Maximum Likelihood Reinforcement Learning
Abstract: Reinforcement learning is the method of choice to train models in sampling-based setups with binary outcome feedback, such as navigation, code generation, and mathematical problem solving. In such settings, models implicitly induce a likelihood over correct rollouts. However, we observe that reinforcement learning does not maximize this likelihood, and instead optimizes only a lower-order approximation. Inspired by this observation, we introduce Maximum Likelihood Reinforcement Learning (MaxRL), a sampling-based framework to approximate maximum likelihood using reinforcement learning techniques. MaxRL addresses the challenges of non-differentiable sampling by defining a compute-indexed family of sample-based objectives that interpolate between standard reinforcement learning and exact maximum likelihood as additional sampling compute is allocated. The resulting objectives admit a simple, unbiased policy-gradient estimator and converge to maximum likelihood optimization in the infinite-compute limit. Empirically, we show that MaxRL Pareto-dominates existing methods in all models and tasks we tested, achieving up to 20x test-time scaling efficiency gains compared to its GRPO-trained counterpart. We also observe MaxRL to scale better with additional data and compute. Our results suggest MaxRL is a promising framework for scaling RL training in correctness based settings.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Maximum Likelihood Reinforcement Learning (MaxRL) — A simple explanation
What is this paper about?
This paper looks at how to train AI models that must try things and then find out if they were right or wrong at the very end—like solving a math problem, writing code that must pass tests, or navigating a maze. Today, people often use reinforcement learning (RL) for these jobs because the steps in the middle aren’t easy to “differentiate” (that’s a math thing computers use to learn).
The authors argue there’s a better target to aim for: making the correct answer as likely as possible (called “maximum likelihood,” or ML). Since direct ML is hard in these tasks, they introduce MaxRL, a new way that uses RL-style sampling but increasingly behaves like ML as you allow more tries per question.
What questions does the paper ask?
- Can we train models to directly increase the chance of being correct (like ML) even when the steps in the middle can’t be differentiated?
- Is regular RL actually aiming at the best goal in these “binary success” tasks? (Answer: not quite—it’s only a rough, first-step approximation.)
- Can we use more compute (more tries per input) to get closer to the ideal ML training target, and does that help in practice?
How does MaxRL work? (With simple analogies)
Think of training like taking a quiz:
- “Pass rate” = how often the model gets a question right on the first try.
- “pass@k” = the chance that at least one of k tries is correct (like submitting up to k solutions and hoping one works).
Regular RL boosts the chance of getting a single try right (pass@1). Maximum likelihood wants to boost the overall chance of being correct and especially fix the hard questions the model often misses. The key idea:
- ML’s learning signal gives more attention to hard inputs. If the model rarely gets something right, ML says: pay extra attention here.
- The authors show that ML can be thought of as a (mathematical) mixture of “pass@k” signals for k = 1, 2, 3, … (like caring about 1 try, 2 tries, 3 tries, and so on). Regular RL only uses the first piece (k = 1).
MaxRL uses this idea to build a “compute knob”:
- If you allow T tries during training on each input, MaxRL combines information from pass@1, pass@2, … up to pass@T.
- When T = 1, you get standard RL.
- As T grows larger, MaxRL gets closer to ideal maximum likelihood training.
How do they estimate the learning signal in practice?
- They sample N attempts (like N essays or N code solutions) for the same question.
- They look at the attempts that succeeded and average the “push” toward those successes. If none succeed, that input doesn’t update the model that step.
- This simple averaging turns out to be an unbiased way to match a truncated ML objective (using up to k = N). In other words, more tries don’t just reduce randomness; they actually change the training target to be closer to true ML.
In everyday terms: instead of treating all attempts equally, MaxRL focuses learning on what worked, and as you let the model try more times, you teach it in a way that better matches “make the right answer likely.”
What did they find, and why does it matter?
