Training Language Models via Neural Cellular Automata
Abstract: Pre-training is crucial for LLMs, as it is when most representations and capabilities are acquired. However, natural language pre-training has problems: high-quality text is finite, it contains human biases, and it entangles knowledge with reasoning. This raises a fundamental question: is natural language the only path to intelligence? We propose using neural cellular automata (NCA) to generate synthetic, non-linguistic data for pre-pre-training LLMs--training on synthetic-then-natural language. NCA data exhibits rich spatiotemporal structure and statistics resembling natural language while being controllable and cheap to generate at scale. We find that pre-pre-training on only 164M NCA tokens improves downstream language modeling by up to 6% and accelerates convergence by up to 1.6x. Surprisingly, this even outperforms pre-pre-training on 1.6B tokens of natural language from Common Crawl with more compute. These gains also transfer to reasoning benchmarks, including GSM8K, HumanEval, and BigBench-Lite. Investigating what drives transfer, we find that attention layers are the most transferable, and that optimal NCA complexity varies by domain: code benefits from simpler dynamics, while math and web text favor more complex ones. These results enable systematic tuning of the synthetic distribution to target domains. More broadly, our work opens a path toward more efficient models with fully synthetic pre-training.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-language summary of “Training LLMs via Neural Cellular Automata”
What is this paper about?
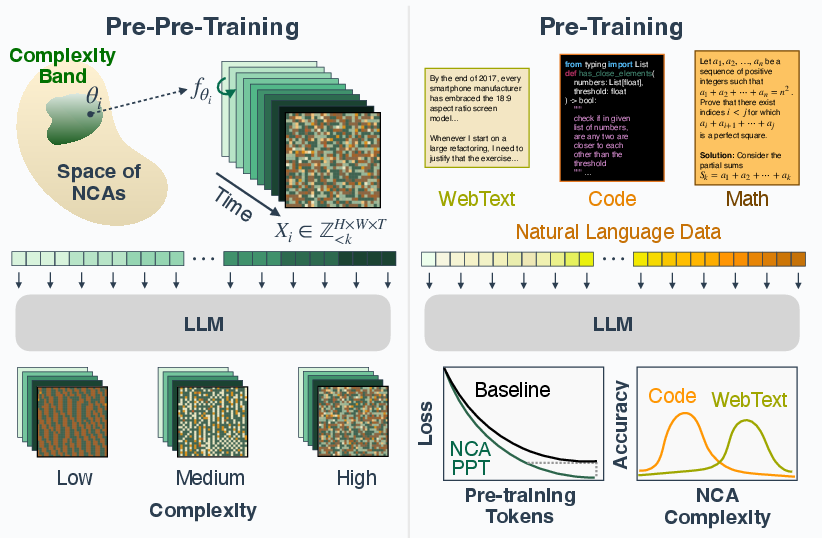
This paper explores a new way to help LLMs (like chatbots) learn faster and better. Instead of only training on real text from the internet, the authors first train the model on synthetic (made-up) data that looks nothing like language: it’s a kind of animated grid of colored symbols that changes over time following simple rules. This step happens before normal text training, so they call it “pre-pre-training.”
The big idea: learning to predict patterns and rules—even without words—can teach a model useful thinking skills that make later language learning easier and more efficient.
What questions are the authors asking?
- Can non-language data (just structured patterns) help a LLM learn useful skills for reading and writing?
- Is there a cheaper, cleaner way to prepare models before feeding them tons of text?
- Which parts of a model benefit most from this early practice?
- How complex should the synthetic data be for different targets like math, code, or general web text?
How did they do it? (Explained simply)
The authors use something called neural cellular automata (NCA). Think of this like a video game on a grid:
- Each tiny square (cell) holds a simple symbol (like a color or number).
- Every step, each cell changes based on a rule that looks at its neighbors—similar to Conway’s Game of Life.
- Here, the “rule” isn’t fixed; it’s a tiny neural network. Each new rule creates a different kind of pattern and motion on the grid.
They:
- Generate lots of these grid “videos” with different rules, so the patterns vary widely—from simple repeating shapes to very complex, chaotic ones.
