STEP3-VL-10B Technical Report
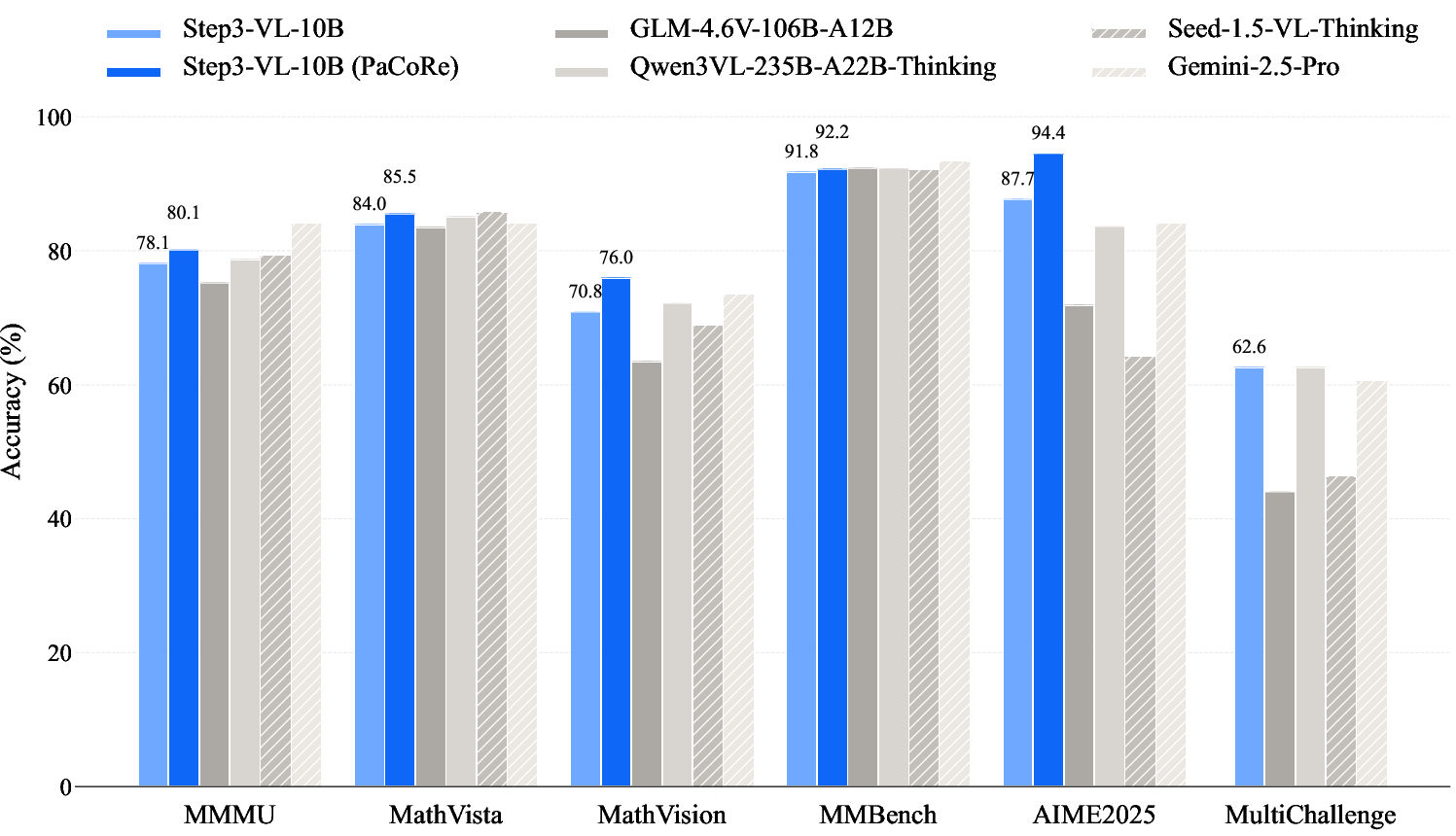
Abstract: We present STEP3-VL-10B, a lightweight open-source foundation model designed to redefine the trade-off between compact efficiency and frontier-level multimodal intelligence. STEP3-VL-10B is realized through two strategic shifts: first, a unified, fully unfrozen pre-training strategy on 1.2T multimodal tokens that integrates a language-aligned Perception Encoder with a Qwen3-8B decoder to establish intrinsic vision-language synergy; and second, a scaled post-training pipeline featuring over 1k iterations of reinforcement learning. Crucially, we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute, allocating resources to scalable perceptual reasoning that explores and synthesizes diverse visual hypotheses. Consequently, despite its compact 10B footprint, STEP3-VL-10B rivals or surpasses models 10$\times$-20$\times$ larger (e.g., GLM-4.6V-106B, Qwen3-VL-235B) and top-tier proprietary flagships like Gemini 2.5 Pro and Seed-1.5-VL. Delivering best-in-class performance, it records 92.2% on MMBench and 80.11% on MMMU, while excelling in complex reasoning with 94.43% on AIME2025 and 75.95% on MathVision. We release the full model suite to provide the community with a powerful, efficient, and reproducible baseline.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Step3‑VL‑10B: A clear, simple explanation
Overview
This paper introduces Step3‑VL‑10B, a powerful yet compact AI model that can understand images and text together. It’s “multimodal,” meaning it can look at pictures (like charts, documents, or app screens) and also read and write text. The big idea is to get top‑tier performance without needing a giant model: Step3‑VL‑10B has about 10 billion parameters, which is much smaller than many leading systems, but it still matches or even beats some models that are 10–20 times larger.
