LightOnOCR: A 1B End-to-End Multilingual Vision-Language Model for State-of-the-Art OCR
Abstract: We present \textbf{LightOnOCR-2-1B}, a 1B-parameter end-to-end multilingual vision--LLM that converts document images (e.g., PDFs) into clean, naturally ordered text without brittle OCR pipelines. Trained on a large-scale, high-quality distillation mix with strong coverage of scans, French documents, and scientific PDFs, LightOnOCR-2 achieves state-of-the-art results on OlmOCR-Bench while being 9$\times$ smaller and substantially faster than prior best-performing models. We further extend the output format to predict normalized bounding boxes for embedded images, introducing localization during pretraining via a resume strategy and refining it with RLVR using IoU-based rewards. Finally, we improve robustness with checkpoint averaging and task-arithmetic merging. We release model checkpoints under Apache 2.0, and publicly release the dataset and \textbf{LightOnOCR-bbox-bench} evaluation under their respective licenses.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
LightOnOCR-2: A simple explanation
What is this paper about?
The paper introduces LightOnOCR-2-1B, a smart computer model that reads text from documents (like PDFs or scanned pages) and turns it into clean, well-ordered text. Unlike older systems that use many separate steps, this model does everything in one go. It also learns to point out where images are on a page by predicting simple rectangles around them.
What questions are the researchers trying to answer?
The researchers focus on a few practical goals:
- Can a single, compact model read complex documents accurately without using a fragile, multi-step pipeline?
- Can it handle tricky layouts (like multi-column pages, tables, math, and scans) and multiple languages?
- Can the same model also find and mark where images appear on the page?
- Can it be both faster and smaller than existing, larger systems while matching or beating their accuracy?
How did they build and train the model?
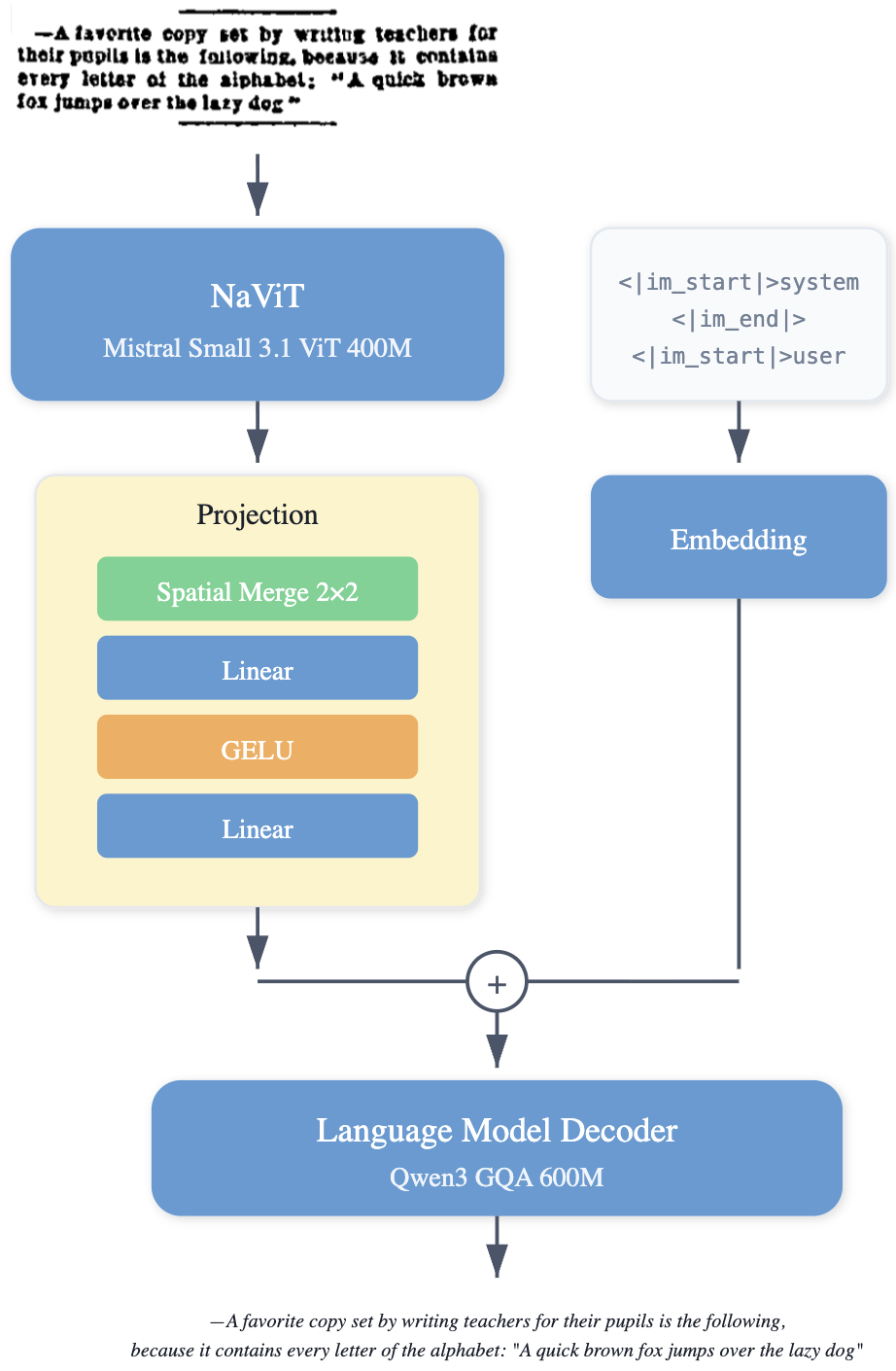
Think of a document page like a photo. The model first “looks” at the photo, then “speaks” the text it sees in the right order.
- The model’s parts:
- Vision encoder: Like the “eyes,” it understands the page image and its layout.
- Multimodal projector: A small “bridge” that connects what the eyes see to how the model writes.
