- The paper introduces LIBERO-Para, a controlled benchmark that diagnoses VLA models’ vulnerability to paraphrased instructions using 43 distinct paraphrase types.
- It proposes PRIDE, a novel metric quantifying semantic and syntactic divergence, revealing uniform performance drops of 22–52 percentage points under linguistic variations.
- The findings highlight that object lexical substitutions critically impair VLA models, underscoring the need for enhanced semantic grounding in instruction-to-task mapping.
LIBERO-Para: A Controlled Benchmark for Diagnosing Paraphrase Robustness in Vision-Language-Action Models
Vision-Language-Action (VLA) models leverage foundation VLMs and language encoders for robotic manipulation, attaining high task success rates via multimodal instruction following. However, in downstream deployment, data-scarce fine-tuning on limited demonstrations often induces overfitting to specific linguistic formulations, giving rise to a critical vulnerability: failure to generalize to unseen paraphrased instructions in the operational environment. The LIBERO benchmark evaluates VLA models under a fixed instruction set, focusing on visual generalization but neglecting robustness to linguistic variation and paraphrasing. Existing benchmarks (CALVIN, LADEV, LIBERO-PRO/Plus/X, LangGap) insufficiently isolate meaning-preserving linguistic perturbations, confound task semantics, or lack formal difficulty quantification.

Figure 1: VLA models' susceptibility to paraphrased instructions after data-scarce fine-tuning, emphasizing the paraphrase robustness gap.
LIBERO-Para: Benchmark Design and Paraphrase Taxonomy
LIBERO-Para proposes a controlled two-axis variation schema (action × object) where action expressions and object references, the core semantic components in robotic instructions, are systematically paraphrased. The benchmark isolates meaning-preserving linguistic changes, grounded in the Extended Paraphrase Typology and Directive taxonomies, resulting in 43 distinct paraphrase types. The dataset comprises 4,092 paraphrased instructions generated via LLMs and verified for semantic fidelity.
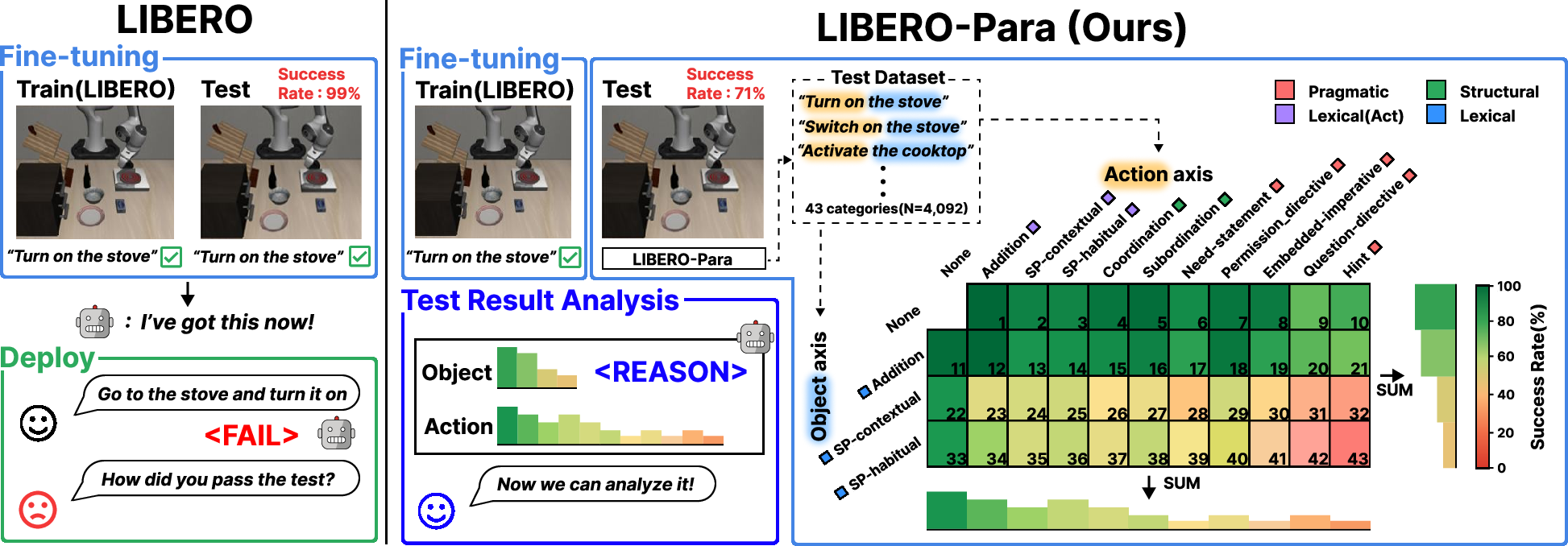
Figure 2: LIBERO-Para's two-axis schema enables interpretable, compositional analysis of paraphrase robustness under limited fine-tuning.
