- The paper presents BeyondSWE, a benchmark that extends traditional code agent evaluation beyond single-repo bug fixing by introducing dual axes of resolution and knowledge scope.
- The paper details an automated Docker pipeline coupled with the SearchSWE framework, which integrates deep search capabilities to enhance code synthesis across diverse tasks.
- The paper reveals significant performance gaps in current models, with challenges in domain-specific logic and search-code integration leading to an average resolution rate around 45%.
Authoritative Essay on "BeyondSWE: Can Current Code Agent Survive Beyond Single-Repo Bug Fixing?" (2603.03194)
Benchmark Motivation and Design
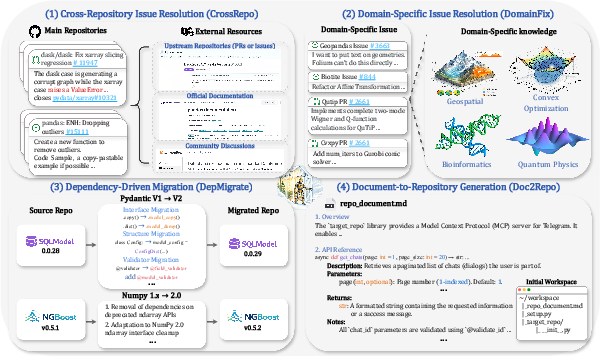
The "BeyondSWE" benchmark systematically addresses critical limitations of contemporary code agent evaluation by extending the scope well beyond repository-local bug fixing. Standard benchmarks such as SWE-bench Verified and its derivatives concentrate on narrow, function-level issue resolution within a single repository, failing to capture the complexity and breadth of real-world software engineering workflows. In response, BeyondSWE introduces two orthogonal evaluation axes: resolution scope (from isolated function repairs to codebase-level refactoring and full system generation) and knowledge scope (ranging from local-only reasoning to use of external repositories, domain-specific information, and open web resources).
The benchmark comprises 500 instances sourced from 246 real-world GitHub repositories and spans four task categories:
Environment Construction and Evaluation Rigor
To ensure reproducibility and eliminate environmental confounders, BeyondSWE employs an automated, agent-based Docker construction pipeline. This leverages frontier LLMs (Gemini 3 Pro) for iterative environment setup within a base container—agents resolve dependencies dynamically, including system-level requirements inaccessible to static scripts. All problem statements are reverse-engineered, filtering solution-specific hints and artifacts, reducing data contamination. Each test suite is strictly audited, and Docker environments are randomly rebuilt multiple times per instance to filter non-determinism.

Figure 2: The three-stage pipeline for robust automated environment provisioning, encompassing candidate collection, agent-driven container setup, and deterministic evaluation checks.
The SearchSWE Framework: Augmenting Code Reasoning with Deep Research
Recognizing that solving BeyondSWE tasks often demands information not resident in the local repository, the paper presents the SearchSWE framework—a unified agentic system integrating deep search capabilities with coding proficiency. SearchSWE overlays traditional Docker-based execution with two external tools: a search interface (via Google Search API) and a browser tool for targeted retrieval and summarization. The framework enforces strict blocklisting to prevent direct retrieval of gold solutions, ensuring evaluations reflect genuine reasoning and synthesis.
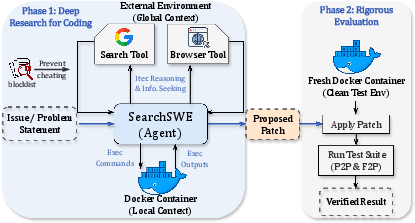
Figure 3: Workflow of SearchSWE showcasing agentic access to external resources and rigorous patch evaluation in isolated environments.
Experimental Results: Revealing Capability Gaps and Search-Code Integration Failures
Evaluation across multiple frontier models (Gemini 3 Pro, GPT-5.2, GLM-4.7, DeepSeek-V3.2, etc.) yields several strong empirical claims. The best models plateau at ~45% resolved rate (average across tasks), markedly below the >80% levels reported for SWE-bench Verified. Notably, no single model exhibits consistent performance across all task types. DomainFix is especially challenging (maximum resolved rate <36%), indicating a bottleneck in domain-specific logical synthesis. Doc2Repo instantiates a failure to generate coherent systems from specifications: while test pass rates hover near 50%, fully correct solutions (all tests passing) comprise <5% of instances.
SearchSWE’s augmentation with deep research tools yields inconsistent benefits. While external search improves performance on select tasks (notably DomainFix and DepMigrate, with gains up to +7.5% for Gemini 3 Pro), it has negligible or negative impact on others (e.g., Doc2Repo), and sometimes degrades code-specialized models. Models with strong repository-local reasoning (e.g., Seed-Coder) underperform when forced to integrate web-sourced information relative to general-purpose LLMs.
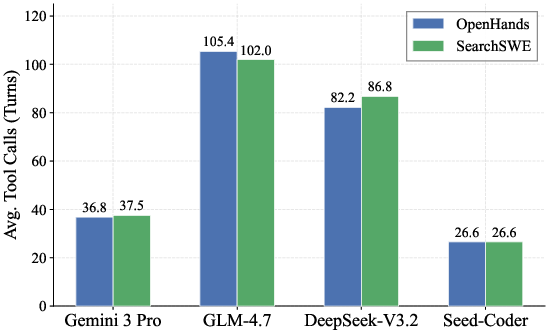
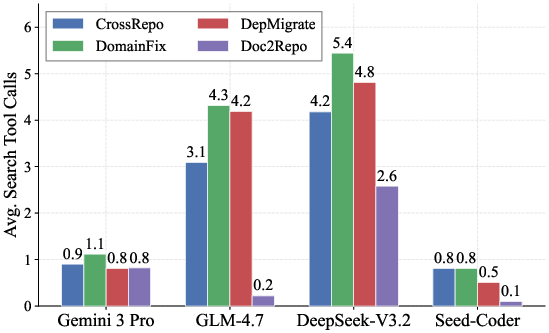
Figure 4: Distribution of average tool calls per instance, showing that higher-performing agents require fewer interactions, indicating efficient search and code manipulation.
