SWE-CI: Evaluating Agent Capabilities in Maintaining Codebases via Continuous Integration
Abstract: LLM-powered agents have demonstrated strong capabilities in automating software engineering tasks such as static bug fixing, as evidenced by benchmarks like SWE-bench. However, in the real world, the development of mature software is typically predicated on complex requirement changes and long-term feature iterations -- a process that static, one-shot repair paradigms fail to capture. To bridge this gap, we propose \textbf{SWE-CI}, the first repository-level benchmark built upon the Continuous Integration loop, aiming to shift the evaluation paradigm for code generation from static, short-term \textit{functional correctness} toward dynamic, long-term \textit{maintainability}. The benchmark comprises 100 tasks, each corresponding on average to an evolution history spanning 233 days and 71 consecutive commits in a real-world code repository. SWE-CI requires agents to systematically resolve these tasks through dozens of rounds of analysis and coding iterations. SWE-CI provides valuable insights into how well agents can sustain code quality throughout long-term evolution.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces SWE-CI, a new way to test how well AI coding assistants (powered by LLMs) can take care of real software projects over time. Instead of checking if an AI can fix a single bug once, SWE-CI checks if an AI can keep a codebase healthy as it changes week after week—like maintaining a garden, not just planting one tree.
What questions did the researchers ask?
The researchers focused on simple, practical questions:
- Can AI coding agents handle long-term software changes, not just one-off fixes?
- Can they plan and make improvements step by step without breaking things that already work?
- How do we measure “good maintenance,” not just “passes the test right now”?
How did they study it?
They built a benchmark (a test system) called SWE-CI that mimics how real software teams work with continuous integration (CI). Think of CI as a loop: make a change → run tests → fix problems → repeat.
Here’s the approach in everyday terms:
- Real projects and real history: They gathered 100 real-world Python code “stories” from GitHub. Each story covers about 233 days and 71 commits (code updates) between a “starting version” and a “goal version.”
- Same kitchen every time: They used Docker (a tool that creates identical computer setups) so the software runs the same way for everyone—like baking in the same kind of oven every time.
- Two AI roles working together:
- Architect: reads failing tests, writes a short, high-level plan for what needs to change next (no more than 5 items per round).
- Programmer: reads the plan and edits the code to meet those goals.
- They repeat this loop up to 20 times, just like a real team doing small, frequent updates.
- Smarter scoring than pass/fail:
- Normalized change: a progress meter from −1 to 1 that shows whether the code is getting better (more tests pass) or worse (things that used to pass now fail). It’s like tracking if your group project is moving forward or slipping back.
- EvoScore: a final score that values later rounds more than early ones. Why? Good design should make future changes easier. It’s like grading a semester project where the later milestones count more because they show whether your early decisions were smart.
What did they find?
- Newer models are getting better: Across many AI models, newer versions generally performed better at long-term maintenance than older ones. Progress is real—not just at fixing one bug, but at keeping code healthy over time.
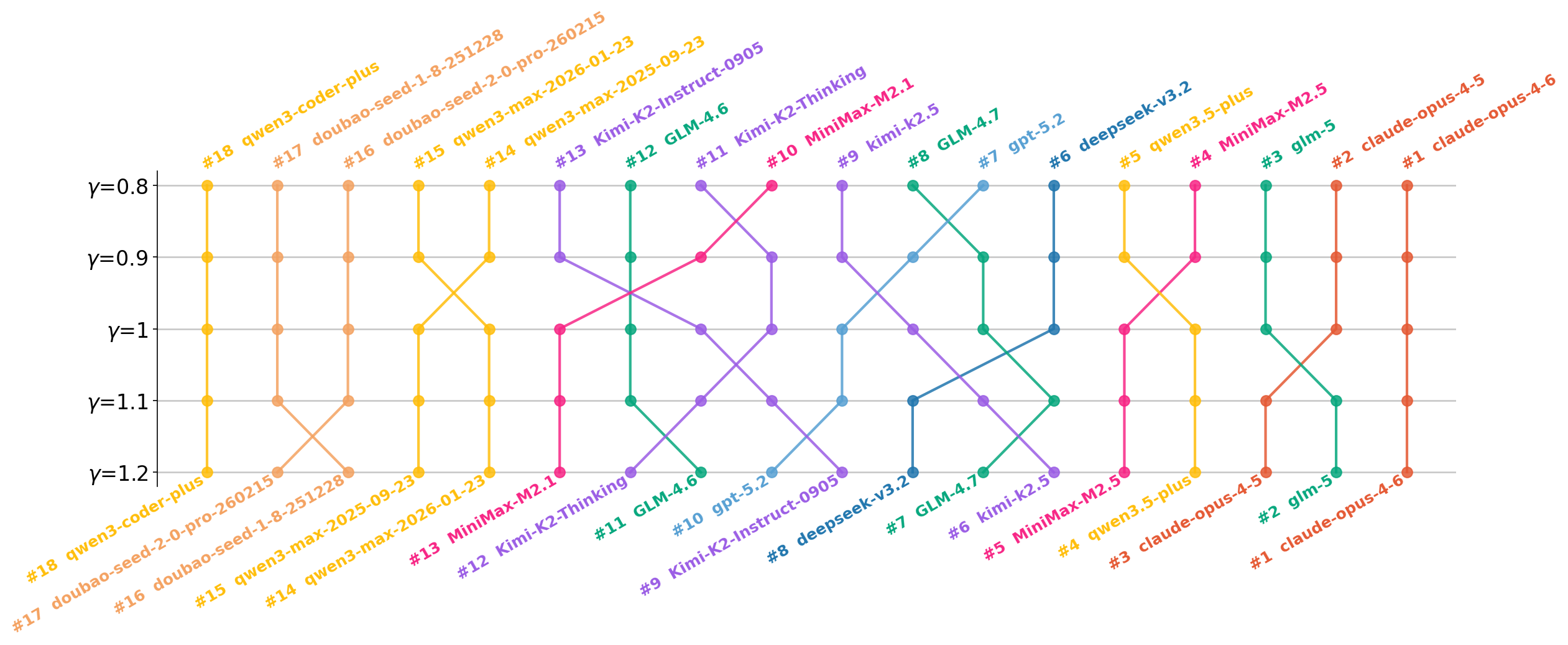
- Different “styles” across providers: Some models chased quick wins early on; others did steadier work that held up better in later rounds. When the scoring favored long-term stability, rankings shifted—showing that training choices affect how a model balances short-term vs. long-term thinking.
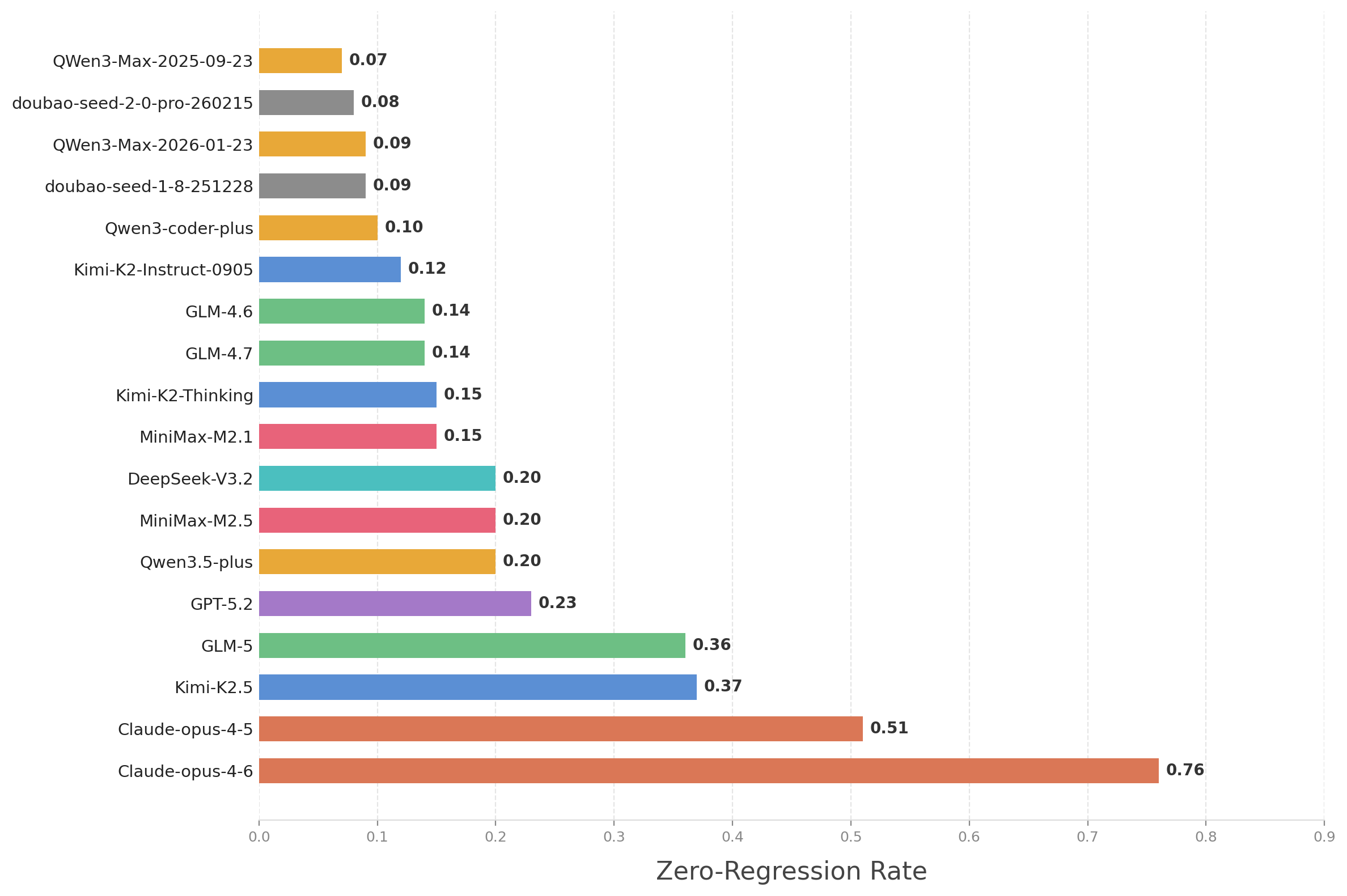
- Regressions are a big problem: A “regression” is when something that used to work breaks after a change—like fixing a bike chain and accidentally messing up the brakes. Most models struggled to avoid regressions over many rounds. For many, the “zero-regression rate” (no breakages across all rounds) was below 25%, and only a couple did better than 50%. This shows that keeping code stable over time is still hard for AI agents.