Axis-specific examples clarify the scope of both object and action paraphrasing: object axis covers same-polarity substitutions and additions; action axis includes lexical, structural, and pragmatic reformulations, graded by directness and linguistic complexity.
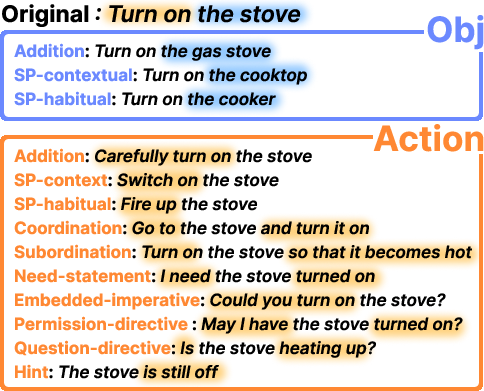
Figure 3: Representative examples of paraphrasing across object and action axes, reflecting lexical, syntactic, and pragmatic variation.
PRIDE: Task-Grounded Paraphrase Distance and Robustness Metric
LIBERO-Para introduces PRIDE—a metric quantifying paraphrase difficulty and robustness—composed of two complementary components:
- Keyword Similarity (SK): Evaluates semantic preservation of task-critical content words (action/object) between original and paraphrased instructions via SBERT embeddings and maximal cosine matching.
- Structural Similarity (ST): Measures syntactic divergence using normalized dependency-tree edit distance on POS and dependency labels, decoupling surface word changes from structural rewritings.
The overall Paraphrase Distance (PD) is a weighted combination of SK and ST, calibrated by parameter α. PRIDE score further incorporates task success, providing a granular robustness measure as models face linguistic deviation.
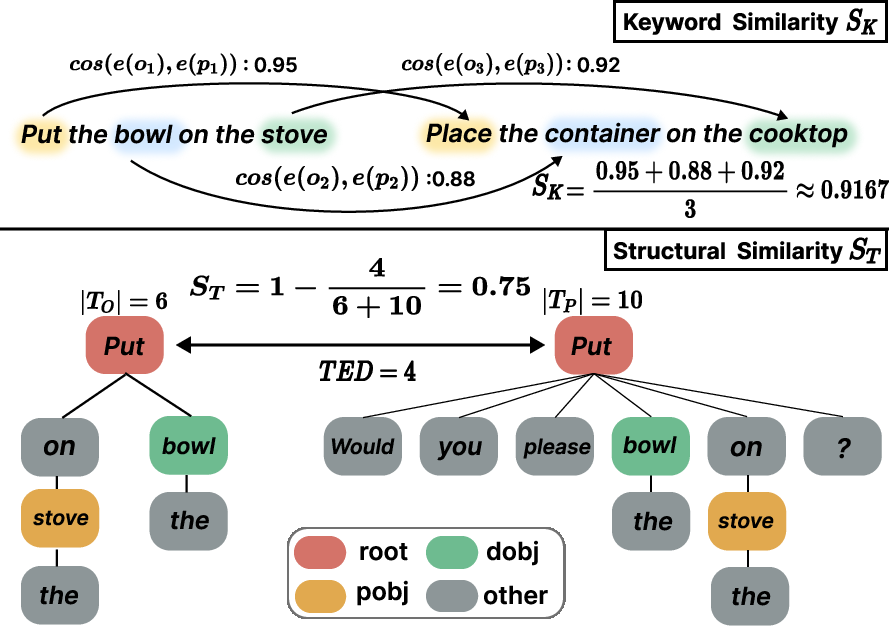
Figure 4: Visualization of SK and ST calculations, respectively capturing semantic overlap and syntactic reorganization between instructions.
Strong Empirical Findings
Evaluation across seven VLA models (0.6B–7.5B parameters, four architectural paradigms) reveals pervasive paraphrase fragility:
- Uniform Performance Degradation: Success rate drops consistently by 22–52 pp under LIBERO-Para, regardless of architecture, scale, or fine-tuning schema.
- Object Paraphrasing is the Primary Bottleneck: Lexical substitutions of target object references cause the largest declines, with surface-level matching outweighing semantic grounding.
- Hidden Non-uniformity Unveiled by PRIDE: Conventional success rate falsely attributes robustness to models that only succeed on “easy” paraphrases; PRIDE reveals systematic failures on difficult variants, overestimating robustness by up to 22%.
- Planning-level Failures Dominate: 80–96% of errors result from trajectory divergence (task misidentification) rather than low-level execution, highlighting impaired instruction-to-task mapping.

Figure 5: PRIDE score grid reflects increased paraphrase difficulty in more indirect action types and object substitutions, identifying challenging regions.