The authors test MaxRL in several settings and compare it to common RL methods like REINFORCE/RLOO and GRPO. Here’s what they saw:
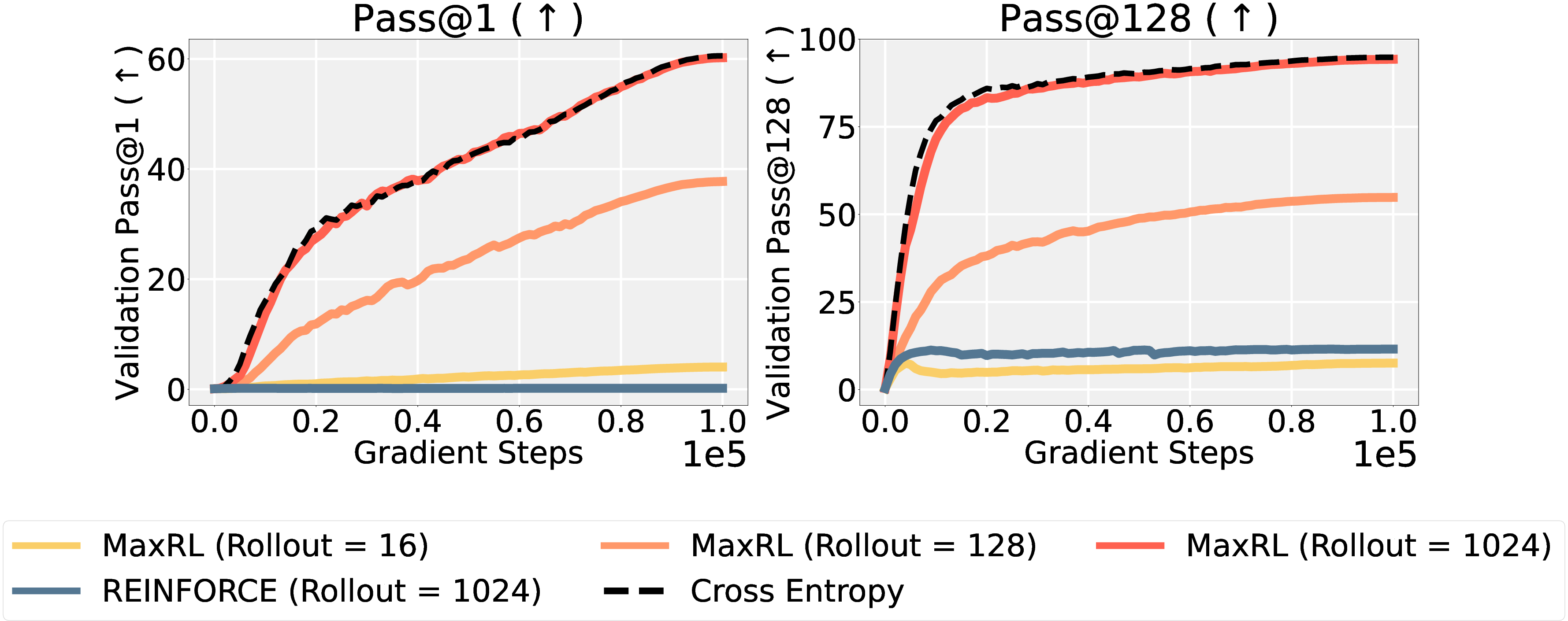
- Image classification (a controlled test where exact ML is possible):
- As they allow more tries per image, MaxRL’s behavior closely matches exact ML (standard cross-entropy training).
- Regular RL fails to improve much from low success rates, even with many tries.
- Why it matters: MaxRL really does approach ML when given more compute.
- Maze navigation (lots of data, many unique mazes):
- MaxRL improves faster and more reliably as they give it more training compute (more rollouts per input) than RL or GRPO.
- Why it matters: In data-rich settings, MaxRL scales better with extra compute.
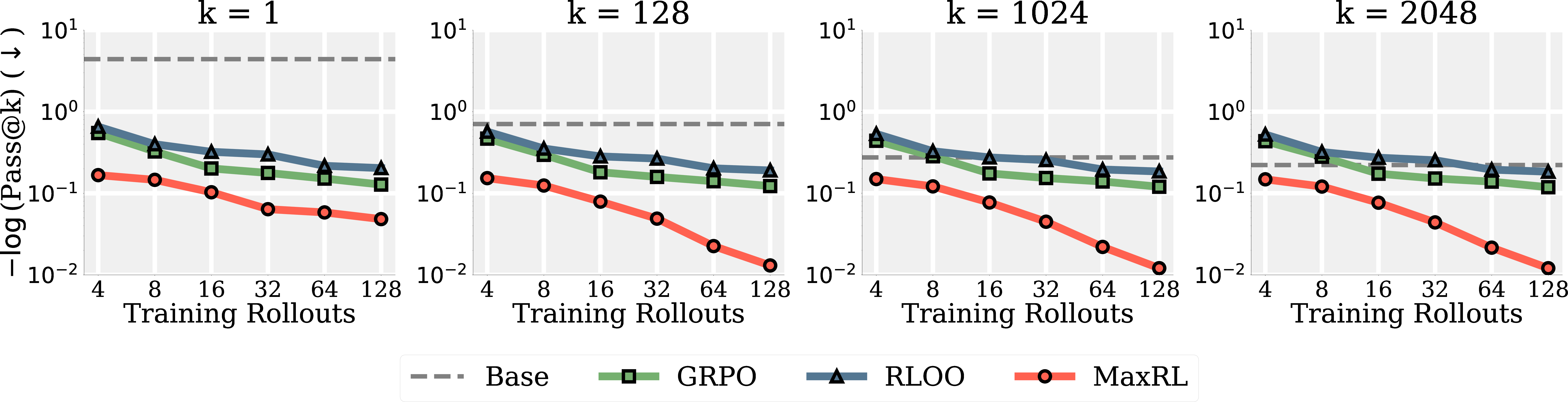
- Math word problems (GSM8K, limited data, many training epochs):
- MaxRL achieves higher peak performance and avoids the “pass@k collapse” (where models get good at one answer but lose variety, so multiple tries don’t help as much).