- Turn each small patch of the grid into a token (like a word piece), and ask a transformer (a standard LLM architecture) to predict the next patch token—just like it predicts the next word in a sentence.
- After this synthetic “pattern practice,” they train the same model normally on real text (web text, math, or code).
- Finally, they test the results on benchmarks for reasoning, math, and coding.
Helpful analogies:
- Pre-pre-training = warm-up drills before the actual practice. You’re not reading stories yet; you’re doing pattern puzzles that sharpen your attention and rule-following.
- Attention layers = the model’s “spotlight,” deciding what earlier parts matter for predicting what comes next.
- Perplexity = a measure of surprise. Lower is better (the model is less surprised by the next token).
- Compression (like zipping a file) = “How squishable is this data?” Hard-to-squish data is more complex.
What did they find, and why does it matter?
Here are the highlights, kept brief:
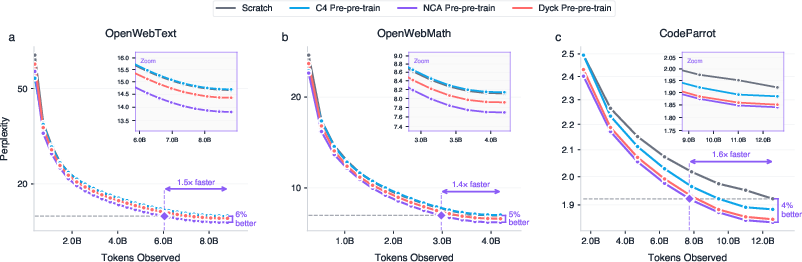
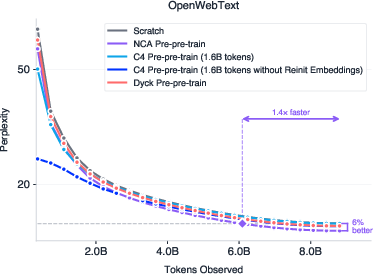
- Training on only 164 million synthetic NCA tokens before real text improved language modeling by up to 6% and made training up to 1.6× faster.
- Surprisingly, this beat pre-pre-training on 1.6 billion tokens of real text from Common Crawl (10× more data and more compute). In other words, a little of the right kind of practice beat a lot of ordinary text.
- These gains carried over to reasoning tasks:
- Math (GSM8K): small but consistent boosts.
- Coding (HumanEval): better at pass@1 and competitive at higher tries.
- General reasoning (BigBench-Lite): clearer gains, especially when allowed a few attempts.
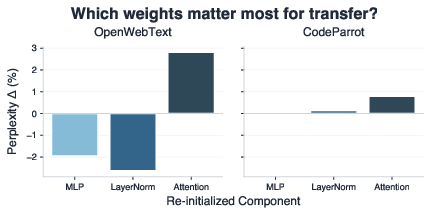
- The most transferable part of the model was the attention layers (the “spotlight”). They seemed to learn general skills like tracking long-range dependencies and figuring out hidden rules. The MLP layers (more like “lookup and mix” parts) were more domain-specific—sometimes helping, sometimes getting in the way.
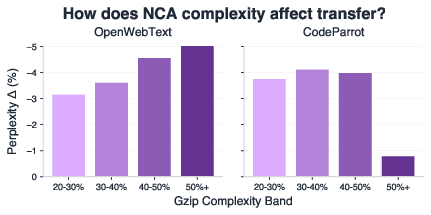
- The best kind of synthetic patterns depends on the target:
- Code worked best with simpler synthetic patterns.
- Math and web text worked best with more complex patterns.
- This means you can tune the synthetic data’s complexity to match what you want the model to be good at.
Why this matters:
- It suggests models don’t need meaning or words to learn useful thinking habits. Structure and patterns can be enough to build core “reasoning muscles” early on.
- Synthetic data is cheap, fast to create, and free of messy human biases and curation problems.
- We can design and adjust the practice data to target specific skills (e.g., stronger logic for code, more complex dependencies for math).
