- The paper demonstrates that a 5M-parameter model, PP-OCRv5, can match billion-parameter VLMs in core OCR tasks by using optimally curated data.
- It employs a two-stage pipeline combining DBNet-based text detection with SVTR_LCNet recognition, leveraging data difficulty, accuracy, and diversity.
- Empirical results reveal over 11-point accuracy gains on structured text benchmarks and improved robustness to label noise.
Data-Centric Scaling Enables Ultra-Lightweight OCR: An Expert Essay on PP-OCRv5
Introduction
The dominance of large-scale multimodal models, particularly billion-parameter vision-LLMs (VLMs), has reshaped expectations for OCR systems. While VLMs show impressive generalist capability, their computational complexity, localization imprecision, and hallucination issues limit real-world deployment in core OCR tasks. "PP-OCRv5: A Specialized 5M-Parameter Model Rivaling Billion-Parameter Vision-LLMs on OCR Tasks" (2603.24373) presents an authoritative challenge to the assumption that high OCR accuracy necessitates large parameter counts. The paper articulates a comprehensive, data-centric framework for maximizing lightweight OCR recognition performance, culminating in a 5M-parameter model—PP-OCRv5—that achieves competitive results with contemporary VLMs.
Motivation and Problem Characterization
The trajectory of OCR research has paralleled the broader model-scaling trend, with architectures such as GPT-4V and Qwen-VL targeting end-to-end document understanding. However, the "generalist’s dilemma" persists: VLMs, by optimizing for breadth, often forgo the high-precision localization and reliability required for structured text extraction, and routinely hallucinate, especially under complex layouts or low-quality images. These limitations are compounded by prohibitive inference costs, hindering deployment in throughput- or resource-constrained environments.
