Grow, Don't Overwrite: Fine-tuning Without Forgetting
Abstract: Adapting pre-trained models to specialized tasks often leads to catastrophic forgetting, where new knowledge overwrites foundational capabilities. Existing methods either compromise performance on the new task or struggle to balance training stability with efficient reuse of pre-trained knowledge. We introduce a novel function-preserving expansion method that resolves this dilemma. Our technique expands model capacity by replicating pre-trained parameters within transformer submodules and applying a scaling correction that guarantees the expanded model is mathematically identical to the original at initialization, enabling stable training while exploiting existing knowledge. Empirically, our method eliminates the trade-off between plasticity and stability, matching the performance of full fine-tuning on downstream tasks without any degradation of the model's original capabilities. Furthermore, we demonstrate the modularity of our approach, showing that by selectively expanding a small subset of layers we can achieve the same performance as full fine-tuning at a fraction of the computational cost.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about a common problem in training AI models called “catastrophic forgetting.” When a big LLM is fine-tuned for a new, specific task (like translating French or solving math problems), it can accidentally “overwrite” older skills it learned during pre-training (like basic reasoning or understanding everyday text). The authors propose a new way to fine-tune models that lets them learn new skills without forgetting old ones. Their motto is “Grow, don’t overwrite.”
Key Questions the Paper Asks
- How can we teach a pre-trained model new skills without making it forget what it already knows?
- Can we fine-tune a model so it performs as well as normal fine-tuning on the new task, but keep its original abilities intact?
- Can we do this efficiently, without training all of the model’s parameters?
How They Did It (Methods Explained Simply)
Think of a Transformer model like a large factory with many layers. Each layer has two main parts: an attention module and an MLP (a small “mini-network” that helps process information). The authors “grow” only the MLP parts to add new capacity, instead of changing the whole model.
Here’s the key trick, in everyday terms:
- Imagine an MLP as two steps: first, it expands information (up-projection), then it compresses it back (down-projection).
- The authors duplicate the “expansion” part (they make two identical copies), so the MLP has more room to learn. But to avoid changing the model’s behavior right away, they adjust the “compression” part so the two copies together produce exactly the same output as before.
- This is called “function-preserving” expansion: after the change, the model’s outputs are mathematically identical to the original at the start. So it’s safe and stable to train.
Analogy:
- Picture a team of workers who transform input into output. You add a second identical team, but each team does half the final push, so together they produce the same result as the original single team. Later, you can train the new team to handle extra tasks without disturbing the original team’s work.
Fine-tuning strategies:
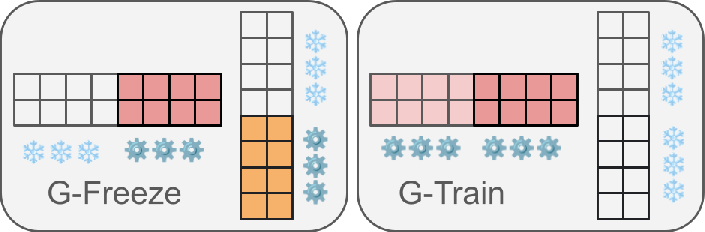
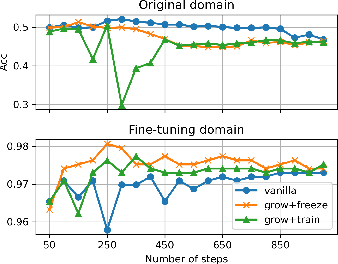
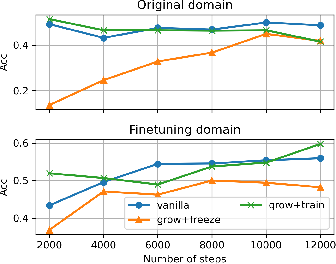
- G-Freeze: Freeze all the original model’s weights and only train the newly added copies. This prevents overwriting the old skills.
