Phi-4-reasoning-vision-15B Technical Report
Abstract: We present Phi-4-reasoning-vision-15B, a compact open-weight multimodal reasoning model, and share the motivations, design choices, experiments, and learnings that informed its development. Our goal is to contribute practical insight to the research community on building smaller, efficient multimodal reasoning models and to share the result of these learnings as an open-weight model that is good at common vision and language tasks and excels at scientific and mathematical reasoning and understanding user interfaces. Our contributions include demonstrating that careful architecture choices and rigorous data curation enable smaller, open-weight multimodal models to achieve competitive performance with significantly less training and inference-time compute and tokens. The most substantial improvements come from systematic filtering, error correction, and synthetic augmentation -- reinforcing that data quality remains the primary lever for model performance. Systematic ablations show that high-resolution, dynamic-resolution encoders yield consistent improvements, as accurate perception is a prerequisite for high-quality reasoning. Finally, a hybrid mix of reasoning and non-reasoning data with explicit mode tokens allows a single model to deliver fast direct answers for simpler tasks and chain-of-thought reasoning for complex problems.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper introduces Phi-4-reasoning-vision-15B, a computer model that can understand both pictures and text and then answer questions or solve problems. It’s designed to be small and fast, but still smart—especially at math and science questions and at understanding computer screens (like buttons and menus). The team explains how they built it, what data they used, and how they made it both accurate and efficient.
What the researchers wanted to figure out
The authors set out to answer a few practical questions:
- Can a smaller model match or beat bigger models on many tasks if it’s trained carefully with high-quality data?
- How do different ways of “looking” at images (like higher resolution or different cropping strategies) change performance?
- Is it possible to train one model that knows when to “think out loud” (step-by-step reasoning) and when to answer quickly and directly?
- What mix of training data (math/science vs. computer-use) gives the best all-around performance?
How they built and trained the model (explained with simple analogies)
Think of this system as a team with two parts: a “camera reader” and a “language brain.”
- The “camera reader” (called a vision encoder) turns an image into notes the language brain can understand.
- The “language brain” is a powerful text model that reads those notes and the user’s question to produce an answer.
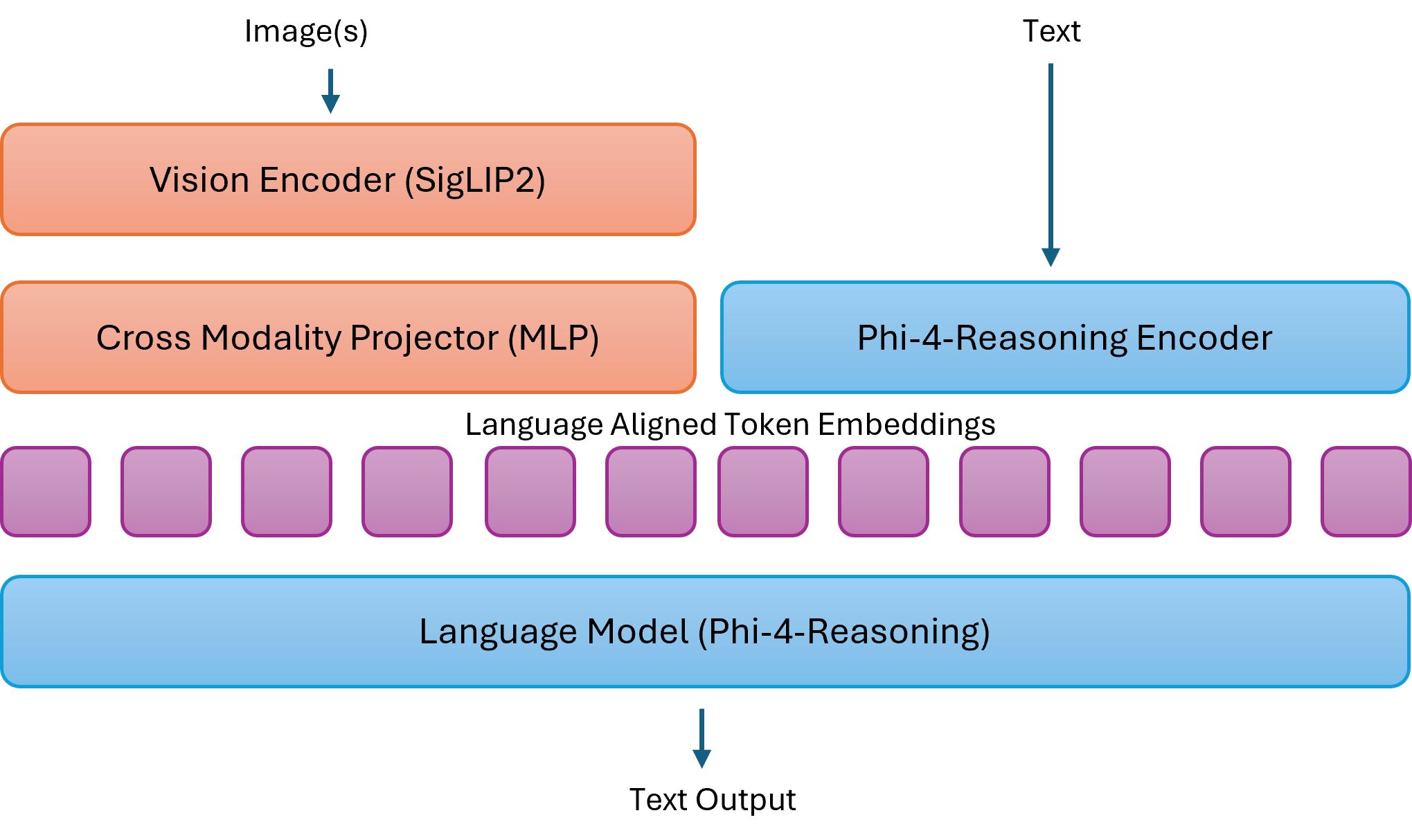
The architecture: a “mid-fusion” design
- Mid-fusion means the image is first summarized into visual notes, and then those notes are mixed with words for the language brain to process.