What questions were the researchers trying to answer?
The team focused on three simple questions:
- Can a smaller model (about 10B) be trained to see and reason as well as much larger models?
- What training recipe helps a compact model learn both “seeing” (perception) and “thinking” (reasoning) really well?
- Can we use smart strategies at test time (when the model is answering a question) to boost performance without making the model itself bigger?
How did they build and train it?
Think of the model as having two main parts working together like a camera and a storyteller:
- A “Perception Encoder” (the camera) that turns images into information the model can understand.
- A “Language Decoder” (the storyteller) that reasons and writes answers.
They trained the whole system end‑to‑end and followed a “study → practice → coached practice” path:
- Pre‑training (“study time”): The model learned from a huge mix of 1.2 trillion multimodal tokens (text + images). This included school‑style problems, charts, documents, OCR (reading text in images), UIs (phone and computer screens), general knowledge images, and more. The goal was to build strong basic skills in seeing and understanding.
- Supervised fine‑tuning (SFT, “guided practice”): The model practiced on carefully chosen question‑and‑answer examples, first focusing mostly on text reasoning, then balancing text and image tasks, to make sure it could connect what it sees with how it thinks.
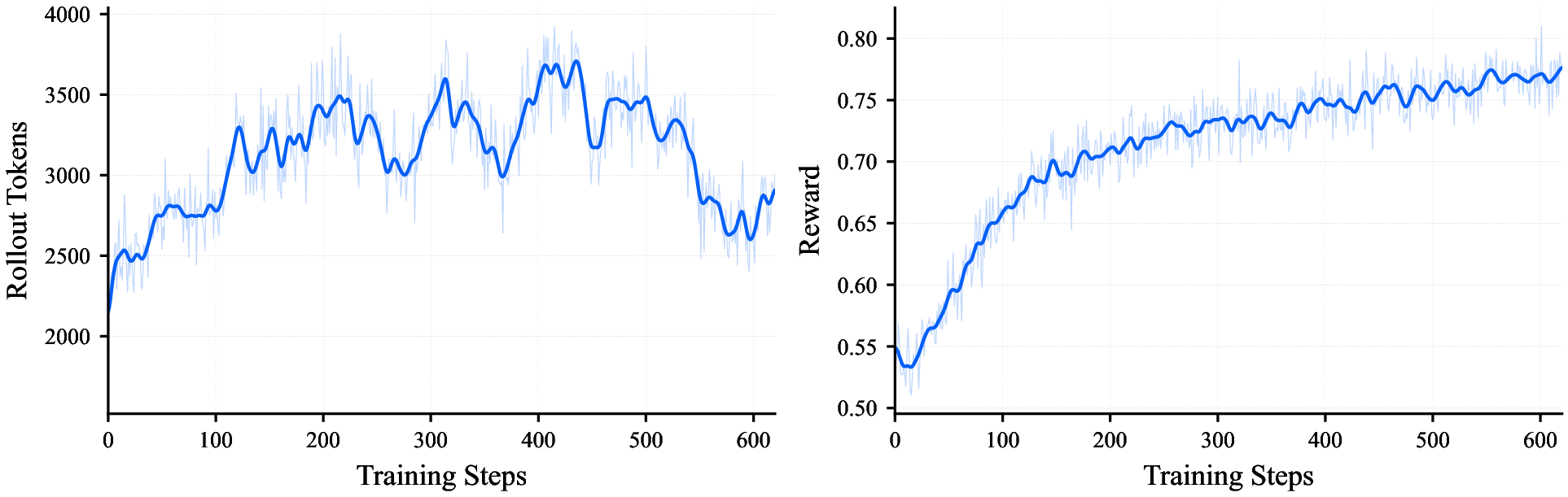
- Reinforcement learning (RL, “coached practice with rewards”):
- Verifiable rewards: like checking with an answer key (math, grounding, OCR). If it got the right answer or located something precisely, it got points.
- Preference rewards: for open‑ended tasks with no single correct answer, it was guided by learned feedback about what people prefer (clear, helpful, safe responses), and penalized for things like making up citations or being overconfident.