Why this matters: In real software, breaking existing features is costly and frustrating. Avoiding regressions is a core skill for maintainers—not just getting new features to work.
Why does it matter?
- Closer to real life: SWE-CI tests what actually happens in mature software: updates, refactors, new features, and the need to keep old things working. This is a step beyond “did it pass the test once?”
- Better training targets: By measuring long-term maintainability (with EvoScore) instead of just short-term correctness, researchers can train AI agents to write cleaner, more future-friendly code.
- Safer automation: If AI can avoid regressions and plan ahead, teams can trust it more for real work—speeding up development without sacrificing quality.
- A new benchmark for progress: SWE-CI gives the community a common, realistic way to see which models are truly good at maintaining software over time, not just solving one-off tasks.
In short: This paper shifts the goal from “fix it now” to “keep it healthy,” and provides tools and data to push AI coding assistants in that direction.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, to guide future research.
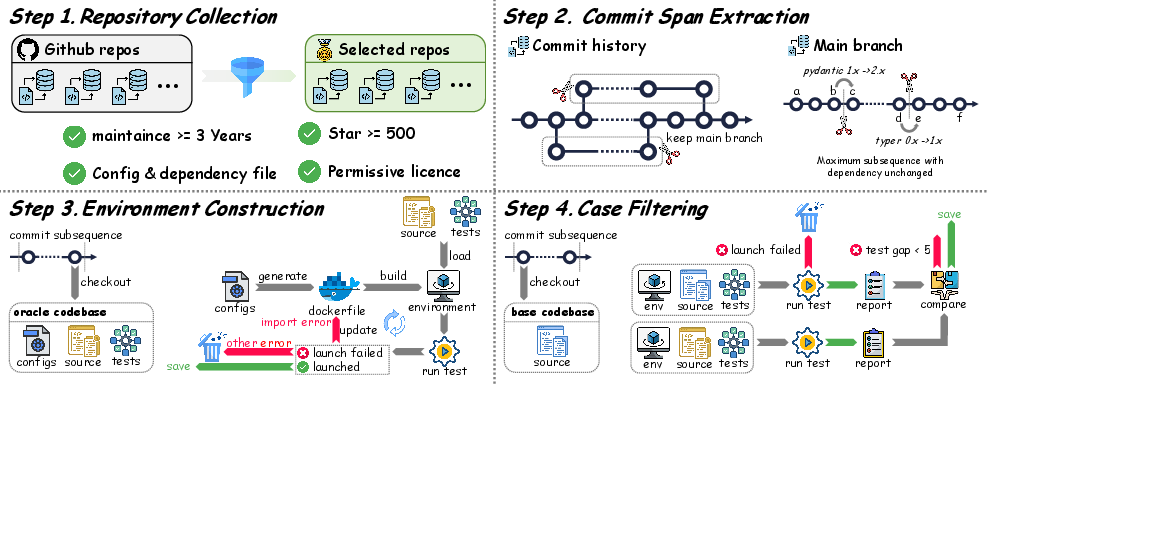
- Language and ecosystem coverage: The benchmark only targets Python; it is unknown whether results generalize to other languages (e.g., Java, C/C++, JavaScript, Rust) with different build systems, dependency managers, and CI conventions.
- Dependency evolution is intentionally excluded: Commit spans are restricted to unchanged dependencies, while “self-repair” may inject missing deps. Real-world maintenance frequently involves dependency upgrades/downgrades and transitive API changes; support for such scenarios is currently absent.