- Why it matters: MaxRL is more resistant to overfitting and keeps useful diversity in outputs, which is crucial when you rely on multiple sampled answers.
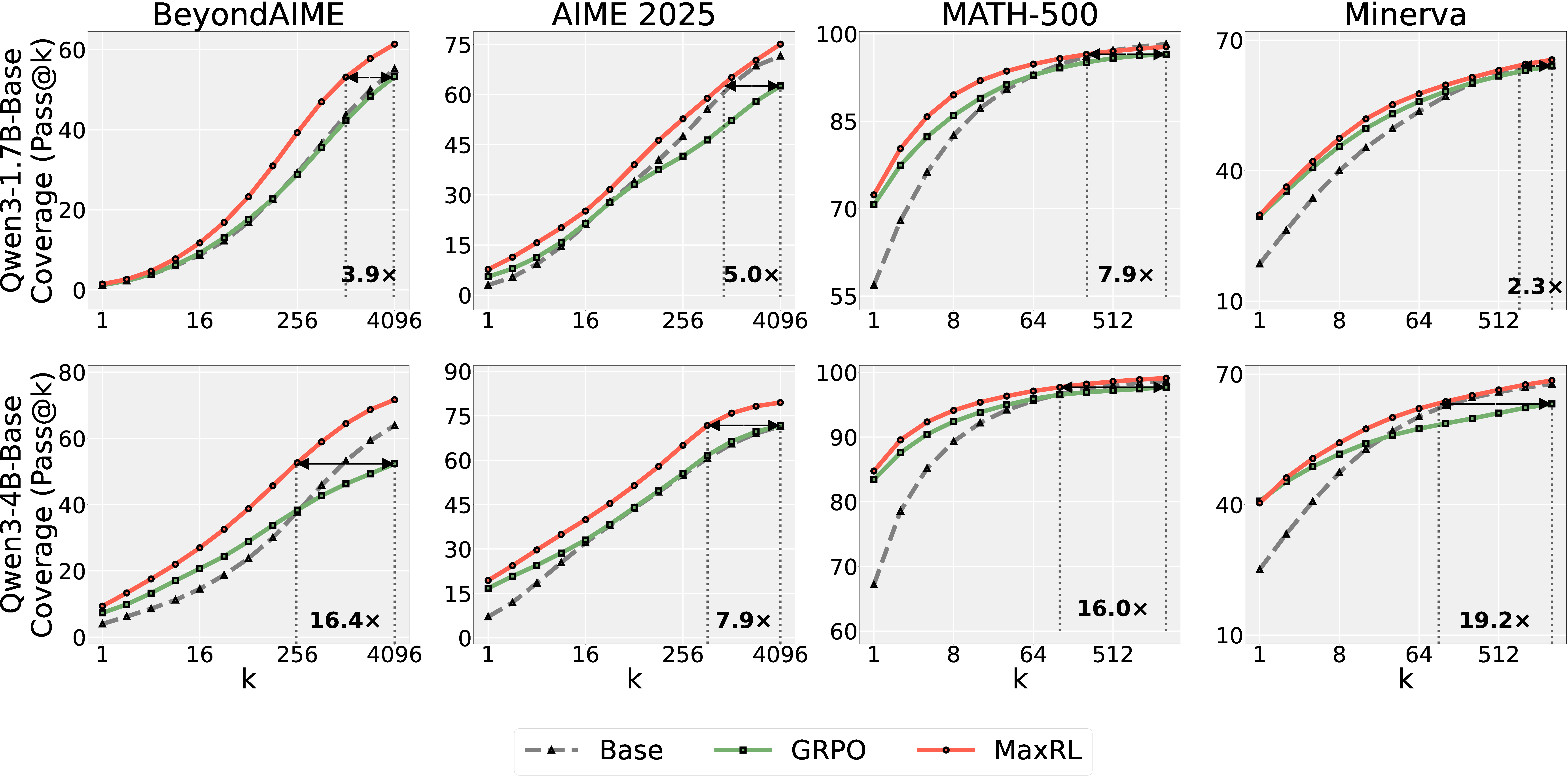
- Larger reasoning models (math benchmarks; summary results in paper):
- MaxRL matches or beats GRPO on several math benchmarks.
- It also brings big test-time efficiency gains: up to about 20× fewer samples needed to reach similar or better accuracy when you can check answers with a verifier.
- Why it matters: Better accuracy and faster inference can go together.
Overall takeaways:
- MaxRL “Pareto-dominates” the baselines in their tests—meaning it offers a better trade-off between accuracy and compute.
