GutenOCR: A Grounded Vision-Language Front-End for Documents
Abstract: GutenOCR is a family of grounded OCR front-ends obtained by fine-tuning Qwen2.5-VL-3B and Qwen2.5-VL-7B. The resulting single-checkpoint vision-LLMs expose reading, detection, and grounding through a unified, prompt-based interface. Trained on business documents, scientific articles, and synthetic grounding data, the models support full-page and localized reading with line- and paragraph-level bounding boxes and conditional ``where is x?'' queries. We introduce a grounded OCR evaluation protocol and show that GutenOCR-7B more than doubles the composite grounded OCR score of its Qwen2.5-VL-7B backbone on 10.5K held-out business and scientific pages (0.40 to 0.82). On Fox and OmniDocBench v1.5, our approach substantially improves region- and line-level OCR as well as text-detection recall, but reveals trade-offs in page-level linearization, color-guided OCR, and formula-heavy layouts.













Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces GutenOCR, a new kind of computer system that “reads” text from document images. It’s designed to act like a smart, reliable front door for documents: it can read all the text on a page, find where the text is located, and let you ask questions like “Where does this word appear?” or “What’s written inside this box?” The key idea is “grounded OCR,” which means the system not only reads the words but also shows exactly where those words are on the page (using bounding boxes). This makes the output easier to trust, check, and use in larger workflows.
What questions were the researchers asking?
The paper focuses on a few simple questions:
- Can a modern vision–LLM (a system that looks at images and understands text) be trained to behave like a traditional OCR tool, but with better flexibility and control?
- Can one single model handle multiple OCR-style tasks (like “read the whole page,” “detect where text is,” “read just inside this box,” or “find where a phrase appears”) using only different prompts?
- Does this approach improve reading accuracy and the ability to correctly locate text compared to standard models?
- What are the strengths and weaknesses of this model on real business and science documents, and on public benchmarks?
How did they do it?
The researchers started with powerful vision–LLMs called Qwen2.5-VL (with 3B and 7B parameters—think of these as model sizes). They fine-tuned (taught) these models to become grounded OCR front-ends. Here’s how:
- Unified interface by prompts:
- Instead of building separate tools for reading and detection, they used one model that switches behavior based on how you ask it (the “prompt”). For example:
- “Read all text” returns a full page transcript.
- “Detect all lines” returns boxes around text lines.
- “Where is ‘Total Due’?” returns boxes where that phrase appears.
- “Read inside [x1,y1,x2,y2]” returns only the text inside a given rectangle (a bounding box).
- This keeps the system simple: one model, different prompts, different outputs.
- Grounding with bounding boxes:
- When the model reads text, it can also attach coordinates (a rectangle on the page) to show where each line or paragraph lives. That’s the “grounded” part.
- Training data:
- Real documents: business forms, invoices, IDs (noisy scans), and scientific articles (long, multi-column pages with equations).
- Synthetic (made-up but realistic) pages: artificial layouts to teach the model how to align text and detect lines, and pages with equations placed at random positions to teach math localization.
- This mixture helps the model learn both real-world messiness and precise geometry.
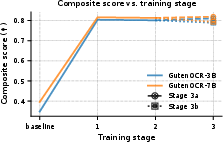
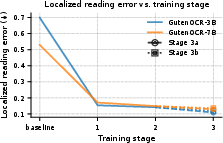
- Gradual curriculum:
- They trained the model in stages, starting with shorter outputs and simpler data, then moving to longer, more complex pages (up to very long transcripts).
- Metrics (how they judged performance):
- CER and WER: measure how many characters or words the model gets wrong when reading.
- F1 and Recall: measure how well the model finds text boxes (Are the predicted boxes correct and complete?).
- End-to-end measures: test both reading and layout order together, to see if the final page text matches the reference in both content and structure.
What did they find?
