No Calibration, No Depth, No Problem: Cross-Sensor View Synthesis with 3D Consistency
Abstract: We present the first study of cross-sensor view synthesis across different modalities. We examine a practical, fundamental, yet widely overlooked problem: getting aligned RGB-X data, where most RGB-X prior work assumes such pairs exist and focuses on modality fusion, but it empirically requires huge engineering effort in calibration. We propose a match-densify-consolidate method. First, we perform RGB-X image matching followed by guided point densification. Using the proposed confidence-aware densification and self-matching filtering, we attain better view synthesis and later consolidate them in 3D Gaussian Splatting (3DGS). Our method uses no 3D priors for X-sensor and only assumes nearly no-cost COLMAP for RGB. We aim to remove the cumbersome calibration for various RGB-X sensors and advance the popularity of cross-sensor learning by a scalable solution that breaks through the bottleneck in large-scale real-world RGB-X data collection.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper tackles a tricky, practical problem: how to line up pictures taken by different kinds of cameras (like normal color cameras and heat or night-vision cameras) so their pixels match. Most past work assumes you already have perfectly aligned pairs, but getting that alignment usually needs lots of hardware setup and careful measuring. The authors show a new way to create aligned pairs without doing all that hard calibration or having 3D depth for the special sensor. In simple terms: they use the color photo to guide the creation of a matching “view” from the other sensor (thermal, NIR, SAR), and they make sure it stays consistent across multiple views.
Key Objectives
The paper asks a few straightforward questions:
- Can we align images from different sensors (color and “X” like thermal, near‑infrared, or radar) without measuring camera details or depth?
- Can we make this process work at scale, in real scenes, and across different sensor types?
- Can we keep the results consistent when looking from multiple angles, like walking around a scene?
- Can this approach beat common shortcuts (like simple warping or image-to-image translation) that often fail when the scene has real 3D structure?
Methods and Approach (explained with everyday ideas)
The approach has three main stages. Think of it like making a detailed drawing by first placing a few dots, then connecting them and coloring in, and finally checking the drawing from different angles to make sure everything matches.
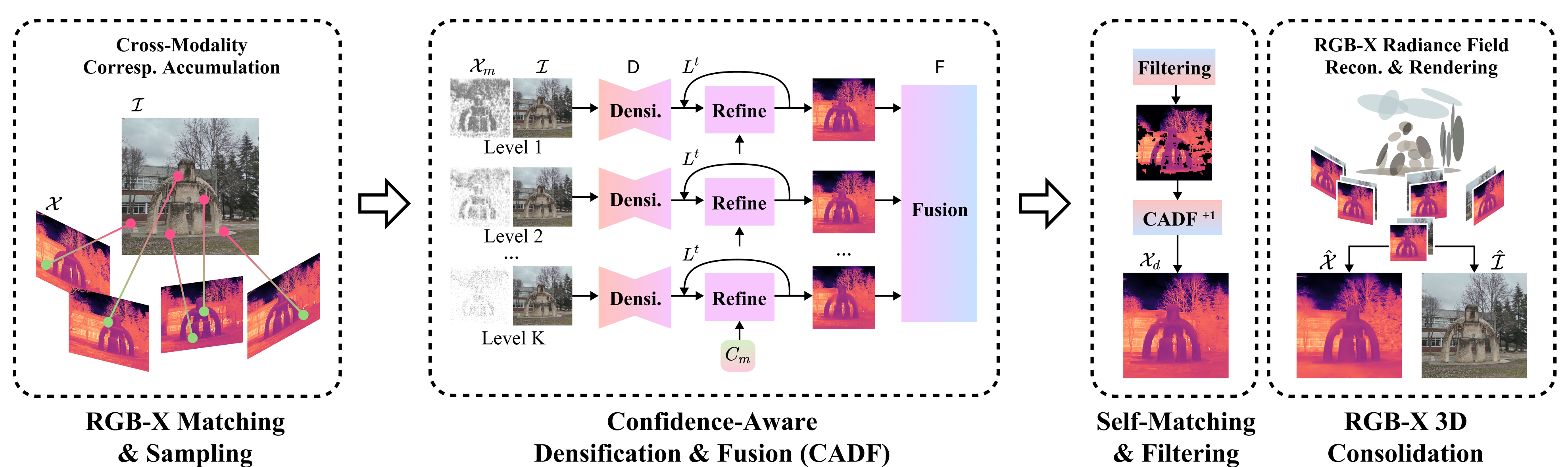
Stage 1: Match
- Idea: Find matching “points of interest” between the color image (RGB) and the other sensor image (X).