- Language decoder: Like the “mouth,” it writes out the text and special tokens (for things like images) in a clean format.
- Training with “teacher-student” learning (distillation):
- A very large, accurate model (the “teacher”) first reads millions of document pages and produces high-quality text targets.
- LightOnOCR-2-1B (the “student”) learns to copy those high-quality outputs.
- The dataset is big (about 43 million pages) and covers scans, scientific PDFs, and French/European languages. Pages are rendered at high resolution so small text and math are clear.
- Cleaning the training data:
- The team normalized the text: they removed weird artifacts (like random code fences, watermarks, or inconsistent formatting) and standardized math (), tables, and headers so the model learns a consistent style.
- They also included some fully blank pages so the model learns not to “hallucinate” text when there’s nothing to read.
- Better supervision for scientific PDFs:
- They used a tool called nvpdftex to compile TeX sources into pixel-aligned page images and perfectly matched text and boxes. This avoids layout mismatches and gives very precise training signals.
- Fixing stubborn mistakes with RLVR:
- RLVR (Reinforcement Learning with Verifiable Rewards) is like running automatic “unit tests” on the model’s outputs. If the model passes the tests (for example, math renders correctly, no repeated loops, good formatting), it gets rewarded.
- This directly targets common failure modes that normal training doesn’t fix well.
- Teaching the model to find images:
- The model already outputs an “image placeholder” token when it sees an image.
- They extend the output to include a bounding box, written as normalized coordinates
x1,y1,x2,y2(like saying “top-left and bottom-right corners,” scaled to 0–1000). - They refine image location quality using RLVR with an IoU reward. IoU (“Intersection over Union”) measures how much the predicted box overlaps the correct box—think of two stickers on the same spot: if they perfectly overlap, IoU is 1.0; if not, it’s lower.
- Lightweight model combination tricks:
- Checkpoint averaging (“souping”): blending the last few saved versions of the model to get a more stable, better-performing model—like averaging several photos to remove blur.
- Task arithmetic merging: mixing weights from different specialized runs to balance OCR quality and image-box accuracy without retraining.
What did they find?
