Rethinking Language Model Scaling under Transferable Hypersphere Optimization
Abstract: Scaling laws for LLMs depend critically on the optimizer and parameterization. Existing hyperparameter transfer laws are mainly developed for first-order optimizers, and they do not structurally prevent training instability at scale. Recent hypersphere optimization methods constrain weight matrices to a fixed-norm hypersphere, offering a promising alternative for more stable scaling. We introduce HyperP (Hypersphere Parameterization), the first framework for transferring optimal learning rates across model width, depth, training tokens, and Mixture-of-Experts (MoE) granularity under the Frobenius-sphere constraint with the Muon optimizer. We prove that weight decay is a first-order no-op on the Frobenius sphere, show that Depth-$μ$P remains necessary, and find that the optimal learning rate follows the same data-scaling power law with the "magic exponent" 0.32 previously observed for AdamW. A single base learning rate tuned at the smallest scale transfers across all compute budgets under HyperP, yielding $1.58\times$ compute efficiency over a strong Muon baseline at $6\times10{21}$ FLOPs. Moreover, HyperP delivers transferable stability: all monitored instability indicators, including $Z$-values, output RMS, and activation outliers, remain bounded and non-increasing under training FLOPs scaling. We also propose SqrtGate, an MoE gating mechanism derived from the hypersphere constraint that preserves output RMS across MoE granularities for improved granularity scaling, and show that hypersphere optimization enables substantially larger auxiliary load-balancing weights, yielding both strong performance and good expert balance. We release our training codebase at https://github.com/microsoft/ArchScale.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about a safer, simpler way to train LLMs so they scale up more smoothly and efficiently. The authors show how to pick training settings (like the learning rate) at a small, cheap scale and then “transfer” those settings to much bigger models and longer trainings—without losing performance or stability. Their key idea is to keep each weight matrix on a fixed “hypersphere,” which helps stop the model’s internal numbers from blowing up as it scales.
What questions do the authors ask?
In simple terms, the paper asks:
- Can we find a single way to set the learning rate that works when we change model width (how wide each layer is), depth (how many layers), training tokens (how much practice data), and Mixture‑of‑Experts (MoE) details (how many experts you use and how you pick them)?
- Can we remove tricky hyperparameters like weight decay and still get top performance?
- Can we make training at larger scales more stable by design, instead of relying on many fragile fixes?
- Can we make MoE models scale better, share the work more evenly among experts, and avoid the usual instability?
How did they study it? (Methods and key ideas)
Think of training a model like climbing down a mountain to reach the lowest point (the best loss). The learning rate is how big each step is, and the optimizer is your strategy for stepping. This paper uses two main tools:
- Hypersphere Optimization (HyperP): Imagine every weight matrix must always lie on a sphere of fixed size—like forcing each climber to stay at the same distance from a center. After every step, they “re-project” the matrix back onto the sphere. This naturally limits how large certain internal numbers (logits) can get. They use a specific version called MuonH: the Muon optimizer plus a “Frobenius-sphere” constraint (Frobenius norm = a way to measure a matrix’s overall “length”).
- Transfer Laws: These are rules for how to change the learning rate when you scale the model. The authors derive and test laws for:
- Width scaling: getting wider layers.
