- The paper introduces specialized pretraining (SPT) to integrate domain data early, reducing domain test loss and mitigating catastrophic forgetting.
- SPT achieves up to 1.75× fewer pretraining tokens and allows smaller models to match larger ones by curbing overfitting and improving parameter efficiency.
- The study presents an overfitting-aware scaling law to predict the optimal domain-general data mix, providing actionable insights for compute and model tuning.
The Finetuner’s Fallacy: Early Domain Data Integration in LLM Pretraining
This work, “The Finetuner’s Fallacy: When to Pretrain with Your Finetuning Data” (2603.16177), systematically critiques the prevailing paradigm in domain adaptation for LLMs, wherein domain-specific data is reserved exclusively for the post-pretraining finetuning phase. The authors introduce and analyze a counter-strategy they call specialized pretraining (SPT), which mixes a small fraction of domain data into the general pretraining set from the outset and continues to use it during finetuning. The motivation is grounded in three persistent challenges:
- Catastrophic forgetting: Post-pretraining finetuning on new domains degrades generalization, particularly for domains poorly represented in the original training distribution.
- Data scarcity: Proprietary or specialized datasets are often orders of magnitude smaller than general web-scale corpora.
- Resource constraints: Finetuning larger models to achieve acceptable domain performance is costlier in inference and deployment, raising questions about optimal amortization of compute and parameter efficiency.
Specialized Pretraining Methodology
