EvoSkill: Automated Skill Discovery for Multi-Agent Systems
Abstract: Coding agents are increasingly used as general-purpose problem solvers, but their flexibility does not by itself confer the domain expertise needed for specialized tasks. Recent work addresses this through \textit{agent skills}: reusable workflows, and code, that augment agents with domain-specific capabilities. Most skills today are hand-crafted, and existing evolutionary approaches optimize low-level artifacts (e.g. prompts & code) that are tightly coupled to specific models and tasks. We introduce \textbf{EvoSkill}, a self-evolving framework that automatically discovers and refines agent skills through iterative failure analysis. EvoSkill analyzes execution failures, proposes new skills or edits to existing ones, and materializes them into structured, reusable skill folders. A Pareto frontier of agent programs governs selection, retaining only skills that improve held-out validation performance while the underlying model remains frozen. We evaluate EvoSkill on two benchmarks: OfficeQA, a grounded reasoning benchmark over U.S.\ Treasury data, where it improves exact-match accuracy by \textbf{7.3\%} (60.6\% $\to$ 67.9\%); and SealQA, a search-augmented QA benchmark with noisy retrieval, where it yields a \textbf{12.1\%} gain (26.6\% $\to$ 38.7\%). We also investigate the zero-shot transfer capabilties of skills evolved on one task to the other; in particular: skills evolved from SealQA transfers zero-shot to BrowseComp, improving accuracy by \textbf{5.3\%} without modification demonstrating that skill-level optimization produces transferable capabilities beyond the training task.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
In one sentence
The paper introduces EvoSkill, a system that helps AI “coding agents” teach themselves new, reusable skills by studying their mistakes, so they get better at tough tasks without changing their core model.
What is this paper about?
Imagine a smart assistant that can write code to solve problems. It’s flexible, but sometimes it lacks the “know-how” for specific jobs—like carefully reading complex tables or doing reliable web searches. EvoSkill is a way for that assistant to automatically discover, write down, and reuse helpful “skills” (like recipes or how-to guides with optional helper code) by learning from its own errors.
What questions did the researchers ask?
They aimed to answer:
- Can a coding agent automatically discover useful, reusable skills by analyzing where it fails?
- Will these skills actually make the agent better on challenging tasks?
- Do the learned skills transfer to new tasks without extra training?
How does EvoSkill work? (Simple version)
Think of EvoSkill like a student with a growing toolbox:
- The student takes a quiz and gets some questions wrong.
- They review what went wrong and write a short “guide” to avoid that mistake next time.
- If this guide helps on a different set of questions, it stays in the toolbox. If not, it’s tossed.
- Over time, the toolbox fills with practical, reusable guides that help the student on many quizzes—even new ones.
The three helper roles
To build these guides (skills), EvoSkill uses three AI roles:
- Executor: Tries to solve the tasks (like taking the quiz).
- Proposer: Looks at the wrong answers and explains what skill might fix the mistake (like a tutor doing error analysis).
- Skill-Builder: Turns that idea into a real “skill folder” with:
- SKILL.md: step-by-step instructions and when to use them,
- optional small helper scripts (code),
- and triggers so the agent knows when to apply the skill.
Important: The AI model itself doesn’t change (“the brain is frozen”). Only the skill library grows.
The improvement loop
- Try: Run on a batch of tasks and collect failures.
- Analyze: Proposer describes a new skill or a tweak to an existing one.
- Build: Skill-Builder creates or edits a skill folder.
- Check: Test the updated agent on a separate “validation” set (like a mini-quiz it didn’t practice on).
- Keep only the best: The system keeps a small “top list” of the best-performing versions and discards worse ones. This is like keeping a short leaderboard of strongest agents.
This repeated cycle is called “iterative failure analysis”—basically, improve by learning from mistakes.
What is a “skill” here?
A skill is a small, self-contained module the agent can reuse. It’s like a recipe card that says:
- When to trigger it,
- What steps to follow,
- Optional helper code for specific sub-tasks.
