Strategic Navigation or Stochastic Search? How Agents and Humans Reason Over Document Collections
Abstract: Multimodal agents offer a promising path to automating complex document-intensive workflows. Yet, a critical question remains: do these agents demonstrate genuine strategic reasoning, or merely stochastic trial-and-error search? To address this, we introduce MADQA, a benchmark of 2,250 human-authored questions grounded in 800 heterogeneous PDF documents. Guided by Classical Test Theory, we design it to maximize discriminative power across varying levels of agentic abilities. To evaluate agentic behaviour, we introduce a novel evaluation protocol measuring the accuracy-effort trade-off. Using this framework, we show that while the best agents can match human searchers in raw accuracy, they succeed on largely different questions and rely on brute-force search to compensate for weak strategic planning. They fail to close the nearly 20% gap to oracle performance, persisting in unproductive loops. We release the dataset and evaluation harness to help facilitate the transition from brute-force retrieval to calibrated, efficient reasoning.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper asks a simple but important question: when AI “agents” search through lots of PDFs to answer questions, are they planning cleverly like a good researcher, or are they just trying many things at random until something works?
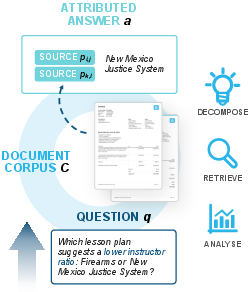
To study this, the authors built a new test called MADQA. It includes 2,250 human-written questions connected to 800 real, mixed‑type PDF documents (like forms, reports, financial filings, manuals). Questions often need information from several pages or even different documents, and sometimes the answer is in tables, figures, or checkboxes—not just plain text.
What were the main goals?
The researchers wanted to:
- Create a clean, realistic challenge that tests whether AI agents can:
- find the right pages across many documents,
- understand both text and visuals (tables, charts, boxes),
- plan multi-step searches and stop at the right time.
- Make sure the questions truly require reading the documents (not just guessing).
- Compare how different AI systems perform versus humans, including how much effort they spend to get answers.
How did they do it?
Building the MADQA benchmark
- They carefully picked 800 “fresh” PDFs with many formats and layouts (so models can’t rely on memorized web data).
- People wrote 2,250 questions by hand. For every question, annotators also marked the “minimal evidence” pages—the smallest set of pages that prove the answer.
- The questions follow six key rules, explained in everyday terms: 1) Extractive: the answer text appears on the cited pages. 2) Multi-hop: sometimes you must combine info from different pages or documents. 3) Closed-world: you can only use these PDFs, not outside knowledge. 4) Grounded: you must cite exactly the pages that justify the answer. 5) Agentic: a single simple search isn’t enough—you need to plan multiple steps. 6) Visual: answers may depend on tables, charts, checkboxes, or layout, not just text.
Checking quality and fairness
- They verified that simple keyword matching doesn’t work well here. In other words, you can’t usually find the right pages just by looking for matching words from the question.
- They asked strong LLMs to “guess” answers from questions alone, with no documents. Only about 11% of answers were guessable, showing most questions need the actual PDFs.
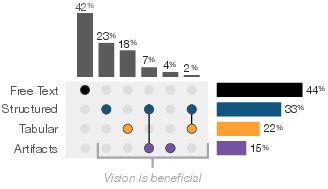
- About 58% of questions benefit from understanding visual structure (like tables) or visual elements (like charts or checkboxes), not just plain text.
Making testing efficient and future-proof
- They used ideas from educational testing (Classical Test Theory) to build:
- a Dev set (200 questions) and
- a Test set (500 questions) that still predict performance on the full benchmark well.
- They also set aside a “Sentinel Pool” of especially hard questions that current models can’t solve, to keep the benchmark challenging as AI improves.
How they measured performance
- Answer correctness: They used an LLM “judge” that checks if the given answer matches the gold answer meaningfully, even if the wording differs. This focuses on whether the concrete value is correct and grounded in the text.
- Grounding: They measured Page F1 (did you cite the exact right pages?) and Doc F1 (did you at least find the right document?). This helps tell whether models find the right area but miss the exact page.