- G-Train: For harder tasks (like math), train the whole expanded “up-projection” while keeping the “down-projection” fixed. This helps learn complex reasoning while protecting factual knowledge believed to live in the down-projection.
Efficiency:
- Even if they grow every layer’s MLPs, they only train about 60% as many parameters as standard fine-tuning.
- They can also grow just a small set of layers (the most relevant ones), cutting training down to about 30% of the original while staying competitive.
Main Findings and Why They Matter
The authors tested their method on several tasks:
- New tasks: French translation (MTNT), science entailment (SciTail), science question answering (QASC), and math word problems (MathQA).
- Retention of old skills: WinoGrande, a benchmark for commonsense language understanding.
What they found:
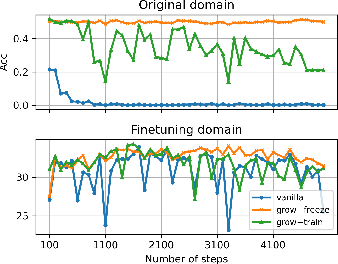
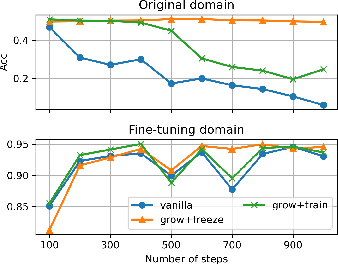
- Their method matches or beats standard fine-tuning on new tasks.
- Unlike standard fine-tuning, it does not cause the model to forget old skills. In some “big shift” tasks like translation and entailment, normal fine-tuning makes old skills collapse, but their method keeps them intact.
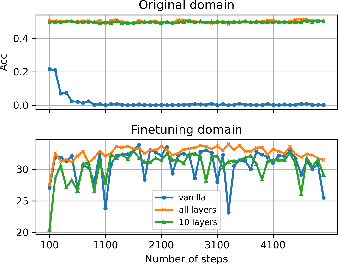
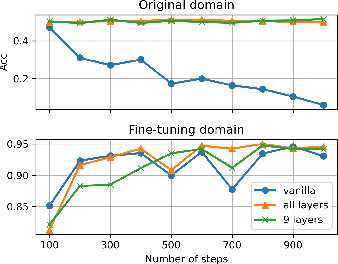
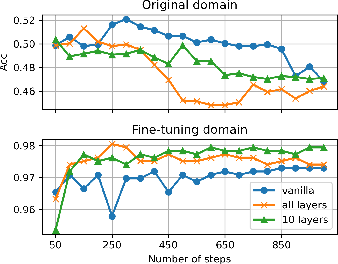
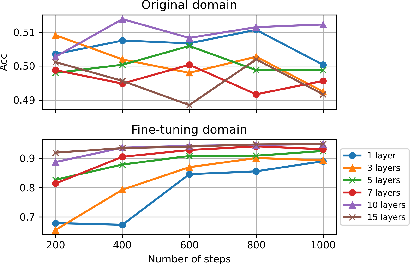
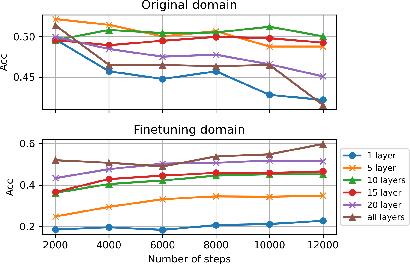
- Growing only 9–10 targeted layers (instead of all layers) often gives the same performance as growing everything, saving a lot of computation.
- More grown layers lead to better performance on complex tasks. Math problems, for instance, benefit from growing more layers.
- The model’s internal “representations” (how it thinks on the inside) stay close to the original, measured with “Function Vectors.” This is a good sign that the model isn’t drifting away from its base knowledge.
Why this matters:
- It proves you don’t have to choose between learning new things and keeping old knowledge. You can have both by adding capacity in a smart way.
- It reduces training cost by focusing only on specific parts of the model.
Implications and Impact
- Safer specialization: You can adapt a general model to a niche area (medicine, law, science) without breaking its basic abilities.