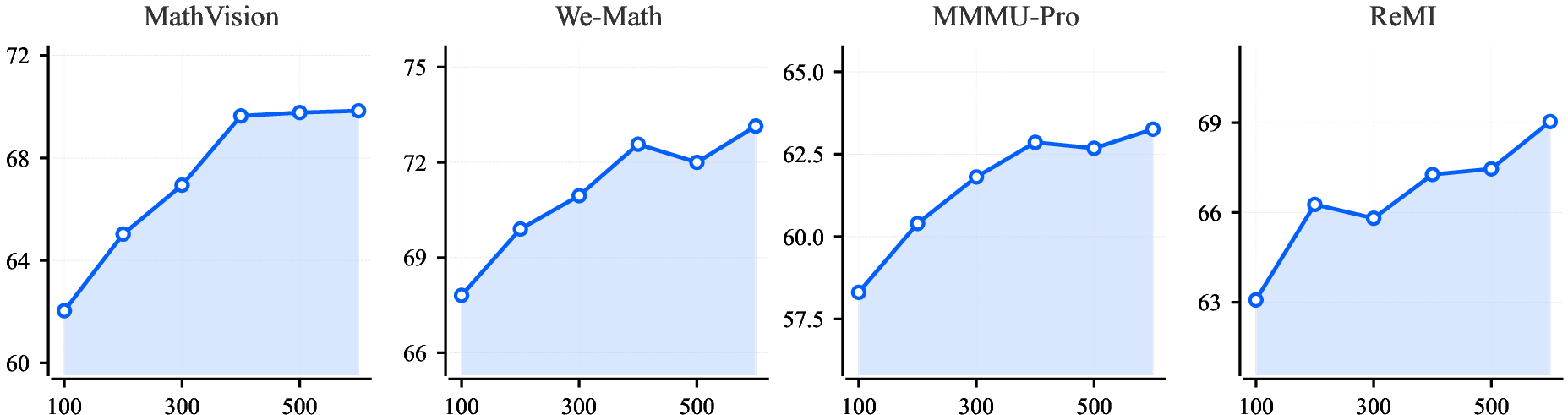
- Parallel Coordinated Reasoning (PaCoRe, “teamwork at test time”): Instead of thinking just once from start to finish, the model runs several parallel “thought paths” (like a team of detectives exploring different clues), then compares notes and synthesizes a final answer. This uses more computation while answering, but it greatly improves accuracy, especially on complex visual and reasoning problems.
In everyday terms:
- Pre‑training = learning from a massive library of examples.
- Fine‑tuning = practicing with a tutor.
- RL = doing practice tests where you get scored and learn from mistakes.
- PaCoRe = solving a problem by having several smart teammates brainstorm in parallel, then agreeing on the best solution.
What did they find, and why is it important?
The model performs extremely well for its size:
- On general vision‑language tests, it scores around the best in its class (about 92% on MMBench and about 80% on MMMU).
- On tough reasoning exams, it scores very high (for example, over 90% on some AIME‑style math tests in their reporting).
- It’s strong at OCR (reading text in images), document/chart understanding, and GUI (app screen) grounding—meaning it can spot the right buttons or text on a screen and reason about what to do.
- Thanks to PaCoRe, it closes much of the gap with very large, expensive models without increasing the model size—just by using smarter test‑time thinking.
Why this matters:
- It shows you don’t always need a huge model to get top performance. With the right training and test‑time strategy, a compact model can be fast, efficient, and very capable.
- It’s open‑source, so researchers and developers can use it, study it, and build on it.
What’s the potential impact?
- More accessible AI: Smaller, efficient models are cheaper to run and easier to deploy, which means advanced vision‑and‑language tools could work on more devices and reach more people.
- Better tools for real tasks: Strong document reading, UI understanding, and math/logic skills can help with education (tutoring), office work (reading forms, tables, charts), accessibility (reading signs or documents), and automation (interacting with apps).
- Research progress: By releasing the model and training details, the community gets a high‑quality, reproducible baseline for future multimodal research.
In short, Step3‑VL‑10B proves that careful design (good data, staged training, RL rewards) plus smart test‑time reasoning (PaCoRe) can make a relatively small model behave like a much larger one—bringing advanced multimodal intelligence closer to everyday use.
Knowledge Gaps
Below is a concise, actionable list of the paper’s unresolved knowledge gaps, limitations, and open questions that future work could address:
- Reproducibility of RL verification: The reward pipeline relies on GPT-OSS-120B for answer verification; an open, replicable verifier and ablation against simpler checkers (exact match, MathVerify) are not provided.
- RL algorithm clarity: The PPO/GAE description is internally inconsistent (off-policy setting while “omitting importance sampling,” yet using truncated importance ratios); exact algorithm variant, hyperparameters, and implementation details require clarification and code release.
- PaCoRe synthesis mechanism: The procedure for aggregating 16–24 parallel rollouts (selection, weighting, conflict resolution, and consistency checks) is not specified or compared to alternatives (majority vote, confidence-weighted voting, LM-based adjudication).
- Compute–performance tradeoffs: No systematic study quantifies how PaCoRe’s rollout count, context length, and synthesis strategy impact accuracy, latency, and cost across task types.
- Dynamic compute allocation: The model lacks an uncertainty-aware policy to adaptively choose the number of rollouts per query; when and how to allocate parallel compute remains unexplored.