- Big gains in grounded OCR:
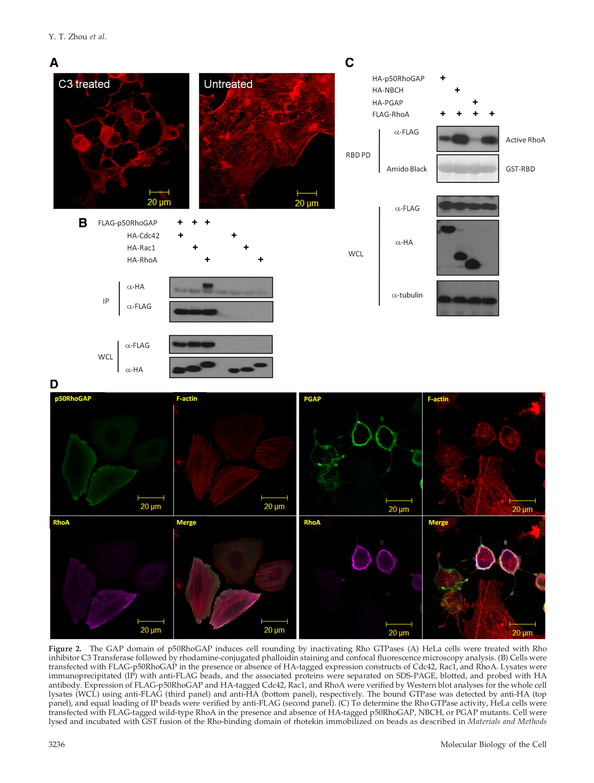
- The 7B model (GutenOCR-7B) more than doubled its overall “grounded OCR” score compared to its original backbone (from about 0.40 to 0.82) on 10,500 held-out pages from business and scientific sources.
- It got much better at localized reading (reading inside a given box) and detecting lines/paragraphs.
- Strong region and line reading on public benchmarks:
- On the Fox benchmark:
- GutenOCR greatly improved region-level and line-level OCR (reading a specific part or a single line) compared to standard models.
- But it traded off some page-level “linearization” (the specific order Fox expects text to be streamed) and did poorly on “color-guided OCR” (when you’re told to read text inside a box marked by a color). In other words, it reads content well but doesn’t always match Fox’s preferred reading order, and it didn’t learn color-based instructions.
- On OmniDocBench v1.5:
- GutenOCR raised text-detection recall massively (finding many more true text regions).
- However, it slightly worsened reading of formula-heavy content and struggled more with colorful backgrounds compared to the base models.
- Unified behavior with one model:
- One model successfully handles reading, detection, “where is X?”, and local reading—all controlled by prompts. This is simpler to use in real workflows than juggling multiple specialized tools.
Why does this matter?
- More trustworthy and controllable OCR:
- Grounding links each piece of text to its exact place on the page. That makes it easier for humans (or downstream apps) to spot mistakes like missing text, hallucinated text, or wrong reading order.
- It supports human-in-the-loop verification (people can quickly check boxes and text) and improves active learning (models learn faster from corrections).
- Flexible front-end for business and research:
- Many systems (like document processing, search, and retrieval-augmented generation) depend on clean, accurate text. If the OCR front-end misses something, those systems can’t see it. GutenOCR’s “find and read” abilities reduce that risk.
- Because it uses prompts and unified outputs (plain text, layout-sensitive text, or JSON with boxes), it can plug into various workflows without forcing everyone to adopt a single, rigid format.
- Open and reproducible:
- The authors release their models, code, and training recipe built on public data and open licenses. This helps others build on their work, test ideas, and adapt the approach to new domains.
In short, GutenOCR shows that a single, prompt-driven, grounded OCR model can be both practical and powerful: it reads and locates text well, gives users fine-grained control, and fits neatly into real document pipelines. While it has some blind spots (like color-guided OCR and complex formulas), its strengths in detection, local reading, and human-verifiable outputs make it a promising front-end for modern document understanding systems.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a single, consolidated list of gaps and open questions the paper leaves unresolved. Each item is phrased to be actionable for future research.
