- The paper presents a novel benchmark that integrates super-deep investigation and wide retrieval to test autonomous LLM research capabilities.
- It employs a graph-anchored evaluation methodology to ensure logical consistency, traceability, and robust synthesis of complex research reports.
- Empirical results reveal significant gaps in current LLMs, underlining limitations in long-horizon planning, citation integration, and multi-source aggregation.
Super Research: A Ceiling-Level Evaluation Paradigm for Autonomous Research with LLMs
Motivation and Positioning
The paper "Super Research: Answering Highly Complex Questions with LLMs through Super Deep and Super Wide Research" (2603.00582) establishes a new evaluation and task paradigm aimed at measuring the operational limits of LLMs in autonomous, long-horizon research settings. Unlike prior benchmarks focused solely on vertical depth ("Deep Research") or horizontal breadth ("Wide Search"), Super Research targets tasks requiring simultaneous synthesis of massive, heterogeneous evidence sources and recursively resolved chains of reasoning. The framework explicitly addresses queries that demand long-horizon planning (100+ retrieval steps), large-scale retrieval (1,000+ web pages), and cohesive integration into verifiable research reports up to 100k words.
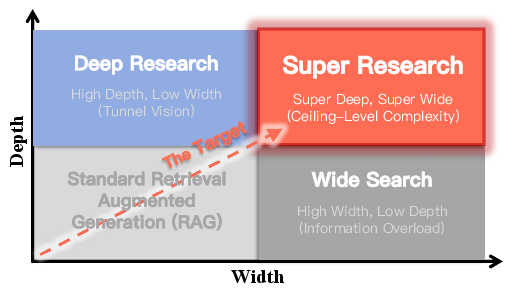
Figure 1: Super Research integrates both super-deep investigation and super-wide retrieval, exceeding the limitations of standard RAG, Deep Research, and Wide Search paradigms.
By framing Super Research as a "ceiling-level" challenge, the paper stresses the importance of stress-testing LLMs for robustness, precision, and logical consistency beyond the capabilities saturated in existing agentic benchmarks.
Benchmark Construction and Dataset Characterization
The SuperResearch benchmark comprises 300 expert-curated tasks spanning 10 specialized domains, each selected for intricate cognitive nuance, structural depth, and the presence of conflicting evidence. A rigorous construction pipeline blends frontier-tier LLM generation with human expert vetting, applying negative constraints to avoid trivial, factoid, or consensus-based queries. Tasks are decomposed algorithmically into Directed Acyclic Graphs (DAGs) of research subtasks, mirroring domain-expert workflows.
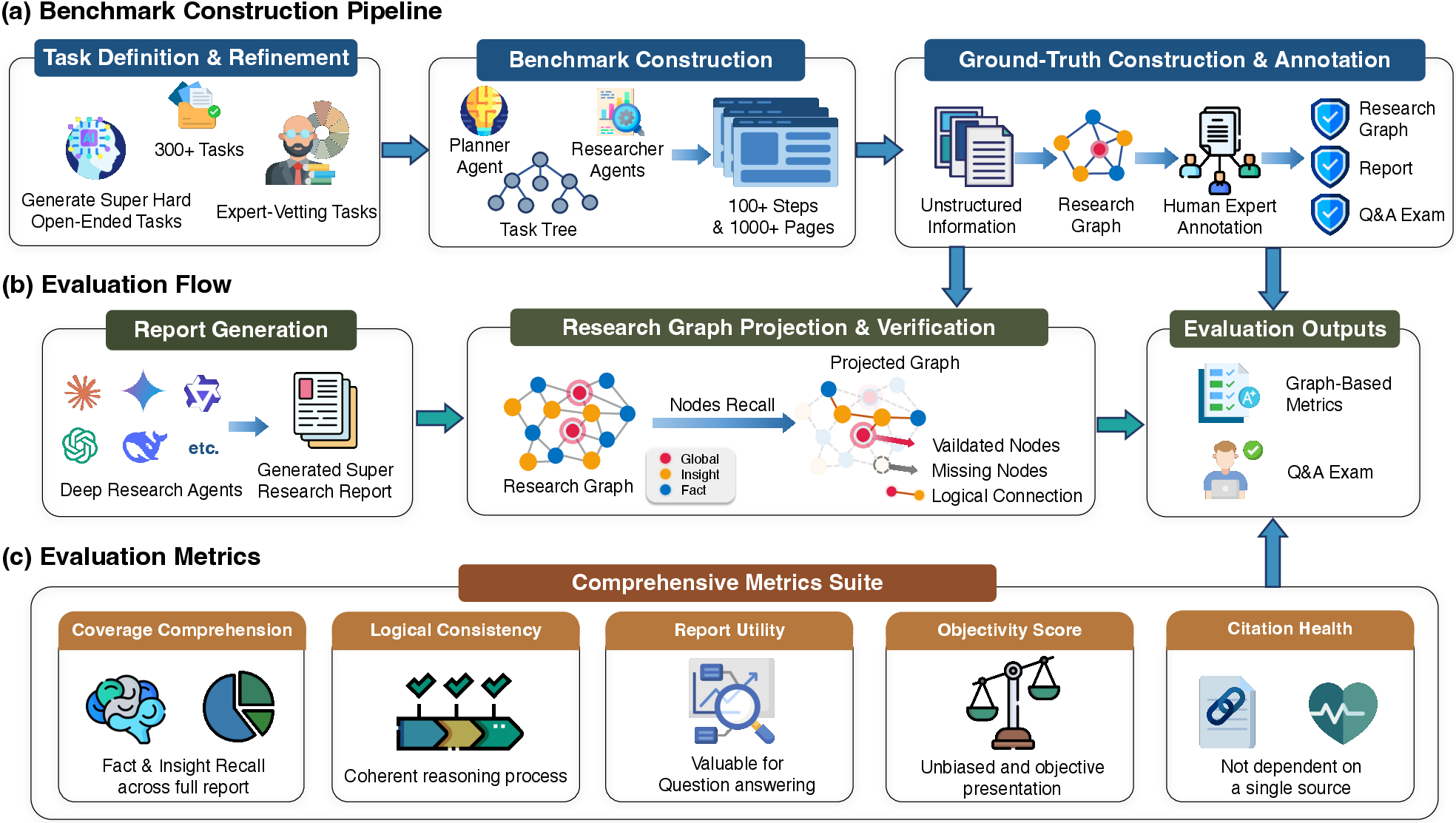
Figure 2: SuperResearch Benchmark pipeline: task definition, agentic long-horizon research, gold-standard graph construction, and multi-dimensional auditing.