- PaCoRe failure modes: The risk of spurious consensus, error amplification across parallel hypotheses, and brittleness under conflicting evidence is not characterized.
- Long-context effectiveness: Although the model is run at up to 131k tokens, there is no measurement of long-context recall/retention, ordering sensitivity, or degradation curves (e.g., needle-in-a-haystack, multi-document reasoning).
- Position encoding choice: The decision to use 1D RoPE with newline tokens for patch rows is not backed by ablations against 2D positional encodings or hybrid schemes; effects on spatial tasks and document parsing remain unclear.
- Visual token compression: The projector’s 16× downsampling could impair small-text OCR and fine-grained perception; no micro-benchmarks quantify recognition vs. downsampling tradeoffs by font size, stroke width, or symbol density.
- Multi-crop strategy: The benefit of global/local crops (728×728/504×504) is not disentangled; ablations on crop count, scale, and sampling policy are missing.
- Encoder freezing in RL: The RL phase updates only the decoder; whether unfreezing the encoder (or partial tuning) improves perceptual reasoning is not studied.
- Data mixture attribution: There are no ablations quantifying the contribution of each pretraining subset (OCR, GUI, grounding, chart/doc) to downstream performance.
- Contamination auditing: Decontamination is described for SFT but not for pretraining and RL datasets; rigorous leakage checks against all reported benchmarks (especially math exams) are missing.
- Safety and hallucination metrics: Behavioral regularization (citation checks, epistemic calibration) is proposed, but no quantitative safety evaluation (toxicity, jailbreak resistance, fabrication rates, misleading confidence) is reported.
- Citation integrity: The “strict citation verification” reward is not evaluated on a dedicated benchmark; false positives/negatives and impact on knowledge tasks remain unknown.
- Bias and multilingual coverage: Aside from MMBench CN and CC-OCR (multi-lang), cross-lingual performance (low-resource scripts, RTL languages, complex typography) and socio-demographic bias analyses are absent.
- Robustness to adversarial inputs: Sensitivity to adversarial images, prompt injection, image perturbations (noise, compression, occlusion), and layout adversaries is not assessed.
- Fairness of comparisons: PaCoRe is used for Step3-VL-10B but competing models may not be evaluated under comparable test-time compute; a standardized inference budget and parity protocol are missing.
- Inference resource profile: Memory/latency footprint for SeRe vs. PaCoRe at 65k–131k tokens is not reported; practical deployment constraints on GPUs/edge devices are unclear.
- GUI interaction end-to-end: Evaluation focuses on grounding; success rates for full execution tasks (multi-step trajectories, stateful interactions) in real environments (OSWorld/Browser-use-GUI) are not provided.
- Counting and spatial gaps: The model underperforms or is only second-best on several counting and spatial benchmarks (e.g., CountBench, RealWorldQA, CVBench, V*); targeted error analyses and remediation strategies are missing.
- Preference optimization stability: GenRM and behavioral regularization may induce reward hacking or mode collapse; no training dynamics diagnostics (diversity, length, coherence) or post-RL calibration metrics (ECE, Brier score) are reported.
- Parallel-reasoning training data: The “synthesis context” built from cached rollouts may not reflect real test-time distributions; generalization of coordinated synthesis beyond curated “some-accept” prompts is not evaluated.
- Knowledge recency and updating: The model’s ability to incorporate post-training knowledge (tools, retrieval augmentation, or lightweight adapters) is not explored.
- Modal coverage: Video and audio modalities are not addressed; temporal reasoning, multi-frame perception, and audiovisual grounding are open.
- Training compute disclosure: Wall-clock time, FLOPs, hardware configuration, and energy usage for pretraining and RL are not provided, hindering reproducibility and cost estimation.
- Licensing and data release: Several datasets (licensed exams, internal crawls, UI trajectories) are described but not released; the absence of public data and reward models limits community reimplementation.
- Attribution of gains: No ablation separates the effects of RLVR vs. RLHF vs. PaCoRe; their individual and combined contributions to each benchmark remain unknown.
- Uncertainty expression: While penalties discourage overconfidence, there is no empirical calibration study linking stated uncertainty to correctness on ambiguous or underspecified queries.
- Theoretical grounding of “externalized” visual processes: The claim that PaCoRe “externalizes implicit visual processes” is not formalized; metrics and methodology to test this hypothesis are lacking.
Practical Applications
Practical Applications of Step3-VL-10B
Below are actionable, real-world applications derived from the model’s reported capabilities, training methods, and innovations. They are grouped by deployability horizon and linked to relevant sectors, prospective tools/workflows, and feasibility considerations.
Immediate Applications
- Document digitization and structured extraction (finance, legal, healthcare admin, government records, publishing)
- What it enables/workflow: End-to-end conversion of scans/PDFs to structured formats (Markdown/HTML/LaTeX/CSV); table and formula reconstruction; layout-aware OCR for complex documents and forms.