- Why this choice? “Early fusion” mixes everything from the start (very powerful but slow and costly). Mid-fusion is a practical balance: strong performance without huge compute bills.
Seeing clearly: high-resolution and dynamic resolution
- The model uses a modern “camera reader” (SigLIP-2) and often looks at pictures in high detail.
- Dynamic resolution is like a smart camera that adjusts how much detail to capture—so it can “zoom in” on small buttons or tiny text when needed.
Training in three steps (like school levels)
The training had three stages to help the parts work well together:
- Warm-up: only the “translator” between vision and language is trained so the image notes fit the language brain’s vocabulary.
- Main training: everything is trained together on tasks like answering questions about pictures, reading charts, doing math from diagrams, reading screens, and more.
- Special skills: the model learns to handle longer documents, multiple images in a row, and safety behavior (knowing when to refuse harmful requests).
Teaching it when to “think out loud” vs. answer quickly
- Some tasks (like reading text in a picture) don’t need step-by-step reasoning. Others (like solving a physics problem from a diagram) do better if the model writes out its steps.
- The team used special tokens to teach this:
- “> … ” means: show chain-of-thought steps first.
- “<nothink>” means: give a short, direct answer.
- This helps the model save time on simple tasks and show its work for hard ones.
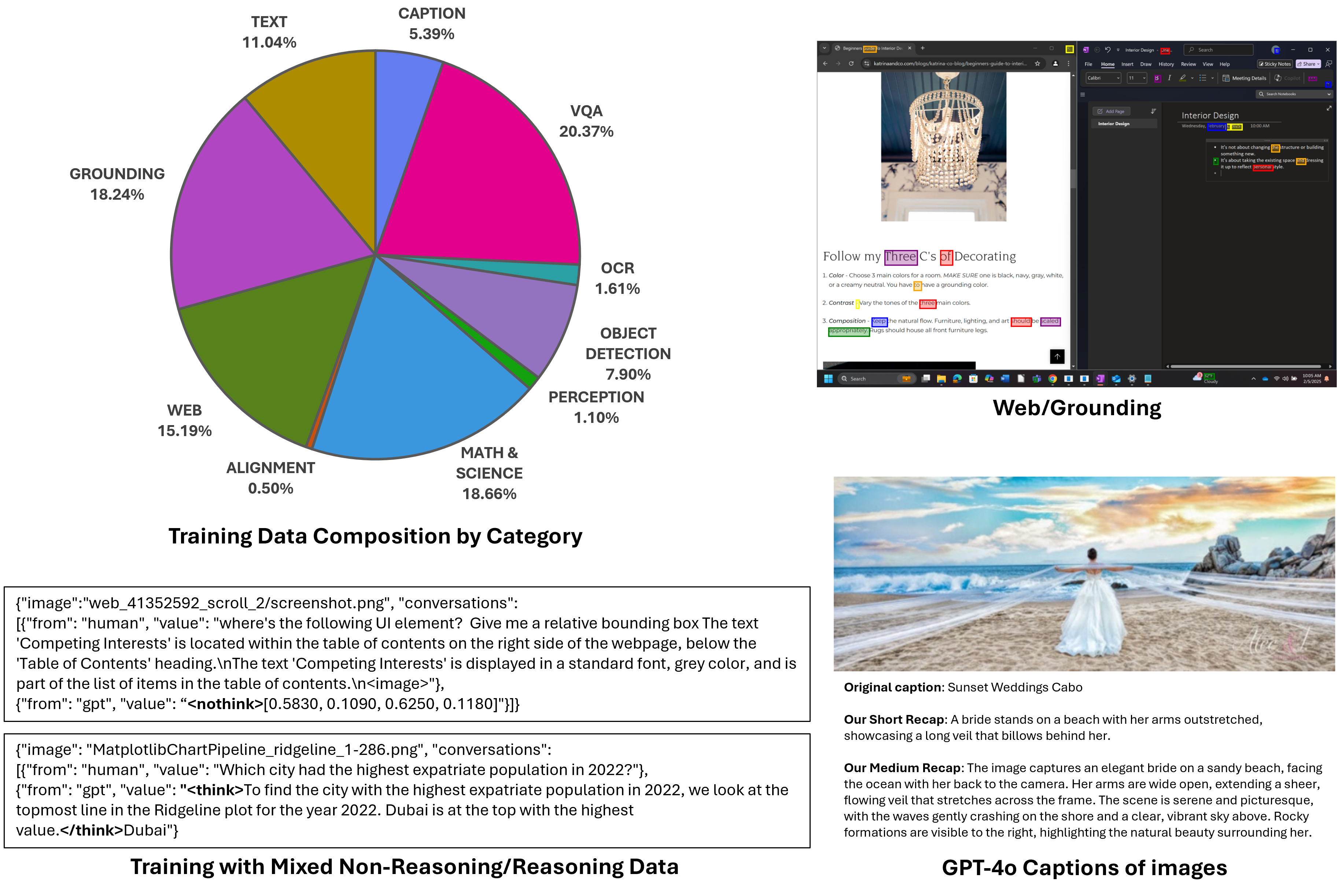
Data: clean, corrected, and carefully chosen
- The team focused on data quality more than sheer size. They:
- Removed bad or confusing examples.