SPT interleaves domain-specific tokens into the general training stream as a controlled mixture fraction δ, typically ranging from 0.1% to 10% of total pretraining tokens. This means the domain corpus is repeated many times (e.g., 10–50×), but always backgrounded by general web data. Both SPT and classical training pipelines apply further standard finetuning exclusively on the domain dataset. The critical empirical questions are:
- Does SPT yield lower domain-specific test loss after finetuning?
- Does SPT mitigate catastrophic forgetting of general capabilities post-finetuning?
- How does SPT compare to naive pretraining and finetuning (NPT→FT) in terms of compute, inference cost, and sample efficiency?
- What are the regimes—domain data scale, domain–pretraining divergence, compute budget, model size—where SPT delivers maximal benefit?
The authors address these via controlled experiments on OLMo-based models and three diverse domains: MusicPile (symbolic music), ChemPile (scientific/chemical), and ProofPile (formal mathematics).
Core Empirical Findings
SPT Lowers Domain Test Loss and Reduces Forgetting
Across all tested domains, SPT consistently achieves lower domain test loss and higher downstream task accuracy, compared to models that see the domain data only during finetuning. This holds for mixture fractions as low as 1–5%, and is especially pronounced when the target domain is underrepresented or structurally far from general web data.
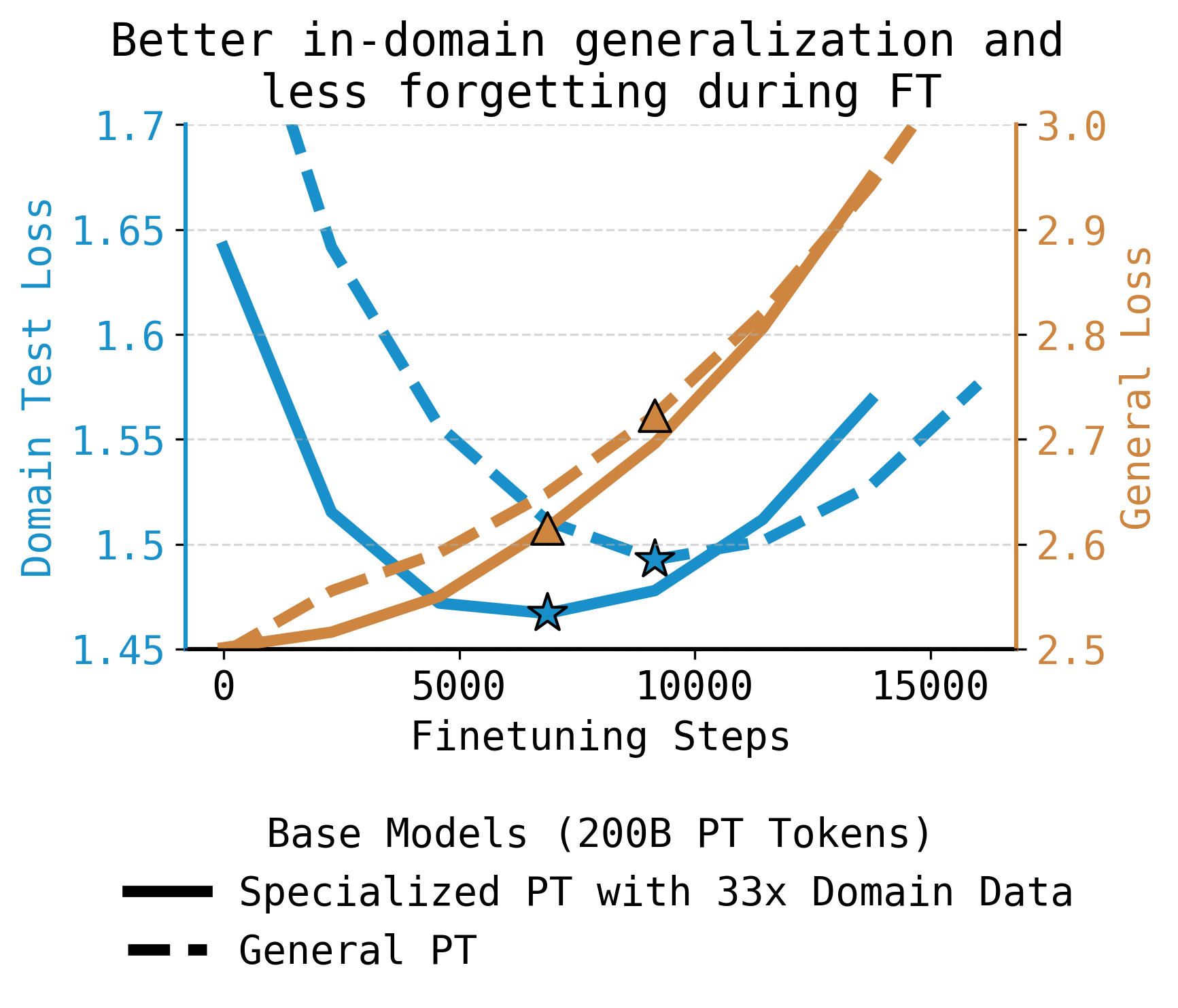
Figure 1: Specialized pretraining (SPT) mixes the finetuning dataset into pretraining as a small fraction of tokens, repeating it many times; SPT (solid) achieves lower domain test loss and less forgetting of general knowledge throughout finetuning relative to general pretraining (dashed), overcoming model scale differences for narrow domains.
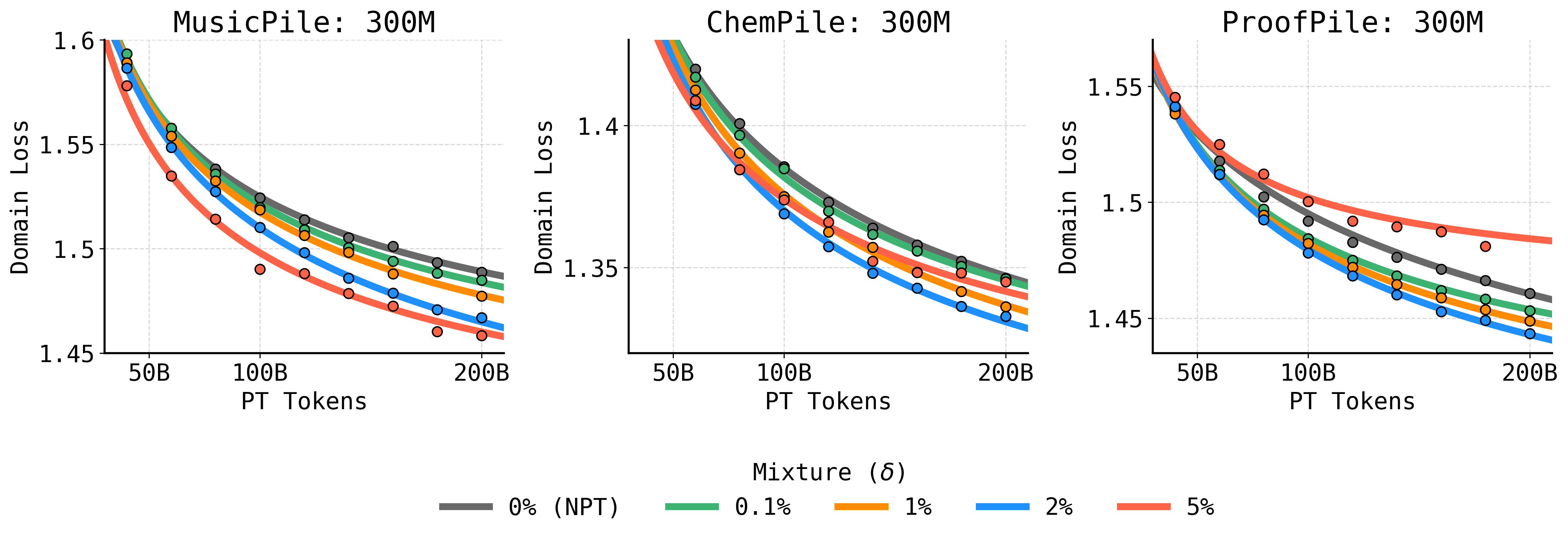
Figure 2: SPT outperforms finetuning alone across ChemPile, MusicPile, and ProofPile, with consistent gains in best post-finetuning domain loss for mixture fractions as small as 1–5%.
