Bilevel Autoresearch: Meta-Autoresearching Itself
Abstract: If autoresearch is itself a form of research, then autoresearch can be applied to research itself. We take this idea literally: we use an autoresearch loop to optimize the autoresearch loop. Every existing autoresearch system -- from Karpathy's single-track loop to AutoResearchClaw's multi-batch extension and EvoScientist's persistent memory -- was improved by a human who read the code, identified a bottleneck, and wrote new code. We ask whether an LLM can do the same, autonomously. We present Bilevel Autoresearch, a bilevel framework where an outer loop meta-optimizes the inner autoresearch loop by generating and injecting new search mechanisms as Python code at runtime. The inner loop optimizes the task; the outer loop optimizes how the inner loop searches. Both loops use the same LLM -- no stronger model is needed at the meta level. On Karpathy's GPT pretraining benchmark, the meta-autoresearch outer loop achieves a 5x improvement over the standard inner loop alone (-0.045 vs. -0.009 val_bpb), while parameter-level adjustment without mechanism change yields no reliable gain. The outer loop autonomously discovers mechanisms from combinatorial optimization, multi-armed bandits, and design of experiments -- without human specification of which domains to explore. These mechanisms succeed by breaking the inner loop's deterministic search patterns, forcing exploration of directions the LLM's priors systematically avoid. The core principle is simple: if autoresearch can meta-autoresearch itself, it can, in principle, meta-autoresearch anything with a measurable objective.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
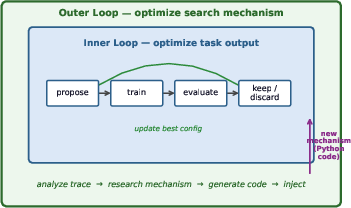
This paper explores a simple but powerful idea: if an AI can run “autoresearch” (trying changes, testing them, and keeping what works), then it might also improve the way it does that research—by rewriting its own search strategy. The authors build a two-level system where:
- The inner level works on a task (like tuning training settings for a small GPT model).
- The outer level watches how the inner level searches, finds problems, and writes new code—on the fly—to improve the inner search process.
They show that letting an AI “research its own research method” can make progress much faster.
What questions did the researchers ask?
The paper focuses on three simple, teen-friendly questions:
- Can an AI not only do experiments, but also redesign how it runs those experiments by editing its own code?
- Does changing the search mechanism (the “how to search” rules) help more than just tweaking the usual knobs (like learning rate)?
- Can the AI discover useful search strategies from different fields (like combinatorial optimization or bandit algorithms) without being told exactly what to use?
How did they test their idea?
Think of a student studying for a test:
- The inner loop is the “student” trying different study settings (like studying in 20-minute bursts vs. 40-minute bursts), checking the score, and keeping what works.
- The outer loop is a “coach” who watches the student, notices bad habits (like always trying the same things), and then changes the study plan—by literally writing new rules and swapping them into the student’s routine.
Both the student and the coach are the same AI model. The difference is what they focus on: the student focuses on the task, the coach focuses on the strategy.
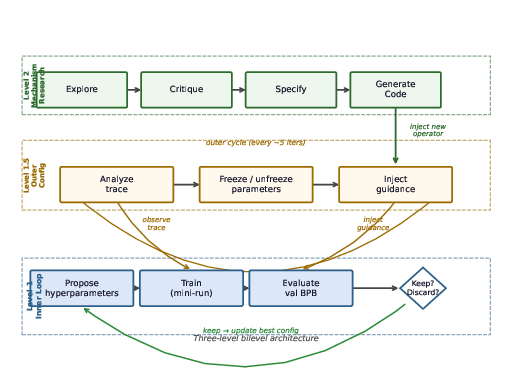
The inner loop (the “worker”)
- Propose a change to training settings (like batch size, learning rate, etc.).
- Train for a fixed time (300 seconds).
- If the result improves, keep the change; otherwise, discard it.
- Do this repeatedly (30 times).
The “Level 1.5” helper (a light-touch guide)
- Every 5 inner steps, it gives gentle strategy advice: freeze parameters that aren’t helping, unfreeze ignored ones, and suggest exploring new areas.