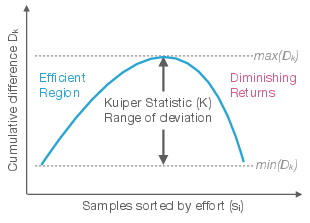
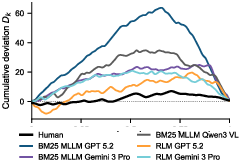
- Effort vs. accuracy: They introduced a calibration score based on how many steps the agent takes. The idea: if you spend more effort, do you actually get better results—or just waste time looping? They summarize this with a statistic (called “Kuiper”) that flags when extra effort doesn’t pay off.
What did they find?
Here are the main takeaways:
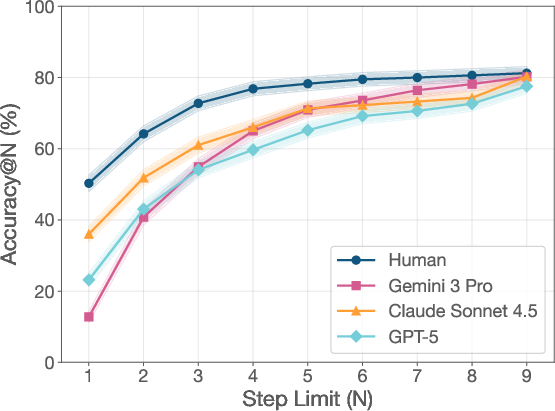
- Best agents can match humans on overall accuracy—but on different questions.
- Humans and agents often succeed on different types of problems. This suggests they have different strengths.
- Many agents lean on brute-force search rather than smart planning.
- They often keep retrieving many pages and still miss the target, or loop unproductively.
- There’s still a big gap to “oracle” performance.
- Even top agents trail an oracle-like setup by nearly 20%. This gap is mostly about retrieval: getting the exact right pages is the main bottleneck, not wording the final answer.
- “Agentic” systems beat simple, one-shot RAG systems.
- Agents that can plan multiple steps do better than basic “retrieve then answer” setups.
- But unconstrained systems that try too many steps can waste a lot of effort without big gains.
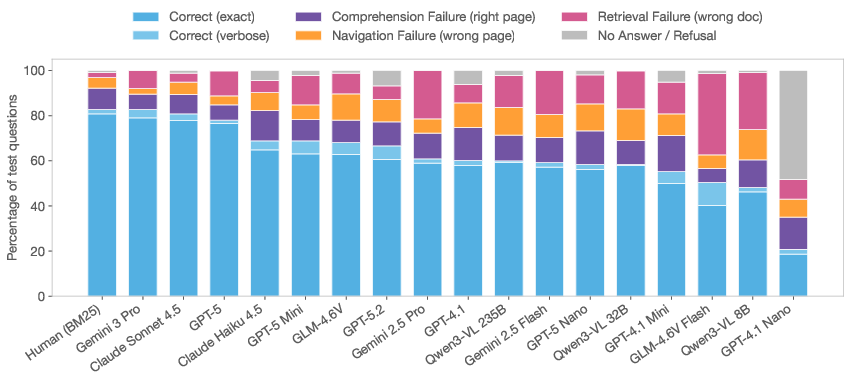
- Visual and layout understanding really matters.
- Over half the questions benefit from recognizing tables, forms, or visual marks. Plain text extraction isn’t enough.
Why does this matter?
If we want AI to help with real-world, document-heavy tasks—like reading reports, filling forms, or comparing filings—then the AI must do more than just keyword search. It needs to:
- plan multi-step searches,
- understand tables and layouts,
- combine clues from different pages and documents,
- stop at the right time and cite precise evidence.
MADQA gives the community a strong, fair test to measure these skills. The results show where today’s agents fall short and how to improve them. This can lead to:
- better retrieval tools that find the exact right pages,
- smarter planning and “stop” rules that avoid wasteful loops,
- stronger visual understanding of tables, charts, and forms,
- hybrid systems that mix human and AI strengths to beat either alone.
In short, this work pushes AI from “try everything and hope” toward “plan, navigate, and prove it,” which is what real research and office work require.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of concrete gaps and open questions that remain unresolved and can guide future research.
- Evidence granularity: Evaluation is limited to page-level attribution. Introduce fine-grained, region-level (bbox), table cell/row/column, and figure/axis grounding to precisely assess visual reasoning and reduce ambiguity in “minimal evidence.”