- Analogy: Like putting stickers on the same corners of a building in two different photos, even if one photo shows heat and the other shows color.
- How it works: A matching tool detects pairs of points that likely represent the same spot in the scene. They collect points from a few nearby frames to get more coverage. In areas that are flat or texture-less (like sky or plain walls), there are fewer matchable points. They lightly sample a few extra points there using a rough warp, but keep it small to avoid errors later.
- Why not just “warp” everything? Simple warping (called homography) treats the scene as a flat sheet. That works for a wall but fails when things have different depths (foreground statue versus background buildings). The authors avoid depending on this.
Stage 2: Densify (CADF: Confidence-Aware Densification and Fusion)
- Idea: Start with the matched points (like a sparse dot map) and fill in the rest of the X-image so it aligns with the RGB image.
- Analogy: You have a few dots; now you carefully color in the rest of the picture, using the color photo as a guide.
- Confidence-aware filling: Not all matched points are equally trustworthy. Each match has a “confidence score” (a trust level).
- The method uses these scores to focus on reliable points while being cautious with questionable ones, so the filled-in image looks clean and accurate rather than messy.
- Multi-level fusion: If you set a strict trust rule, you get fewer points and must rely more on the color image’s guidance. If you’re too lenient, you keep noisy points that can distort the result.
- Solution: Densify at several trust levels and then fuse the results using an enhancement network that learns to combine them, suppressing noise and sharpening edges.
- Self-matching filtering: Once you have a densified X-image aligned to the RGB, they check it with the matcher itself.
- Analogy: If two pages of a coloring book should line up, each patch on one page should match the same patch on the other. If a patch doesn’t match itself well, it’s likely wrong, so they remove or fix those parts and re-densify.
Stage 3: Consolidate in 3D (optional but helpful)
- Idea: Make the results consistent across multiple views by building a simple 3D scene using only the RGB camera’s 3D from a standard tool (COLMAP).
- Analogy: Imagine filling the scene with tiny “paint blobs” in 3D (this is called 3D Gaussian Splatting). The color camera anchors where those blobs go. Then the other sensor’s values ride along with those blobs, so different views stay consistent.
- Key point: They only need 3D info from the RGB camera (which is easy and common). They don’t need any 3D for the X sensor.
Main Findings and Why They Matter
Across several datasets and sensor types (thermal, near‑infrared, and SAR), the method:
- Produces clearer, sharper, and more accurate X-images aligned with the RGB views.
- Beats simple warping and advanced image translation (like generating thermal from color) on quality and multi-view consistency.
- Works even without the final 3D step; with the 3D consolidation, it gets even better.
- Improves consistency over time (important for videos or moving through a scene), meaning the synthesized X-images don’t flicker or change randomly between frames.
- Sometimes even helps the RGB view synthesis, because having better X-images can guide the 3D consolidation.
Why this matters:
- Collecting perfectly aligned multi-sensor data is usually expensive and time-consuming (measuring camera internals, syncing sensors, getting depth, etc.). This method reduces that burden, making it easier to build large, real-world datasets with multiple sensors.
- Better aligned data helps tasks like night driving with thermal cameras, search and rescue, industrial inspections, and mapping.
Implications and Impact
This research suggests a practical path forward:
- Easier data collection: Teams can capture RGB and X sensor data without heavy calibration, then align them using this pipeline.
- Scalable multi-sensor learning: More and better datasets lead to stronger models in safety-critical areas (autonomous driving, robotics, infrastructure inspection).
- Cross-sensor cooperation: Sensors that look “blurry” or “low-texture” (like thermal) can still be aligned and made useful by leveraging the RGB camera.
- Limitations to keep in mind:
- Works best for mostly static scenes; moving objects are still hard for current 3D consolidation methods.
- Very uniform areas (like huge patches with no features) are hard to match; extreme cases still challenge matching-based approaches.
- Low-resolution or noisy sensors may need extra cleaning.
Overall, the paper shows “no calibration, no depth” can still mean “no problem” if you smartly match a few points, carefully fill in the rest with confidence, and, when possible, tie everything together in 3D from the RGB side.