Because skills are stored in folders with clear instructions and code, they are easy to reuse, share, and transfer to other tasks.
What did they test and find?
The team tested EvoSkill on tough question-answering tasks where coding agents must read documents or search the web and return exact answers.
OfficeQA (government reports)
- Task: Answer questions by reading long U.S. Treasury bulletins filled with tables and figures.
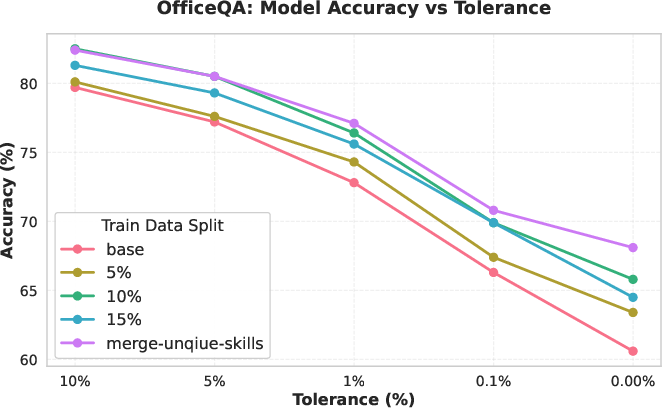
- Result: Exact-match accuracy improved from 60.6% to 67.9% (+7.3 points).
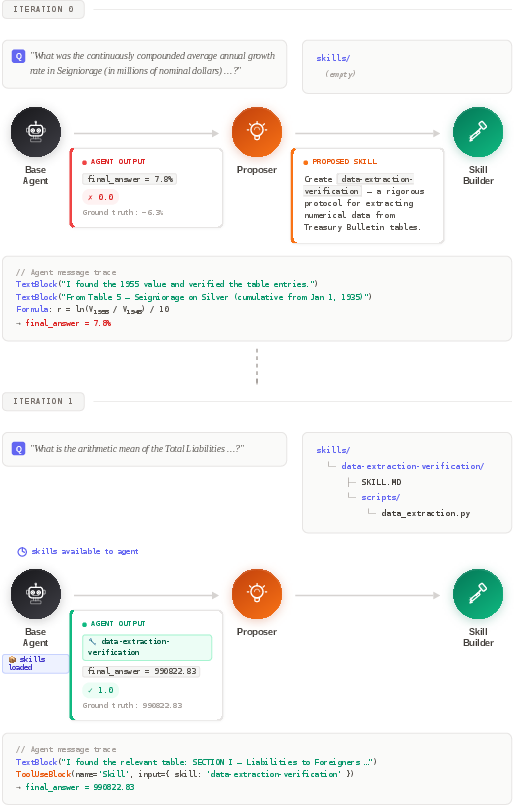
- Why it worked: EvoSkill created skills like:
- Data Extraction Verification (helps avoid reading the wrong table cell or wrong time period),
- Quantitative Analysis Methodology (checkpoints for safe financial calculations).
They also found that merging unique skills from separate runs produced the strongest result, suggesting different runs discover complementary skills.
SealQA (web searching with noise)
- Task: Answer fact questions using web search where results can be conflicting or misleading.
- Result: Accuracy improved from 26.6% to 38.7% (+12.1 points).
- Key skill discovered: A “search-persistence” protocol that:
- Expands search terms,
- Checks multiple sources,
- Avoids stopping early when results are noisy,
- Requires verifying consistency before answering.
Zero-shot transfer to BrowseComp (no extra training)
- They took the “search-persistence” skill learned on SealQA and applied it, unchanged, to BrowseComp (another web-browsing QA benchmark).
- Result: Accuracy rose from 43.5% to 48.8% (+5.3 points).
- Takeaway: Skills learned in one place can help in another without retraining—showing true transferability.
Why are these results important?
- Reusability: Instead of optimizing prompts or code for one setup, EvoSkill builds general, readable skills that can be used again and again.