- It does not change the core logic of the inner loop.
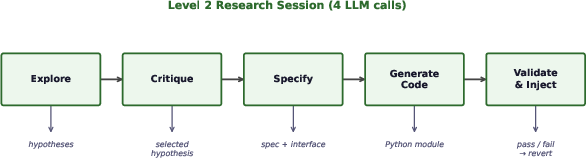
The outer loop (the “coach” that rewrites the rules)
Every so often, it:
- Reads the inner loop’s code and recent history to find bottlenecks (like “we keep trying the same bad change”).
- Chooses a promising idea for improving the search rules (drawing inspiration from other fields).
- Writes a clear plan for a new component.
- Generates runnable Python code for that new search mechanism and injects it into the running system—only if the code loads correctly.
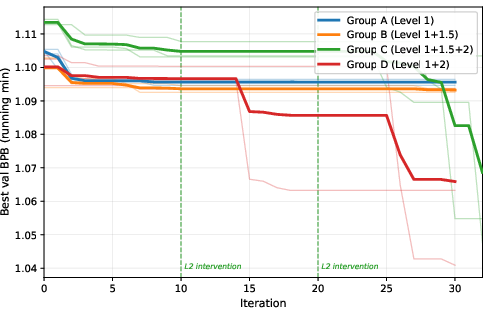
To check what really helps, they ran four versions (with everything else held constant):
- Group A: inner loop only.
- Group B: inner loop + light strategy guidance.
- Group C: inner loop + guidance + outer loop code-writing (full system).
- Group D: inner loop + outer loop (no light guidance).
What did they discover?
- The full system (Group C) improved results about 5× more than the inner loop alone. In plain terms: the outer loop’s ability to change how the search works made a big difference, much more than just tinkering with settings.
- The outer loop invented helpful mechanisms from different areas, such as:
- Tabu Search: keeps a “no-go list” of recently tried changes so the system doesn’t get stuck repeating them.
- Multi-Armed Bandit: treats different parameters like slot machines and balances trying new ones vs. exploiting known good ones.
- Orthogonal Exploration: nudges the system to explore different “directions” (parameters) instead of obsessing over just one.
- These mechanisms broke the inner loop’s habits. For example, the system had a bias to try increasing batch size first. The outer loop pushed it to try decreasing batch size instead—which turned out to be a big win under the fixed 300-second time budget because smaller batches allowed more training steps and better learning in that time.
- Importantly, the same AI model powered both loops; the improvement came from the architecture (the two-level setup), not from using a “smarter” model in the outer loop.
Why this matters:
- The biggest improvements came when the outer loop changed the rules of the search, not just the values. This shows that “improving the way we search” can be more impactful than “searching harder with the same method.”
Why does this matter?
- It shows that an AI can improve its own research process by editing code and importing ideas from many fields—without a human coder stepping in.
- If an AI can self-improve any process with a measurable score (like accuracy, speed, or cost), then in principle, it can keep getting better at many tasks over time.
- This could speed up progress in AI training, algorithm design, and other areas where you can test and score results.
A few limits and what’s next
- The tests were small (few runs) and on one benchmark (training a small GPT model under a time limit). More tests are needed to be sure it generalizes.
- Dynamic code injection can be fragile (e.g., missing libraries); the system has safeguards but this is still a practical risk.
- Future work: run more repeats, try different tasks and model sizes, and add better tools for testing newly generated code.
Bottom line
The paper proves a clear point: autoresearch can research itself. Giving an AI the ability to rewrite its own search strategy—safely and step by step—can unlock improvements that tweaking parameters alone can’t find. This turns the AI into both the scientist and the method designer, which could accelerate discovery wherever we can measure success.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
The paper makes several claims and reports promising results, but it leaves multiple gaps and uncertainties. The following concrete, actionable items identify what remains missing or unexplored:
- Statistical power and significance
- Increase repeats per group (e.g., n ≥ 10) and report confidence intervals or statistical tests to verify the 5× improvement claim beyond high run-to-run variance.
- Control and report random seeds for data ordering and initialization to reduce baseline variance and quantify noise-induced gains.