Traditional lightweight, specialized OCR systems, particularly two-stage pipelines, offer greater deployment efficiency but have been perceived to hit a performance ceiling. Model-centric research, focusing on architectural innovation, has generated only incremental gains, largely ignoring the pivotal role of data curation. This work positions data—curated via attributes of difficulty, accuracy, and diversity—as the primary limiting factor of lightweight OCR capability, and proposes to systematically optimize for these dimensions.
System and Methodology
Lightweight Architecture
PP-OCRv5 follows a two-stage detection-recognition pipeline based on the PP-OCRv4 foundation. Text detection employs DBNet with a PP-LCNetV3 backbone and large-kernel PAN neck, while text recognition utilizes SVTR_LCNet with guided CTC and an attention-based decoder. This enables optimal efficiency and accuracy, maintaining the architecture within a compact 5M-parameter bound.
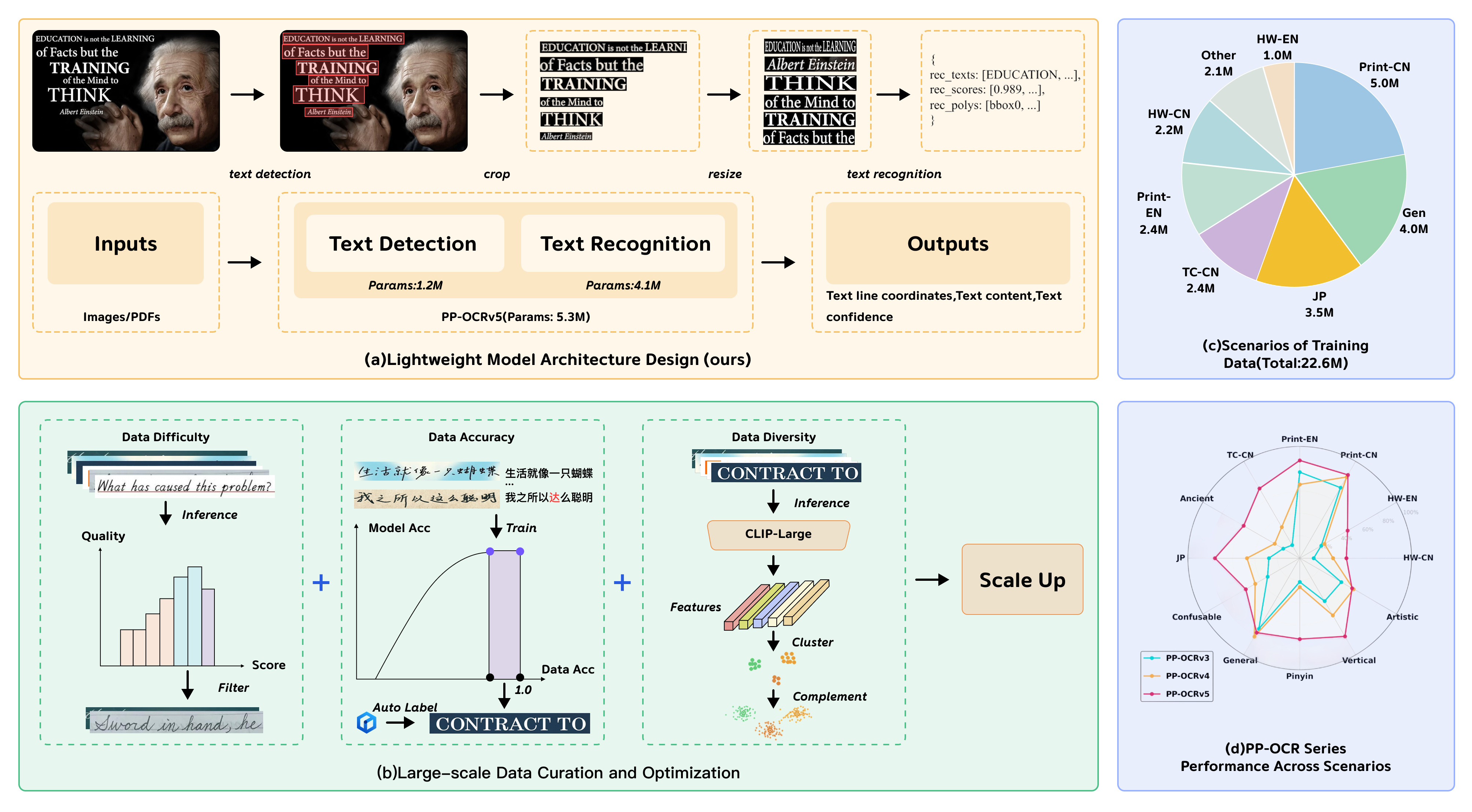
Figure 1: The PP-OCRv5 framework integrates a lightweight architecture and large-scale data optimization strategy, visualizing the diverse, high-quality dataset and series performance.
Data-Centric Scaling
The key contribution is a principled, empirical framework for large-scale OCR data optimization, centered on:
- Data Difficulty: Assigning sample-wise confidence scores using a bootstrap model to filter out noisy (low-confidence) and non-informative (high-confidence) examples; optimal performance derives from training on moderate-difficulty, correctly labeled data, identified as the "sweet spot".
- Data Accuracy: Systematic ablation using synthetic label noise demonstrates model robustness; even with 20% label noise, performance degradation remains minimal, justifying semi-automatic annotation at large scale.