- Alternative valid evidence: Many documents redundantly present facts across pages. Extend gold annotations to include multiple valid evidence sets per question or adopt entailment-based scoring to avoid unfairly penalizing correct but differently grounded answers.
- Enforcing the “agentic” property: The claim that no single retrieval query can surface all evidence is targeted but not guaranteed. Empirically quantify the share of instances solvable via a single strong query using state-of-the-art hybrid/dense/vision-aware retrievers and refine items that violate the assumption.
- Retrieval–reasoning decomposition: Report upper bounds with oracle contexts (e.g., model with gold pages) and lower bounds (retrieval-only) per item to partition errors into retrieval vs reasoning and to pinpoint which capability drives the 18–20% gap.
- Visual retrieval coverage: Retrieval is largely text-centric (BM25). Benchmark and ablate hybrid dense + sparse + vision/layout-aware retrieval that indexes visual structure (tables, forms, figures) and evaluate their impact on Page F1 and “last-mile” navigation.
- OCR robustness: Quantify and control for OCR noise. Create targeted subsets with degraded OCR, scans, handwriting, low-resolution images, and redactions; compare text-only vs vision-first pipelines and OCR-free VLMs.
- Visual necessity reliability: The visual-modality taxonomy and necessity labels are not accompanied by inter-annotator agreement. Measure IAA, publish labeling protocol, and release adjudicated labels to ensure validity of visual-dependence claims.
- Multi-hop depth and diversity: Only ~17% of items are multi-hop, with unclear hop-length distribution. Introduce controlled subsets with ≥3-hop chains, cross-document comparisons across >2 sources, and compositional operators (e.g., filter → join → aggregate) to stress planning.
- Extractive constraint vs derived answers: The benchmark enforces extractive answers, yet examples require aggregation (e.g., summations). Clarify policy for derived outputs, or add an explicit “derived-from-evidence” subset with formal evaluation rules for arithmetic/logical composition.
- Joint accuracy–attribution scoring: Accuracy and evidence are scored separately, enabling ungrounded but correct answers to score well. Add a “supported accuracy” metric (answer correct AND evidence sufficient) to drive grounded correctness.
- Calibration metric comparability: The Kuiper-based effort–accuracy measure depends on step semantics that differ across frameworks. Standardize effort units (e.g., normalized tool-call cost, tokens, latency), report significance testing (null distributions, confidence intervals), and calibrate across agents with different tool granularities.
- Cost and latency: “Effort” is proxied by step count; economic cost, wall-clock latency, and energy are not reported. Provide Pareto curves (accuracy vs ) and standardized budgets to enable fair cross-system comparisons.
- Failure mode taxonomy: The paper notes unproductive loops but lacks a systematic error analysis. Annotate and quantify failure categories (query reformulation, document selection, page localization, visual misread, aggregation error, premature termination) to target interventions.
- Planning quality measurement: Beyond effort and accuracy, there is no measure of plan quality. Introduce plan annotations and metrics (subgoal correctness, order optimality, loop detection, reuse of intermediate findings) to isolate “strategic navigation” from brute-force search.
- Retrieval index reproducibility: Vendor “File Search” and other closed services obscure index construction and configurations. Release standardized indexing scripts, versions, and corpus snapshots, and require reporting of index parameters to ensure leaderboard reproducibility.
- LLM-judge transparency and robustness: The LLM-based accuracy judge (κ=0.88) may introduce bias and drift. Open-source the judge prompts, provide a frozen open-weight judge, report adversarial robustness (prompt/format attacks), and periodically re-validate against human adjudication.
- Contamination auditing: Guessability analysis suggests residual training data contamination but is indirect. Add time-based splits, near-duplicate detection against public corpora, and controlled post-cutoff document injections to more rigorously quantify contamination.
- Human annotation reliability: Minimal-evidence selection and question solvability lack reported inter-annotator agreement. Provide IAA and adjudication protocols for both answer spans and evidence minimality; publish disagreement analyses.
- Sentinel-pool validation: Items reserved for “headroom” are defined by model failure, not by human solvability thresholds. Verify all sentinel items via expert humans with time budgets; document why they are hard (e.g., long-range joins, visual artifacts) to ensure they are not artifacts of annotation or OCR.