- Fair compute/time accounting
- Equalize or explicitly normalize results by total wall-clock time and GPU hours, as Level 2 sessions reduce inner-loop iterations by ~6 minutes per run.
- Report compute cost per unit improvement to assess ROI and scalability.
- Generalization beyond a single setting
- Evaluate on multiple hardware setups (e.g., H100, A100, 4090) and confirm whether the TOTAL_BATCH_SIZE finding is RTX 5090–specific or robust.
- Test across model sizes (e.g., 100M, 1B), different tasks (e.g., fine-tuning, RL, non-LLM tasks), and varied training budgets to assess transferability.
- Comparative baselines
- Benchmark against strong, standardized HPO methods (e.g., Optuna, SMAC, Bayesian optimization) and human-expert tuning to contextualize gains.
- Include algorithm portfolios and bandit/Bayesian approaches at the task level, not only as generated mechanisms.
- Mechanism-level attribution and reliability
- Perform per-mechanism ablations to quantify how much each injected mechanism (Tabu Search, Multi-Scale Bandit, Orthogonal Exploration) contributes to improvement.
- Re-run the same mechanism across multiple seeds, tasks, and hardware to measure robustness and failure rates.
- Analyze why certain sessions (e.g., Group C R2) underperform despite valid mechanism injection and identify failure modes.
- Sensitivity to prompting and LLM behavior
- Measure outcome sensitivity to Level 2 prompt templates, including removal of domain hints, to quantify prompt-induced bias.
- Vary the LLM model (smaller/larger, different providers) to test whether “same LLM” is necessary/sufficient and how scaling model capability affects meta-level performance.
- Acceptance criterion under noisy evaluations
- Replace “keep if val decreases once” with statistically robust acceptance (e.g., repeated runs, bootstrapping, sequential tests) to prevent accepting noise fluctuations.
- Evaluate multi-objective criteria (e.g., accuracy vs. time/throughput) and Pareto-aware acceptance rules.
- Scope and safety of code injection
- Clearly constrain which files Level 2 may modify (e.g., runner-only vs. train/eval scripts) to prevent “specification gaming” (e.g., altering validation logic or metrics).
- Introduce sandboxing, resource limits, and permissioning (file/network/OS) to mitigate security risks of runtime code execution.
- Expand validation beyond “import succeeds” to include unit tests, integration tests, and behavior checks before activation.
- Dependency management and environment reproducibility
- Enforce dependency whitelists/lockfiles or provide a mechanism for on-the-fly, reproducible dependency installation to avoid reverts (e.g., sklearn issue).
- Capture and version-control generated code, prompts, seeds, and environment hashes to ensure exact reproducibility of “autogenerated” experiments.
- Robustness against silent failures
- Address fragility of dynamic loading (e.g., prior sys.modules bug) with end-to-end canary tests, fail-fast mechanisms, and monitoring that detect silent reversion or degraded behavior.
- Exploration metrics and diagnostics
- Quantify exploration diversity (e.g., coverage of parameter space, entropy of proposals, orthogonality metrics) to support the claim that Level 2 breaks deterministic patterns.
- Provide diagnostics correlating exploration patterns with outcomes to guide mechanism selection.
- Scheduling and orchestration
- Systematically tune and ablate the cadence of Level 1.5 and Level 2 (e.g., every K iterations, M cycles) to understand trade-offs between overhead and benefit.
- Investigate adaptive scheduling (trigger Level 2 based on stagnation signals rather than fixed periods).
- Interaction between Level 1.5 and Level 2
- Clarify how Level 1.5’s frozen-parameter guidance affects Level 2’s mechanism choices; perform factorial experiments to isolate synergies and interference.
- Search-space limitations
- Explore allowing architecture-level changes (e.g., unfreezing DEPTH and ASPECT_RATIO) with guardrails, to test whether mechanism generation can safely navigate larger, more impactful spaces.
- Characterize how constraints on editable parameters modulate Level 2’s efficacy.
- Long-horizon behavior
- Extend beyond 30 inner iterations to study whether Level 2 continues to yield gains, plateaus, or degrades performance over longer horizons.
