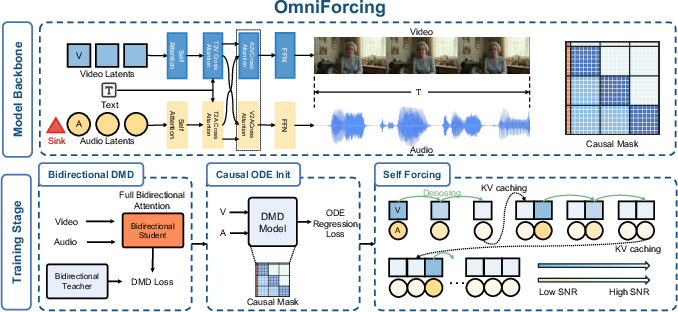
OmniForcing: Unleashing Real-time Joint Audio-Visual Generation
Abstract: Recent joint audio-visual diffusion models achieve remarkable generation quality but suffer from high latency due to their bidirectional attention dependencies, hindering real-time applications. We propose OmniForcing, the first framework to distill an offline, dual-stream bidirectional diffusion model into a high-fidelity streaming autoregressive generator. However, naively applying causal distillation to such dual-stream architectures triggers severe training instability, due to the extreme temporal asymmetry between modalities and the resulting token sparsity. We address the inherent information density gap by introducing an Asymmetric Block-Causal Alignment with a zero-truncation Global Prefix that prevents multi-modal synchronization drift. The gradient explosion caused by extreme audio token sparsity during the causal shift is further resolved through an Audio Sink Token mechanism equipped with an Identity RoPE constraint. Finally, a Joint Self-Forcing Distillation paradigm enables the model to dynamically self-correct cumulative cross-modal errors from exposure bias during long rollouts. Empowered by a modality-independent rolling KV-cache inference scheme, OmniForcing achieves state-of-the-art streaming generation at $\sim$25 FPS on a single GPU, maintaining multi-modal synchronization and visual quality on par with the bidirectional teacher.\textbf{Project Page:} \href{https://omniforcing.com}{https://omniforcing.com}

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (overview)
The paper introduces OmniForcing, a way for AI to create video and audio together in real time. Think of it like a smart tool that can make a short movie and its matching soundtrack at the same time, while you watch it appear. Older systems could make high‑quality results, but they were slow because they needed to look at the entire video and audio all at once before producing anything. OmniForcing keeps the quality and the timing between sound and picture, but makes everything fast enough to stream live.
What questions the researchers asked
Here are the main goals the team focused on, explained simply:
- How can we turn a slow, high‑quality “offline” model into a fast, “streaming” one that starts playing almost immediately?
- How can we keep the video and audio perfectly in sync, even though audio happens much more frequently than video frames?
- How can we prevent training from becoming unstable when we switch from “seeing the whole future” to “working step by step”?
- How can we keep quality high while running on just one GPU (a single graphics card)?
How they did it (methods and ideas, in everyday language)
To understand the approach, imagine making a comic and a soundtrack at the same time, but doing it in tiny chunks so people can start watching and listening right away.
- The “teacher” and “student” idea (distillation):
- There’s a big, slow expert model (the teacher) that can make great videos with audio, but it needs to see the whole thing at once. The researchers train a smaller, faster model (the student) to copy the teacher’s behavior so it can work quickly and stream in real time.
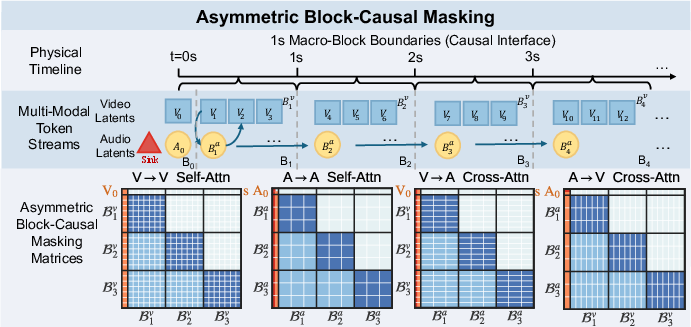
- Working in one‑second chunks (block‑causal alignment):
- Video and audio don’t move at the same speed. In their setup, the video effectively has 3 frames per second, while the audio has 25 “mini‑frames” per second. Instead of trying to line up every single frame one by one, they bundle time into neat one‑second blocks: each block has exactly 3 video frames and 25 audio steps. This makes the two streams line up naturally.