Compute and Parameter Efficiency
SPT achieves target domain performance with up to 1.75× fewer pretraining tokens. Furthermore, a 1B-parameter model pretrained with SPT can match or surpass a 3B-parameter model trained using standard NPT→FT on domains distant from web data. Thus, SPT enables serving smaller models without sacrificing quality, translating to lower inference cost after a modest break-even point in inference volume.
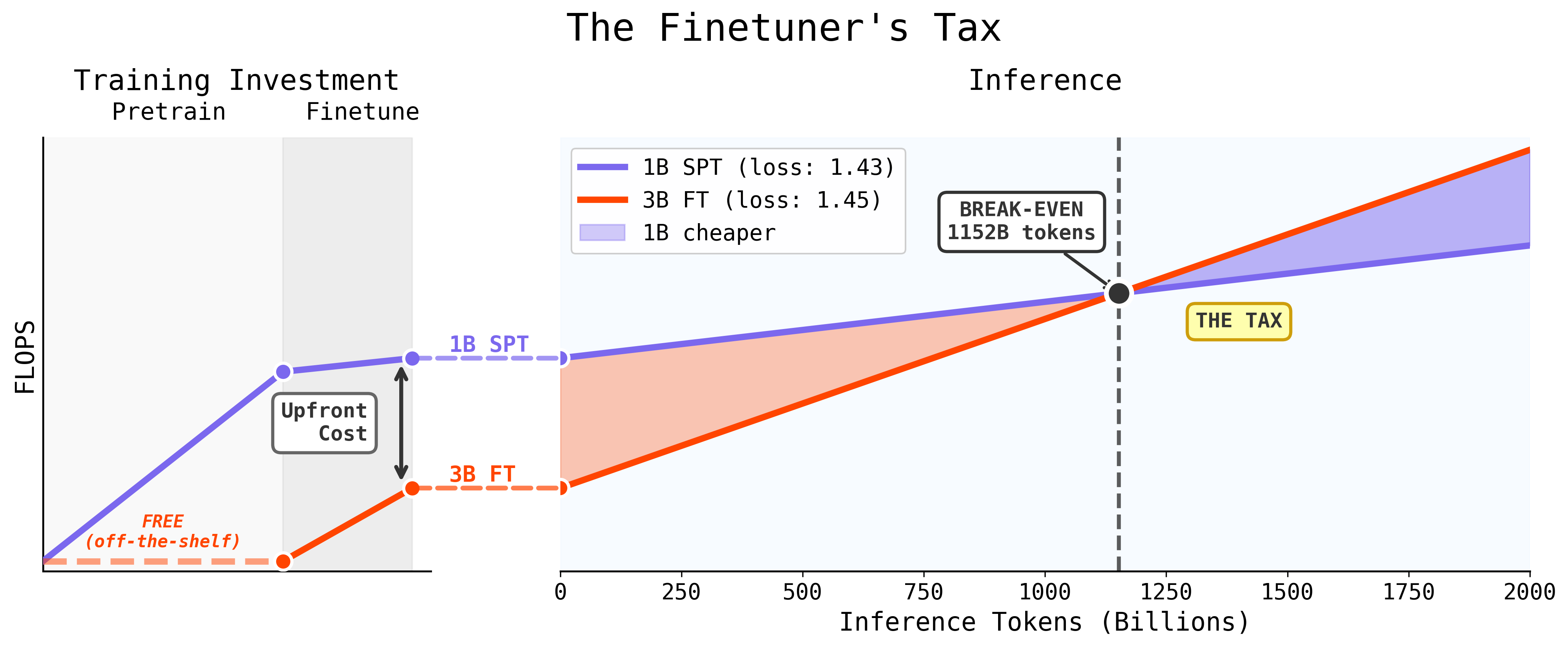
Figure 3: SPT requires a higher upfront training cost than finetuning a 3B model, but the much smaller 1B model is cheaper to serve; after about 1 trillion inference tokens, SPT is both cheaper and often higher performing.
SPT Beats Scaling and Controls Overfitting
Compared to simply increasing token count or model parameters, SPT provides a more efficient Pareto-optimal frontier: it closes the gap to larger models and accelerates domain learning.