- Interpretability: Skills are human-understandable recipes, not obscure tweaks. You can see what they do and when.
- Transfer: Skills work across tasks, meaning improvements don’t get “locked” to a single dataset or model.
- Efficiency: The main model stays fixed. You improve performance by growing a smarter toolbox, not by retraining the model.
Takeaway
EvoSkill shows a practical way for coding agents to “self-study”—by turning mistakes into clear, reusable skills. This makes agents better at tricky document reading and web searching and creates tools that travel well to new tasks. In the future, this approach could build shared skill libraries for many agents, speed up progress across domains, and reduce the need for costly model retraining.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list captures what remains missing, uncertain, or left unexplored, framed to enable targeted follow-up studies and engineering work:
- Model and harness generality: EvoSkill is only evaluated with Claude Code (Opus 4.5) and a specific skill-harness; assess portability to other agents and runtimes (e.g., OpenHands, DSPy, GPT-4.1, Llama), and quantify any adaptation effort.
- Statistical robustness: Results are single-run due to compute cost; conduct multi-seed experiments, report variance and confidence intervals, and test stability across different random splits.
- Validation overfitting risk: The frontier repeatedly optimizes against a fixed validation set; measure selection-induced overfitting, use nested validation or rolling/bootstrapped validation, and report generalization gaps.
- Ground-truth usage during proposal: The Proposer sees ground-truth answers to diagnose failures; quantify leakage/overfitting risks and ablate performance when proposals are generated without or with partial ground truth.
- Hyperparameter sensitivity: System performance likely depends on k (frontier capacity), T (iterations), failure thresholds (τ), training split size, and epoch count; perform sensitivity analyses and identify stable operating regimes.
- True Pareto selection: Despite claims of a Pareto frontier, selection uses a single objective (accuracy); formalize multi-objective criteria (e.g., accuracy, latency, token cost, safety) and implement genuine Pareto-based updates.
- Compute and cost accounting: Report token usage, wall-clock time, and compute per iteration; establish cost–performance curves and sample efficiency relative to baselines.
- Baselines and ablations: Compare against prompt-level evolution (e.g., GEPA), code-level evolution (e.g., AlphaEvolve), simple retry/self-refine loops, and hand-authored skills; ablate Proposer, Skill-Builder, feedback history H, and round-robin parent selection to isolate contributions.
- Scoring reliability on SealQA: Reliance on LLM-as-a-judge introduces bias; measure agreement with human judgments or deterministic gold scorers, detect reward hacking, and calibrate judge variability across models.
- Category clustering validity: Dataset partitioning uses LLM-based category assignments; evaluate clustering accuracy and its impact on stratified sampling and skill evolution compared to random or supervised partitioning.
- Skill trigger mechanisms: Define and empirically evaluate trigger precision/recall, conflict resolution when multiple skills fire, and the impact of false positives/negatives on downstream accuracy.
- Skill composition and interference: Analyze how multiple skills interact (synergy, redundancy, conflicts), quantify negative transfer, and explore automated orchestration or policy learning to resolve conflicts.
- Skill merge methodology: Current merge uses name/description matching; investigate semantic deduplication, conflict detection, and regressions introduced by merged skills; design principled merging strategies.
- Failure analysis quality: Measure the Proposer’s root-cause diagnostic accuracy, proposal acceptance rate, and diversity; explore ensembles or retrieval augmentation to improve diagnosis quality.
- Exploration strategy: Round-robin parent selection may under-explore promising branches; compare against bandit or UCB-style parent selection and evaluate exploration–exploitation trade-offs.
- Early stopping and convergence: Define formal stopping criteria, characterize convergence behavior, and detect oscillations or stagnation in frontier scores.
- Skill interpretability and maintainability: Develop metrics for clarity, auditability, and reuse; perform human evaluations of skill quality and establish best practices for versioning and lifecycle management.
- Safety and security: Helper scripts and web browsing introduce risks (prompt injection, tool misuse, data exfiltration); evaluate sandboxing, guardrails, and safety incidents, and include safety as a selection objective.