- Multilingual support is untested: all evaluations are restricted to English; assess performance and training recipes for multilingual documents (including RTL scripts and vertical text).
- Word-level grounding is not exposed: extend interfaces and metrics to produce and evaluate word-level boxes/token alignment in addition to line/paragraph outputs.
- Rotated/skewed text is approximated with axis-aligned boxes only: add rotated boxes or polygonal regions and measure gains on skewed, curved, and non-horizontal text.
- Fixed 72 DPI rasterization may limit small-font readability and long-page fidelity: study resolution scaling, tiling, or multi-scale inputs and quantify their impact on CER/F1.
- Color-guided OCR shows catastrophic forgetting: introduce color-conditioned pointer training (synthetic overlays, color-aware prompts) and evaluate recovery on Fox Color.
- Formula-heavy layouts remain a failure mode: expand math-specific data (complex LaTeX, inline/display math, handwritten equations), adopt math-normalization-aware loss, and measure CDM/CER improvements.
- Page-level linearization conflicts with benchmark expectations (Fox Page CER): define configurable reading-order policies (e.g., column-major, reference-Markdown) and quantify trade-offs across tasks.
- Domain generalization is weak for visually diverse pages (magazines, slides, multi-colored backgrounds): broaden training mixtures and measure per-domain robustness in OmniDocBench subsets.
- No explicit uncertainty or confidence scores are provided for text and boxes: add per-span confidence and calibration studies to support human-in-the-loop verification and active learning.
- Conditional detection is limited to exact string inclusion in normalized text: extend to fuzzy matching, regex, and semantic queries (e.g., “total due”) and benchmark precision/recall.
- Localized reading returns plain text without boxes, hindering verifiability: add optional box outputs for localized reads and test end-to-end CER with grounding.
- Table structures are not modeled or evaluated: incorporate table region detection and cell-level OCR, and benchmark on table-centric datasets.
- Benchmarks omit comparisons to classical OCR engines under the same protocol: add Tesseract/Textract/Cloud Vision baselines for grounded outputs to contextualize VLM gains.
- No inference efficiency or throughput analysis is reported: measure latency, memory footprint, and cost across 3B/7B checkpoints for production viability.
- Long-context decoding (8k–16k tokens) lacks performance–cost trade-off analysis: study truncation/streaming strategies and their effect on page fidelity and speed.
- JSON output robustness and parsing reliability are not characterized: evaluate failure rates, repair pipeline effectiveness, and adversarial prompt resilience for structured outputs.
- Handwriting, stamps, and camera-captured artifacts are under-characterized: create targeted test sets for noisy business forms and measure detection/reading robustness.
- Multi-page workflows are not addressed (cross-page linking, TOC/footnote handling): design and evaluate multi-page grounded reading interfaces and metrics.
- Coordinate systems assume a single rasterization reference frame: investigate DPI/zoom invariance and provide utilities to remap boxes across renderings/resolutions.
- Training-induced forgetting of base-model behaviors (e.g., color cues) is observed but not mitigated: test strategies like multi-objective training, elastic weight consolidation, or partial freezing.
- Evaluation uses IoU≥0.5 matching; sensitivity to IoU thresholds and small-box detection is unexplored: run threshold sweeps and size-stratified analyses to calibrate localization metrics.
- Privacy, bias, and license audits of training data mixtures are not discussed: assess PII exposure, domain biases, and compliance, and publish audit artifacts.
- Downstream impact on extraction/RAG quality is only argued, not measured: run controlled RAG/extraction tasks comparing grounded vs non-grounded front-ends and quantify gains.
- Robustness to adversarial or malformed prompts is anecdotal: perform systematic prompt perturbation studies (paraphrases, instruction conflicts) and report stability metrics.
Practical Applications
Immediate Applications
The following applications can be deployed today using the grounded, prompt-based OCR front-end, JSON outputs, and layout-sensitive text2d that GutenOCR already provides. Each item notes the sector, a specific workflow/tool that could emerge, and assumptions/dependencies affecting feasibility.
