- The paper introduces a novel real-time generative frame model that generates view-conditioned frames independently for low-latency rendering.
- It employs a hybrid architecture combining explicit 3D anchors with implicit spatial memory to ensure multi-view spatial consistency.
- Progressive three-stage training and transformer-based condition injection achieve efficient, high-fidelity world modeling on workstation GPUs.
InSpatio-WorldFM: A Real-Time Generative Frame Model for Spatial Intelligence
Frame-Based Paradigm for Real-Time World Modeling
InSpatio-WorldFM introduces a frame-based generative approach for world modeling, departing from traditional video-based models that synthesize scenes by sequential frame generation and temporal window processing. Conventional video-based methods, despite inheriting strong priors for motion and camera dynamics, suffer from accumulated spatial errors and unavoidable high inference latency due to their sequential nature. In contrast, InSpatio-WorldFM generates each view-conditioned frame independently, achieving low-latency rendering and enabling seamless interactive exploration.
The model's architecture enforces multi-view spatial consistency by combining explicit 3D anchors (e.g., point cloud renderings) with implicit spatial memory (reference frame attention). Each generated frame remains consistent in global geometry and local texture, regardless of the exploration trajectory, supporting persistent world simulation suitable for real-time applications. Diverse qualitative outputs across various scene styles and real-time joystick-driven interactions are demonstrated, evidencing negligible latency and robust visual continuity.

Figure 1: Examples of generated worlds across diverse styles, including photorealistic, science-fiction, game-like, and artistic environments. The joystick interface enables real-time interactive exploration with negligible latency.
Architecture and Condition Injection
The pipeline is organized into two main stages: offline data curation and online real-time inference. Offline, multi-view-consistent image sets are generated using a multi-view model from a single image, with 3D anchors derived from reconstructions or panoramic methods. For online operation, a transformer-based frame model receives a reference image, noisy latent (from the diffusion process), an explicit point cloud rendering, and camera pose controls to generate the target frame.
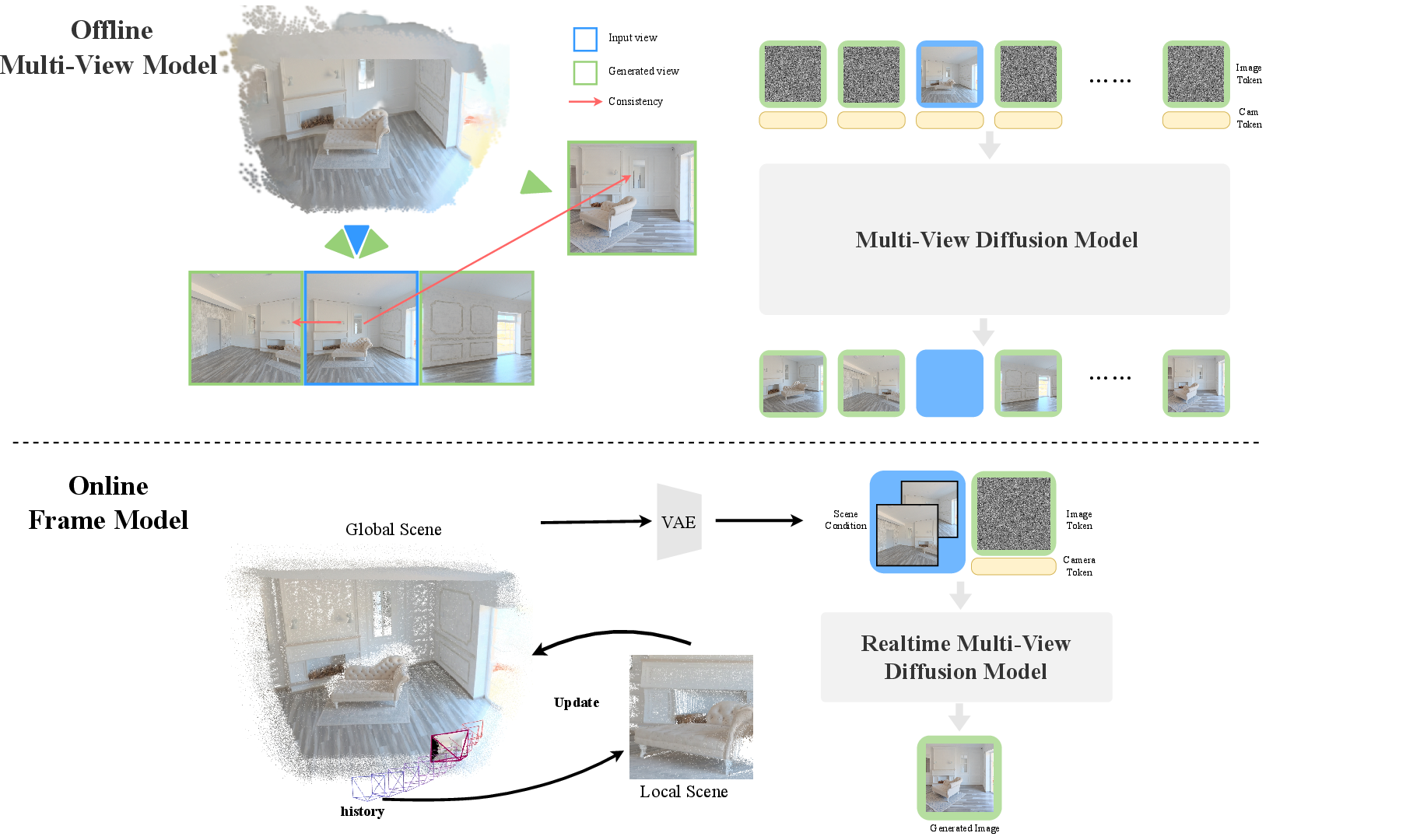
Figure 2: Overview. In the offline stage, a multi-view-consistent model generates plausible observations that provide 3D anchors and reference appearances. In the online stage, frame model performs fast real-time inference while updating scene content at keyframes.
Within the generative process, all conditions are concatenated and injected via self-attention, proved empirically superior to cross-attention strategies. Camera pose information is encoded using Projection Relative Position Embedding (PRoPE), modulating transformer attention via camera-specific transformations. Explicit anchors (from point cloud renderings) ensure geometric accuracy, while implicit memory permits appearance and detail preservation, enabling consistent view synthesis even from sparse observations.
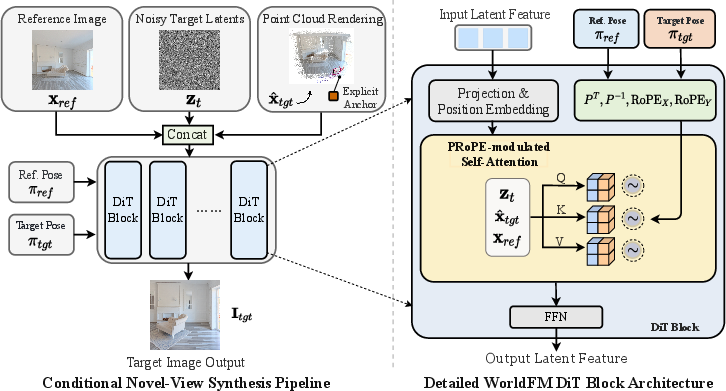
Figure 3: The pipeline of InSpatio-WorldFM. The left part illustrates the conditional novel-view synthesis pipeline of WorldFM.
Progressive Three-Stage Training
Training is split into three progressive stages:
- Pre-Training: Initializes with a high-fidelity, efficient foundation image generator—PixArt-Σ's Diffusion Transformer—ensuring quality and computational tractability.
- Middle-Training: Transforms the base model into a frame-wise world model by augmenting with multi-view consistent data, explicit pose control, and the hybrid spatial memory mechanism. Training data includes real video sources, captured sequences, and synthetic environments with accurate pose/depth annotations.
- Post-Training: Employs Distribution Matching Distillation (DMD) to compress the multi-step diffusion workflow into a few-step process (optimal at two steps), achieving real-time frame generation while minimally impacting perceptual fidelity.
Distinct training strategies (noise schedule biasing, progressive condition exposure, random anchor masking) mitigate mode collapse and over-reliance on explicit spatial anchors, ensuring robust and flexible spatial inference.
Empirical Evaluation and Visual Consistency
Across extensive scene types, the distilled InSpatio-WorldFM model achieves approximately 10 frames per second at a spatial resolution of 512×512 on workstation-class GPUs. Visual inspection indicates superior multi-view spatial consistency, even during continuous or wide-baseline exploration, with the hybrid memory design effectively preserving global geometry and fine details.
Qualitative evaluations, as presented across a series of figures, show strong correspondence between reference images and generated sequences, minimal frame-to-frame jitter, and high-fidelity appearance retention under user-driven navigation.

