- The paper introduces Dr.Rec, a multi-agent framework that proactively simulates user exploration and synthesizes decision-support reports to ease cognitive load.
- The paper employs novel reinforcement learning techniques with multi-reward signals and diverse trajectory sampling to enhance behavioral modeling and recommendation precision.
- The paper demonstrates significant gains on the Tmall dataset, achieving up to 52% improvement in Recall@5 and a 49% increase in NDCG@5 over baseline methods.
Deep Research for Recommender Systems: A Multi-Agent Paradigm for Proactive, Report-Centric Recommendation
Motivation and Problem Statement
Despite significant advances in recommender system technology—including deep neural models and LLMs—fundamental limitations persist in deployed systems, which remain wedded to the traditional item-list paradigm. Current systems act as passive filters, presenting item lists for user-driven exploration, comparison, and synthesis, thereby imposing substantial cognitive and interaction costs on the user, particularly in high-involvement decision scenarios (e.g., expensive goods). The paper "Deep Research for Recommender Systems" (2603.07605) challenges this item-centered interaction model and proposes a transition to a proactive, agent-driven paradigm that autonomously simulates exploration and synthesizes decision-support reports.
Dr.Rec: Multi-Agent Deep Research Pipeline
The central contribution is the Dr.Rec architecture, a multi-agent framework that operationalizes the deep research paradigm for recommendation. It comprises two coordinated agents: a user trajectory simulation agent and a self-evolving report generation agent, as outlined below.
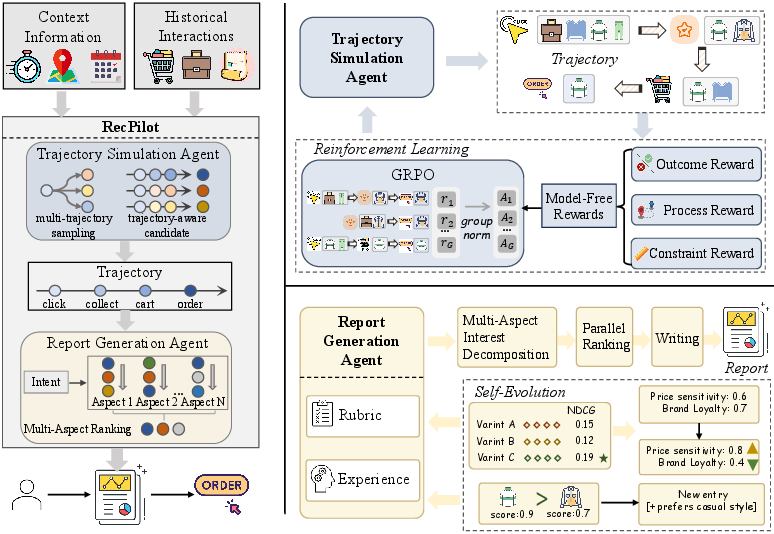
Figure 1: Overview of Dr.Rec. The pipeline combines autonomous user exploration simulation via RL-optimized agents with a multi-aspect, rubric- and experience-driven report generator supporting self-evolution.
User Trajectory Simulation Agent
The first agent models the entire exploration-to-decision process as a conditional generative task, using contextual and historical interactions to auto-regressively synthesize plausible future behavioral trajectories. By resorting to generative modeling with reinforcement learning (employing model-free, rule-based rewards and the GRPO objective), the agent robustly simulates the breadth and depth of potential user interaction paths, moving beyond truncated one-step prediction typical of pure discriminative models.
Core technical capabilities include:
- Session-aware trajectory tokenization: Behavioral sessions are structured to capture action-type prefixes and compress high-frequency, low-information actions.
- Multi-reward RL optimization: Training combines outcome (final purchase match), process (collaborative semantic similarity via embedding max-pooling), and constraint rewards (length and structure penalties). This multi-signal optimization addresses the limitations of outcome-only RL, providing both end-state and intermediate semantic guidance.