What could this change in the future?
- More efficient training: Models could first learn general thinking from synthetic patterns, then learn vocabulary and facts from a smaller amount of clean, curated text. This saves time, money, and energy.
- Custom training: You could “dial in” synthetic data complexity to fit different domains—like using simpler patterns for code-focused models and richer patterns for math or science models.
- Better small models: With tuned practice, smaller models might punch above their weight, performing better without needing trillions of words.
In short: The paper shows that before teaching a model language, it helps to teach it how to pay attention to patterns and rules. Doing this with neural cellular automata—a kind of rule-based grid game—makes later language learning faster and better, sometimes even beating a huge amount of text-only practice.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and unresolved questions that future work could address.
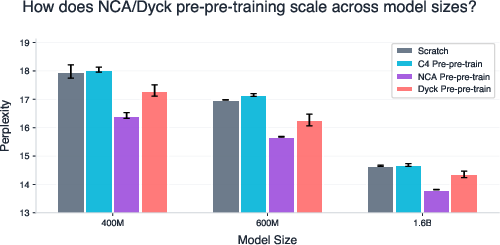
- Scaling to larger models: Do the reported gains persist or change at >7B, 13B, and 70B+ parameters, and under compute-optimal token budgets for those scales?
- Architecture generality: How robust are effects across non-Llama architectures (e.g., GPT-NeoX, Mamba, state space models), Mixture-of-Experts, and different positional encodings (RoPE vs ALiBi)?
- Long-context regimes: Do NCA-induced attention priors transfer to much longer contexts (32k–200k) beyond the 1024-token setup?
- Domain breadth: Are gains consistent on broader and harder benchmarks (e.g., MMLU, ARC-Challenge, TruthfulQA, MBPP, Codeforces, SAT-style math), multilingual corpora, and domain-specific corpora (biomed, law)?
- Magnitude of reasoning gains: After controlling for perplexity (iso-perplexity comparisons), do the reasoning improvements exceed what perplexity alone predicts?
- Pre-pre-training schedule: Is staged pre-pre-training optimal, or would interleaving synthetic and natural tokens (or alternating curricula) yield better transfer?
- Synthetic-to-natural token ratio: What is the compute-optimal proportion of NCA tokens to natural language tokens for different model sizes and domains?
- Generator ablations: How do results change with different NCA variants (continuous/stochastic NCAs, anisotropic neighborhoods, larger grids, 1D/3D lattices, asynchronous updates, different neighborhood radii)?
- Grid and serialization design: How sensitive are results to grid size (12×12 fixed here), patch size (2×2), overlap vs non-overlap, and serialization order (raster vs space-filling curves) and delimiters?
- Tokenization confounds: Does the 104 patch-token vocabulary create frequency and Zipfian artifacts that unduly ease next-token prediction compared to alternative tokenizations?
- Complexity measurement: gzip is a crude proxy; which complexity axes (epiplexity, entropy rate, mutual information, long-range dependency statistics, fractal dimension, Kolmogorov proxies) best predict transfer?
- Complexity matching: Can we algorithmically match synthetic complexity to target domains beyond gzip bands—e.g., via multi-metric matching or learned predictors of transfer?
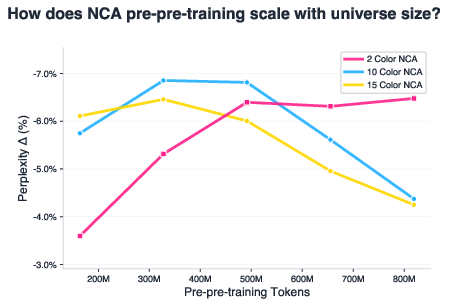
- Alphabet size vs diversity: Why do larger alphabets (n=10,15) show diminishing returns while n=2 scales better? Can guided sampling over larger rule spaces fix diversity/coverage issues?
- Sampling the rule space: Random weight sampling plus gzip filtering may give poor coverage; can we learn or evolve the distribution over NCA rules to target specific downstream domains?
