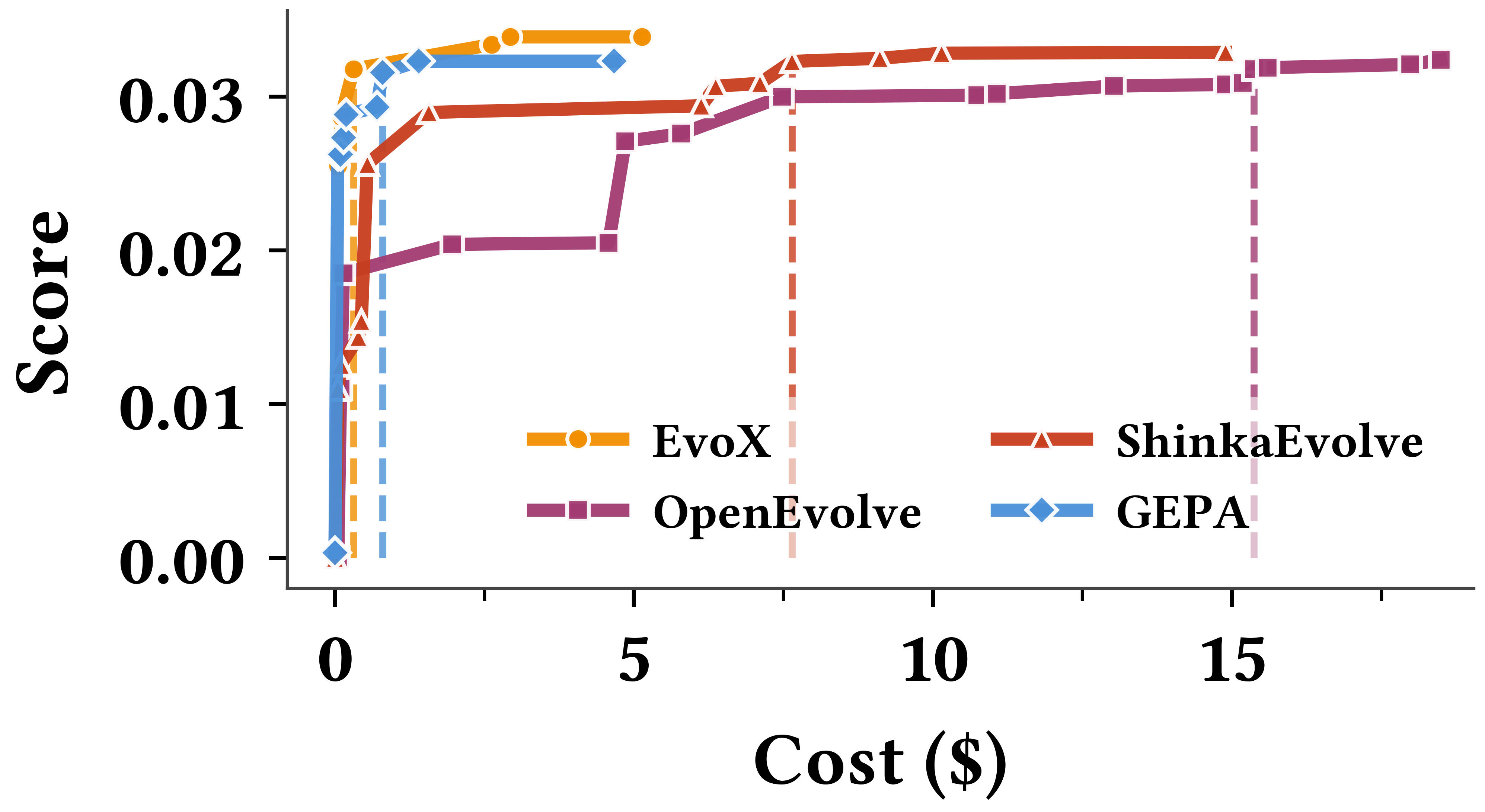
Across nearly 200 real-world tasks, EvoX beat other strong systems that use fixed strategies, like AlphaEvolve, OpenEvolve, GEPA, and ShinkaEvolve. Here are a few examples of what changed and why it mattered:
- Math problems (like packing circles tightly or arranging points to maximize distances):
- EvoX often matched or exceeded the best-known results, even those reported by previous top systems.
- It found smart structures (like hexagonal packings) and used optimization tools to refine them.
- Systems performance (like placing models on GPUs or reducing cloud data transfer costs):
- EvoX discovered practical strategies, such as packing models to reduce peak memory or using clever routing (similar to building efficient trees of connections) to lower transfer cost.
- Example: GPU placement performance jumped from about 26 to over 30 on one benchmark (higher is better), and cloud transfer costs dropped below strong human-made solutions (lower is better).