Knowledge Gaps
Below is a concise, actionable list of the paper’s unresolved gaps, limitations, and open questions for future work to address.
- Dynamic scenes and moving objects are not handled; extend the pipeline (matching, densification, and consolidation) to support non-rigid/dynamic content (e.g., dynamic 3DGS, motion segmentation, or flow-guided consistency).
- Dependence on RGB-only SfM: the 3DGS stage requires COLMAP poses for RGB; robustness when COLMAP fails (low-texture, repetitive patterns, rolling shutter, or dynamic scenes) is unstudied; alternatives like learning-based SfM or joint pose optimization with X are unexplored.
- Occlusions/disocclusions across frames are not explicitly modeled in keypoint stacking or densification; develop occlusion-aware aggregation and visibility reasoning to prevent hallucinations in non-co-visible regions.
- Homography-based area sampling assumes local planarity and introduces bias; no systematic analysis of its failure modes or adaptive strategies for non-planar scenes and large parallax.
- Sensitivity to hyperparameters remains unquantified (e.g., number of frames N, thresholds K and δ, 5% area sampling rate, patch size for self-matching); provide principled tuning guidelines and robustness analyses.
- The densification model requires per-modality training (often on synthetic/pseudo-paired data); generalization to unseen sensors/spectral bands without retraining (or with test-time adaptation) is not established.
- Radiometric/physical fidelity for modalities with physical units (e.g., thermal in °C) lacks calibration guarantees under domain shifts; develop sensor-agnostic normalization or self-calibration to preserve absolute units.
- Uncertainty is only heuristically injected via matcher confidence and patch similarity; no probabilistic end-to-end formulation to propagate and calibrate uncertainty through densification and 3DGS.
- The self-matching assumption (diagonal similarity matrix) may break under scale/rotation differences, strong viewpoint changes, or residual misalignments; need scale- and rotation-invariant self-consistency checks and analysis of failure cases.
- Reliance on segmentation (GroundedSAM) for area sampling is untested under segmentation errors; quantify sensitivity and explore segmentation-free or uncertainty-aware sampling.
- Field-of-view, intrinsics, and lens distortion differences are not explicitly handled beyond implicit matching; support for strong FOV mismatches or per-pixel ray correction is missing.
- Temporal synchronization and rolling-shutter effects are assumed negligible (“rough alignment”); explicit estimation and correction of time offsets and RS distortions are unaddressed.
- X modality does not inform geometry: in 3DGS, geometry is derived from RGB only and X is added as channels; investigate joint geometry learning or multimodal radiance fields that leverage X for geometry where RGB fails.
- Choice of shared vs disentangled 3DGS parameters is not explored; study trade-offs between shared parameters and modality-specific branches for better cross-modal fidelity.
- Robustness on extremely homogeneous X scenes (e.g., textureless thermal areas, uniform SAR backscatter) remains limited; investigate stronger cross-modal descriptors, region-level matches, or learned priors to seed densification.
- Limited evaluation breadth: results focus on thermal, NIR, and a small SAR set; missing assessment on additional sensors (polarization, event cameras, hyperspectral), varied environments (indoor, nighttime, adverse weather), and larger-scale datasets.
- Metrics: use of image-text and cross-modal feature similarity may not faithfully reflect alignment or physical correctness; develop modality-appropriate, geometry-aware metrics for unpaired evaluation.
- Downstream utility is not quantified; demonstrate how synthesized aligned RGB-X pairs improve segmentation/detection/tracking or other multimodal tasks compared to existing pairing pipelines.
- Failure mode analysis is sparse (e.g., specularities, emissivity variations, thermal reflections, SAR layover/shadowing, multi-bounce); catalog and address modality-specific artifacts.
- Computational cost and scalability are undocumented; profile time/memory for matching, multi-threshold densification, self-matching, and 3DGS; explore pruning, distillation, or streaming GS for large-scale deployment.
- Bidirectional synthesis is not considered; the method aligns X to RGB viewpoints but not vice versa; evaluate synthesizing RGB aligned to X (and cross-check consistency).
- Learning to infer calibration from synthesized pairs is unexplored; investigate whether generated aligned pairs can recover intrinsics/relative pose (closing the loop to replace calibration entirely).