- Meta-optimization of generators: Can we gradient-free (e.g., ES) or gradient-based meta-learn NCA generators to maximize a transfer metric (e.g., downstream perplexity drop) under a token budget?
- Objective design: Beyond next-token prediction, would auxiliary tasks (predicting the latent NCA rule, contrastive trajectory matching, masked modeling, multi-step rollout consistency) enhance transfer?
- Mechanistic interpretability: What specific attention circuits (e.g., induction heads, copy heads, rule-inference patterns) emerge during NCA pre-pre-training, and how do they evolve during language pre-training?
- Component-wise transfer strategy: Is it better to transfer only attention, freeze-unfreeze schedules, or selective layer subsets? What policies minimize MLP-induced interference noted on some domains?
- Negative transfer characterization: When and why do MLP/LayerNorm transfers hurt (e.g., OpenWebText)? Can we detect misalignment early and adaptively reinitialize or regularize?
- Robustness and safety: Does synthetic pre-pre-training affect robustness to adversarial prompts, calibration, truthfulness, or bias formation compared to natural-language-only pre-training?
- Generalization beyond language: Do NCA-primed attention priors transfer to vision, audio, proteins, or RL policy learning without language pre-training?
- Full synthetic pre-training: To what extent can models be trained entirely on synthetic data and later grounded with minimal natural text for semantics? How much real data is actually needed?
- Data/compute accounting: What are the end-to-end generation and training costs (wall-clock, energy) of NCA pipelines versus data curation of web-scale corpora at parity in downstream quality?
- Fair baselines: Are C4 comparisons confounded by suboptimal C4 data quality, tokenization, or sampling? Would curated textbooks or highly filtered corpora reverse the advantage?
- Curriculum over complexity: Does a schedule that ramps up NCA complexity over training improve transfer relative to static complexity bands?
- Long-range dependency diagnostics: Do NCA-pretrained models measurably improve on synthetic probes of dependency length, algorithmic copying, and hierarchical generalization?
- Positional encoding transfer: Do NCA-trained positional representations transfer, and would reusing them (instead of reinitializing) help downstream learning?
- Instruction tuning and RLHF: Do pre-pre-training gains persist or change after instruction tuning, preference optimization, or safety fine-tuning?
- Catastrophic interference: Does synthetic pre-pre-training reduce or increase interference when later specializing to very different domains (e.g., code → poetry)?
- Data diversity and de-duplication: Are NCA trajectories sufficiently diverse and de-duplicated across seeds and rule initializations to avoid implicit memorization?
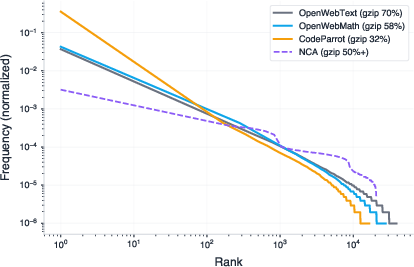
- Statistical alignment: How do NCA token distributions (Zipf tails, burstiness, entropy) compare to target domains, and which mismatches most harm transfer?
- Long-horizon rollouts: Would longer NCA trajectories (more timesteps) that emphasize nonlocal dependencies improve attention priors, or do they increase chaos and hurt learning?
- Safety and ethics: While synthetic data avoids copyright and human biases, could it induce novel brittleness or spurious priors that surface during deployment?
- Reproducibility and standardization: Can the community standardize NCA generator specs, seeds, and complexity bands to ensure comparable, reproducible evaluations?
- Theoretical guarantees: Can we formalize when deterministic synthetic processes like NCA provably induce inductive biases that aid learning on classes of natural token processes?
- Mixing with other synthetic families: How do NCAs compare or combine with other generators (PCFGs with complexity control, L-systems, probabilistic programs, physics/PDE simulators, elementary CA, Lenia, graph growth processes)?
- Early-training dynamics: Are the observed advantages an initialization effect or do they reshape scaling laws throughout training? Analyze loss landscape shifts and sample efficiency curves in detail.
- Hyperparameter sensitivity: How sensitive are gains to optimizer, batch size, LR schedule, weight decay, context length, and gradient clipping, especially across domains and scales?
