- The paper demonstrates that key design choices—in starting artifact, credit horizon, and experience batching—critically influence optimization outcomes.
- Empirical case studies reveal that modularized and monolithic artifact configurations yield significantly different performance across tasks.
- The study highlights that task-specific heuristics and meta-optimization are essential for balancing convergence and generalization in agentic systems.
Challenges and Design Decisions in Iterative Generative Optimization with LLMs
Overview of Generative Optimization and Learning Loop Design
The paper "Understanding the Challenges in Iterative Generative Optimization with LLMs" (2603.23994) systematically analyzes the impediments to practical adoption of LLM-based iterative optimization for agentic systems. Generative optimization refers to the process where LLMs iteratively modify artifacts—such as code, prompts, or workflows—using feedback from execution traces, converging towards improved task performance. Despite active research and infrastructure development, adoption in production remains limited, with only 9% of surveyed agents utilizing automated optimization.
The authors hypothesize that this brittleness stems from the difficulty of configuring a robust learning loop. The implementation necessitates non-trivial, often implicit design choices regarding: (i) the starting artifact, (ii) the credit horizon, and (iii) the batching of experience traces. Each of these influences both practical convergence and generalization.
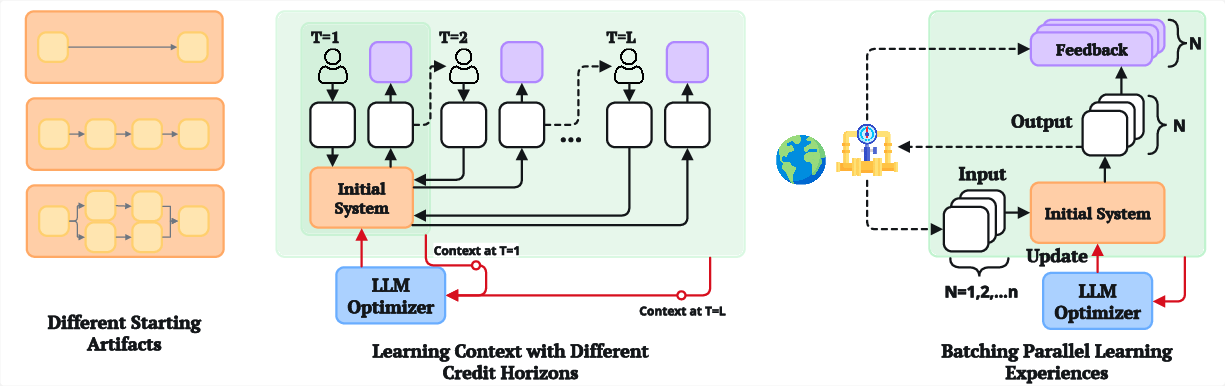
Figure 1: Three principal decisions—starting artifact, credit horizon, experience batching—govern the learning loop for iterative generative optimization.
Starting Artifact: Initialization and Modularization in ML Pipelines
Initialization of the optimizable artifact exerts significant control over the reachable solution space, paralleling the impact of architectural and weight initialization in deep learning. The case study on MLAgentBench demonstrates two artifact configurations: a monolithic train_model function and a modularized multi-component pipeline (preprocess, feature selection, training, prediction), both with equivalent semantic annotations.
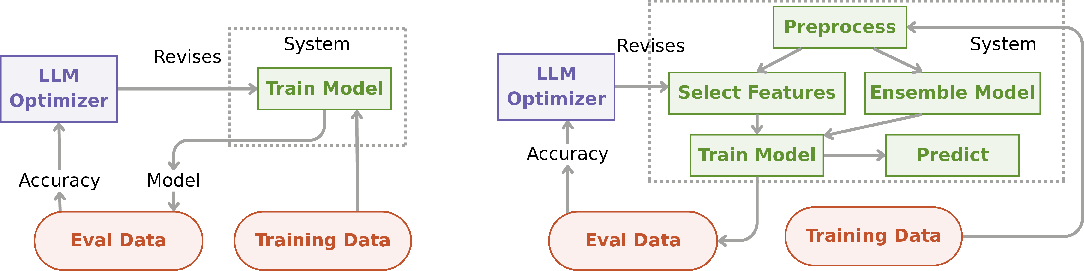
Figure 2: Comparing initializations: monolithic vs modular ML pipeline designs.