- Coding and algorithm challenges (like Frontier-CS, with 172 problems):
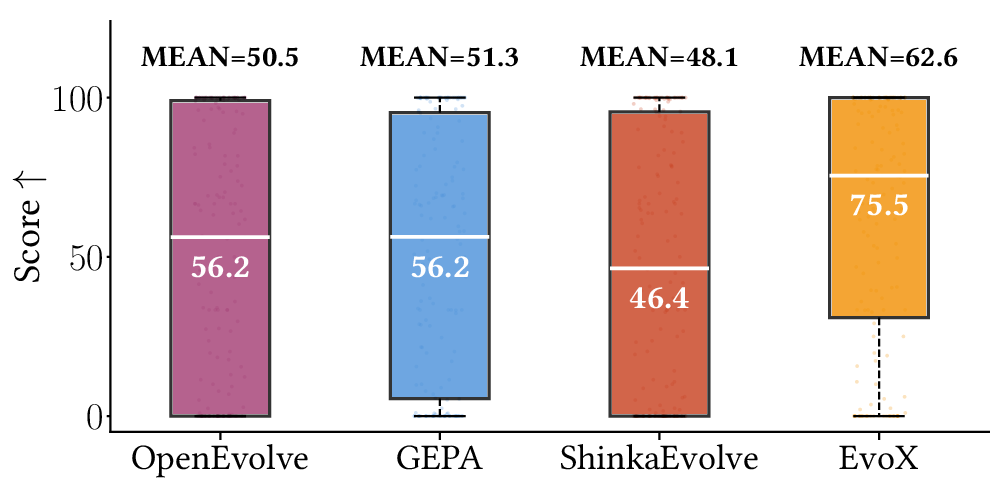
- EvoX achieved a much higher median score (75.5) than other AI systems (for example, a previous best reported was 56.2).
- It stayed consistent across many different tasks, not just a few.
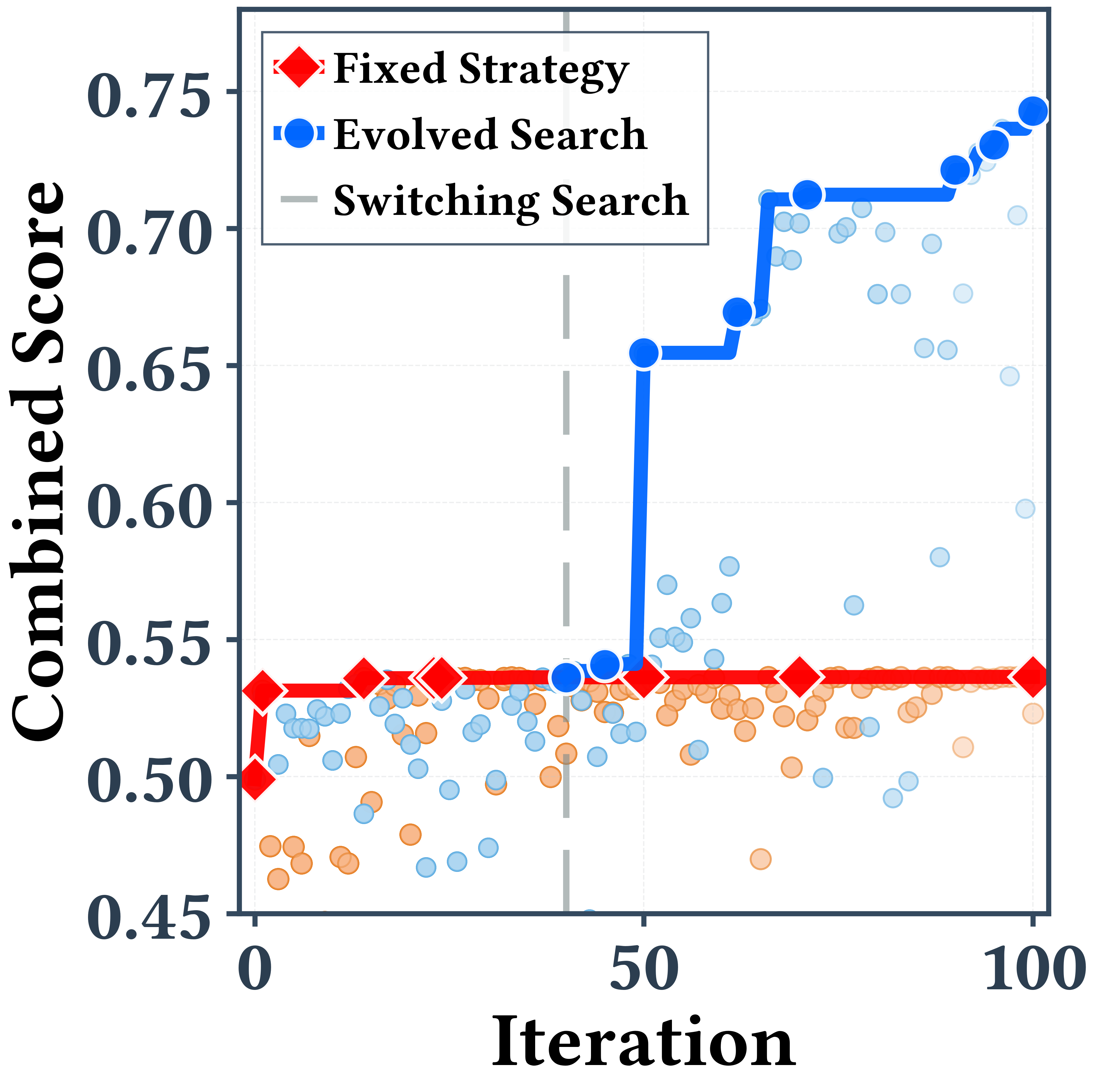
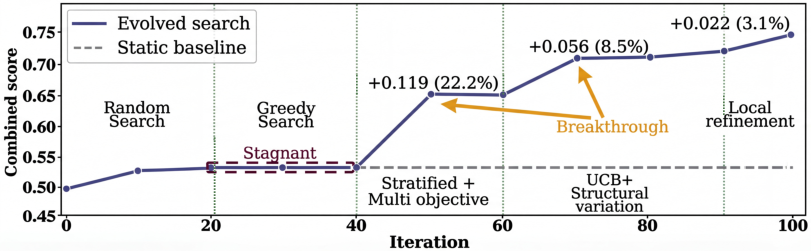
Case study: In a signal processing task (filtering noisy data), EvoX started with random ideas, then switched to mixing solutions that were good at different objectives (like smoothness vs low delay), later tried bigger structural changes, and finally did precise fine-tuning. Each switch led to a jump in performance, ending 34% higher than a fixed strategy.
Why this is important: Fixed strategies often do well at the beginning but get stuck later. EvoX’s ability to change strategies mid-run helps it push past plateaus.
What’s the impact of this research?
- Smarter search: EvoX shows that adapting how you search—based on what’s working right now—is a powerful idea. It’s like a coach who changes tactics mid-game rather than sticking to one plan.
- Broad usefulness: The method worked across math, systems, and coding tasks. That means it could help in many areas where AI needs to discover or improve solutions over time.
- Less manual tuning: Instead of people guessing the right “explore vs exploit” settings or selection rules for each problem, EvoX learns and updates those choices automatically.
- Future directions: This could lead to AI systems that:
- Discover new algorithms in science and engineering.
- Optimize complex computer systems with fewer trial-and-error steps.
- Improve code and prompts more reliably without constant human retuning.
In short, EvoX takes evolution one step further: it evolves solutions and the way it searches for them. That extra layer of learning is what gives it the edge.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, actionable list of what remains missing, uncertain, or unexplored in the paper, to guide future research.
- Lack of theoretical guarantees: no convergence, regret, or stability analysis for the meta-evolution process (outer loop) or for interaction between the two loops; conditions under which strategy evolution provably helps (or hurts) remain unknown.
