AgentIR: Reasoning-Aware Retrieval for Deep Research Agents
Abstract: Deep Research agents are rapidly emerging as primary consumers of modern retrieval systems. Unlike human users who issue and refine queries without documenting their intermediate thought processes, Deep Research agents generate explicit natural language reasoning before each search call, revealing rich intent and contextual information that existing retrievers entirely ignore. To exploit this overlooked signal, we introduce: (1) Reasoning-Aware Retrieval, a retrieval paradigm that jointly embeds the agent's reasoning trace alongside its query; and (2) DR-Synth, a data synthesis method that generates Deep Research retriever training data from standard QA datasets. We demonstrate that both components are independently effective, and their combination yields a trained embedding model, AgentIR-4B, with substantial gains. On the challenging BrowseComp-Plus benchmark, AgentIR-4B achieves 68\% accuracy with the open-weight agent Tongyi-DeepResearch, compared to 50\% with conventional embedding models twice its size, and 37\% with BM25. Code and data are available at: https://texttron.github.io/AgentIR/.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper looks at how AI “research assistants” search the web to answer hard questions. These assistants don’t just type a short query like a person might. Before each search, they write down their thinking in plain language (their plan, what they’ve learned so far, and what they want next). The paper’s big idea is simple: use that thinking text to make search work better.
What questions did the researchers ask?
The researchers focused on two easy-to-understand questions:
- Can a search system do better if it reads the AI assistant’s reasoning (not just the short query)?
- How can we train such a search system when there isn’t much training data that includes both queries and the assistant’s reasoning?
How did they study it?
They built a new way to search and a way to create training data. Here’s the idea in everyday terms.
Key idea: Use the assistant’s reasoning, not just the query
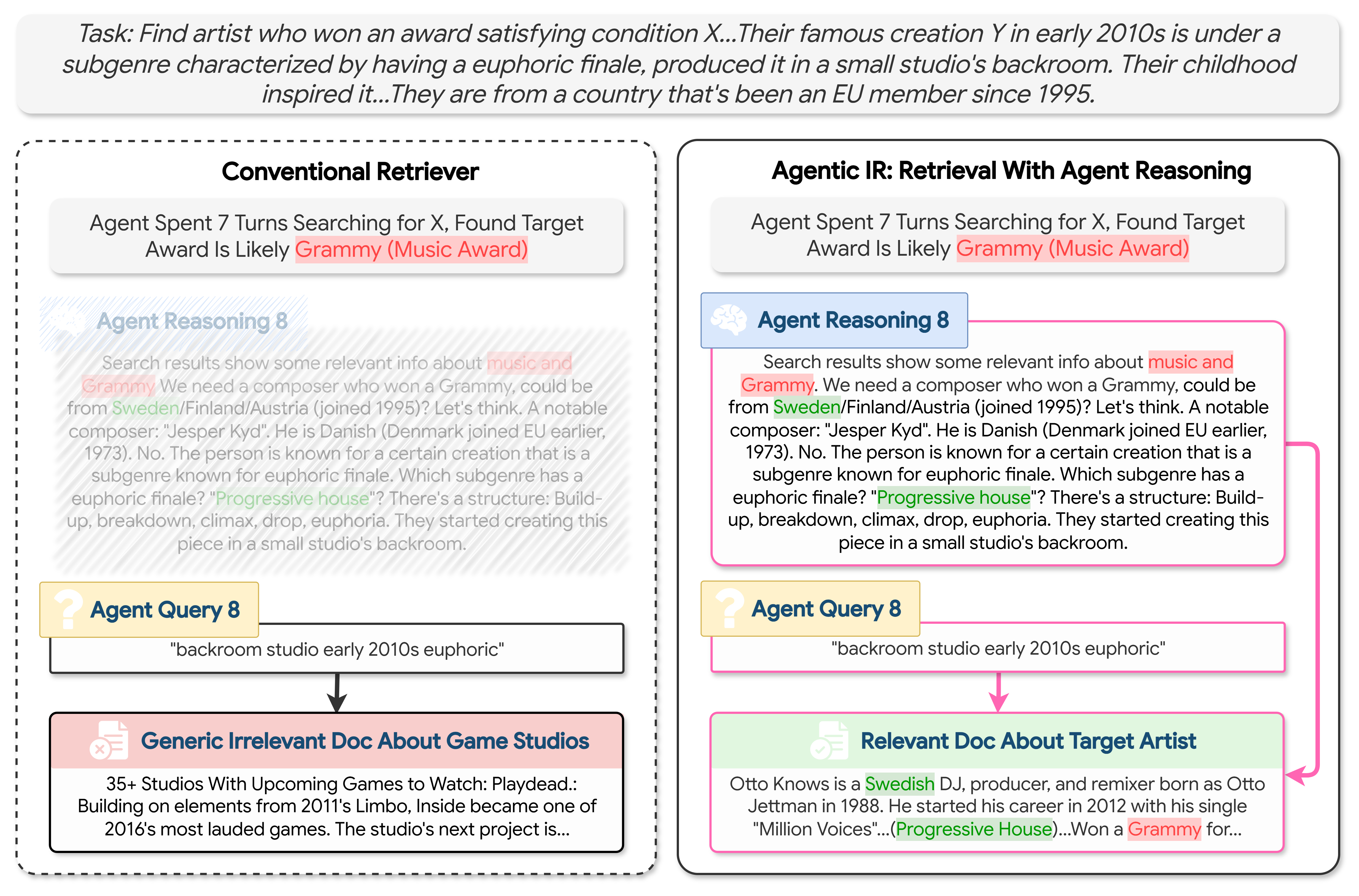
- Imagine you’re asking a librarian for a book. If you only say “euphoric backroom studio,” that’s vague.
