- The paper demonstrates that small, carefully curated SFT datasets aligned with pretraining gaps yield optimal performance, while excessive scaling causes interference.
- It models pretraining as population-level in-context learning with linear self-attention and derives precise error bounds and convergence rates for SFT and RL paradigms.
- Empirical validations using LSA and GPT-2 confirm the theoretical predictions, emphasizing balanced data curation and the need for diversified outcome supervision.
Theoretical Analysis of Data Quality and Synergistic Effects in LLM Pre- and Post-Training
Motivation and Conceptual Framework
The paper investigates the theoretical underpinnings of data quality, scaling, and interaction dynamics between pretraining and post-training for LLMs, specifically focusing on reasoning ability and in-context learning. While empirical best practices dictate massive, diverse pretraining and careful selection of post-training data, there has been limited rigorous understanding of why these protocols yield certain behaviors. The authors bridge this gap by studying transformer models on an in-context weight prediction task for linear regression, enabling tractable yet expressive analysis of transformer learning dynamics.
Key facets delineated in the work include:
- Latent capabilities induced during pretraining and subsequently activated by post-training.
- Contrasts between process supervision (SFT) and outcome supervision (RL/RLHF) from an optimization and generalization perspective.
- Precise characterization of "hard" and "informative" examples and the role of interference in post-training.
Formal Pretraining and Post-Training Modeling
Pretraining is modeled as population-level in-context learning such that the transformer acquires parameters encoding the statistics of the input distribution. The theoretical analysis leverages a linear self-attention (LSA) abstraction to elucidate the role of empirical covariances and optimal weight initializations.
Post-training is decomposed into two major paradigms:
- Supervised Fine-Tuning (SFT): The model receives ground-truth chain-of-thought intermediate supervision, which minimizes KL divergence and encourages coverage over plausible reasoning trajectories.
- Outcome Supervision (OS / RL): The model is optimized only for final reasoning outcomes, with the RL loss landscape typically exhibiting sharp curvature and sensitivity to distributional alignment.
The authors present formal loss functions and recurrence relations for both SFT and RL, analyzing convergence, sparsity preservation, and adaptation under covariate shift in input statistics.
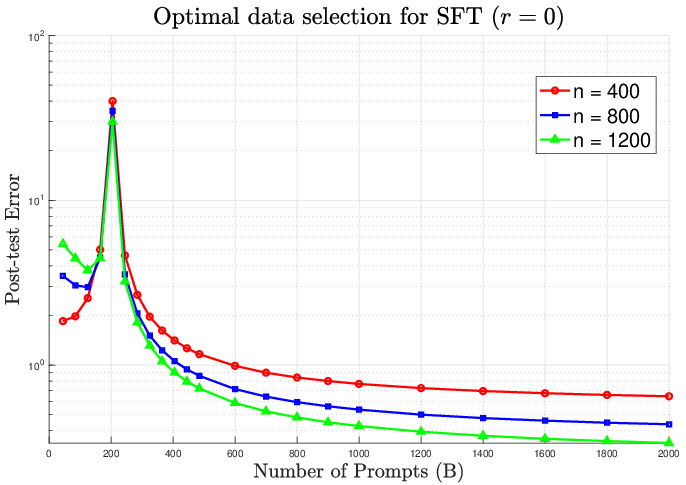
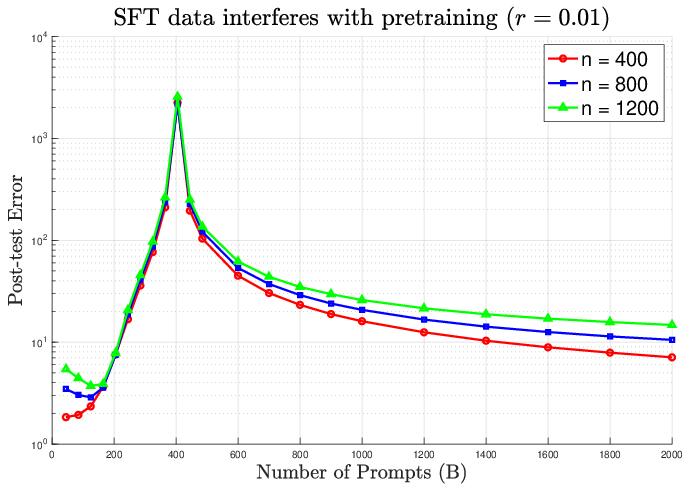
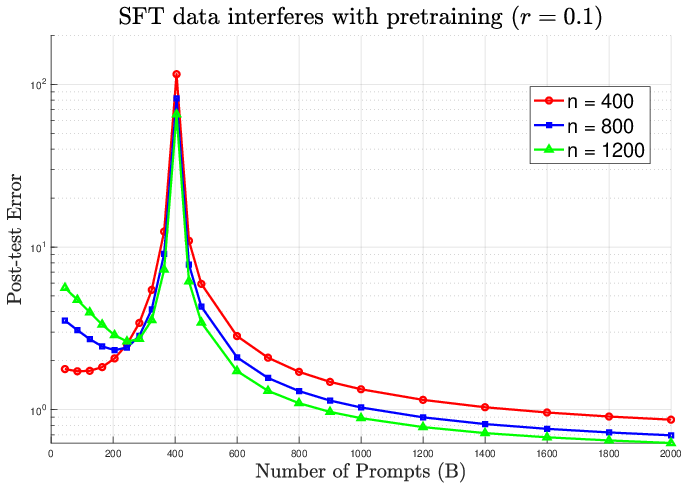
Figure 1: Optimal SFT data selection minimizes post-test error in the absence of distributional interference (r=0).
Analytical Results: SFT vs. RL/RLHF Optimization Landscapes
Theoretical results reveal several novel and empirically validated insights:
- SFT learns most efficiently from a small collection of examples that the pretrained model finds difficult. Excessive SFT data volume introduces detrimental interference, eroding the latent structure acquired during pretraining.
