Post-Training with Policy Gradients: Optimality and the Base Model Barrier
Abstract: We study post-training linear autoregressive models with outcome and process rewards. Given a context $\boldsymbol{x}$, the model must predict the response $\boldsymbol{y} \in YN$, a sequence of length $N$ that satisfies a $γ$ margin condition, an extension of the standard separability to sequences. We prove that on test samples where the base model achieves a non-trivial likelihood $α$, a variant of policy gradient (PG) can achieve likelihood $1 - \varepsilon$ with an essentially minimax optimal number of reward queries $\tilde{O}((α{-1} + \varepsilon{-1})/γ2)$. However, a barrier arises for going beyond the support of the base model. We prove that the overall expected error after post-training with outcome rewards is governed by a property of the base model called the Likelihood Quantile (LQ), and that variants of PG, while minimax optimal, may require a number of reward queries exponential in $N$ to go beyond this support, regardless of the pre-training algorithm. To overcome this barrier, we study post-training with a process reward model, and demonstrate how PG variants in this setting avoid the curse of dimensionality in $N$ via dependence on a token-level LQ. Along the way, we prove that under the margin condition, SGD with adaptive learning rate (LR) achieves a near optimal test error for statistical learning, and PG with adaptive LR achieves a near optimal number of mistakes for online learning while being computationally efficient whenever possible, both of which may be of independent interest.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big idea)
Imagine solving a puzzle that has N steps, like a combination lock with N dials and k options on each dial. A “base model” (the model before any extra training) already has some idea how to solve it. After that, we do “post‑training” to make the model better using trial‑and‑error feedback.
This paper asks: when can post‑training really make the model better, how fast, and what limits block improvement? The authors study a simple, math‑friendly version of a LLM to get clear answers, and they analyze two types of feedback:
- Outcome reward: you’re only told if the entire final answer is right or wrong (all dials set).
- Process reward: you get feedback at each step (each dial), so you know if you’re on the right track as you go.
Their main message: if you only get “right/wrong at the end,” there’s a built‑in barrier that often stops post‑training from going much beyond what the base model already knew—especially for long answers. But if you get step‑by‑step feedback, that barrier largely disappears.
What questions the paper tries to answer
- Q1: For post‑training with policy gradients (a common trial‑and‑error method), how many feedback queries and training steps are needed to improve the model, and how does this depend on the base model’s abilities?
- Q2: Can post‑training reduce the average test error (make fewer mistakes on new problems) much more than the base model—and still be efficient?
How they studied it (in everyday terms)
They simplify a LLM to focus on the last decision layer (think: the final stage that chooses the next word). The model writes answers one token at a time (autoregressive), like picking one dial after another on a lock.
Key ideas explained simply:
- Autoregressive sequence: the model picks the first token, then the second given the first, and so on until N tokens are chosen.
- Policy gradient (PG): a way to “nudge” the model’s choices in the direction that increases rewards (more correct answers), based on what it tried and how it scored.
- Margin (γ): at each step, there’s a “clear winner” token that’s better than the others by at least some amount γ. This makes learning possible and gives clean math guarantees.
- Outcome reward vs. process reward:
- Outcome reward (ORM): You only learn “correct” or “incorrect” after finishing the entire sequence. Like checking the full combination at the end.
- Process reward (PRM): You get a check at each step. Like a teacher telling you each dial setting is right or wrong as you go.
- Likelihood (chance of success): How likely the model is to produce the correct full answer for a given prompt.
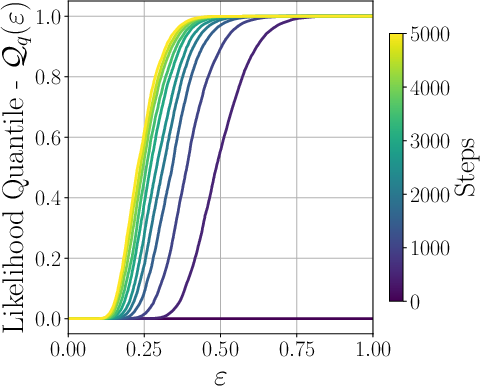
- Likelihood Quantile (LQ): A way to summarize the base model’s coverage: “for most prompts, how big is the chance the base model already gives the correct full answer?” It’s a curve that tells you how much of the test set has at least a certain likelihood.