Empirical results reveal pronounced sensitivity to this design. For the Spaceship Titanic task, modularized pipelines surpass monolithic initializations in best-case leaderboard performance, achieving 86.6% against 72.7%. Conversely, on Housing Price, the monolithic variant yields higher performance. These findings underscore that modularization does not monotonically yield better optimization; its effectiveness is context-dependent, and the artifact design must be explicitly tailored per task.
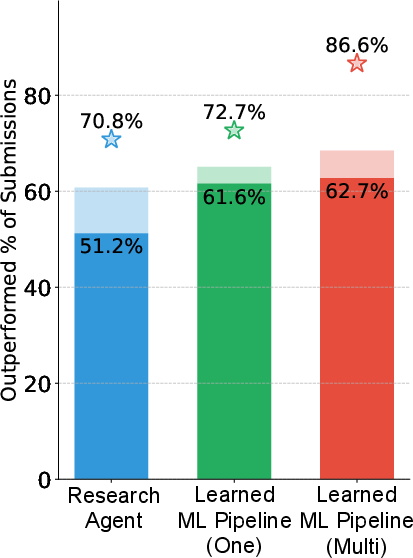
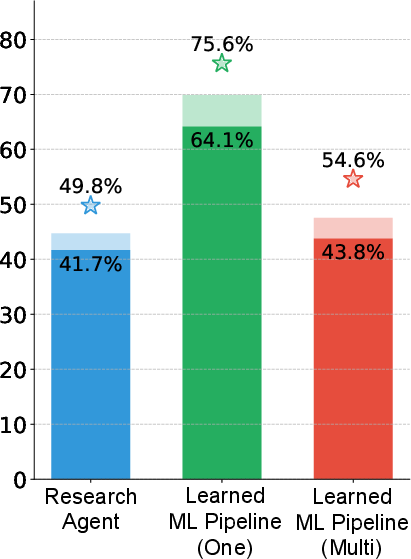
Figure 3: MLAgentBench leaderboard performance as percentile rank.
Credit Horizon: Traces and Feedback Granularity in Sequential Environments
Credit assignment in multi-step tasks—a classical concern in reinforcement learning—manifests as the "credit horizon" in generative optimization. Using OCAtari environments, the authors evaluate the effect of short (immediate reward) versus long (full rollout) horizons in Atari agent optimization.