- They also add a “Global Prefix,” like a permanent title page or a shared intro, that both audio and video can always see. This keeps everything anchored and in sync from the start.
- Stabilizing the audio side with “sink tokens”:
- Audio updates much more often than video, so early on the audio doesn’t have much to “look at” when making predictions. That can make training blow up (literally, the math can go unstable).
- To fix this, they add a few special “sink tokens” at the start of the audio stream. Think of them as extra blank sticky notes that the model can always glance at to stabilize itself. These tokens don’t move in time and don’t carry misleading timing signals—they act like a small, steady memory buffer that keeps the math calm.
- Practicing with its own outputs (Self‑Forcing training):
- When models generate long sequences step by step, small mistakes can pile up. So during training, the student practices unrolling its own predictions and learns to correct itself, instead of relying on perfect data. This reduces drift and keeps audio and video aligned over time.
- Remembering efficiently (rolling KV‑cache):
- Imagine keeping a short, rolling notebook of what’s been produced recently, so the model doesn’t have to reread the entire script every time. This “KV‑cache” keeps the essential memory small and quick to access, which makes each new step fast. The audio and video “notebooks” can be handled independently and in parallel, which saves time and fits on one GPU.
In short: they teach a fast model to copy a slow expert, generate in tidy one‑second blocks for clean timing, use special audio helpers to prevent instability, train it to handle its own imperfect outputs, and give it a smart short‑term memory to run quickly.
What they found and why it matters
- Speed: OmniForcing can stream at about 25 frames per second with a very low “time‑to‑first‑chunk” (~0.7 seconds). The original teacher model took about 197 seconds to produce the same clip offline. That’s roughly a 35× speedup.
- Quality and sync: Even with the big speed boost, the video and audio stay well‑matched and high quality—close to the slow teacher model and better than many other systems that try to connect audio and video after the fact.
- Stability: The special audio sink tokens and the one‑second block design make training stable, avoiding crashes and keeping the audio‑video timing accurate.
- Efficiency: The system runs in real time on a single GPU and keeps up the pace, which is practical for real‑world use.
Why this is important: Before this, models that made great audio‑video content were too slow for live or interactive use. OmniForcing shows you can have both: the quality of a big “offline” model and the speed needed for streaming.
What this could lead to (implications)
- Live content creation: Streamers, creators, and game developers could generate video and sound effects together on the fly.
- Interactive characters and dubbing: Virtual presenters, animated avatars, and live dubbing could respond instantly with synced voice and video.
- Education and accessibility: Real‑time, auto‑generated illustrations and matching audio could help explain concepts or create accessible content quickly.
- Better performance on modest hardware: Because it runs efficiently, more people and apps can use it without huge servers.
Overall, OmniForcing takes a big step toward making high‑quality, synchronized audio‑video generation practical for real‑time, interactive experiences.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains uncertain or unexplored in the paper and could guide future research:
- Generalization beyond LTX-2: It is unclear how OmniForcing applies to other joint AV teachers with different architectures (e.g., single-stream token fusion, different cross-attention coupling, non-RoPE position encodings) or parameter scales; a systematic study across diverse teachers is missing.
- Dependence on specific VAE strides and rates: The approach hinges on the 25:3 audio:video latent rate and stride characteristics; robustness to other (possibly non-integer) ratios, variable frame rates, alternative tokenizers, or non-VAE discretizers is not evaluated.
- Fixed 1-second macro-block choice: No ablation of block duration (e.g., 0.25 s, 0.5 s) is provided; the trade-off between latency, stability, and synchronization as a function of block size is unknown.
- Intra-block bidirectional “lookahead” vs strict causality: Because attention is bidirectional within each block, early tokens can access later tokens in the same block, implying at least a block-sized algorithmic delay; the exact latency-cost of this design and whether smaller blocks or truly causal intra-block masks can preserve quality is unexplored.