- Handling of minimization tasks in the progress score: the strategy score and stagnation trigger are defined for “scores” that are implicitly maximized; the paper does not specify how and are consistently computed for minimization objectives or mixed-sign objectives across tasks.
- Sensitivity to hyperparameters: robustness to
W(window size),τ(stagnation threshold), and the specific form of the scoring functionJis not systematically studied across tasks; guidelines for setting or adapting these knobs are absent. - Population descriptor design: the choice of
φ(·)(which features to include, how to normalize, how to handle multi-objective fronts) is not ablated; the contribution of each descriptor component to successful strategy updates is unknown. - Growth and management of the strategy memory
H: memory size, pruning, retrieval policy, and computational overhead asHgrows are unspecified; effects on performance, latency, and context length are not reported. - Representation and validation of strategies: the paper does not detail the DSL/specification for a search strategy, how
Valid(S')is implemented, what failure modes it guards against, and the rate at which invalid or unsafe strategies are generated. - Token and context-budget management: how many parents/inspiration examples are surfaced to the LLM, how prompts are composed within a finite context window, and how context length affects quality/cost are not described or evaluated.
- Reliance on very strong, closed-source LLMs: the outer loop uses GPT-5 as the strategy generator even when the solution generator is Gemini; there is no ablation with smaller/open models or a same-backbone-only setup to isolate the effect of this extra capability on reported gains.
- Cost and latency accounting at scale: aside from a single-task cost plot, there is no comprehensive, per-benchmark report of token usage, wall-clock time, and cost broken down by inner vs. outer loop calls; comparisons to baselines may not reflect total compute fairly.
- Fairness of baseline comparisons: AlphaEvolve results are taken from its paper with unknown budgets; baseline frameworks are capped at 100 iterations without ensuring cost parity; the impact of differing token counts, prompt sizes, and invalid generations is not controlled.