- Fixed wrong answers and formatting mistakes.
- Used synthetic improvements (like better captions or verified answers) when useful.
- They also balanced data across important areas like math/science and computer-use (understanding GUIs), and found these skills can improve together.
What they found (and why it matters)
Here are the main takeaways, explained simply:
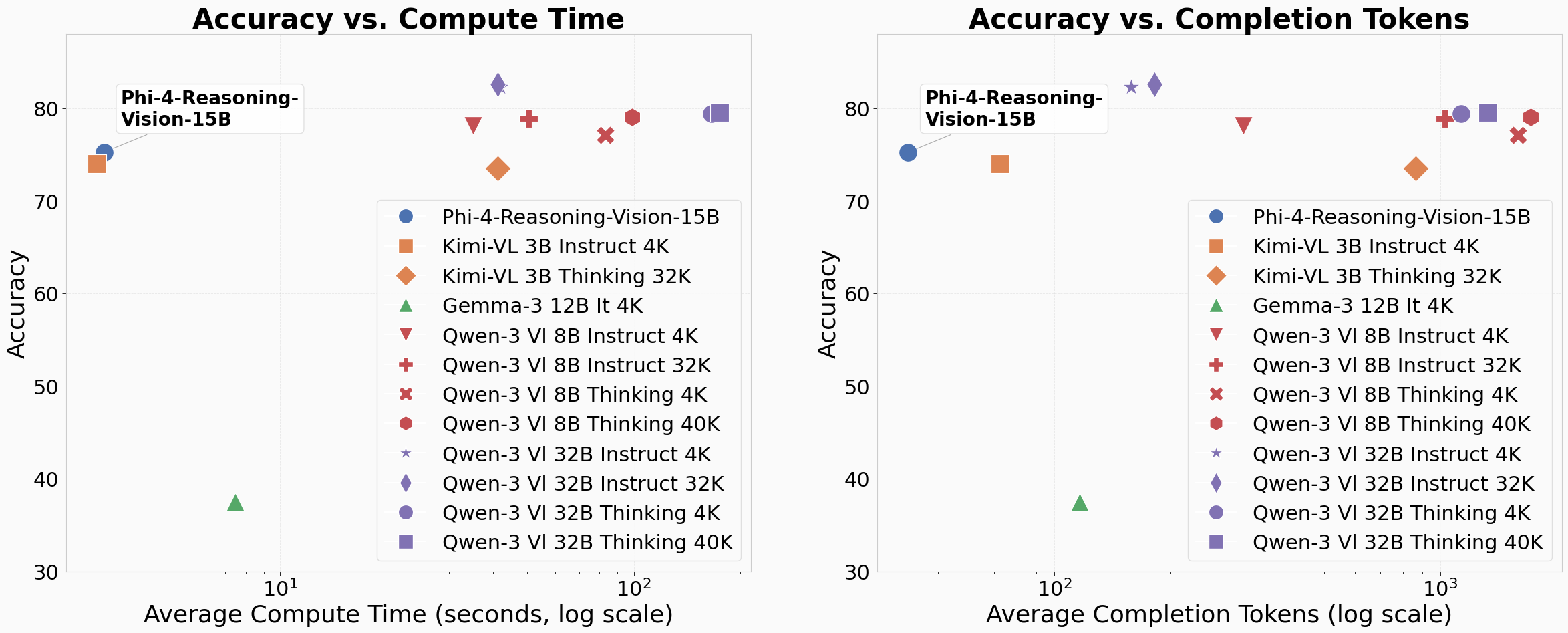
- Smaller and faster can still be great: With smart design and clean data, a 15B-parameter model can perform competitively with bigger, slower models—often using fewer tokens and less time per answer. That means lower cost and better responsiveness.
- Data quality beats data quantity: Filtering out bad examples, fixing errors, and adding good synthetic content gave the biggest performance boost.
- Seeing better helps thinking better: High-resolution, dynamic image processing consistently improved tasks that need careful visual attention (like reading small screen elements or detailed diagrams).
- One model can switch modes: Training with both reasoning and non-reasoning examples (and tagging them) produced a single model that answers quickly when it can and reasons step-by-step when it should.
- Math and computer-use can help each other: Adding more math data didn’t hurt screen understanding, and vice versa—in some cases, both improved together.