- Multi-modal extension: Provide concrete designs for integrating vision/table parsing and code–language coordination; test on multi-modal benchmarks and report modality-specific challenges.
- Transfer breadth and limits: Zero-shot transfer is shown for one skill (SealQA → BrowseComp); expand to more task pairs, directions (e.g., OfficeQA → other grounded QA), and domains, and map conditions predicting successful transfer or negative transfer.
- Cross-model transferability: Validate that evolved skills remain effective across different base models; identify model-specific adaptations needed for instructions, triggers, and scripts.
- OfficeQA evaluation detail: Report exact test set sizes, per-category performance, numeric vs textual error breakdowns, and an error taxonomy to guide targeted skill development.
- Diminishing returns diagnosis: Accuracy plateaus at 15% training split; investigate causes (overfitting, noisy failure labels, proposal saturation), test curricula, longer runs, and regularization strategies.
- Repository/process overhead: Quantify git-branching overhead, artifact size, and reproducibility trade-offs; establish policies for branch pruning and artifact retention without compromising traceability.
- Trigger learning vs authoring: Explore learning triggers via classifiers or retrieval models, compare against static metadata triggers, and quantify gains in precision/recall and downstream accuracy.
- Alternative objectives: Beyond accuracy, measure calibration, robustness to retrieval noise, step-by-step correctness, and consistency; include these in frontier selection and reporting.
- Human–AI collaboration: Compare evolved skills to expert-authored ones via user studies, and assess hybrid workflows where humans review or refine Proposer/Skill-Builder outputs.
Practical Applications
Immediate Applications
Below is a set of actionable, real-world uses that can be deployed now, leveraging EvoSkill’s skill-level evolution, failure analysis loop, and reusable skill folders.
- Finance: Treasury-grade document extraction and verification
- Application: Automate table parsing and number verification in financial bulletins, earnings reports, and regulatory filings (10-K/10-Q), reducing misreads and metric confusion.
- Sector: Finance, auditing, fintech.
- Tools/workflows: “Data Extraction Verification” skill folders triggered on table reads; frontier-based evaluation against validation sets; git-backed SkillOps pipelines.
- Assumptions/dependencies: Access to structured documents and parsers; reliable scoring functions; small labeled QA or spot-check data for failure detection; agent harness supporting skill folders (e.g., Claude Code).
- Enterprise knowledge retrieval with search persistence
- Application: Improve internal and external search workflows (wikis, policy docs, product manuals) by enforcing exhaustive search, multi-source verification, and completeness checks before answering.
- Sector: Software, customer support, enterprise IT.
- Tools/workflows: “Search-Persistence-Protocol” skill; browser/builder plugins for agents; validation dashboards to monitor answer quality.
- Assumptions/dependencies: Web or intranet retrieval tooling; basic ground-truth or adjudication process; LLM-as-judge only where acceptable.
- Compliance and regulatory reporting assistants
- Application: Cross-document consistency checks, unit normalization, and date alignment for compliance submissions (SOX, Basel III, SEC, ESG).
- Sector: Finance, policy/government, compliance.
- Tools/workflows: Triggered verification skills on numeric extraction and cross-references; audit trails via git branch lineage; Pareto-frontier selection for best-performing skill sets.
- Assumptions/dependencies: Access to canonical sources; privacy/security controls; clear scoring criteria; acceptance of frozen model with evolving skills.
- Customer support and helpdesk answer quality
- Application: Reduce premature or incorrect answers on ambiguous tickets by mandating multi-source verification and term interpretation checks.
- Sector: Software, telecoms, e-commerce.
- Tools/workflows: Search persistence skills integrated with support KBs; automatic failure logging and skill refinement on misresolved tickets; skill-merge to capture complementary capabilities across teams.
- Assumptions/dependencies: Ticket resolution ground truth or supervisor labels; integration with support platforms; modest compute for evolution loops.