- State-of-the-art accuracy with a small model:
- On OlmOCR-Bench (a respected OCR test), LightOnOCR-2-1B achieves the best overall score (about 83.2), beating larger models (8–9B parameters) while only using 1B parameters.
- It performs especially well on scientific PDFs, old math scans, and table-heavy pages—areas that are usually tough.
- Image localization works well:
- On the new LightOnOCR-bbox-bench, the image-box variant matches or beats a larger 9B baseline in detecting and counting figures, with similar box precision (IoU).
- It’s fast:
- Throughput on a single H100 GPU is about 5.71 pages per second, much faster than larger end-to-end baselines (e.g., 3.28 and 1.70 pages/sec for 8B and 9B models).
- Robustness improvements:
- RLVR noticeably reduces repetition loops and formatting mistakes, especially for math.
- Checkpoint averaging and merging provide practical ways to tune the balance between pure text accuracy and image-box accuracy.
Why are these results important?
- Simpler and cheaper: A single, end-to-end model is easier to deploy and maintain than a fragile pipeline with many parts. It also uses fewer compute resources.
- High quality: It reads complex real-world documents—columns, tables, equations—accurately and in the right order.
- Practical features: It doesn’t just read text; it also finds images and marks where they are, which is useful for building clean, structured datasets from PDFs.
- Open releases: The team released model checkpoints, datasets, and a new image-localization benchmark, which helps the community reproduce and build upon their work.
What does this mean for the future?
- Better access to information: More documents (including scientific papers) can be turned into clean, machine-readable text, helping search, analysis, and learning.
- Easier adaptation: Because it’s end-to-end and trainable, organizations can fine-tune it for their own types of documents without rebuilding complex pipelines.
- Areas to improve: The model is strongest on printed, Latin-script documents. Handwriting and non-Latin scripts (like Chinese or Arabic) need more targeted data and work.
- Next steps: Expanding language coverage, improving handwriting recognition, and refining layout understanding could make document AI even more capable and inclusive.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list identifies what remains missing, uncertain, or unexplored in the paper, framed to be concrete and actionable for future research:
- Multilingual coverage beyond Latin scripts: quantify per-script performance (e.g., CJK, Arabic, Indic), diagnose tokenizer inefficiencies (token count inflation), and develop script-aware tokenization, data curation, and training to close gaps.
- Handwriting OCR: evaluate on standard handwriting benchmarks (e.g., IAM, Bentham, FUNSD forms with handwriting), characterize failure modes (cursive, mixed print), and investigate supervision strategies for robust handwriting recognition.
- Reading-order fidelity: establish metrics and ground truth for reading-order consistency (especially in multi-column and complex layouts), and create or adopt a benchmark that directly evaluates reading order rather than proxy tasks.
- Table structure accuracy: measure structural fidelity using strict metrics (e.g., TEDS, cell-level F1) against ground-truth table annotations, and ablate the effects of HTML table standardization on downstream usability.
- Figure–caption association: extend bounding-box detection to evaluate linking figures to their captions (precision/recall of correct associations and reading-order placement), not just detection/localization.
- Multi-class localization: generalize bbox prediction beyond images to include tables, formulas, headers/footers, and other semantic regions; evaluate detection and classification jointly (mAP/AP across classes).
- Text embedded in figures: test and improve extraction of text within images (charts, diagrams, scanned figures) beyond placeholder detection; quantify OCR accuracy inside visual regions.
- Benchmark scale and diversity: expand LightOnOCR-bbox-bench (currently 290 manual + 565 automatic pages) with more domains, languages, and layouts; establish cross-benchmark comparability and annotation quality audits.
- Teacher-distillation bias: quantify how teacher errors propagate to the student (category-wise error rates, math fidelity, formatting artifacts), and assess mixed-teacher or human-verified subsets to reduce bias.
- nvpdftex supervision usage: evaluate the impact of fully integrating nvpdftex-derived pixel-aligned annotations into pretraining (not only RLVR) on both OCR and localization, and compare to PDF parsing–based pipelines.