- It benefits more from extra data and extra sampling compute than standard RL approaches.
Why is this important?
- It reframes how we train models on “try-and-check” tasks: instead of just making the first try better (RL), MaxRL pushes the model to make the correct answer likely overall (ML), especially on hard questions.
- It provides a clear, simple way to turn extra compute into better learning, not just less noise—more tries per input actually move training closer to the ideal objective.
- It helps avoid overfitting and preserves useful variety in model outputs, which is vital when you plan to sample multiple answers and pick the best with a checker.
- This could improve many practical systems in code generation, math reasoning, planning, and navigation, making them both more accurate and more efficient at test time.
In short
MaxRL bridges the gap between reinforcement learning and maximum likelihood for tasks where success is only known at the end. By letting the model try more times during training and learning mostly from the successful attempts, MaxRL acts more and more like ML—leading to better results, better scaling with compute and data, and big efficiency gains when generating multiple answers at test time.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored, written to guide future research efforts.
- Assumption of perfect, binary verifiers: Extend MaxRL to noisy, imperfect, or graded feedback (partial credit, continuous rewards), and analyze bias/consistency of the estimator under label noise.
- Zero-gradient when there are no successes (
K=0): Develop estimators or sampling strategies that provide informative gradients when pass rates are extremely low (e.g., adaptive rejection sampling, shaped rewards, curriculum), and quantify minimal pass-rate thresholds for reliable progress. - Independence assumption behind pass@k: Generalize the Maclaurin expansion and estimators to non-i.i.d. sampling (beam search, tree-of-thought exploration, deduplication, reranking), where sample dependence violates current derivations.
- On-policy-only treatment: Formulate and analyze off-policy MaxRL with importance sampling, compatibility with PPO-style clipping, and constrained objectives (e.g., with KL regularization to a reference model as used in RLHF).
- Variance and stability guarantees: Provide formal variance bounds and sample-complexity analyses for the conditional estimator, especially when
pis small, and propose principled gradient clipping/normalization schemes to prevent exploding gradients whenr̂is near zero. - Adaptive rollout allocation: Design compute-aware schedulers that allocate rollouts per input as a function of estimated difficulty (
p̂(x)), with theoretical guarantees on approximation error to ML for a fixed compute budget. - Convergence to ML: Prove that optimizing the truncated objective
J_MaxRL^(N)converges to ML optimization asN → ∞under practical SGD conditions (non-convex models, stochastic batches), and characterize the rate in terms ofpandN. - Weighting-function consequences: Analyze how MaxRL’s
w(p) = (1-(1-p)^T)/pinfluences diversity, distribution sharpening/flattening, and coverage; provide theory and diagnostics (entropy, uniqueness rate, self-consistency) beyond pass@k. - Integration with RLHF/preference learning: Extend MaxRL to pairwise or listwise preference objectives and multi-objective training, studying interplay with KL constraints to maintain general language quality.
- Beyond terminal rewards: Generalize MaxRL to MDPs with intermediate rewards and credit assignment along trajectories (token-level or step-wise), including variance-reduced advantage shaping compatible with the conditional estimator.
- Multiple correct outputs and semantic equivalence: Evaluate robustness when multiple solutions exist; incorporate equivalence classes and fuzzy verifiers, and study how this affects pass@k, deduplication, and gradient credit.
- Compute and memory costs at scale: Quantify memory/latency overhead for large
Nin billion-parameter LLMs, and propose pipeline optimizations (streaming batches, partial backprop, microbatching) to keep MaxRL practical. - Hyperparameter sensitivity and reproducibility: Systematically study sensitivity to
N, learning rates, entropy bonuses, batch sizes, baselines, and control variates across seeds; report statistical significance and variance across runs. - Safety and fairness: Investigate whether upweighting very hard, low-pass-rate inputs harms performance on common/easy inputs or exacerbates adversarial prompt exploitation; propose fairness-aware weighting schemes and robustness tests.
- Calibration: Measure whether MaxRL improves probability calibration (ECE, Brier score) relative to RL objectives and whether ML-like calibration benefits transfer to non-differentiable settings.
- Baseline breadth and parity: Expand comparisons beyond RLOO/GRPO, including recent pass@k-optimized methods (PKPO variants, adaptive sampling, rejection fine-tuning, differential smoothing) under matched compute/token budgets and unified evaluation protocols.
- Bootstrapping from very low pass rates: Characterize the role of supervised warm starts and curricula; derive guidelines for when MaxRL will stall versus succeed, and how to combine with rejection fine-tuning or self-rewarding methods to escape low-pass-rate regimes.
- Verifier cost and availability: Reassess test-time scaling efficiency claims under expensive, imperfect, or unavailable verifiers (e.g., human feedback); design cost-aware training/inference policies that remain effective without perfect verifiers.