- Token‑Level LQ (for PRM): Like LQ, but measured per token (per step). This is much easier to satisfy, because getting each step right is easier than getting the whole sequence right in one go.
They analyze policy gradient updates with different step‑size rules (learning rates), including an “adaptive” learning rate that takes smaller steps when gradients are large, which stabilizes training and speeds up convergence.
They also look at two scenarios:
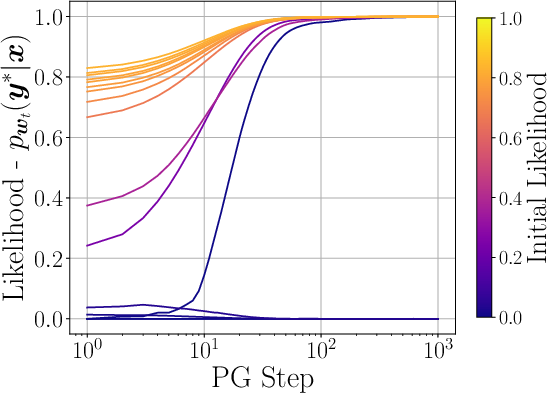
- On‑support: the base model already gives the correct answer a non‑tiny fraction of the time (likelihood α is not extremely small).
- Off‑support: the base model almost never gives the correct answer (likelihood ~ 0).
What they found (main results)
1) With only outcome rewards (end‑of‑answer feedback), improvement depends heavily on the base model
- If, for a given prompt, the base model already has a non‑trivial chance α of generating the correct full answer, policy gradient can boost that chance close to 1 using roughly proportional to 1/(α·γ²·ε) feedback queries to reach error ε. In plain words: if the base model is already “in the right neighborhood,” post‑training is efficient.
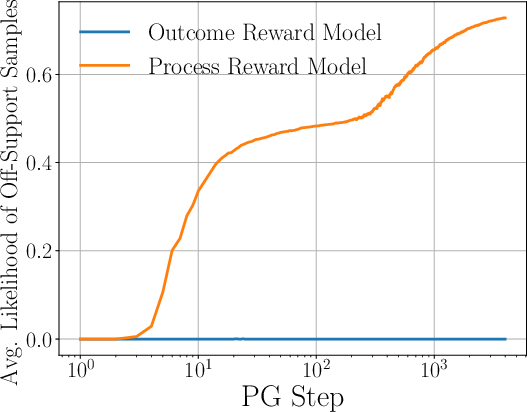
- But if the base model’s chance is basically zero (off‑support), then outcome‑only post‑training may need exponentially many tries in the sequence length N to find and reinforce the correct answer. This is the “base model barrier.”
- They formalize this barrier using the Likelihood Quantile (LQ). If the LQ is tiny (many prompts have near‑zero chance of being right under the base model), then no reasonable outcome‑only method can improve much without an exponential number of reward queries in N—no matter how you pre‑trained.
Why this matters: It explains why outcome‑only RL post‑training often “sharpens” what the base model already knows but struggles to create truly new capabilities when the base model is weak on those tasks.
2) With process rewards (step‑by‑step feedback), the barrier largely goes away
- If you can check each token as you generate it, you only need to explore at the token level. In the worst case, the number of reward queries grows roughly linearly with the sequence length N (and with k, the number of token choices), not exponentially with N.
- This improvement is captured by the Token‑Level LQ, which is typically much more favorable than full‑sequence LQ. Even a uniform base policy has token‑level coverage 1/k (not 1/kⁿ).
- Bottom line: process feedback allows policy gradient to find and reinforce the correct path step by step, avoiding the curse of dimensionality in N.
3) Good learning‑rate choices make a big difference
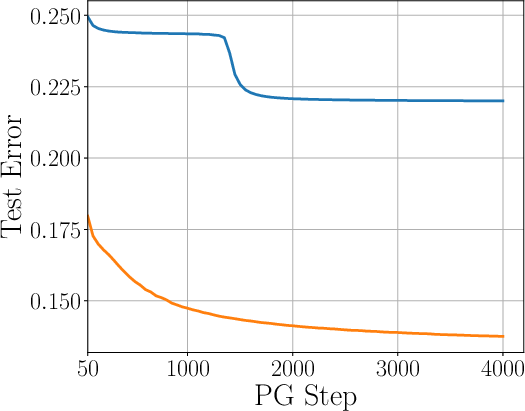
- Stochastic Gradient Descent (SGD) with an adaptive learning rate during pre‑training is near‑optimal in how fast test error goes down with more data—even for sequences.