- RLVR generalization and ablation: perform component-wise reward ablations (loop penalties, KaTeX rendering checks, formatting rules, IoU rewards), measure generalization to real-world pages (not synthetic unit tests), and monitor overfitting risks to reward checks.
- Joint multi-objective RL: study training regimes that optimize OCR and bbox rewards simultaneously (rather than post-hoc merging), characterize trade-offs, and propose principled multi-objective scheduling or Pareto-front selection.
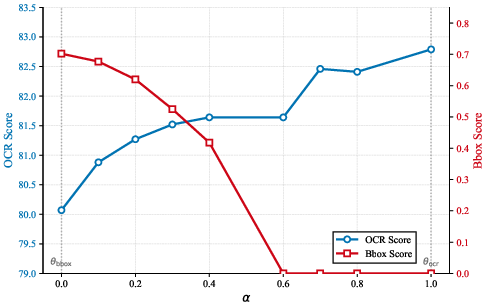
- Merging and averaging methodology: analyze reproducibility and stability of checkpoint averaging and task-arithmetic merging (choice of α, sensitivity to run-to-run variance), and compare to alternative weight-space methods (e.g., SWA, low-rank merging).
- Long documents and cross-page coherence: investigate multi-page processing (linking references across pages, consistent headers/footers, continued tables) and define evaluation protocols for document-level fidelity.
- Math fidelity beyond renderability: move beyond KaTeX render checks to evaluate semantic equivalence (symbols, ordering, numeric values, environments), canonicalization consistency, and robustness to custom macros/newcommands.
- Orientation and distortion robustness: systematically evaluate robustness to rotations (90°, 180°), skew, blur, compression, and background artifacts; compare no-heuristic inference to test-time augmentation (TTA) strategies.
- Resolution and spatial merging choices: ablate longest-edge resolution, patch size, and 2×2 spatial merging factor to quantify effects on small-text legibility, math density, and throughput; consider adaptive merging for dense regions.
- Efficiency on commodity hardware: report latency/throughput, memory footprint, and cost per page on non-H100 hardware (A10, L4, consumer GPUs, CPU), and evaluate INT8/FP8 quantization and sparsity for deployment.
- Confidence and error detection: design uncertainty estimates or self-verification to flag low-fidelity outputs (loops, missing content, mislocalized boxes), enabling selective human-in-the-loop correction.
- Dataset bias and privacy: characterize domain/language biases in the training mix, establish privacy and watermark detection checks, and explore de-dup strategies’ impact on learning rare formats and edge cases.
- Vocabulary pruning on v2: extend vocabulary pruning evaluation to LightOnOCR-2, quantify effects across languages/scripts, and explore script-aware or dynamic tokenization to avoid non-Latin degradation.
- Promptless decoding vs. controllability: study prompt-based control for task-specific outputs (subset extraction, JSON schemas, infilling), and compare to promptless decoding in terms of reliability and user configurability.
- Structured extraction beyond transcription: evaluate and train for key-value extraction, form understanding, table-to-CSV conversion, and document normalization against structured ground truth (e.g., FUNSD, SROIE, DocLayNet).
- Detection metrics choices: report bbox performance across IoU thresholds (AP@[.5:.95], mean AP), and study sensitivity to coordinate normalization (0–1000) and rounding under different page resolutions.
- Inference strategy sensitivity: quantify effects of decoding parameters (temperature, top-p/k), repeats, and retries/rotations on accuracy and stability; propose deterministic modes for production use.
- Component-level ablations: isolate contributions of the vision encoder initialization, projector design, and decoder choice (Qwen3), and compare to cross-attention–based fusion or alternative architectures.
- Headers/footers benchmark alignment: propose a community-aligned metric that rewards full-page fidelity (including headers/footers) and demonstrate how different objectives impact comparative rankings.