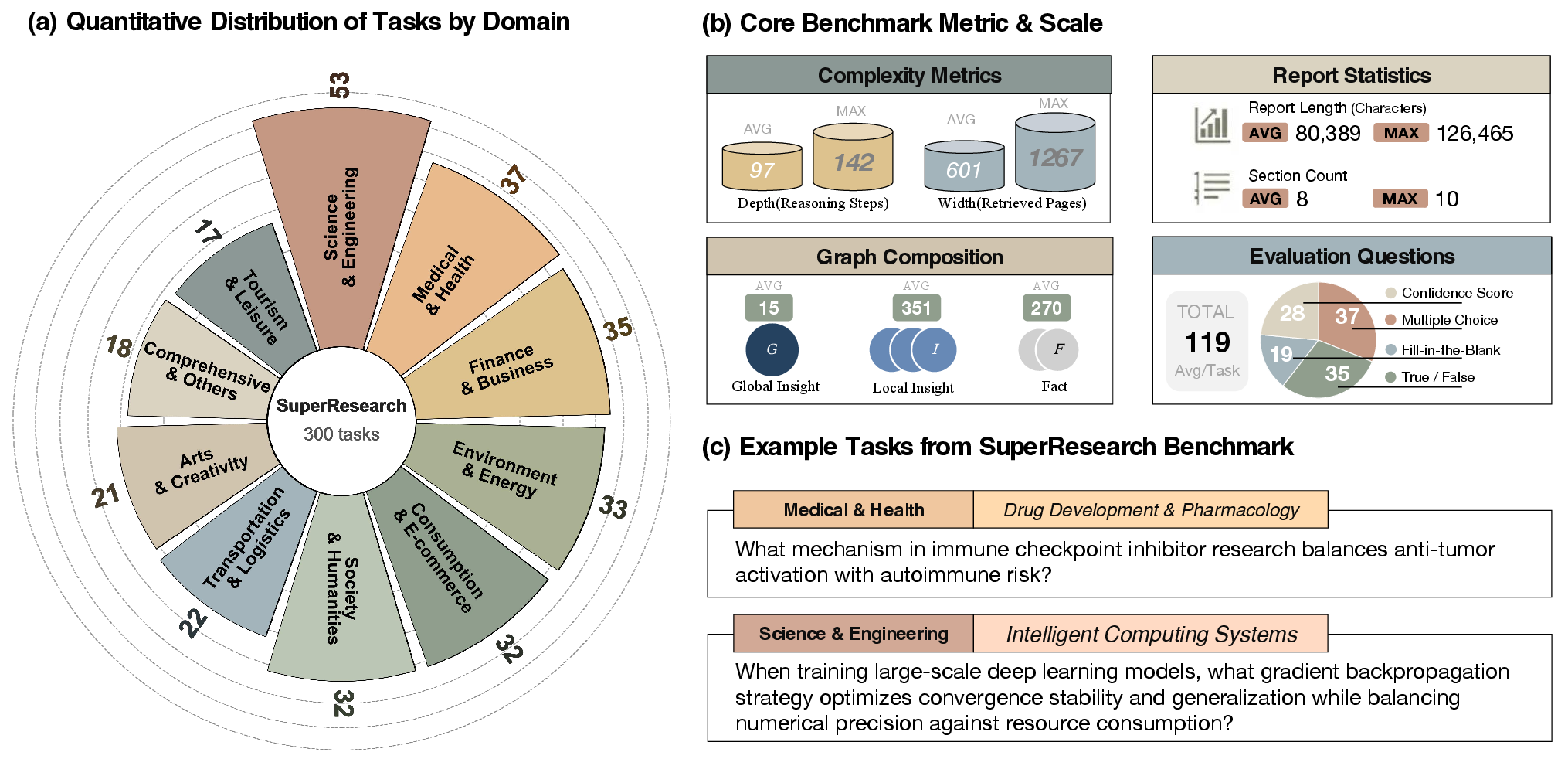
Figure 3: SuperResearch tasks are quantitatively distributed and characterized by complexity, report structure, hierarchical graph density, and diverse evaluation mechanisms.
Granularity and diversity within domains are further visualized across specific subfields, confirming benchmark coverage from science and engineering to business and healthcare.