- Policy gradient with an adaptive learning rate is also near‑optimal in how quickly mistakes decrease in online learning (where prompts can arrive one by one, even adversarially), and it’s computationally efficient.
4) Lower bounds (proofs of limits) show these results are tight
- The authors prove that their performance guarantees for policy gradient are essentially the best anyone can do in these settings (minimax optimal up to log factors).
- They also prove that no pre‑training method can, with only a small number of labeled examples, produce a base model that has strong full‑sequence LQ across the board. In other words, the base model barrier with outcome‑only feedback is fundamental, not an artifact of a particular algorithm.
Why these results are important
- Practical guidance: If you want post‑training to truly expand what a model can do (not just sharpen it), rely on process/step‑by‑step feedback when possible (like checking intermediate steps in math/code). Outcome‑only rewards (just “right/wrong” at the end) are often not enough unless the base model is already pretty good at the full task.
- Efficient strategies: Use adaptive learning rates in both pre‑training (SGD) and post‑training (policy gradients) to get near‑optimal progress. Consider exploration strategies that mix the base model with some randomness to cover more possibilities.
- Realistic expectations: The “base model barrier” explains many real‑world observations: outcome‑only RL often helps formatting, confidence, or sampling strategies but struggles to discover new, complex solutions when the base model didn’t cover them.
- Research implications: Building and using process reward models (PRMs) is a powerful way to overcome the curse of long sequences. Designing tasks and tools that give intermediate feedback can dramatically cut the number of required trials.
A short, plain‑language recap
- If you only get a thumbs‑up/thumbs‑down after finishing a long answer, learning new things is hard unless your base model already gets it right sometimes.
- If you get hints at each step (“this token is right/wrong”), learning becomes much easier and scales well with answer length.
- Smart step sizes (adaptive learning rates) help you reach the best‑possible speed of improvement.
- These are not just suggestions—they come with proofs, including limits showing you can’t consistently beat these strategies by a lot.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper establishes sharp, largely minimax-optimal results for linear autoregressive models under strong assumptions. Below is a consolidated list of concrete gaps and open problems that remain unresolved and could guide future work:
- Assumption realism: Extend all guarantees beyond the token-level separability/margin condition to non-separable, noisy-label, or Tsybakov-style margin regimes; quantify how rates degrade without hard margins.
- Multiple valid outputs: Generalize the theory (ORM/PRM, LQ/TL-LQ, bounds and lower bounds) to settings where each prompt admits a set of acceptable responses rather than a unique y*, including partial credit.
- Noisy/verifier-imperfect rewards: Analyze robustness when ORM/PRM rewards are stochastic, biased, or adversarially misspecified; provide stability/consistency guarantees and adjusted lower bounds under reward noise.
- Feature learning vs. frozen features: Remove the “frozen feature map” assumption and analyze joint representation and policy learning (full-network training), including whether feature learning can overcome the base-model barrier.
- Variable-length generation: Formalize and prove versions of all results for variable-length sequences with EOS tokens and length-dependent rewards (rather than fixed N).
- Practical PG variants: Provide tight guarantees for on-policy PG (PPO/GRPO) with KL regularization, clipped ratios, entropy bonuses, and baselines/critics, beyond the ζ2 slow-down; identify optimal clipping/regularization schedules.
- Variance reduction: Determine whether using learned baselines/critics or generalized advantage estimators can provably improve constants or relax assumptions in the presented bounds.
- High-probability guarantees: Strengthen expectation bounds (test error, mistake counts, query complexity) to high-probability, anytime guarantees that are important for deployment.
- Initialization: Extend analysis from w0=0 to realistic initialization from a nontrivial base model; quantify how starting weights affect rates and the conditioning on initial likelihood.
- Estimating LQ/TL-LQ: Develop practical, label-efficient estimators (with confidence intervals) for LQ and token-level LQ from rollouts without privileged access to y*, and adaptive strategies to set m online.