Practical Applications
Practical applications of “Training LLMs via Neural Cellular Automata”
The paper introduces a synthetic pre-pre-training stage using neural cellular automata (NCA) that: (a) yields 1.4–1.6× faster convergence and up to 6% lower perplexity on web text, math, and code; (b) improves downstream reasoning (GSM8K, HumanEval, BigBench-Lite); (c) shows that attention layers carry most transferable priors; and (d) enables domain-targeted tuning of synthetic data complexity (e.g., simpler dynamics for code; more complex for math/web). Below are actionable applications, grouped by time horizon.
Immediate Applications
The following can be deployed now with modest engineering effort, using the paper’s codebase and standard pre-training stacks.
- Synthetic “Stage-0” pre-pre-training to cut compute costs and time
- Sectors: software, cloud/ML platforms, academia, startups
- What: Add an NCA pre-pre-training stage before natural-language pre-training to improve token efficiency and convergence speed (1.4–1.6×) and final perplexity (up to 6%).
- Tools/products/workflows:
- “Stage-0” NCA data generator service; plug-in to existing MLOps (Hugging Face Datasets, PyTorch/DeepSpeed pipelines).
- Training recipe that re-initializes embeddings but transfers attention and (optionally) other layers.
- Assumptions/dependencies:
- Gains reported at ~1.6B params; effects may shift with larger/smaller models.
- Need GPU time for Stage-0 (offset by later pre-training savings).
- Best results require simple hyperparameter sweep (LR, weight decay) as in paper.
- Domain-targeted synthetic curricula via NCA complexity matching
- Sectors: software (code LMs), education (math LMs), web search/content (general LMs)
- What: Tune NCA complexity using gzip compressibility to match target domain (simpler rules for code; more complex for math/web) and improve transfer.
- Tools/products/workflows:
- “Complexity-Tuner” that bins NCA trajectories by gzip band (e.g., 30–40% vs 50%+).
- Lightweight AutoML loop to pick the best band per domain.
- Assumptions/dependencies:
- gzip is a practical, imperfect proxy for complexity; domain validation is needed.
- Mis-tuned complexity can reduce transfer or slow convergence.
- Attention-centric transfer strategy to maximize positive transfer
- Sectors: enterprise ML, academia
- What: Preserve attention weights from the NCA stage and consider re-initializing MLP/LayerNorm when domain mismatch is high (web text vs code) to avoid interference.
- Tools/products/workflows:
- “Attention-Only Transfer” toggle in pre-training pipeline.
- Selective re-initialization automation for diagnostics.
- Assumptions/dependencies:
- Effect size may vary by domain and model size.
- Requires clean component-wise checkpointing.
- Safer, IP- and privacy-friendly warm starts
- Sectors: healthcare, finance, legal, public sector
- What: Use synthetic pre-pre-training to reduce exposure to copyrighted or sensitive data while still instilling long-range dependency tracking and in-context learning.
- Tools/products/workflows:
- Privacy-first training policies: synthetic Stage-0 + curated, de-risked fine-tuning corpora.
- Compliance artifacts documenting synthetic share in pretraining.
- Assumptions/dependencies:
- Semantics still require curated natural data later.
- Synthetic data can still encode biases from generator choices (monitoring needed).
- Small, specialized models with better reasoning under tight budgets
- Sectors: on-device assistants, embedded/edge AI, robotics
- What: Train compact LMs for targeted domains (e.g., math tutoring, IDE copilots) with improved reasoning using NCA Stage-0 versus scaling parameters/tokens.
- Tools/products/workflows:
- “TinyLM+NCA” recipes for 100M–1B models; mobile/edge deployment.
- Assumptions/dependencies:
- Measurement on small models needed; paper shows 400M–1.6B trends are favorable.
- Rapid experimentation and pedagogy
- Sectors: academia, ML education, labs
- What: Use the open-source NCA generator to teach/diagnose in-context learning, attention circuits, and complexity effects in coursework and lab settings.
- Tools/products/workflows:
- Reproducible lab kits: reinit ablations; complexity bands; attention probing.