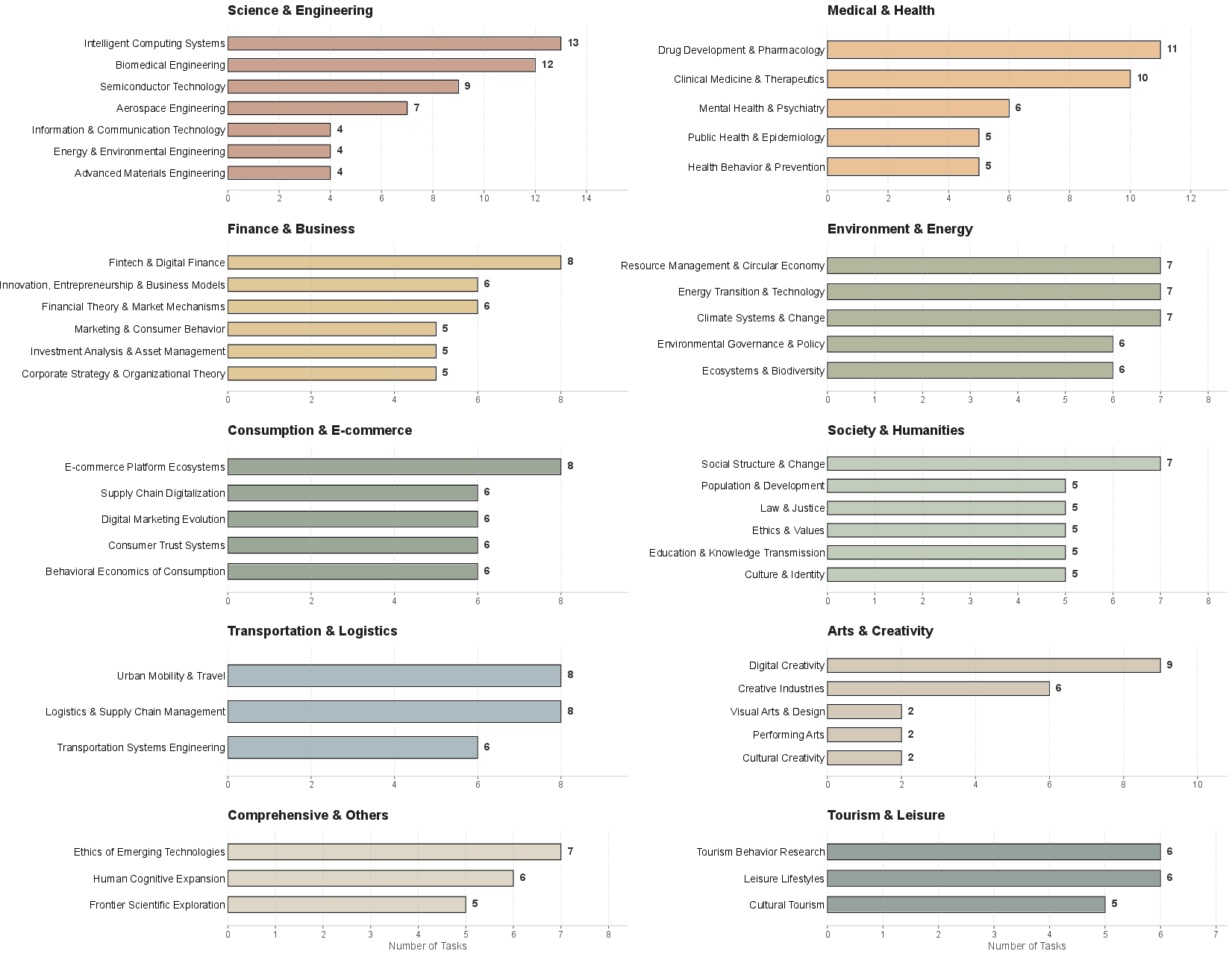
Figure 4: Detailed subdomain task distribution, confirming broad coverage and high entropy across specialized fields.
Human-AI Collaborative Research Graph Pipeline
The framework operationalizes a four-phase pipeline: hierarchical task decomposition, research graph construction, report synthesis, and automated evaluation. During graph construction, raw reports are distilled into atomic factual nodes, abstracted into higher-order insights, and synthesized into global conclusions through iterative human-AI collaboration.
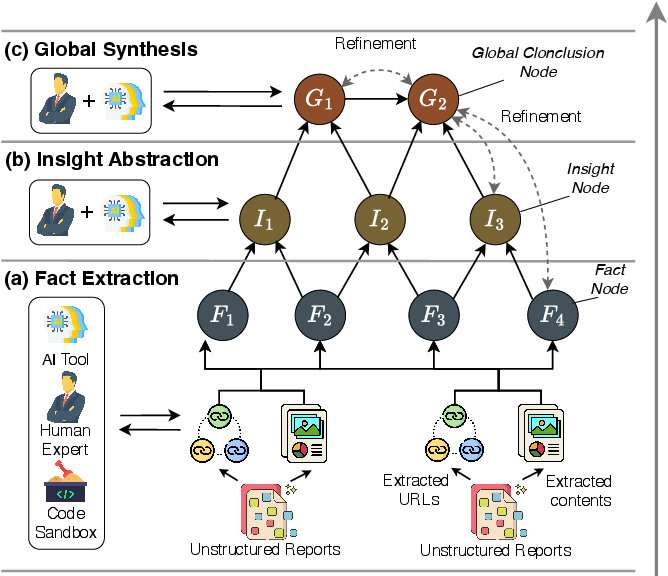
Figure 5: Research graph construction stages—fact extraction, insight abstraction, and global synthesis form structured, ground-truth knowledge.
This approach enables explicit traceability and logical connectivity, supporting both auditability and reproducibility of complex research agent outputs.
Graph-Anchored Evaluation Methodology
Super Research introduces a five-dimensional evaluation suite: Coverage Rweighted, Logical Consistency Clogic, Report Utility Uqa, Objectivity Obias, and Citation Health. Distinct from LLM-as-a-judge metrics or atomic fact recall, the graph-anchored protocol maps claims to ground-truth graph nodes, checks citation chains, and penalizes hallucinated conclusions. Objectivity auditing employs thesis-antithesis calibration to explicitly measure stance balance amidst ambiguous evidence clusters.