- Off-support exploration: Identify structural conditions (e.g., compositionality, low effective branching, program syntax constraints) under which exponential-in-N barriers for ORM can be circumvented; provide corresponding algorithms and proofs.
- Structured action spaces: Generalize TL-LQ to constrained decoding (grammar, type systems, compiler constraints) that reduce the effective k and study how this changes minimax rates.
- Cost models and wall-clock: Incorporate compute, latency, and verifier cost into complexity measures (beyond iteration/reward-query counts); derive optimal allocations of gradient steps vs. reward queries under budget constraints.
- Learning PRMs: Quantify the sample/label complexity and error propagation for learning process reward models from data; trade-offs between PRM quality and overall query/sample complexity.
- Partial/process shaping: Replace the strict prefix-correctness PRM with weaker but more realistic process rewards (heuristic or learned step-level signals) and analyze how guarantees degrade gracefully.
- Domain shift: Study how LQ/TL-LQ and the base-model barrier behave under distribution shift between pre-training and post-training prompts; propose adaptation methods with provable guarantees.
- Deterministic model selection: Replace the random-iterate or averaging selection with deterministic selection rules at test time (e.g., last iterate), preserving rates.
- Minibatching and parallelism: Analyze minibatched PG/SGD variants and the effect of parallel rollouts on rates and query complexity in both ORM and PRM settings.
- Tokenization effects: Quantify sensitivity to vocabulary size and tokenization (subword vs. character), and redesign TL-LQ to reflect the “effective” branching factor under modern tokenizers.
- KL-regularized objectives: Re-derive results for objectives with an explicit KL penalty to the base policy (as in PPO/GRPO) and clarify how the penalty trades off with exploration and convergence.
- Best-of-m practicality: Replace the need for known Qq(·)/QqTL(·) with adaptive m-tuning methods (e.g., bandit or quantile-estimation schemes) and analyze their regret and sample/query complexity.
- Beyond worst-case lower bounds: Identify natural problem classes (e.g., sparse or low-rank features, low-entropy outputs) where polynomial-time, off-support learning under ORM is information-theoretically possible; give tight bounds.
- Empirical verification at scale: Validate LQ/TL-LQ, the base-model barrier, and PRM benefits on real LLMs and tasks (math/coding/NL reasoning), including methods to estimate these quantities in practice.
- Combining SGD and PG optimally: Find principled schedules that jointly allocate supervised samples (pre-training) and PRM/ORM queries (post-training) to minimize total cost for a target error, especially when adaptive-LR SGD already nears optimality.
- Constants in tilde bounds: Make hidden polylog factors and constants explicit to guide practical hyperparameter choices (learning rates, m, mixing weights, clipping levels).
- Multi-output/structured correctness: Extend the framework to tasks with hierarchical correctness, intermediate subgoals, or graph/program outputs where correctness is not strictly prefix-based.
- Continuous/discrete hybrids: Explore extensions to continuous action spaces or mixed discrete–continuous outputs relevant to program synthesis with continuous parameters or tool-use settings.
Practical Applications
Immediate Applications
Below are concrete, deployable uses of the paper’s findings and methods, organized by sector and accompanied by likely tools/workflows and key assumptions.
- LQ-driven RL gating and budgeting for post-training of LLMs (software/AI)
- What: Measure the base model’s Likelihood Quantile (LQ) and token-level LQ to decide whether to use outcome-reward RL (ORM) or process-reward RL (PRM), and to size the number of reward queries and iterations.
- Tools/workflows:
- LQ/Token-LQ analyzer that computes empirical CDFs/quantiles of ground-truth likelihoods under the base model and per-token likelihoods.
- A training scheduler that switches to PRM if the target error is below the “base model barrier” threshold ε < Qq−1(k−N) or if long sequences make outcome-only RL inefficient.
- Assumptions/dependencies: Ability to compute likelihoods under the base model (access to logits/probs); approximate separability (margin γ > 0) and i.i.d. prompts.
- Best-of-m exploration policy for RL post-training (software/AI; coding, math)
- What: Implement the paper’s best-of-m exploration (mixture of base model and uniform) to reduce iteration/sample complexity while controlling reward-query cost.
- Tools/workflows:
- Behavior policy library (mixture sampler + uniform fallback) with a tunable m.