- Academic literature review and synthesis
- Application: Strengthen reference validation and completeness checks when summarizing papers, claims, or meta-analyses; enforce citation accuracy and numerical consistency.
- Sector: Academia, R&D.
- Tools/workflows: Review skills that trigger on citation or quantitative claims; held-out validation sets built from known abstracts/outcomes; zero-shot transfer to new subfields.
- Assumptions/dependencies: Access to bibliographic databases; clear correctness criteria; minimal labeled sets for failure analysis.
- EdTech: Quantitative problem-solving assistants
- Application: Enforce structured methodology for calculations (risk, forecasting, conversions, statistical checks) to reduce systematic errors in homework and tutoring scenarios.
- Sector: Education.
- Tools/workflows: “Quantitative Analysis Methodology” skills; course-specific validation sets; teacher dashboards for skill performance.
- Assumptions/dependencies: Curriculum-aligned data and rubrics; safe browsing policies; parental/educational privacy constraints.
- Software engineering agent CI for documentation and analytics
- Application: Agents that read logs, dashboards, or internal metrics with verification gates before reporting KPI changes or incident summaries.
- Sector: Software/DevOps.
- Tools/workflows: SkillOps CI/CD integrated with git; round-robin frontier exploration on validation metrics; skill provenance logging.
- Assumptions/dependencies: Access to internal metrics; correctness criteria (alerts, thresholds); buy-in for agent governance.
- Public sector data Q&A (FOIA and records requests)
- Application: Agents answering questions over government bulletins with strict verification, reducing time-to-answer and increasing transparency.
- Sector: Policy/government.
- Tools/workflows: Document-grounded skills (table extraction checks, unit normalization, date alignment); controlled evaluation sets; auditable skill lineage.
- Assumptions/dependencies: Document availability; public-sector security and compliance; measurable QA correctness.
- Personal web browsing assistants
- Application: Browser copilots that avoid hasty conclusions on conflicting sources (shopping comparisons, travel planning, home finance research).
- Sector: Daily life, consumer software.
- Tools/workflows: Search-persistence skill embedded in browser agents/extensions; lightweight validation via personal preferences or known facts.
- Assumptions/dependencies: Agent integration with browser; acceptable latency for extra search steps; user consent for data handling.
- Skill library management and sharing within organizations
- Application: Create internal “skill marketplaces” where teams publish, merge, and reuse evolved skills; skill-merge shown to yield complementary gains.
- Sector: Cross-industry.
- Tools/workflows: Git-backed repositories; metadata-rich SKILL.md; automated frontier selection; tagging for domain and trigger conditions.
- Assumptions/dependencies: Skill specification adherence; permissions and provenance tracking; compatibility with multiple agent harnesses.
Long-Term Applications
These opportunities require further research, scaling, interoperability, or regulatory development before broad deployment.
- Cross-model, cross-harness skill marketplaces
- Application: Interoperable skill distribution platforms (“SkillHub”) where reusable capabilities transfer across models and agent frameworks.
- Sector: Software, platform ecosystems.
- Tools/workflows: Standardized skill triggers, signing/provenance, semantic compatibility layers; marketplace curation and ranking.
- Assumptions/dependencies: Broad adoption of skill specifications; versioning and safety vetting; sustainable incentives for publishers.
- Multi-modal skill induction (vision + language + code)
- Application: Evolving skills that coordinate OCR/table-vision parsing with numerical verification for PDFs, charts, and scans (e.g., healthcare imaging reports, scientific figures).
- Sector: Healthcare, finance, legal, scientific publishing.
- Tools/workflows: Multi-modal parsers; visual-grounding validation; frontier evaluation on mixed-modal held-out sets.
- Assumptions/dependencies: High-quality multi-modal models; domain-specific privacy and compliance (e.g., HIPAA); reliable scoring across modalities.
- Healthcare clinical protocol enforcement and EHR retrieval
- Application: Agents that verify drug dosages, lab interpretations, and guideline conformance via evolved verification skills.
- Sector: Healthcare.