- Assumptions/dependencies:
- Requires modest GPU access; CPU-only NCA generation is feasible but slower.
- Data governance and quality control via compressibility metrics
- Sectors: data platforms, content moderation, policy/compliance
- What: Apply gzip-based complexity signals to label or stratify natural corpora (e.g., remove overly redundant segments; match target domain complexity).
- Tools/products/workflows:
- “Compressibility-based sampler” in data loaders.
- Assumptions/dependencies:
- Compressibility is not a substitute for semantic filtering; it complements dedup/PII removal.
- Benchmarking and diagnostics for reasoning readiness
- Sectors: model evaluation vendors, enterprise ML
- What: Use NCA pre-pre-training as a standardized diagnostic to assess whether a model’s attention mechanisms support long-range dependency tracking prior to costly pre-training.
- Tools/products/workflows:
- “NCA-Probe” suite: short Stage-0 run + evaluation on synthetic held-out rules; attention-head inspection.
- Assumptions/dependencies:
- Predictiveness for very-large-scale models needs validation.
Long-Term Applications
These require further research, scaling studies, or productization, but are directional pathways implied by the paper’s findings.
- Fully synthetic pre-training with minimal curated language fine-tuning
- Sectors: software, cloud AI, open-source foundation models
- What: Replace most of language pre-training with synthetic curricula (NCA and beyond), then fine-tune on small, high-quality corpora to acquire semantics.
- Tools/products/workflows:
- “Synthetic-first” pretraining platforms; synthetic curriculum schedulers; post-hoc semantic grounding.
- Assumptions/dependencies:
- Demonstrated here as pre-pre-training; full replacement needs better coverage of semantic phenomena and scaling proof.
- Auto-curriculum design and generator search
- Sectors: AutoML, research platforms
- What: Automatically discover NCA (and other generators) parameters—alphabet size, grid size, noise, complexity bands—to maximize target-domain transfer.
- Tools/products/workflows:
- Bayesian optimization/RL controllers over generator hyperparameters; closed-loop validation on downstream perplexity/accuracy.
- Assumptions/dependencies:
- Requires fast evaluation proxies and careful overfitting control to target metrics.
- Domain-matched synthetic pre-training across sectors
- Sectors: healthcare (clinical reasoning), finance (quant/maths), cybersecurity (log analysis), bioinformatics (genomics), education (math tutors), robotics (planning)
- What: Tailor synthetic distributions to approximate each domain’s computational character (e.g., high long-range dependencies for genomics; rigid state tracking for code).
- Tools/products/workflows:
- “Domain Complexity Profiler” that measures compressibility, long-range dependency statistics of target corpora, then matches synthetic generator settings.
- Assumptions/dependencies:
- Complexity is multi-dimensional; gzip alone is insufficient—additional metrics (e.g., mutual information at long lags, epiplexity) likely needed.
- IP-safe and privacy-preserving foundation models
- Sectors: policy, regulated industries
- What: Train models predominantly on synthetic data to reduce copyright/privacy exposure; align with emerging AI data provenance regulations.
- Tools/products/workflows:
- Synthetic proportion attestations; audit trails; regulator-ready evidence packages.
- Assumptions/dependencies:
- Must demonstrate parity in safety and capability versus language-heavy pretraining.
- Energy- and cost-efficient training standards
- Sectors: cloud providers, sustainability initiatives
- What: Adopt synthetic Stage-0 to reduce GPU-hours and emissions per quality point of pretraining progress.
- Tools/products/workflows:
- “Green Pretraining” guidelines; carbon accounting that credits synthetic shares; cloud credits tied to efficiency.
- Assumptions/dependencies:
- Requires standardized reporting and third-party verification of efficiency gains.
- Architecture co-design: parameter allocation guided by transfer analysis
- Sectors: model design, chip co-design, enterprise ML
- What: Allocate more compute/params to attention for general reasoning, and manage MLP specialization for domain knowledge, based on observed transfer patterns.
- Tools/products/workflows:
- Attention-heavy variants; selective freezing/regularization of MLPs post Stage-0.