Glossary
- AdamW: An optimizer that decouples weight decay from gradient updates, often improving training stability and generalization. "Optimization uses AdamW with no weight decay, a peak learning rate of , a cosine learning rate schedule with a 100-step warmup"
- affine shears: Geometric transformations that slant images along an axis, used for data augmentation. "small affine shears"
- bf16: Brain floating point 16-bit format that speeds up training while maintaining numerical stability. "using bf16 precision"
- bbox: Shorthand for bounding box; a rectangular region specifying an object’s location in an image. "bbox accuracy across released checkpoints."
- bounding boxes: Rectangular annotations used to localize objects (e.g., figures) within an image or page. "predict normalized bounding boxes for embedded images"
- checkpoint averaging: Combining parameters from multiple recent checkpoints to improve robustness and performance. "We use checkpoint averaging by souping the last $5$ checkpoints"
- cosine learning rate schedule: A schedule that reduces the learning rate following a cosine curve, often with warmup. "a cosine learning rate schedule with a 100-step warmup"
- count accuracy: Metric that checks whether the predicted number of objects matches the ground truth exactly. "and count accuracy (exact match on the number of predicted boxes)"
- CRNN: Convolutional Recurrent Neural Network architecture for sequence recognition, commonly used in OCR. "deep neural sequence recognizers like CRNN~\cite{shi2015crnn}"
- data augmentation: Techniques that modify training data to improve model robustness and generalization. "apply data augmentation"
- DDP: Distributed Data Parallel; a multi-GPU training strategy that synchronizes gradients across devices. "Training is distributed with DDP over $96$ NVIDIA H100 GPUs (80\,GB)"
- distillation: Training a smaller “student” model using outputs from a larger “teacher” model to transfer knowledge. "built primarily through distillation: a strong vision--language teacher produces naturally ordered transcriptions (Markdown with \LaTeX{} spans) from rendered PDF pages."
- DPI: Dots per inch; a measure of image resolution relevant for rendering document pages. "Document pages are rendered at 200\,DPI during training"
- end-to-end: A single model that learns the full task directly from inputs to outputs without modular pipelines. "a 1B-parameter end-to-end multilingual vision--LLM"
- erosion/dilation: Morphological image operations used in augmentation to simulate noise or scanning artifacts. "erosion/dilation"
- [email protected]: F1 score computed at an IoU threshold of 0.5, balancing precision and recall for detection tasks. "We report at IoU threshold 0.5, mean IoU, and count accuracy"
- FlashAttention-2: An efficient attention algorithm that improves speed and memory usage in Transformer models. "using bf16 precision and FlashAttention-2~\cite{dao2023flashattention2fasterattentionbetter}"
- GELU: Gaussian Error Linear Unit; an activation function that often outperforms ReLU in Transformers. "a two-layer MLP with GELU activation"
- GRPO: A reinforcement learning algorithm variant used for post-training LLMs. "train with GRPO~\cite{shao2024deepseekmath} for one epoch"
- grid distortions: Non-linear warps applied to images during augmentation to improve robustness. "mild grid distortions"
- group-scaled rewards: RL technique that scales rewards within sampled groups to stabilize training signals. "We use group-scaled rewards with token-level importance sampling"
- IoU: Intersection over Union; overlap metric between predicted and ground-truth boxes. "IoU threshold 0.5"
- IoU-based rewards: RL rewards derived from IoU, directly optimizing localization accuracy. "RLVR using IoU-based rewards."
- KaTeX: A fast math typesetting library used to validate and render LaTeX expressions. "KaTeX~\cite{katex} compatibility"
- KL regularization: Kullback–Leibler penalty that keeps the learned policy close to a reference policy in RL. "KL regularization strength "
- LLM decoder: The autoregressive text-generation component that produces the structured transcription. "LLM Decoder"
- layout analysis: Detecting and categorizing regions (e.g., text, tables) in documents prior to recognition. "layout analysis, text detection, text recognition, table extraction, and reading-order reconstruction"
- linearized representation: A serialization of structured page content into a single text sequence preserving reading order. "a single, linearized representation of the page"
- MLP: Multi-Layer Perceptron; a stack of fully connected layers used here as a projector between modalities. "a two-layer MLP with GELU activation"
- multimodal projector: Network that maps visual features into the language embedding space. "Multimodal Projector"
- normalization pipeline: Preprocessing that standardizes outputs across heterogeneous sources to reduce noise and entropy. "We therefore apply a unified normalization pipeline that maps all sources to a single, canonical target format"
- nvpdftex: NVIDIA’s toolchain hooking into pdfLaTeX to produce pixel-aligned OCR annotations from TeX sources. "nvpdftex, a recently released NVIDIA toolchain that hooks directly into the pdf\LaTeX{} engine"
- OCR: Optical Character Recognition; converting images of text into machine-readable text. "Despite decades of progress in Optical Character Recognition (OCR)"
- OlmOCR-Bench: A benchmark suite for evaluating document OCR and related capabilities. "We evaluate LightOnOCR-2-1B on OlmOCR-Bench~\cite{poznanski2025olmocr} as our primary OCR benchmark."