- Tools/workflows: Triggered clinical verification skills; audit trails; integration with EHR systems; human-in-the-loop oversight.
- Assumptions/dependencies: Regulatory approval; robust de-identification; gold-standard clinical ground truth; liability and safety frameworks.
- Autonomous RPA with failure-driven skill evolution
- Application: Back-office process agents (invoice reconciliation, procurement checks, policy compliance audits) that evolve domain skills from observed errors.
- Sector: Enterprise operations, finance, supply chain.
- Tools/workflows: Continuous SkillOps pipelines; process-specific validation suites; change management and fallbacks.
- Assumptions/dependencies: Stable interfaces/APIs; labeled failures; governance for automated changes; integration with legacy systems.
- Robotics and embodied agents: skill-level transfer from textual tasks
- Application: Use feedback descent to evolve interpretable procedural skills (checklists, validation gates) that coordinate sensing, planning, and action.
- Sector: Robotics, manufacturing, logistics.
- Tools/workflows: Mapping textual skills to low-level controllers; simulation-to-real validation; frontier selection on task success rates.
- Assumptions/dependencies: Reliable grounding from text to control; safety certification; extensive evaluation infrastructure.
- Skill governance, safety, and provenance standards
- Application: Policy frameworks for auto-generated skills (signing, review, revocation, auditability) to prevent harmful or deceptive behaviors.
- Sector: Policy/regulation, platform governance.
- Tools/workflows: Skill signing and version control; risk tiers; mandatory eval suites; transparent lineage metadata.
- Assumptions/dependencies: Regulator and industry consensus; interoperability across vendors; clear compliance criteria.
- Model-agnostic agent improvement in resource-constrained settings
- Application: Organizations with frozen or fixed models achieve sustained gains by evolving skills, not parameters.
- Sector: Public sector, SMBs, regulated industries.
- Tools/workflows: Lightweight evaluation sets; iterative frontier loops; cross-task transfer libraries.
- Assumptions/dependencies: Enough labeled or adjudicated failures; predictable task distributions; compatible agent harnesses.
- Curriculum-aware education skills and fairness-aware evaluation
- Application: Evolve reusable, interpretable tutoring skills that adapt across subjects while tracking fairness, accessibility, and bias mitigation.
- Sector: Education.
- Tools/workflows: Curriculum-aligned evals; skill transfer across grades; safety filters for pedagogical appropriateness.
- Assumptions/dependencies: High-quality educational datasets; fairness metrics; stakeholder oversight.
- Energy and infrastructure analytics
- Application: Verify and synthesize grid reports, emissions data, and capacity planning documents with structured numerical skills.
- Sector: Energy, climate tech.
- Tools/workflows: Domain-tailored extraction/verification skills; multi-source reconciliation; audit-ready trails.
- Assumptions/dependencies: Access to public and private datasets; domain-specific units and standards; evaluators for correctness.
- “Frontier Manager” and enterprise SkillOps suites
- Application: Productizing EvoSkill’s loop into turnkey enterprise platforms that manage frontier selection, skill evolution, validation, and deployment.
- Sector: Software tooling.
- Tools/workflows: CI/CD for agent skills; dashboards for performance deltas; automated rollback and canary deployment of skills.
- Assumptions/dependencies: Organizational maturity in agentops; consistent evaluation pipelines; change control policies.
Common assumptions and dependencies across applications
- Requires an agent harness that supports skill folders (metadata, SKILL.md, helper scripts) and can trigger skills by context.
- Needs task-appropriate scoring or adjudication (numeric tolerance, textual match, or LLM-as-judge with safeguards).
- Depends on failure visibility (execution traces, incorrect predictions) and small but representative validation sets.
- Compute and cost constraints for iterative evolution (particularly with high-end models like Opus 4.5).
- Skill interoperability and governance (metadata standards, provenance, safety review) influence adoption in regulated domains.
Glossary
- Adversarial retrieval conditions: Retrieval setting where search results are conflicting, noisy, or misleading, making evidence gathering harder for agents. "under adversarial retrieval conditions."