How well it performs
The team tested the model on many “quizzes” (benchmarks) for charts, science diagrams, OCR (reading text from images), multi-subject questions, and screen grounding (finding the right button or link on a UI). It showed a strong balance:
- Competitive or better accuracy than similarly fast models, and often close to larger, slower systems.
- Lower response times and fewer output tokens on average—good for real-time use.
Safety and limits
- The model was trained to avoid harmful outputs (e.g., hateful, violent, or dangerous content) and to refuse unsafe requests. It was tested with automated safety checks.
- Limitations: larger proprietary models still do better on broad, open-ended tasks; sometimes the model may choose the wrong mode (reason vs. direct); extremely fine details in images can still be hard.
Why this work is important
This research shows a practical path to building multimodal AI that is:
- Efficient enough for everyday devices and interactive apps.
- Smart enough for math/science problems and understanding computer screens.
- Flexible enough to switch between fast answers and thoughtful, step-by-step reasoning.
In the near future, this can help:
- Educational tools that explain math and science homework from photos.
- Accessibility tools that describe images, read documents, or guide users through on-screen tasks.
- Agents that can safely and reliably help people navigate software and the web.
- Researchers and developers, thanks to open weights and code, to build on these ideas transparently and responsibly.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper; each item is phrased to guide follow-up research.
- Architecture trade-offs: No head-to-head comparison of early-fusion vs. mid-fusion under matched data/compute to quantify accuracy, latency, and memory trade-offs across tasks (especially high-resolution GUI grounding and math).
- Visual encoder choices: Only SigLIP-2 NaFlex is explored; missing comparisons to other encoders (e.g., CLIP variants, DINOv2, EVA-CLIP) and hybrid strategies (frozen vs. partially fine-tuned vs. LoRA heads) on the same data.
- Text-conditioned vision tokenization: Dynamic-resolution featurization is not conditioned on the query; open how to do query-guided token budgeting (e.g., cross-modal token pruning, learned patch selection, Q-Former-like modules) that preserve agentic performance.
- Token efficiency vs. accuracy: No analysis of average/variance of visual token counts per image, their contribution to wall-clock latency, or scheduling policies to adaptively cap tokens by task difficulty.
- Efficient attention: Quadratic attention cost with large visual contexts is acknowledged but not addressed; missing experiments with efficient attention (e.g., sliding-window, block-sparse, MHA variants) or token merging/Pooling (ToMe, adaptive pooling) for high-res inputs.
- Interleaving strategy: Limited detail/ablation on where and how visual tokens are interleaved with text, positional encodings used, and their effect on long-context stability and multi-image reasoning.
- Stage-wise training ablations: No quantification of how much each stage (MLP warm-up, instruction tuning, long-context/RAI) contributes to downstream capabilities; missing controlled ablations and sensitivity to hyperparameters.
- Training compute transparency: Absent reporting of training compute (GPU type/count, GPU-days, batch-time), throughput, and energy/carbon accounting—limits reproducibility and cost comparisons.
- Data transparency: Appendix with public data sources is referenced but not included; partial future data release is planned, leaving current reproducibility and auditing limited.
- Decontamination: No analysis of train–test overlap or decontamination procedures; risk of benchmark leakage remains unmeasured.
- Synthetic label quality: Answers re-generated with GPT-4o/o4-mini are not audited with human verification rates, error taxonomies, or bias checks; lack of post-cleaning quality metrics and blind re-annotation studies.
- Synthetic bias propagation: Unclear whether synthetic rewrites change problem distributions (e.g., math difficulty, chart types) or inject language/style biases; needs measurement of induced shifts and downstream effects.
- Multilingual coverage: Despite SigLIP-2 being multilingual, training/evaluation appears English-centric; missing multilingual VQA, OCR, and GUI grounding evaluations across scripts and locales.
- Data scaling interactions: Math–CUA ratio results are shown only on a 5B model and modest data; need controlled large-scale experiments (larger models, extreme imbalance <1%) to test interference/transfer and saturation effects.
- Mixed reasoning policy: The 20/80 reasoning-to-non-reasoning split is heuristic; no exploration of alternative mixes, curricula, or task-aware gating policies learned via cost-aware objectives or RL.
- Automatic mode switching: No learned or calibrated policy to decide when to reason vs. answer directly; need per-task auto-selection accuracy metrics, token-savings analysis, and latency-aware controllers.
- Chain-of-thought safety: No evaluation of how exposing > traces affects safety (e.g., leakage of sensitive content, jailbreakability, confabulation), nor mitigation strategies (redacted CoT, distilled rationales).
Long-context/multi-image evaluation: Stage 3 trains these skills, but there is no standardized evaluation on long-document VQA (e.g., DocVQA, InfographicVQA) or multi-image reasoning benchmarks and no scaling analysis to higher image counts.
- Agentic/interactive benchmarks: No closed-loop evaluations on interactive GUI/web tasks (e.g., MiniWoB++, WebArena, OSWorld, ScreenAgent, grounded UX tasks) with success rates, latency, and click accuracy.
- Grounding metrics: ScreenSpot is reported, but there’s no localization error distribution (pixel/IoU), robustness to DPI/zoom/theme, or cross-platform (Windows/macOS/Linux/mobile) generalization studies.