- SAR-specific generalization is minimally validated (three large images cut into patches); assess robustness across incidence angles, polarizations, frequencies, speckle statistics, and geolocation inconsistencies.
- Interplay of CADF and self-matching filtering is not deeply analyzed; characterize when each helps/hurts and how to schedule or weight them adaptively per-scene.
- Automatic decision rules for using 3DGS vs. pre-GS outputs are missing; define pose-quality thresholds or confidence-based criteria to choose consolidation strategies.
Practical Applications
Overview
This paper proposes a “match–densify–consolidate” pipeline that produces pixel-aligned RGB–X pairs (where X can be thermal, NIR, SAR, etc.) without requiring X-sensor calibration, intrinsics, or metric depth. It leverages cross-modal keypoint matching, confidence-aware densification guided by RGB (CADF), self-matching–based filtering for quality control, and optionally consolidates across views with RGB-only COLMAP and RGB–X 3D Gaussian Splatting (3DGS). Below are practical applications enabled by this framework, grouped by immediacy and annotated with sectors, workflows/products, and key assumptions/dependencies.
Immediate Applications
These can be deployed now with the provided pipeline and off-the-shelf components (cross-modal matcher, pre-trained densifier per modality, and COLMAP on RGB when multi-view consistency is required).
- Calibration-light RGB–Thermal/NIR alignment for data collection and curation (Autonomous Driving, Robotics, Software)
- Workflow/Product: An SDK/CLI that ingests time-synchronized but uncalibrated RGB and X recordings, runs match–densify, and outputs aligned RGB–X frames for training detection/segmentation/tracking models.
- Dependencies/Assumptions: Static scenes or near-static during capture; sufficient view overlap; a cross-modal matcher (e.g., XoFTR/LightGlue variants) that produces usable correspondences; pre-trained densifier for the target modality; COLMAP on RGB if 3D consistency is desired.
- Retrofitting legacy RGB and thermal/NIR datasets to pixel-aligned pairs (Academia, AV/Robotics, Public Safety)
- Workflow/Product: Batch conversion tool to align existing unpaired archives for immediate use in multimodal fusion research and benchmarking.
- Dependencies/Assumptions: Overlapping fields of view; adequate texture in RGB for COLMAP; reasonable SNR in X; static scenes.
- 3D thermal facade mapping for building energy audits using drones (Energy, Construction/Facility Management)
- Workflow/Product: Drone survey using an RGB and a low-cost thermal sensor mounted without precise rig calibration; post-process via CADF + RGB-only COLMAP + 3DGS to deliver 3D thermal overlays, orthomosaics, and hotspot analytics.
- Dependencies/Assumptions: Stationary structures; sufficient RGB coverage for SfM; thermal sensor noise manageable by densification/fusion; requires offline processing.
- Solar farm and substation inspection (Energy, Utilities)
- Workflow/Product: Pipeline generating 3D thermal overlays of panels or equipment from ad-hoc rigs; enables hotspot localization and defect reporting without factory calibration.
- Dependencies/Assumptions: Static assets; RGB visual texture for COLMAP; ambient conditions stable during runs.
- Industrial asset inspection for leaks and hotspots (Oil & Gas, Manufacturing)
- Workflow/Product: Handheld or mobile rigs collecting RGB and thermal; align offline to produce pixel-matched thermal maps for reports and maintenance workflows.
- Dependencies/Assumptions: Minimal motion/occlusion during short capture bursts; acceptable thermal sensor noise; reliable cross-modal keypoints in relevant areas.
- BIM/Digital Twin overlays of thermal/NIR information (AEC/FM software)
- Workflow/Product: Export 3D-consistent thermal layers (via 3DGS) to overlay on BIM/digital-twin platforms for operations and maintenance.
- Dependencies/Assumptions: Accurate RGB camera trajectories from COLMAP; simple alignment from reconstructed geometry to BIM coordinate frames.
- SAR–optical alignment for damage assessment and change detection (Disaster Response, Earth Observation)
- Workflow/Product: Patch-based RGB–SAR alignment and densification for improved co-registration, enabling analysts to compare pre-/post-event imagery without specialized calibration.
- Dependencies/Assumptions: Patch overlap; acceptable SNR in SAR; offline processing; no 3D consolidation (satellite views are not multi-view in the same sense).