The diagnostic Citation Health metrics—Source Dominance and Narrative Monopolization—expose single-source dependency and the spatial distribution of evidence, mitigating risks of summary or bias regression.
Model Evaluation and Results
Empirical benchmarking covers 12 contemporary systems grouped as Deep Research Systems (Gemini, Sonar, Tongyi, OpenAI o3/o4-mini), Native Search-Integrated Agents (Kimi-k2, Grok-4-1-fast), and Search-Augmented Baselines (DeepSeek-r1, Claude-3.5-sonnet, etc.). Operational scores exhibit a marked gap between ceiling-level demands and current agentic capabilities; Gemini Deep Research achieves the highest aggregate metric (28.62), confirming the challenge posed.
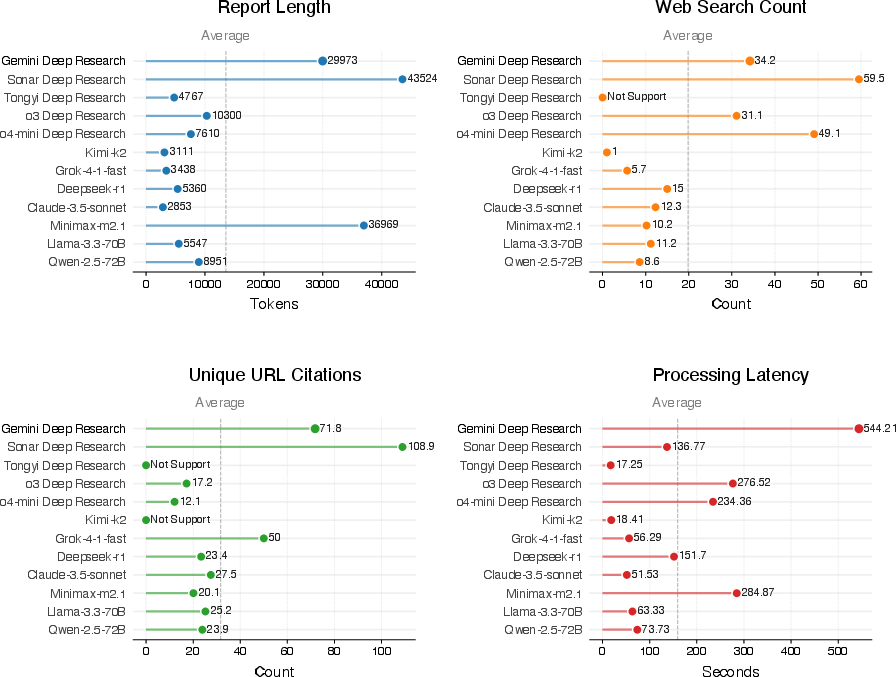
Figure 6: Multi-dimensional operational benchmarking demonstrates Gemini Deep Research's superior depth, synthesis volume, and sourcing diversity against industry averages.
Cross-domain analysis reveals domain-specific stratification, with Gemini Deep Research excelling in analytic-heavy sectors. Baseline models consistently lag across all evaluation axes, lacking both systematic retrieval coverage and logical synthesis.
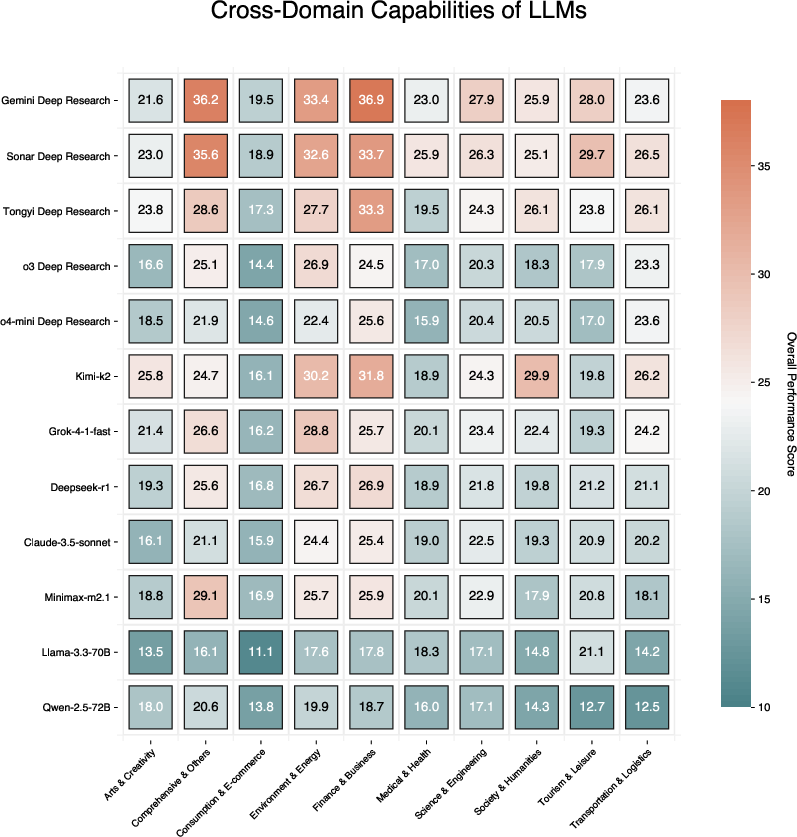
Figure 7: Cross-domain capability radar chart—Gemini Deep Research outperforms in analytical and technical domains.