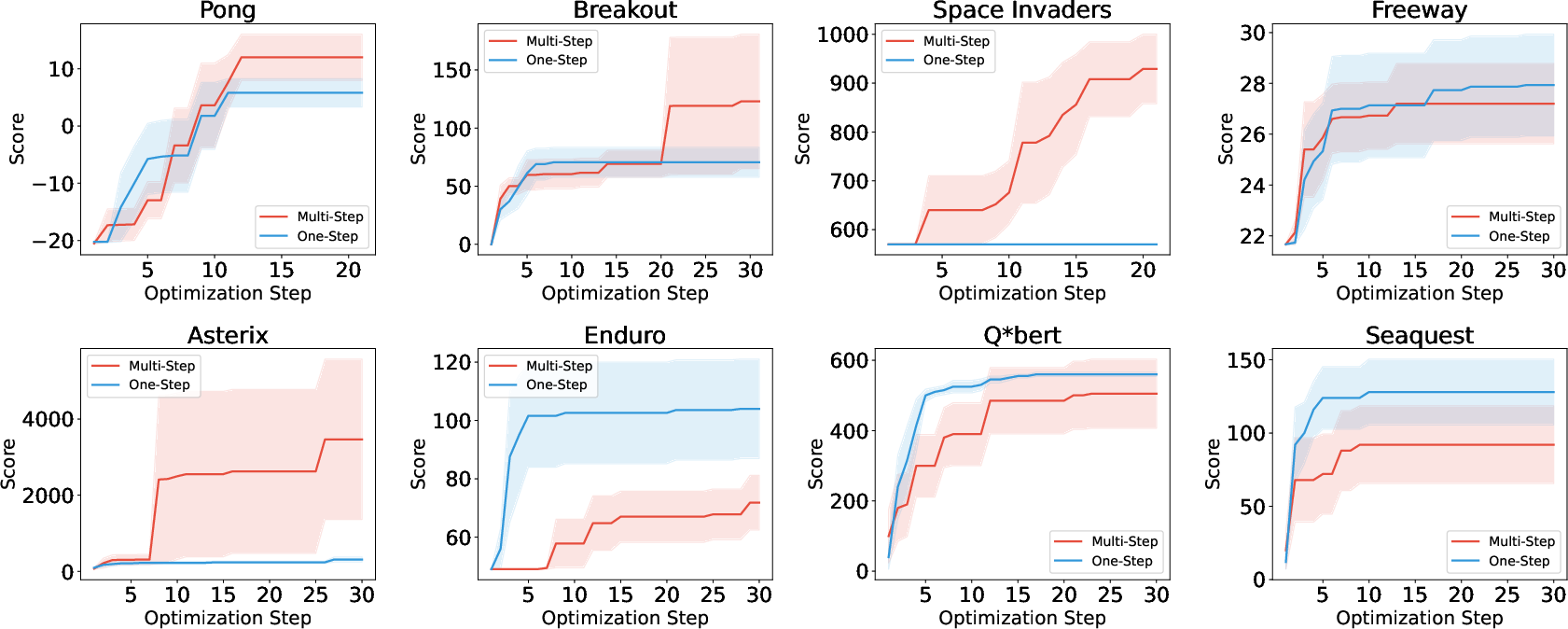
Figure 4: Performance comparison for short vs long credit horizons across eight Atari games.
Results show that longer credit horizons only improve performance in 4/8 tasks; in others, frequent short-horizon updates using immediate rewards are superior. This task dependency mirrors the temporal alignment between local reward signals and ultimate task objectives. Notably, generative optimization achieves competitive sample efficiency against deep RL baselines, even with lower computational resource consumption.
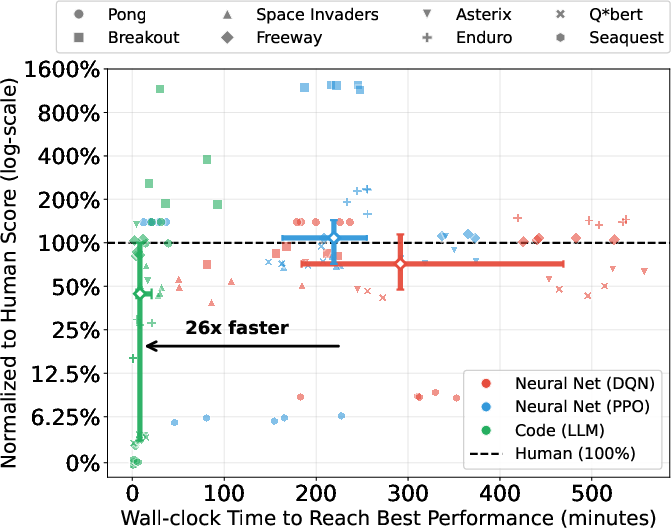
Figure 5: Training efficiency for generative optimization versus Deep RL baselines.