- Crop/vegetation monitoring with RGB–NIR alignment (Agriculture)
- Workflow/Product: Align NIR to RGB to produce consistent maps supporting proxy indices and model training for plant health assessment.
- Dependencies/Assumptions: For quantitative indices (e.g., reflectance-based), radiometric calibration is still required; static scenes; good illumination; view overlap.
- AR prototyping with consumer thermal add-ons (Software, Consumer)
- Workflow/Product: Post-capture alignment enabling mobile apps to overlay thermal on RGB without per-user calibration, useful for demos, education, and tech trials.
- Dependencies/Assumptions: Offline or near-real-time latency acceptable; adequate keypoint matches in both domains; device motion minimized.
- Dataset creation for cross-modal foundation and fusion models (Academia, AI Research)
- Workflow/Product: Large-scale paired RGB–X datasets generated from unpaired captures, with built-in quality control using self-matching metrics.
- Dependencies/Assumptions: Availability of modality-specific densifier pretraining data; compute for batch conversion and 3D consolidation.
- Quality assurance and filtering for cross-modal datasets (Academia, Software)
- Workflow/Product: Use the self-matching similarity metric to flag/reject poor patches, grading alignment quality before training.
- Dependencies/Assumptions: A transformer-based matcher to expose patch-level features; threshold choice tuned to scene/modality.
- RGB–X 3D Gaussian Splatting add-on for existing GS/NeRF toolchains (Software)
- Workflow/Product: A plugin that adds X-channels to GS for joint RGB–X rendering, denoising via RGB guidance, and cross-sensor view synthesis.
- Dependencies/Assumptions: RGB poses from COLMAP; static scenes; sufficient RGB detail to anchor Gaussians.
- Offline multi-sensor mapping in low-texture environments (Robotics)
- Workflow/Product: Generate 3D-consistent NIR/thermal maps aligned to RGB reconstructions, improving mapping in low-light or adverse conditions without calibration.
- Dependencies/Assumptions: Static environments; sufficient RGB anchor frames; post-processing allowed.
- Privacy/audit studies on thermal–RGB pairing (Policy, Ethics)
- Workflow/Product: Tools to quantify how aligned thermal and RGB may enhance identification or profiling, supporting privacy-impact assessments.
- Dependencies/Assumptions: Representative datasets; institutional review for sensitive data handling.
Long-Term Applications
These require additional research, scaling, real-time engineering, or ecosystem development (e.g., modality coverage, dynamic scenes, or regulatory frameworks).
- Real-time onboard cross-sensor alignment and 3D consolidation on vehicles/drones (Autonomous Driving, Robotics)
- Potential Product: Embedded “calibration-free” RGB–X alignment module with streaming 3DGS or equivalent fast volumetric rendering for online perception/fusion.
- Dependencies/Assumptions: Faster matchers and densifiers; incremental/online GS; hardware acceleration; robust handling of motion blur and latency.
- Dynamic-scene support with moving objects (Software, Robotics)
- Potential Product: CADF + dynamic 3DGS/NeRF to separate static background and dynamic foreground for consistent cross-modal overlays in crowded scenes.
- Dependencies/Assumptions: New model components for motion segmentation and dynamic radiance fields; training data with dynamic content.
- Extension to broader sensor families (R&D across sectors)
- Potential Product: Modules for LWIR/SWIR, polarization, event cameras, mmWave/FMCW radar, hyperspectral bands; unified SDK covering diverse X-sensors.
- Dependencies/Assumptions: Cross-modal matchers and densifiers per modality; signal-specific pretraining; new confidence models for extremely low-texture or noisy modalities.
- End-to-end cross-modal SLAM without calibration (Robotics)
- Potential Product: SLAM systems that maintain joint RGB–X maps using self-matching and confidence-aware densification for loop closure and relocalization.
- Dependencies/Assumptions: Real-time performance; robustness under rapid motion; integration with VIO/IMU.
- Consumer AR glasses with thermal overlays (Consumer, Public Safety)
- Potential Product: Calibration-free thermal AR for electricians, firefighters, and maintenance crews with stable overlays during movement.
- Dependencies/Assumptions: On-device acceleration; dynamic scene support; lightweight models; thermal sensor form-factor and power constraints.
- City-scale thermal mapping and benchmarking (Policy, Energy)
- Potential Product: Municipal energy-efficiency maps integrating building facades and roofs, informing retrofit incentives and code enforcement.