Qualitative Failure Modes
Multiple case studies highlight critical failure regimes: (i) The Complexity Trap, where reasoning chains collapse under deep multi-hop requirements; (ii) Single-Source Regression, manifesting as narrative monopolization despite the breadth of retrieval; (iii) Spatial Overload, artificially inflating source diversity without true integration; and (iv) Defensive Summarization Paradox, where excessive objectivity yields generalized but actionably shallow reports.

Figure 8: Complexity trap case—models fail to resolve deep, multi-layered dependencies.

Figure 9: Single-source regression—model fails to synthesize across sources and monopolizes narrative.

Figure 10: Spatial overload—appearance of evidence diversity without structural integration.

Figure 11: Defensive summarization paradox—reports exhibit objectivity but lack actionable detail.
Evaluation Sensitivity and Consistency
Ablation studies demonstrate the superiority of the graph-anchored metrics over LLM-based judging in terms of responsiveness to perturbations and consistency across evaluator models. The graph metric achieves responsiveness rates of 57–80%, whereas LLM judges fluctuate between 15–22%. Standard deviation in objectivity scoring is reduced by 65× under the graph protocol, supporting robust, reproducible benchmarking.
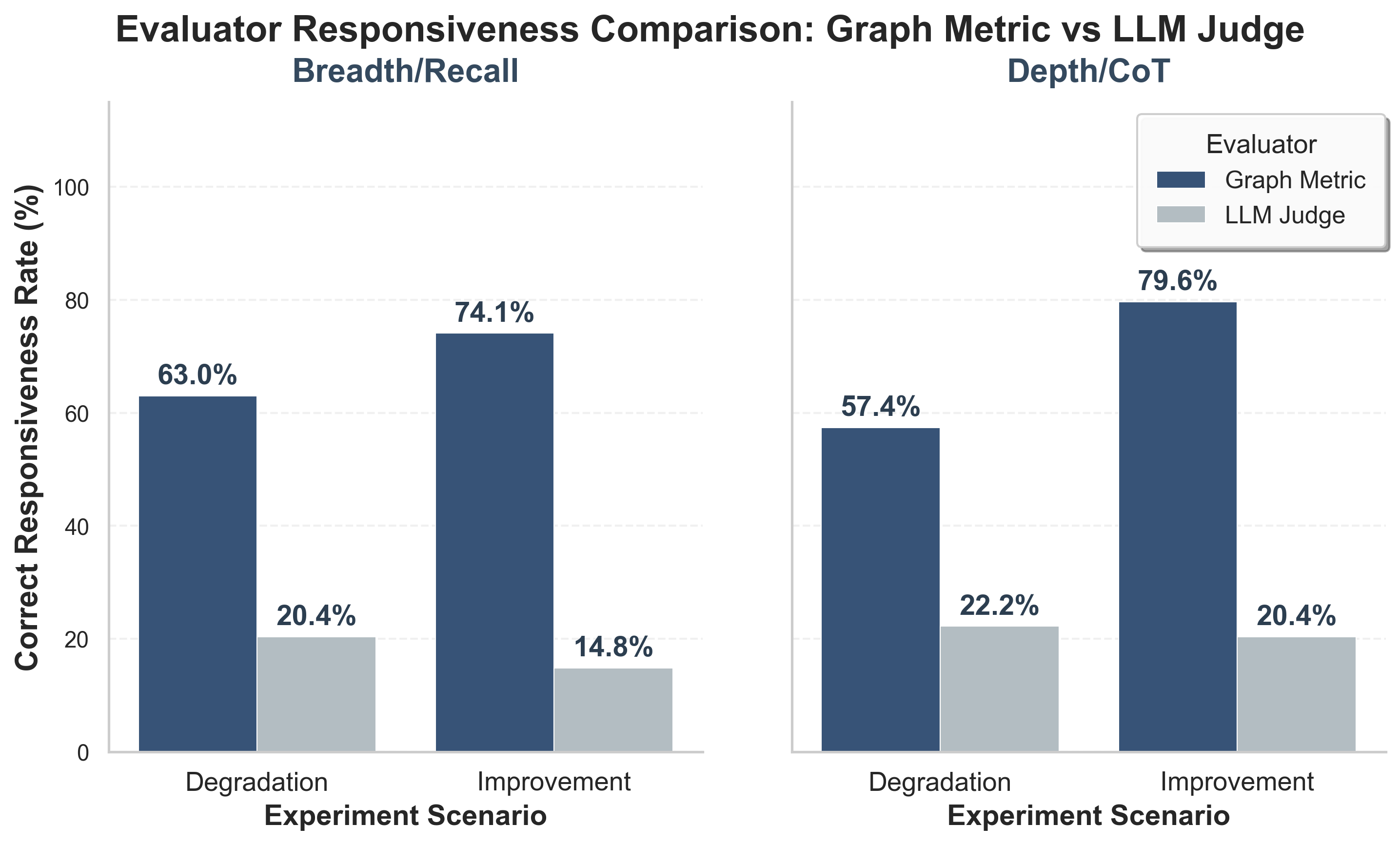
Figure 12: Evaluation sensitivity analysis—graph metrics produce higher responsiveness to quality changes than LLM-based scoring.
Visualization and Auditing Interfaces
The paper details advanced visualization tools supporting interactive report management, graph projection, quiz-based evaluation, and holistic audit dashboards. These interfaces facilitate both automated and expert-driven interventions, maintaining transparency in the evaluation lifecycle.