Behavioral Analysis and Failure Modes
Analysis of agent interaction logs reveals that frequency of search invocation does not correlate with improved performance: agents invoking fewer but higher quality searches achieve superior outcomes (e.g., Gemini 3 Pro with <1.1 search calls per instance). The paper identifies three major, empirically verified failure modes in search-code integration:
- Information Landscape Gap: Agents often retrieve ambiguous, high-level documentation when precise low-level behavioral artifacts (source code, diffs) are needed, leading to brittle or incomplete implementations.
- Version Bias and Temporal Misalignment: Agents may prioritize hallucinated or latest-version documentation over repository-local constraints, breaking signature compatibility and fragmenting inheritance chains.
- Semantic Drift and Context Contamination: Polysemy in technical terminology causes agent search queries to return irrelevant results, leading to erroneous synthesis and test failures.
Task Scale and Distribution
The Doc2Repo task demonstrates that agents face non-trivial code generation workloads—40 of 50 repositories exceed 1,500 lines of code, with the largest at >16,000 lines. The spectrum of tasks (cross-repo, domain-specific, dependency migration, documentation to repo) encapsulates a comprehensive set of real-world software engineering challenges.
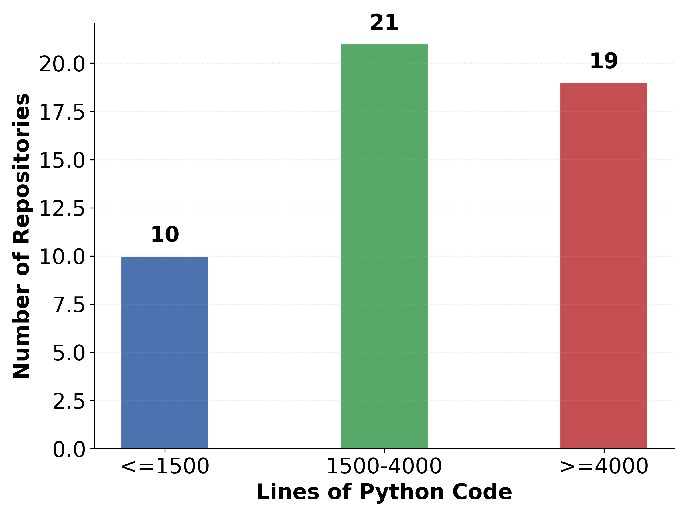
Figure 5: Distribution of lines of code across the Doc2Repo instances, evidencing significant non-toy generation requirements.
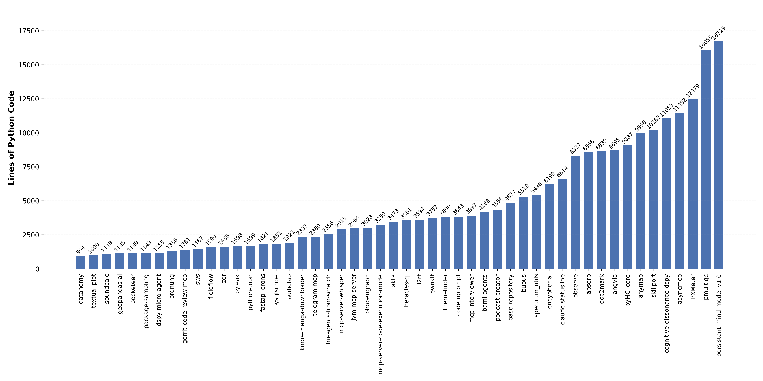
Figure 6: Per-instance code line statistics for Doc2Repo, highlighting the diversity and scale inherent in repository generation tasks.
Implications and Future Directions
BeyondSWE establishes rigorous, contamination-minimized infrastructure for holistic code agent evaluation. Empirical results reveal enduring limitations in cross-repository reasoning, domain integration, large-scale migration, and full system generation. The critical disconnect between search and coding proficiencies suggests that simple tool augmentation is insufficient. Effective integration may require explicit development of search-aware reasoning modules, improved retrieval strategies, and context-sensitive filtering.
Practically, these findings indicate that code agents remain ill-equipped for realistic developer workflows involving external research, system-level changes, and scientific domain adaptation. Theoretically, BeyondSWE provides a multi-dimensional testbed for future research in retrieval-augmented code generation, agent behavior optimization, and long-horizon reasoning. Systematic benchmarking along knowledge and resolution axes is essential for the advancement of robust, developer-aligned code agents.
Conclusion
BeyondSWE irrevocably expands the evaluation landscape for code agents to include knowledge-integration and resolution-level challenges previously unaddressed. Despite advances in LLMs and code-specialized agents, current architectures exhibit substantial capability gaps and inconsistent search augmentation efficacy. The benchmark and SearchSWE framework furnish actionable infrastructure for investigating these limitations and catalyzing the development of next-generation code agents capable of developer-grade reasoning and synthesis across divergent contexts.