- The paper demonstrates that aligned models trade descriptive fidelity for normative bias, leading to a performance drop in multi-round strategic tasks.
- Methodologically, the study systematically compares 120 base–aligned model pairs across 10,000 human decisions, showing a base-model win ratio of 9.7:1.
- Implications stress that using aligned LLMs for behavioral simulations may misrepresent actual human behavior, urging new paradigms to preserve output diversity.
Alignment-Induced Normative Bias in LLMs: A Systematic Comparison of Base and Aligned LLMs
Motivation and Context
The paper "Alignment Makes LLMs Normative, Not Descriptive" (2603.17218) systematically interrogates the pervasive assumption that post-training alignment methods, such as RLHF or DPO, inherently improve LLMs as proxies for human behavior. While aligned models are frequently deployed both in user-facing applications and research settings to replicate or predict human decisions, this work challenges the foundational equivalence between maximizing human approval and accurately modeling human behavior — an issue of paramount importance for behavioral and social science simulations using LLMs. The authors argue that alignment introduces a normative bias, shifting model predictions from descriptive fidelity (what people actually do) to normative regularity (what is socially approved). This distinction is especially prominent in strategic domains where actual human actions systematically diverge from idealized behavior.
Experimental Framework
The study constructs an extensive empirical testbed: 120 base–aligned model pairs from 23 families spanning over 10,000 real human decisions, derived from multi-round games in economic and psychological benchmarks (bargaining, persuasion, negotiation, repeated matrix games). The evaluation is based on Pearson correlation between LLM-assigned decision probabilities and actual human choices at each decision point, utilizing deterministic logprob extraction rather than text generation to provide a controlled, format-agnostic basis for comparison.
The experimental protocol rigorously controls for prompt structure, model provider, size, and diverse task parameters. Four main prompt variants are used to isolate the impact of alignment versus format artifacts; an additional battery of 14 prompt formulations is examined to check robustness against prompt wording, framing, and role assignment.
Main Results: Empirical Findings
Across all multi-round game families, base models surpass aligned counterparts in predicting human decisions by a margin of 9.7:1 (213 base wins vs. 22 aligned wins, p<10−40).
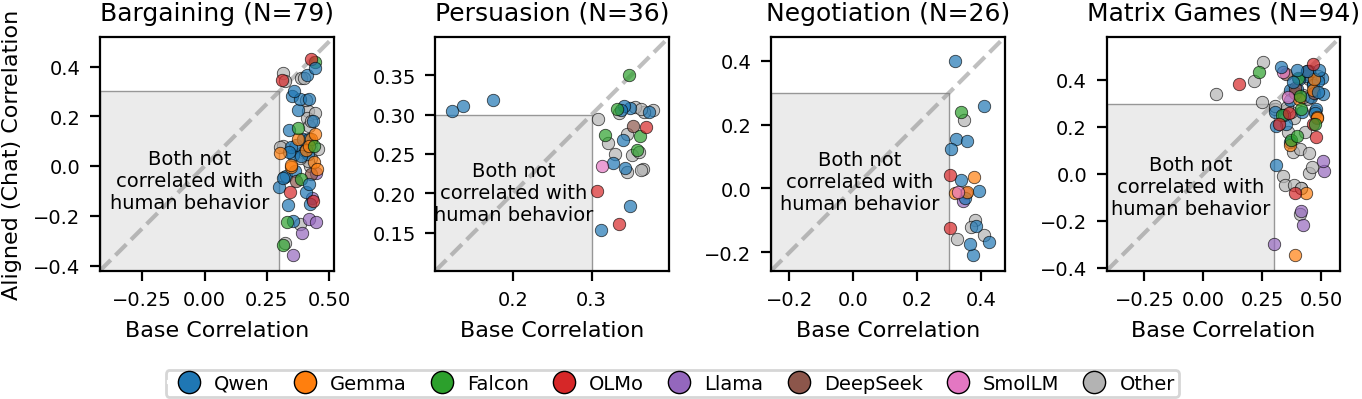
Figure 1: Pearson correlations of base models and human decisions (x-axis) vs. aligned models and human decisions (y-axis) across four game families. Each point represents a same-provider model pair; a strong base advantage is observed, especially below the diagonal.
This effect is consistent:
- Across model families: Every major provider (Qwen, Gemma, Llama, Falcon, OLMo, DeepSeek, SmolLM) exhibits a persistent base-model advantage, generally scaling positively with model size.
- Across prompt and format variants: Even when both models are evaluated with exactly the same plain-text or chat-formatted prompt, the base advantage remains (e.g., 5.0:1 and 5.3:1, respectively), ruling out prompt artifact confounds.
- Throughout prompt content variations: Out of 1,003 prompt-variant comparisons, base models win 959 (95.6%).
Notably, in every configuration parameter of each game family except one, the base-model superiority holds. Robustness checks with different token mass and correlation thresholds confirm the stability of these results.