- The optimal SFT allocation requires data concentrated in directions poorly covered by the pretraining covariance, aligning with adaptation shifts.
- RL benefits from scale: stability and effective adaptation are achieved only when outcome supervision datasets are large and not overly difficult relative to the pretrained model's capabilities. The RL loss landscape is sharply curved, demanding careful learning rates and substantial data diversity.
Theoretical error bounds, convergence rates, and population regime asymptotics substantiate these claims. The paper analytically demonstrates double descent phenomena and catastrophic error increases when SFT dataset size approaches model dimensionality in the presence of distributional interference.
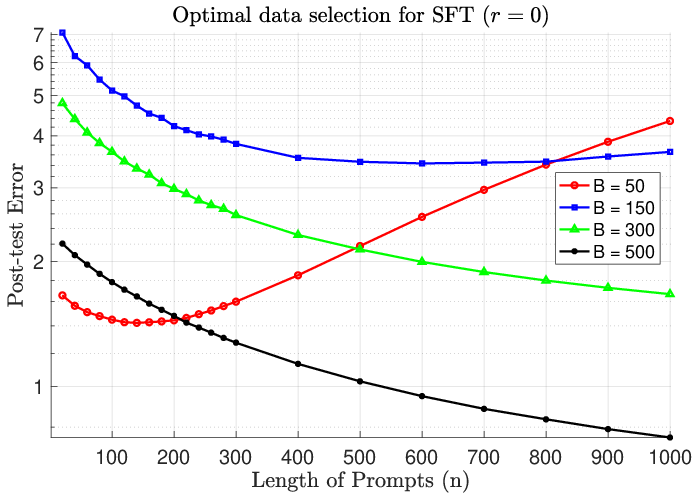
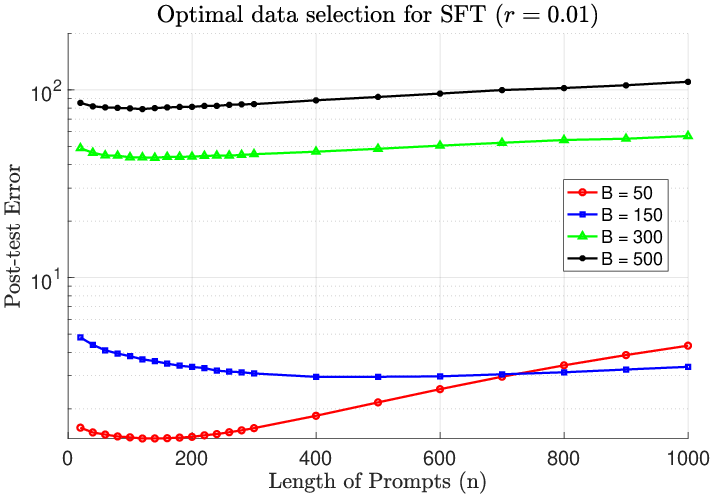
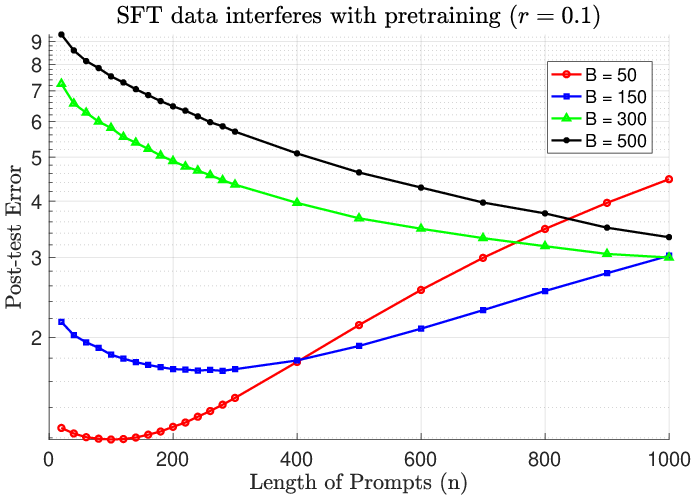
Figure 2: Post-training error escalates with interference; increasing SFT prompts (B) past optimal causes pronounced degradation.