- Query-budget manager that sets m ≈ min(Qq((1−o(1))ε)−1, kN) for ORM or m ≈ min(QTL q ((1−o(1))ε)−1, k) for PRM.
- Assumptions/dependencies: Access to base-model sampling; reliable verifiers; compute budget for multiple proposals per prompt.
- Adaptive-learning-rate policy gradient (PG) for online/autoregressive bandits (software/AI; online systems)
- What: Use PG with adaptive learning rates to get near-minimax online mistake bounds and improved dependence on sequence length versus constant LR.
- Tools/workflows:
- PG optimizer with adaptive LR tied to gradient norms (PPO/GRPO-compatible).
- Lightweight online training loop for streaming prompts with bandit feedback.
- Assumptions/dependencies: Bandit-style rewards available; feasibility of clipping or removing importance weights in practice.
- Process reward model (PRM) integration to avoid exponential off-support cost (software/AI; coding, math education)
- What: Deploy PRMs that reward correct intermediate steps (e.g., test-passing code blocks, verified math steps) to replace or complement outcome-only verifiers.
- Tools/workflows:
- Unit tests/static analyzers as PRMs for code; step-checkers/rule-based graders for math proofs/derivations.
- Token-level feedback wiring to the RL loop (A_i = r*(x, y1:i)).
- Assumptions/dependencies: Availability and correctness of step-wise verifiers; alignment between step-wise reward and final correctness.
- Targeted supervised fine-tuning to raise LQ before RL (software/AI; data ops)
- What: Use active or difficulty-targeted SFT on low-likelihood regions (lowest quantile bins) to boost LQ, reducing RL sample/query complexity.
- Tools/workflows:
- LQ-driven data selection/augmentation; focused labeling for hard contexts.
- Iterative cycle: measure LQ → targeted SFT → remeasure → proceed to RL.
- Assumptions/dependencies: Access to labeled data in hard regions; measurable LQ improvements translate into RL savings.
- Quality-control dashboards for RL post-training (industry/ML Ops; governance)
- What: Track LQ, token-level LQ, expected error curves, and reward-query costs to avoid unproductive outcome-only RL when off-support.
- Tools/workflows:
- Dashboards with LQ plots (CDF/quantile), error vs. iterations, queries vs. N and k.
- Alarms when projected query cost scales exponentially in sequence length.
- Assumptions/dependencies: Logging infrastructure; reproducible metrics; stable verifiers.
- Educational assistants with step-wise feedback (education)
- What: Build math/coding tutors that provide process rewards for each derivation step or code chunk, improving learning outcomes and model reliability.
- Tools/workflows:
- Step graders, syntax/semantic checkers, partial proof validators.
- RL loop that reinforces correct intermediate reasoning (chain-of-thought compatible).
- Assumptions/dependencies: High-precision step validators; guardrails to prevent reward hacking.
- Safer generation through verifiable intermediate constraints (daily life; content creation)
- What: Use checklists/templates as process verifiers for structured writing (e.g., legal/compliance drafts), rewarding intermediate compliance.
- Tools/workflows:
- Section-by-section validators; linters for citations/facts; “pass-to-proceed” generation workflows.
- Assumptions/dependencies: Rule sets that can be encoded as verifiers; acceptance that PRM shapes style as well as correctness.
Long-Term Applications
These opportunities require additional research, scaling, or tooling maturation but are directly motivated by the paper’s results and limits.
- Standardization of LQ and token-level LQ as industry metrics (software/AI; policy)
- What: Establish LQ reporting standards to assess base-model support and to justify RL budgets; include in model cards and compliance reports.
- Dependencies: Agreement on measurement protocols; access to representative evaluation sets; mitigations for distribution shift.
- Curriculum strategies that switch among SFT, ORM-RL, and PRM-RL (software/AI)
- What: Dynamic curricula that use LQ thresholds to decide when to add supervised data, when to run process- vs. outcome-based RL, and how to allocate query budgets.
- Dependencies: Robust LQ estimators; controllers that can estimate ROI (error reduction per query) under each regime.
- General-purpose PRM development kits for broad task families (software/AI; multi-domain)
- What: Tooling to author/debug PRMs (rule-based + learned) for chain-of-thought, data analysis, planning, and multi-hop QA, with correctness guarantees where possible.
- Dependencies: Methods to train and verify PRMs; defenses against reward misspecification and gaming.