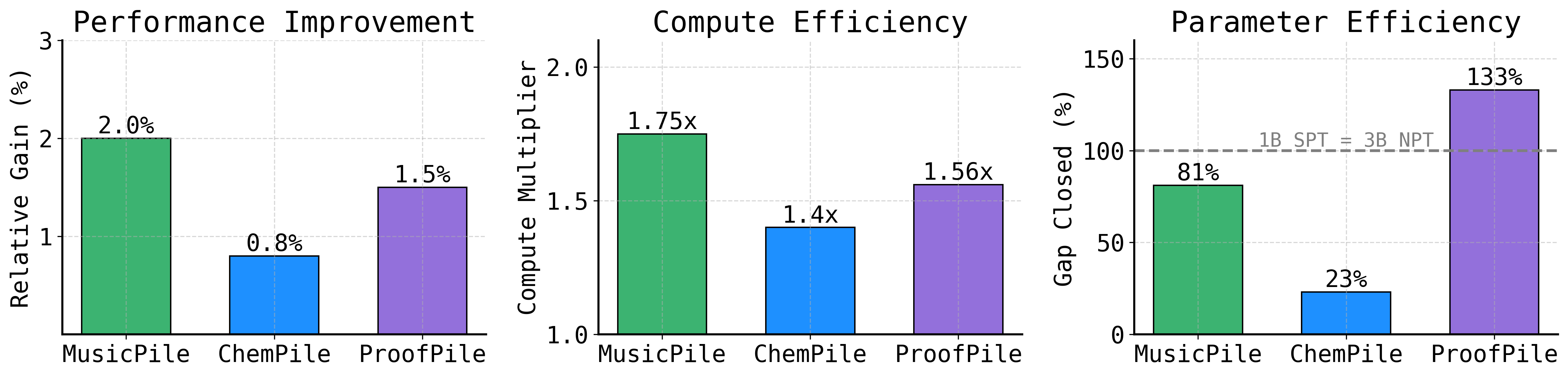
Figure 4: SPT outperforms token/model scaling, closing a substantial percentage of the parameter gap or even surpassing the base model.
SPT reduces overfitting during finetuning. Models exposed to domain data early generalize better, requiring less aggressive adaptation and preserving both specialized and broad knowledge.
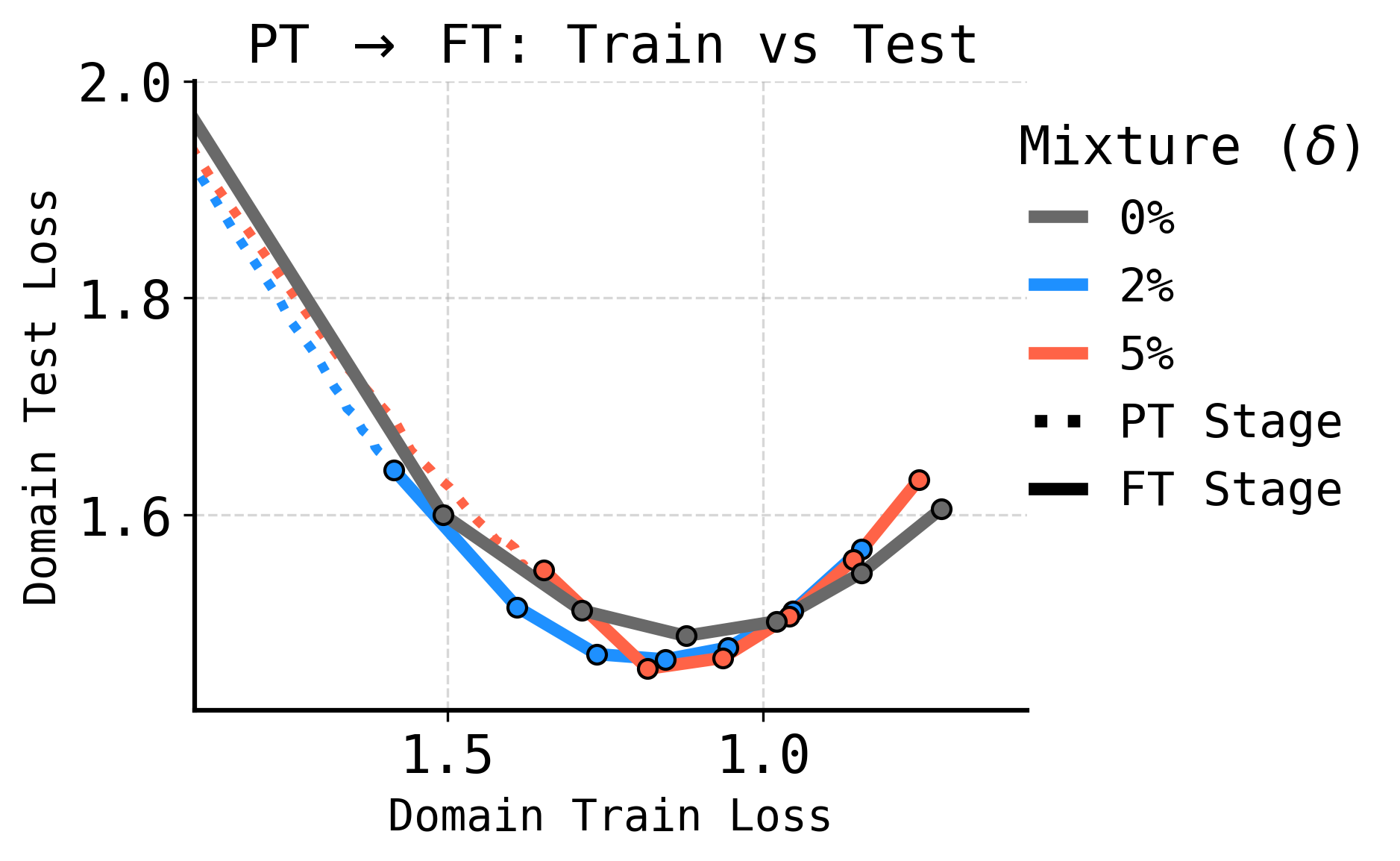
Figure 5: SPT regularizes finetuning; for the same domain training loss, SPT models exhibit lower domain test loss, reducing overfitting despite having seen the domain data many times during pretraining.