Data Selection, Scaling, and Quality Trade-offs
Optimal data selection for SFT is derived analytically by minimizing post-test error through covariance alignment. The results concretize empirical intuition: high-quality SFT data should be hard and diverse, targeting latent gaps left by pretraining. Scaling up SFT data—either in number of prompts (B) or prompt length (n)—increases the risk of interference, leading to performance degradation.
Population and mean-field analyses, leveraging random matrix theory, provide closed-form and asymptotic formulas for test error as a function of data parameters, covariance structure, and adaptation shift.
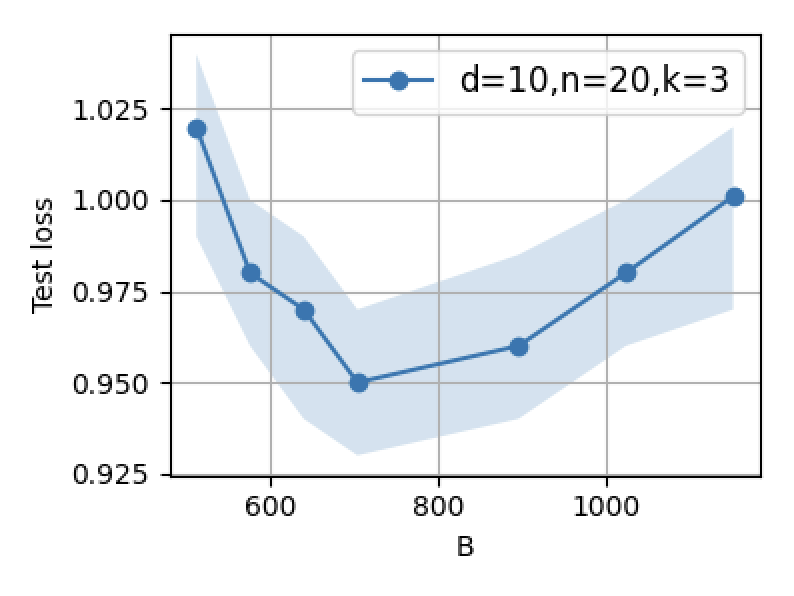
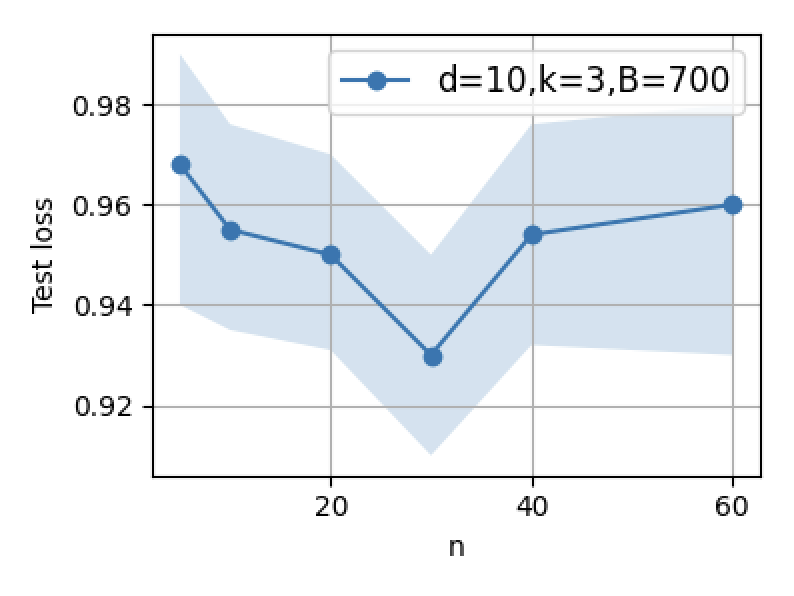
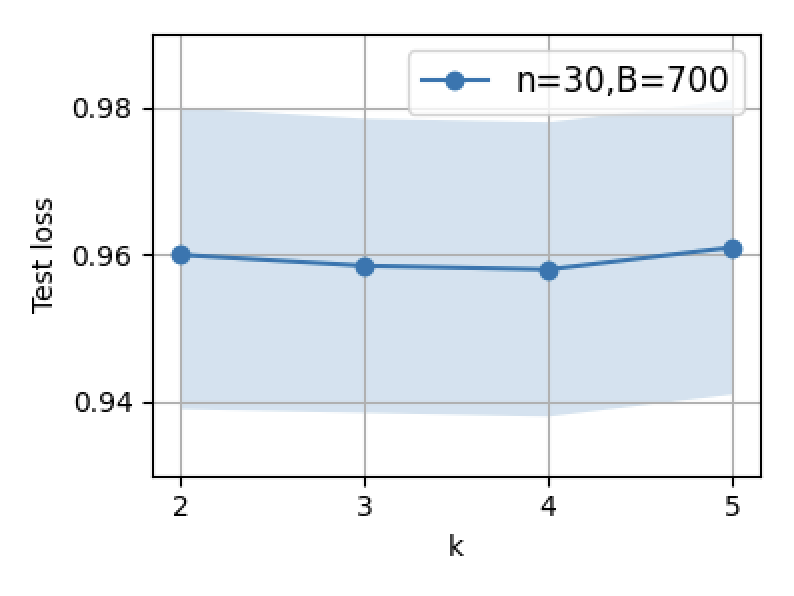
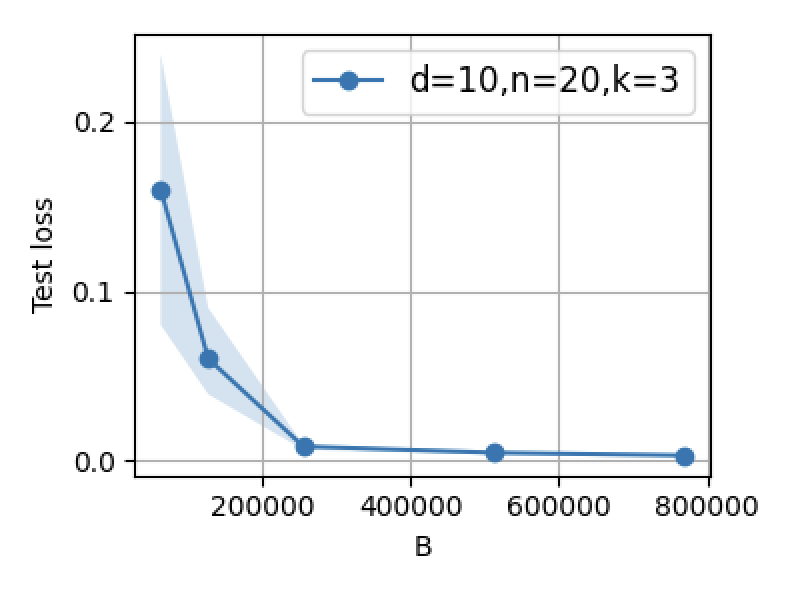
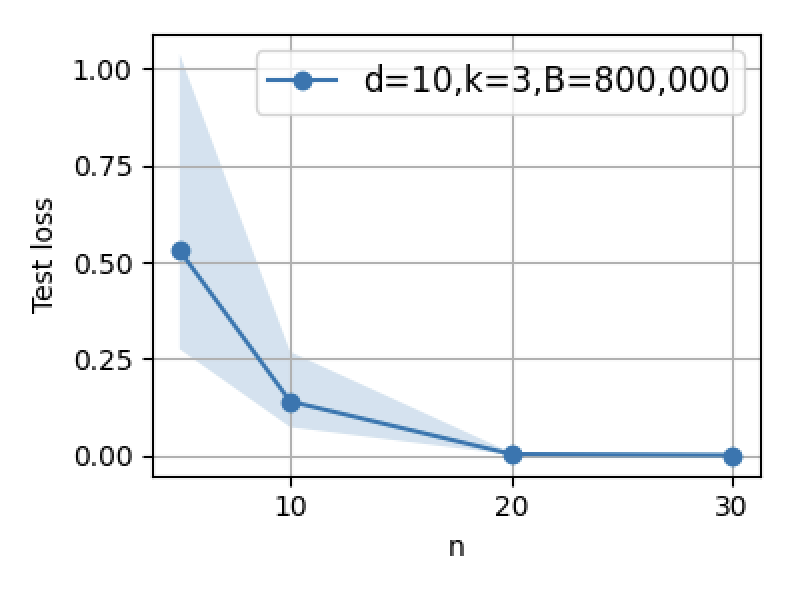
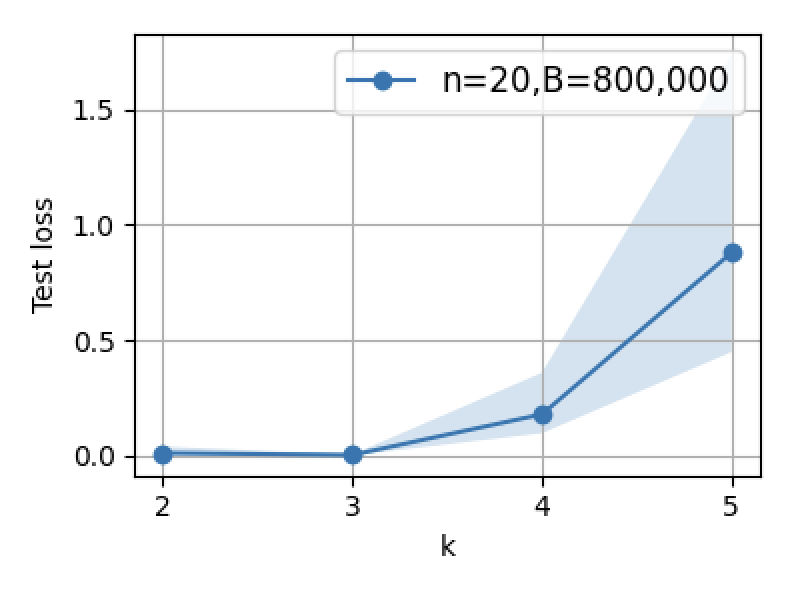
Figure 3: Supervised fine-tuning performance: increasing B or n initially decreases error, but excessive scaling leads to reversal due to interference.