- Healthcare: digitize and audit clinical documents — Use case: Ingest scanned lab reports, referral letters, discharge summaries into EHR/RCM pipelines with verifiable text+box outputs. — Tools/workflows: “Grounded OCR API” that outputs lines/paragraphs with bounding boxes; a reviewer UI that highlights errors and missing coverage; localized reading to transcribe only protected regions. — Assumptions/dependencies: English-heavy pages perform best; axis-aligned boxes only (rotated/skewed text handled as enclosing boxes); color-guided pointers not reliable; privacy-compliant deployments and audit logging required.
- Finance: invoice, statement, and receipt processing — Use case: Accounts payable automation, bank-statement parsing, expense receipt ingestion with human-in-the-loop verification. — Tools/workflows: Layout-aware chunking (text2d) for accurate reading order; conditional detection (“Where is invoice number?”) to find fields; export JSON with coordinates for downstream extraction and audit trails. — Assumptions/dependencies: Domain alignment is strong (business forms/tables); long-context outputs may need memory-aware batching; no rotated box predictions.
- Insurance: claims and KYC document intake — Use case: Extract claimant info, policy numbers, and signatures from noisy scans, highlight errors for manual review. — Tools/workflows: Unified prompt schema per task (full-page reading, detection, localized reading); “targeted box” reading for high-risk fields; active-learning workflows based on grounded errors (missing boxes, hallucinated regions). — Assumptions/dependencies: Works best with axis-aligned text; adequate page image quality; governance for PII across environments.
- Legal: eDiscovery and contract analysis with source-grounding — Use case: Search and extract clauses while returning bounding boxes for immediate verification in PDFs. — Tools/workflows: “Grounded search” that uses conditional detection (“where is clause x?”); export line/paragraph boxes to link to citations; layout-aware text2d to preserve sectioning. — Assumptions/dependencies: Page-level linearization may differ from some legal markup conventions; reviewer UI needed to reconcile order differences.
- Public sector policy/admin: FOIA processing and public records digitization — Use case: Grounded OCR to accelerate intake, redaction, and publication of scanned records with verifiable provenance. — Tools/workflows: Redaction tools driven by detected boxes; completeness checks from box coverage; audit logs that tie extractions to pixel coordinates for compliance. — Assumptions/dependencies: Color-guided tasks weak (avoid color-based redaction prompts); standardization around JSON schemas and DPI settings needed.
- Software & RAG: source-grounded retrieval and answer verification — Use case: Build RAG systems that index document chunks with bounding boxes and return highlighted source spans. — Tools/workflows: “Layout-aware chunker” using text2d; index paragraphs/lines along with page and bbox metadata; UI overlays the exact region behind an answer; localized reading for post-retrieval verification. — Assumptions/dependencies: Long transcripts (8k–16k tokens) require memory-aware pipelines; page order may differ from canonical Markdown—use layout-aware linearization.
- Education: digitizing exam papers and textbooks for grading and search — Use case: Transcribe exam pages and find question numbers/answers via conditional detection; preserve layout for rubric alignment. — Tools/workflows: Prompt presets (“detect all LINES,” “read region [x1,y1,x2,y2]”); structured outputs per question/answer block; teacher review panels with error localization. — Assumptions/dependencies: Formula-heavy pages may underperform; color-coded tasks (e.g., colored annotations) are not robust.
- Libraries/archives: large-scale, human-verifiable OCR pipelines — Use case: Digitize heterogeneous collections with grounded outputs to reduce QC cost. — Tools/workflows: QC dashboards that visualize box coverage gaps and hallucinations; batch “localized reading” passes on problematic regions; export JSON for downstream cataloging. — Assumptions/dependencies: Diverse backgrounds (magazines/newspapers) can degrade recognition; consider domain-tuned prompts and post-processing.