- Robustness to shift/adversaries: Missing tests for robustness to distribution shifts (dark mode, font changes, low-light scans), OCR noise, adversarial visual prompts, and instruction-following attacks embedded in images/UI.
- Uncertainty and abstention: No confidence calibration, selective prediction, or abstention mechanisms—critical for safe agentic deployment and downstream decision-making.
- Safety coverage depth: Safety results are summarized (defect rates), but lack category-wise breakdowns, human evals, visual jailbreak probes, PII extraction from images/docs, copyright/logos handling, and post-deployment monitoring plans.
- Tools and modularity: No exploration of tool-augmentation (external OCR, calculators, DOM parsers, chart parsers) to offload complex perception/reasoning while reducing token budgets and latency.
- Quantization/edge deployment: Claims of modest hardware viability are not substantiated with 8-bit/4-bit quantization results, RAM/VRAM footprints, throughput on GPUs/CPUs/mobile NPUs, or accuracy degradation under quantization.
- Error analysis: Absent detailed per-task error taxonomies (e.g., OCR misreads vs. arithmetic slips vs. grounding mislocalization) to guide targeted data collection and architectural fixes.
- Temporal reasoning/video: Only static multi-image examples are shown; no temporal modeling or video benchmark results (e.g., NExT-QA, STAR), nor design for temporal positional encoding.
- Coordinate outputs in practice: Normalized coordinates are reported, but no closed-loop evaluation of mapping errors under multi-monitor setups, dynamic DPI scaling, viewport transforms, or scrolling.
- Post-release fine-tuning: No guidance on domain adaptation (LoRA vs. full fine-tune), expected catastrophic forgetting risks, or recipes to preserve mixed reasoning behavior during downstream fine-tuning.
- Prompting and templates: Evaluation uses a system prompt and chat template, but these are not released; sensitivity of results to prompting (and prompt robustness) is not analyzed.
- Statistical rigor in timing: Timing uses 100 examples per benchmark without variance/confidence intervals; no analysis of outliers, throughput vs. latency trade-offs, or concurrency effects.
- Position- and token-budgeting across modalities: Unclear policies for allocating the 16k context between text and images; need schedulers that enforce fair budgets and analyze failure under overload.
- Early fusion for high-res UIs: The paper notes early fusion is expensive but potentially more expressive; open whether sparse early-fusion (e.g., MoE over image tokens, sparse cross-attention) can reach better GUI grounding with controlled compute.
- Data duplication effects: Tripling math data improved results but might overfit; need studies on duplication vs. diversification and curriculum balancing to avoid narrow specialization.
- Licensing/provenance: “Targeted acquisitions” are mentioned without licensing specifics; downstream use and redistribution rights—and their impact on model license and data release—remain unclear.
Practical Applications
Immediate Applications
Below are actionable, real‑world uses that can be deployed today based on the model’s demonstrated capabilities (high‑resolution visual perception, mixed reasoning/non‑reasoning, screen/UI grounding, OCR, chart/document understanding, long‑context and multi‑image reasoning), its open‑weight release, and its efficiency profile.
- [Software/IT; RPA; Productivity] Screen-aware automation and assistance
- What: Use the model to locate and label interactive UI elements (buttons, menus, fields) and map them to actions for desktop, web, and mobile environments.
- Tools/products/workflows:
- “ScreenPilot SDK” for grounding+action via normalized coordinates; bindings to Playwright/Selenium/WinAppDriver/AppleScript/ADB.
- Voice-driven computer help (“Click Settings,” “Open Downloads,” “Fill this form”) with <nothink> for fast actions and > for complex flows. > - Regression testing bots that verify “what changed?” across builds with multi-image diffs. > - Assumptions/dependencies: Access to screenshots; stable window scaling to map normalized to pixel coordinates; actuator layer (mouse/keyboard/OS APIs); guardrails for safety (no unintended actions); privacy controls for captured screens. > > - [Customer Support; IT Helpdesk] Screenshot triage and guided troubleshooting > - What: Understand error dialogs, settings pages, and app states from user screenshots and return step-by-step fixes. > - Tools/products/workflows: Ticket intake that accepts images; guided click-through responses; knowledge-base article linking. > - Assumptions/dependencies: Integration with helpdesk systems; up-to-date product UI snapshots; human-in-the-loop for escalations; content safety filters. > > - [Accessibility] Real-time screen and image descriptions for low‑vision users > - What: Describe on-screen content, highlight actionable controls, read text (OCR), and summarize documents or receipts. > - Tools/products/workflows: On-device screen narrator; “focus mode” to announce nearest actionable control; automatic alt‑text for intranet dashboards. > - Assumptions/dependencies: OS-level accessibility hooks; latency targets met with quantization/batching; safety to avoid hallucinated actions or misreads. > > - [Finance; Ops; Compliance] Chart/document QA and structured extraction > - What: Answer questions about charts (ChartQA), extract fields from invoices/KYC forms, and check consistency across tables/figures. > - Tools/products/workflows: “DocIQ” pipeline combining OCR+chart QA+schema validation; spreadsheet agents that reconcile report numbers with embedded charts. > - Assumptions/dependencies: Clear scan quality; template variability handling; human review for high-stakes filings; audit trails. > > - [Education; EdTech] Math