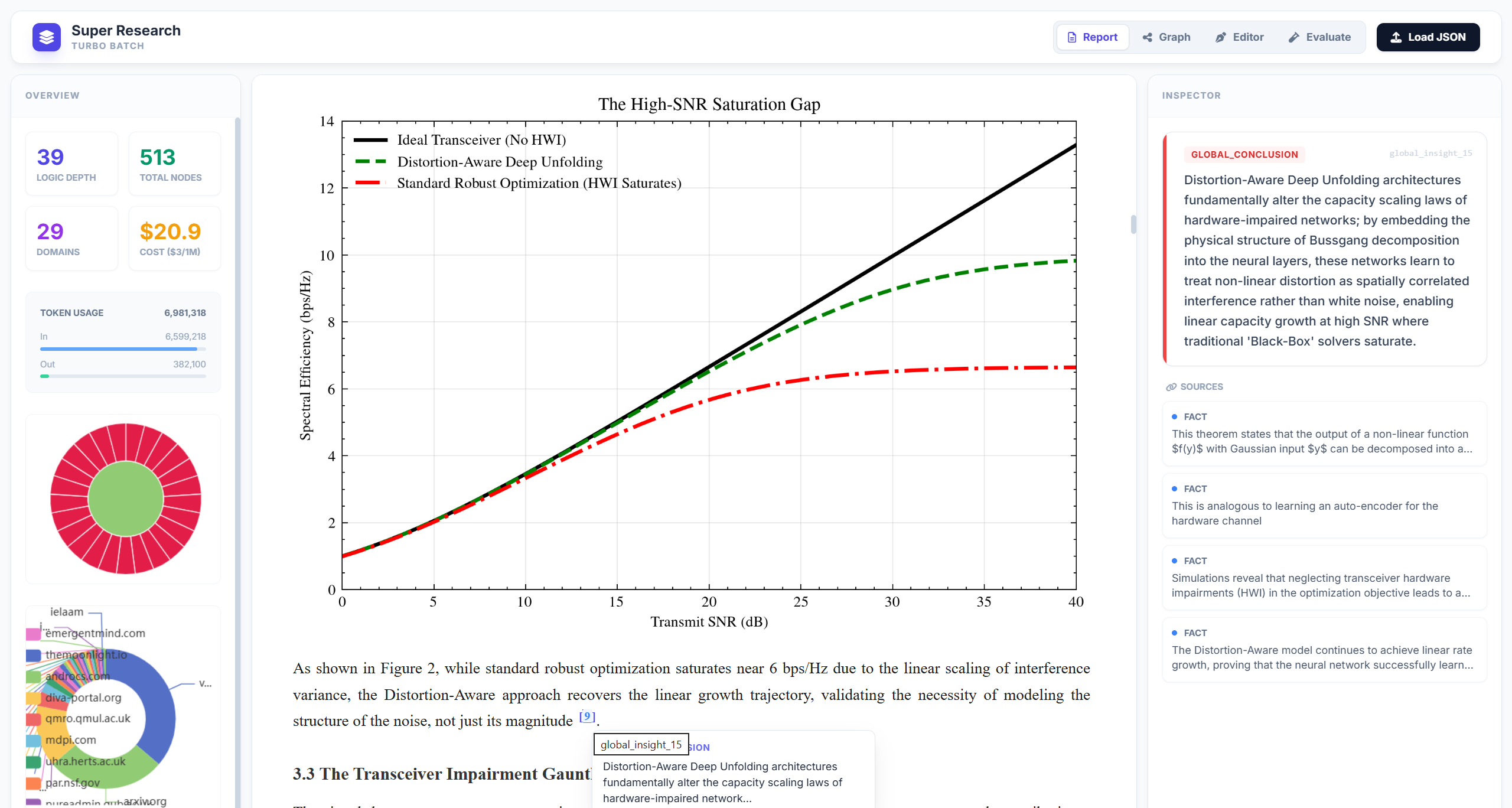
Figure 13: Report management dashboard—visualizes report metrics, citation density, and content structure.
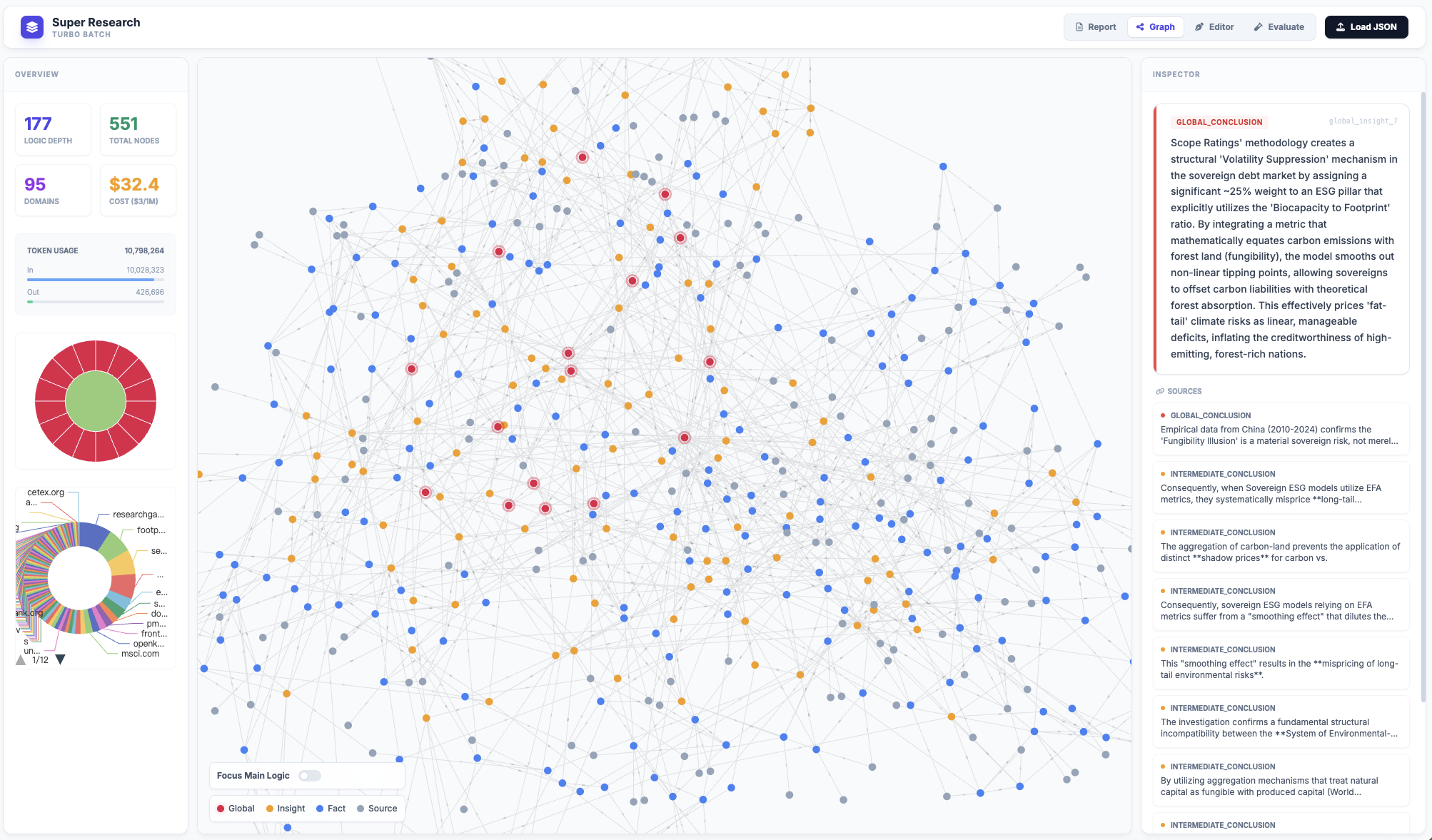
Figure 14: Interactive research graph