- Strategy switching dynamics and failure modes: no analysis of oscillations between strategies, premature switching, or sticking with suboptimal strategies; absence of safety mechanisms like hysteresis, cooldowns, or ensemble selection is not discussed.
- Noisy or stochastic evaluators: how EvoX handles evaluation noise (e.g., variance in systems benchmarks or stochastic programs), de-biasing of
J, or statistical tests for deciding stagnation is not addressed. - Multi-objective optimization formalization: while multi-objective sampling is used in case studies, the outer-loop objective is scalarized; general support for Pareto-aware progress signals (e.g., hypervolume) or principled multi-objective
Jis not explored. - Operator design and extensibility: only three variation operators are supported (refinement, structural, free-form), instantiated by a “lightweight model”; procedures for automatically discovering new operators, adapting operator semantics per domain, or ablations on operator sets are missing.
- Robustness to initialization beyond one task: the paper shows robustness to different fixed initial strategies on a single math task; broader evidence across domains and tasks, and diagnostics for when strong initial solutions bias search to local optima, are limited.
- Generalization and overfitting risks: discovered algorithms and programs are evaluated on the same benchmark settings; transfer to held-out instances, deployment settings (e.g., real clusters for PRISM/Cloudcast), or distribution shifts is not tested.
- Scaling with evaluation budget: how EvoX behaves with larger
T(e.g., diminishing returns, number and timing of strategy updates, memory/cost blow-up) is not systematically measured. - Role of the solution-generator backbone: performance dependence on the solution LLM (e.g., smaller open-source models vs. GPT-5/Gemini), and whether the outer loop can compensate for weaker generators, is unstudied.
- Integration with generator adaptation: combining EvoX’s search-strategy evolution with model fine-tuning or RL-based generator adaptation (e.g., ThetaEvolve/FLEX-style) is not explored; potential synergies or interference remain open.
- Oscillation and diversity control in the population: explicit population curation (e.g., elitism, deduplication, novelty metrics) and its interaction with strategy evolution are not specified; impacts on exploration vs. exploitation balance are unclear.
- Applicability beyond text-coded domains: feasibility in domains requiring non-text actions (e.g., circuit/robot design, wet-lab protocols) or multi-modal generators is not demonstrated.
- Frontier-CS/ALE evaluation details: per-task timeouts, compile/runtime failures, and flake rates are not reported; it is unclear how invalid code is handled, and how much variance exists across runs beyond “mean over 3 seeds.”
- Transfer learning of strategies: whether strategies (or components of
H) learned on one task can bootstrap others (cross-task meta-learning) is not evaluated. - Security and prompt robustness: the outer-loop prompting that conditions on
Handφmay be susceptible to prompt drift or degenerate strategies; safeguards against adversarial or self-referential prompts are unspecified. - Reproducibility assets: prompts for both solution and strategy generation, operator templates, and evaluator configurations are not fully described; it is unclear whether the released code includes all artifacts to reproduce results across the 196 tasks.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed with today’s systems and evaluators, leveraging the EvoX method’s demonstrated performance on systems optimization, algorithm engineering, and signal processing tasks.
- GPU/Model Placement Optimizer for AI Inference/Training
- Sector(s): Software, Cloud/MLOps, AI Infrastructure
- What it does: Co-evolves placement strategies (e.g., PRISM-style KV-cache–aware thresholds + Best-Fit-Decreasing) to maximize throughput, reduce latency, and improve hardware utilization across heterogeneous GPUs and clusters.
- Tools/products/workflows:
- MLOps plugin for Ray/Databricks/Kubeflow or Kubernetes schedulers that monitors load and evolves placement heuristics under SLA constraints.
- Canary rollout + A/B evaluation harness leveraging cluster telemetry.
- Assumptions/dependencies:
- Accurate evaluators (throughput, latency, SLA metrics) and safe rollback mechanisms.
- Access to a strong LLM for strategy generation and sufficient iteration budget.
- Compliance with production change management and auditability.
- Cross-Region Data Transfer & Multicast Cost Optimizer
- Sector(s): Cloud Networking, CDN/Data Platforms
- What it does: Evolves routing and batching policies (e.g., Steiner-tree inspired multicast) to minimize cost/egress while meeting delivery SLAs.
- Tools/products/workflows:
- Cloud cost optimizer integrated into data pipeline schedulers (e.g., Airflow, Dagster).
- Policy-as-code modules that evolve and validate strategies against a traffic replay/simulator.
- Assumptions/dependencies:
- Reliable cost/performance simulators or offline replays; guardrails to avoid SLA violations.
- APIs/permissions to influence routing/scheduling choices.
- High-Throughput Transaction Scheduling for Databases/Services
- Sector(s): Databases, FinTech/Payments, Distributed Systems
- What it does: Generates and refines schedulers that balance conflicts, fairness, and throughput (as in the “Transaction” benchmark improvements).