- But if you add, “I’m trying to find a music producer from Sweden who won a Grammy and made a famous early-2010s track with a big uplifting ending, recorded in a studio’s back room,” the librarian will instantly understand your goal and find better results.
- The AI assistant already writes this kind of reasoning “for free” before it searches. The authors teach the search system to read both the query and the reasoning together, so it understands the purpose and context.
Training data: Creating practice examples for the search system
Real training sets rarely contain “assistant reasoning + sub-queries + which documents are relevant” for multi-step tasks. So the authors make their own:
- They start with regular question-answer data (big questions, correct answers, and documents that support those answers).
- They let a research agent try to solve each big question step by step. At every step, they collect the agent’s reasoning and the short query it issued.
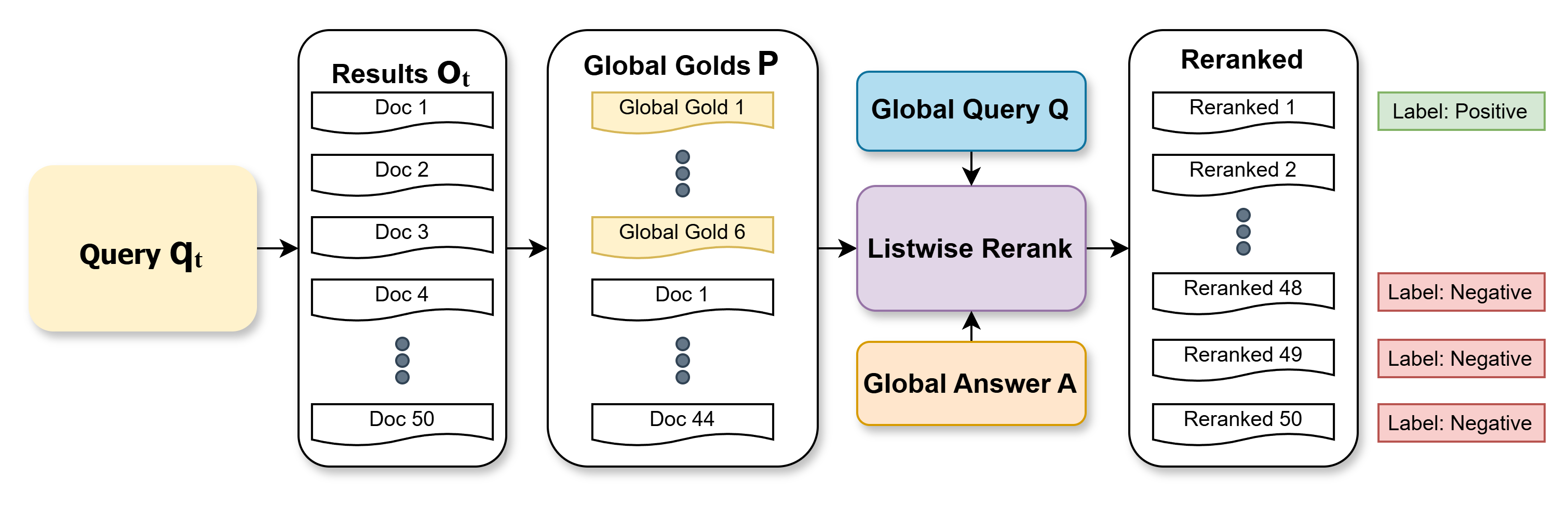
- To label which documents are most helpful for each step, they:
- Pull a bunch of candidate documents from a normal search.
- Mix in documents known to be useful for the overall question.
- Ask a LLM to re-rank these documents for the current step, making sure they still fit the big question and its correct answer.
- Use the top document as the “positive” example and some low-ranked ones as “hard negatives.”
This creates many training examples like: “reasoning + query” → “good doc” vs. “bad docs.”
Teaching the search system to match the right documents
- The search system turns text into a kind of “digital fingerprint” (called an embedding) so it can measure how similar a query is to a document.