- pages/sec: Throughput metric measuring fully processed pages per second, more comparable than tokens/sec for OCR. "reporting pages/sec as the total number of pages divided by the wall-clock time to complete the benchmark."
- pretraining mixture: The curated multi-dataset corpus used during pretraining. "We scale the pretraining mixture from 17M to 43M pages"
- reading-order reconstruction: Rebuilding the logical reading sequence from complex page layouts. "reading-order reconstruction"
- Reinforcement Learning with Verifiable Rewards (RLVR): RL approach that uses deterministic, unit-test-like checks to score outputs. "We apply Reinforcement Learning with Verifiable Rewards~(RLVR)~\cite{Lambert2024TLU3P}"
- resume strategy: Continuing training from a prior checkpoint to introduce new supervision without degrading existing skills. "via a resume strategy"
- spatial merging: Reducing visual token count by grouping neighboring image patches while retaining spatial structure. "we apply spatial merging with a factor of 2"
- task-arithmetic merging: Weight-space combination of checkpoints using linear arithmetic to blend capabilities. "task-arithmetic merging"
- token-level importance sampling: Sampling method that reweights tokens to focus learning on more informative parts during RL. "token-level importance sampling"
- unit-test style checks: Automatic, deterministic validators that verify specific formatting or content properties. "unit-test style checks"
- vLLM: High-throughput inference engine for LLMs used to generate RL rollouts efficiently. "rollouts are generated with vLLM for increased efficiency."
- Vision Transformer: Transformer architecture applied to images by splitting them into patches. "We employ a native-resolution Vision Transformer"
- vision encoder: The model component that extracts visual features from input images. "Vision Encoder"
- Vision–LLM (VLM): Models that jointly process images and text for multimodal understanding or generation. "End-to-end vision-LLMs (VLMs) reduce this engineering burden"
- Vocabulary pruning: Reducing tokenizer vocabulary size to speed up inference at potential cost to multilingual coverage. "We investigate frequency-based vocabulary pruning"
Practical Applications
Practical Applications of LightOnOCR-2-1B
Below are actionable, sector-linked applications derived from the paper’s findings, methods, and innovations. Each item includes key assumptions or dependencies that affect feasibility.
Immediate Applications
These can be deployed now using the released Apache 2.0 checkpoints, datasets, and benchmark; they leverage the model’s end-to-end OCR, scientific/math fidelity, image bounding box prediction, and high throughput.
- PDF-to-structured-text ingestion for enterprise search and RAG
- Sector: software, enterprise IT
- Application: Replace brittle multi-stage pipelines with a single service that converts diverse PDFs (multi-column, tables, math) into Markdown/HTML with KaTeX math, ready for indexing (e.g., Elastic, OpenSearch) and retrieval-augmented generation.
- Emergent workflow: LightOnOCR-2 → normalized Markdown/HTML + KaTeX → document store + vector DB → enterprise QA.
- Assumptions/Dependencies: GPU-backed inference for throughput; downstream systems must support KaTeX; limited support for non-Latin scripts and handwriting.
- High-volume back-office document processing
- Sector: finance, insurance, logistics
- Application: Automate extraction from invoices, receipts, forms, bank statements; preserve reading order and tables without layout heuristics.