- Sub-second latency constraints: The reported TTFC (~0.7 s) may be insufficient for applications requiring <200 ms latency; methods to achieve sub-200 ms TTFC (e.g., micro-blocking, progressive decoding, partial decoding within a block) are not studied.
- Long-horizon stability and memory: Results are reported for ~5 s clips; the impact of rolling KV-cache window length, forgetting policies, and context truncation on minute-level or longer AV coherence, identity consistency, and drift is not quantified.
- Window size selection for the rolling KV-cache: How the cache length L is chosen, its memory/computation footprint over long streams, and the quality–efficiency trade-offs are not detailed.
- Real resource requirements at inference: “Single GPU” feasibility for a 19B model lacks specifics (GPU type, memory, quantization/activation offloading); reproducible resource–throughput scaling curves are absent.
- Scaling to higher resolutions and frame rates: Empirical evidence for 720p/1080p or >25 FPS outputs, and the efficiency/quality trade-offs when scaling resolution or temporal rate, are missing.
- Robustness to modality-rate changes: How the system behaves if audio or video rates change mid-stream (e.g., variable FPS, variable mel hop sizes) or under jitter is not assessed.
- Audio Sink Tokens scope: Only audio receives sink tokens; whether video also benefits from sink tokens (or periodic/recurrent sinks per block) and how sink tokens influence semantics over long rollouts are untested.
- Identity RoPE dependency: The method presumes RoPE; applicability with other positional encodings (ALiBi, learned absolute embeddings) or hybrid schemes, and the effect on stability, is unknown.
- Stability across extreme density mismatches: Behavior when audio density is much higher (e.g., >100 Hz tokens) or when video tokens are sparser/denser is not analyzed; the required sink size S under different ratios is unspecified.
- Theoretical analysis of training stability: A formal treatment of why sink tokens with Identity RoPE stabilize gradients (e.g., entropy/variance bounds, Softmax curvature analysis) is not provided.
- Alternative stabilizers and regularizers: While a few alternatives (QK-Norm, Tanh-gated attention) are compared, broader stabilizers (e.g., entropy regularization, label smoothing for attention, temperature scaling, Sinkhorn/entmax) and their effect on quality are not explored.
- Exposure bias under distribution shift: Joint Self-Forcing reduces exposure bias, but its behavior under out-of-distribution prompts, rapid scene changes, or rare audio events is not characterized.
- Teacher–student mismatch during distillation: The causal student is trained against a bidirectional teacher; the effect of this mismatch, and whether a partially causal teacher or teacher dropouts could improve alignment, is unstudied.
- Distillation objective sensitivity: No ablations on loss weights (λv, λa), guidance scales (wv, wa), step counts, or comparisons against alternative distillation objectives (e.g., consistency training, adversarial distillation) are provided.
- Synchronization at fine phoneme/action scales: Metrics like DeSync and AVHScore are reported, but fine-grained lip-sync or transient alignment (e.g., per-phoneme SyncNet-style scores, event onset errors in ms) are not evaluated.
- Audio intelligibility and naturalness: No ASR-based word error rate, MOS listening tests, or speech prosody/phoneme coverage analyses are presented; speech-centric quality remains uncertain.
- Audio representation limits: Using 25 Hz audio latents may be too coarse for sharp transients or detailed timbre; the impact of higher-frequency audio tokens or multi-scale audio latents is not explored.
- End-of-sequence and ragged blocks: Handling of final partial blocks (shorter than 1 s) and their effects on synchronization/quality is unspecified.
- Mid-stream editing and control: The system’s ability to accept prompt updates, control signals, or conditioning changes mid-stream (and how the Global Prefix interacts with edits) is not addressed.
- Robustness to noise or perturbations: Sensitivity to noisy prompts, adversarial tokens, or corrupted cache states and recovery mechanisms are unreported.
- Benchmark coverage and fairness: Comparisons involve models of very different sizes; parameter-normalized baselines and human preference studies are lacking.
- Domain, language, and content diversity: Generalization to diverse audio domains (music, non-speech vocalizations, non-English speech), multi-speaker scenes, or dense auditory soundscapes is not demonstrated.