- Compliance & audit: provable extraction with pixel-level traceability — Use case: Demonstrate which exact region was read to produce a value (e.g., tax ID), enabling auditability and dispute resolution. — Tools/workflows: Store extracted values with their bounding boxes and page hashes; replayable verification via localized reading; CER/Recall-based KPIs for process monitoring. — Assumptions/dependencies: Stable image references (DPI, page crops) are necessary to keep coordinates consistent; security controls for sensitive fields.
- Daily life: personal document search and receipt management — Use case: “Find where the warranty expiry date is” across scanned warranties; highlight the region in the app. — Tools/workflows: Lightweight mobile/desktop app integrating conditional detection and localized reading; export searchable metadata with coordinates. — Assumptions/dependencies: On-device inference may need smaller models or cloud fallback; rotated text captured only via enclosing axis-aligned boxes.
Long-Term Applications
These applications require further research, scaling, or development—especially around color guidance, formula-heavy layouts, rotated/skewed text, multilingual robustness, and standardized page-level linearization.
- STEM publishing and education: high-fidelity math/formula OCR — Use case: Accurate recognition of complex equations, Greek symbols, and layout-heavy mathematical content for publishers and digital classrooms. — Tools/workflows: Enhanced training with math datasets and CDM metrics; specialized decoding for LaTeX; formula-aware localized reading. — Assumptions/dependencies: Current models show degradation on formula-heavy layouts; requires domain-specific fine-tuning and evaluation.
- Color-conditioned pointers and UI-guided reading — Use case: Read text inside color-coded boxes (e.g., PDF annotations, UI overlays) for workflows that rely on visual cues. — Tools/workflows: Color-aware training data and prompts; explicit conditioning channels; reliability benchmarks for color guidance. — Assumptions/dependencies: Present models exhibit catastrophic forgetting on color-guided OCR; needs targeted data and training strategies.
- Rotated/skewed text and non-axis-aligned layouts — Use case: Engineering drawings, labels, and receipts with rotated fields read accurately with rotated bounding boxes. — Tools/workflows: Rotated box prediction (5-parameter boxes or quadrilaterals); rotation-aware matching in metrics; UI for rotated box verification. — Assumptions/dependencies: Current interface uses axis-aligned boxes; new geometry conventions and parsers must be adopted.
- Multilingual, low-resource document OCR — Use case: Global operations across diverse scripts (Arabic, Devanagari, CJK) for government and enterprise. — Tools/workflows: Multilingual corpora and tokenizers; script-aware normalization; localized reading tuned per script. — Assumptions/dependencies: Present training is English-centric; tokenizer and data expansion are required.
- Page-level linearization harmonization for downstream systems — Use case: Align grounded outputs with canonical page-to-Markdown orders used by popular benchmarks and production parsers. — Tools/workflows: Configurable reading-order policies (e.g., “columns-first,” “Z-order,” “table-aware”); adaptive text2d renderers; order-aware CER in pipelines. — Assumptions/dependencies: Current text2d favors layout-preserving linearization; requires policy selection and evaluation across domains.
- Table understanding and structured extraction — Use case: Extract cells, headers, and relations from complex tables in financial and scientific documents with grounding. — Tools/workflows: Table schema prompts; cell-level box+text outputs; linkage to downstream ETL tools; table-aware CER/Recall metrics. — Assumptions/dependencies: Needs targeted table datasets and supervision beyond line/paragraph granularity.
- Privacy-preserving, on-device OCR for edge/mobile — Use case: Local processing of sensitive IDs and receipts without cloud transfer, with grounded verification. — Tools/workflows: Distilled/smaller models; hardware acceleration; compact JSON outputs; offline reviewer modes. — Assumptions/dependencies: Model size and long-context requirements must be reduced; device-specific optimizations needed.
- Agentic document workflows and automated QA — Use case: Autonomous agents that iteratively detect, read, and verify targeted regions (e.g., “find all dates; confirm against policy”). — Tools/workflows: Composable prompts across task families; feedback loops using grounded errors; policy-encoded checks. — Assumptions/dependencies: Robust prompt semantics and error recovery; standardized APIs and guardrails.
