- The paper presents an asymmetric distillation method that transfers a 2B-parameter VLM’s embedding space to a compact 70M text-only encoder for query processing.
- It employs a query-centric training with cosine alignment loss, achieving 92–95% teacher retrieval quality while drastically reducing compute and memory requirements.
- Experimental results demonstrate up to 50× faster CPU inference and significant efficiency gains, with multilingual query augmentation improving cross-lingual performance.
Asymmetric Cross-Modal Distillation for Visual Document Retrieval: A Technical Essay on "NanoVDR: Distilling a 2B Vision-Language Retriever into a 70M Text-Only Encoder for Visual Document Retrieval" (2603.12824)
Introduction: The Challenge of Efficient Visual Document Retrieval
Recent advances in visual document retrieval (VDR) have predominantly relied on large vision-LLMs (VLMs) to encode both @@@@1@@@@ and user queries into a shared embedding space. Typically, this is achieved using multi-billion parameter networks capable of capturing both nuanced semantic and visual features. While such strategies have yielded impressive retrieval quality, this “symmetric” approach—applying the same heavyweight encoder to both documents (with visual complexity) and queries (usually short, text-only)—is computationally inefficient and imposes a significant latency and hardware burden, particularly at serving time for plain-text queries.
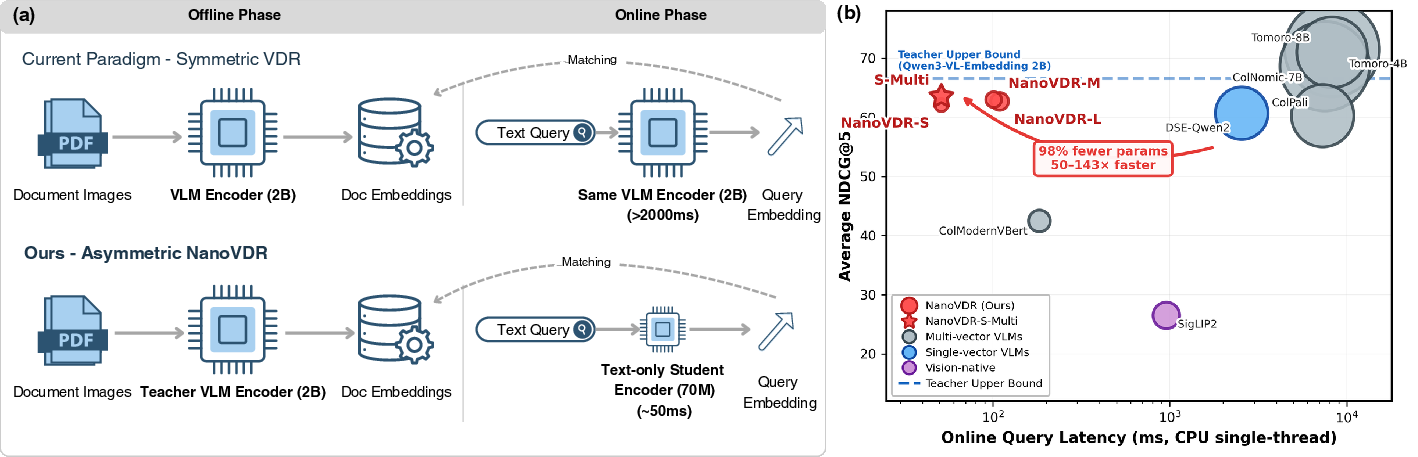
Figure 1: Asymmetric retrieval in NanoVDR decouples heavy visual offline encoding from lightweight text-only online encoding, reducing query latency by over 50x compared to state-of-the-art symmetric VLM-based systems.
NanoVDR addresses this inefficiency by leveraging the inherent asymmetry of the retrieval task: while documents require complex visual understanding, queries are purely textual. The core proposition is to use a high-quality, frozen VLM for offline document indexing, but to distill its semantic space into a minimal, CPU-efficient text-only encoder (70M params) exclusively for query processing. This decoupling promises drastic efficiency improvements while maintaining retrieval fidelity.
Methodology: Asymmetric Distillation and Query-Centric Learning
At the center of NanoVDR is an asymmetric dual-encoder pipeline: (1) a frozen 2B-parameter VLM teacher indexes document images offline, producing dense, single-vector embeddings; (2) a compact student model, built on backbones such as DistilBERT (69M params), encodes text-only queries at inference time by mapping them into the teacher-determined visual embedding space. During online retrieval, documents are never re-encoded—only queries are passed through the streamlined student network, which outputs embeddings in milliseconds on CPU.
The pivotal design consideration is the distillation objective. NanoVDR’s training paradigm is purely query-centric: all training queries are first encoded by the VLM teacher in text mode, and the student is then trained to match these teacher embeddings as closely as possible using a pointwise cosine alignment loss. Crucially, no document images, negative sampling, or corpus-level contrastive training are involved in this process.