- Agent Skills specification: An open format that standardizes how modular, reusable skills are packaged and shared for agents. "the Agent Skills specification has formalized skills as a portable, open format:"
- Artifact optimization: Improving low-level artifacts like prompts or code directly, as opposed to higher-level capabilities or skills. "applying textual feedback descent to the problem of skill discovery rather than artifact optimization."
- Embodied AI: AI systems that act within environments (e.g., robotics or simulated worlds) and learn skills via interaction. "both embodied AI and software engineering."
- Frontier-based selection: A selection mechanism that maintains a set of top-performing candidates and updates it as new candidates are evaluated. "supports efficient frontier-based selection."
- Fuzzy scoring function: A grading method that allows partial or tolerance-based matches rather than strict exact matches. "We use the fuzzy scoring function provided by OfficeQA"
- Grounded reasoning: Reasoning that requires tying answers directly to evidence in a specified corpus or data source. "a grounded reasoning benchmark over U.S.\ Treasury data"
- Held-out test set: A dataset split reserved exclusively for final evaluation, never seen during training or selection. "a held-out test set comprising the remaining questions"
- Held-out validation set: A dataset split used for model or program selection during development, separate from training data. "held-out validation set "
- LLM-as-a-judge: Using a LLM to automatically grade or evaluate outputs instead of human annotators. "We use the default LLM-as-a-judge template"
- Multi-modal tasks: Tasks that require processing and coordinating multiple data modalities, such as text, code, and images. "multi-modal tasks where skills may need to coordinate across vision, code, and language"
- Pareto frontier: The set of candidates that are not dominated across multiple objectives; improving one objective would worsen another. "A Pareto frontier of agent programs governs selection"
- Pareto-based candidate selection: Choosing candidates using Pareto efficiency principles across competing evaluation metrics. "Pareto-based candidate selection"
- Progressive disclosure: A design where metadata is preloaded while detailed instructions or scripts are accessed only when needed to reduce context load. "leverage progressive disclosure: metadata is loaded at startup, instructions are read on demand, and scripts are executed without entering the context window"
- Round-robin cycling: An even, cyclic scheduling method that iterates through candidates in order before repeating. "via round-robin cycling"
- Search-augmented LLMs: LLMs that incorporate web or document search to retrieve evidence before answering. "evaluating search-augmented LLMs on fact-seeking questions"
- Search-augmented QA: Question answering enhanced by search to gather external evidence, often in noisy or conflicting settings. "a search-augmented QA benchmark with noisy retrieval"
- Semantic similarity: A retrieval or matching approach based on meaning rather than exact token overlap. "retrieved by semantic similarity."
- Skill folders: Structured skill packages containing metadata, instructions, and optional helper code that agents can load and reuse. "structured, reusable skill folders"
- Skill-merge configuration: An approach that combines unique skills discovered across runs into a single library for improved performance. "The skill-merge configuration, which combines unique skills from independent runs, achieves the highest exact-match accuracy (67.9%)"
- Stratified partitioning: Data splitting that preserves the distribution of categories across training, validation, and test sets. "We then perform stratified partitioning into three disjoint subsets"
- Textual feedback descent: An optimization approach where iterative natural-language feedback is used to guide improvements. "applying textual feedback descent to examples where the current agent fails."
- Tree-structured search: Exploring candidate configurations as nodes in a tree, capturing lineage and enabling efficient rollbacks. "This design yields a tree-structured search over program space"
- Vector database: A database that indexes and retrieves items using vector embeddings for similarity search. "stored as programs in a vector database"
- Weighted tolerance levels: Evaluation that aggregates scores over multiple error tolerances with weights favoring stricter thresholds. "a weighted average over five tolerance levels"
- Zero-shot transfer: Applying a learned capability to new tasks without additional training or adaptation. "transfers zero-shot to BrowseComp"
Collections
Sign up for free to add this paper to one or more collections.