visualization—color-coded by abstraction levels, supporting semantic inspection.
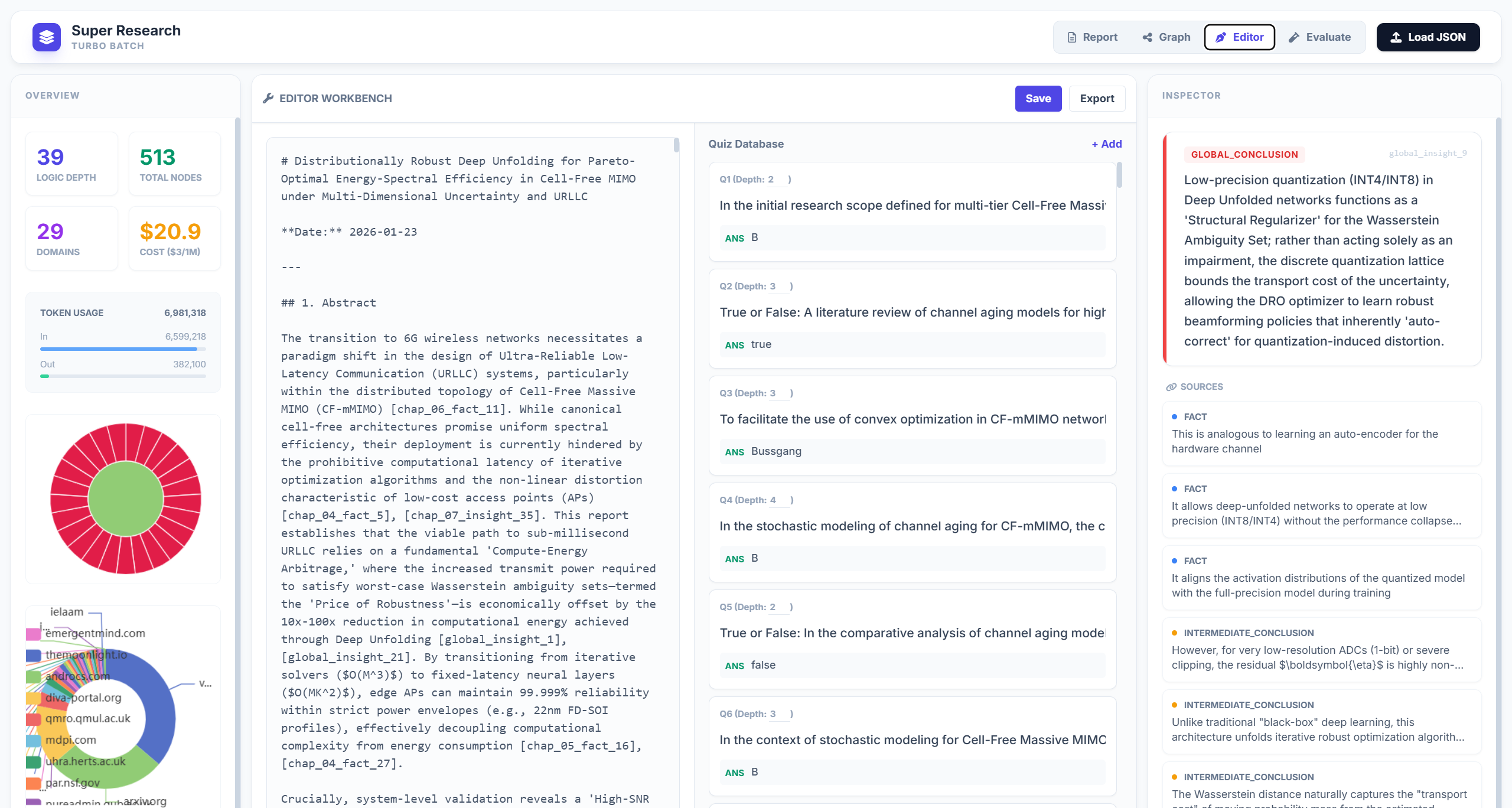
Figure 15: Split-view evaluation editor couples report with QA/metrics, supporting domain expert intervention.