- Assumptions/dependencies:
- Needs validation across much larger scales and MoE settings.
- Multimodal synthetic pre-training (spatiotemporal world models)
- Sectors: robotics, autonomous systems, AR/VR
- What: Extend NCA-style generators to video-like or 3D tokenizations to teach latent-rule inference and prediction in world-model architectures.
- Tools/products/workflows:
- Spatiotemporal CA/NCAs; patch-tokenization streams; transformer world models preconditioned on synthetic dynamics.
- Assumptions/dependencies:
- Requires careful bridging from synthetic dynamics to real sensor streams; sim2real gaps.
- Safety-by-construction curricula
- Sectors: AI safety, alignment
- What: Use synthetic rules/tasks to instill consistent rule-following, compositional reasoning, and robust in-context learning before exposure to messy natural data.
- Tools/products/workflows:
- “Rule-Following Curriculum” that gradually increases complexity and adversarial patterns; post-training safety evaluations.
- Assumptions/dependencies:
- Transfer from synthetic rule adherence to natural instruction-following must be empirically validated.
- Data governance tooling: complexity-aware curation of natural corpora
- Sectors: data platforms, content providers
- What: Combine compressibility and long-range dependency metrics to rebalance pretraining corpora (reduce redundancy, improve diversity).
- Tools/products/workflows:
- “Complexity-Aware Sampler” for large corpora; dedup+compressibility joint filters; per-domain sampling policies.
- Assumptions/dependencies:
- Need to ensure complexity targeting does not inadvertently drop rare but important semantics.
- On-device and edge assistants with better reasoning per FLOP
- Sectors: mobile, IoT, automotive
- What: Leverage synthetic pre-pre-training to ship smaller assistants that retain stronger ICL and long-range dependency tracking for everyday tasks (planning, code snippets, math help).
- Tools/products/workflows:
- Distillation from NCA-conditioned teachers; hardware-aware fine-tuning.
- Assumptions/dependencies:
- Must validate latency/throughput trade-offs and user-perceived improvements.
- Standardized “synthetic share” benchmarks and disclosures
- Sectors: policy, standards bodies, model marketplaces
- What: Create reporting standards and benchmarks that quantify how much and which kind of synthetic pretraining a model used, with correlations to downstream safety/capability.
- Tools/products/workflows:
- Metadata schemas; evaluation suites for synthetic transfer; procurement checklists.
- Assumptions/dependencies:
- Community consensus on useful metrics (e.g., epiplexity proxies, long-range MI) is needed.
In all cases, feasibility hinges on a few key assumptions and dependencies identified by the paper: attention layers are the primary carriers of transferable priors; optimal synthetic complexity is domain-dependent and must be tuned; semantic grounding still requires curated natural data; and results demonstrated at 400M–1.6B parameters must be confirmed at larger scales and with diverse architectures.
Glossary
- Alphabet size: Number of distinct symbols (states) available to each cell in the automaton, controlling rule-space expressiveness and data complexity. "alphabet size (size of the state space)"
- Attention layers: Transformer components that compute token-to-token dependencies and are key carriers of transferable computational priors. "attention layers are the most transferable"
- Autoregressive modeling: Training paradigm where the model predicts each next token conditioned on previous tokens. "We train a transformer autoregressively"
- Bayesian view of in-context learning: Perspective that next-token prediction induces implicit Bayesian inference over latent rules or concepts from the context. "Bayesian view of in-context learning"
- BigBench-Lite: A benchmark suite for evaluating broad reasoning capabilities of LLMs. "BigBench-Lite"
- C4: A large natural language corpus (Colossal Clean Crawled Corpus) used for pre-training baselines. "C4 pre-pre-training"
- CodeParrot: A code-focused corpus used as a downstream pre-training dataset for evaluating transfer. "CodeParrot"
- Compute-optimal scaling laws: Guidelines relating optimal dataset size to model size for efficient training. "compute-optimal scaling laws suggest"
- Convergence speed: How quickly a model achieves a target performance during training, often measured in tokens to reach a given perplexity. "convergence speed"
- Cross-entropy loss: Standard objective for next-token prediction that measures divergence between predicted and true token distributions. "cross-entropy loss"
- Dyck language: A family of formal languages of balanced parentheses used to probe syntactic/stack-like reasoning. "Dyck pre-pre-training"
- Epiplexity: A complexity measure for computationally bounded observers capturing emergent structure learnable from deterministic processes. "epiplexity was introduced as a complexity metric for computationally bounded observers"
- GSM8K: A grade-school math word problem benchmark for evaluating mathematical reasoning. "GSM8K"
- Gzip compression ratio: Practical proxy for sequence complexity via compressibility; higher ratios indicate more complex, less compressible data. "gzip compression ratio serves as a practical measure of intrinsic sequence complexity."