- Dataset representativeness: The ≥500 stars and ≥3-year activity filters bias toward popular, mature open-source projects; it is unclear if findings hold for small/medium repos, enterprise/private codebases, or domain-specific software.
- Task diversity: Selecting pairs with ≥1000 non-test LoC changes and long time spans emphasizes large evolutions; small-scale maintenance tasks (minor bug fixes, refactors, configuration tweaks) are underrepresented.
- Test-only objective: The benchmark equates progress with passing oracle tests; maintainability dimensions beyond functional correctness (e.g., complexity, cohesion, duplication, readability, type errors, lint violations) are not captured.
- Metric validation: The paper does not validate whether EvoScore correlates with human judgments of maintainability or independent static-quality metrics; external validity of the metric remains unproven.
- Gamma choice ambiguity: EvoScore is defined with but later analyses explore , creating inconsistency; no principled procedure is provided for choosing , nor a sensitivity analysis across tasks.
- Normalized change edge cases: The piecewise definition assumes when normalizing regressions; behavior when the base passes zero tests (division by zero) is unspecified.
- Regression measurement clarity: The “zero-regression rate” is introduced without formal definition of counting rules (e.g., transient vs persistent failures, per-iteration windows), and no confidence intervals are reported.
- Flaky/nondeterministic tests: The benchmark does not discuss detecting or mitigating flakiness (reruns, quarantine policies), which threatens reliability of EvoScore and regression metrics.
- Environment self-repair effects: The automatic dependency injection in Dockerfiles may alter intended environments; the frequency, criteria, and downstream bias introduced by this mechanism are not quantified or audited.
- Agent-test execution policy: Prohibiting agents from running tests (TDD loop) deviates from developer practice; the impact of allowing agent-initiated test runs on maintainability outcomes is unexplored.
- Dual-agent protocol ablations: The influence of the Architect–Programmer split, requirement granularity (1–5 items), and cross-model pairing on performance remains unstudied; no comparison with single-agent or alternative workflows.
- Tooling and static analysis: The evaluation omits or does not standardize use of linters, formatters, type checkers, static analyzers, or refactoring tools; benefits of tool-augmented agents are unmeasured.
- Context management and retrieval: The paper does not specify how agents ingest large repositories (context windows, retrieval strategies, chunking); effects on fairness and performance across models with different context capacities are unclear.
- Evaluation fairness and reproducibility: Decoding parameters (temperature, top‑p), token budgets per iteration, and stop criteria are not fully disclosed; stochasticity, multiple runs, and statistical significance tests are missing.
- Data contamination risk: Many benchmark repositories are public and likely included in LLM pretraining; the extent of training-test leakage is unquantified, and “post-cutoff” or held-out histories are not used to control for contamination.
- Integration and system tests: The focus is on unit tests; scenarios involving databases, networked services, external systems, or multi-process setups (common in CI) are largely excluded.
- CI realism gaps: Elements like code review, style checks, merge conflicts, branching strategies, and PR feedback loops are not modeled; their impact on agent maintainability performance is unknown.
- Human baseline absent: No expert developer runs or curated baselines are provided to contextualize task difficulty or to calibrate EvoScore against human maintenance pathways.
- Overfitting to tests: With oracle tests as the sole arbiter, agents may “program to the tests” via brittle implementations; there is no evaluation on unseen, held‑out future tests to assess generalization beyond the given suite.
- Iterations vs evolution length: Real commit spans average 71 commits, but iterations are capped at 20; mapping between real-world commit increments and benchmark iterations is unspecified, possibly underestimating long-term effects.
- Cross-task comparability: Although normalized change is used, heterogeneity in test suite quality/coverage across repositories may still confound comparability; per-task metadata and calibration are not reported.
- Security/performance regressions: The benchmark does not track security issues, resource usage, or performance regressions—important aspects of maintenance in CI.
- Dataset transparency: Detailed per-task metadata (e.g., categories of changes, failure modes, environment self-repair logs, test coverage deltas) are not provided, limiting diagnostic utility and secondary analyses.
- Documentation and non-code assets: Maintenance involving documentation, packaging, and configuration (beyond tests) is currently out-of-scope; their inclusion and evaluation criteria are unspecified.
- Mathematical/notation clarity: Minor inconsistencies/typos in equations and the policy reduce precision; a formal, unambiguous spec for all metrics and edge cases is needed.
Practical Applications
Overview
Based on the paper’s benchmark, metrics, and dual-agent workflow, the following applications translate its contributions into deployable tools and forward-looking opportunities across industry, academia, policy, and everyday practice.