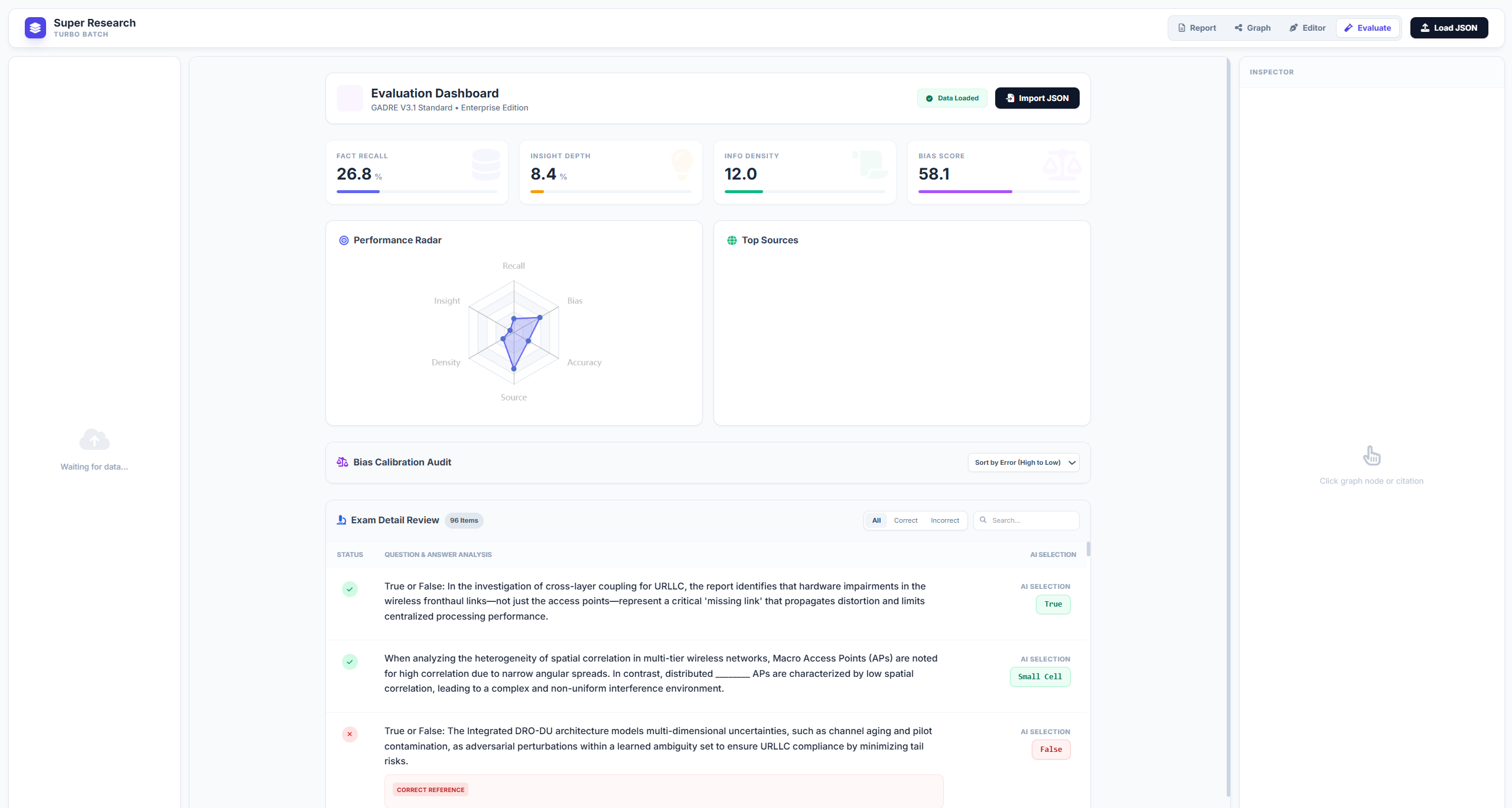
Figure 16: Comprehensive metric score visualization and exam QA performance breakdown.
Implications and Future Directions
Super Research operationalizes a strategic-tier paradigm for autonomous research, pushing agentic AI systems toward extremes of evidence integration, logical depth, and reliable synthesis. By exposing current limitations (~29% ceiling performance) in even SOTA models, the benchmark signals a significant gap in long-horizon planning, citation management, and adversarial robustness. Practically, this protocol is vital for domains such as scientific discovery, regulatory analysis, and professional intelligence, where synthesis across conflicting, high-entropy data is non-negotiable.
Theoretically, Super Research provides a reference standard and measurement protocol for future advances in agentic planning, multi-agent collaboration, and graph-structured reasoning. However, the computational expense and risk of compounding hallucinations in large-scale synthesis necessitate parallel research into efficiency and adversarial safety. Integration with "Green AI" practices and automated verification schemes is paramount.
Conclusion
Super Research formalizes the next frontier in agentic LLM benchmarking, integrating super-deep investigation with super-wide retrieval and graph-anchored evaluation protocols. The benchmark reveals persistent gaps in logical consistency, evidence synthesis, and domain-specific robustness across all commercial and research systems, establishing a stringent proxy for general research competence. Its adoption will accelerate development and rigorous assessment of long-horizon autonomous research agents, supporting both theoretical advancement and practical deployment in high-stakes settings.