- Data Diversity: Coverage of visual feature space is maximized via CLIP-based feature clustering and K-Means sampling, shown empirically to be essential for generalization—much more so than sheer data volume.
- Data Quantity: Scaling within a diverse, curated pool yields near-linear gains, compounding the effect of representational breadth.
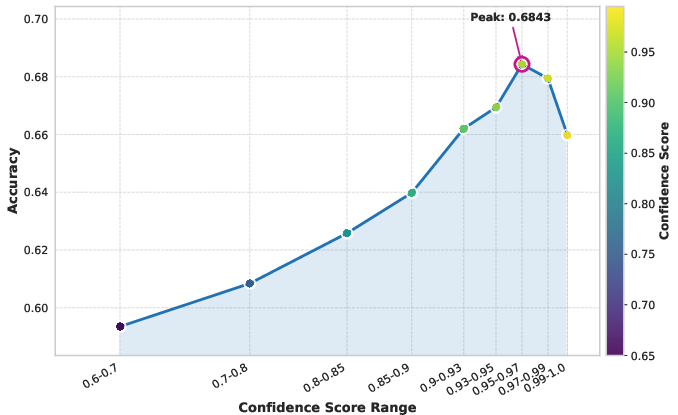
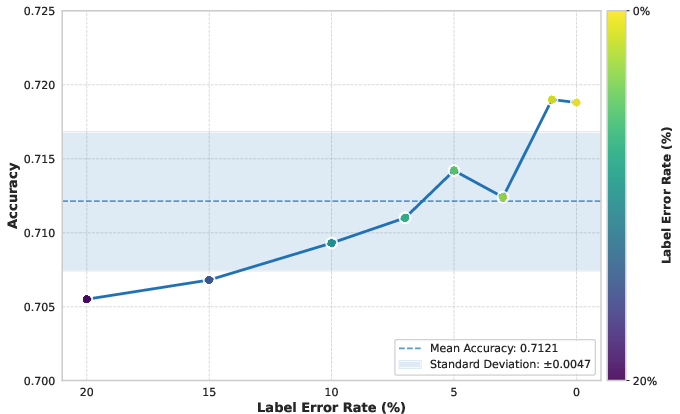
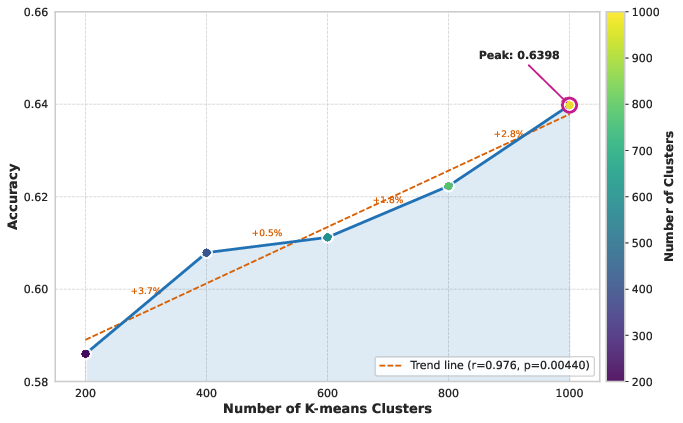
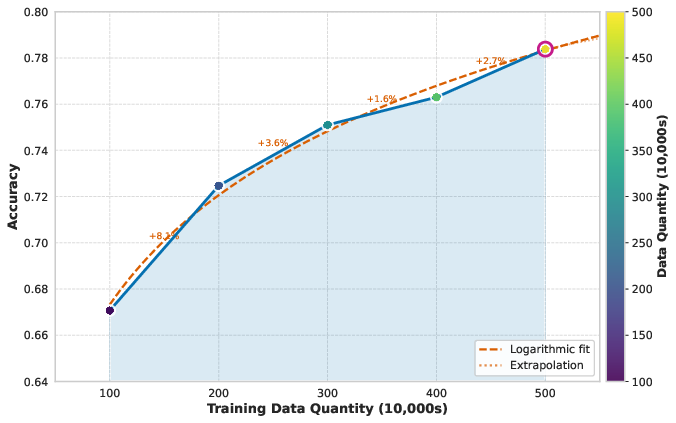
Figure 2: Data difficulty, accuracy, and diversity each exert quantifiable effects on recognition accuracy, guiding optimal dataset construction.
Experimental Analysis
Rigorous ablations validate every aspect of the data-centric framework. Training exclusively on "sweet spot" samples (0.95–0.97 confidence) provides peak accuracy, diminishing when data becomes too noisy or trivial. Noise tolerance experiments indicate that resilience to label corruption may be leveraged to reduce annotation costs via weakly supervised or semi-automatic methods.
Data diversity experiments, controlling for volume, demonstrate monotonic accuracy gains as visual feature cluster coverage expands, underscoring the primacy of diversity over raw volume. Finally, scaling curated datasets from 1M to 5M samples increases accuracy by over 11 points, demonstrating the synergistic effect of data quality and quantity.
Benchmark Results
PP-OCRv5 sets a new standard for lightweight OCR systems. On a comprehensive in-house benchmark spanning 12 categories, it achieves an 80.1% weighted accuracy, substantially outperforming PP-OCRv3 (42.5%) and PP-OCRv4 (53.0%). Gains are especially marked in handwritten, multilingual, and challenging text scenarios.
In public evaluation on OmniDocBench, PP-OCRv5 (5M params) rivals Qwen3-VL (235B params) and outperforms nearly all specialized and pipeline-based models on average normalized edit distance (0.067), with top-tier performance in languages, rotated text, and complex backgrounds.