- Lower cost: You don’t have to train all parameters. Growing and training only selected parts saves time and money.
- Better stability: Because the expansion is function-preserving, training starts from a known, stable point, reducing the risk of bad behavior.
- Works with other techniques: The approach can be combined with parameter-efficient fine-tuning methods to get both efficiency and strong memory retention.
In short, the paper shows a practical, simple way to teach AI models new skills without making them forget old ones: instead of rewriting the brain, add new “rooms” and train those, while keeping the original rooms intact.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper proposes a function‑preserving MLP expansion to fine‑tune without forgetting. While promising, several aspects remain unaddressed or insufficiently explored. The points below identify concrete gaps for future work to act on:
- Architectural generality:
- Verify and formalize function preservation for modern LLM MLPs that use gated activations (e.g., SwiGLU/GEGLU) and multi‑matrix structures, not just the single‑matrix ReLU MLPs used in the proof.
- Assess interactions with dropout, residual connections, and layer norms under pre‑norm/post‑norm variants; prove that initialization remains function‑preserving in these settings and quantify any deviations due to stochastic layers.
- Evaluate applicability to other submodules (attention projections, K/V/value dimensions, embeddings). Does expanding only MLPs suffice for tasks dominated by attention (e.g., long‑context retrieval, tool use, code synthesis)?
- Practical efficiency and deployment trade‑offs:
- Quantify inference costs introduced by expansion (FLOPs, latency, memory footprint) and compare to standard fine‑tuning and PEFT (e.g., LoRA) under equal downstream performance and retention.
- Report wall‑clock training time, GPU memory, throughput, and energy use for G‑Freeze/G‑Train, especially when expanding many layers, to substantiate the “fraction of computational cost” claim beyond parameter count.
- Analyze storage overhead and model size growth for multiple successive expansions (e.g., multi‑task scenarios) and whether pruning/merging can control parameter bloat.
- Robustness and scope of “no forgetting”:
- The retention assessment relies on a single proxy (WinoGrande). Evaluate across broader general‑capability suites (e.g., MMLU, BIG‑bench, HellaSwag, ARC, GSM8K, multilingual benchmarks) and LM perplexity on pretraining‑like corpora to validate “eliminates catastrophic forgetting.”
- Provide statistical significance, variance across seeds, and sensitivity to hyperparameters to ensure retention claims are robust.
- Characterize when G‑Train introduces measurable forgetting and establish guidelines for choosing between G‑Freeze and G‑Train per task.
- Scaling and generalization:
- Test on substantially larger models and diverse base architectures (e.g., 7B–70B LLMs, MoE, encoder‑decoder) with full quantitative results; define how outcomes scale with model size and pretraining quality.
- Investigate expansion factor k>2: why does k=2 work best, and can k be adaptively chosen per layer/task? Provide principled criteria or automatic procedures for selecting k.
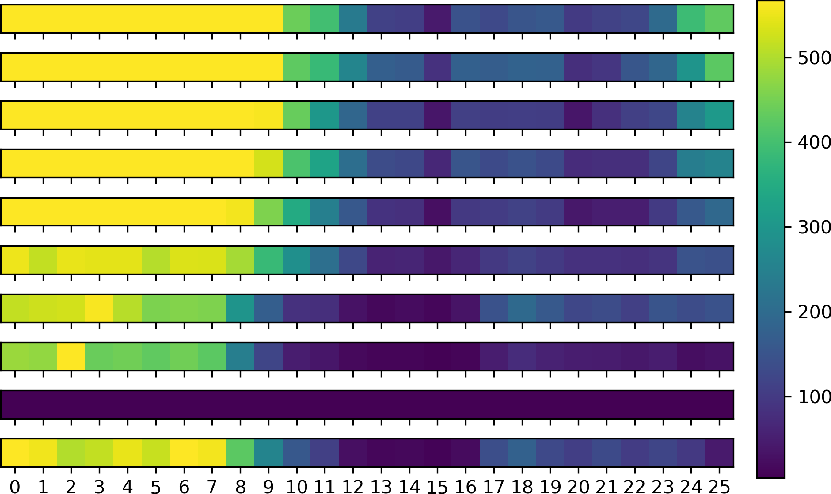
- Layer selection and skill localization:
- The current layer‑selection heuristic requires a preliminary SFT run (which may be costly and induce forgetting). Develop selection methods that do not rely on SFT (e.g., gradients on a small validation set, Fisher information, representational sensitivity, probing).