- Safety, copyright, and bias: Potential for generating harmful or copyrighted audio content and bias propagation from the teacher or caption rewriting pipeline is not discussed.
- Data pipeline effects: Using LLM-rewritten captions may introduce style biases; the impact on cross-modal grounding and evaluation leakage is unexamined.
- Reproducibility details: Critical training/inference hyperparameters (noise schedules, step counts, cache sizes, block decoding order) and code artifacts needed for faithful reproduction are not fully specified.
- Implementation scheduling: The practical scheduling of parallel audio/video computation with periodic cross-attention sync points (and potential stalls) is not benchmarked under varied hardware/driver stacks.
- Applicability without a strong teacher: The method assumes access to a capable bidirectional teacher; feasibility of training a high-quality causal joint model from scratch (or with a weaker teacher) remains open.
- Multi-GPU inference scaling: Although an asymmetric tensor-parallel path is suggested, empirical results for multi-GPU real-time scaling and interconnect effects are not provided.
Practical Applications
Practical applications derived from OmniForcing
OmniForcing converts heavy, bidirectional joint audio–visual diffusion models into low-latency, streaming autoregressive generators while maintaining cross-modal synchronization and quality. Below are actionable applications that leverage its findings (Asymmetric Block-Causal Alignment with Global Prefix, Audio Sink Tokens with Identity RoPE, Joint Self-Forcing Distillation, modality-independent rolling KV-cache) and their dependencies.
Immediate Applications
- Bold live content co-pilot for creators (real-time background scenes + foley)
- Sector: Media/entertainment, creator economy
- Tools/products/workflows: OBS/Streamlabs plugin to generate streaming video+audio backdrops or transitions on prompts; “scene-on-demand” hotkeys for clip intros/outros
- Dependencies/assumptions: Access to a pretrained joint AV teacher (e.g., LTX-2-like), single high-memory GPU for ~25 FPS at target resolution, content safety filters; T2AV prompting rather than editing existing footage
- Rapid foley and ambience preview in NLEs
- Sector: Post-production, film/TV, social video
- Tools/products/workflows: Premiere/Resolve plugin to auto-generate synchronized foley/ambience for rough cuts in real time; replace later with studio assets if needed
- Dependencies/assumptions: Integration with timeline I/O and audio buses; rights management for generated audio; current model favors T2AV generation—direct V2A conditioning would require additional training
- Interactive ad creatives and dynamic banners
- Sector: Adtech/marketing
- Tools/products/workflows: Ad servers that generate tailored audio–visual snippets on-the-fly per user context; low TTFC enables sub-1s first-frame delivery
- Dependencies/assumptions: Strict latency SLAs and caching; safety guardrails and brand controls; measurement frameworks to audit generative variation
- Customer support/commerce video avatars
- Sector: Customer experience (CX), enterprise software
- Tools/products/workflows: WebRTC-based agents that produce synchronized speaking visuals and soundtracks for scripted responses and product demos
- Dependencies/assumptions: Voice/style control is limited in a pure T2AV setup; consistent persona or TTS voice cloning requires fine-tuning/conditioning extensions; moderation and provenance tags
- Game engine previsualization for designers
- Sector: Game development, tools
- Tools/products/workflows: Unity/Unreal plugin for live “previz” of scenes with synchronized sfx; speed up ideation without asset authoring
- Dependencies/assumptions: Runtime plugin, texture/audio routing into the engine; current output resolutions/frame rates must align with engine preview needs; not for shipping runtime content yet
- Synthetic data generation for AV model training
- Sector: AI/ML, audio–visual perception
- Tools/products/workflows: On-demand generation of synchronized sound–event and action datasets for detection/segmentation training with controllable prompts
- Dependencies/assumptions: Domain gap vs. real data; dataset licensing and prompt engineering; need for balanced prompt distributions
- Load testing and QoE benchmarking for streaming platforms
- Sector: Networking, CDN, video platforms