- Diverse trajectory sampling: Top-p sampling and temperature control increase coverage of plausible user interests beyond beam search or deterministic methods, enabling the generation of high-confidence candidate exploration-to-decision sequences.
Self-Evolving Report Generation Agent
The second agent materializes the transition from an item list to a structured, interpretable report. It processes simulated trajectories to generate decision-support artifacts along multiple axes:
- Dual-channel preference modeling: User priors are factored into structured rubrics (category-attribute weights supporting long-term, stable, and controllable preference encoding) and unstructured experience (contextual, scenario-dependent cues mined from natural language and stored in vector memory).
- Multi-aspect ranking: The agent decomposes user intention into fine-grained aspects (attribute subsets), applies aspect-specific ranking using LLM-based evaluation, and consolidates these to create both overall and aspect-specific ranked lists. This supports both global and facet-level comparison and explanation.
- Structured, interpretable report synthesis: The output is a report containing the simulated trajectory, intent summary, primary and aspect-oriented recommendations, and explicit decision rationales, all grounded in traceable evidence.
Additionally, the agent is equipped with a training-free self-evolution module for both rubrics and experience memory. Online user feedback continuously informs fine-grained rubric weight updates (via best-of-n attribution) and semantic experience expansion (via LLM-guided contrastive extraction), enabling lifelong, sample-efficient personalization.
Empirical Results
Rigorous evaluation—both automatic and with human annotators—demonstrates that Dr.Rec yields substantial numerical improvements in both behavioral modeling and report quality on the Tmall dataset:
- Trajectory simulation: Dr.Rec reports up to 0.1557 Recall@5 and 0.1241 NDCG@5 on purchase prediction; these correspond to up to 52% and 49% improvements over top multi-behavior baselines (MBSTR, PBAT) and reasoning-enhanced models (ReaRec, Plan-and-Solve).
- Report generation: Human and LLM evaluators converge on significant superiority in clarity, coverage, and especially novelty (77% win rate in pairwise comparison; see Figure 2), validating that Dr.Rec generates reports with more evidence-backed, non-trivial insights and reduced user cognitive effort compared to general-purpose LLMs and agent planning frameworks.
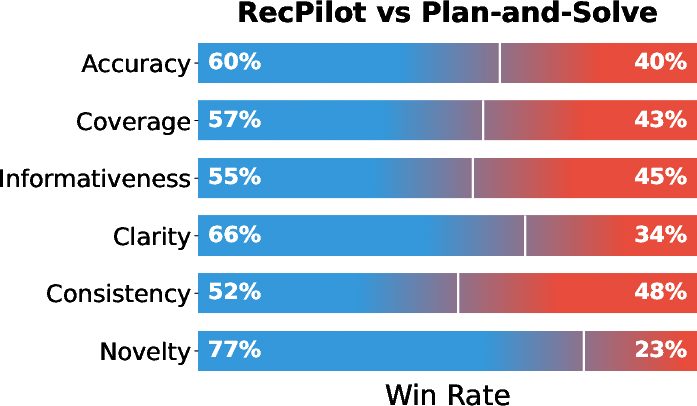
Figure 2: Win-rate analysis in pairwise report comparison reveals Dr.Rec's dominance over Plan-and-Solve, especially in Novelty and Clarity.
Ablations confirm the necessity of all core mechanisms: process and structural rewards in RL, interest decomposition, dual-channel preference representations, and self-evolution. Additional analyses identify sensitive dependencies on hyperparameters governing trajectory sampling diversity (see Figure 3), which control the trade-off between exploration coverage and semantic coherence.