- Potential tools/products: “Paper-to-Data” pipelines; invoice/claims ingestion; scientific paper converters; enterprise knowledge ingestion (Doc-to-HTML/Markdown/LaTeX).
- Assumptions/dependencies: High-quality scans; PII/PHI handling and compliance; domain-specific validation; on-prem or VPC deployment for sensitive data; accuracy thresholds for regulated processes.
- Visual-to-code reconstruction for charts/diagrams/tables (software, finance, scientific publishing, education)
- What it enables/workflow: Convert figures to executable code (Matplotlib, LaTeX/TikZ, Graphviz); regenerate tables/charts from images for editing, reuse, and audit.
- Potential tools/products: “Figure Reproducer” for journals; financial chart auditing; design handoff of diagrams; classroom tools to inspect chart generation.
- Assumptions/dependencies: Human-in-the-loop for high-stakes use; domain-specific symbol sets; robust rendering/round-trip tests.
- GUI understanding and RPA-style screen automation (software QA, enterprise IT, customer operations, accessibility)
- What it enables/workflow: Ground UI elements (buttons, fields) and execute granular actions (CLICK, SCROLL, TYPE) across Windows/macOS/Linux/iOS/Android; robust element localization for test automation and IT workflows.
- Potential tools/products: “Screen agent” copilots; test recorder and auto-regressor; IT helpdesk bots; accessibility overlays that find and activate UI elements.
- Assumptions/dependencies: OS/application coverage; privacy and screen-content governance; safe action constraints and rollback; latency constraints for interactive use.
- Chart/CSV question answering and document reasoning (business intelligence, research, media)
- What it enables/workflow: Interrogate charts, tables, and PDFs; answer “what-if” and consistency questions; detect mismatches between narrative and figures.
- Potential tools/products: Meeting/report copilots; compliance checks in research workflows; newsroom fact-checking assistants.
- Assumptions/dependencies: Calibrated uncertainty; benchmarked reliability on domain-specific chart types; human review for consequential decisions.
- High-accuracy OCR and multi-language text-rich image understanding (global operations, e-commerce, logistics)
- What it enables/workflow: Read receipts, labels, shipping documents, and multilingual signage; layout-aware extraction for downstream systems.
- Potential tools/products: Retail shelf scanners; returns triage; logistics document parsers; global content moderation for text-in-image.
- Assumptions/dependencies: Camera/scan quality; multi-language coverage; edge vs cloud deployment trade-offs.
- Counting and fine-grained visual QA for QC and inventory (manufacturing, retail, warehousing)
- What it enables/workflow: Object counting and spot checks from photos/video; conformance verification; anomaly surfacing.
- Potential tools/products: “Count-from-Camera” station; QC dashboards; automated pick/pack verification.
- Assumptions/dependencies: Domain-specific calibration (lighting, occlusions); false-negative/positive tolerances; integration with MES/WMS.
- Math and STEM tutoring with step-by-step solutions (education; daily life)
- What it enables/workflow: Photo-based problem solving with verifiable reasoning; geometry/diagram understanding; exam prep across K–12 and professional certifications.
- Potential tools/products: Homework helper apps; teacher-assist authoring and grading; exam practice platforms with process feedback.
- Assumptions/dependencies: Content licensing; safeguards against answer-only behavior; alignment with curricula; parental/educator oversight.
- Developer productivity for design-to-code and visual coding (software, product design)
- What it enables/workflow: Generate front-end scaffolds from screenshots/wireframes; reconstruct widgets and layout markup; iterate on UI variants.
- Potential tools/products: IDE plugins; Figma-to-code bridges; regression testers that diff visual intent and generated code.
- Assumptions/dependencies: Human review for production code; design system alignment; accessibility and performance checks.
- Accessibility: screen reading and “what’s on my screen?” assistance (daily life, public sector)
- What it enables/workflow: Element-aware narration, focus guidance, and command execution on arbitrary apps; live OCR and layout description.
- Potential tools/products: Assistive desktop/mobile companions; voice-driven UI control.
- Assumptions/dependencies: Real-time latency targets; on-device or secure local processing; robust fallback when elements are dynamic.
- Content integrity checks for text and citations (publishing, policy, enterprise comms)
- What it enables/workflow: Enforce citation presence/format; discourage fabricated links and overconfident claims; internal review bots for documents.
- Potential tools/products: Editorial validators; enterprise comms “safety linting” before release.
- Assumptions/dependencies: Organization-specific policy rules; acceptance of conservative behavior; manual overrides for edge cases.
- Training-method adoption: verifiable-reward RL for multimodal tasks (academia, applied ML teams)
- What it enables/workflow: Reuse RLVR/RLHF recipe, checkability filters, and difficulty-tagging to train compact specialized models under limited compute.
- Potential tools/products: Open training harnesses; reward-model kits; data curation pipelines (some-accept filtering, model-based verification).
- Assumptions/dependencies: Access to verifiers (or open substitutes) and domain ground truths; compute budget; dataset licensing and decontamination routines.