- Efficient off-support exploration beyond outcome rewards (research)
- What: New algorithms that mitigate the exponential barrier without relying on PRM, e.g., structured search, error-correcting decoding, or learned proposal distributions with provable guarantees.
- Dependencies: Advances in theory to break the kN barrier; practical samplers compatible with LLM decoding.
- Pre-training strategies explicitly optimized for LQ (software/AI; data strategy)
- What: Active pre-training and synthetic-data curricula that raise LQ cheaply (vs. uniformly improving average likelihood), reducing downstream RL cost.
- Dependencies: Reliable detection of low-LQ regions before labeling; scalable synthetic generation aligned with target distributions.
- Cross-domain process-verifier ecosystems (healthcare, finance, robotics)
- What: Verified intermediate-step checkers for clinical guideline adherence, regulatory compliance drafting, and robot subgoal attainment—each serving as PRMs.
- Dependencies: High-stakes verifiers with strong guarantees; regulatory buy-in; safe deployment frameworks; handling partial observability in robotics.
- Streaming online learners with bandit feedback in non-text domains (recommendation, ads, A/B platforms)
- What: Adapt PG-with-adaptive-LR to non-text contextual bandits where only outcome feedback is available but intermediate signals can be engineered (e.g., partial conversions).
- Dependencies: Mapping multi-step decisions to token-like steps; proxy process rewards; safeguards for exploration costs in production.
- Benchmarks and theory for deep, non-linear settings (academia)
- What: Extend the sequence-margin framework and LQ-based lower/upper bounds to Transformer-scale models and richer, non-separable regimes; publish PRM vs. ORM scaling laws.
- Dependencies: New proof techniques; large-scale empirical validation; community datasets with verifiable intermediate labels.
- Governance and compute-planning guidelines for RL post-training (policy)
- What: Evidence-based policies advising when outcome-only RL is compute-inefficient (due to exponential scaling in N) and recommending process-reward infrastructures for public models.
- Dependencies: Transparent reporting of query budgets; standardized error targets; sector-specific risk assessments.
Key assumptions and dependencies across applications
- Margin condition (token-level separability, γ > 0) approximately holds; violations may degrade guarantees.
- Accurate, low-latency verifiers are available; for PRMs, intermediate rewards must correlate strongly with final correctness and resist gaming.
- The analysis uses a linear head with frozen features; extensions to fully non-linear models are empirical (though strongly suggestive).
- Behavior policies must support base-model and uniform sampling; budgeted best-of-m sampling must fit compute constraints.
- Distributional stability: LQ estimates are meaningful only if eval distributions match deployment or are robustly adjusted.
Glossary
- Advantage estimator: A method in policy gradient algorithms that estimates the benefit of taking an action compared to a baseline. "Note that \eqref{eq:pg-or} considers a simple advantage estimator with no baseline."
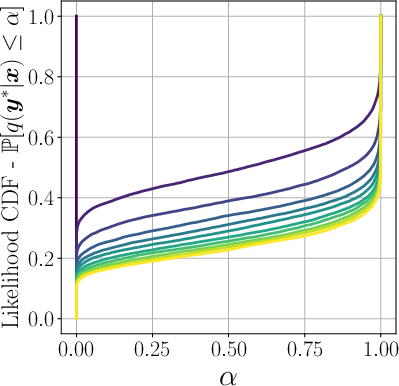
- Adagrad: An adaptive gradient optimization algorithm that scales learning rates based on historical gradients. "Likelihood CDF (left) and quantile (right) functions for a model trained with Adagrad with varying number of steps."
- Autoregressive model: A generative model that factorizes the probability of a sequence into a product over token-level conditional distributions. "We study post-training linear autoregressive models with outcome and process rewards."
- Bandit feedback: A limited-feedback setting where the learner only observes the reward for the chosen action, not for all actions. "learning a linear multiclass classifier with bandit feedback."
- Behavior policy: The policy used to generate actions (samples) during training, which may differ from the current model policy. "and is the behavior policy at round "
- Best-of-m exploration: An exploration strategy that samples up to m candidates and selects one based on reward checks to improve success probability. "Best-of- exploration for PG-OR."