- Benchmarking and standards: grounded OCR metrics adoption — Use case: Industry-wide evaluation protocols that separate recognition, localization, and page fidelity to avoid “good reader, bad paginator” failures. — Tools/workflows: Standard CER/WER, [email protected], [email protected], CER_e2e suites; public leaderboards and testbeds; JSON normalization pipelines. — Assumptions/dependencies: Community alignment on schemas and matching rules; cross-model comparability.
- Knowledge graph construction from scanned corpora — Use case: Build verifiable entity-relation graphs from documents, with each triple backed by coordinates for auditability. — Tools/workflows: Conditional detection to locate entity mentions; localized reading for context; store bbox provenance with graph edges. — Assumptions/dependencies: Requires robust NER/RE models integrated with grounded OCR; domain-specific ontologies and QC processes.
In all cases, feasibility and quality depend on stable image references (DPI, cropping), coherent prompt conventions, JSON parsing/repair routines, domain-specific fine-tuning where needed, and careful handling of known limitations (color guidance, formula-heavy pages, rotated text).
Glossary
- AdamW: An optimization algorithm with decoupled weight decay commonly used for fine-tuning deep neural networks. "We fineâtune using AdamW~\cite{loshchilov2019decoupledweightdecayregularization}"
- axis-aligned bounding boxes: Rectangular regions aligned with the image axes used to localize content in pixel coordinates. "All outputs of type BOX are axis-aligned bounding boxes in pixel coordinates, represented as with , in the original image reference frame."
- catastrophic forgetting: A phenomenon where a model loses previously acquired capabilities after fine-tuning on new tasks. "Color-conditioned pointers are absent from our training data, and the OCR-focused fine-tuning overwrites the base modelsâ heuristic ability to interpret these cues, a form of catastrophic forgetting on this narrow but challenging sub-task."
- CDM: A specialized metric for evaluating formula recognition quality on mathematical expressions. "formula recognition via CDM~\cite{wang2025imagetexttransformingformula} and CER on cropped equations"
- CER: Character Error Rate; a string-level metric based on edit distance to quantify transcription errors. "For any task that returns plain text, we report character error rate (CER) and word error rate (WER)."
- CER_e2e: End-to-end character error rate measuring page-level fidelity after layout-preserving linearization. "using CER, WER, [email protected], [email protected], and ."
- conditional detection: Detecting and returning bounding boxes that match a given query string within a document image. "Conditional detection tasks take a query string and an image as input"
- curriculum: A staged training strategy that gradually increases sequence length or task difficulty to stabilize optimization. "To stabilize optimization and handle complex layouts at long context, we adopt a curriculum over total sequence length (image prompt plus full-page reading output)."
- deterministic reading order: A fixed ordering used to linearize structured predictions into page-level text for evaluation. "We linearize all predictions and references into page-level strings using a deterministic reading order and a whitespace-preserving layout"
- diacritics: Marks added to letters in many languages that affect pronunciation and recognition, important for OCR accuracy. "(i) distinct page organizations (forms, tables, narrative prose), (ii) broad typographic and symbol distributions (small fonts, math, diacritics)"
- [email protected]: The F1 score computed after matching predicted and ground-truth boxes with IoU ≥ 0.5. "For detection-style outputs (plain or conditional), we report [email protected] and [email protected]."
- Fox: A multi-page OCR benchmark evaluating page, region, line, and color-guided reading capabilities. "Fox is a multi-page benchmark that probes a model's ability to ``focus anywhere'' on a document via region-level, line-level, and color-guided OCR."
- grounded OCR front-end: An OCR component that outputs transcripts with precise spatial grounding and supports localized reading via prompts. "We refer to the OCR component that downstream systems actually interact with as a grounded OCR front-end"
- human-in-the-loop: A verification paradigm where humans review and correct model outputs, improving reliability and training data. "Grounding therefore directly supports human-in-the-loop verification and active-learning workflows."