- Dataset scope and modality gaps: PDFs dominate; real workflows include emails, spreadsheets, presentations, HTML, images, CAD, and mixed archives. Extend to multi-file, multi-format corpora and evaluate cross-format retrieval and reasoning.
- Multilingual and script coverage: The benchmark appears English-centric. Add non-Latin scripts, right-to-left languages, code-switching, and multi-language cross-document tasks; measure the effect on retrieval, OCR, and visual parsing.
- Domain representativeness: Enterprise-critical domains (e.g., clinical/biomedical, proprietary engineering specs) are underrepresented. Curate privacy-safe proxies or synthetic-but-structurally-faithful corpora to test out-of-domain generalization.
- Alternative evidence forms: Page-level grounding ignores structured parses furnished by modern PDF parsers (tables, form fields). Provide parallel structured ground truth (e.g., table schemas, key–value pairs) and evaluate structure-aware answering.
- Single-query solvability audits: Beyond lexical n-gram tests, use strong re-rankers and multi-vector dense retrievers to estimate how often “single-shot” retrieval actually suffices; refine “agentic” labeling accordingly.
- Leaderboard stability over time: Closed-source model updates can reorder rankings. Introduce frozen “reference baselines,” versioned evaluation harnesses, and periodic re-runs to quantify temporal drift and maintain comparability.
- Scale and statistical power: With 2,250 questions (500 test), some per-subset CIs remain wide. Scale the benchmark or add bootstrap protocols to stabilize rankings, especially within narrow slices (e.g., X-Doc + visual artifacts).
- Robustness to adversarial formatting: Assess resilience to layout perturbations (column shuffles, table border removal), watermarks, stamps, and compression artifacts; create controlled perturbation suites.
- Tooling ablations: The effect of parser choice (PDF→MD, table extractors), re-rankers, and layout parsers is not isolated. Provide standardized ablation harnesses to attribute gains to retrieval, parsing, vision encoding, and planning components.
- Human–agent complementarity: Agents and humans solve different items yet the paper stops short of hybrid designs. Explore collaborative protocols (agent pre-triage, human-in-the-loop for hard cases, supervision signals from human strategies) and measure combined performance/cost.
- Termination criteria: Agents “persist in loops,” but termination policies are not compared. Evaluate and learn stopping rules (meta-controllers) that optimize the accuracy–cost frontier; report their effect on Kuiper and cost metrics.
- Privacy and licensing: DocumentCloud sources may carry heterogeneous licensing and potential PII. Provide explicit licensing audits, PII redaction policies, and usage constraints to support safe industrial adoption.
Practical Applications
Immediate Applications
The following applications can be deployed now by leveraging the benchmark, evaluation harness, and design principles introduced in the paper.
- Evidence-anchored document QA for enterprise workflows (Industry: finance, legal, government, energy, HR)
- Build agentic “document researcher” bots that answer extractive questions with page-level citations across multi-page and multi-document PDF collections (e.g., SEC filings, contracts, permits, regulatory reports, HR policies).
- Use Page F1 and Doc F1 to enforce precise grounding and penalize lazy/spurious citations, improving auditability and trust.
- Assumptions/dependencies: reliable PDF rendering and OCR; BM25 or equivalent index over corpora; MLLM with visual understanding; governance requiring extractive, closed-world answers.
- Compliance, audit, and risk review assistants (Industry/Policy: finance, government, legal)
- Automate checks that require cross-document evidence synthesis (e.g., verifying policy adherence, comparing disclosures across years, validating permit totals).
- Maintain an audit trail via minimal evidence sets and page-level attributions.
- Assumptions/dependencies: access to relevant regulated document corpora; standardized storage; privacy controls; integration with compliance tooling.
- Effort governance and agent calibration in RAG pipelines (Software/MLOps)
- Instrument agent frameworks with the cumulative-difference Kuiper metric to detect unproductive loops and effort-accuracy miscalibration; trigger early stopping or escalate to humans when effort rises without accuracy gains.
- Calibrate step budgets (tool calls) and introduce “effort governors” to avoid brute-force search behavior documented in the paper.
- Assumptions/dependencies: step-level logging; tokens/tool-call metering; process control hooks in agent orchestration; agreement to trade modest recall for efficiency.