Experience Batching: Trade-offs in Generalization and Learning Efficiency
Batching execution traces into learning contexts governs the optimizer's exposure to task diversity and impacts generalization, reminiscent of batch size effects in SGD. On BigBench Extra Hard (BBEH), varying batch sizes (1, 3, 5) in prompt tuning and postprocessing optimization exhibit non-monotonic effects on generalization.
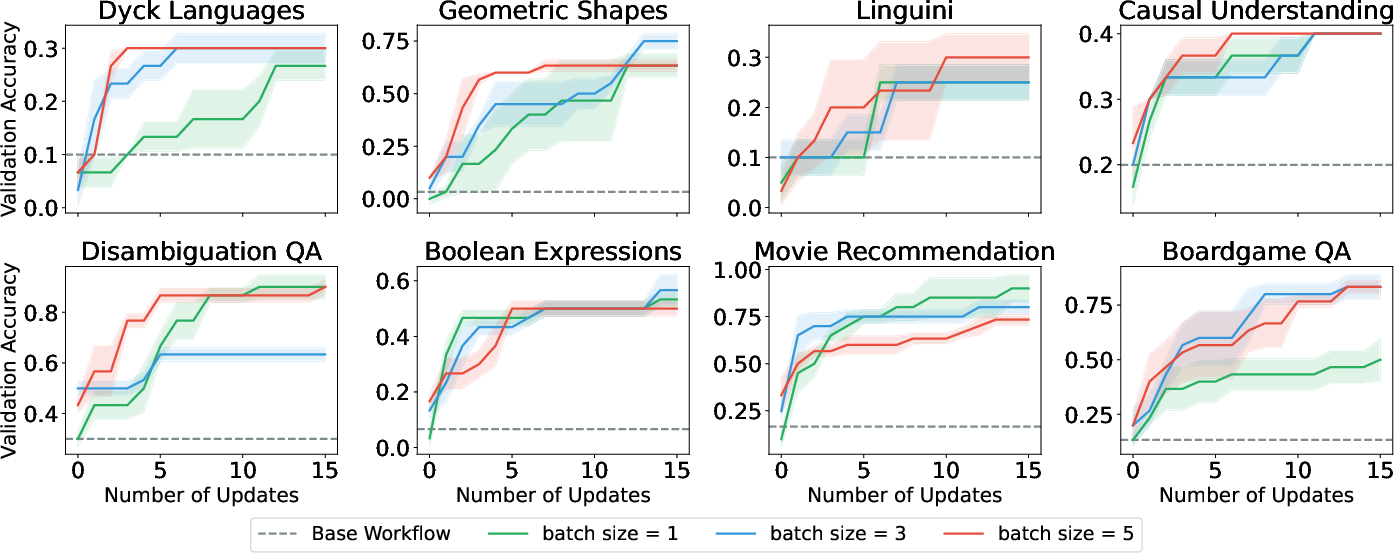
Figure 6: Validation performance dynamics as a function of batch size.
No single batch size dominates across tasks. Larger batches facilitate rapid initial learning (smoother, less noisy feedback aggregation) but tend to plateau or even degrade generalization. The optimal batch size is highly task-dependent, further complicating universal prescription.
The paper offers a formalization using the OPTO framework: an iterative process parameterized by (Θ,ω,T), where Θ denotes the editable artifact, ω encodes the problem context, and T specifies the trace oracle defining executions and feedback. Learning templates (interactive, batch, episodic) dictate aggregation of workflow graphs into optimizer-facing learning contexts, thus operationalizing the three critical design decisions.