- Portability and reuse of discovered mechanisms
- Determine whether mechanisms generated in one setting can be serialized into a reusable library and ported to new tasks with consistent benefits.
- Develop criteria for promoting mechanisms to a “trusted portfolio” and policies for selection among portfolio entries.
- Theoretical framing and guarantees
- Formalize bilevel optimization when the upper-level variable is a program; analyze convergence, stability, and safety properties.
- Investigate conditions under which program-level meta-optimization improves lower-level search in expectation.
- Preventing metric gaming and undesired behavior
- Audit whether Level 2 could alter training-time accounting, validation dataset composition, or metric computation to “improve” val without true performance gains.
- Implement integrity checks (e.g., checksum/CI for evaluation code and datasets).
- Compute efficiency of mechanisms
- Measure overhead introduced by each mechanism (e.g., bandit bookkeeping, tabu checks) and its impact on the number of training steps per budget.
- Failure analysis and triage
- Build automated triage for mechanism failures (import passes but performance drops), including rollback policies and criteria for blacklisting harmful mechanisms.
- Human-in-the-loop boundaries
- Define when human oversight is necessary (e.g., security policy updates, dependency approvals) and measure how limited, targeted human input compares to fully autonomous Level 2.
- External validity of the core principle
- Test the “meta-autoresearch anything with a measurable objective” claim on non-ML domains (e.g., compiler flags, scientific simulations, algorithm configuration in SAT/CSPs).
These gaps outline a concrete roadmap for strengthening evidence, improving safety and reproducibility, and assessing how broadly the bilevel autoresearch approach can be trusted and applied.
Practical Applications
Immediate Applications
Below are practical, deployable uses that leverage the paper’s bilevel autoresearch framework (inner loop optimizes a task; outer loop generates and injects new search mechanisms as code). Each item names sectors, concrete tools/workflows, and key dependencies.
- ML engineering: self-improving hyperparameter optimization for training pipelines
- Sectors: software, AI/ML, LLMOps/MLOps
- Tool/product/workflow: Integrate the Level 2 “mechanism research + code injection” into MLFlow/Kubeflow pipelines to auto-generate search mechanisms (e.g., Tabu Search, multi-armed bandits) that adapt to budget and hardware; attach validate-and-revert gates to ensure safe deployment
- Assumptions/dependencies: Clear, measurable objective (e.g., validation loss), extensible runner code with well-defined integration points, safe sandbox for dynamic code loading, dependency whitelisting
- Hardware-aware training optimization under fixed budgets
- Sectors: AI/ML, HPC, cloud compute
- Tool/product/workflow: Use the framework to find hardware-specific configurations (e.g., batch-size tuning for RTX vs. datacenter GPUs) that maximize gradient steps per time; deploy as a “hardware profile tuner” in CI
- Assumptions/dependencies: Accurate per-run telemetry, hardware diversity in staging, consistent time-bounded training runs
- Experimentation platforms that auto-upgrade their search logic
- Sectors: product development, growth/marketing, online experimentation
- Tool/product/workflow: Apply Level 2 to generate/select allocation policies (e.g., Thompson sampling, UCB, orthogonal exploration) at runtime for A/B/n tests; integrate with existing experimentation services
- Assumptions/dependencies: Regulated guardrails for user-facing experiments, measurable objectives (CTR, conversion), strict rollback mechanisms
- AutoML systems that self-improve the search layer
- Sectors: AI/ML, software
- Tool/product/workflow: Add a “meta-optimizer” to AutoML platforms that periodically rewrites proposer/acceptor strategies (mechanisms) rather than only tuning knobs; store and version mechanism patches
- Assumptions/dependencies: Stable mechanism interface, searchable configuration space, reproducible metrics
- Algorithm configuration for operations research workloads
- Sectors: logistics, manufacturing, energy, scheduling
- Tool/product/workflow: Wrap OR solvers (e.g., routing, scheduling) with the bilevel loop so the outer loop injects mechanism changes (tabu lists, portfolios, bandits) that steer solver parameters and exploration heuristics for specific instances