- They train it with a simple rule: pull the “reasoning + query” closer to the correct document and push it away from the wrong ones. You can think of this like practicing with flashcards—get rewarded for matching the right pairs and corrected for mixing them up.
What did they find?
The main results (on a tough benchmark where tasks often need 20+ searches) are clear and important:
- Using the assistant’s reasoning plus the query beats traditional methods that use the query alone.
- Their trained model answered about two-thirds of the questions correctly (around 66–68%) when paired with a strong open-source research agent. That’s much better than:
- A popular old-school keyword search (about 37%).
- A strong modern embedding model that’s twice as big (about 50%).
- It also needed fewer searches to finish a task (roughly 20% fewer steps than some baselines), which saves time and computing.
- Even expensive add-on tricks like having another AI re-rank top results didn’t close the gap—their approach still did better by roughly 10 percentage points.
- The gains worked across different research agents, not just the one used for training, which suggests the idea is robust.
They also studied why this works:
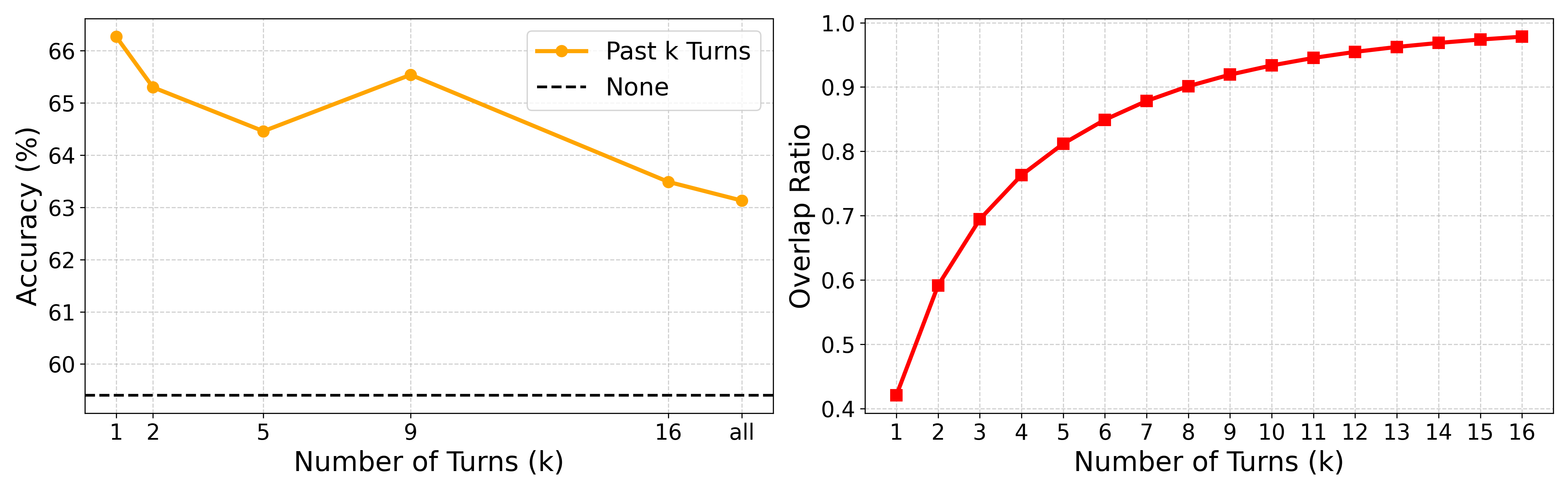
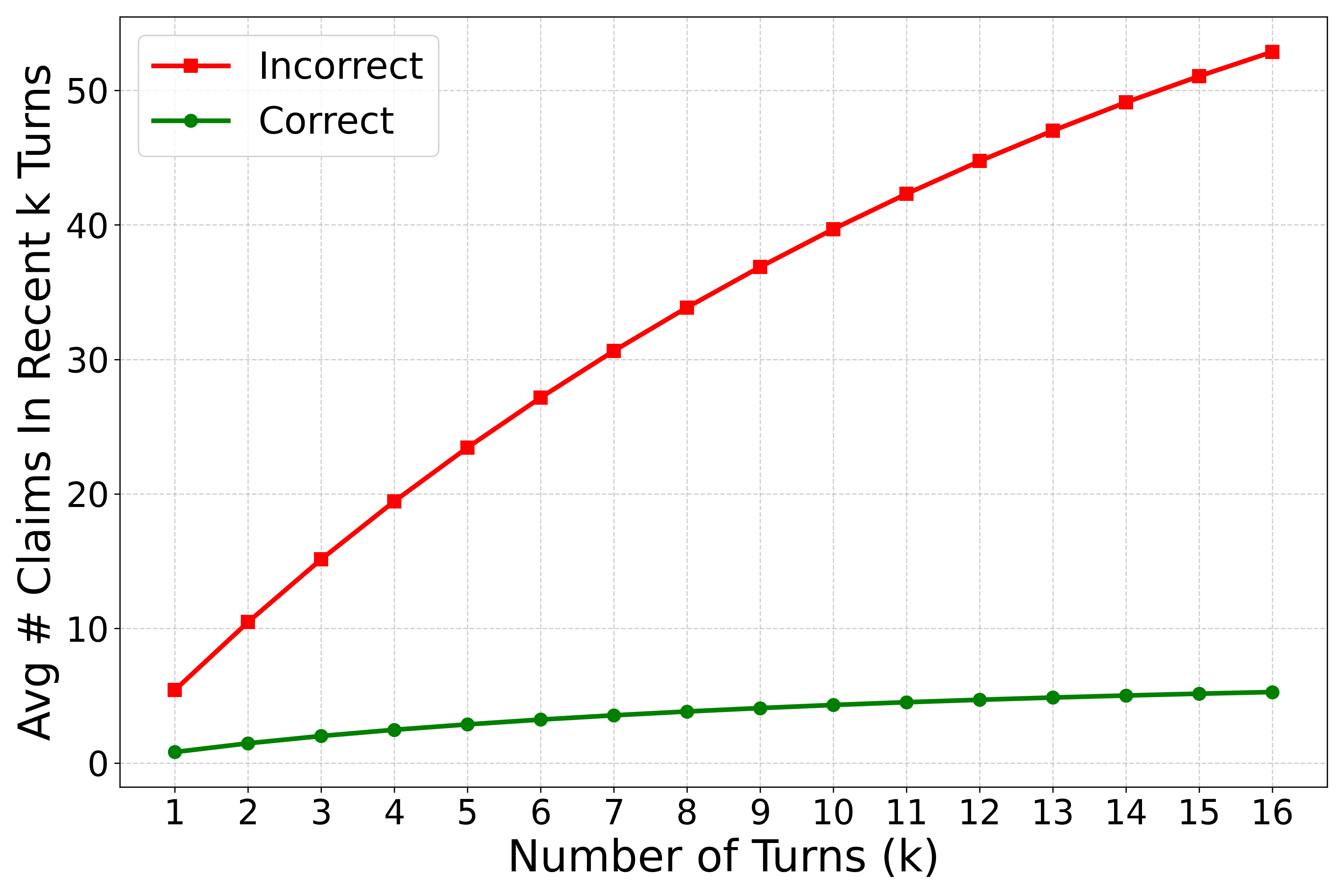
- The reasoning explains the task’s intent, remembers what was already found, and suggests smart next guesses—so the search knows exactly what to look for.
- Surprisingly, using only the most recent reasoning worked best. Packing in the entire history (all earlier thoughts and documents) often added noise like old wrong guesses. The latest reasoning tends to summarize what’s important and quietly drop bad leads—like a cleaned-up to-do list.
Why does this matter?
As AI assistants take on more complex “deep research” (think: multi-step investigations instead of single quick answers), they become the main users of search. This paper shows a practical way to make search engines work better for them:
- It boosts both accuracy and speed without extra costs, because it reuses the reasoning the agent already writes.