Immediate Applications
- Bold model selection for maintainability under CI (software/DevTools)
- Use case: Evaluate and compare LLM coding agents for internal deployment using SWE-CI’s repository-level tasks and EvoScore to choose models that minimize regressions over iterations, not just one-shot test passes.
- Tools/workflows: SWE-CI harness + Dockerized repos + pytest; integrate into GitHub Actions/GitLab CI for periodic bake-offs between models.
- Assumptions/dependencies: Access to candidate LLMs and sufficient token budget; target projects have usable test suites; Python-first scope.
- CI regression sentinel driven by normalized change and zero-regression rate (DevOps/QA)
- Use case: Monitor pull requests and iterative changes with normalized change a(c) and track a “zero-regression rate” KPI; gate merges when a regression threshold is exceeded.
- Tools/workflows: Lightweight CI plugin that captures baseline test pass counts, computes normalized change per run, and reports dashboards.
- Assumptions/dependencies: Stable/representative tests; reproducible CI environments (Docker); acceptance of new KPIs in quality gates.
- Dual-agent “Architect–Programmer” triage bot for failing tests (software engineering, open source)
- Use case: When CI fails, an Architect agent produces a concise, high-level requirement XML from failing tests; a Programmer agent drafts a patch; human reviews and merges.
- Tools/workflows: Adopt the provided prompts; run as a GitHub App that comments on failing builds with requirement.xml and PR patches.
- Assumptions/dependencies: Human-in-the-loop review; LLM access; adequate repository context windows; adherence to policy forbidding test edits.
- Maintainability-aware developer productivity dashboards (engineering management/DevEx)
- Use case: Display EvoScore-like trends and zero-regression rates across sprints to complement throughput metrics (e.g., lead time, PR cycle time).
- Tools/workflows: CI data warehouse + small service that aggregates normalized change over iterations; Grafana dashboards.
- Assumptions/dependencies: Consistent test execution; teams accept long-term quality metrics alongside velocity.
- Curriculum and labs for TDD/CI with evolution focus (education)
- Use case: Instructional modules that show how small design choices compound over iterations using SWE-CI tasks; students run architect–programmer iterations to observe maintainability effects.
- Tools/workflows: Classroom Docker images; prebuilt tasks from the SWE-CI dataset; assignments emphasizing regression control and incremental delivery.
- Assumptions/dependencies: Course infrastructure supports Docker; trained instructors; students have machine time to run tests.
- Research benchmarking for long-term code evolution (academia)
- Use case: Study agent planning, regression control strategies, or tool-use policies using SWE-CI; replicate and extend model comparisons with different γ weightings in EvoScore.
- Tools/workflows: Experimental harness + iFlow CLI agents; ablation pipelines for prompt variants and tool stacks.
- Assumptions/dependencies: Compute budgets for multi-iteration test runs; careful environment pinning to avoid flakiness.
- Procurement/RFP criteria that include maintainability metrics (policy + enterprise IT)
- Use case: Buyers specify benchmarks like SWE-CI/EvoScore to evaluate vendor-provided coding copilots or agents, ensuring long-term stability emphasis.
- Tools/workflows: RFP templates citing normalized change, zero-regression rate, and future-weighted evaluation requirements.
- Assumptions/dependencies: Vendor willingness to run standardized evaluations; legal/IT acceptance of open-source benchmark content.
- Nightly open-source maintainer bots (open source communities)
- Use case: Run the dual-agent loop on nightly CI to identify failing tests/regressions and open targeted PRs with clear requirement rationale.
- Tools/workflows: GitHub Actions scheduled runs + labelers; auto-generated requirement.xml and PRs; maintainer review.
- Assumptions/dependencies: Projects have clear tests and permissive policies for bot PRs; LLM quotas.
- Reproducible environment harness for historical bug replay (DevOps/QA)
- Use case: Use the paper’s Docker-based environment construction to reproduce historical test states and investigate evolution-induced failures.
- Tools/workflows: Automated Dockerfile generation from pyproject/lockfiles; baseline and target commit snapshots.
- Assumptions/dependencies: Dependency availability in registries; Python dependency resolution; network access for builds.
- Test-suite health tracking using normalized change (QA)
- Use case: Identify brittle or under-specified tests by observing disproportionate regressions relative to lines changed and evolutions attempted.
- Tools/workflows: CI-side module that correlates change sets with normalized test impacts; reports flaky vs robust test pools.
- Assumptions/dependencies: Sufficient iteration data for signal; consistent test determinism.
Long-Term Applications
- Autonomous maintainers integrated into CI/CD (software/cloud)
- Use case: Multi-agent systems (architect–programmer–reviewer–tester) that evolve codebases over months with regression budgets and long-term maintainability targets.
- Tools/workflows: Expanded agent roles, policy engines for regression gating, structured artifacts (requirements XML, design notes), human oversight at defined risk thresholds.