- Assumptions/dependencies: Deterministic or stable objectives (time, cost), solver APIs that can be programmatically patched or configured
- Self-tuning CI/CD build and test pipelines
- Sectors: software engineering, DevOps
- Tool/product/workflow: Use Level 2 to generate search mechanisms for test-ordering, flaky-test isolation, and cache strategy selection (e.g., bandit-based prioritization)
- Assumptions/dependencies: Measurable CI objectives (time to green), safe execution environment, rollback on import failure
- Data pipeline optimization (throughput/latency/quality)
- Sectors: data engineering, analytics
- Tool/product/workflow: Outer loop injects mechanisms for sampling policies, batch sizing, retry/dedup rules; inner loop evaluates on SLA metrics
- Assumptions/dependencies: Observability for pipeline metrics, non-destructive test environment, config-in-code pattern
- Research labs: self-improving autoresearch harness
- Sectors: academia, industrial research
- Tool/product/workflow: Adopt the paper’s open-source repo to accelerate hyperparameter and architecture exploration with periodic Level 2 mechanism generation; archive mechanism inventory for meta-analysis
- Assumptions/dependencies: IR reproducibility protocols, compute quotas, code review for generated patches
- Robotics parameter tuning in simulation
- Sectors: robotics, autonomy
- Tool/product/workflow: Apply to controller gains and exploration strategies in sim; outer loop generates exploration policies (e.g., orthogonal parameter sweeps) to avoid fixation on single parameters
- Assumptions/dependencies: High-fidelity simulators, safety gating before deployment to real hardware
- Local developer workflows: Jupyter/VSCode plug-in for self-tuning experiments
- Sectors: software, education
- Tool/product/workflow: A lightweight extension that runs the inner loop on a notebook/script and periodically lets Level 2 inject mechanism modules; displays import validation and performance deltas
- Assumptions/dependencies: Pythonic runner structure, user consent for code injection, virtual environment isolation
- Continuous query/data system tuning
- Sectors: databases, analytics infrastructure
- Tool/product/workflow: Auto-generate mechanism patches for join order search or cache strategies based on workload traces (e.g., add tabu regions for pathological join plans)
- Assumptions/dependencies: Hook points in query optimizer or tuning layer, benchmarkable objectives (latency, cost)
- Teaching/learning labs: auto-designed experiments
- Sectors: education
- Tool/product/workflow: In lab courses, have the system propose/design-of-experiments mechanisms (orthogonal exploration) for student projects to improve parameter coverage and reduce bias
- Assumptions/dependencies: Well-specified experimental objectives, sandboxed code execution
Long-Term Applications
These applications require further research, scaling, validation in broader settings, or added safety/verification layers.
- General self-improving research agents beyond hyperparameters
- Sectors: academia, AI/ML, scientific discovery
- Tool/product/workflow: Use the outer loop to synthesize new inner-loop scientific methods (e.g., new proposal/acceptance criteria, new surrogate models) across domains (bio, materials, compilers)
- Assumptions/dependencies: Domain test harnesses, cross-task generalization, richer verification than simple import checks
- Safety-critical model development (healthcare, finance) with verified mechanism injection
- Sectors: healthcare, finance, autonomy
- Tool/product/workflow: Mechanism generation with formal verification, unit/prop tests, and audit trails; e.g., bandit-driven hyperparameter search for risk models with coverage guarantees
- Assumptions/dependencies: Regulatory compliance, formal methods integration, human-in-the-loop approvals, bias/robustness audits
- Autonomous experimentation platforms for policy pilots
- Sectors: public policy, govtech
- Tool/product/workflow: Outer loop proposes and implements allocation/experimentation mechanisms (e.g., contextual bandits) for limited-scale pilots; rigorous ethical oversight and pre-registered guardrails
- Assumptions/dependencies: Clear social objectives and constraints, ethics review, data privacy guarantees, rollback capacity
- Self-optimizing compilers and systems software
- Sectors: systems, dev tools
- Tool/product/workflow: Mechanism generation for flag search, inlining/loop-transform heuristics, and cache policies; co-design with autotuners