- Duplicate solutions and coverage metrics: Clarify whether pass@k handles duplicates consistently; propose deduplicated success metrics and objectives aligned with solution diversity and unique-correct coverage.
- Modality and task generalization: Validate MaxRL on code execution, robotics/navigation, program synthesis, and multimodal tasks where sampling policies or verifiers differ substantially from math/vision benchmarks.
- Control variate design: Move beyond a fixed coefficient on the unconditional average score to learn/tune optimal control variate coefficients per task or per-token to minimize variance while preserving unbiasedness.
- Numerical stability of per-task normalization: Study the impact of the
1/(N·r̂)normalization whenr̂is small; introduce smoothing (e.g.,ε-stabilization), robust normalizers, or gradient rescaling rules with theoretical backing. - Entropy regularization for MaxRL: Determine whether adding entropy bonuses (or other exploration incentives) improves diversity without undermining ML-approximation, and provide principled recipes for tuning.
- Practical guidance for choosing
TandN: Develop data-driven heuristics to pick truncation order and rollout counts based on the empirical pass-rate distribution and compute budget, including adaptive schedules over training. - Large-scale results completeness: The large LLM section is truncated; provide full training details, compute accounting, evaluation seeds, and statistical tests on Qwen models to support claims of Pareto dominance and inference efficiency.
Practical Applications
Immediate Applications
These applications can be deployed now using the paper’s estimator, training objective, and on-policy algorithm (a one-line change to advantage computation), assuming you have a binary verifier and can run multiple rollouts per input.
- LLM reasoning post-training (sector: software/education)
- What: Fine-tune reasoning LLMs (math, logic proofs, structured QA) with MaxRL to improve pass@1 and pass@k and reduce overfitting versus GRPO/RLOO.
- Why: MaxRL focuses learning on hard, low-pass-rate items; empirically yields 2.3×–19.2× test-time scaling efficiency and up to 20× speedups when a perfect verifier is available.
- How (workflow/tools): Swap GRPO/RLOO for the MaxRL estimator (normalize by per-task mean reward; skip gradient when no successes K=0); keep existing on-policy pipelines (e.g., TRL/PPO codebases) and use existing verifiers (numeric equality, regex/AST checks).
- Assumptions/dependencies: Reliable automatic verifier; at least modest initial pass rate; budget for N rollouts per input.
- Code generation with unit tests (sector: software engineering/devops)
- What: Train code LLMs against unit/integration tests and “continuous learning from failing tests” in CI.
- Why: Pass/fail signals from tests are ideal binary verifiers; MaxRL improves sample efficiency and reduces overfitting to easy cases.
- How: For each prompt+test suite, sample N code variants, run tests, compute K successes, and update with the MaxRL gradient. Integrate into CI to harvest failing tests as new training data and to schedule N adaptively by test difficulty.
- Assumptions: Deterministic, fast-running tests; sandboxed execution; stable decoding of code to AST/binaries.
- Navigation and manipulation in simulation (sector: robotics)
- What: Train policies where success is verified at episode end (reach-goal, open-door, grasp, maze completion).
- Why: The binary success is native to MaxRL; empirically scales better with added rollouts and emphasizes rare successes.
- How: Use on-policy rollouts in sim (N per task), compute success indicator, apply the MaxRL estimator; deploy to sim2real after validation.
- Assumptions: Access to fast simulators; clear success criteria; enough pretraining or curriculum so K>0 occurs regularly.
- Data-scarce post-training with verifiers (sector: enterprise AI)
- What: Fine-tune small/medium models on fixed datasets where outputs can be validated (e.g., form-to-JSON with schema verification, SQL generation validated by execution and constraints).
- Why: MaxRL shows less pass@k degradation (distribution sharpening) under prolonged training; better peak performance with limited data.
- How: Keep dataset fixed, increase training epochs and per-task rollouts; monitor pass@k; use MaxRL variance reduction and skip K=0 tasks.
- Assumptions: Verifiers (schema/DB constraints) are reliable; careful monitoring to avoid overfitting to narrow schemas.
- Math tutoring and auto-grading systems (sector: education)
- What: Train tutors to reliably produce correct final answers (and optionally step-checks).
- Why: Binary correct/incorrect is easily verified; MaxRL improves pass@1 and maintains diversity (healthier pass@k).
- How: Use CAS/numeric checkers for final answers; optionally add per-step checks to reduce K=0; deploy with adaptive sampling (k at inference) to meet latency/accuracy targets.
- Assumptions: Robust answer extraction/normalization; access to graded problem sets or synthetic generators.
- Inference orchestration with verifiers (sector: platform/infra)
- What: Use MaxRL-trained models with verifier-guided multi-sampling to hit accuracy SLAs at lower latency/cost.
- Why: Models trained with MaxRL need fewer samples to achieve a target pass@k; easy plug-in for production inference controllers.