- Inference-time scaling with PaCoRe for high-stakes queries (cross-sector)
- What it enables/workflow: Turn on parallel coordinated reasoning only for difficult tasks; aggregate multi-perspective hypotheses for better accuracy.
- Potential tools/products: “Boosted mode” in copilots; selective parallel inference policies keyed by difficulty detectors.
- Assumptions/dependencies: Higher latency/compute costs; policy to trigger PaCoRe; monitoring for diminishing returns.
Long-Term Applications
- Autonomous multimodal desktop agents operating across arbitrary applications (software, enterprise ops)
- What it could enable/workflow: Plan-and-act sequences with reliable grounding, self-verification, and recovery across heterogeneous UIs; end-to-end task completion.
- Potential tools/products: Generalist enterprise agents for back-office workflows; autonomous test authoring and execution.
- Assumptions/dependencies: Further robustness from PaCoRe-like synthesis; stronger safety constraints; sandboxed execution; comprehensive audit logging.
- Embodied perception and robotics decision-making from visual scenes (robotics, logistics, field service)
- What it could enable/workflow: Use 2D/3D spatial reasoning and grounding to guide manipulation, navigation, and inspection; integrate with control stacks.
- Potential tools/products: Vision-language controllers; tele-op assistants that propose safe action plans; digital twin validation loops.
- Assumptions/dependencies: Real-world generalization; closed-loop control integration; strict safety certification; additional sensor modalities.
- Scientific integrity and figure forensics at scale (publishing, policy, compliance)
- What it could enable/workflow: Large-scale reproduction of figures from code inferred from images; flagging inconsistencies and manipulation.
- Potential tools/products: Journal preflight checks; research audit services for funders and institutions.
- Assumptions/dependencies: Very low false positive rates; cooperative editorial workflows; standardized disclosure requirements.
- Healthcare document automation and structured clinical data extraction (health IT)
- What it could enable/workflow: Robust extraction from scanned charts, forms, and discharge summaries; codeable output for EMR/claims.
- Potential tools/products: Intake and records digitization; claims pre-processing; patient-facing document assistants.
- Assumptions/dependencies: HIPAA/GDPR compliance; medical domain adaptation; rigorous QA; exclusion of diagnostic use without clinical validation.
- On-device multimodal assistants (edge, mobile, automotive)
- What it could enable/workflow: Privacy-preserving OCR, chart reasoning, and UI support on consumer hardware through quantization and optimized runtimes.
- Potential tools/products: Offline study helpers; in-vehicle infotainment assistants; smart glasses for accessibility.
- Assumptions/dependencies: Efficient quantization, memory optimizations, and schedulers; battery/thermal constraints; selective PaCoRe due to resource limits.
- Regulatory and procurement frameworks for compact, high-performance MLLMs (policy)
- What it could enable/workflow: Standards emphasizing verifiability (RLVR), dataset decontamination, auditability, and energy-efficient deployment for public-sector AI.
- Potential tools/products: Certification checklists; model cards emphasizing verifiable task performance; green-AI procurement criteria.
- Assumptions/dependencies: Multi-stakeholder consensus; reliable public benchmarks and auditing bodies; transparency around training data and reward models.
- “Trust-at-inference” pipelines combining verifiers and coordinated reasoning (cross-sector)
- What it could enable/workflow: Production patterns that automatically route uncertain cases to parallel reasoning, external verifiers, or humans.
- Potential tools/products: Confidence-aware routers; verifier ensembles for math/code/grounding; cost–latency controllers.
- Assumptions/dependencies: Accurate uncertainty estimates; scalable verifier availability; cost controls and SLAs.
- Domain-specialized compact MLLMs trained with verifiable-reward RL (academia/industry verticals)
- What it could enable/workflow: Replicate the Step3-VL-10B recipe to produce 10B-class models for legal, energy, aviation, or finance with domain-grounded rewards.
- Potential tools/products: Sector-specific assistants with strong small-model performance; verifiable compliance checkers.
- Assumptions/dependencies: Curated, legally clean, high-quality multimodal corpora; domain verifiers; ongoing RL iteration and governance.
- Advanced misinformation detection in multimodal media (platform integrity, public sector)
- What it could enable/workflow: Cross-check visual content, captions, and cited sources; detect fabricated references and incongruent figure–text pairs.
- Potential tools/products: Editorial and platform moderation coprocessors; newsroom investigation suites.
- Assumptions/dependencies: Access to trustworthy knowledge bases; low false positives; adversarial robustness.
- Human-in-the-loop evaluation standards for parallel reasoning (academia, standards bodies)
- What it could enable/workflow: Shared protocols and datasets to assess PaCoRe-like methods, hypothesis diversity, and synthesis quality.
- Potential tools/products: Open leaderboards for coordinated reasoning; diagnostics for ensemble-of-thought behaviors.
- Assumptions/dependencies: Community adoption; reproducible compute budgets; standardized reporting of inference-time cost.