- Tools/products/workflows:
- DB/queue scheduler component that runs EvoX in staging against deterministic replays; deploys best policy to prod via feature flag.
- Assumptions/dependencies:
- Strict correctness/serializability constraints in evaluators.
- Representative workload traces; safety checks for regression.
- LLM-SQL Prompt/Query Optimizer for BI/Analytics
- Sector(s): Data Analytics, Business Intelligence
- What it does: Evolves prompts, system messages, and query rewriting strategies to maximize accuracy and performance of LLM-assisted SQL generation.
- Tools/products/workflows:
- BI copilot that iteratively tests candidate prompts/queries against ground-truth queries or unit tests; integrates with dbt/Looker/Mode.
- Assumptions/dependencies:
- Ground-truth datasets or high-quality acceptance tests; cost/latency budgets for iterative evaluation.
- Data privacy controls when sending schema/context to LLMs.
- Telemetry/ETL Auto-Repair and Drift Mitigation
- Sector(s): DevOps, Observability, Data Engineering
- What it does: Evolves repair strategies for broken pipelines, schema drifts, and data-quality regressions (“Telemetry Repair” results), with progressive refinement and structural variation.
- Tools/products/workflows:
- CI/CD guardrails that run EvoX repairs on failing jobs, auto-generate patches, validate via tests, and open PRs with diffs and rationale.
- Assumptions/dependencies:
- High-quality unit/integration tests; rollback and human-in-the-loop approval for risky changes.
- Signal Processing Filter/Pipeline Designer (Time-Series, Audio, Wearables)
- Sector(s): IoT, Consumer Health/Wearables, Audio/Communications
- What it does: Designs multi-objective filters balancing fidelity, lag, noise, and false-change rates (e.g., hybrid SSA + Whittaker smoothing; SciPy pipelines).
- Tools/products/workflows:
- Auto-filtering assistant for SciPy/NumPy that proposes/evaluates pipelines on labeled datasets and deploys exportable config/code.
- Assumptions/dependencies:
- Task-specific evaluation metrics and representative labeled data or robust proxy metrics.
- Algorithmic Programming Assistant for Competitive/General Coding
- Sector(s): Software Engineering, Education
- What it does: Evolves candidate solutions (strategy + code) for algorithmic problems (Frontier-CS, ALE-like tasks), switching between exploration and refinement to avoid stagnation.
- Tools/products/workflows:
- IDE extension (VS Code/JetBrains) with local tests and leaderboard; maintains a population of candidates and strategy history.
- Assumptions/dependencies:
- Strong unit tests to prevent regressions; sandboxed execution for untrusted code.
- Prompt and System-Message Optimization for Chatbots/Support Flows
- Sector(s): Customer Support, Marketing, Product Ops
- What it does: Co-evolves prompts, tool-calling policies, and selection heuristics (e.g., Pareto-stratified sampling + UCB) to optimize task success, safety, and CSAT.
- Tools/products/workflows:
- Offline evaluation pipelines using conversation replays and synthetic evals; staged promotion with guardrails.
- Assumptions/dependencies:
- Reliable eval metrics (success, hallucination, safety), data governance, and approval workflows.
- Auto-Tuning and Hyperparameter Search with Adaptive Strategies
- Sector(s): Machine Learning, AutoML
- What it does: Applies EvoX’s evolving search policies to HP tuning (switching between local refinement and structural exploration) for better sample efficiency.
- Tools/products/workflows:
- Integration with Ray Tune/Optuna; pluggable evaluator for validation metrics and budget constraints.
- Assumptions/dependencies:
- Training cost budgets; accurate early stopping/learning-curve predictors to reduce waste.
- Cost/Energy Governance in Cloud Operations
- Sector(s): FinOps, Sustainability
- What it does: Evolves policies for placement, scheduling, and data movement to reduce cost and energy (e.g., shifting workloads to low-carbon regions/slots).
- Tools/products/workflows:
- FinOps dashboards with EvoX-based policy suggestions and automated change proposals with audit trails.
- Assumptions/dependencies:
- Trustworthy carbon-intensity signals, financial models, and governance for automated changes.
- Personal Data Workflow Optimizer (Spreadsheets/SQL in Daily Work)
- Sector(s): Productivity/No-Code Tools
- What it does: Iteratively improves formulas and SQL for speed/correctness using user-provided tests/examples; adjusts search strategy when progress stalls.
- Tools/products/workflows:
- Add-ons for Google Sheets/Excel and notebook plugins with test harnesses and “evolve strategy” controls.
- Assumptions/dependencies:
- User-provided acceptance tests; privacy-safe LLM access and predictable cost controls.
Long-Term Applications
These opportunities extend EvoX to higher-stakes or more complex settings and likely require additional research, domain simulators, or regulatory frameworks.