- How: Introduce a verifier in the inference path; adaptively increase k until success or budget cap; cache and rank candidates by verifier confidence.
- Assumptions: Verifier latency fits the budget; “perfect” or high-precision verifiers for the target tasks.
- Research and teaching (sector: academia)
- What: Reproduce, benchmark, and extend training objectives via the weight-function lens (w(p)); teach ML↔RL link for correctness-based tasks.
- Why: Simple estimator and on-policy implementation; repeatable scaling results (ImageNet, maze, GSM8K, math LLMs).
- How: Integrate MaxRL into open-source RLHF stacks; add dashboards for pass@k, w(p), and K=0 fraction; release teaching labs comparing RL/GRPO/MaxRL.
- Assumptions: Availability of baseline code and datasets; compute for controlled rollouts.
- Compute and sustainability policy inside organizations (sector: policy/ops)
- What: Prefer MaxRL for verifiable tasks to achieve target accuracy with fewer inference samples and better train-time scaling.
- Why: Better compute–accuracy trade-off; reduces scavenger sampling at inference.
- How: Update model evaluation KPIs to include pass@k and test-time scaling efficiency; bake MaxRL into internal training standards for tasks with verifiers.
- Assumptions: Tasks expose verifiable correctness; governance accepts pass@k as a primary KPI.
Long-Term Applications
These require further research, scaling, or infrastructure maturity (e.g., robust verifiers, hardware, safety approvals).
- Training with imperfect/noisy or partial-credit verifiers (sectors: healthcare, legal, finance, education)
- What: Extend MaxRL to soft rewards, partial credit, or noisy adjudication (human or automated).
- Why: Many real tasks can’t offer perfect binary checks; robustness to label noise is essential.
- How: Design and analyze soft/robust variants of the estimator; develop confidence-weighted K>0 conditioning; calibrate with human-in-the-loop QA.
- Dependencies: Trustworthy grading pipelines; bias/variance control for noisy feedback; safety reviews in regulated domains.
- Adaptive per-example rollout scheduling (sectors: platform/infra, robotics, software)
- What: Automatically choose N per input to achieve target truncation order T or desired gradient quality with minimal compute.
- Why: The estimator quality scales with N; unevenly allocating compute can reduce cost while preserving gradient fidelity.
- How: Online policies that raise N for low-p tasks (estimated via recent pass history), lower N for easy tasks; theoretical guarantees on convergence and budget.
- Dependencies: Low-latency verifiers; scheduler stability; guardrails against starvation of mid-difficulty items.
- Safety-critical deployment with real-world verifiers (sectors: healthcare, autonomous systems, industrial control, energy)
- What: Train agents where success means satisfying safety/regulatory constraints (e.g., treatment-eligibility logic, grid dispatch rules, flight envelopes).
- Why: MaxRL emphasizes rare successes, aligning training with strict constraint satisfaction.
- How: Build high-assurance, auditable verifiers for domain constraints; simulate rare events; combine with curriculum and uncertainty estimation; add formal verification where feasible.
- Dependencies: Certified/verifiable rule engines; regulator-approved evaluation; strong simulation fidelity; human oversight loops.
- On-robot/on-device learning with constrained rollouts (sector: robotics, mobile)
- What: Use MaxRL for limited, expensive real-world rollouts where K is often zero initially.
- Why: Weighting hard tasks is desirable, but sample scarcity and safety constraints are severe.
- How: Bootstrapping with sim and rejection fine-tuning; adaptive sampling (RAFT/REINFORCE-ADA); strict safety filters; off-policy extensions to leverage logged data.
- Dependencies: Safe exploration; fast sim2real transfer; memory- and compute-efficient implementations.
- Multi-objective and stepwise-verified reasoning (sectors: software, education, research)
- What: Generalize to compositional verifiers (e.g., proofs/programs checked at intermediate steps, plus final correctness).
- Why: Reduces K=0, aligns gradient with intermediate progress, mitigates reward hacking.
- How: Define factorized f(z) with stepwise checks; blend per-step and final success weighting; analyze new weight functions w(p1, p2, …).
- Dependencies: Reliable step-checkers; careful balance to avoid overfitting to shallow heuristics.
- Hardware and systems co-design for MaxRL training (sector: semiconductors/cloud)
- What: Optimize training throughput for success-conditioned gradients (e.g., batching verifier runs, K-aware gradient aggregation).
- Why: Verifier latency dominates in many domains; specialized kernels and schedulers can cut cost significantly.
- How: Asynchronous sampling/execution pools; verifier vectorization; gradient accumulation conditioned on K; memory-efficient per-task statistics.
- Dependencies: Systems engineering; verifier batching; cluster schedulers aware of N/K dynamics.
- Fairness, robustness, and distributional monitoring (sector: policy/responsible AI)
- What: Ensure “hard-example focusing” doesn’t cause harmful distributional shifts or neglect subgroups.