and science tutoring from photos and worksheets > - What: Step-by-step solutions and error detection for handwritten problems; diagram-based physics/geometry reasoning; solution formatting control via <think>/<nothink>. > - Tools/products/workflows: Homework helper apps; LMS plug-ins that provide hints not full answers; grader assistants that flag likely mistakes. > - Assumptions/dependencies: Academic integrity safeguards; localized curricula and notation; teacher override modes; explainability logging. > > - [Scientific & Engineering Workflows] Figure/plot understanding and “what changed?” analyses > - What: Extract and reason over plots in papers and lab reports; analyze time-lapse images to detect meaningful changes. > - Tools/products/workflows: Literature mining agents extracting chart values and captions; microscopy change-detectors; lab notebook assistants. > - Assumptions/dependencies: Domain calibration for units/scales; quality scans; verification against source data to prevent misinterpretation. > > - [Retail/E‑commerce] Catalog understanding and attribute grounding > - What: Localize products within dense catalogs; extract attributes (color, size, price) and link to SKU metadata. > - Tools/products/workflows: Seller onboarding assistants; shelf-monitoring bots for planogram compliance using screenshots/photos; competitive site screenshot analysis. > - Assumptions/dependencies: OCR accuracy on small text; consistent image quality; SKU ground truth; legal considerations for competitor scraping. > > - [Public Sector; Government] Forms processing and accessibility upgrades > - What: Intake and parse legacy forms; summarize long multi-image case files; produce accessible content alternatives. > - Tools/products/workflows: FOI/records processing assistance; automated field validation; alt‑format generation for public dashboards. > - Assumptions/dependencies: Procurement and data residency requirements; human validation; privacy/classification controls. > > - [Safety & Trust; Content Moderation] Visual policy screening with explanations > - What: Detect policy-relevant content in images/memes, refuse harmful requests, and provide policy-grounded rationale. > - Tools/products/workflows: “SafetyGuard” pre-filter in user UIs and agent toolchains; audit logs of refusal reasoning. > - Assumptions/dependencies: Calibrated thresholds; evolving policy updates; adversarial testing; bias monitoring. > > - [Developer Tooling; Data Ops] Data curation and synthetic augmentation at scale > - What: Apply the paper’s filtering, error correction, and synthetic augmentation methods to improve existing V+L datasets. > - Tools/products/workflows: Data-cleaning pipelines with majority-vote verification; auto-fix of formatting errors; “caption plus QA” dual-use datasets. > - Assumptions/dependencies: Access to verification models or human raters; dataset licensing; reproducible data lineage. > > - [Field Service; Edge/IoT] Low-latency reading of dials, gauges, and forms > - What: On-device or near-edge inference for reading meters, safety labels, and checklists; quick OCR+reasoning to validate thresholds. > - Tools/products/workflows: Rugged tablet apps; offline quantized models; alerts when readings exceed limits. > - Assumptions/dependencies: Hardware constraints (VRAM, compute); lighting variability; secure model updates. > > - [Daily Life] Everyday image understanding > - What: Interpret receipts, garment care labels, travel signage, and multi-photo events; generate concise captions and summaries. > - Tools/products/workflows: Personal assistants on phones or PCs; email attachment summarizers; trip photo journaling. > - Assumptions/dependencies: Camera/image quality; user privacy controls; multilingual OCR needs (supported by SigLIP‑2 but quality varies by script). > > ## Long-Term Applications > > These leverage the paper’s innovations but need further research, scaling, integration, or validation (e.g., text-conditioned visual tokenization, more robust safety switching between reasoning modes, domain certifications). > > - [Software/IT; Agent Platforms] Fully autonomous, multi‑app computer‑using agents > - What: Goal-driven agents that plan across apps, browse, extract, cross-check, and execute multi-step workflows reliably. > - Tools/products/workflows: “AgentOps Orchestrator” with planning, memory, and UI grounding; self-healing flows that adapt to UI changes. > - Dependencies: Stronger reliability guarantees; exception handling; secure tool-use; enterprise-grade auditability; deeper RL/feedback training. > > - [Mobile; Wearables; AR] On-device, context-aware screen and world assistants > - What: Real-time guidance on phones/glasses that understands both the screen and the environment to assist users. > - Tools/products/workflows: AR overlays highlighting controls/objects; screen+world co-grounding; low-latency <nothink>/<think> routing. > - Dependencies: Efficient text-conditioned tokenization to control visual token budgets; hardware acceleration; robust privacy protections. > > - [Robotics; HRI] Visual+UI hybrid agents for kiosks and machinery interfaces > - What: Robots that read on-device UIs, operate panels, and verify outcomes via vision; factory/kiosk automation without custom APIs. > - Tools/products/workflows: Policy-constrained control loops; “act-and-verify” grounded by normalized coordinates and visual checks. > - Dependencies: Safety certifications; closed-loop verification; sim-to-real robustness; domain-specific training. > > - [Healthcare] EHR navigation and coding assistance; document comprehension > - What: Screen-aware agents that navigate EHRs, extract clinically relevant fields, and propose codes or prior authorization packets. > - Tools/products/workflows: Clinician-in-the-loop copilots; automatic chart-to-summary; prior auth assembly