- Automated Discovery of New Algorithms Across Scientific Domains
- Sector(s): Academia, Software, Scientific Computing
- What it could do: Systematically explore algorithm families for combinatorial optimization, PDE solvers, experimental design, and beyond—co-evolving search strategies as the frontier shifts.
- Tools/products/workflows:
- Research IDEs that integrate EvoX with domain simulators; artifact tracking of strategies/solutions for reproducibility.
- Assumptions/dependencies:
- High-fidelity simulators and objective functions; mechanisms to verify correctness and avoid overfitting to simulators.
- Learned Compiler/Kernel Scheduling and Systems Co-Design
- Sector(s): Systems, Compilers, Hardware/Software Co-Design
- What it could do: Evolve scheduling passes (e.g., TVM/LLVM) and runtime policies (caching, prefetching, NUMA/IO scheduling) that adapt across workloads.
- Tools/products/workflows:
- EvoX integrated into autotuners (e.g., TVM Ansor) and OS-level schedulers with shadow/blue-green deployments.
- Assumptions/dependencies:
- Deterministic performance benchmarks; safe sandboxing; reproducibility across hardware heterogeneity.
- Robotics: Planning, Control, and Task Strategy Evolution
- Sector(s): Robotics, Manufacturing, Logistics
- What it could do: Evolve planning heuristics and control pipelines that adapt to changing environments (e.g., motion planning, grasp policies).
- Tools/products/workflows:
- Sim2real pipelines with risk-aware evaluators; mixed-initiative operation where humans approve strategy shifts.
- Assumptions/dependencies:
- Robust simulators and transfer methods; strict safety constraints and certification.
- Healthcare Operations and Treatment Policy Optimization
- Sector(s): Healthcare, Clinical Operations
- What it could do: Evolve scheduling/triage protocols, resource allocation, or personalized treatment heuristics under multi-objective constraints (outcomes, safety, equity).
- Tools/products/workflows:
- Offline retrospective evaluators; clinical trial frameworks to validate evolved strategies.
- Assumptions/dependencies:
- Regulatory approval, bias and safety audits, and explainability requirements; strong privacy protections.
- Energy and Grid Optimization
- Sector(s): Energy, Utilities, Smart Buildings
- What it could do: Discover dispatch/demand-response policies that respond to dynamic supply, prices, and constraints; co-evolve strategies with seasonality.
- Tools/products/workflows:
- Integration with grid and building energy simulators; staged real-world pilots with override capability.
- Assumptions/dependencies:
- Accurate grid models; robust fail-safes for critical infrastructure; regulator buy-in.
- Financial Strategy and Risk Policy Evolution
- Sector(s): Finance, Trading, Risk Management
- What it could do: Evolve execution/risk policies balancing return, liquidity, and compliance constraints; adapt strategies to regime shifts.
- Tools/products/workflows:
- Backtesting + paper trading environments; compliance and model risk management (MRM) approval gates.
- Assumptions/dependencies:
- Avoiding backtest overfitting; stringent governance; transparency and audit trails.
- Cybersecurity Defense/Detection Heuristic Discovery
- Sector(s): Cybersecurity, IT Ops
- What it could do: Evolve detection rules, response playbooks, and honeypot strategies with meta-evolution to counter stagnation against adaptive adversaries.
- Tools/products/workflows:
- Red/blue team simulators for safe evaluation; controlled deployments with kill switches.
- Assumptions/dependencies:
- Adversarial robustness; minimization of false positives/negatives; strict incident response governance.
- Public Policy and Urban Planning Optimization
- Sector(s): Government, NGOs, Smart Cities
- What it could do: Explore policy portfolios (e.g., congestion pricing, zoning incentives) using multi-objective evaluators (equity, cost, environmental impact).
- Tools/products/workflows:
- Policy labs with agent-based simulations; transparent reporting of assumptions and sensitivity analysis.
- Assumptions/dependencies:
- Reliable causal models; ethical oversight; public accountability and interpretability.
- Personalized Productivity and Home Automation Optimizers
- Sector(s): Consumer Tech, Smart Home
- What it could do: Evolve routines (energy use, HVAC, task schedules) based on preferences and constraints, switching strategies as behavior changes.
- Tools/products/workflows:
- Privacy-preserving on-device or federated EvoX; “explain-and-approve” UX for users.
- Assumptions/dependencies:
- Local evaluators; robust privacy controls; minimal compute footprints and cost predictability.
- Multi-Agent and Tool-Orchestration Strategy Evolution
- Sector(s): Agent Platforms, Enterprise Automation
- What it could do: Meta-evolve how agents select tools, share context, and coordinate, dynamically balancing exploration and exploitation across tasks.
- Tools/products/workflows:
- Orchestrators (LangGraph/LangChain) with EvoX modules; cross-tool evaluation harnesses.
- Assumptions/dependencies:
- Reliable tool telemetry and success metrics; guardrails for cascading errors across tools.