Figure 4: Qualitative results of teacher model.

Figure 5: Qualitative results of InSpatio-WorldFM.

Figure 6: Qualitative results of InSpatio-WorldFM.

Figure 7: Qualitative results of InSpatio-WorldFM.

Figure 8: Qualitative results of InSpatio-WorldFM. Across observations at varying viewing distances, the content and fine details generated by the FrameModel remain consistent.
Limitations and Future Prospects
Despite its capacity for robust, real-time novel-view synthesis, InSpatio-WorldFM inherits several limitations:
- Dynamic Content Limitations: Both its generation and training data are primarily static; thus, high-fidelity dynamic scene synthesis remains a challenge.
- Motion Boundaries: The requirement for multi-view consistent memory, which is computationally expensive to generate, introduces practical constraints on viewpoint traversal during online inference.
- Temporal Jitter: The inherently frame-based structure, lacking explicit inter-frame temporal constraints, may result in occasional frame-to-frame visual instability in interactive regimes.
Future directions include leveraging architectural advances such as linear attention, enhanced VAE caching, and edge-focused acceleration to scale real-time model deployment to less powerful hardware. Replacing point cloud anchors with Gaussian Splatting primitives could improve fidelity, and integrating temporally/physically plausible dynamics remains an open avenue. Efficient handling of dynamic content and unbounded persistent expansion are also emphasized as crucial next steps.
Conclusion
InSpatio-WorldFM presents a scalable, open-source paradigm shift for real-time world modeling, sidestepping the intrinsic latency and spatial drift of video-centric diffusion architectures. By structuring scene synthesis around explicit 3D anchors, implicit spatial memory, and efficient distillation, the model supports interactive, multi-view-consistent scene generation at scale. Continued refinement of explicit and implicit spatial priors, along with better dynamic scene modeling, will extend its applications in both simulated and embodied AI systems.
(2603.11911)