Empirical Validation with LSA and GPT-2
Experimental results on linear self-attention and nonlinear GPT-2 architectures confirm theoretical predictions:
- For SFT, optimal performance is obtained at small, carefully selected datasets aligned with adaptation directions. Scaling SFT data volume beyond this point increases test error, corroborating theoretical double descent and interference phenomena.
- RL/OS training always benefits from larger volume and diversity of outcome-supervised data, with stability and robustness emerging only at large scale.
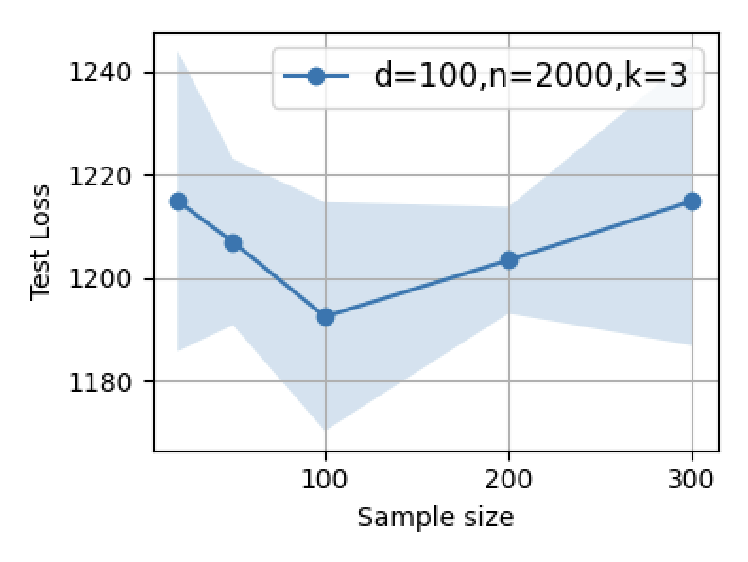
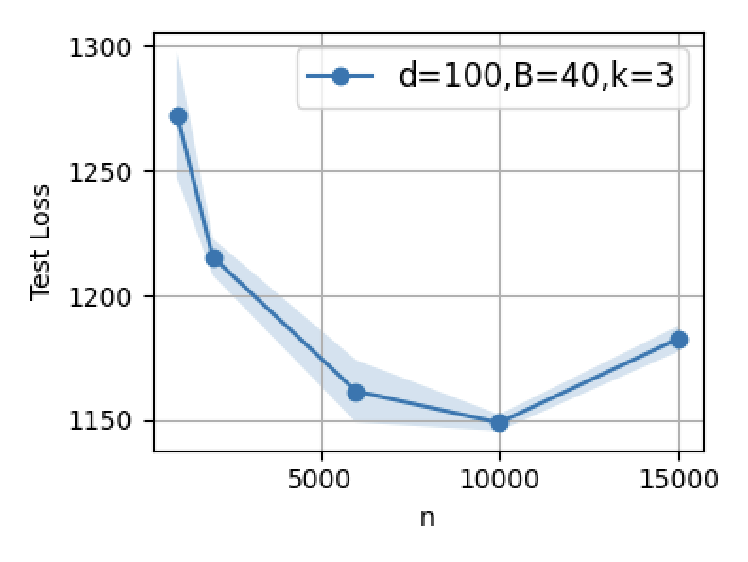
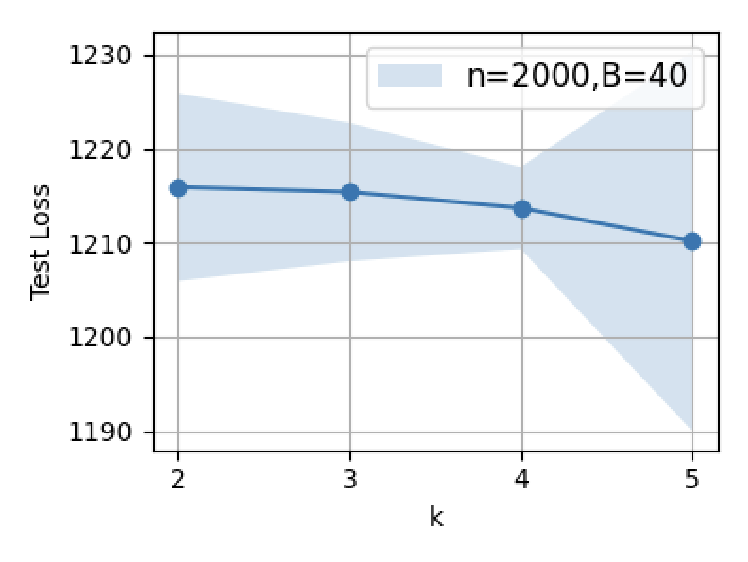
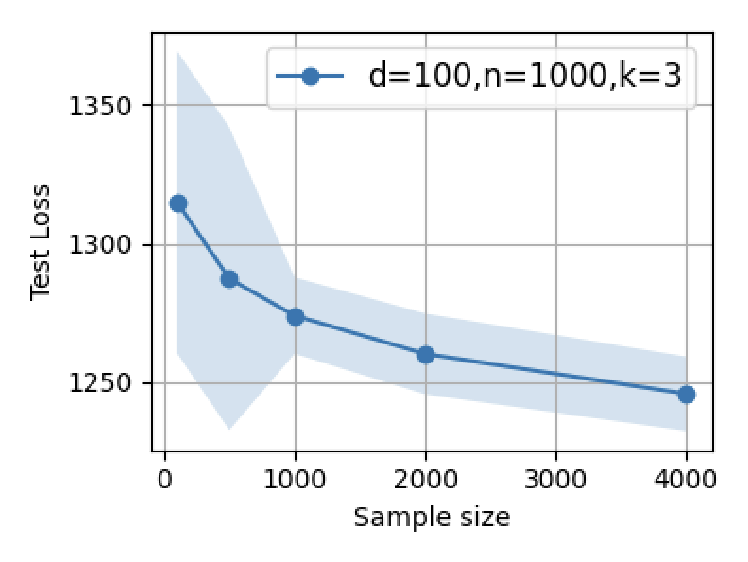
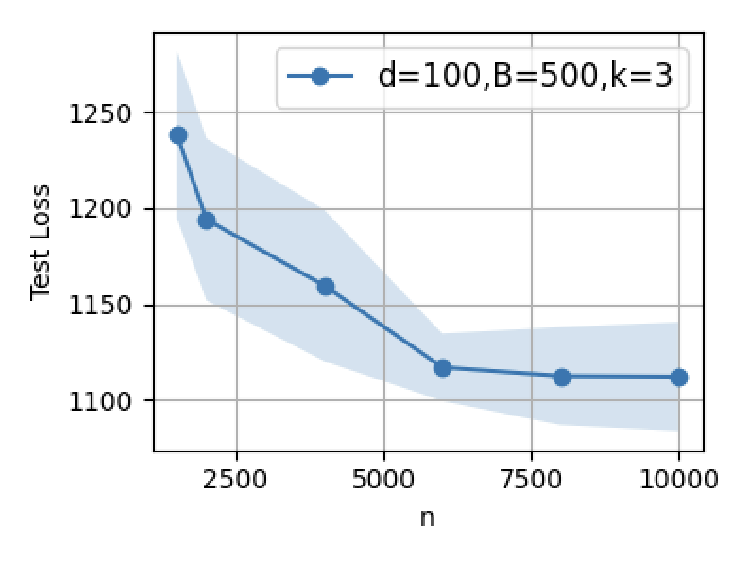
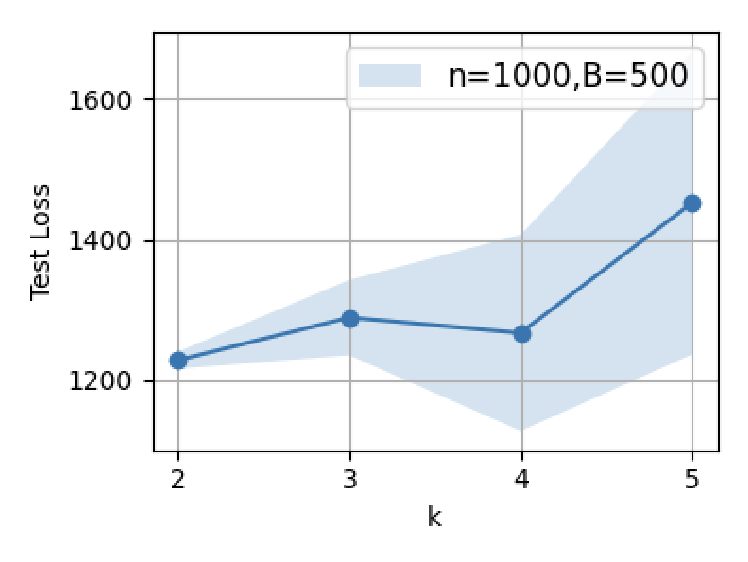
Figure 4: Supervised fine-tuning in GPT-2: test loss minima are attained at modest SFT dataset sizes; further scaling induces error increases.