- Assumptions/dependencies: Further model gains in zero-regression rates; stronger code understanding; robust audit trails.
- LLMs trained for maintainability with EvoScore-based reinforcement (AI research/model providers)
- Use case: Optimize agents with future-weighted rewards that penalize technical debt and regressions, yielding maintainable-by-design models.
- Tools/workflows: RLHF/RLAIF pipelines using EvoScore; curriculum training on evolution tasks; regression-focused synthetic data.
- Assumptions/dependencies: Scalable training infra; high-fidelity simulators for long horizons; careful reward shaping.
- Standards and regulation embedding maintainability metrics (policy/standards bodies)
- Use case: Update software quality standards and AI coding tool certifications to include evolution-based metrics aligned with ISO/IEC 25010 principles.
- Tools/workflows: Conformance test suites that measure normalized change and zero-regression rates across staged iterations.
- Assumptions/dependencies: Consensus among stakeholders; mechanisms to certify third-party tools; legal alignment across jurisdictions.
- Cross-language and domain expansion of SWE-CI (software vendors, embedded/mobile)
- Use case: Java/TypeScript/C++/mobile/embedded variants with language-appropriate build systems and test frameworks; ROS/robotics and data/ML pipelines.
- Tools/workflows: Dataset curation pipelines for other ecosystems; containerized build/test toolchains; language-specific agent prompts.
- Assumptions/dependencies: Sufficient open-source repos with tests; deterministic builds in non-Python ecosystems; specialized tooling.
- Predictive CI gating using future-weighted risk estimation (DevOps/ML)
- Use case: Learn models that forecast the long-term regression risk of a change; gate merges by predicted impact on future test evolution (γ-weighted).
- Tools/workflows: Historical CI logs + metadata; risk models trained on normalized change trajectories; policy plug-ins for GitHub/Jenkins/GitLab.
- Assumptions/dependencies: Rich historical data; generalization across projects; acceptance of probabilistic gates.
- Security and dependency-maintenance bots with stability guarantees (DevSecOps)
- Use case: Agents that continuously upgrade dependencies and patch vulnerabilities while optimizing for minimal regressions and maintainability.
- Tools/workflows: Integrations with Dependabot/Renovate; maintainability-aware patch planning; sandbox validation with evolution tests.
- Assumptions/dependencies: Reliable vulnerability feeds; reproducible tests; robust rollback strategies.
- Project health and technical debt analytics from evolution metrics (product/PM tools)
- Use case: Longitudinal dashboards that infer technical debt via declining normalized change or EvoScore across releases; prioritize refactoring.
- Tools/workflows: Data pipeline from CI to analytics; heuristics tying regression patterns to architecture hotspots.
- Assumptions/dependencies: Consistent instrumentation; organizational buy-in to act on insights.
- IDE guidance for evolvable designs (developer tooling)
- Use case: Code assistants that suggest design choices likely to preserve future maintainability under evolving tests and interfaces.
- Tools/workflows: IDE plugins that simulate “micro-evolutions” or consult learned heuristics; inline hints and refactor proposals.
- Assumptions/dependencies: Real-time analysis cost budgets; trained models with maintainability priors; developer trust.
- Regulated-sector AI-in-the-loop pipelines with auditable CI artifacts (healthcare/finance)
- Use case: Architect–programmer agents propose changes with explicit requirement XMLs, acceptance criteria, and traceability, meeting compliance needs.
- Tools/workflows: Signed artifacts, approval workflows, structured logs tying requirements to tests; compliance attestation using maintainability KPIs.
- Assumptions/dependencies: Strong governance, model validation, and data security controls; regulatory acceptance.
- Continual-learning repo-aware agents (AI/DevOps)
- Use case: Agents adapt to a repository’s evolving style guides and architecture using feedback from repeated CI iterations over long horizons.
- Tools/workflows: Feedback loops ingesting CI outcomes, code review comments, and test histories; on-policy updates with safety constraints.
- Assumptions/dependencies: Safe online learning mechanisms; drift detection; guardrails against catastrophic forgetting.
- Community/SMB hosted maintainability evaluation service (SaaS/SMB)
- Use case: Turnkey cloud service that runs periodic SWE-CI-style evaluations on a customer’s repos and provides recommendations to improve maintainability.
- Tools/workflows: Multi-tenant runner fleet; dashboards; integration apps for GitHub/GitLab/Bitbucket.
- Assumptions/dependencies: Privacy/security assurances; cost-effective test execution; customer test maturity.
Notes on cross-cutting dependencies:
- High-quality, representative unit tests are a foundational prerequisite.
- Reproducible environments (e.g., Docker) are essential to obtain reliable metrics.