- Tools/Products: “OCR-microservice” API with batching and autoscaling (e.g., vLLM serving); CSV/table exports from standardized HTML tables.
- Assumptions/Dependencies: PII/PHI handling requires secure deployment; post-processing needed to convert standardized HTML tables to domain schemas.
- Scientific content extraction for publishers and repositories
- Sector: academia, publishing, education
- Application: Convert arXiv-like PDFs into machine-readable text and math; localize figures to enable linking, captions, and alt text.
- Workflow: LightOnOCR-2 → structured text + figure bbox → captioning/alt-text generation → web publication.
- Assumptions/Dependencies: Reliable KaTeX rendering; caption generation requires an auxiliary vision-language captioner; publishers with TeX sources can also use nvpdftex (below).
- Accessibility-enhanced PDF readers
- Sector: education, accessibility, daily life
- Application: Produce screen-reader-friendly outputs with correct reading order, math rendered via KaTeX, and figure regions for alt text insertion.
- Tools/Products: Reader plugins that replace raw PDF text with OCR-normalized content; automated alt text workflow seeded by bbox outputs.
- Assumptions/Dependencies: Integration with assistive tech; alt text requires additional captioning or human-in-the-loop review.
- Government records digitization and FOIA processing
- Sector: public sector, policy
- Application: Bulk digitize typed/scanned records (including rotated/noisy scans), preserving headers, footers, and page numbers for legal traceability.
- Workflow: Scan ingest → LightOnOCR-2 → normalized text + page metadata → eDiscovery/search platforms.
- Assumptions/Dependencies: Compliance (privacy, retention); limited performance on handwriting; language coverage strongest in European/Latin scripts.
- Image extraction and cataloging from PDFs
- Sector: media archives, IP/patent offices, research libraries
- Application: Use bounding box outputs to crop, count, and catalog embedded images/figures for downstream tagging and reuse.
- Tools/Products: “PDF figure miner” pipeline; automated figure count QA using model’s count accuracy.
- Assumptions/Dependencies: Coordinate normalization [0–1000] must be mapped back to original page pixels; downstream storage/tagging required.
- Library and archive digitization of legacy scientific documents
- Sector: cultural heritage, academia
- Application: Robust extraction from “old scans math” and multi-column layouts for preservation and search.
- Workflow: Batch scanning → LightOnOCR-2 → text + HTML tables → digital repository indexes.
- Assumptions/Dependencies: Handwriting remains a limitation; page images must be of adequate resolution.
- Standardized document AI evaluation and model iteration
- Sector: academia, ML platforms, applied research
- Application: Adopt LightOnOCR-bbox-bench to measure image localization; use RLVR unit-test style checks to reduce repetition loops and formatting failures.
- Tools/Products: Continuous evaluation pipelines with deterministic verifiable rewards; GRPO training to specialize formats.
- Assumptions/Dependencies: RLVR requires domain-specific “unit tests” (deterministic checkers) and controlled rollout infrastructure.
- Publisher TeX-to-pixel-aligned annotation via nvpdftex
- Sector: academic publishing
- Application: Generate high-quality, pixel-aligned training/evaluation sets directly from TeX sources (rendered page PNGs, semantic bboxes, region text).
- Tools/Products: nvpdftex pipeline to produce supervision for OCR and localization; automatic figure subset creation.
- Assumptions/Dependencies: Access to TeX sources; nvpdftex tooling; not applicable to PDFs without source TeX.
- Domain-specific OCR formatting compliance using RLVR
- Sector: software, regulated industries
- Application: Enforce formatting invariants (e.g., math cleanup, EOS termination, presence of headers/footers) via verifiable rewards—without labeling new datasets.
- Tools/Products: RLVR recipes tailored to organizational templates; checkpoint averaging/task arithmetic merging to trade off text vs bbox performance.
- Assumptions/Dependencies: Engineering capability to author deterministic checks; careful KL regularization to avoid regressions.
Long-Term Applications
These require additional research, data, scaling, or engineering (e.g., expanded language coverage, handwriting, edge deployment, richer layout semantics).