- Human-in-the-loop hybrid research workflows (Industry/Academia)
- Route instances where agents and humans succeed on different items to complementary processing, beating the ceiling of either alone; use the benchmark’s insight that aggregate accuracy hides differing competencies.
- Practical workflow: agents triage and gather citations; humans verify edge cases and sentinel-like hard queries.
- Assumptions/dependencies: task routing and review UI; access controls; defined thresholds for escalation; training for reviewers.
- Procurement and model evaluation with construct-valid metrics (Policy/Industry)
- Adopt MADQA’s evaluation protocol (LLM-judged extractive correctness with bias corrections, Page/Doc F1, Kuiper) in vendor RFPs to evaluate grounded QA solutions on fresh PDFs.
- Use the CTT-based dev/test splits for cost-efficient, rank-faithful benchmarking during procurement.
- Assumptions/dependencies: acceptance of LLM-judge with human calibration; shared reference corpora; reproducible evaluation harness.
- Educational and research tooling for document-centric tasks (Academia/Education)
- Use the dataset to teach multi-hop, visual-layout-aware reasoning, and agent planning; analyze visual necessity (tables, forms, artifacts) to design curricula and projects.
- Assumptions/dependencies: access to the open dataset and harness; GPUs/MLLMs with visual input; instructors comfortable with agent tooling.
- Personal document assistants for everyday tasks (Daily life)
- Automate multi-step questions over personal PDFs (tax forms, insurance policies, bills), with page-level citations and minimal evidence sets.
- Provide calibrated effort budgets so assistants don’t stall in loops; surface “I don’t know” with escalation when evidence is missing.
- Assumptions/dependencies: local privacy-preserving indexing; consumer-friendly agent UIs; robust OCR for scans; opt-in storage of evidence snippets.
- Product analytics for visual vs textual bottlenecks (Software/Product)
- Use the visual necessity taxonomy to prioritize investments in layout-aware parsers, table understanding, or artifact detection; quantify how improvements shift Page/Doc F1 and accuracy.
- Assumptions/dependencies: instrumentation of modality-specific failures; A/B capabilities on agent components; benchmarking cadence.
- Continuous benchmarking with headroom (Software/Research)
- Use the Sentinel Pool strategy to maintain long-term headroom in internal leaderboards; prevent benchmark saturation while tracking progress on discriminatory items.
- Assumptions/dependencies: periodic runs on dev/test sets; storage of per-item trajectories and metrics; governance for dataset updates.
Long-Term Applications
These applications require further research, scaling, or development to become production-ready.
- Strategic retrieval agents that plan and decompose queries (Software/Industry)
- Move beyond brute-force search to agents that learn sub-query planning, navigation, and evidence aggregation under agentic constraints; reduce the ~20% oracle gap.
- Tools/products: learned search-planners; sub-query graph builders; budget-aware retrieval policies.
- Assumptions/dependencies: training data with trajectory supervision; policy learning (e.g., RL/IL); robust evaluation on agentic properties.
- Certification-grade grounded QA for regulated sectors (Policy/Industry: healthcare, finance, government)
- Define standards (page-level evidence, minimality, closed-world constraint) for certifying document QA systems; align with audit and safety regimes.
- Tools/products: certifiable QA APIs; evidence provenance stores; compliance dashboards.
- Assumptions/dependencies: sector-specific benchmarks; legal acceptance of LLM-judging + human audits; secure provenance infrastructure.
- Adaptive compute allocation and effort-aware orchestration (Software/MLOps)
- Learn policies that dynamically allocate compute across queries and sub-queries; jointly optimize accuracy, Page/Doc F1, and Kuiper.
- Tools/products: orchestration layers with learned effort controllers; per-domain effort profiles; token-aware pricing models.
- Assumptions/dependencies: rich logs; offline RL from human/agent traces; strong monitoring and guardrails.
- Bounding-box-level evidence and fine-grained grounding (Software/Research)
- Extend page-level attribution to element-level citations (tables, cells, form fields) to tighten grounding and enable deterministic verification.
- Tools/products: layout parsers paired with agents; visual element linkers; verifiable extractive pipelines.
- Assumptions/dependencies: reliable detection/recognition of layout elements; annotation or weak supervision for boxes; robust PDF variability handling.