- It suggests a new direction called “context engineering” for search: carefully choosing which parts of the agent’s ongoing thinking to include can make search smarter and less distracted.
- In short, teaching search engines to “listen” to the agent’s thought process can make future AI research tools more reliable, efficient, and helpful for big, complicated questions.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased to be concrete and actionable for follow-up research.
- External validity beyond a single benchmark
- Validate zero-shot generalization across multiple Deep Research benchmarks (e.g., WebArena variants, Search-R1 tasks), domains (biomedical, legal, code), and corpora sizes (enterprise/private indexes vs. open web).
- Assess cross-lingual/multilingual effectiveness when agent reasoning and the target corpus are in different languages.
- Scalability and systems considerations
- Quantify the computational overhead of embedding longer inputs (reasoning + query) at inference time, including latency, throughput, and cost vs. query-only baselines.
- Stress-test at web scale (hundreds of millions to billions of documents) and report retrieval quality vs. index size; clarify how the method behaves under large candidate pools and document-length variability.
- Examine streaming or rapidly-changing corpora (freshness) and whether reasoning-augmented queries remain stable under document churn.
- Dependence on high-quality reasoning traces
- Measure robustness when agent reasoning is noisy, minimal, or systematically wrong (e.g., with weaker/cheaper agents, or under adversarial prompt injection).
- Evaluate performance on failed or flailing trajectories (not only “successful” rollouts), and develop mechanisms to detect and correct misleading reasoning at retrieval time.
- Test sensitivity to reasoning verbosity/style (short summaries vs. long chain-of-thought), including truncation effects and token-budget constraints.
- Training data synthesis pipeline limitations
- Remove or ablate access to the gold answer and dataset positives during label generation to avoid unrealistic supervision leakage; measure performance drop and propose answer-free supervision.