- Tools/products/workflows: Synthetic, controllable audio–visual streams to evaluate player buffering, lip-sync, and low-latency playback pipelines
- Dependencies/assumptions: Stable decode/encode pipeline for generated streams; traffic shaping; recording QoE metrics including AV sync under variable network conditions
- Live classroom demonstrations and media pedagogy
- Sector: Education
- Tools/products/workflows: In-class “type-to-scene” demos of cinematography concepts (audio layering, timing) with immediate feedback
- Dependencies/assumptions: Campus GPU resource or cloud credits; age-appropriate content filters; lesson plans aligned to T2AV capabilities
- Cost-effective API for streaming AV generation
- Sector: Cloud/edge compute, developer platforms
- Tools/products/workflows: Managed API leveraging rolling KV-cache to offer low-latency T2AV generation for prototypes and apps
- Dependencies/assumptions: GPU instances with sufficient VRAM; usage limits; watermarking/provenance support for downstream compliance
- Generalizable training stabilizer for sparse streams
- Sector: AI/ML research
- Tools/products/workflows: Apply Audio Sink Tokens + Identity RoPE to stabilize causal training in other sparse/high-frequency streams (e.g., speech-only AR models, sensor fusion)
- Dependencies/assumptions: Requires tuning sink pool size and compatibility with model’s positional encoding; benefits most in pronounced token sparsity regimes
Long-Term Applications
- Real-time telepresence with controllable synthetic avatars
- Sector: Communications, enterprise, social
- Tools/products/workflows: Two-way, low-latency agents that render speaking avatars with context-aware soundscapes driven by live semantics
- Dependencies/assumptions: Conditioning on live audio/video inputs (beyond T2AV), high-fidelity identity/voice control, robust safety/watermarking, bandwidth-efficient streaming
- Generative streaming as a perceptual codec
- Sector: Networking, media distribution
- Tools/products/workflows: Transmit compact control signals/prompts and synthesize audio–visual content on the receiver, reducing bitrate for certain classes of content
- Dependencies/assumptions: Strong controllability and determinism, acceptable fidelity variance, regulatory approval for generative delivery, standardized quality/sync metrics
- In-game runtime content generation
- Sector: Gaming
- Tools/products/workflows: Dynamic scene and soundscape generation reacting to gameplay; personalized experiences per player
- Dependencies/assumptions: Tight latency budgets on consoles/PCs, guardrails for content unpredictability, fine-grained conditioning APIs, on-device or edge acceleration
- XR/AR world and soundscape generation
- Sector: XR, spatial computing
- Tools/products/workflows: Real-time generation of 2D/2.5D panels evolving into 3D-consistent, spatialized audio–visual experiences
- Dependencies/assumptions: 3D geometry/multiview consistency and spatial audio; integration with SLAM and scene understanding; significant research on 3D T2AV
- Robotics and multi-sensor simulation
- Sector: Robotics, autonomy
- Tools/products/workflows: Use Asymmetric Block-Causal Alignment to jointly simulate multi-rate streams (e.g., camera, IMU, audio) for training and testing
- Dependencies/assumptions: Extend beyond AV to additional sensors; task-specific physics plausibility; domain adaptation to bridge sim-to-real gaps
- Multimodal forecasting for industry (energy, finance, ops)
- Sector: Energy, finance, AIOps
- Tools/products/workflows: Apply block-causal masking and sink-token stabilization to multi-rate time-series transformers (e.g., high-frequency ticks vs. daily indicators)
- Dependencies/assumptions: Not content generation but forecasting; requires re-training on domain data; careful evaluation for stability and calibration
- Accessibility tools (audio description and visualization)
- Sector: Healthcare, public services
- Tools/products/workflows: Real-time, synchronized audio descriptions for low-vision users and complementary visualizations for Deaf/hard-of-hearing users
- Dependencies/assumptions: Conditioning on live content (A2V/V2A) rather than pure T2AV; safety/accuracy standards; human-in-the-loop oversight
- On-device/mobile streaming AV generation
- Sector: Mobile, edge AI
- Tools/products/workflows: Quantized, pruned OmniForcing-like models for smartphones and wearables powering personal media assistants