from multi-doc packets. > - Dependencies: Regulatory approval; PHI handling; bias and error analysis; hospital IT integration; extensive validation. > > - [Finance; Risk & Compliance] Automated report reading and cross-source reconciliation > - What: Agents that read earnings decks, charts, and footnotes and reconcile them against filings/data feeds. > - Tools/products/workflows: “ChartReconcile” service; audit-ready reasoning traces; discrepancy alerts. > - Dependencies: High-precision numeric reasoning; explainability at scale; model governance under financial regulations. > > - [Education] Curriculum-aligned tutors and graders with robust proctoring and pedagogy > - What: Tutors that adapt hints by grade level and local standards; graders that give targeted feedback; longitudinal learning analytics. > - Tools/products/workflows: District-aligned content packs; privacy-preserving analytics; teacher dashboards. > - Dependencies: Pedagogical validation; safeguards against over-reliance; bias checks across demographics; content licensing. > > - [Scientific Discovery] Automated knowledge extraction from figures across literature at scale > - What: Systematically extract data from plots/diagrams and build structured, queryable knowledge graphs. > - Tools/products/workflows: Literature ETL for figures; unit normalization; confidence-calibrated fact stores. > - Dependencies: Large-scale QA of extracted values; handling of edge cases (log scales, panel figures); publisher permissions. > > - [Policy & Governance] Standards for on-device multimodal AI in sensitive environments > - What: Procurement and certification frameworks for screen-aware assistants (e.g., audit trails, privacy, refusal behavior). > - Tools/products/workflows: Conformance test suites; government reference deployments (document accessibility, forms processing). > - Dependencies: Cross-agency standards; robust red‑teaming; lifecycle governance; public transparency. > > - [Systems/ML Research] Text-conditioned visual tokenization and adaptive resolution > - What: Condition image tokenization on the query to reduce compute while preserving answer quality (e.g., focus on ROIs). > - Tools/products/workflows: Encoder adapters/Q-Former-like modules for query-directed featurization; mixed-resolution pipelines. > - Dependencies: New training recipes; stability at scale; agentic task validation; benchmark extensions for efficiency-quality trade-offs. > > - [Data Ecosystems] Shared, high-quality multimodal data stewardship > - What: Community pipelines that reproduce the paper’s filtering, error correction, synthetic augmentation, and verification at scale. > - Tools/products/workflows: Open “Data Steward” kits; dataset cards with correction provenance; majority-vote validators. > - Dependencies: Licensing clarity; responsible synthetic data generation; community governance and maintenance. > > - [Trust & Safety] Mode selection guarantees and safe reasoning under adversarial inputs > - What: Formalized switching policies between reasoning and non-reasoning with safety constraints and detect-and-refuse behaviors. > - Tools/products/workflows: Runtime policy enforcers; adversarial visual prompt detectors; explainable refusal traces. > - Dependencies: Expanded safety datasets; standardized evaluations; observable guarantees needed for regulated domains. > > ### Cross-cutting assumptions and dependencies (affecting both near- and long-term) > > - Compute vs. resolution trade-offs: Dynamic-resolution encoders improve accuracy on dense UIs but increase context length and latency; consider text-conditioned tokenization and ROI cropping. > > - Accuracy bounds: Smaller open models trail the best proprietary systems on broad tasks; human verification is advised for high-stakes use. > > - Privacy and security: Screens and documents often contain sensitive data; deploy on-device or air‑gapped servers where required; enforce logging redaction. > > - Tool integration: Practical deployments need reliable actuator layers, OCR, window management, and error recovery. > > - Safety and governance: Use RAI data and refusal behaviors; maintain audit logs, monitoring, and red-teaming; calibrate for bias and robustness. > > - Licensing and data rights: Ensure compliance for any data used in training, augmentation, or inference-time storage.
Glossary
- ablation: A systematic experiment where components or settings are removed or varied to analyze their effect on performance. "we conducted a large-scale ablation of several vision encoder and image processing techniques"
- AdamW optimizer: An Adam variant with decoupled weight decay commonly used to train deep neural networks. "All stages use the AdamW optimizer, bf16 mixed precision, DeepSpeed ZeRO-1, and train for one epoch."
- agentic: Referring to models or systems capable of autonomous, goal-directed actions in interactive environments. "making fine-grained high-resolution feature extraction a prerequisite for agentic applications."
- automated red teaming: Automated adversarial testing to probe a model’s safety and robustness against harmful or policy-violating outputs. "Automated red teaming was performed on Azure to assess safety risks across multiple risk categories"
- bf16 mixed precision: A training/inference precision format (bfloat16) that reduces memory/compute while maintaining model stability. "All stages use the AdamW optimizer, bf16 mixed precision, DeepSpeed ZeRO-1, and train for one epoch."
- BLIP-2: A vision–language framework that uses a query transformer (Q-Former) to bridge visual and LLMs. "the Q-Former from BLIP-2"
- catastrophic forgetting: The tendency of a model to lose previously learned capabilities when trained on new tasks or data. "but risks catastrophic forgetting, as reasoning training may degrade previously learned visual capabilities."