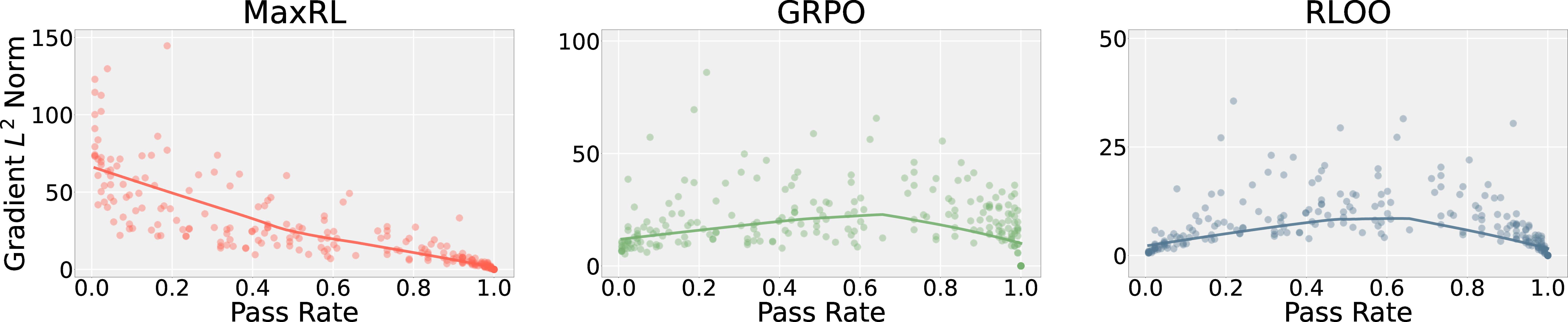
- Why: Weighting low-pass-rate items can skew training towards certain patterns; GRPO’s inverted weights at high p illustrate sensitivity of objectives to weighting.
- How: Monitor pass@k by subgroup; regularize with entropy/differential smoothing; constrain w(p) to avoid pathological sharpening; publish training logs for audit.
- Dependencies: Demographic/segment metadata (where appropriate and ethical); privacy-preserving telemetry; governance processes.
- Standardization: pass@k-first evaluation and procurement
- What: Establish standards and benchmarks that emphasize pass@k and test-time scaling efficiency for correctness-based tasks.
- Why: Aligns training objectives with deployment metrics; clarifies compute–accuracy trade-offs across vendors.
- How: Publish reference verifiers and evaluation suites; define contract SLAs in terms of pass@k at specified k and latency budgets; include MaxRL-compatible training disclosures.
- Dependencies: Community adoption; shared datasets and verifiers; agreement on reporting practices.
Cross-cutting assumptions and dependencies
- Verifier availability and quality: The closer to a “perfect” verifier, the larger the realized gains. For noisy verifiers, robust extensions are needed.
- Compute budget for rollouts (N): MaxRL benefits from larger N; in low-pass-rate regimes, K=0 can be frequent early on and needs mitigation (pretraining, curriculum, adaptive sampling).
- On-policy training: Paper’s guarantees/experiments are on-policy; off-policy variants and replay-buffer integrations require further work.
- Deterministic decoding f(z): The framework assumes a known mapping from latent trajectories to final outputs; extraction errors (e.g., boxed answers, code parsing) must be minimized.
- Distributional match: Training and deployment distributions should be similar for pass@k gains to transfer; otherwise, monitor and adapt N and curriculum dynamically.
Glossary
- Adaptive sampling: A sampling strategy that adjusts based on observed successes to efficiently target a desired objective. "Recent works have proposed rejection fine-tuning~\citep{touvron2023llama2openfoundation,yuan2023scalingrelationshiplearningmathematical,dong2023raftrewardrankedfinetuning,xiong2025minimalistapproachllmreasoning,davis2025objectivereasoningreinforcementlearning} and adaptive sampling~\citep{xiong2025reinforceadaadaptivesamplingframework} as mechanisms to sample from this conditional distribution."
- Compute-indexed: Parameterized by the amount of sampling compute; objectives become more faithful to ML as compute grows. "compute-indexed family of sample-based objectives that interpolate between standard reinforcement learning and exact maximum likelihood as additional sampling compute is allocated."
- Conditional estimator: An estimator that conditions on successful outcomes, averaging only successful trajectory gradients. "Comparison of the REINFORCE estimator ($\nabla_\theta J_{\mathrm{RL}(x)$) and the conditional estimator ($\nabla_\theta J_{\mathrm{MaxRL}^{(T)}(x)$)."
- Conditional expectation representation: Expressing a gradient as an expectation conditioned on success. "The gradient of the maximum likelihood objective admits the following conditional expectation representation:"
- Control variate: A zero-mean auxiliary quantity used to reduce estimator variance without changing its expectation. "We instead proceed from first principles and use a simple zero-mean control variate, the unconditional average score:"
- Cross-entropy training: Training by minimizing cross-entropy loss, equivalent to maximizing log-likelihood in classification. "which is directly analogous to cross-entropy training in differentiable supervised learning."