- Replace LLM-based oracle reranking with weaker or differently-parameterized rankers to quantify labeler-induced bias and noise; study inter-labeler consistency and effects on retriever calibration.
- Move beyond single-positive labeling (top-1 as ) to multi-positive supervision and harder negative mining beyond the bottom-7 heuristic; assess impact on recall/precision trade-offs.
- Analyze selection bias from training only on successful rollouts; include partial/failed runs and study curriculum or rejection-sampling alternatives that improve robustness.
- Method design choices left unexplored
- Compare simple concatenation to architectures that explicitly model fields (separate encoders for and with gating/attention or late interaction such as ColBERT); learn weighting between reasoning and query.
- Explore structured “intent/constraints/hypotheses” extraction from reasoning and its targeted use for retrieval (fielded retrieval or controlled expansion).
- Investigate dynamic “context engineering” policies that learn what subset of the history to include (summarization, deduplication, contradiction filtering), rather than fixed -turn windows.
- Examine hybrid pipelines that add an efficient second-stage reranker on top of the proposed retriever to test whether gains are complementary.
- Generalization across agents and co-adaptation
- Test with a broader and more diverse set of agents (closed-source, smaller/larger models, RL-tuned vs. purely SFT) and quantify performance vs. reasoning style/quality distributions.
- Study joint or alternating training of the retriever and the agent policy (e.g., RL with retrieval-in-the-loop) to mitigate co-adaptation issues and reduce reliance on fixed agent idiosyncrasies.
- Evaluation gaps
- Report standard retrieval metrics (MRR@n, nDCG@n, precision/recall at various k) per-turn and overall, alongside end-to-end accuracy; provide error taxonomies (missed constraints, wrong entity, off-topic retrieval).
- Measure efficiency metrics end-to-end (token counts, GPU time, memory) and report variability across tasks; quantify how many fewer steps are attributable to better retrieval vs. easier tasks.
- Validate with human judgments (not only LLM-as-judge) for both final answers and document relevance to reduce evaluation bias.
- Data and potential leakage
- Clarify and audit corpus overlap between training (WebShaper-derived) supervision and the BrowseComp-Plus evaluation corpus; provide leakage analyses and use timestamped snapshots.
- Test on private/enterprise datasets to ensure findings are not specific to open-web distributions.
- Robustness and safety
- Evaluate susceptibility to adversarial or poisoned pages that target common agent reasoning phrases; design defenses (adversarial training, lexical diversity constraints, anomaly detection).
- Address privacy risks of sending full agent reasoning to a retrieval service; explore on-device retrieval, redaction, or secure computation that preserves reasoning utility without exposing sensitive content.
- Data scaling laws and ablations
- Provide performance vs. training-size curves (beyond 5,238 instances); assess diminishing returns and label quality vs. quantity.
- Analyze the effect of alternative negative sampling strategies (in-batch hard negatives, cross-corpus negatives) and temperature/margin choices in the contrastive loss.
- Interaction with query expansion and conversation context
- Compare against stronger conversational rewriting baselines that incorporate selective history rather than full history; test multi-query retrieval and fusion-in-decoder with reasoning-aware queries.
- Examine whether hypothetical expansions (e.g., HyDE) become useful if conditioned on agent state (history-grounded HyDE) rather than parametric-only hypotheses.
- Practical deployment questions
- Determine policies for when to include reasoning (always vs. confidence-triggered); learn a gate that decides if reasoning helps for a given .
- Study privacy-preserving summaries (e.g., PII-masked or constraint-only summaries) that retain retrieval gains while reducing risk.
- Provide guidelines for integrating with production search stacks (indexing granularity, snippet vs. full-doc retrieval, caching strategies for repeated reasoning patterns).
Practical Applications
Immediate Applications
The following use cases can be deployed now by adapting existing RAG/deep-research agents to pass their current “reasoning trace” along with each sub-query to the retriever, or by fine-tuning a domain retriever using the paper’s data synthesis pipeline.
- Enterprise knowledge search and support (software/enterprise)
- Use case: Internal agents answering employee questions across wikis, tickets, and docs; helpdesk copilots that chain multiple searches. Jointly embedding current reasoning + query improves hit quality and reduces the number of search calls.
- Tools/workflows: Drop-in “reasoning-aware retriever” for LangChain/LlamaIndex-style agents; vector DB storing document chunks; concatenate [reasoning || query] before embedding; optional fine-tuning via the paper’s contrastive setup.
- Dependencies/assumptions: Agents must expose current reasoning (ReAct-style scratchpad or “intent summary”); corpora indexed as chunks; privacy controls for storing/transporting traces.
- Customer support and troubleshooting copilots (software/telecom/consumer electronics)
- Use case: Multi-step diagnosis (e.g., device/network issues) where queries are ambiguous but the reasoning captures hypotheses and prior findings, yielding better retrieval than query-only or HyDE expansions.