- Cross-document analytics for longitudinal reporting (Industry: energy, environment, finance)
- Automate comparisons and trend synthesis across years and sources (e.g., emissions, permit revenues, financial KPIs) with evidence-backed summaries.
- Tools/products: longitudinal analyzer agents; evidence roll-ups; multi-document narrative builders.
- Assumptions/dependencies: corpus clustering; temporal normalization; unit/definition reconciliation; domain-specific evaluation sets.
- Privacy-preserving, on-device agentic document QA (Daily life/Healthcare)
- Deliver local agents that index and reason over personal medical, financial, and legal PDFs with calibrated effort and strong grounding.
- Tools/products: mobile/desktop on-device indexing; secure rendering; local visual MLLMs.
- Assumptions/dependencies: efficient on-device models; secure storage; user-friendly evidence review.
- Curriculum learning for multimodal agentic reasoning (Academia/Software)
- Train models on staged tasks (text-only → layout → artifacts → cross-doc multi-hop) guided by construct validity, improving generalization to complex PDFs.
- Tools/products: curriculum datasets; staged evaluators; pedagogy-driven training benches.
- Assumptions/dependencies: curated multi-stage data; training infrastructure; alignment with real-world document heterogeneity.
- Domain-specialized agent toolchains (Industry: healthcare, legal, finance)
- Develop vertical toolkits (e.g., ICD/LOINC-aware medical parsers, clause finders for contracts, GAAP-aware finance parsers) with agent plans tailored to domain layouts.
- Tools/products: domain parsers and validators; terminology normalizers; rulebooks integrated into agent prompts/tools.
- Assumptions/dependencies: domain ontologies; annotated domain corpora; user acceptance and validation pipelines.
- Benchmark-driven policy guidance for AI procurement (Policy)
- Use agentic metrics (grounding, calibration, effort budgets) to draft procurement guidelines and minimal evidence standards for public institutions.
- Tools/products: policy templates; auditing checklists; public leaderboards on fresh corpora.
- Assumptions/dependencies: stakeholder consensus; alignment with existing AI risk frameworks; accessible public benchmarks.
- Agent trajectory datasets and learning from human strategies (Research/Software)
- Collect and learn from fine-grained human-agent trajectories to teach strategic navigation and avoid loops; exploit the observation that humans and agents solve different items.
- Tools/products: trajectory repositories; imitation learning pipelines; strategy analyzers.
- Assumptions/dependencies: consented data collection; robust anonymization; stable APIs for replay and analysis.
Each application’s feasibility depends on corpus freshness and integrity, high-quality OCR/rendering, layout-aware perception, reliable retrieval indices, calibrated evaluation (LLM-judges with human validation), and governance practices that enforce extractive, closed-world, and minimal-evidence grounding.
Glossary
- Agentic: A property requiring planning, iterative navigation, and aggregation across steps rather than single-shot retrieval. "The agentic property, when satisfied, necessitates planning (decomposing into sub-queries), navigation (iterating on intermediate findings), and aggregation (synthesizing partial answers)."
- Agentic Document Collection Visual Question Answering: A task setting where agents answer questions grounded in a corpus of multi-page documents using visual and textual evidence with multi-step reasoning. "MADQA exemplifies Agentic Document Collection Visual Question Answering."
- ANLS*: A strict string-similarity metric (Average Normalized Levenshtein Similarity) variant used for answer grading in document VQA. "We initially considered ANLS~\cite{peer2025anlsuniversaldocument}, but found it too strict---even after adding alternative answers, 35\% of predictions where ANLS assigned zero score were actually correct per human review."
- BM25: A probabilistic ranking/retrieval function widely used for term-based document search. "Gemini 3 Pro \textsubscript{BM25 Agent}"
- Classical Test Theory: A psychometrics framework for analyzing item difficulty/discrimination and constructing reliable test splits. "Guided by Classical Test Theory, we design it to maximize discriminative power across varying levels of agentic abilities."
- Closed-World: An assumption that answers must be derived only from the provided corpus, prohibiting external knowledge. "Closed-World & Answer derived solely from ; no external parametric knowledge."
- Cohen's kappa: An inter-rater agreement statistic; the quadratic-weighted variant accounts for graded disagreements. "the final setup achieves a quadratic-weighted Cohen's with human judgments, indicating almost perfect agreement~\cite{Landis77}."
