- The paper introduces CharacterFlywheel, an iterative framework that integrates reward modeling, data curation, and reinforcement learning to boost LLM engagement and steerability.
- It details a robust methodology leveraging multi-mode data annotation and diverse traffic sampling to balance user interactions and character adherence.
- Results demonstrate up to 8.8% improvement in engagement breadth and significant reductions in instruction violations, proving the framework's production scalability.
CharacterFlywheel: Iterative Engagement Optimization for Social LLMs
Introduction
The paper "CharacterFlywheel: Scaling Iterative Improvement of Engaging and Steerable LLMs in Production" (2603.01973) introduces a methodological framework designed to optimize LLMs for engaging, steerable social chat experiences deployed across major platforms such as Instagram, WhatsApp, and Messenger. Departing from utility-focused LLMs targeting objective tasks and benchmarks, the authors focus on conversational AI where optimizing for subjective metrics—user engagement and character adherence—presents formidable challenges due to the lack of standardized benchmarks and reward signals. The CharacterFlywheel process leverages iterative reward modeling, data curation, supervised fine-tuning, reinforcement learning, and aggressive metric tracking at both offline and online levels.
Iterative Development Cycle and Production Deployment
Central to CharacterFlywheel is a tightly integrated flywheel of model deployment, user traffic curation, annotation, reward modeling, training, and evaluation.
After each deployment, curated user and internal traffic is processed through a diversified sampling pipeline to ensure balanced learning across character personas, locales, conversation depths, and job-to-be-done distributions. Annotators tag response quality, failure modes, and character adherence in both static and interactive settings. Reward models are trained as differentiable surrogates of user engagement—blending pairwise/pointwise preference learning with auxiliary user signal prediction.
The iterative cycle supports both supervised fine-tuning (SFT) and direct preference optimization (DPO), with reinforcement learning (RL) leveraging reward model scores and importance-sampling corrected losses (notably GRPO). Continuous online experimentation via A/B tests and metric tracking guide model selection and drive policy revisions.
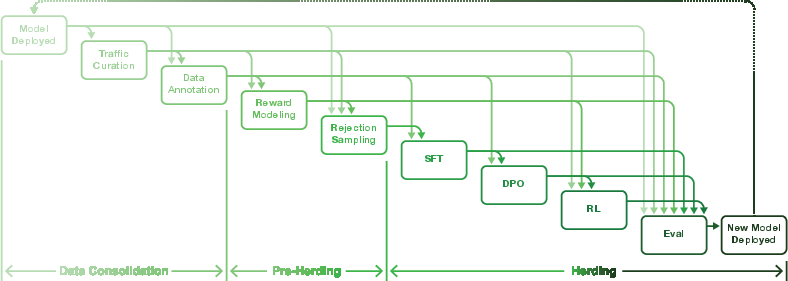
Figure 1: Overview of the CharacterFlywheel iterative development cycle, showing closed-loop data flow and optimization for engagement metrics.
Data Pipeline and Annotation Strategies
Robust traffic curation and annotation underpin the process. The data pipeline consolidates high-volume user interactions into structured, filtered subsets, privileging privacy, diversity, and task relevance through embedding-based sampling (using DRAMA-1B) and stratified constraints.
Annotations are conducted at scale in both static and interactive modes. In static annotation, annotators score final responses; in interactive mode, they challenge model personas and tag instruction violations. Pairwise comparisons are generated via sampling from policy pools or chain-of-thought prompts and are filtered to mitigate reward hacking (e.g., filtering by length or emoji count).
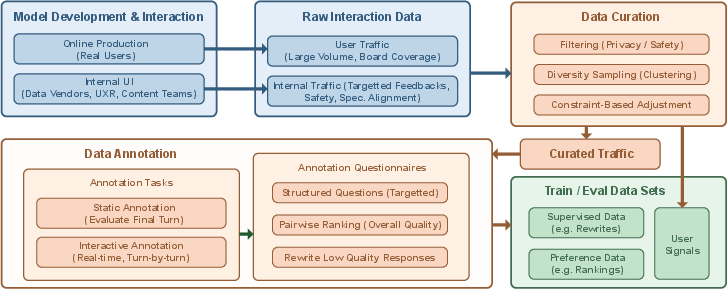
Figure 2: The CharacterFlywheel data pipeline, depicting multi-phase filtering, sampling, and constraint-based dataset preparation.
Reward Modeling and Alignment Techniques
Engagement metrics being non-differentiable, optimization is mediated by surrogate reward models. Preference models (Bradley-Terry) are trained pointwise and pairwise, initialized from Llama 3.1 weights, and are used both for RL training and win-rate evaluation. User signal models predict explicit feedback events (thumbs up/down, continue, etc.), but are ultimately used as auxiliary ranking scores rather than RL objectives due to observed vulnerabilities to reward hacking.