- Assumptions/dependencies: Stable performance benchmarks, fine-grained instrumentation, isolation from production until verified
- Meta-optimizing closed-loop lab automation
- Sectors: robotics, biotech, materials
- Tool/product/workflow: Lab robots with outer loops that generate new experimental design mechanisms (DOE, Bayesian optimization) and inject them into run controllers
- Assumptions/dependencies: Rigorous safety interlocks, simulation-to-real validation, dependency control
- Cross-language, cross-environment mechanism synthesis
- Sectors: software, platform engineering
- Tool/product/workflow: Generate code patches for heterogeneous stacks (Python, C++, Rust) and distributed systems; standardized interfaces for mechanism integration
- Assumptions/dependencies: Polyglot codegen quality, ABI/API constraints, robust test suites
- Federated/collaborative mechanism libraries (“mechanism marketplace”)
- Sectors: AI platforms, open-source ecosystems
- Tool/product/workflow: Share and benchmark auto-generated mechanisms across teams; automated curation with provenance and reproducibility badges
- Assumptions/dependencies: Common interfaces and metadata, security vetting, licensing
- Multi-level meta-optimizers (beyond bilevel)
- Sectors: AI/ML research
- Tool/product/workflow: Stacked meta-optimizers where outer-most layers choose entire search paradigms (evolutionary vs. Bayesian vs. bandits), mid-layers design mechanisms, inner loops run tasks
- Assumptions/dependencies: Cost-aware orchestration, variance control, theoretical guarantees on convergence/safety
- Organizational governance for self-modifying systems
- Sectors: enterprise IT, risk management
- Tool/product/workflow: Policies, approval workflows, and observability (diff reviews, automated rollback SLAs) specific to code-injecting optimizers
- Assumptions/dependencies: Change management tooling, incident response integration, compliance frameworks
- Personal automation that learns better routines
- Sectors: consumer software, productivity
- Tool/product/workflow: Agents that meta-iterate on scheduling, reminders, or budgeting heuristics (e.g., bandit-based habit prompts), with opt-in privacy-preserving evaluation
- Assumptions/dependencies: Clear utility metrics, strong privacy controls, user transparency and consent
Notes on Feasibility and Risk (shared across applications)
- Dependencies/assumptions common to most deployments:
- A measurable, trustworthy objective signal; stable evaluation harnesses
- Clear integration points in the “runner” code to accept mechanism injections
- Secure sandboxing, dependency whitelisting, and validate-and-revert safeguards to avoid unsafe code execution
- Monitoring and provenance tracking for all auto-generated patches
- Adequate compute budgets and telemetry to assess improvements
- Awareness of prompt-induced domain bias and mechanisms to diversify search
- Current limitations from the paper that affect generalization:
- Evidence is from a single benchmark and small-sample ablation; performance variance is nontrivial
- Dynamic loading is fragile without robust test harnesses and dependency control
- Mechanism effectiveness may be context/hardware specific (e.g., batch-size discovery on RTX 5090 under time-bounded training)
These applications translate the paper’s central finding—an LLM can improve its own search mechanism via code generation—into concrete tools and workflows, with clear paths to adopt now and to mature over time.
Glossary
- acceptance rule (keep/discard): The decision criterion for whether a proposed change is adopted or rejected in the inner loop. "introduced the single-track inner loop with a keep/discard acceptance rule."
- algorithm configuration: The process of selecting parameter settings or algorithmic options to optimize performance on a given problem instance. "Algorithm configuration and algorithm selection choose among candidate algorithms or parameter settings for a given problem instance."
- algorithm selection: Choosing the most suitable algorithm from a set for a specific problem instance, often based on performance predictors. "Algorithm configuration and algorithm selection choose among candidate algorithms or parameter settings for a given problem instance."
- autoresearch: An automated propose–execute–evaluate loop where an LLM iteratively modifies and tests configurations, effectively performing research. "we call this loop autoresearch."