- Evaluate the stability of layer rankings across seeds, datasets, and tasks; quantify how selection noise impacts performance and retention.
- Explore finer‑grained choices (e.g., per‑neuron or per‑channel expansion) and whether structured sparsity can reduce overhead while preserving gains.
- Optimization dynamics and symmetry:
- Analyze potential symmetry issues from duplicating weights (e.g., identical columns/rows at init). Do the “new” and “original” halves remain coupled without explicit symmetry‑breaking noise? Would small perturbations or orthogonalization at init improve learning speed and diversity?
- Study gradient flow in the expanded blocks (conditioning, effective rank growth, sharpness) to understand when and why expansion yields better plasticity.
- Broader baselines and fairness:
- Compare against strong PEFT and anti‑forgetting baselines (e.g., LoRA, DoRA, Adapters, EWC/SLDA/Replay, knowledge‑retention/editing methods) on both new‑task performance and retention to contextualize gains.
- Ensure hyperparameter parity (learning rates, schedulers, batch sizes, early stopping) across baselines; investigate whether the chosen LR (1e‑3) biases results.
- Continual/multi‑task settings and composability:
- Evaluate sequentially adding multiple tasks: how to manage multiple expansions, route between them, or compose them without interference? Can expansions be merged or distilled back to a compact model?
- Develop mechanisms for task routing or conditional activation so different expanded “skills” do not interfere at inference.
- Mechanistic interpretability and representation claims:
- The claim that down‑projection stores factual knowledge motivates G‑Train; test this across tasks where edits are known to require down‑projection changes and quantify trade‑offs when freezing it.
- Extend the Function Vector (FV) analysis to more tasks and layers, and provide statistical tests; assess whether FV preservation correlates systematically with retention across benchmarks.
- Compatibility and deployment constraints:
- Examine behavior under mixed‑precision and low‑bit quantization; function‑preserving scaling by 1/k may be sensitive to quantization error, potentially breaking equivalence.
- Test interoperability with PEFT (e.g., LoRA on top of expanded blocks), pruning, and distillation; quantify combined benefits and interactions.
- Safety and alignment use cases:
- Explore how the method behaves for safety/alignment fine‑tuning (e.g., instruction following, refusal behaviors). Does freezing large parts of the base model preserve undesirable biases or toxic behaviors that safety tuning seeks to mitigate?
- Evaluation transparency and reproducibility:
- Provide missing training details (batch sizes, token counts, schedulers, weight decay, prompt formats) and release code/checkpoints to facilitate replication and broader validation.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage the paper’s function‑preserving MLP expansion and fine‑tuning strategies to add new skills without erasing foundational ones. Each item lists sectors, potential tools/workflows that could be built now, and key assumptions/dependencies.