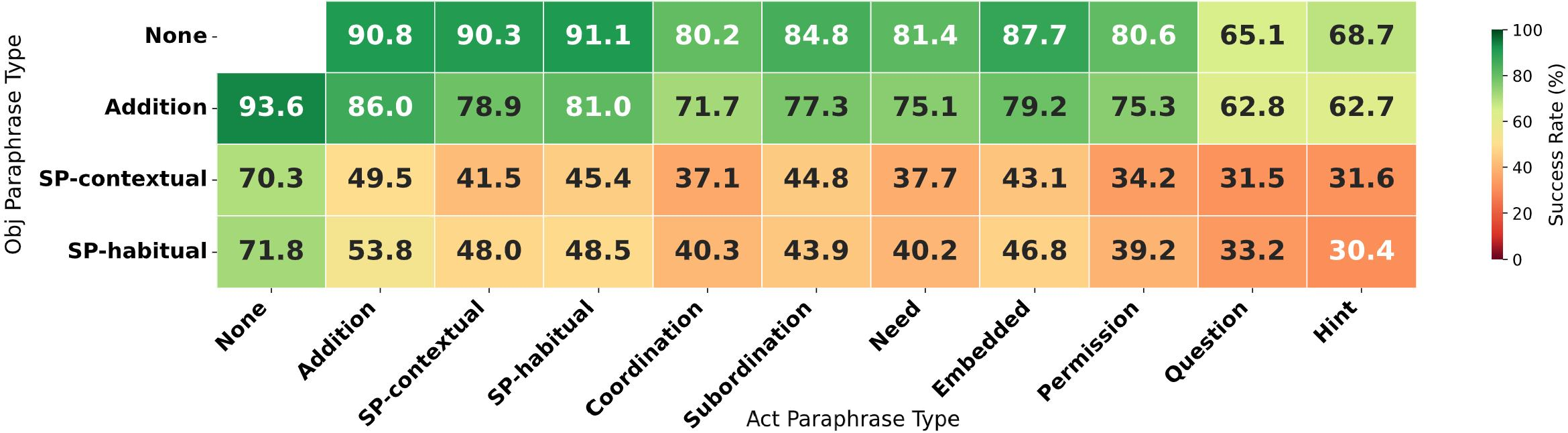
Figure 6: Model-average success rates sharply decrease under object paraphrasing, especially combined with indirect action types.
Detailed Analysis
Cross-model comparison confirms that paraphrase fragility cannot be attributed to architectural choices, training data scope, or VLM adaptation strategy. Increasing task diversity or freezing the VLM backbone does not mitigate the linguistic robustness gap.
Object grounding emerges as the fundamental challenge: synonym or contextually appropriate substitutions for objects (e.g., “stove” → “range”) consistently incur pronounced failures. This is further exacerbated by canonical instruction datasets, which offer only one lexical reference per object during training.
Action indirectness and pragmatic paraphrases cause stepwise declines in performance but are less severe than object lexical variation due to limited ambiguity in motor primitives. However, questions or hints that require inference (indirect speech acts) can be substantially disruptive.
Failure analysis using Dynamic Time Warping (DTW) on end-effector trajectories validates that the vast majority of errors are “Far-GT”—the model plans toward incorrect targets under paraphrased instructions. Only a minimal proportion (<5% for most models) are “Near-GT,” indicating correct task planning but physical execution errors.
Implications and Future Directions
LIBERO-Para and PRIDE diagnose a critical and quantifiable limitation in current VLA systems: shallow linguistic grounding precludes robust task identification for paraphrased instructions, severely impacting operational reliability. The findings indicate that enhancing paraphrase robustness requires:
- Prioritizing instruction-to-task semantic mapping rather than low-level motor control;
- Explicitly modeling object reference diversity and training on lexical alternatives;
- Developing architectures and training procedures that emphasize semantic object grounding and compositional generalization;
- Integrating PRIDE or equivalent metrics in evaluation to accurately reflect robustness across linguistic difficulty gradients.
The benchmark facilitates future research into LLM-based paraphrase augmentation, adaptive object grounding, and multimodal instruction mappings that can bridge the robustness gap. Additionally, validating these failures in real-world settings and extending linguistic variation to compound paraphrases remains an open avenue.
Conclusion
LIBERO-Para establishes a rigorous diagnostic framework for evaluating VLA models’ robustness to paraphrased instructions. The work identifies object-level lexical variation as the dominant source of failures, quantifies performance degradation and its hidden non-uniformity, and demonstrates that most errors stem from planning rather than execution. PRIDE offers a task-grounded, interpretable metric, revealing that current VLA models lack generalization to unseen linguistic formulations and motivating advancements in semantic grounding and instruction-language diversity (2603.28301).