- Best-of-N sampling: A technique where multiple generations are sampled and the best is selected, used to assess coverage and success rates. "studies coverage profile which characterizes the probability of success with best-of-N sampling"
- Clipped importance weights: A stabilization technique that clips importance sampling ratios to control variance in off-policy updates. "Our analysis can also accommodate clipped importance weights;"
- Contextual bandit: A reinforcement learning framework where the agent observes a context, chooses an action, and receives a reward for that action only. "This approach yields a contextual bandit formulation:"
- Coverage profile: A function describing how likely a model is to produce a correct output as a function of a target likelihood threshold. "studies coverage profile which characterizes the probability of success with best-of-N sampling"
- Curse of dimensionality: The exponential growth in complexity or sample requirements with respect to sequence length or dimensionality. "avoid the curse of dimensionality in "
- Generalized inverse (of a CDF): A function that maps a probability level to the corresponding quantile; here used for the likelihood distribution. "and is the generalized inverse of this function;"
- GRPO (Group Relative Policy Optimization): A policy gradient algorithm variant that uses group-relative advantages for updates. "such as PPO or GRPO."
- Implicit bias: The tendency of optimization methods (like SGD) to prefer certain solutions (e.g., max-margin) without explicit regularization. "and its implicit bias"
- Importance weights: Ratios used to correct for the mismatch between behavior and target policies in off-policy learning. "we have to introduce the importance weights "
- Likelihood Quantile (LQ): The quantile function of the base model’s likelihood assigned to correct responses, capturing how much probability mass the base model places on ground-truth outputs. "a property of the base model called the Likelihood Quantile (LQ)"
- Margin condition (γ margin condition): A separability assumption stating that correct labels score at least γ more than any incorrect label under some linear predictor. "a sequence of length that satisfies a margin condition"
- Max-margin SVM: A classifier that maximizes the margin between classes; connected to the limiting behavior of SGD on separable data. "connection to the max-margin SVM"
- Minimax optimal: Achieving the best possible worst-case performance up to constant or logarithmic factors. "essentially minimax optimal number of reward queries"
- On-policy: A learning setup where the behavior policy equals the current model policy. "unless we are fully on-policy, i.e.\ ."
- Online-to-batch conversion: A technique to convert guarantees from online learning to statistical (i.i.d.) generalization bounds. "proofs are obtained by an online analysis and an online-to-batch conversion"
- Outcome reward model (ORM): A reward signal that evaluates only the final sequence, typically returning 1 for a correct full response and 0 otherwise. "receives a reward from an outcome reward model (ORM)."
- Policy gradient (PG): A family of methods that optimize a parameterized policy by ascending the expected reward gradient. "a variant of policy gradient (PG) can achieve likelihood "
- PPO (Proximal Policy Optimization): A practical policy gradient algorithm that constrains policy updates, often via clipped objectives or importance weights. "proximal policy optimization (PPO)"
- Process reward model (PRM): A reward signal that provides intermediate feedback during sequence generation, e.g., per-token correctness. "a process reward model (PRM) can provide intermediate signal to the learner."
- REINFORCE: A classic Monte Carlo policy gradient algorithm using the log-likelihood trick. "also referred to as REINFORCE"
- Separability: The existence of a classifier that strictly separates correct from incorrect labels by a positive margin. "an extension of the standard separability to sequences."
- Softmax parameterization: A common policy representation where action probabilities are a softmax over linear scores. "PG with softmax parameterization are only asymptotic."
- Stochastic Gradient Descent (SGD) with adaptive learning rate (LR): An SGD variant where the step size adapts to gradient magnitudes to improve convergence. "SGD with adaptive learning rate (LR) achieves a near optimal test error"
- Token-Level Likelihood Quantile: The quantile function of the base model’s per-token likelihoods along the correct trajectory, used with process rewards. "called the Token-Level Likelihood Quantile"
- Uniform behavior policy: A behavior policy that samples actions uniformly, used for exploration and analysis of worst-case guarantees. "a variant of PG with a uniform behavior policy that achieves the minimax optimal mistake bound"
- Uniform policy: A policy that assigns equal probability to all actions or sequences. "if is simply the uniform policy"
- VC dimension: A measure of the capacity of a hypothesis class, governing sample complexity in statistical learning. "the VC dimension of the class of -margin half-spaces"
Collections
Sign up for free to add this paper to one or more collections.