- Intersection over Union (IoU): A measure of overlap between predicted and ground-truth boxes used for matching in detection tasks. "Predicted and ground-truth boxes are matched one-to-one using IoU~;"
- KaTeX: A fast math rendering library; compatibility ensures consistent LaTeX equation rendering. "normalize them to KaTeX-compatible \LaTeX"
- layout analysis: The process of identifying document structure such as text regions, columns, and tables. "Classical pipelines---with distinct stages for detection, recognition, and layout analysis---offer explicit text grounding"
- layout-sensitive text2d: A whitespace-preserving linearization that encodes 2D document layout using only spaces and newlines. "Return a layout-sensitive text2d representation of the image."
- Levenshtein edit distance: A string distance measure counting insertions, deletions, and substitutions, underpinning CER/WER. "Both are based on Levenshtein edit distance on lightly normalized strings (Unicode NFKC + whitespace cleanup)."
- linearization: Converting 2D document content and structure into a single linear text sequence for evaluation or downstream use. "reveals trade-offs in page-level linearization, color-guided OCR, and formula-heavy layouts."
- localized reading: Transcribing text only within a specified bounding box region of an image. "Localized reading transcribes user-specified subregions, and conditional detection highlights all instances of a query string."
- long-context: The ability of a model to handle very long token sequences in inputs and outputs. "supporting long-context page transcripts (up to 8k--16k tokens)."
- [email protected]: Matched CER computed only on box pairs with IoU ≥ 0.5, isolating recognition from localization errors. "[email protected] isolates recognition quality given successful localization"
- NaViT-style Qwen2.5-VL vision encoder: A patch-based visual transformer style for processing whole images without cropping or tiling. "NaViTâstyle Qwen2.5âVL vision encoder"
- NFKC: Unicode Normalization Form KC; a normalization step applied before computing edit-distance metrics. "(Unicode NFKC + whitespace cleanup)."
- OCR-free: A VLM approach that treats text as latent without explicit transcripts or token grounding. "``OCR-free'' vision--LLMs (VLMs), by contrast, now dominate many document-understanding benchmarks"
- OmniDocBench v1.5: A diverse PDF benchmark with dense annotations for layout regions, text, formulas, and tables. "OmniDocBench v1.5 is a diverse PDF benchmark with dense annotations for layout regions, text spans, formulas, and tables"
- prompt-based interface: An interaction mode where tasks are specified via textual prompts rather than fixed APIs. "expose reading, detection, and grounding through a unified, prompt-based interface."
- prompt templates: Predefined prompt variants sampled during training to improve robustness to phrasing. "For each (task, input, output) tuple we maintain a bank of prompt templates and sample one uniformly at training time."
- RAG (retrieval-augmented generation): A system that integrates retrieved documents with generative models to improve accuracy and specificity. "LLMs and retrieval-augmented generation (RAG) systems"
- [email protected]: Detection recall computed after matching with IoU ≥ 0.5, measuring the fraction of ground-truth boxes found. "For detection-style outputs (plain or conditional), we report [email protected] and [email protected]."
- rasterization: Converting vector PDF pages into pixel images; can introduce visual noise affecting OCR. "varied rasterization noise and reading-order conventions."
- token-level grounding: Linking recognized text tokens to precise pixel coordinates or bounding boxes. "token-level grounding is at best partial"
- tokenizer: The component that segments text into tokens for model processing; often kept unchanged during specialization. "without modifying the tokenizer, adding adapters, or freezing modules"
- VLM (vision--LLM): A multimodal model that processes both visual inputs and text. "``OCR-free'' vision--LLMs (VLMs), by contrast, now dominate many document-understanding benchmarks"
- WER: Word Error Rate; an edit-distance-based metric counting word-level insertions, deletions, and substitutions. "For any task that returns plain text, we report character error rate (CER) and word error rate (WER)."
Collections
Sign up for free to add this paper to one or more collections.