- Tools/workflows: Existing support bots pass reasoning + query to retriever; telemetry and prior results summarized in the reasoning; monitor search calls and recall.
- Dependencies/assumptions: Access to structured logs and KBs; ability to redact PII in traces; guardrails to avoid amplifying incorrect early hypotheses.
- Legal and compliance research (legal/finance)
- Use case: Multi-hop queries (e.g., find cases satisfying X, Y, Z) benefit from reasoning’s narrowing constraints and reflection on prior results, reducing time-to-answer and false positives.
- Tools/workflows: Reasoning-aware retrieval over case law/regs; store retrieval + reasoning logs for auditability; optional rerank only for final bundles if needed.
- Dependencies/assumptions: High-quality corpora and citations; trace retention policies; legal review for storing reasoning content.
- Scientific literature review and evidence synthesis (healthcare/research/biotech)
- Use case: Systematic searches where the agent iteratively refines inclusion/exclusion criteria and sub-questions; reasoning traces encode criteria that guide retrieval more precisely than queries alone.
- Tools/workflows: PubMed/PMC index; PRISMA-like workflows; reasoning-aware retriever; exportable trails for audit and reproducibility.
- Dependencies/assumptions: Access to full-text or high-quality abstracts; strong de-duplication; curation to prevent sensitive patient info in reasoning.
- Clinical decision support and pharmacovigilance triage (healthcare)
- Use case: Bedside agents or safety teams searching for specific adverse-event patterns or guideline clauses; reasoning conveys patient/context constraints that disambiguate queries.
- Tools/workflows: EHR-derived contexts summarized into short “search intent” strings; reasoning-aware retrieval over guidelines/drug labels; human-in-the-loop validation.
- Dependencies/assumptions: Strict PHI redaction; secured on-prem deployment; domain-tuned embeddings.
- Software engineering assistants (software/devtools)
- Use case: Code agents that iteratively form hypotheses about APIs, versions, or patterns; reasoning-aware retrieval over repos, docs, issues accelerates navigation and reduces pointless searches.
- Tools/workflows: Index code + docs; pass current plan/hypotheses + sub-query; logging search-call reductions as a KPI.
- Dependencies/assumptions: Up-to-date code index; context windows allowing longer inputs; permissioning across repos.
- Newsroom fact-checking and investigative workflows (media)
- Use case: Agents triangulate claims by iteratively refining what to look for; reasoning includes refutations and confirmations that increase retrieval precision.
- Tools/workflows: Index archives, public records, social posts; chain searches using reasoning-aware retrieval; flagged claims and retrieved evidence packaged for editors.
- Dependencies/assumptions: Provenance scoring; robust deduplication; policies for storing sensitive hypotheses.
- Market and competitive intelligence (finance/enterprise)
- Use case: Multi-constraint searches on companies/products (e.g., award history + launch timing + geography) benefit from the reasoning signal to target narrower document sets.
- Tools/workflows: Crawl/news/filings index; agents maintain running hypotheses; reasoning-aware retrieval reduces noisy hits; dashboards track recall vs. search calls.
- Dependencies/assumptions: Licensing for news/filings; bias controls; human review for material significance.
- Education and learning assistants (education)
- Use case: Research helpers that scaffold multi-step questions; reasoning captures learner’s evolving focus, improving retrieval of relevant readings/examples.
- Tools/workflows: Course content index; student agent passes step-by-step intent + query to retriever; formative feedback grounded in retrieved content.
- Dependencies/assumptions: Age-appropriate safeguards; academic integrity policies; content alignment.
- Procurement and policy analysis in government (public sector/policy)
- Use case: Multi-hop policy/contract queries where the reasoning narrows agencies, timelines, and clauses; fewer turns to reach the right documents.
- Tools/workflows: Index RFPs/contracts/regs; reasoning-aware retrieval with exportable audit trails; cross-document link graphs.
- Dependencies/assumptions: FOIA-sensitive materials redacted; chain-of-thought storage policies; change management.
- Low-lift upgrade for existing agents (cross-sector)
- Use case: Even without fine-tuning, concatenating [current reasoning + query] to the existing embedding model yields immediate gains (per ablations).
- Tools/workflows: Simple wrapper around your retriever call; A/B test on accuracy/recall/search calls; no extra LLM expansion calls.
- Dependencies/assumptions: Agent must output a concise reasoning or “intent summary”; ensure model input length and tokenizer budget.
Long-Term Applications
These opportunities may require further research, scaling, domain adaptation, or ecosystem standards before broad deployment.
- Standardized “reasoning-aware search” protocol (software/search)
- Vision: A cross-vendor API where agents pass a structured intent schema (task intent, constraints, prior findings, hypotheses) to search providers; retrievers learn to weight fields.
- Potential products: Open schema and SDKs for agent-to-search interfaces; vector DBs supporting multi-field embedding fusion.