- Dependencies/assumptions: Aggressive model compression, thermal/battery constraints, platform-specific accelerators; resolution/frame rate trade-offs
- Creative co-performance and live shows
- Sector: Arts, entertainment
- Tools/products/workflows: Stage systems that co-create visuals and sound in response to performers’ cues
- Dependencies/assumptions: Robust control interfaces (MIDI/control nets), predictable timing under stage conditions, licensing for generated content
- Standards and policy for real-time generative media
- Sector: Policy/regulation, industry consortia
- Tools/products/workflows: AV-sync evaluation standards (e.g., JavisBench-derived), watermarking/provenance for live generative streams, incident response playbooks
- Dependencies/assumptions: Multi-stakeholder consensus; secure metadata channels; alignment with deepfake and accessibility regulations
- Developer kits for cross-modal, multi-rate streaming AI
- Sector: Software infrastructure
- Tools/products/workflows: “OmniForcing-style” SDKs to retrofit existing multi-modal foundation models (beyond AV) with block-causal masks, sink tokens, KV-rolling inference
- Dependencies/assumptions: Access to teacher models and modality-specific VAEs; each modality’s stride and tokenization must be known; re-tuning for non-1s block boundaries
Notes on feasibility across applications:
- Architectural assumptions: The block-causal alignment hinges on known, stable VAE stride/frequency relationships; porting to different models/modalities may require re-deriving block sizes and re-tuning sink tokens.
- Compute: Single high-memory GPU suffices for 480p-class streaming at ~25 FPS; higher resolutions or longer horizons need multi-GPU or further distillation/quantization.
- Control and safety: Today’s setup is primarily T2AV; precise control (identity, prosody, exact lip dynamics) and edit-conditional modes (V2A/A2V) require additional training. Content moderation, watermarking, and provenance are critical for deployment.
- Data/rights: Training/distillation relies on access to a pretrained teacher and appropriately licensed datasets/prompts; generated audio may implicate rights/clearances in commercial use.
Glossary
- A2V: Abbreviation for audio-to-video generation, where audio drives video synthesis. Example: "audio-to-video (A2V)"
- Adversarial Diffusion Distillation: A distillation method that uses adversarial (discriminator-based) losses to compress diffusion sampling steps. Example: "Adversarial Diffusion Distillation~\cite{sauer2024adversarial} leverages discriminator-based losses."
- Asymmetric Block-Causal Alignment: A masking/alignment scheme that groups audio and video into synchronized one-second blocks to handle their different token rates while enforcing causality. Example: "Asymmetric Block-Causal Alignment with a zero-truncation Global Prefix"
- Asymmetric Block-Causal Masking: An attention mask that permits bidirectional attention within each block but enforces causality across blocks. Example: "Asymmetric Block-Causal Masking."
- Asymmetric tensor parallelism: Allocating different amounts of computation across devices for different model parts (e.g., heavier video stream vs. lighter audio stream). Example: "asymmetric tensor parallelism across devicesâassigning more compute to the heavier video stream"
- Audio Attention Sink mechanism: A stabilization technique that adds dedicated “sink” tokens to the audio stream to prevent attention collapse under sparse causal context. Example: "we propose an unsupervised Audio Attention Sink mechanism"
- Audio Sink Tokens: Learnable tokens prepended to the audio sequence that serve as a position-agnostic memory buffer to stabilize attention. Example: "Audio Sink Tokens with Identity RoPE"
- Autoregressive: A generation approach that conditions each new output on previously generated outputs, proceeding causally through time. Example: "streaming autoregressive generator"
- Bidirectional full-sequence attention: Attention that allows tokens to attend to both past and future positions across the entire sequence. Example: "bidirectional full-sequence attention"
- Causal mask: An attention mask that prevents tokens from attending to future positions to enforce temporal causality. Example: "a strict frame-by-frame causal mask"
- Causal ODE Regression: Training that regresses the student’s predictions to a teacher’s continuous-time (ODE) trajectories under causal masking. Example: "Stage II: Causal ODE Regression."