- Enterprise LLM adaptation without losing general ability
- Sectors: software, customer support, knowledge management, legal
- Tools/Workflows:
- “Growth Adapter” modules that duplicate MLP up‑projections and scale down‑projections to create per‑task expansions
- Two training modes:
G-Freeze(train only new weights) for strong retention,G-Train(train full up‑projection) for harder tasks - Layer selection pipeline (pre‑run short SFT, rank layers by update magnitude, expand top‑N)
- Assumptions/Dependencies: write access to base weights and architecture; modest compute for expanding a subset of layers; acceptance of slightly higher inference cost from wider MLPs
- Domain‑specific assistants that preserve baseline chat and reasoning
- Sectors: healthcare (clinical note summarization, medical QA), finance (policy/compliance QA), legal (contract analysis)
- Tools/Workflows:
- Task‑specific expansions packaged as plug‑ins for existing assistants (e.g., a “clinical QA growth module”)
- Retention guardrails using proxy tasks (e.g., WinoGrande‑like suite) and “function vector” similarity checks to certify no degradation
- Assumptions/Dependencies: domain data access and governance; rigorous evaluation of retention and safety; on‑prem or VPC training for sensitive data
- Safer continual fine‑tuning in regulated settings
- Sectors: healthcare, finance, public sector
- Tools/Workflows:
- Compliance‑friendly “no‑overwrite” updates: original weights frozen; new skills added in expanded slots
- Audit artifacts: before/after retention benchmarks and FV cosine similarity reports
- Assumptions/Dependencies: regulatory acceptance of proxy retention metrics; versioning/MLOps to manage per‑update expansions
- Multilingual/translation adaptation with retention of base language skills
- Sectors: localization, customer support, content platforms
- Tools/Workflows:
- Per‑language or per‑domain growth modules (e.g., French for “noisy” MT) that can be toggled per request
- Shared base with tenant‑specific expansions to avoid cross‑language interference
- Assumptions/Dependencies: router/metadata to select the right expansion at inference; memory budget for multiple expansions
- In‑house code assistant tuned to company repositories while retaining general coding knowledge
- Sectors: software engineering, DevOps
- Tools/Workflows:
- Growth modules trained on internal codebases; evaluate retention on public coding benchmarks
- Combine with LoRA/QLoRA for memory efficiency; expand only top‑N layers to keep footprint small
- Assumptions/Dependencies: access to internal code; ability to integrate expansion into IDE/server; trade‑off between inference latency and expanded layers
- Multi‑tenant SaaS model serving with per‑customer “growth slots”
- Sectors: enterprise SaaS, contact centers, knowledge platforms
- Tools/Workflows:
- Maintain one base model and store each customer’s new weights (∼30–60% of base) as separate expansions
- Hot‑swap expansions at inference based on customer ID without retraining or risk of interference
- Assumptions/Dependencies: robust routing/keying; storage for many small expansions; guardrails to avoid leakage across tenants
- Education: curriculum‑aligned tutors that retain general reasoning and literacy
- Sectors: education, EdTech
- Tools/Workflows:
- Grade‑/subject‑specific expansions (e.g., AP biology) with built‑in retention checks
- Targeted expansion of 9–10 layers to match full fine‑tuning while keeping compute low
- Assumptions/Dependencies: aligned datasets; on‑device or cloud inference resources; parental/school governance
- Robotics and embodied agents: task‑specific language/planning modules without degrading world knowledge
- Sectors: robotics, industrial automation, home assistants
- Tools/Workflows:
- Growth modules tied to new environments/tasks (e.g., warehouse policy updates)
- Retention tests on core instruction‑following and safety rules
- Assumptions/Dependencies: model used for high‑level planning; resource‑constrained inference may necessitate expanding only a small subset of layers
- Safer model editing and rapid skill injection
- Sectors: search, content moderation, operations
- Tools/Workflows:
- Inject new facts/policies via small expansions; preserve base by freezing original weights
- Rollback by detaching the expansion if an edit is incorrect
- Assumptions/Dependencies: fact/policy datasets; governance around which expansions are allowed in which contexts
- MLOps pipelines for retention‑aware fine‑tuning
- Sectors: platform/ML infrastructure
- Tools/Workflows:
- CI/CD steps: preliminary SFT for layer ranking → function‑preserving expansion →
G-Freezetraining → retention and FV checks → deploy - Metrics dashboard: task performance vs. retention over training steps
- Assumptions/Dependencies: integration with training stack (e.g., Hugging Face/DeepSpeed), model checkpoint tooling, orchestration for per‑task variants
- On‑device or constrained‑compute adaptation with reduced training cost
- Sectors: mobile, IoT, edge devices
- Tools/Workflows:
- Train only new parameters (∼60% if all MLPs grown; ∼30% with top‑layer subset), potentially combined with 4/8‑bit PEFT
- Assumptions/Dependencies: inference overhead must be acceptable; consider expanding fewer layers to bound latency/memory
Long‑Term Applications
These opportunities require further research, scaling, or ecosystem development to realize their full potential.