- Governance and Certification for Self-Optimizing Software
- Sector(s): Policy, Compliance, Safety Engineering
- What it could do: Establish standards for auditing, versioning, and certifying systems that evolve their own search strategies.
- Tools/products/workflows:
- Strategy change logs with performance evidence; fail-safe policies; reproducible evaluations.
- Assumptions/dependencies:
- Clear regulatory frameworks; standardized benchmarks; verifiable provenance of changes.
In all cases, feasibility hinges on having:
- High-quality evaluators (objective functions, tests, or simulators) aligned with real-world goals to prevent overfitting or unsafe optimizations.
- Access to capable LLMs and budgeted iteration cycles; cost control and latency constraints in production loops.
- Safety, privacy, and compliance guardrails (sandboxes, canary deploys, audit trails) tailored to the sector’s risk profile.
- Integration pathways that preserve existing populations/evidence and allow human oversight, especially in safety-critical or regulated domains.
Glossary
- ARC-AGI-2: A benchmark for assessing generalization and reasoning in AI systems. "We also report results on the ARC-AGI-2 benchmark, a widely used benchmark for evaluating reasoning and generalization capabilities"
- autoconvolution: Convolution of a function with itself, often used to analyze signal properties. "computes its autoconvolution via FFT"
- bandit-based selection: A decision strategy using multi-armed bandit algorithms to balance exploration and exploitation when choosing among options. "incorporating bandit-based selection on LLM generators."
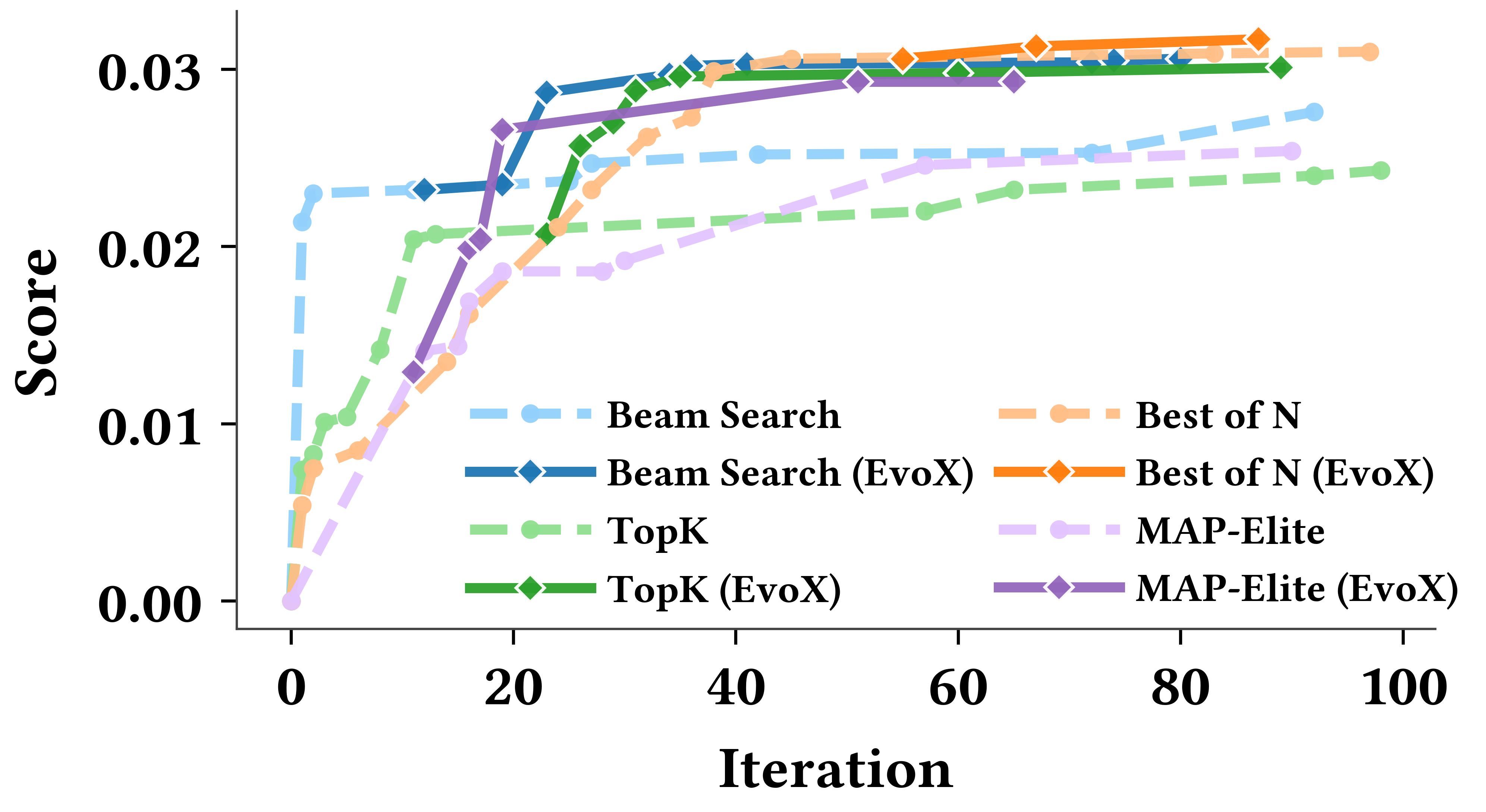
- Beam search: A heuristic search that expands the most promising nodes while limiting the number of candidates kept at each step. "Beam search and Best-of- provide the strongest initializations"
- Best-Fit-Decreasing: A bin-packing heuristic that places items in the tightest-fitting bin after sorting items in decreasing size. "applying Best-Fit-Decreasing packing."