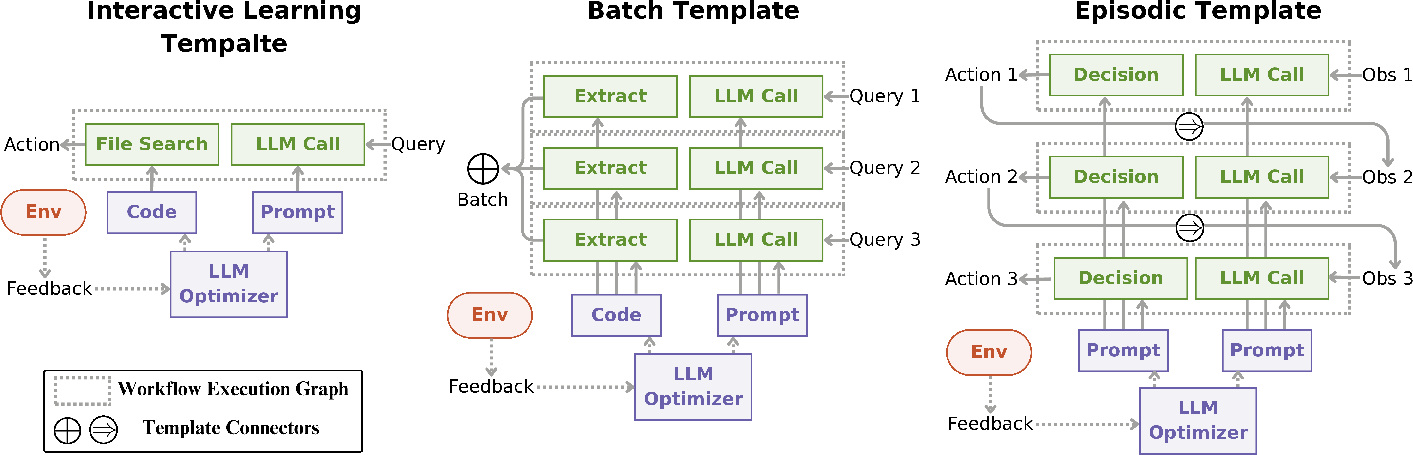
Figure 7: Workflow and learning graph templates for batch and episodic learning in agentic systems.
Agentic System Abstraction and Practical Examples
The learning loop abstraction is valid across a broad range of agentic systems, including prompt tuning, tool-assisted LLMs, and end-to-end ML pipelines. Figure 8 illustrates diverse instantiations, highlighting the universality of the conceptual framework.

Figure 8: Representative applications of generative optimization: search + LLM, retrieval-augmented prompting, and full ML pipeline.
Infinite nesting of optimizer hierarchies (Figure 9) is theoretically possible but disregarded in favor of finite, commonly used architectures in practice.

Figure 9: Illustration of recursive agentic optimization and its theoretical infinite regress.
Implications and Future Directions
The results make several strong claims:
- No universal recipe exists for learning loop setup; optimal configurations for artifact modularity, credit horizon, and experience batching are task dependent and require explicit consideration.
- Productionization faces practical obstacles: Engineering effort and manual trial-and-error dominate, unless default heuristics can be discovered.
- Meta-overfitting is a risk: Optimizer-induced artifacts may overfit validation splits, degrading generalization—a phenomenon parallel to conventional overfitting but at the workflow/code level.
Theoretically, the parallels with neural architectures, RL credit assignment, and batch optimization suggest that systematic exploration can yield robust defaults and inductive biases (analogous to Transformer or Adam in deep learning). Task-dependent configuration is, however, currently required.
Practically, the findings warn agent engineers against one-size-fits-all design, and validate meta-optimization strategies—hyperparameter search, task-specific heuristics, automated feedback shaping—for effective deployment.
Conclusion
Through methodical case studies and formal analysis, the paper elucidates why iterative generative optimization with LLMs is brittle and rarely productionized. The three critical, often implicit, learning loop design decisions—starting artifact, credit horizon, and experience batching—have profound effects on convergence and generalization, are not monotonic, and demand task-specific tailoring. The implications highlight the non-triviality of deploying self-improving agentic systems, suggest systematic study paralleling conventional ML, and call for research to define robust defaults facilitating broader adoption of generative optimization.