- Composable multi‑domain “growth libraries” and routers
- Sectors: platform AI, enterprise, education, healthcare
- Tools/Workflows:
- Libraries of expansions for many domains/users; inference‑time router selects which expansion(s) to activate per prompt
- Potential mixtures: combine multiple expansions (e.g., legal + finance) with gating
- Assumptions/Dependencies: reliable domain detection; conflict resolution when multiple expansions interact; memory/latency budget
- Automated skill localization for expansion targeting
- Sectors: AI research, tooling vendors
- Tools/Workflows:
- Replace heuristic layer ranking with automated methods (e.g., task localization, function vectors, attribution)
- “Auto‑Grow” that proposes k and N (expansion factor, layer count) by task difficulty
- Assumptions/Dependencies: scalable interpretability; generalization of FV‑based metrics across tasks/models
- Growth‑merge cycles: expand for learning, then compress for efficient serving
- Sectors: cloud AI, edge deployment
- Tools/Workflows:
- After training with expansions, distill or merge expanded weights back into the base or low‑rank adapters for smaller inference cost
- Explore structured pruning/knowledge distillation specific to expanded MLPs
- Assumptions/Dependencies: algorithms that preserve retention when merging; reliable evaluation showing no regression
- Continual learning at scale: life‑long accumulation of skills
- Sectors: robotics, autonomous systems, enterprise knowledge bases
- Tools/Workflows:
- Periodic expansion as tasks arrive; scheduling policies for when to grow vs. retrain vs. merge
- Memory management to prune obsolete expansions and keep the model bounded
- Assumptions/Dependencies: task sequencing strategies; robust retention metrics; operational budgets for long‑term growth
- Cross‑modal and multimodal extensions
- Sectors: vision, speech, multimodal assistants
- Tools/Workflows:
- Apply function‑preserving growth to ViTs, speech encoders, and multimodal MLP blocks
- Study how expansion interacts with modality‑specific components (e.g., patch embeddings, projection heads)
- Assumptions/Dependencies: proof of function preservation for modality‑specific architectures; data for new modalities
- Standards and policy for “non‑degrading fine‑tuning”
- Sectors: public sector, safety‑critical industries
- Tools/Workflows:
- Certification frameworks requiring function‑preserving initialization, retention proxy suites, and FV similarity thresholds
- Regulatory guidance for update processes that minimize catastrophic forgetting
- Assumptions/Dependencies: consensus on proxies and thresholds; independent evaluation bodies
- Personal AI with private, on‑device expansions
- Sectors: consumer, mobile
- Tools/Workflows:
- Per‑user expansions trained locally (private data remains on device); base is shared, expansions are personal
- Cloud‑assisted distillation or syncing when permitted
- Assumptions/Dependencies: on‑device training capability; secure storage and routing; efficient subset expansion
- Adaptive capacity planning and curriculum growth
- Sectors: education, enterprise training, L&D
- Tools/Workflows:
- Dynamically adjust expansion factor k and number of layers N as tasks grow in complexity (e.g., from retrieval to reasoning)
- Budget‑aware schedulers to meet SLAs while maximizing performance
- Assumptions/Dependencies: accurate complexity estimates; monitoring to avoid over‑growth
- Knowledge graph and RAG integration with growth
- Sectors: enterprise search, analytics
- Tools/Workflows:
- Use external retrieval during training to focus expansions on reasoning integration (not raw memorization)
- Grow only where “fusion” with context is most beneficial
- Assumptions/Dependencies: high‑quality retrieval; training curricula combining RAG and growth effectively
- Federated/consortia training with shared base and local expansions
- Sectors: healthcare networks, finance consortia, public sector collaborations
- Tools/Workflows:
- Each participant trains its own expansion locally and shares only optional compressed summaries; base remains common
- Assumptions/Dependencies: protocols for expansion interchange; privacy constraints; aggregated evaluation of retention across sites
Notes on Feasibility and Dependencies
- Architectural compatibility: The expansion operates on Transformer MLP submodules and assumes element‑wise activations; it is compatible with common setups (bias terms included). Some modern activations (e.g., GELU) should still preserve function because duplicated post‑activation vectors are recombined linearly; nonetheless, implementations must verify numerics.