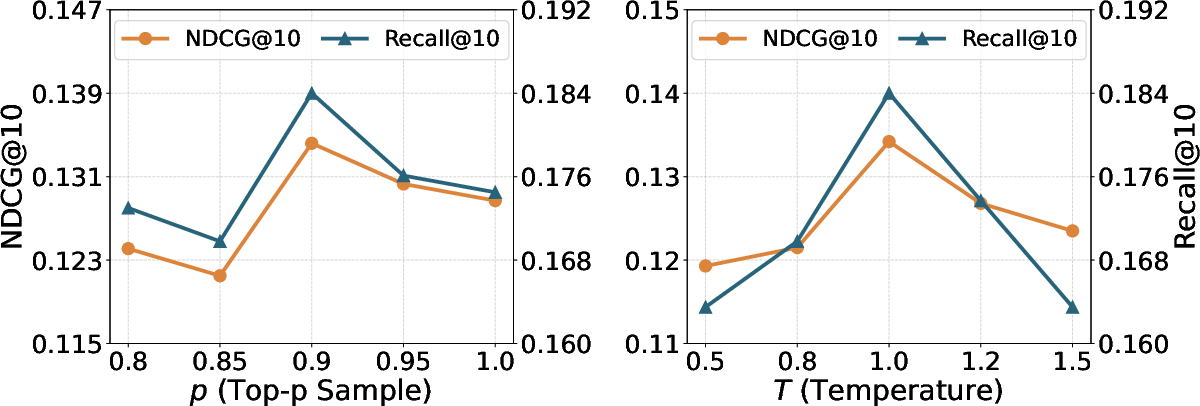
Figure 3: Recall and NDCG performance on Tmall as a function of top-p and temperature, highlighting the importance of controlled trajectory diversity.
Implications and Theoretical Impact
This work reframes the recommender system pipeline: rather than relying on users for iterative exploration and synthesis, intelligent agents absorb these burdens, autonomously traversing item space and providing validated, user-aligned recommendations in interpretable report form. This represents a decisive break from tool-centric paradigms and shifts towards agentic interfaces, mirroring concurrent transformations in IR (deep research) and knowledge work (LLM-based multi-agent orchestration).
Key implications include:
- Interaction cost minimization: By automating labor-intensive behaviors (e.g., attribute extraction, comparison, intent synthesis), cognitive load is transferred from end-users to the agent, with empirical reductions in interaction steps and mental workload.
- Explainability and trust: Reports codify not only the recommended items but disclose (and justify) the underlying reasoning pathways, critical for high-value or risk-averse decision contexts.
- Personalization as a continuous, real-time trajectory: The self-evolution logic enables models to rapidly adapt to shifts or drifts in user interest based on sparse feedback, without periodic retraining.
- Generalizability: The report-centric paradigm is extensible to any scenario requiring trade-off analysis or transparent rationale, including but not limited to high-priced e-commerce, B2B procurement, or professional tool selection.
Future Directions
The paradigm shift embodied in Dr.Rec opens new research avenues:
- Scalable trajectory simulation: Efficient exploration and coverage in very large item spaces remain non-trivial. Integration with learned world models, scalable RL, and amortized sampling will be important.
- Robust evaluation protocols: Traditional accuracy and ranking metrics cannot capture user experience improvements or reduction in cognitive cost, motivating new benchmarks reflecting the holistic utility of agent-generated reports.
- Dual-mode recommenders: Not all users or scenarios benefit equally from deep research; hybrid systems offering both rapid item lists and slower, in-depth reporting (with user mediation) constitute a practical deployment path.
- Factually consistent report synthesis: Reliability and calibration of LLM-generated rationales remain risk factors, and necessitate further research on hallucination mitigation, evidence tracing, and post-generation verification.
Conclusion
"Deep Research for Recommender Systems" introduces a multi-agent architecture that advances recommender system interaction from passive exposure to active, synthesized, and explainable reporting. By unifying generative trajectory simulation, aspect-level personalized ranking, and lifelong preference self-evolution, Dr.Rec establishes new SOTA performance on user behavior modeling and decision support, delivering demonstrable reductions in user effort and cognitive load. The implications are broad, positioning agent-centric, report-driven recommendation as a likely trajectory for next-generation systems that aim to be not just accurate, but deeply helpful and aligned with user decision-making.