- chain-of-thought reasoning: Generating intermediate reasoning steps before a final answer to improve accuracy on complex tasks. "and chain-of-thought reasoning for complex problems."
- cross-attention: Attention mechanism enabling interactions between different modalities (e.g., image and text) within a model. "allowing unrestricted cross-attention across modalities throughout the network"
- cross-modality projector (MLP): A module that maps visual features into the language embedding space to enable fusion with text. "via a cross-modality projector (MLP)."
- DeepSpeed ZeRO-1: A memory-optimization technique for distributed training that partitions optimizer states to enable larger models. "All stages use the AdamW optimizer, bf16 mixed precision, DeepSpeed ZeRO-1, and train for one epoch."
- Dynamic S2: A resolution-handling technique that adapts S2 tiling dynamically to minimize distortion while covering high-resolution content. "Dynamic S"
- dynamic resolution: Using a vision encoder that adapts the number or size of patches/tokens based on the input image resolution. "dynamic resolution vision encoders with a large number of visual tokens perform uniformly well"
- early-fusion: An architecture that feeds image patches and text tokens into a single transformer for joint processing throughout. "Early-fusion models, by contrast, process all image patches and text tokens into a single transformer"
- Eureka ML Insights: An open-source evaluation framework used for benchmarking accuracy, timing, and token usage of models. "All timing experiments were conducted using Eureka ML Insights on NVIDIA H100 GPUs"
- greedy decoding: A generation strategy that selects the highest-probability token at each step without sampling. "and we ran all evaluations with temperature, greedy decoding, and 4096 max output tokens."
- groundedness: The degree to which a model’s outputs are supported by provided inputs or evidence. "The evaluation assessed the model's groundedness and its tendency to generate fabricated or misleading information."
- grounding: Linking textual references or instructions to specific visual regions or interface elements. "with the goal of understanding and maximizing grounding performance."
- GUI grounding: Identifying and localizing interactive elements within graphical user interfaces. "GUI grounding on a Windows desktop."
- jailbreak susceptibility: Vulnerability to prompts designed to circumvent safety guardrails and elicit disallowed behavior. "and jailbreak susceptibility."
- long-tailed classification: A setting where many classes are rare, requiring strategies to handle imbalanced data distributions. "Research on long-tailed classification robustness has suggested that balancing the data"
- mid-fusion: An architecture that first encodes images into visual tokens before fusing them with text in a LLM. "we use a mid-fusion architecture."
- mode tokens: Special tokens that explicitly signal whether a response should include reasoning steps or be direct and concise. "explicit mode tokens allows a single model to deliver fast direct answers for simpler tasks and chain-of-thought reasoning for complex problems."
- NaFlex: A SigLIP-2 variant supporting flexible native resolutions by adjusting the number of visual patches. "the NaFlex variant of the SigLIP-2 encoder"
- open-weight: Model checkpoints whose weights are publicly released for community use, inspection, and fine-tuning. "a compact open-weight multimodal reasoning model"
- optical character recognition (OCR): Automatically reading and transcribing text from images. "for tasks such as image captioning and optical character recognition (OCR), reasoning is often unnecessary"
- pan-and-scan: A high-resolution handling method that scans across subregions (panes) of an image to cover fine details. "uses pan-and-scan"
- Pareto frontier: The set of models for which improving one metric (e.g., accuracy) cannot occur without worsening another (e.g., compute cost). "pushing the Pareto frontier of the trade-off between accuracy and compute costs."
- Q-Former: A query-based transformer module that extracts task-relevant visual tokens for LLMs. "the Q-Former from BLIP-2"
- quadratic complexity (of attention): The O(n2) scaling of attention with sequence length, increasing compute and memory with longer contexts. "it comes at the cost of efficiency due to the quadratic complexity of attention with respect to the context length."
- reinforcement learning (RL): Training via reward signals to optimize policies or outputs, often used to elicit reasoning without large SFT traces. "Language-only reasoning models are typically created through supervised fine-tuning (SFT) or reinforcement learning (RL):"
- responsible AI (RAI): Practices and datasets aimed at aligning models with ethical and safety principles. "responsible AI (RAI) data"
- SigLIP-2: A multilingual vision–language encoder family with strong localization and dense feature capabilities. "We build on the SigLIP-2 vision encoder"
- supervised fine-tuning (SFT): Training a model using labeled input–output pairs to align it with target tasks or behaviors. "Language-only reasoning models are typically created through supervised fine-tuning (SFT) or reinforcement learning (RL):"
- unimodal models: Models that process a single modality (e.g., text-only or image-only) rather than combining multiple modalities. "preserving the strengths and scalability of large unimodal models."
- visual “soft” tokens: Continuous embeddings representing image content that are interleaved with text tokens for joint processing. "The resulting visual ``soft'' tokens are interleaved with text tokens"
- vision--LLMs (VLMs): Models that jointly process images and text to perform multimodal tasks. "Many popular vision--LLMs (VLMs)"
- VLMEvalKit: An open-source toolkit for evaluating vision–LLMs across standardized benchmarks. "and VLMEvalKit"
Collections
Sign up for free to add this paper to one or more collections.