- Dependencies/Assumptions: Scalable data collection campaigns; governance for data sharing; privacy safeguards; standardized accuracy metrics.
- Healthcare monitoring with RGB–thermal alignment (Healthcare)
- Potential Product: Continuous monitoring for fever/inflammation or wound care with aligned modalities to stabilize readings across poses.
- Dependencies/Assumptions: Clinical validation; strict privacy/compliance; radiometric calibration for clinical-grade accuracy; dynamic subject handling.
- Satellite-scale SAR–optical fusion for global monitoring (Earth Observation, Defense)
- Potential Product: Automated co-registration pipelines generating fused products for change detection, flood mapping, and infrastructure monitoring.
- Dependencies/Assumptions: Handling diverse geodetic projections and viewing geometries; massive-scale compute; varying atmospheric/illumination effects.
- Cross-modal label transfer and auto-annotation (Software, Academia)
- Potential Product: Tools to propagate labels from RGB to X (and vice versa) to bootstrap X-only models where manual annotation is scarce.
- Dependencies/Assumptions: High alignment precision; uncertainty modeling for label noise; downstream training pipelines tolerant to propagated errors.
- Foundation model pretraining with aligned RGB–X pairs (Academia, AI R&D)
- Potential Product: Multimodal pretraining datasets and encoders leveraging aligned views to improve robustness in low-light/adverse conditions.
- Dependencies/Assumptions: Large-scale curated data; compute budget; modality-specific tokenizers/architectures.
- Standardization and procurement guidelines (Policy, Industry Consortia)
- Potential Product: Benchmarks and minimum specs for “calibration-light” cross-sensor alignment in public tenders (e.g., building audits, infrastructure inspections).
- Dependencies/Assumptions: Community consensus on metrics (e.g., self-matching scores, cross-modal similarity), datasets, and reporting practices.
- Hardware simplification in manufacturing (Imaging, Device OEMs)
- Potential Product: Reduced factory calibration steps for dual-sensor rigs relying on software alignment, lowering BoM and assembly costs.
- Dependencies/Assumptions: Verified alignment accuracy for intended use; quality control pipelines; fallback calibration for edge cases.
- Privacy and governance frameworks for aligned thermal/RGB data (Policy)
- Potential Product: Policies addressing re-identification risk and sensitive attribute inference when cross-sensor overlays become precise.
- Dependencies/Assumptions: Multistakeholder input; legal compliance; auditability of pipelines and outputs.
Cross-Cutting Assumptions and Dependencies
- Static or quasi-static scenes during capture, as the current pipeline and 3DGS consolidation assume static geometry.
- Sufficient RGB texture for COLMAP reconstruction when 3D consistency is needed; method still works without 3DGS but benefits from it.
- Availability of a robust cross-modal matcher and modality-specific densifier pretraining (thermal, NIR, SAR shown; others require new training).
- Overlapping FOVs and rough time synchronization between sensors; extreme parallax or occlusions reduce performance.
- Sensor quality: very low-resolution or highly noisy X-sensors may need in-domain denoising or super-resolution prior to densification.
- Quantitative analyses (e.g., absolute temperature, reflectance indices) may still require radiometric calibration; the method improves alignment, not absolute calibration.
Glossary
- 3D Gaussian Splatting (3DGS): A real-time 3D scene representation/rendering method using anisotropic Gaussians to model radiance for novel view synthesis. "later consolidate them in 3D Gaussian Splatting (3DGS)."
- 3D priors: Pre-existing 3D information (e.g., depth, camera intrinsics/poses) used to align or render views. "Our method uses no 3D priors for X-sensor"
- 3D reprojection: Projecting 3D scene points into image coordinates using camera calibration and depth. "The traditional industrial settings leverage 3D reprojection"
- CADF (Confidence-Aware Densification and Fusion): The proposed module that uses image-matching confidence to guide densification and fuse multi-threshold results. "We propose Confidence-Aware Densification and Fusion (CADF) that densifies and fuses multi-level threshold X-maps into one X-image."