- Dependencies/assumptions: Industry consensus on intent schema; privacy standards for transmitting agent traces.
- Co-trained agent–retriever systems with context engineering (software/IR)
- Vision: Jointly optimizing agents and retrievers so agents produce curated, noise-minimized “search intents,” while retrievers learn to trust/discount uncertain hypotheses.
- Potential products: RL or direct-preference-optimized co-training pipelines; automatic curation modules that summarize recent history for retrieval.
- Dependencies/assumptions: Reliable noise labeling and uncertainty estimation; compute for joint training; stable evaluation suites.
- Privacy-preserving reasoning summaries (healthcare/finance/public sector)
- Vision: On-the-fly redaction and abstraction of traces into compliant intent summaries (exclude PHI/PII/proprietary info) without degrading retrieval gains.
- Potential products: Trace sanitizer/intent summarizer; compliance dashboards linking summaries to retrieved evidence.
- Dependencies/assumptions: High-precision redaction; regulator acceptance; alignment with evolving chain-of-thought disclosure norms.
- Foundation retrieval models trained on agent traces (software/AI platforms)
- Vision: General-purpose embedding models pre-trained on diverse agent reasoning traces across domains, outperforming task-specific fine-tunes.
- Potential products: Open-weight “Agent-IR” family; adapters for sector-specific corpora (EHR, code, legal).
- Dependencies/assumptions: Large-scale, consented trace datasets; robustness to stylistic variance across agents; domain adaptation methods.
- Search engines and browsers natively supporting agent users (consumer/enterprise)
- Vision: Web search that accepts agent rationales as first-class inputs, prioritizing pages consistent with multi-turn goals and prior findings.
- Potential products: “Agent mode” in search; browser extensions exposing an agent’s current plan to the search bar for better ranking.
- Dependencies/assumptions: User and site privacy; abuse prevention; publisher ecosystem buy-in.
- Regulated-industry auditability via trace–retrieval pairing (finance/healthcare/legal)
- Vision: End-to-end audit logs pairing reasoning snapshots with retrieved evidence at each step to explain outcomes (e.g., suitability, clinical recommendations).
- Potential products: Compliance-ready agent frameworks; time-stamped, immutable retrieval trails; explainability tooling.
- Dependencies/assumptions: Legal clarity on storing/using reasoning traces; standardized evidence sufficiency criteria.
- Multi-agent orchestration using shared reasoning-aware retrieval (software/automation)
- Vision: Teams of specialized agents share succinct, curated search intents to coordinate literature, code, and data retrieval without cross-agent noise explosions.
- Potential products: Orchestrators that merge and reconcile intents; retrieval conflict resolution and deduplication services.
- Dependencies/assumptions: Protocols for trust and confidence signals; scalable context merging; error propagation controls.
- Robotics and operations procedure look-up (robotics/industrial/energy)
- Vision: Embodied agents use high-level plan traces to retrieve procedures, safety constraints, and equipment manuals in dynamic environments.
- Potential products: On-device reasoning-aware retrievers; procedure compliance monitors that align actions with retrieved SOPs.
- Dependencies/assumptions: Robust on-device indexing; latency constraints; safe handling of ambiguous or conflicting instructions.
- Personalized, on-device retrieval for consumer assistants (consumer/daily life)
- Vision: Private agents that use reasoning-aware retrieval over personal knowledge (email, notes, files) to plan travel, projects, and purchases with fewer missteps.
- Potential products: Local vector stores with intent-aware indexing; privacy-first reasoning summarizers; cross-app search orchestrators.
- Dependencies/assumptions: Strong on-device models; permissioned data access; user control over trace retention.
- Hallucination-aware weighting and trust calibration (software/AI safety)
- Vision: Retrievers that detect and down-weight unverified hypotheses in reasoning traces (learned from noise analyses like those in the paper), improving robustness.
- Potential products: Uncertainty-aware embeddings; calibration modules that score segments of reasoning by reliability before embedding.
- Dependencies/assumptions: Gold labels for correctness of hypotheses; integration with verifier/reranker models.
- Domain generalization and continual learning from live agent traces (cross-sector)
- Vision: Continually improve retrievers as agents solve tasks, using successful trajectories to synthesize new (reasoning, query, doc) training pairs.
- Potential products: Online learning pipelines; trace-to-training data transformers; adaptive retrieval governance.
- Dependencies/assumptions: Safe data collection with consent; drift detection; safeguards against feedback loops.
Notes across applications:
- The method reduces cost and latency by avoiding extra LLM calls for query expansion (e.g., HyDE), leveraging traces already produced by the agent.
- Best results come from using the current turn’s reasoning; adding long histories can introduce noise unless curated (“context engineering”).
- Feasibility hinges on having agents that output usable reasoning or intent summaries; where chain-of-thought is restricted, structured “search intent” fields can be used as a substitute.
- Quality of the underlying index and the ability to fine-tune embeddings with synthesized data are key drivers of performance.