- Best-of-N: A selection strategy that samples N candidates and chooses the best according to a score. "Beam search and Best-of- provide the strongest initializations"
- bin-packing: A combinatorial optimization problem of packing objects into a minimal number of bins without exceeding capacity. "reformulating the problem as a bin-packing assignment."
- exploration-exploitation ratio: A control parameter that balances trying new options versus refining known good ones in search. "A strategy with fixed exploration-exploitation ratio (MAP-Elites, red) stagnates, while an evolving search strategy (blue) produces discrete performance breakthroughs."
- extremal-distance problem: An optimization problem to arrange points to maximize or minimize extremal pairwise distances under constraints. "by solving a constrained extremal-distance problem initialized from structured polyhedral seeds."
- filtfilt: A forward–backward zero-phase filtering function (e.g., in SciPy) that applies a filter twice to remove phase distortion. "forwardâbackward filtering operations (e.g., filtfilt)."
- forward–backward filtering: Applying a filter forward and then backward to remove phase shifts and achieve zero-phase response. "forwardâbackward filtering operations (e.g., filtfilt)."
- hexagonal-lattice: A dense packing arrangement where points form a hexagonal grid, often optimal for circle packing. "a hexagonal-lattice core packing"
- island-based genetic algorithm: An evolutionary framework where multiple subpopulations evolve in parallel with occasional migration between islands. "within an island-based genetic algorithm"
- KV-cache: Cached key and value tensors used by transformer decoders to speed up autoregressive inference. "minimizes peak KV-cache pressure"
- MAP-Elites: An evolutionary “illumination” algorithm that maintains elites across a feature map to preserve diversity while improving quality. "AlphaEvolve employs MAP-Elites with predefined population database structures and selection ratios."
- meta-evolution loop: An outer optimization process that evolves the search strategy itself based on performance feedback. "a two-level evolution process comprising a solution-evolution loop and a meta-evolution loop"
- meta-learning: Learning to learn; optimizing the learning or search procedure rather than just the model or solution. "EvoX frames LLM-driven optimization as a meta-learning problem"
- multi-objective sampling: Selecting candidates by considering multiple objectives or trade-offs rather than a single score. "switches to greedy search, stratified multi-objective sampling, UCB-guided structural variation, and finally local refinement."
- Pareto frontier: The set of non-dominated solutions where improving one objective would worsen at least one other. "GEPA selects along Pareto frontiers,"
- population state descriptor: A summary of the current population’s scores, diversity, and progress used to condition search decisions. "Population state descriptor. The descriptor summarizes the current state of the solution population."
- semantic delta: A representation of the semantic change between two candidates, beyond superficial syntactic differences. "models semantic deltas between candidates."
- SLSQP: Sequential Least Squares Programming, a numerical method for constrained nonlinear optimization. "constrained SLSQP optimization."
- SSA (Singular Spectrum Analysis): A signal decomposition technique for extracting trends and oscillatory components from time series. "combining singular spectrum analysis (SSA) with Whittaker smoothing."
- stagnation threshold: A progress cutoff below which the system deems improvement insufficient and triggers a strategy update. "If falls below a stagnation threshold , EvoX triggers a strategy update;"
- Steiner tree: A minimal interconnection structure that may include additional Steiner points to reduce total length in a network. "discovers a Steiner-treeâbased multicast routing strategy"
- structural variation: Large, coarse-grained changes to a candidate’s structure to explore new solution families. "UCB-guided structural variation"
- UCB (Upper Confidence Bound): A bandit algorithm that selects options by balancing estimated reward with uncertainty bonuses. "it uses a UCB selection rule that encourages exploration of programs that have been largely ignored (rarely selected as parents)."
- variation operator: A mechanism that specifies how to modify parent candidates (e.g., refinement, structural change) during evolution. "We use three variation operators:"
- Whittaker smoothing: A penalized least squares method for smoothing signals by trading off fidelity and roughness. "combining singular spectrum analysis (SSA) with Whittaker smoothing."
Collections
Sign up for free to add this paper to one or more collections.