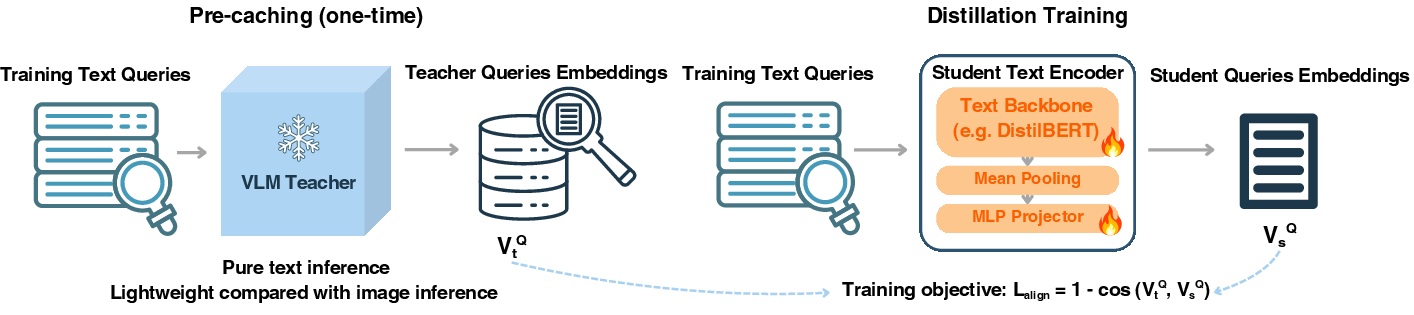
Figure 2: NanoVDR’s training process: teacher encodes queries offline; student minimizes cosine distance to teacher’s query embeddings—document images are not used during training.
Formally, given a teacher embedding vtQ for a query q and a student embedding vsQ from the text-only encoder, the loss is
Lalign=1−cos(vtQ,vsQ)
The clear separation of roles—heavy visual processing for documents, lightweight text-only mapping for queries—produces a production-ready system that is both fast and hardware-efficient.
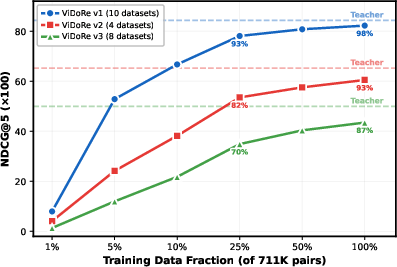
NanoVDR models were evaluated on the ViDoRe benchmark, which covers 22 datasets of varying complexity and languages, under both single- and multi-vector retrieval regimes. Three NanoVDR student variants (based on DistilBERT, BERT-base, and ModernBERT, ranging from 69M to 151M parameters) were benchmarked against both multi-vector and single-vector VLMs.
Key findings:
Ablation and Analysis: Objective Superiority and Data Efficiency
A systematic ablation investigated six loss objectives across three backbones and three benchmark splits, totaling 54 runs. Results:
- Increasing the weight of the alignment loss over ranking/contrastive objectives led to monotonic improvements in NDCG@5.
- The InfoNCE baseline (hard labels) underperformed by 10–22 NDCG points relative to alignment-based distillation, underscoring the importance of geometric embedding fidelity (“dark knowledge”) over binary relevance.
- Data efficiency is pronounced: NanoVDR-S achieves ~93% of teacher quality using only 25% of training data (178K pairs); marginal gains diminish rapidly, especially on multilingual corpora.
Cross-Lingual Transfer and Multilingual Query Augmentation
A critical limitation of the pure alignment, query-centric approach is language transfer: while the modality gap (text-only student encoding visual space) is efficiently bridged, cross-lingual performance lags behind if student training data is predominantly English.
Language-specific analysis revealed:
- Retention correlates tightly with training set language distribution (94% on English, dropping to 75–85% for languages absent from training).
- Multilingual augmentation—translating English queries to underrepresented target languages and encoding them with the frozen teacher—restores cross-lingual retention to English levels (all six languages >92% retention).
- This augmentation incurs trivial additional computational cost (no need for VLM image inference, only text-mode query encoding).
Impact, Implications, and Future Directions
The practical implication is immediate: visual document retrieval with near-state-of-the-art quality can now be deployed using only a compact text encoder for queries, running entirely on CPU, with offline-indexed VLM embeddings for documents. This reduces hardware demands for production search systems, enables battery-friendly edge deployment, and allows scalable single-vector retrieval over massive document collections. The key technical insight is that cross-modal geometric alignment is sufficient for transfer—exploiting the teacher’s structured visual-text space—so long as query–language coverage is sufficient.
Several research avenues remain:
- Since retrieval performance is bounded by teacher embedding quality, further compression or distillation of the document encoder may be investigated.
- Application to settings where queries have mixed visual/textual content is natural.
- Extension of training to other VLM architectures or backbones can broaden applicability and robustness.
- Higher-fidelity translations (LLM-assisted) or native-language annotations could further close the long-tail cross-lingual gap for domain-specific jargon.
Conclusion
NanoVDR establishes a technically rigorous, empirically validated framework for asymmetric, cross-modal distillation tailored to visual document retrieval. By demonstrating the dominance of pointwise cosine alignment and highlighting cross-lingual augmentation as the primary bottleneck, it achieves nearly complete knowledge transfer from a multi-billion parameter VLM teacher to a lightweight, CPU-efficient text-only encoder. This paradigm can serve as a blueprint for efficient dense retrieval systems, catalyzing both practical deployment and further research in cross-modal and cross-lingual transfer.