- Compute and latency: Expansions increase intermediate width and inference cost; mitigate by expanding only 9–10 key layers or smaller k. For on‑device/real‑time applications, careful budgeting is required.
- Data and evaluation: Retention relies on suitable proxies (e.g., WinoGrande) and optionally function vector metrics; organizations should define representative, domain‑appropriate retention suites.
- Licensing and access: Requires access to base weights and the ability to modify/save architectures; some closed‑model licenses may restrict this.
- Tooling ecosystem: Practical deployment benefits from integration into popular stacks (e.g., Hugging Face Transformers) and MLOps pipelines for layer ranking, growth, training, and validation.
In summary, function‑preserving growth enables organizations to add specialized capabilities to pretrained models while provably retaining baseline performance at initialization and empirically maintaining it after training. This unlocks safer adaptation workflows now and supports a roadmap toward scalable, composable, and auditable continual learning systems.
Glossary
- Adapters: Lightweight, task-specific modules inserted into a frozen backbone to enable adaptation with few trainable parameters. "Adapters \citep{houlsby2019parameter}, which insert small, task-specific modules into a frozen model,"
- Adam optimizer: A stochastic gradient-based optimization algorithm that adapts learning rates using first and second moment estimates. "using Adam optimizer with $1e-3$ learning rate."
- Activation patching: An interpretability technique that replaces internal activations to test causal roles of components. "First, an activation patching procedure \cite{meng2022locating} is performed to determine the causal set of attention heads important for the task."
- Attention heads: Independent attention mechanisms within multi-head attention that attend to different aspects of the input. "the causal set of attention heads important for the task."
- Capacity growth: A strategy that adds new parameters to a model (rather than reusing existing capacity) to learn new skills while freezing original weights. "An alternative family of methods, capacity growth, circumvents this trade-off by adding new parameters for new tasks while freezing the original model."
- Catastrophic forgetting: A phenomenon where fine-tuning on new tasks degrades performance on previously learned tasks. "catastrophic forgetting, where new knowledge overwrites foundational capabilities."
- Cosine similarity: A measure of similarity between two vectors based on the cosine of the angle between them. "the cosine similarity between the pre-trained model's FV and the fine-tuned model's FV."
- Deep Fusion: A training paradigm that initializes new modules by reusing pre-trained components to accelerate learning. "inspired by Deep Fusion \citep{mazzawi2023deep}."
- Domain shift: A change in data distribution between training (pre-training) and fine-tuning or evaluation tasks. "tasks with large domain shifts like translation and entailment."
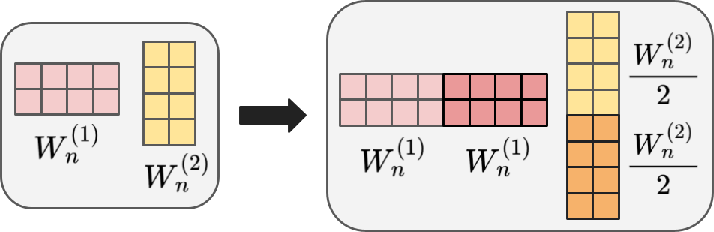
- Down-projection layer: The second linear layer in a Transformer MLP that projects the expanded hidden dimension back to the model dimension. "(a) We double the MLP's hidden dimension by duplicating the up-projection weights () and compensating in the down-projection layer ()"
- Downstream tasks: Tasks used to evaluate or fine-tune a pre-trained model beyond its original training objectives. "matching the performance of full fine-tuning on downstream tasks without any degradation of the model's original capabilities."