- Deterministic decoding: A fixed mapping from the latent trajectory to the final output. "Under the latent generation model with deterministic decoding ,"
- Entropy bonus: An additional reward term encouraging exploration by increasing policy entropy. "GRPO (with entropy bonus)"
- GRPO (Group Relative Policy Optimization): An RL objective that normalizes advantages using group statistics, altering population-level weighting. "GRPO~\citep{shao2024deepseekmathpushinglimitsmathematical} is a notable exception due to its division by standard deviation in the advantage calculation,"
- Harmonic mixture: A weighted sum with weights 1/k, used here to combine pass@k gradients. "Thus, maximum likelihood optimizes an infinite harmonic mixture of gradients,"
- Importance weight truncation via clipping: A PPO mechanism that limits importance weights to trade bias for robustness. "(importance weight truncation via clipping) that trade bias for robustness."
- Latent generation model: A model that samples a latent trajectory and deterministically decodes it to an output. "Under the latent generation model with deterministic decoding ,"
- Maclaurin expansion: A power series around zero, used to expand the log-likelihood in terms of failure probabilities. "admits the Maclaurin expansion in terms of failure events:"
- Maximum Likelihood Reinforcement Learning (MaxRL): A framework that approximates maximum likelihood using RL techniques under non-differentiable sampling. "We call this framework Maximum Likelihood Reinforcement Learning (MaxRL)."
- On-policy: Training using data sampled from the current policy without off-policy corrections. "Because we compare training objectives rather than algorithms, all methods are trained on-policy."
- Pareto-dominates: Outperforms across multiple metrics such that improvements don’t require sacrificing others. "Empirically, we show that MaxRL Pareto-dominates existing methods in all models and tasks we tested,"
- Pass rate: The probability that a single sampled output is correct for a given input. "We define the pass rate as the probability that the model produces the correct answer for a fixed input :"
- Pass@1 objective: The objective of maximizing the probability that a single sample is correct. "the classical reinforcement learning approach is to optimize only the expected pass@1 objective \citep{koenig1993complexity,silver2016mastering,vecerik2018leveragingdemonstrationsdeepreinforcement,guo2025deepseek}:"
- Pass@k: The probability that at least one of k independent samples is correct. "We define as the probability of at least one correct sample:"
- Policy-gradient baselines: Baseline terms subtracted from rewards to reduce variance in policy-gradient estimates. "Policy-gradient baselines are typically introduced to reduce variance without changing the expected gradient~\citep{sutton1988learning}."
- Policy-gradient estimator: An unbiased gradient estimator using likelihood ratios (e.g., REINFORCE). "The resulting objectives admit a simple, unbiased policy-gradient estimator and converge to maximum likelihood optimization in the infinite-compute limit."
- REINFORCE: A classic likelihood-ratio policy-gradient estimator averaging gradients over sampled trajectories. "We average score functions only over successful trajectories and obtain the following REINFORCE-style estimator:"
- Rejection fine-tuning: A method that samples from the model and fine-tunes on accepted (e.g., verified-correct) outputs. "Recent works have proposed rejection fine-tuning~\citep{touvron2023llama2openfoundation,yuan2023scalingrelationshiplearningmathematical,dong2023raftrewardrankedfinetuning,xiong2025minimalistapproachllmreasoning,davis2025objectivereasoningreinforcementlearning} and adaptive sampling~\citep{xiong2025reinforceadaadaptivesamplingframework} as mechanisms to sample from this conditional distribution."
- RLOO (leave-one-out baseline): A variance-reduction baseline that uses the mean reward excluding the current sample. "REINFORCE with a leave-one-out baseline (RLOO) \citep{ahmadian2024basicsrevisitingreinforcestyle}"
- Rollout: A sampled trajectory or sequence generated by the policy used for training or evaluation. "Increasing compute as rollouts leads to a better approximation of the maximum likelihood gradient."
- Score function: The gradient of the log-probability of a sampled trajectory, used in likelihood-ratio estimators. " denote the score function,"
- Success-conditioned distribution: The distribution over trajectories conditioned on being successful (correct). "The key insight is that the maximum likelihood gradient can be expressed as an expectation under the success-conditioned distribution"
- Success-conditioned policy: Sampling only from successful trajectories implied by the current model. "suggests drawing samples from the success-conditioned policy."
- Truncated maximum likelihood objective: A finite-order approximation to the ML objective via truncated Maclaurin expansion. "we define the truncated maximum likelihood objective for a fixed input as"
- Weighting function: A scalar function w(p) that reweights gradient contributions by pass rate at the population level. "Population-level weighting functions ."
Collections
Sign up for free to add this paper to one or more collections.