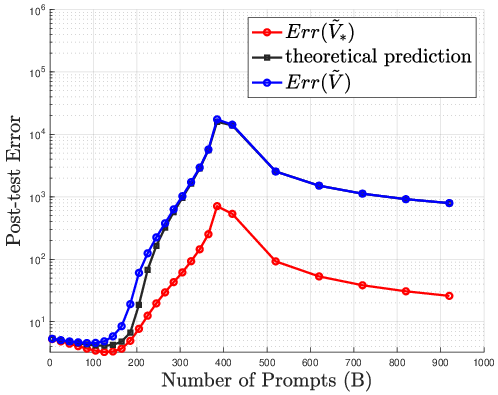
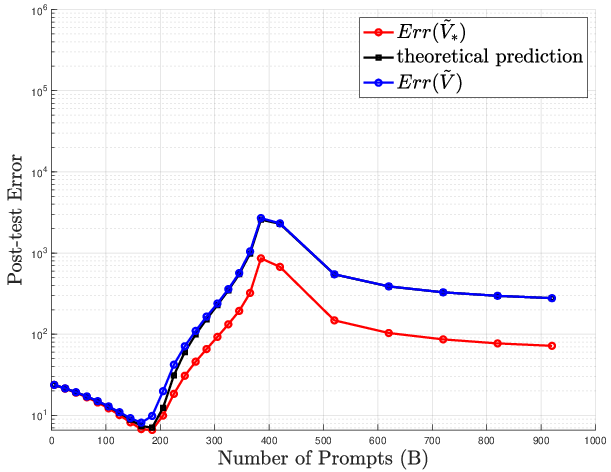
Figure 5: Test error as a function of prompt length (n=1000): optimal SFT scaling minimizes post-test error, but overparameterization yields U-shaped trends.
Practical and Theoretical Implications
The findings imply critical guidance for LLM development:
- Pretraining should emphasize spectral balance and broad distributional coverage, as latent generalization is strictly bottlenecked by pretraining data diversity.
- SFT must be curated to cover gaps and challenging cases, avoiding over-saturation that diminishes prior structure.
- RL post-training is effective only when preceded by balanced pretraining and executed with massive, diverse feedback data to mitigate instability from sharp loss landscape curvature.
The synergy between pretraining and post-training is shown to be fundamental: SFT activates latent reasoning abilities via challenging examples, while RL serves as scale-intensive refinement, particularly when the pretrained model already possesses partial alignment in the target adaptation directions.
Future developments will likely focus on principled data allocation, leveraging theoretical error expansions and mean-field approaches for optimal pretrain/post-train synergy, advancing robustness in reasoning models.
Conclusion
This paper provides rigorous theoretical and empirical insight into the interaction dynamics between pretraining and post-training data selection in reasoning-centric LLMs. The results formalize key empirical phenomena—such as the necessity of balanced pretraining, the optimality of small, high-quality SFT datasets, and the scale dependence of RL—guided by precise error bounds and optimization landscape analysis. These findings underpin principled data curation and training paradigms for both efficiency and robustness in advanced LLMs (2603.01293).