- Effective rank: An estimate of the intrinsic dimensionality (rank) of a matrix, often computed via singular values, reflecting update complexity. "The effective rank of weight update matrix."
- Function-preserving expansion: A model-growing approach that increases capacity while guaranteeing identical input-output behavior at initialization. "We introduce a novel function-preserving expansion method that resolves this dilemma."
- Function-preserving property: The guarantee that an expanded model computes the same function as the original at initialization. "The function-preserving property holds for any value of ."
- Function Vectors (FV): Compact vectors representing task-specific computations within model hidden states discovered via interpretability tools. "Function Vectors (FV): a compact vector representation identified within transformer models hidden states during in-context learning (ICL)"
- G-Freeze: Variant that trains only the newly added weights after expansion, keeping original parameters frozen. "G-Freeze: Our primary and default strategy."
- G-Train: Variant that fine-tunes the entire expanded up-projection while freezing the down-projection and original parameters. "G-Train: An alternative strategy designed for cognitively demanding tasks like mathematical reasoning."
- In-context learning (ICL): The ability of LLMs to perform tasks by conditioning on examples in the prompt without parameter updates. "identified within transformer models hidden states during in-context learning (ICL)"
- Identity modules: Inserted network components initialized to act as identity mappings, often used to enable stable expansion. "inserting randomly initialized identity modules, which is inefficient as it ignores existing knowledge"
- Layer normalization: A normalization technique applied across features to stabilize and accelerate training in deep networks. "with residual connections and layer normalization applied after each."
- LoRA (Low-Rank Adaptation): A PEFT method that approximates weight updates with trainable low-rank matrices to reduce trainable parameters. "Low-Rank Adaptation (LoRA) \citep{hu2022lora}, which approximates weight updates using trainable low-rank matrices."
- MHA (multi-head self-attention): The attention mechanism in Transformers that computes multiple attention heads in parallel for richer representations. "multi-head self-attention (MHA) mechanism"
- MLP submodules: The feed-forward blocks in Transformer layers that provide non-linear transformations between attention operations. "within a Transformer's MLP submodules (i.e., the intermediate neurons in the MLP)."
- Parameter Efficient Finetuning (PEFT): Techniques that adapt models by updating a small subset of parameters or adding small modules. "Parameter Efficient Finetuning (PEFT)."
- Proxy benchmark: A stand-in evaluation dataset used to approximate performance on the (often inaccessible) pre-training distribution. "the WinoGrande proxy benchmark."
- ReLU: A nonlinear activation function defined as max(0, x), commonly used in MLPs. "ReLU"
- Representational shift: A change in internal representations relative to the base model, often linked to forgetting. "preventing the representational shift known to cause forgetting."
- Residual connections: Skip connections that add a layer’s input to its output to ease optimization and preserve information. "with residual connections and layer normalization applied after each."
- Replication factor (k): The number of copies used to expand parameters during function-preserving growth. "dividing them by the replication factor ."
- SacreBLEU: A standardized implementation of BLEU used for fair and comparable machine translation evaluation. "Performance on mtnt is measured using SacreBLEU"
- Standard fine-tuning (SFT): Updating all or most model parameters on a new task without architectural changes. "Our approach matches standard fine-tuning (SFT) performance on new tasks"
- Transformer: A neural network architecture built from stacked attention and feed-forward layers with normalization and residuals. "A Transformer model is composed of a stack of layers."
- Up-projection layer: The first linear layer in a Transformer MLP that expands the hidden dimension to a larger intermediate size. "duplicating the up-projection weights ()"
- Weight update matrix: The matrix of parameter changes between training steps, analyzed to study adaptation characteristics. "from the perspective of the weight update matrix,"
Collections
Sign up for free to add this paper to one or more collections.