- Current LLMs’ regression control is imperfect; high-stakes or fully autonomous scenarios require human oversight and stricter gates.
- The paper’s dataset and prompts are Python-centric; broader adoption will require language and ecosystem extensions.
Glossary
- Acceptance criteria: Concrete conditions that verify whether a change meets its intended goals. "Detail the acceptance criteria that can verify whether this code change is successful."
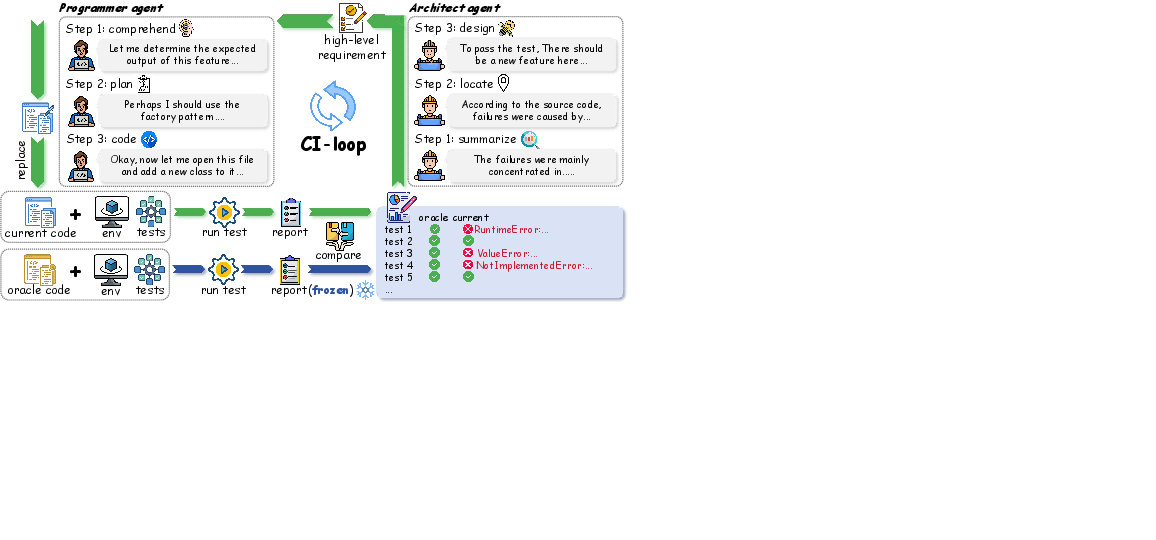
- Architect--Programmer dual-agent evaluation protocol: A two-agent workflow where one agent defines requirements and the other implements changes to simulate CI. "SWE-CI employs an Architect--Programmer dual-agent evaluation protocol: starting from the base commit, the agents execute a CI-loop that iteratively generates requirements, modifies source code, and runs tests"
- base commit: The starting point in a repository’s history from which evolution begins in a task. "SWE-CI comprises 100 tasks, each defined by a base commit and a target commit from a real-world repository"
- behavioral contracts: High-level, testable descriptions of expected software behavior used to guide implementation. "You MUST focus on behavioral contracts and verifiable results, and avoid providing specific code implementations."
- CI-loop: An iterative process of requirement generation, coding, and testing in continuous integration. "the agents execute a CI-loop that iteratively generates requirements, modifies source code, and runs tests"
- Dockerfile: A specification file that defines the environment and dependencies for building a containerized runtime. "we automatically generate a Dockerfile based on the configuration and dependencies of the oracle codebase"
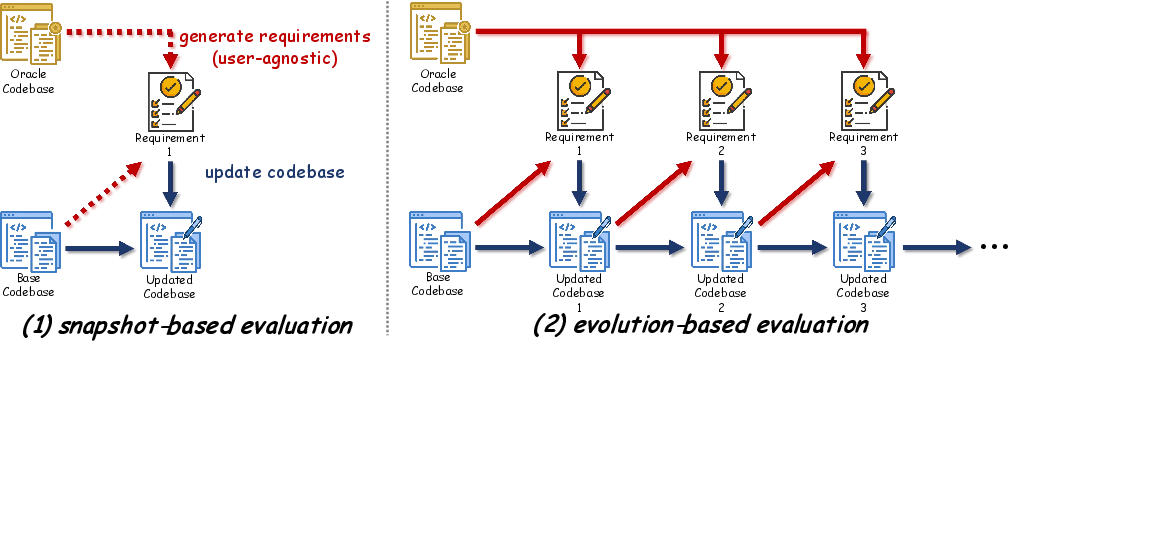
- evolution-based evaluation paradigm: An assessment approach that measures performance over successive code changes rather than a single snapshot. "we turn to consider an evolution-based evaluation paradigm."