Scaling Analysis
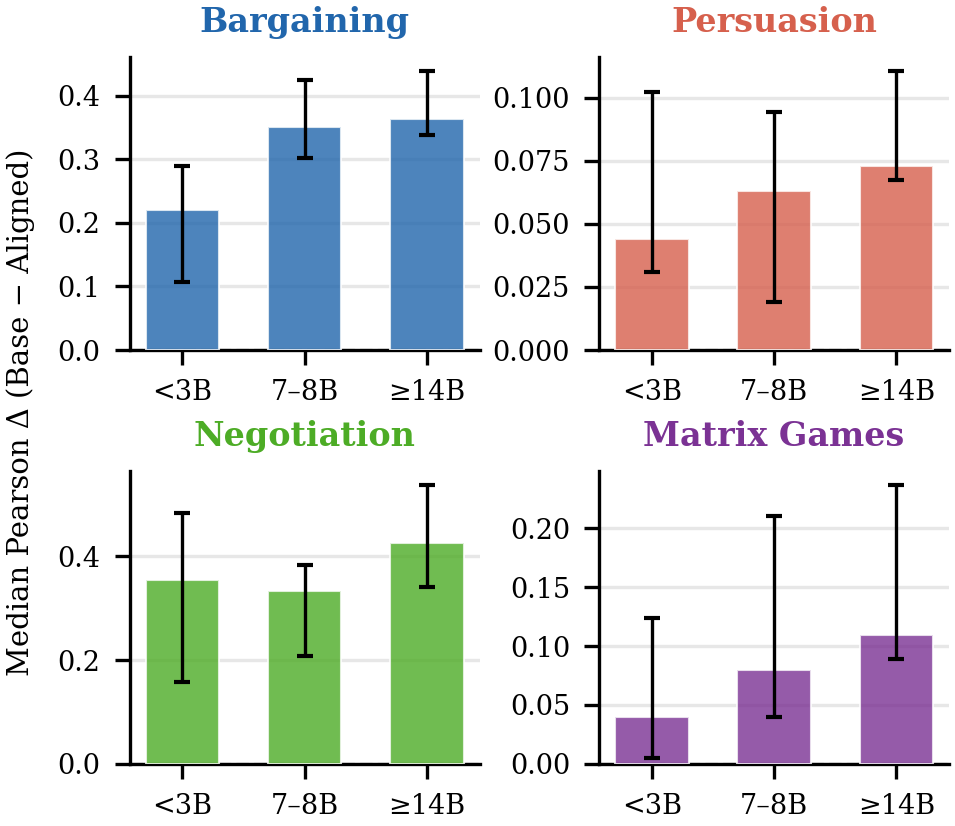
Figure 2: Median Pearson correlation difference (base minus aligned) by model size; the base advantage grows systematically with increasing model scale.
Model scaling accentuates the base advantage, particularly in bargaining and negotiation, implying that larger base models better preserve the diverse, descriptive patterns required to match empirical human behavior.
Boundary Conditions and Reversal of Effect
However, the pattern reverses in scenarios where human behavior conforms more closely to normative theories:
- One-shot textbook games: On a large benchmark (2,416 one-shot 2×2 games, 93,000 human choices), aligned models achieve a 4.1:1 win ratio, consistently across all 12 game types. The same reversal is observed for non-strategic binary lotteries (2.2:1 aligned-model win rate).
- Early rounds in multi-round games: Aligned models outperform base models at round one, but as intertemporal dynamics like reciprocity and history-dependence build, base models gain the advantage.
Aligned models' predictions in one-shot games also closely track Nash equilibrium probabilities, which themselves moderately correlate with human actions in these settings.
Theoretical Implications and Mechanism
These results elucidate a sharp trade-off induced by current alignment methods. RLHF and DPO, by optimizing models toward human-preferred (normative) outputs, perform an exponential tilting of the base model's distribution that collapses behavioral diversity and under-represents the tail behaviors critical for descriptive accuracy in complex, history-dependent strategic settings. Theoretical work clarifies that this distributional narrowing is not incidental but is inherent to the objective, leading to "preference collapse" and a systematic loss of representation for less-approved, but frequently observed, human behaviors.
The selective reversal of performance — with aligned models excelling in settings best described by normative theories, and base models dominating in descriptive, dynamic, or multi-round domains — demonstrates that alignment does not simply reduce overall capacity (e.g., via catastrophic forgetting), but fundamentally shifts the locus of model prediction on the normative-descriptive axis.
Methodological and Practical Consequences
The findings have significant implications for both research and deployment:
- Behavioral and social simulation: Using aligned models as behavioral proxies risks modeling normative or idealized versions of human action, potentially misleading results in economics, policy simulation, and social science, especially in domains where strategic behavior is non-normative.
- Choice of model: For tasks requiring faithful representation of observed behavior — particularly in multi-shot, interactive, or dynamic strategic contexts — base models offer substantially greater descriptive accuracy. Aligned models may be preferable for decision-support or user-facing applications emphasizing socially approved patterns.
- Method development: There is a need for new alignment paradigms that enhance helpfulness and preference-matching while preserving the rich, empirical diversity of human behavior.
Directions for Future Work
Several open problems remain:
- Identification of which specific multi-round mechanisms (opponent modeling, trajectory novelty, temporal credit assignment) account for the persistent base advantage.
- Extension to continuous action spaces, larger or closed models, and other strategic domains (e.g., auctions, coalition games).
- Algorithms that achieve alignment without sacrificing behavioral entropy or diversity, possibly by separately estimating normative and descriptive distributions or regularizing for entropy preservation.
Conclusion
This study demonstrates a robust trade-off in LLM alignment: while alignment enhances predictive accuracy when human choices are normative (textbook or one-shot games, non-strategic lotteries), it degrades descriptive fidelity in multi-round, dynamic settings where actual behavior diverges from normative ideals. This emerges as an inherent property of reward-maximization alignment and calls for more nuanced strategies when employing LLMs as behavioral models in scientific research or simulation. The choice between base and aligned models should be made with explicit consideration of normative-descriptive trade-offs, and alignment pipelines must be revisited to accommodate applications requiring broad behavioral realism.