Robustness Under Replay
Replay-based continued pretraining, a common defense against forgetting, is not an adequate substitute for early domain integration. SPT→FT consistently outperforms NPT→FT, even as replay rates are increased—demonstrating when the model sees domain data is critical, not just how often.
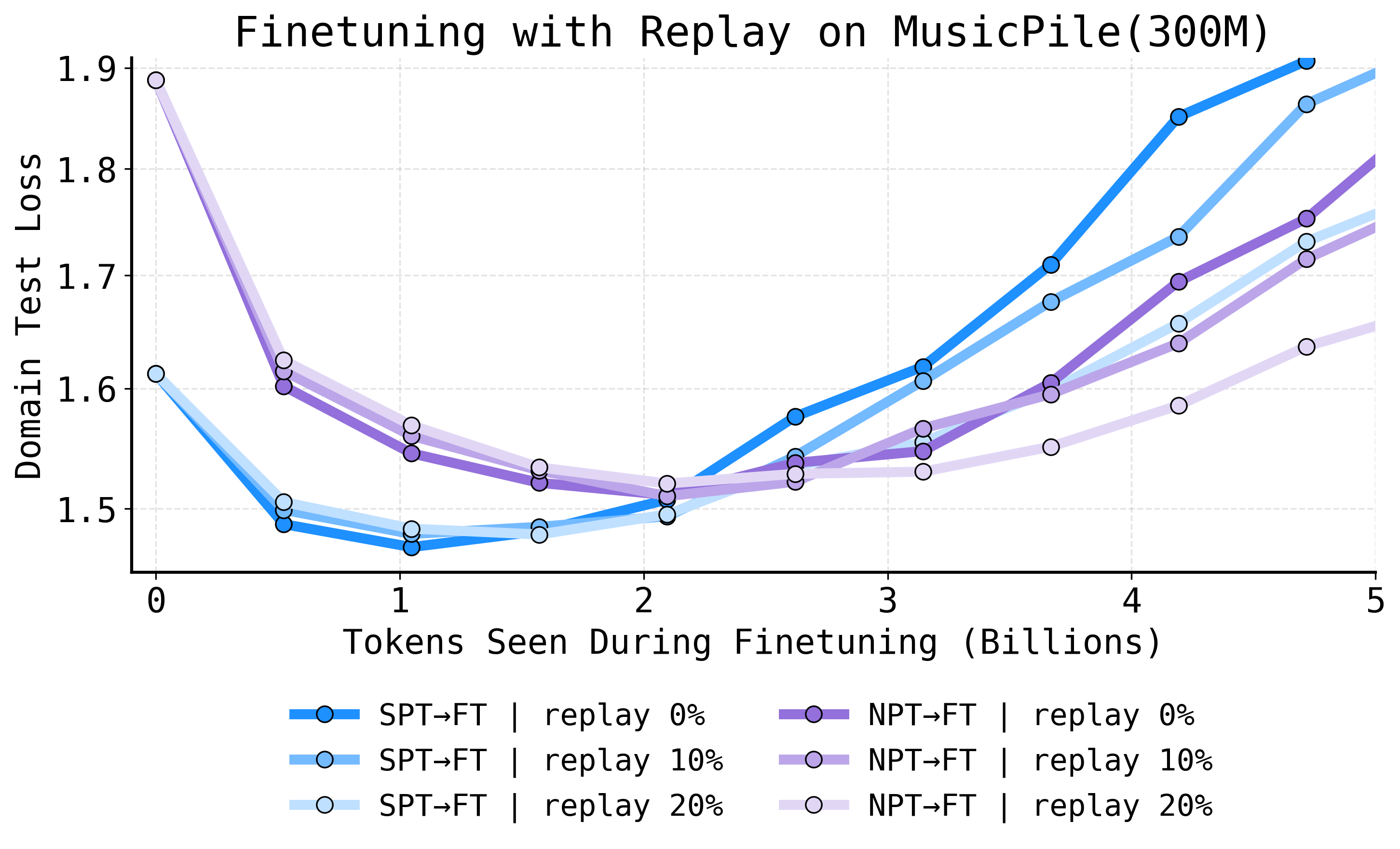
Figure 6: SPT to CPT (blue) achieves lower domain test loss than NPT to CPT (purple) at all replay rates, indicating lasting benefits of early exposure.
Analytical Contributions: Overfitting Scaling Laws
The paper formalizes the SPT regime by introducing an overfitting-aware scaling law. The test loss as a function of pretraining budget and mixing fraction is decomposed into a sum of two competing powers: one corresponding to continuously decreasing training loss, the other to an increasing train–test gap induced by repeated exposure, i.e., overfitting.