- EvoScore (Evolution Score): A metric that aggregates progress across iterations, emphasizing later maintainability. "SWE-CI introduces EvoScore (Evolution Score) as a proxy metric: it measures functional correctness on future modifications"
- future-weighted mean: An average that gives more weight to later iterations to reflect long-term maintainability. "we aggregate them into a single scalar, EvoScore, via a future-weighted mean:"
- iFlow CLI: The agent framework used to orchestrate the evaluation workflow. "iFlow CLI \cite{10} serves as the default agent framework"
- indicator function: A function returning 1 if a condition holds and 0 otherwise, used to count passing tests. "the indicator function equals 1 if and only if unit test passes on codebase "
- ISO/IEC 25010: An international standard defining software quality models, including maintainability. "The ISO/IEC 25010 standard defines maintainability as the degree to which software can be modified effectively without introducing defects or degrading existing quality"
- Issue-to-PR paradigm: A benchmarking setup where models turn issue descriptions into pull-request patches within a repository context. "SWE-bench introduced the ``Issue-to-PR'' paradigm, requiring models to generate patches within complete repository contexts."
- lockfiles: Dependency lock files that pin exact versions to ensure reproducible environments. "(e.g., pyproject.toml and lockfiles)"
- normalized change: A scaled measure of improvement or regression relative to baseline and target test pass counts. "To this end, we introduce the normalized change."
- oracle codebase: The target, ground-truth code state used to define success in evolution tasks. "we run the oracle codebase's test suite against the base codebase."
- permissive license: Open-source licenses allowing broad reuse with minimal restrictions (e.g., MIT, Apache-2.0). "it is released under a permissive license such as MIT or Apache-2.0."
- proxy metric: An indirect measure used to capture a property that is hard to observe directly. "SWE-CI introduces EvoScore (Evolution Score) as a proxy metric:"
- pytest-json-report: A pytest plugin that outputs test results in JSON for programmatic analysis. "We use \verb|pytest| and \verb|pytest-json-report| as the testing framework, with a timeout of 3600 seconds per test run."
- regression: The reintroduction of defects causing previously passing tests to fail after changes. "a phenomenon known as regression."
- repository-level benchmark: An evaluation suite that operates over full repositories rather than single files or functions. "the first repository-level benchmark built upon the Continuous Integration loop"
- self-repair mechanism: An automated process that resolves environment setup failures by adding missing dependencies. "we introduce a self-repair mechanism: whenever the test suite fails to launch due to a missing dependency, we detect the failure and dynamically inject the required dependency into the Dockerfile to build a new environment."
- snapshot-based evaluation paradigm: A protocol assessing a single-shot solution to a fixed requirement without considering evolution. "follow the snapshot-based evaluation paradigm"
- snapshot-style protocol: A benchmark setup where the agent is given a complete requirement and produces a one-time fix. "Existing benchmarks universally adopt a snapshot-style protocol: the agent receives a single, complete requirement and produces a one-shot solution."
- target commit: The endpoint in a repository’s history that defines the desired functionality to be achieved. "each defined by a base commit and a target commit from a real-world repository"
- technical debt: Short-term implementation choices that increase future maintenance costs and hinder evolution. "those that accumulate technical debt see progressively declining performance."
- Test-Driven Development (TDD): A development approach where tests are written before code to drive design and verification. "proficient in Python software engineering and Test-Driven Development (TDD)."
- test gap: The difference between current behavior and expected behavior as revealed by failing tests. "Based on the test gap between the current code and the oracle code"
- zero-regression rate: The proportion of runs with no regressions across all iterations in long-term maintenance. "referred to as the zero-regression rate"
Collections
Sign up for free to add this paper to one or more collections.