- Gzip compressibility band: A targeted range of gzip ratios used to control and sample specific complexity regimes of synthetic data. "50%+ gzip compressibility band"
- HumanEval: A coding benchmark evaluating functional correctness of generated programs via unit tests. "HumanEval"
- In-context learning: The ability of a model to infer and apply latent rules from the prompt without parameter updates. "in-context learning"
- Induction heads: Attention circuits that copy and extend patterns from earlier tokens to later positions, enabling ICL. "induction heads -- attention circuits that help copy information"
- Kolmogorov complexity: The length of the shortest program that produces a sequence; a formal notion of intrinsic complexity. "Kolmogorov complexity"
- LLM: Scaled transformer-based model trained on next-token prediction over large corpora. "LLMs"
- LayerNorm: Normalization layer in transformers whose weights can encode domain-specific statistics. "LayerNorm weights"
- Lempel–Ziv compression: Dictionary-based algorithm underlying gzip that upper-bounds Kolmogorov complexity in practice. "Lempel-Ziv compression"
- Logits: Unnormalized scores output by a model before the softmax that determine token probabilities. "logits over next-cell states"
- Mixture-of-Expert architectures: Models that route inputs to specialized subnetworks (experts), often scaling MLP capacity. "Mixture-of-Expert architectures"
- MLP (Multilayer Perceptron): Feedforward sublayers in transformers that tend to store domain-specific patterns. "MLP layers"
- Neural cellular automata (NCA): Cellular automata whose local update rule is parameterized by a neural network, enabling diverse, learnable dynamics. "neural cellular automata (NCA)"
- Neural scaling laws: Empirical laws relating performance to compute, model size, and data size in neural networks. "neural scaling laws predict that continued improvements require exponentially more data"
- Next-token prediction: Objective of predicting the following token given prior context, central to LLM training. "Next-token prediction"
- OpenWebMath: A mathematics-focused web text corpus used for downstream pre-training. "OpenWebMath"
- OpenWebText: A web text corpus used to evaluate language modeling transfer. "OpenWebText"
- Pass@k: Metric for generative tasks measuring whether any of k independent samples solve the problem. "pass@"
- Perplexity: Exponential of the average negative log-likelihood; a standard measure of language modeling quality. "validation perplexity"
- Periodic boundary conditions: Topology where grid edges wrap around, making opposite borders adjacent. "periodic boundaries"
- Pre-pre-training: An initial synthetic training phase before standard language pre-training to instill transferable priors. "pre-pre-training"
- Softmax: Normalization function that converts logits into probabilities over tokens or states. "softmax"
- Spatiotemporal: Involving structure over both space and time, as in NCA trajectories. "spatiotemporal"
- State alphabet: The finite set of possible cell states in a cellular automaton. "state alphabet"
- Token budget: The number of training tokens allocated to a dataset or phase, used for fair comparisons. "matched token budgets"
- Transformer: The attention-based neural network architecture underlying modern LLMs. "transformer"
- Weight tying: Sharing parameters between input and output embeddings to reduce model size and improve consistency. "weight-tying"
- Zipfian distribution: Heavy-tailed frequency distribution where rank and frequency follow a power law, common in natural language. "Zipfian token distributions"
Collections
Sign up for free to add this paper to one or more collections.