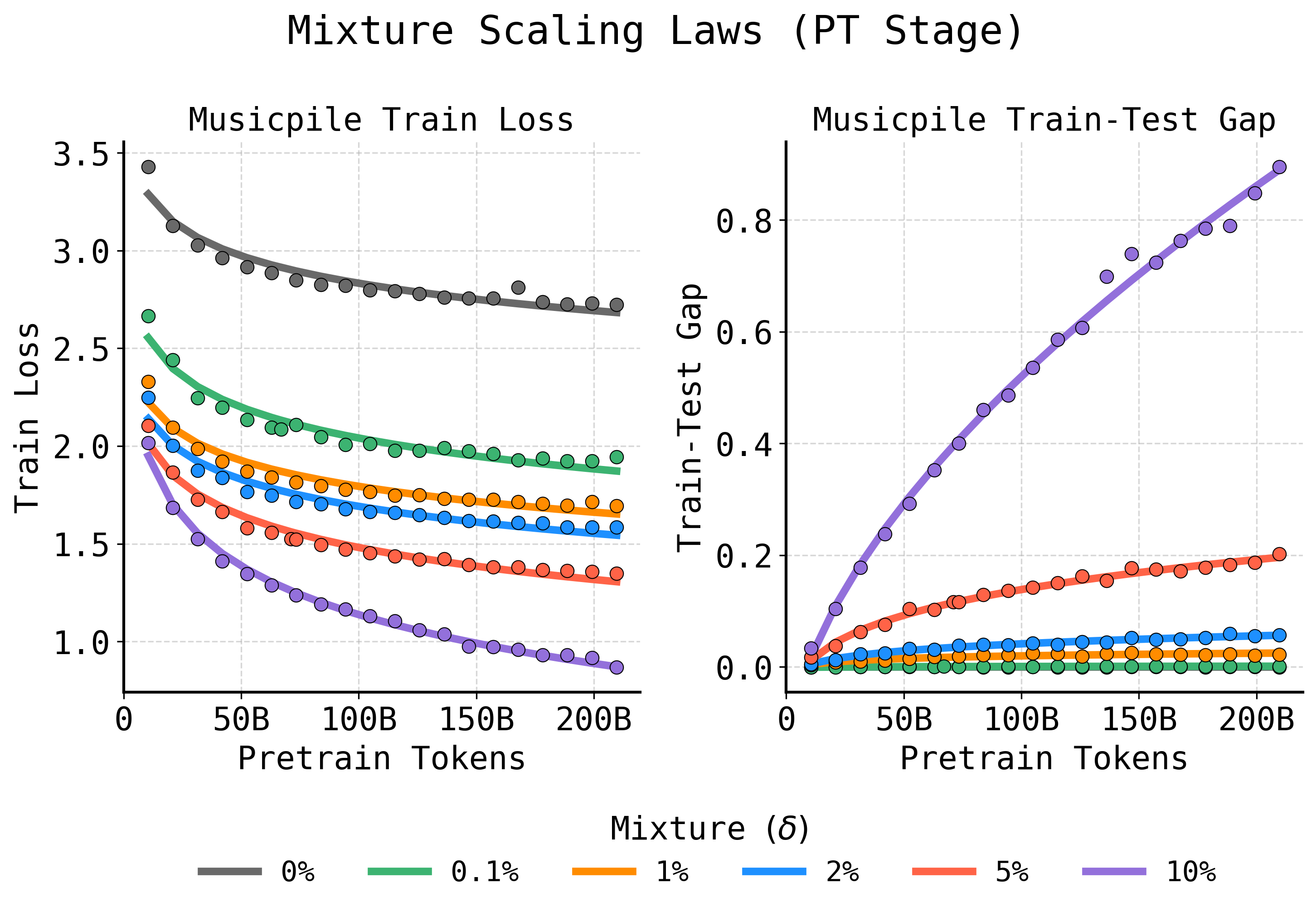
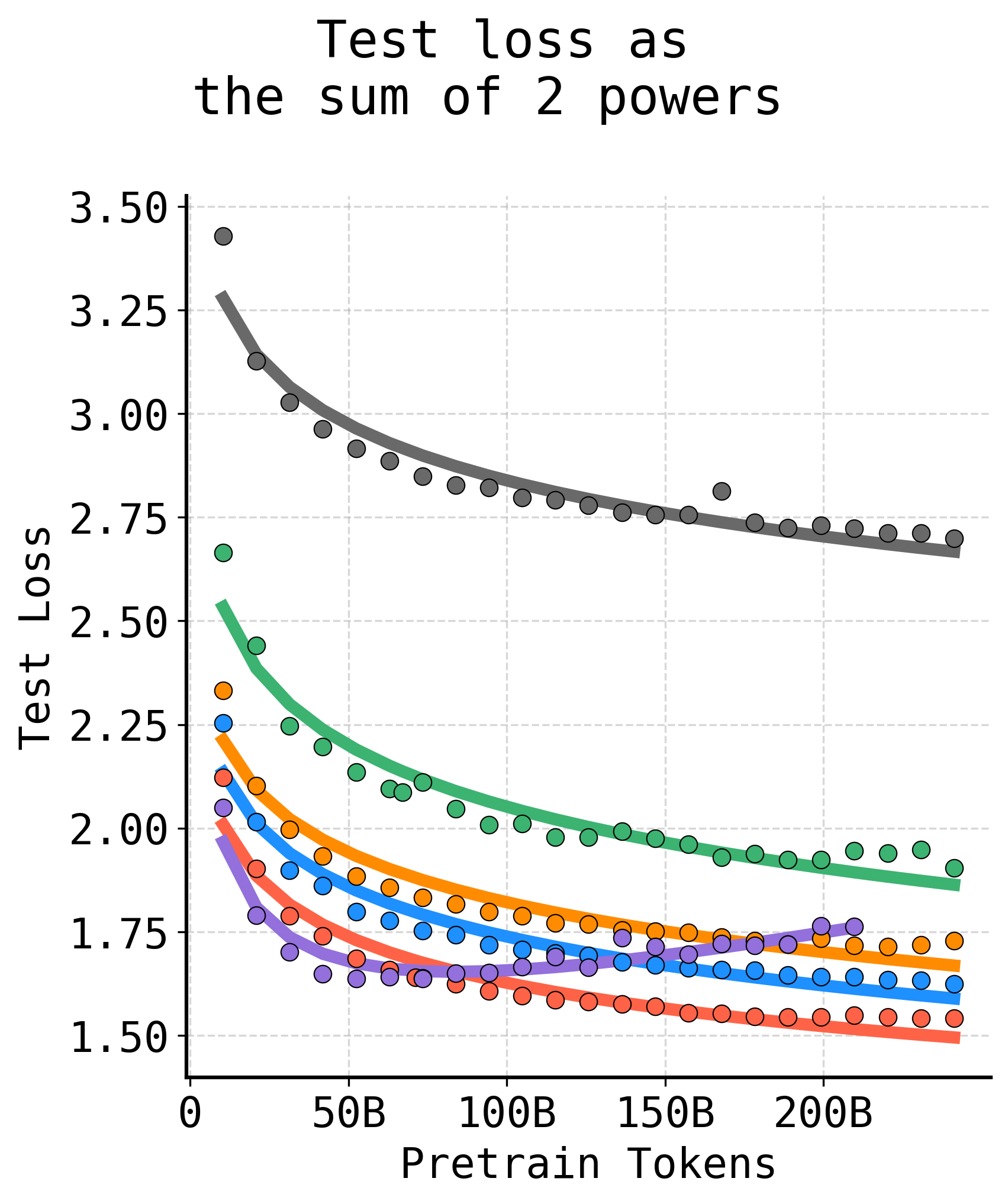
Figure 7: Standard power laws fail to capture nonmonotonic overfitting from repeated data. Modeling training loss and train–test gap as distinct power laws provides accurate fits for SPT behavior.
By modeling the test loss trajectory as
Ltest(T,δ)=AtrainTbtrain(δ)+Ctrain(δ)+Agap(δ)Tbgap(δ)
and fitting coefficients as functions of δ, the framework allows practitioners to accurately forecast the optimal domain–general mixture for a desired compute budget, eliminating expensive sweeps.
Factors Governing SPT Efficacy
The SPT benefit amplifies as:
- Domain distribution diverges from pretraining data: Larger gains observed on domains least represented in general corpora.
- Domain data size increases: For small datasets, late-stage mixing (SCPT) may be preferred to avoid rapid overfit, but for moderate to large domain datasets, SPT is optimal.
- Model scale increases: Larger models show bigger gains due to their greater propensity for memorization.
- Compute budgets vary: Higher mixture fractions are preferred under budget-constrained regimes; longer training makes lower mixtures optimal.