Glossary
- Agent rollouts: Executions of an agent to generate trajectories used for data creation or evaluation. "we propose , a data synthesis pipeline that generates sub-query level retriever training data from standard QA datasets by leveraging agent rollouts."
- BM25: A classic sparse retrieval algorithm that scores documents based on term frequency and inverse document frequency with length normalization. "the classic sparse retriever BM25~\citep{bm25}"
- Contrastive learning loss: A training objective that pulls positive pairs closer and pushes negative pairs apart in the embedding space. "We achieve this using a standard contrastive learning loss~\citep{contrastive_learning}:"
- Cosine similarity: A metric measuring the cosine of the angle between two vectors, often used to compare embeddings. "..., denotes cosine similarity, and is the temperature used."
- Dense retriever: A retrieval model that embeds queries and documents into a dense vector space for similarity search. "a strong dense retriever Qwen3-Embedding-8B~\citep{qwen3-embed},"
- Global question: The original task-level question in multi-hop QA from which sub-queries are derived. "Traditional QA and single-turn information retrieval datasets provide triples consisting of a global question , an answer , and a set of positive documents sufficient to answer "
- Hard negatives: Challenging non-relevant documents that are difficult to distinguish from positives and are used to improve training. "Label the top-ranked document as the positive document for turn , and the bottom seven documents as hard negatives ."
- HyDE: A query expansion approach that uses an LLM to hypothesize relevant content from parametric knowledge. "To mitigate this, query expansion methods such as HyDE~\citep{hyde} prompt an LLM to interpret an ambiguous query, and enrich it with hypothetical context from parametric knowledge."
- LLM-as-judge: An evaluation setup where a LLM judges the correctness of answers. "we report end-to-end QA Accuracy following the same LLM-as-judge setup as BrowseComp-Plus,"
- LLM-based reranking: Reordering retrieved documents using a LLM to improve ranking quality. "It also outperforms computationally intensive methods such as LLM-based reranking by 10\% absolute."
- Listwise reranking: A reranking approach that considers a list of documents jointly rather than pairwise or pointwise. "Prompt an LLM to perform listwise reranking~\citep{rankgpt, lrl} over the candidate pool."
- Oracle reranking: A reranking procedure that uses privileged information (e.g., gold answers) to produce high-quality labels or rankings. "we refine the candidate ranking with an oracle reranking procedure, and derive labels from the refined ranking:"
- Parametric knowledge: Information encoded in the parameters of a LLM rather than provided explicitly in the context. "Further, drawing from its parametric knowledge, the agent hypothesizes that a subgenre with a
euphoric finale'' is likelyprogressive house,'' which turns out to be correct." - Query expansion: Techniques that augment or reformulate a query to improve retrieval effectiveness. "To mitigate this, query expansion methods such as HyDE~\citep{hyde} prompt an LLM to enrich ambiguous queries with hypothetical relevant content;"
- ReAct-style: An approach that interleaves reasoning and acting (tool use) in LLM agents. "we formulate Deep Research as a ReAct-style~\citep{react} loop,"
- Reasoning trace: The explicit natural language chain of thought produced by an agent that explains its decisions or queries. "At each turn , the LLM's policy generates a reasoning trace and an action conditioned on the interaction history"
- Retrieval-Augmented Generation (RAG): A paradigm where generation is supported by retrieving external documents relevant to the query. "Recently, Retrieval-Augmented Generation (RAG)~\citep{rag,rag2} has evolved from single-turn retrieve-then-answer pipelines to LLMs that autonomously conduct multi-turn searches through test-time scaling to solve complex problems~\citep{selfrag}."
- Search call: An agent action that queries a retriever to obtain documents during problem solving. "Deep Research agents generate explicit, natural language reasonings before every search call."
- Sparse retriever: A retrieval model that represents texts as sparse term vectors (e.g., bag-of-words) and uses lexical matching. "the classic sparse retriever BM25~\citep{bm25}"
- Sub-query: A local, turn-level query issued by an agent that targets a specific part of the overall task. "there is currently no retriever training data tailored to sub-queries 's in multi-turn Deep Research."
- Temperature (in contrastive learning): A scaling factor in the softmax of contrastive objectives that controls the sharpness of similarity distributions. "and is the temperature used."
- Test-time scaling: Increasing an agent’s performance by allowing more steps or computation during inference rather than changing training. "LLMs that autonomously conduct multi-turn searches through test-time scaling to solve complex problems~\citep{selfrag}."
- Trajectory (of an agent): The sequence of reasonings, actions, and observations an agent experiences over multiple turns. "The agent's behavior can be represented as a trajectory of turns:"
- Zero-shot: Evaluating or applying a model to tasks it was not explicitly trained on. "First, it is trained on WebShaper queries, making the improvements on BrowseComp-Plus zero-shot."
Collections
Sign up for free to add this paper to one or more collections.