- Global multilingual expansion beyond Latin scripts
- Sector: public sector, global enterprises
- Application: Robust OCR for CJK, Arabic, RTL scripts with efficient tokenization and high fidelity.
- Dependencies: Expanded training data and tokenizer vocab; normalization updates; potential model size/training recipe tuning.
- Handwriting-capable OCR for clinical and operational workflows
- Sector: healthcare, postal services, logistics
- Application: Accurate transcription of handwritten notes, forms, prescriptions.
- Dependencies: Targeted handwriting datasets; architectural adjustments; domain-specific RLVR checks; strict privacy/security constraints.
- Richer document layout semantics and interactive structure
- Sector: software, robotics, forms processing
- Application: Extend bbox prediction to tables, formulas, headers, footers, and form fields with fine-grained structure (e.g., table cells, key-value pairs).
- Tools/Products: “Layout-aware” OCR APIs producing semantic JSON; interactive PDF viewers with selectable regions.
- Dependencies: Additional annotations; new unit tests/rewards; more complex output formats and post-processing.
- Automated compliance/audit pipelines over massive corpora
- Sector: finance, legal, policy
- Application: Detect required disclosures, regulatory phrases, and formatting compliance across hundreds of thousands of documents.
- Tools/Products: RLVR-enforced formatting and content checks; dashboards for exception handling.
- Dependencies: High-precision checkers; domain lexicons; human oversight; strong data governance.
- Edge/mobile OCR for field operations
- Sector: logistics, field services, daily life
- Application: On-device processing of forms and receipts without cloud dependency.
- Tools/Products: Quantized/distilled variants (e.g., 4–8-bit), pruned vocabularies; energy-efficient inference on mobile NPUs.
- Dependencies: Compression/distillation research; performance tuning; trade-offs in accuracy vs footprint.
- End-to-end accessibility pipelines with automated captions
- Sector: education, public sector, publishing
- Application: Combine figure bbox detection with captioning models to auto-generate alt text and accessible summaries for PDFs.
- Tools/Products: Accessibility pipeline integrating OCR + vision captioning + human validation.
- Dependencies: Captioning model integration; bias/quality controls; compliance with accessibility standards (e.g., WCAG).
- Scientific knowledge graph extraction with math-aware linking
- Sector: academia, research analytics
- Application: Convert PDFs to structured entities (methods, formulas, results), linking across papers; preserve math semantics.
- Tools/Products: OCR → NER/relation extraction → KG builders; math canonicalization with KaTeX/LaTeX spans.
- Dependencies: Advanced IE models; consistent math normalization; curation and evaluation frameworks.
- Autonomous document handling in physical workflows
- Sector: robotics, mailrooms, digitization centers
- Application: Integrated scanning, orientation correction, segmentation, and OCR with layout-aware feedback.
- Tools/Products: Vision systems controlling feeders/scanners; RLVR-based quality gates; human-in-the-loop for edge cases.
- Dependencies: Hardware integration; additional perception tasks (cropping/orientation); expanded unit tests for physical variability.
- Legal eDiscovery with math/figure-aware summarization
- Sector: legal services
- Application: OCR outputs feeding LLM summarizers that respect tables, equations, and figures.
- Tools/Products: End-to-end pipelines with formatting-preserving summarization; cross-document linking.
- Dependencies: Summarization tuned for structured inputs; confidentiality and access controls; auditability.
- Document authenticity and watermark/forgery analysis
- Sector: security, compliance
- Application: Use consistently normalized outputs to detect anomalous formatting/watermarks indicative of manipulation.
- Dependencies: Research on robust watermark detection across scans; ground-truth labeling; integration with security tooling.
In all cases, deployment benefits from the model’s high throughput (e.g., 5.71 pages/sec on a single H100), open licensing, and end-to-end simplicity. Feasibility hinges on domain-specific constraints (privacy, regulatory compliance), language/script coverage, and the ability to integrate verifiable reward checks for robust formatting and content fidelity.
Collections
Sign up for free to add this paper to one or more collections.