Rejection sampling is employed to select candidate responses for SFT/DPO datasets, rigorously rebuilt at each iteration—a quasi-on-policy approach validated by engagement lifts in A/B tests. RL training employs both online DPO and GRPO, with GRPO favored for fine-grained reward exploitation.
Evaluation: Offline Metrics and Online Engagement
Evaluation combines community benchmarks, human side-by-side comparisons, reward model win-rates, and custom ad-hoc metrics. Engagement is rigorously defined as breadth (average participation per user across periods) and depth (aggregate engagement conditional on participation), with percentage lift estimated and confidence intervals constructed via Fieller’s theorem.
The framework establishes a dual guardrail for reward model win-rates: maintaining them below 65% and preventing divergence between internal and user traffic signals. Overfitting mitigation is evidenced most notably in the V12 experiment, where reward model win-rates spiked on user traffic but engagement degraded, prompting sequenced process corrections.
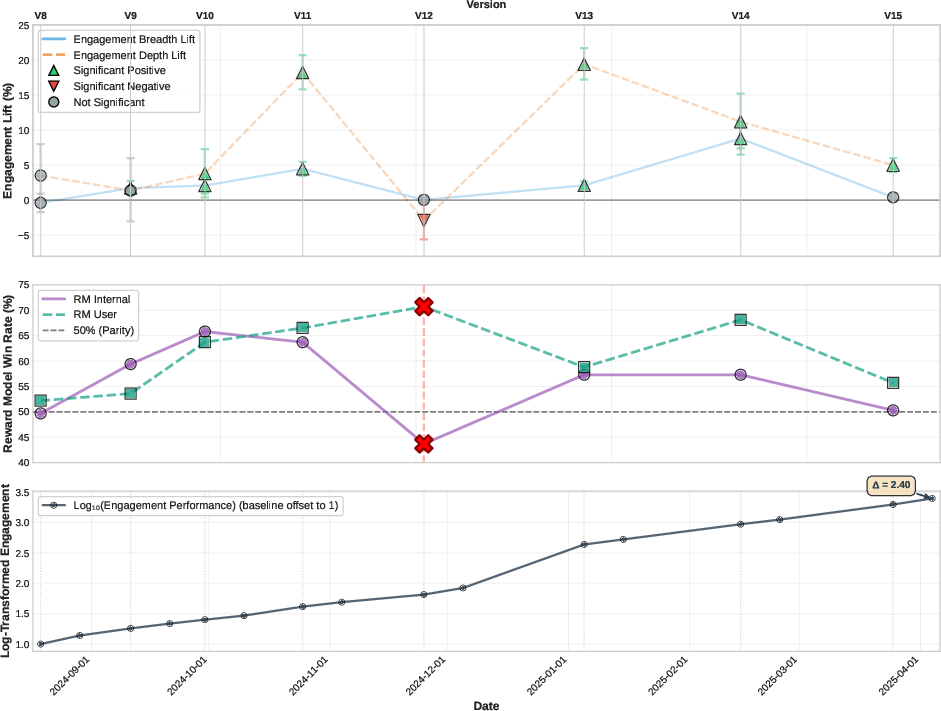
Figure 3: Post-launch engagement trajectory (V8-V15), combining A/B lift, reward model win rates, and cumulative engagement growth.
Results: Sustained Improvement and Tradeoffs
Across 15 model iterations (Jan 2024–Apr 2025), CharacterFlywheel models achieved:
- Engagement lift: Up to 8.8% in breadth and 19.4% in depth over baseline in production-scale A/B tests.
- Steerability: Instruction following increased from 59.2% to 84.8%, violations fell from 26.6% to 5.8% (78% reduction).
- Benchmark robustness: General knowledge, mathematical reasoning, and code generation metrics remained competitive, with some degradation (e.g., MBPP drop from Llama 3.1 baseline) reflecting prioritization of conversational engagement.
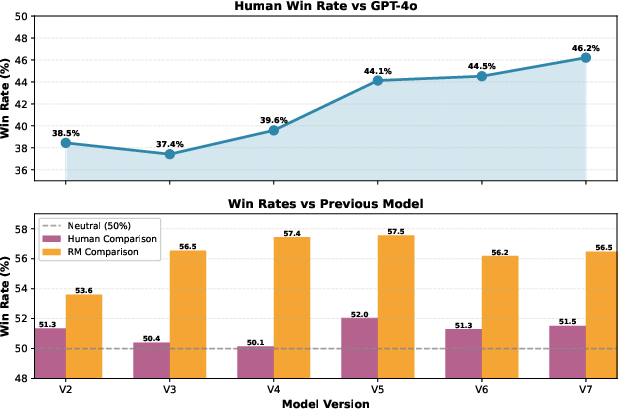
Figure 4: Pre-launch quality progression V2–V7, showing win-rate improvements against GPT-4o baseline and prior versions.