- COLMAP: A structure-from-motion pipeline that recovers camera poses and sparse/dense reconstructions from RGB image collections. "Structure-from-motion methods like COLMAP~\cite{schonberger2016structure} are widely used in scene reconstruction"
- Cross-modal image matching: Establishing keypoint correspondences between images from different sensing modalities (e.g., RGB and thermal). "we adopt cross-modal image matchers to match keypoints between RGB and X views"
- Cross-sensor view synthesis: Generating images from one sensor modality that are aligned with another modality’s viewpoint. "cross-sensor view synthesis to acquire paired and aligned RGB-X data"
- Densification: Converting sparse or semi-dense measurements into a dense image/map via learned propagation or prediction. "we find that densification may lead to irregular or noisy structures"
- DySPN (Dynamic Spatial Propagation Network): A refinement mechanism that iteratively propagates information across spatial neighborhoods using learned affinities. "dynamic spatial propagation (DySPN) layers~\cite{lin2022dynamic} that refine the output"
- Essential matrix: A 3×3 matrix encoding relative rotation and translation between two calibrated cameras from epipolar geometry. "from essential matrix using matched keypoints"
- Frobenius norm: A matrix norm equal to the square root of the sum of squared entries, often used to normalize matrices. "where is the Frobenius norm"
- GroundedSAM: A segmentation model used to obtain masks of broad regions (e.g., sky, ground) to guide sampling/matching. "we adopt GroundedSAM~\cite{ren2024grounded} to segment these areas on RGB images."
- Homogeneous coordinates: Projective coordinates that add an extra dimension to facilitate perspective transformations and homographies. "both in homogeneous coordinates"
- Homography matrix: A 3×3 projective transformation relating points between two views of the same plane (or planar assumption). "homography matrix "
- Image-Text Matching (ITM): A multimodal scoring task/model that assesses whether an image and a text description correspond. "image-text matching score (ITM)"
- Indicator function: A function that returns 1 when a condition is true and 0 otherwise, used here to aggregate matched points. "and is the indicator function that equals 1 if the condition holds and 0 otherwise."
- Intrinsics (camera intrinsics): Internal camera parameters (e.g., focal length, principal point) required for projection and calibration. "including measuring intrinsics, sensor synchronization, relative pose estimation, and metric depth,"
- Lidar: A depth sensing technology that measures distance by emitting laser pulses and timing their return. "sensors like Lidar or ToF"
- MEt3R: A metric for evaluating temporal or multi-view consistency of generated sequences. "higher MEt3R~\cite{asim2025met3r} indicates worse consistency."
- Metric depth: Depth measurements with absolute scale (e.g., meters), as opposed to relative or up-to-scale depth. "and metric depth"
- Near-Infrared (NIR): An electromagnetic spectrum band just beyond visible red; NIR cameras capture this band. "such as NIR (Near-Infrared) sensors"
- Quantile function: The inverse cumulative distribution function that returns the value at a specified percentile. "with as the quantile function."
- Radiance field: A function mapping 3D locations and viewing directions to emitted/absorbed light, enabling view synthesis. "a unified 3D RGB-X radiance field"
- RANSAC: A robust estimation algorithm that fits a model to data containing outliers by iteratively sampling subsets. "and find a transformation with RANSAC~\cite{fischler1981random}."
- Relative pose estimation: Estimating the rotation and translation between cameras from image correspondences. "image matching aims for relative pose estimation"
- SAR (Synthetic-Aperture Radar): A microwave imaging technique that synthesizes a large antenna aperture via sensor motion for high-resolution radar images. "Synthetic-Aperture Radar (SAR)"
- Scaled dot product: A similarity measure (often used in attention) that computes a dot product scaled by a factor. "computed by scaled dot product of the RGB-X features."
- Self-matching: The proposed consistency check that uses a matcher to ensure aligned RGB–X patches match to themselves. "We propose a self-matching mechanism"
- SigLIP2 image encoder: A vision-language pretraining model used to extract features and compute cosine similarity losses. "using SigLIP2 image encoder~\cite{tschannen2025siglip}"
- Structure-from-motion (SfM): Recovering 3D structure and camera motion from overlapping images. "Structure-from-motion methods like COLMAP~\cite{schonberger2016structure}"
- Time-of-Flight (ToF): A depth sensing method that measures the time light takes to travel to a surface and back. "sensors like Lidar or ToF"
- Trace (matrix): The sum of a square matrix’s diagonal elements, used here in a similarity objective. "is trace for a matrix"
Collections
Sign up for free to add this paper to one or more collections.