- Classifier-free guidance: A sampling technique that mixes conditional and unconditional predictions to steer generation strength without an explicit classifier. Example: "classifier-free guidance scales"
- Consistency Models: Models distilled to produce consistent outputs across different diffusion or ODE steps, enabling fast sampling. Example: "Consistency Models~\cite{song2023consistency,luo2023latent} enforce self-consistency along ODE trajectories"
- Cross-attention: Attention mechanism that lets one sequence (e.g., video) attend to another (e.g., audio). Example: "coupled through bidirectional cross-attention"
- Cross-modal attention: Attention operations that connect different modalities (e.g., audio-to-video and video-to-audio). Example: "cross-modal attention boundaries (A2V and V2A)"
- DeSync: A metric for measuring audio–video desynchronization. Example: "with a DeSync of 0.392"
- Distribution Matching Distillation (DMD): A distillation objective that matches the student’s output distribution to the teacher’s, typically via KL-based losses. Example: "Distribution Matching Distillation (DMD)"
- Exposure bias: The discrepancy caused by conditioning on ground truth during training but on model outputs during inference, leading to error accumulation. Example: "exposure bias during long rollouts"
- FAD: Fréchet Audio Distance, a metric for audio quality based on distributional similarity of embeddings. Example: "FAD of 5.7"
- FFN sub-layers: Feed-forward network components inside transformer layers that process token representations between attention blocks. Example: "independent FFN sub-layers"
- Flow-matching time: The continuous-time parameterization used in flow/ODE-based training of diffusion-like models. Example: "flow-matching time "
- FVD: Fréchet Video Distance, a metric for video quality assessing distributional similarity of video embeddings. Example: "FVD of 137.2"
- Global Prefix: A globally visible, bidirectional initial block that anchors the sequence and remains accessible to all future tokens. Example: "Global Prefix that aligns the joint sequence at exact one-second boundaries"
- Identity RoPE: A constraint that makes Rotary Position Embeddings act as the identity (no rotation) for certain tokens, avoiding positional bias. Example: "Identity RoPE"
- JavisBench: A benchmark suite for evaluating joint audio–visual generation across multiple dimensions. Example: "We evaluate on JavisBench"
- JavisScore: An audio–visual synchrony/quality metric reported within the JavisBench framework. Example: "JavisScore~\cite{liu2026javisdit}"
- KL divergence: A measure of divergence between probability distributions, used here for distillation objectives. Example: "minimizes an approximate KL divergence between student and teacher"
- KV-cache: A cache of keys and values from past tokens used to accelerate autoregressive transformer inference. Example: "KV-cache predictions"
- Mel spectrograms: A time–frequency representation of audio on the mel scale used for audio modeling/visualization. Example: "Mel spectrograms."
- Modality-Independent Rolling KV-Cache: A per-modality rolling cache of attention keys/values that reduces context complexity and enables parallel inference. Example: "Modality-Independent Rolling KV-Cache"
- ODE trajectories: Continuous-time trajectories defined by ordinary differential equations that describe the denoising/generation process. Example: "regress the ODE trajectories"
- Patchified: The process of splitting frames into patches and embedding them as tokens for transformer processing. Example: "patchified into tokens"
- QK-Norm: A normalization technique applied to query/key matrices in attention to stabilize training. Example: "QK-Norm~\cite{dehghani2023scaling}"
- Rotary Position Embeddings (RoPE): A method for encoding positional information by rotating query/key vectors in attention. Example: "Rotary Position Embeddings (RoPE)"
- Self-Forcing: A training paradigm where the model unrolls and conditions on its own predictions to reduce exposure bias. Example: "joint Self-Forcing"
- Softmax collapse: An attention failure mode where the Softmax distribution becomes nearly one-hot due to tiny denominators, causing unstable gradients. Example: "Softmax collapse"
- Time-To-First-Chunk (TTFC): The time latency from the start of generation to the first emitted chunk suitable for streaming playback. Example: "Time-To-First-Chunk (TTFC)"
- VAEs: Variational Autoencoders used to map audio and video into continuous latent spaces for generative modeling. Example: "modality-specific VAEs"
- V2A: Abbreviation for video-to-audio generation, where video drives audio synthesis. Example: "video-to-audio (V2A)"
Collections
Sign up for free to add this paper to one or more collections.