Figure 5: Benchmark score stability and convergence across nine community tasks during pre-launch iterations.
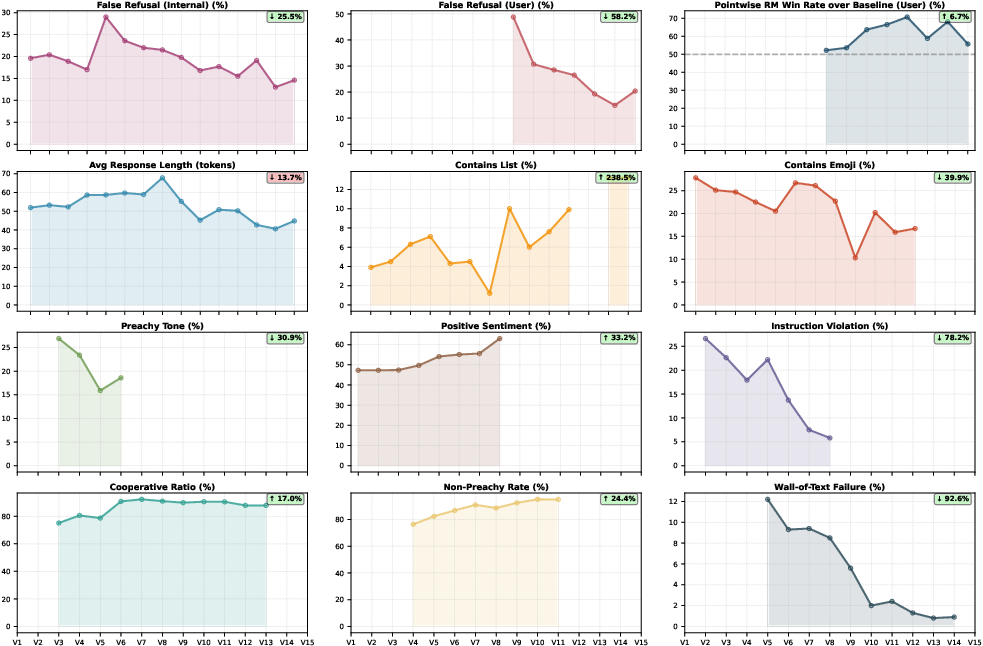
Figure 6: Evolution of false refusal, formatting, sentiment, and quality indicators V1–V15 with annotated relative changes.
The iterative optimization process exhibits self-correcting dynamics: transient spikes in negative metrics (false refusal, preachy tone, emoji overuse) are reliably resolved in subsequent iterations via targeted annotation and training recipes.
Analysis of Methodological Decisions
Explicit image generation introduced at V9 improved breadth metrics (+1.7%), while implicit image agentic generation at V10 contributed an additional +2.1%. On-policy sampling (traffic from the latest policy) for RL yielded +10.6% depth lift; GRPO loss led to +1.52% breadth lift versus online DPO. Variance-based downsampling of prompts (prioritizing high intra-prompt RM variance) prevented over-sampling easy prompts, improving robustness.
User signal models were shown unsuitable for RL due to confounding biases and reward hacking susceptibility; thus, they are used only for rejection sampling ranking.
Annotation agreement was empirically found critical for engagement modeling: multi-review consensus data provided clear improvement (+4.02 points for Pointwise RM) compared to noisy single-review data, guiding preference modeling strategy.
Practical and Theoretical Implications
CharacterFlywheel establishes an engineering paradigm for optimizing subjective engagement metrics in production-deployed LLMs. The implications are broad:
- Practically: Large-scale, multi-objective conversational AI can be systematically improved via iterative, metric-driven loops, even in the absence of deterministic reward signals.
- Theoretically: The results illuminate reward modeling dynamics, safe RL optimization in stochastic engagement landscapes, and strategies for tradeoff management between steerability, engagement, and general capabilities.
As conversational AI expands into social, entertainment, and companionship domains, empirically robust, multi-metric iterative optimization will become central. The observed self-correction dynamics also hint at adaptability in complex objective spaces.
Future Directions
Unresolved challenges include principled reward hacking detection, improved multi-turn RL formulations, and systematic generalization analysis for preference models across distributional shifts. As preference modeling matures, incorporating richer annotation signals, inter-annotator agreement, and adversarial traffic sampling may further improve convergence and stability.
Conclusion
CharacterFlywheel demonstrates that engagement-optimized conversational LLMs can achieve sustained metric improvement in real-world deployment. By integrating reward modeling, rigorous data curation, comprehensive metric tracking, and iterative fine-tuning and RL, the process reliably increases both social engagement and character steerability. The methodologies and empirical guardrails outlined serve as practical guidance for future production conversational AI systems—and provide a prototype for rigorous optimization in inherently subjective, user-centric domains.