- Construct Validity: The degree to which a benchmark measures the intended construct and not confounders. "we operationalize a Construct Validity framework \cite{bean2025measuringmattersconstructvalidity} to certify the benchmark's integrity."
- Cumulative Difference method: A technique for assessing dependence between a covariate (e.g., effort) and outcomes via cumulative deviations from the mean. "we design a metric based on the Cumulative Difference method \cite{kloumann2024cumulativedifferencespairedsamples},"
- Doc F1: An attribution metric measuring overlap of cited documents with gold documents, relaxing page-level strictness. "We also report Doc F1, which relaxes the constraint to the document level."
- Extractive: A property where the answer tokens must physically appear in the cited evidence. "Extractive & Answer tokens must appear physically in the evidence set ."
- Grounded: An attribution property requiring that cited evidence entails the answer and is minimal (no extra pages). "Grounded & must entail and be minimal (no superfluous pages)."
- Kuiper statistic: A range-based statistic (related to Kolmogorov–Smirnov) used here to quantify calibration between effort and accuracy. "We quantify the dependency between effort and accuracy using the Kuiper range statistic (Figure~\ref{fig:kuipe}, Appendix~\ref{app:calibration_metrics}):"
- LLM-based Accuracy: An answer-correctness metric judged by a calibrated LLM to allow semantically correct variants beyond exact match. "We use LLM-based Accuracy to balance two needs: answers must be concrete values suitable for downstream automation, yet the metric should accept semantically correct responses even when they differ in surface form from ground truth."
- Multi-Hop: A reasoning requirement where evidence spans multiple pages/documents and answers are composed across them. "Multi-Hop & may span disjoint pages (cross-page) or documents (cross-doc)."
- Oracle performance: An upper-bound score achievable with perfect retrieval/evidence, used to quantify remaining gaps. "They fail to close the nearly 20\% gap to oracle performance, persisting in unproductive loops."
- Page F1: A page-level attribution metric measuring overlap between cited and gold evidence pages. "we chose the Page F1 metric (Appendix~\ref{app:retrieval_metrics}) to serve as a proxy for the Context Relevance component of the RAG Triad \cite{truera2024ragtriad}."
- Parametric knowledge: Facts encoded in model parameters (training) rather than derived from the provided corpus. "Parametric Knowledge vs.\ Grounding."
- Point-biserial correlation: A statistical measure of item discrimination correlating binary correctness with overall ability. "We evaluate every question based on Difficulty (mean accuracy) and Discrimination (point-biserial correlation)."
- RAG Triad: A framework decomposing retrieval-augmented generation quality into components (e.g., context relevance). "to serve as a proxy for the Context Relevance component of the RAG Triad \cite{truera2024ragtriad}."
- Recursive LLMs (RLM): A paradigm where LLMs programmatically decompose and iteratively process inputs, often with sub-LLM calls. "We compare static RAG, unconstrained Recursive LLMs (RLM), and tool-augmented Agents, and demonstrate that constrained agency significantly outperforms static RAG while avoiding the catastrophic effort overhead of RLMs (\S\ref{sec:experiments})."
- Sentinel Pool: A reserved set of the hardest items ensuring benchmark headroom as models improve. "The Sentinel Pool (\textcolor{snowpink}{}) captures the hardest items to preserve headroom, regardless of discrimination scores."
- Spearman's rho: A rank-correlation coefficient used to assess consistency between test subset and full benchmark rankings. "The Test set achieves a strong rank correlation with the complete benchmark (Spearman's ) while retaining 100 items that are too complex for current models to ensure long-term relevance."
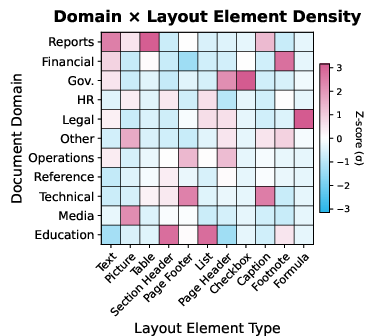
- z-score normalization: Standardizing features by subtracting the mean and dividing by the standard deviation to compare across domains. "We extract layout elements and compute per-element z-score normalization to highlight domain-specific patterns (see Appendix~\ref{app:layout_elemt_density})."
Collections
Sign up for free to add this paper to one or more collections.