Notes on cross-cutting feasibility
- Compute/latency: PaCoRe improves accuracy but raises inference cost; deploy selectively for hard or high-stakes queries.
- Safety/guardrails: Behavioral regularization (citation checks, language consistency, calibrated uncertainty) should be retained and extended in production.
- Data rights and privacy: Training and deployment must respect licensing and sensitive data handling; favor on-prem for regulated sectors.
- Evaluation drift: Maintain continuous evaluation, decontamination, and domain calibration to prevent silent regressions.
Glossary
- AdamW: A variant of the Adam optimizer that decouples weight decay from gradient-based updates to improve generalization. "optimized with AdamW~\citep{loshchilov2017adamw} (, , , and weight decay )"
- Advantage estimator: An estimator of how much better an action is compared to the expected value, used to reduce variance in policy gradient methods. "The advantage estimator for a state-action pair is defined as:"
- Batch-dimension parallelism: Executing operations in parallel across the batch dimension to improve throughput and avoid complexity from variable-length inputs. "This design leverages batch-dimension parallelism to sidestep the complexity of variable-length packing"
- Behavioral Regularization: Penalty-based constraints during RL to prevent unsafe or manipulative behaviors and stabilize training. "Behavioral Regularization. To mitigate ``reward hacking'' and enforce safety and reliability constraints during optimization, we incorporate a set of model-based penalty terms as behavioral regularization."
- Bounding-box-based grounding: Localizing objects or UI elements by predicting rectangular regions aligned to the target. "The dataset further includes over 19M grounding samples with both point-based and bounding-box-based grounding across diverse interface layouts and resolutions."
- Citation verification: Automatic checks that references or links are valid to reduce hallucinated citations. "apply strict citation verification that zeros the reward when fabricated references or links are detected"
- CLIP-based clustering: Using CLIP embeddings to cluster and balance concepts in data sampling. "To mitigate long-tail concept imbalance, we apply concept-balanced resampling via CLIP~\citep{radford2021clip}-based clustering."
- Code-switching: Inconsistent switching between languages in a response, often penalized for alignment. "we impose language consistency penalties to discourage code-switching and questionâanswer language mismatch"
- Concept-balanced resampling: Resampling strategy to balance underrepresented concepts in training data distributions. "To mitigate long-tail concept imbalance, we apply concept-balanced resampling via CLIP~\citep{radford2021clip}-based clustering."
- Cosine learning rate scheduler: A learning rate schedule that decays following a cosine curve, typically with warmup. "We employed a cosine learning rate scheduler with a $200$-step warmup phase"
- Epistemic calibration penalties: Penalties designed to discourage unjustified certainty and encourage calibrated uncertainty. "introduce epistemic calibration penalties to suppress unjustified certainty or overconfident claims"
- Generalized Advantage Estimation (GAE): A method to compute advantages that balances bias and variance using temporal smoothing. "We adopt PPO combined with GAE as our optimization algorithm for reinforcement learning"
- Generative Reward Modeling (GenRM): A preference-based model that scores generated responses by comparing them to teacher outputs and judging reasoning quality. "Generative Reward Modeling (GenRM). We adopt a pairwise preference framework where the GenRM evaluates rollouts against responses generated by a more capable teacher model."
- Grounding: Linking language outputs to precise visual locations or elements (points/boxes) for actionable perception. "Grounding data include both bounding-box-based and point-based annotations"
- GUI Grounding: Mapping UI elements to actions or coordinates to enable interaction with interfaces. "GUI Grounding: To evaluate actionable intelligence, we employ ScreenSpot-Pro~\citep{screenspot}, ScreenSpot-V2~\citep{wu2024atlas}, OSWorld-G~\citep{osworldg}, and MMBench-GUI~\citep{mmbenchgui}."
- Importance sampling: A technique to correct distribution mismatch between behavior and target policies in off-policy RL. "Concretely, we adopt a variant of PPO algorithm with GAE () for off-policy setting, omitting standard importance sampling."
- Intersection over Union (IoU): A metric for overlap between predicted and ground-truth regions, used in detection/grounding. "using metrics like Intersection over Union (IoU) or Euclidean distance."
- Mosaic augmentation: Data augmentation concatenating multiple images into one to increase content density and spatial reasoning. "Mosaic augmentation, in which four images are concatenated into a single input."
- Multi-agent synthesis: Combining outputs from multiple parallel reasoning agents to reach a coordinated conclusion. "we leverage PaCoRe to facilitate a form of multi-agent synthesis"
- Multi-crop strategy: Training with multiple crops of different scales per image to capture global and local details. "we adopt a multi-crop strategy~\citep{caron2021multicrop} that decomposes images into a global view and multiple local crops."
- Multimodal LLMs (MLLMs): LLMs that process and reason over multiple modalities such as text and images. "The development of Multimodal LLMs (MLLMs) has largely been driven by a relentless pursuit of scale."
- Non-Verifiable Rewards: Preference-based objectives for tasks without deterministic ground truth, guided by constraints and learned models. "Non-Verifiable Rewards: Preference and Constraints."