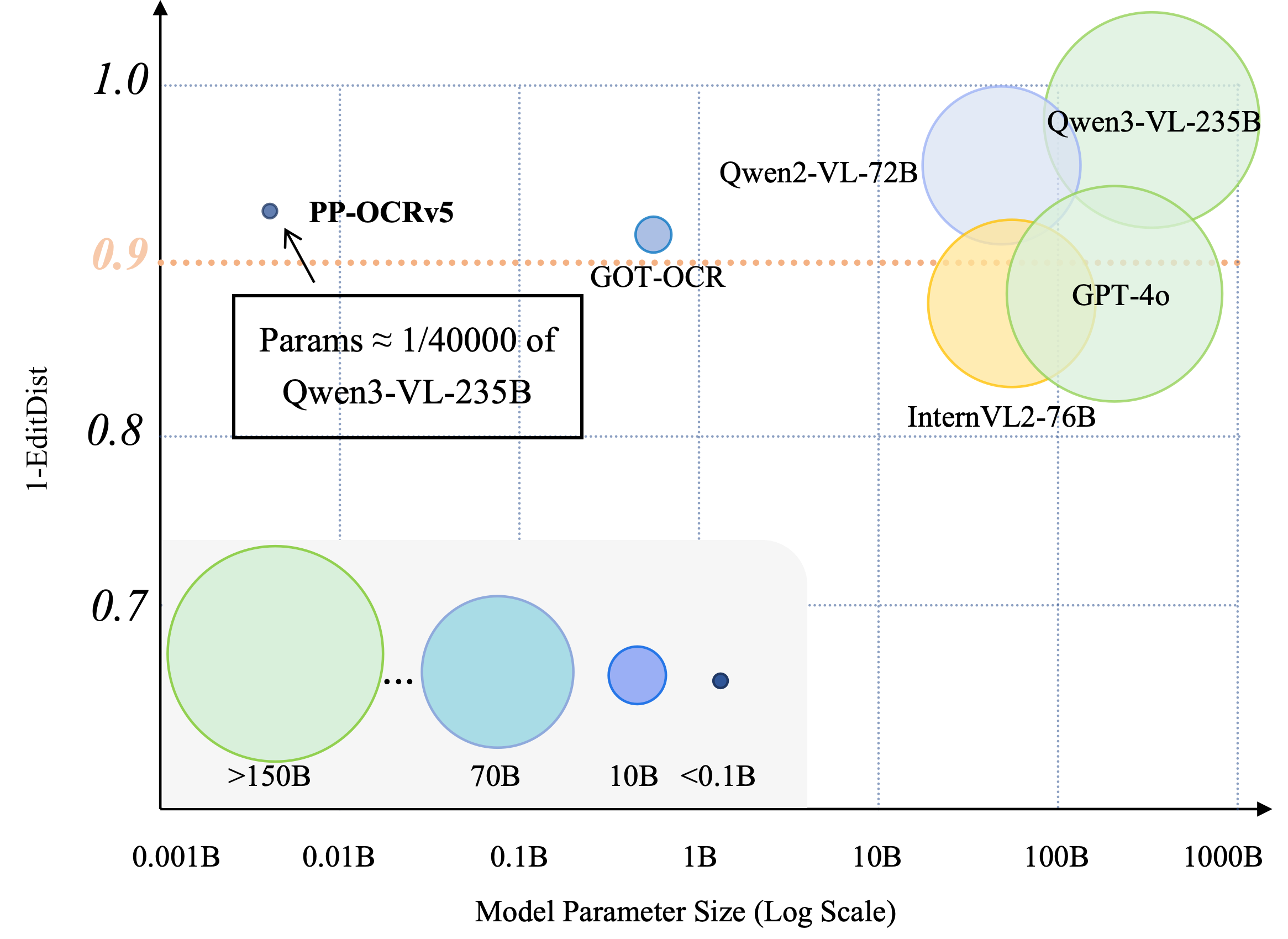
Figure 3: PP-OCRv5 achieves competitive accuracy with VLMs at a fraction of the parameter count, illustrating efficiency-accuracy trade-offs.
Key empirical claims substantiated in the paper:
- Lightweight (5M) specialized models, when fed optimally curated data, can match or exceed VLMs in core OCR tasks.
- Model robustness to label noise supports industrial-scale, semi-automatic dataset construction.
- Feature-space diversity, not raw data volume, determines the upper-bound of model generalization in OCR.
Practical and Theoretical Implications
From a practical perspective, this work defines deployment-ready pathways for high-throughput, edge- or cloud-based OCR with minimal resource overhead. The methodology for dataset construction and the demonstration of model scale irrelevance (within error-tolerant OCR tasks) is immediately applicable to real-world document digitization, archiving, and workflow automation.
Theoretically, the findings undermine the assumption that generalist models, by virtue of size or multimodal pretraining, are the inevitable future in OCR. Data-centric curation—especially targeting representational diversity and moderate difficulty—emerges as the lever for efficient, domain-specific model scaling. This paradigm is extensible beyond OCR, with implications for compact expert models across visual, textual, and multimodal domains.
Future Directions
Potential developments include:
- Automated, dynamic data-sampling policies that adaptively balance difficulty and diversity during training.
- Extension of the diversity-clustering framework to multi-modal or multi-task scenarios.
- Further exploration of model robustness under adversarial conditions given structured label noise.
- Integration of data-centric scaling strategies with small model distillation from VLMs, leveraging strong but label-imperfect supervision.
Conclusion
PP-OCRv5 sets a new benchmark for lightweight OCR, achieving performance comparable to VLMs through a scientifically rigorous, data-centric approach to training dataset construction. This research systematically discredits the prevailing emphasis on model scaling, refocusing field attention on data diversity and curation strategies. The methodologies and empirical insights presented offer replicable, domain-agnostic templates for building accurate, efficient specialized models—challenging fundamental assumptions about size, scale, and generalizability in industrial AI.