- Bayesian optimization: A sample-efficient strategy for optimizing black-box functions using probabilistic surrogate models and acquisition functions. "(combinatorial optimization, online learning, design of experiments, Bayesian optimization)"
- bilevel optimization: An optimization framework with two nested levels where the upper (outer) objective depends on the solution of a lower (inner) problem. "We formalize autoresearch as a bilevel optimization problem"
- combinatorial optimization: Optimization over discrete structures (e.g., sets, permutations) often requiring specialized search heuristics. "mechanisms from combinatorial optimization, multi-armed bandits, and design of experiments"
- design of experiments: A statistical framework for planning experiments to efficiently explore factor effects and interactions. "mechanisms from combinatorial optimization, multi-armed bandits, and design of experiments"
- dynamic loading: Loading and activating code modules at runtime rather than at startup, enabling on-the-fly behavior changes. "validated via importlib dynamic loading before activation."
- Flash Attention 3: A high-performance attention algorithm variant designed to accelerate Transformer attention computations. "Flash Attention~3 is unsupported on Blackwell compute~12.0"
- gradient-free feedback: Performance signals (e.g., validation loss changes) used to guide search without relying on gradient information. "training outcomes provide gradient-free feedback."
- hill climbing: A local search method that iteratively moves to neighboring configurations that improve the objective. "LLM-guided hill climbing in configuration space"
- import validation: A safety check ensuring generated modules can be successfully imported before activating them in the system. "passed import validation and were activated"
- importlib: A Python module used for dynamic import and loading of modules at runtime. "validated via importlib dynamic loading before activation."
- meta-learning: Learning to learn across tasks by optimizing mechanisms that enable fast adaptation to new tasks. "Meta-learning trains models to learn efficiently from few examples"
- multi-armed bandits: A class of sequential decision problems balancing exploration and exploitation among competing options (arms). "mechanisms from combinatorial optimization, multi-armed bandits, and design of experiments"
- multi-batch parallelism: Evaluating multiple candidate configurations simultaneously to increase search breadth per iteration. "multi-batch parallelism: several candidate configurations are evaluated simultaneously"
- Multi-Scale Bandit Proposer: A generated mechanism that frames parameter selection as a bandit problem at multiple scales to balance exploration and exploitation. "R2's Level~2 generated the Multi-Scale Bandit Proposer"
- neural architecture search: Automating the design of neural network structures using search and optimization methods. "Applications include meta-learning, neural architecture search, and hyperparameter optimization."
- online learning: Learning that updates models incrementally as data arrives, often used in sequential decision-making contexts. "(combinatorial optimization, online learning, design of experiments, Bayesian optimization)"
- persistent experience memory: A mechanism that stores and reuses lessons from prior runs to inform future proposals. "EvoScientist added persistent experience memory across runs."
- portfolio methods: Techniques that maintain a set of algorithms and choose among them based on instance characteristics or performance. "Portfolio methods maintain a library of algorithms and select among them."
- runtime code injection: Modifying a running system by inserting new code modules during execution. "the fragility of runtime code injection: silent fallback without error is a dangerous failure mode."
- SDPA: Scaled Dot-Product Attention, a standard attention mechanism in Transformers used here as the runtime attention path. "running SDPA (Flash Attention~3 is unsupported on Blackwell compute~12.0)"
- sys.modules registration bug: An error involving Python’s module registry that can disrupt dynamic imports or cause fallbacks. "contained a sys.modules registration bug"
- Systematic Orthogonal Exploration: A mechanism enforcing exploration along orthogonal parameter dimensions to avoid fixation on a single axis. "Systematic Orthogonal Exploration (forces the LLM to explore orthogonal parameter dimensions, preventing over-focus on a single parameter)."
- tabu list: A memory structure in Tabu Search that forbids revisiting recently explored configurations to escape local cycles. "maintains a tabu list of recently visited parameter regions"
- Tabu Search: A metaheuristic that guides local search using memory structures (tabu lists) to prevent cycling and encourage exploration. "generated mechanisms (Tabu Search, Bandit, Orthogonal Exploration)"
- validate-and-revert mechanism: A safety procedure that activates generated code only if validation succeeds; otherwise it restores the prior state. "This validate-and-revert mechanism ensures that Level~2 failures are non-destructive."
Collections
Sign up for free to add this paper to one or more collections.