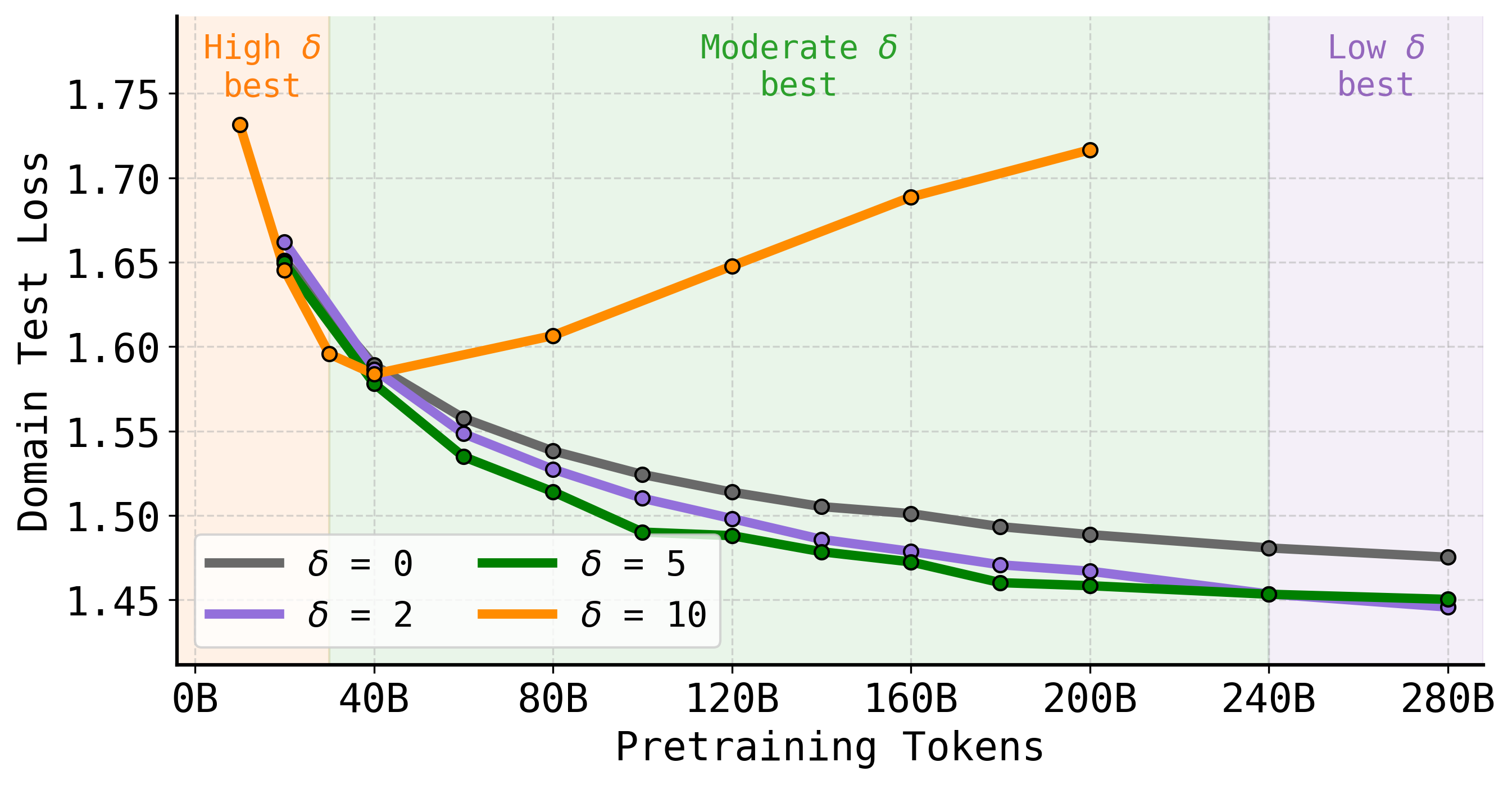
Figure 8: The optimal domain–general mixture fraction depends on pretraining budget; larger mixtures win early, but overfit later, so tuning δ to available compute is essential.
Implications and Outlook
Practical Impact
The findings call into question the standard practice of “domain last”, i.e., inserting domain data solely during post-pretraining finetuning. For high-value, data-scarce, or distribution-shifted applications (legal, clinical, scientific, code, etc.), early integration via SPT unlocks both parameter and compute savings, lowers inference costs, and enhances model robustness. As the marginal cost of custom pretraining falls, SPT adoption is poised to grow in industry and research.
Theoretical Considerations
This work substantiates a broader theoretical principle: the time of data introduction in the training pipeline fundamentally modulates model generalization and memory. The scaling-law-based framework for overfitting, now accommodating nonmonotonic trajectories in the small-data, high-repetition regime, advances the modeling of data mixtures and repetition effects in LM training.
Future Directions
- Automated mixture fraction selection: Integrating scaling law estimation into hyperparameter optimization or AutoML pipelines, particularly for organizations with compute or data constraints.
- Extension to instruction-tuning, RLHF, and synthetic data: Evaluating SPT for tasks involving heavier distributional shifts or non-MLM supervision, as well as mixtures of synthetic and real data.
- Generalization beyond language: Applying SPT and associated scaling laws in vision and multimodal systems, where domain drifts and fine-tuning are equally prevalent.
- Linking to continual learning and catastrophic forgetting: Further mechanistic study into why early injection is more robust than replay, potentially exploiting insights from continual learning theory.
Conclusion
This study presents a decisive empirical and analytical case for the early introduction of domain data in the LLM pretraining pipeline, demonstrating that SPT confers lasting benefits in parameter efficiency, compute amortization, and retention of generalization. The formal introduction of overfitting-aware scaling laws provides actionable guidance for practitioners and grounds future theoretical developments at the intersection of data mixing, memorization, and transfer. The finetuner’s fallacy—believing finetuning alone is optimal for domain adaptation—is challenged; practitioners should now regard early domain exposure as fundamental to robust, efficient specialization of large models.