- Off-policy: Training where the data (behavior policy) differs from the current policy being optimized. "Concretely, we adopt a variant of PPO algorithm with GAE () for off-policy setting"
- On-policy: Training that uses data sampled from the current policy being optimized. "The model is optimized using PPO in a strict on-policy setting for 500 iterations."
- Optical Character Recognition (OCR): Extracting text from images or documents, often including layout and font variations. "\paragraph{Optical Character Recognition (OCR).} We curate a comprehensive OCR corpus spanning image-level and document-level text recognition, and visual-to-code reconstruction."
- PaCoRe (Parallel Coordinated Reasoning): A test-time reasoning paradigm that runs diverse parallel hypotheses and synthesizes them. "we implement Parallel Coordinated Reasoning (PaCoRe) to scale test-time compute"
- Parse-invariant evaluation: Evaluation that is robust to formatting differences, focusing on semantic equivalence rather than string match. "it provides parse-invariant evaluation that is resilient to formatting variations"
- Perception Encoder: A vision backbone optimized for language alignment to produce features compatible with a language decoder. "Step3-VL-10B integrates the 1.8B language-optimized Perception Encoder~\citep{bolya2025perception}"
- Preference models: Learned models that rank or score outputs based on human-like preferences. "we rely on learned preference models and heuristic constraints to guide human-centric alignment."
- Proximal Policy Optimization (PPO): A stable policy gradient RL algorithm using clipped objectives to limit policy updates. "We adopt PPO combined with GAE as our optimization algorithm for reinforcement learning"
- Projector: A module that maps visual features to the token space of a decoder, often compressing spatial information. "these components are bridged by a projector performing spatial downsampling via two consecutive stride-2 layers"
- Reinforcement Learning from Human Feedback (RLHF): RL using preference signals derived from human or teacher model judgments for open-ended tasks. "over 1k iterations of RL with both verifiable rewards (RLVR) and human feedback (RLHF)."
- Reinforcement Learning with Verifiable Rewards (RLVR): RL on tasks with deterministic ground truth using strict correctness signals. "over 1k iterations of RL with both verifiable rewards (RLVR) and human feedback (RLHF)."
- Reward hacking: Exploiting the reward function to achieve high scores without genuinely solving the task. "To mitigate ``reward hacking'' and enforce safety and reliability constraints during optimization"
- RoPE (Rotary Positional Embedding): A positional encoding technique that rotates embeddings to encode token positions. "utilize standard 1D RoPE~\citep{su2024roformer} for positional modeling"
- Rollouts: Multiple sampled trajectories/responses per prompt used for training, evaluation, or synthesis. "we perform 24 rollouts per prompt to identify some-accept samples"
- Sequential Reasoning (SeRe): A mode where the model thinks step-by-step before answering, often with explicit thought tags. "By default, the model uses Sequential Reasoning (SeRe), generating thoughts wrapped in > and tags"
- SFT (Supervised Finetuning): Post-training with labeled data to align model behavior before RL. "In the post-training stage, we adopt a two-stage Supervised Finetuning (SFT) strategy"
- Synthesis Filtration: A filtering step ensuring tasks remain non-trivial under parallel synthesis contexts. "Starting with the identified some-accept prompts, we apply a secondary Synthesis Filtration to ensure coordinated solvability"
- Stride-2 layers: Convolutional layers with stride 2 that downsample spatial dimensions by a factor of two. "two consecutive stride-2 layers"
- Spatial downsampling: Reducing the spatial resolution of feature maps to compress tokens while retaining salient information. "performing spatial downsampling via two consecutive stride-2 layers"
- Test-time compute: Additional inference-time computation (e.g., longer thoughts or parallel rollouts) used to improve final performance. "Step3-VL-10B scales test-time compute to bridge the perception and reasoning performance gap"
- Trajectory Modeling: Learning to perform sequences of UI actions grounded in perception for realistic human-computer interaction. "Trajectory Modeling. To model realistic sequential humanâcomputer interactions, we curate more than 2M trajectory samples"
- Truncated importance sampling ratio: A clipped ratio used to limit variance when correcting off-policy data. "we apply the truncated importance sampling ratio with threshold "
- Unified Pre-training: A single, synergistic pre-training stage that jointly aligns vision and language components. "Unified Pre-training on High-Quality Multimodal Corpus:"
- Variable-length packing: Packing sequences of different lengths efficiently for batched training without excessive padding. "batch-dimension parallelism to sidestep the complexity of variable-length packing"
- Value function: A learned estimator of expected return from a state used in advantage and policy optimization. "the value function is updated to minimize the mean squared error between the estimated value and a target value"
- Verifiable Rewards: Objective, correctness-based rewards for tasks with reliable ground truth and deterministic checks. "Verifiable Rewards: Precision and Consistency."
- Visual Question Answering (VQA): Tasks where a model answers questions about image content, integrating perception and reasoning. "Visual Question Answering (VQA)."
Collections
Sign up for free to add this paper to one or more collections.