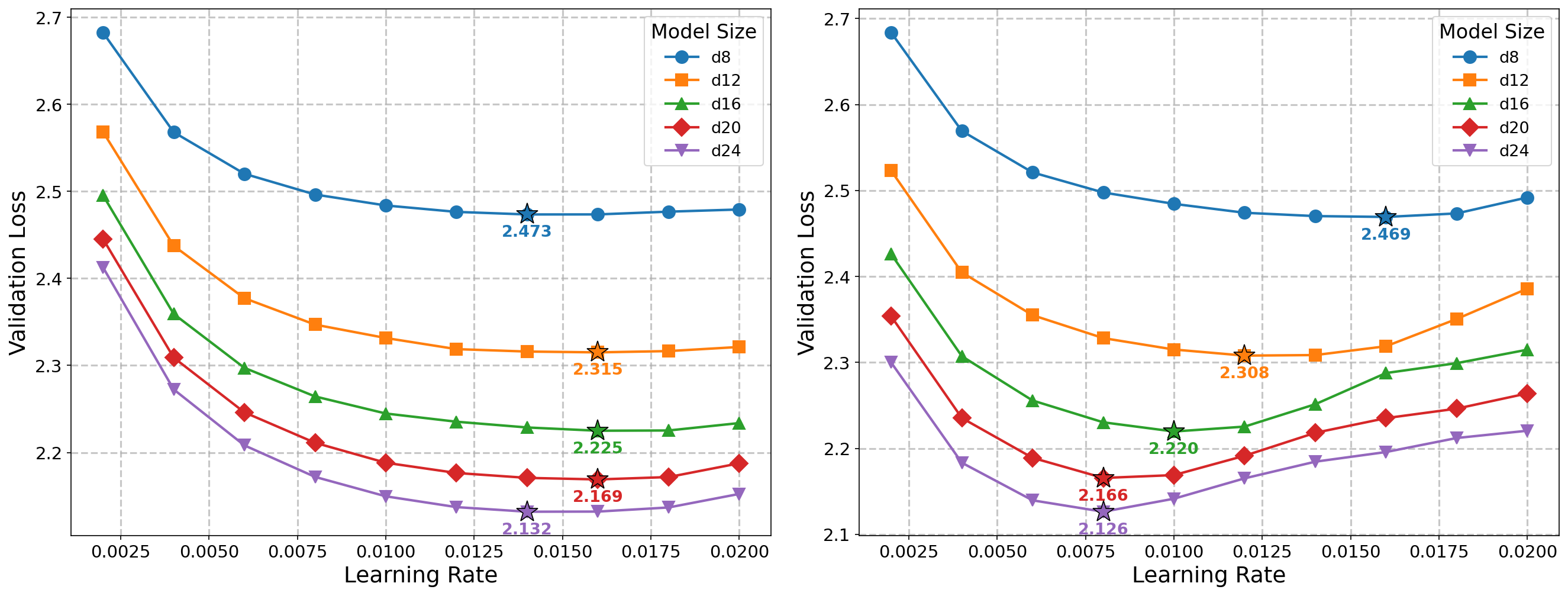
- Depth scaling: adding more layers (they use a method called Depth-μP to adjust learning rates with depth).
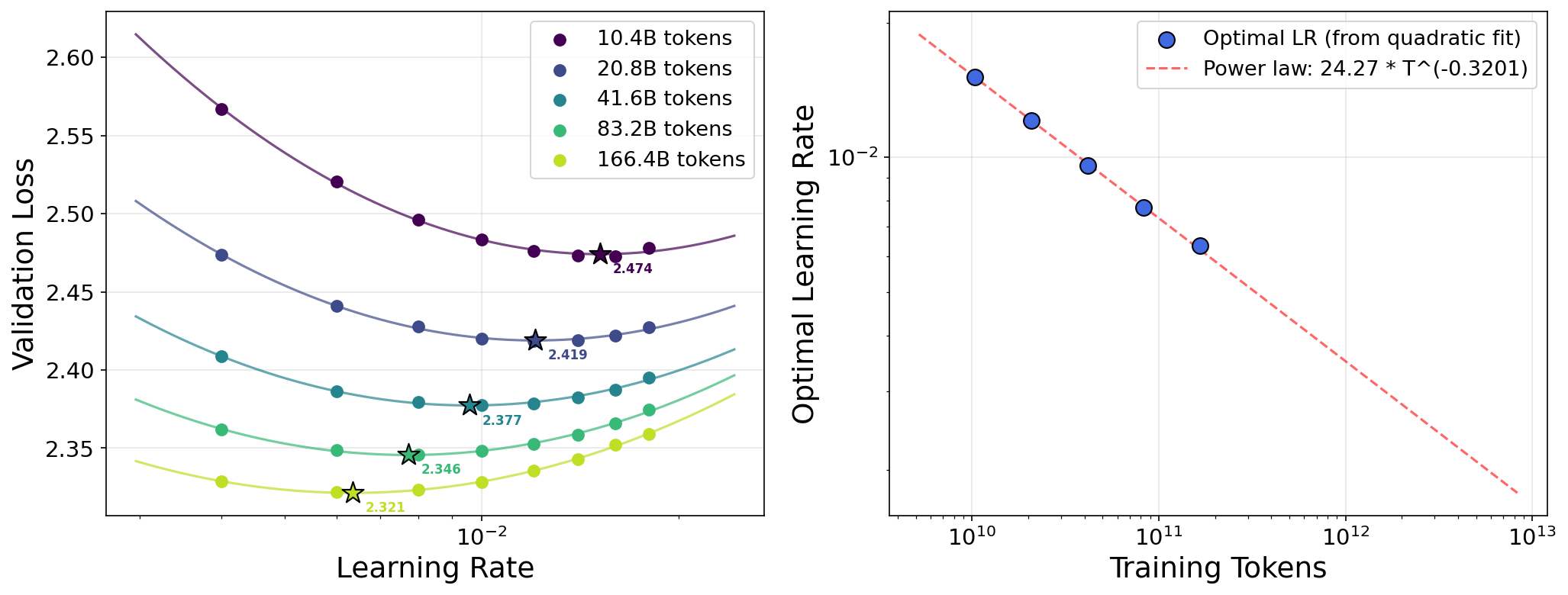
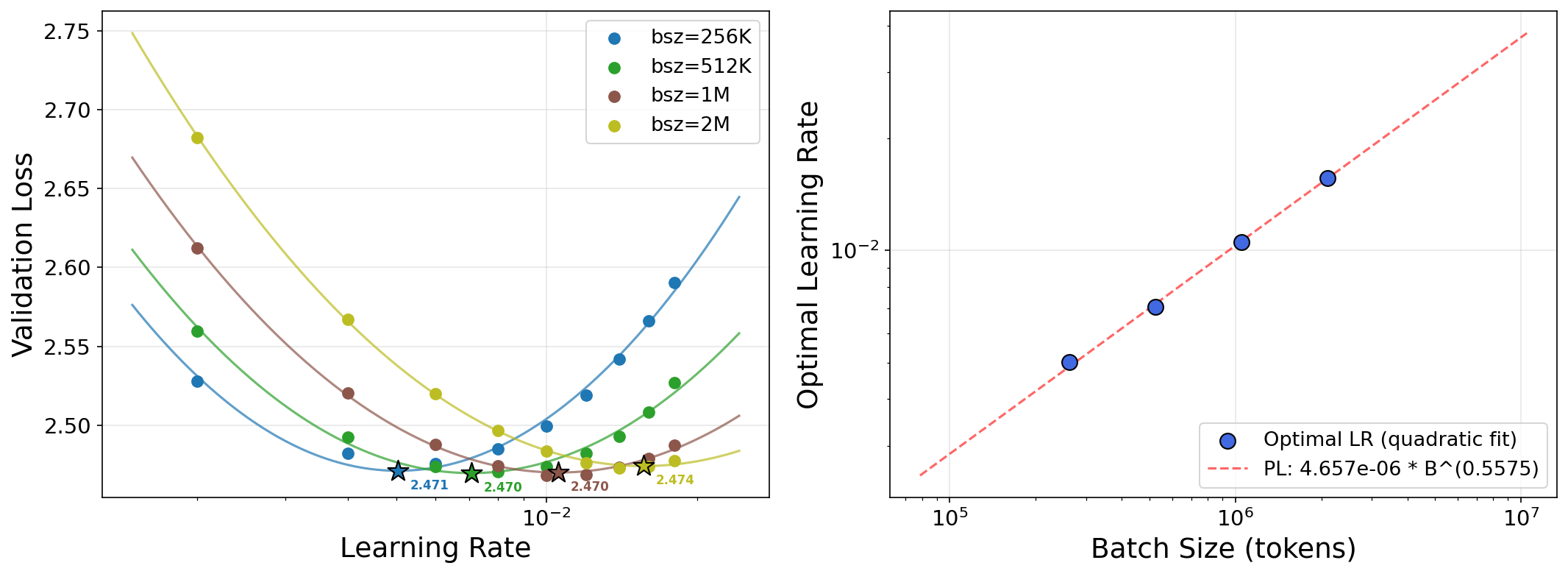
- Data scaling: training on more tokens (more practice). They find a simple power law: the best learning rate goes down as the number of training tokens goes up, with an exponent of about 0.32.
- MoE granularity: how many experts you activate per token (k) and how many experts exist in total (sparsity S).
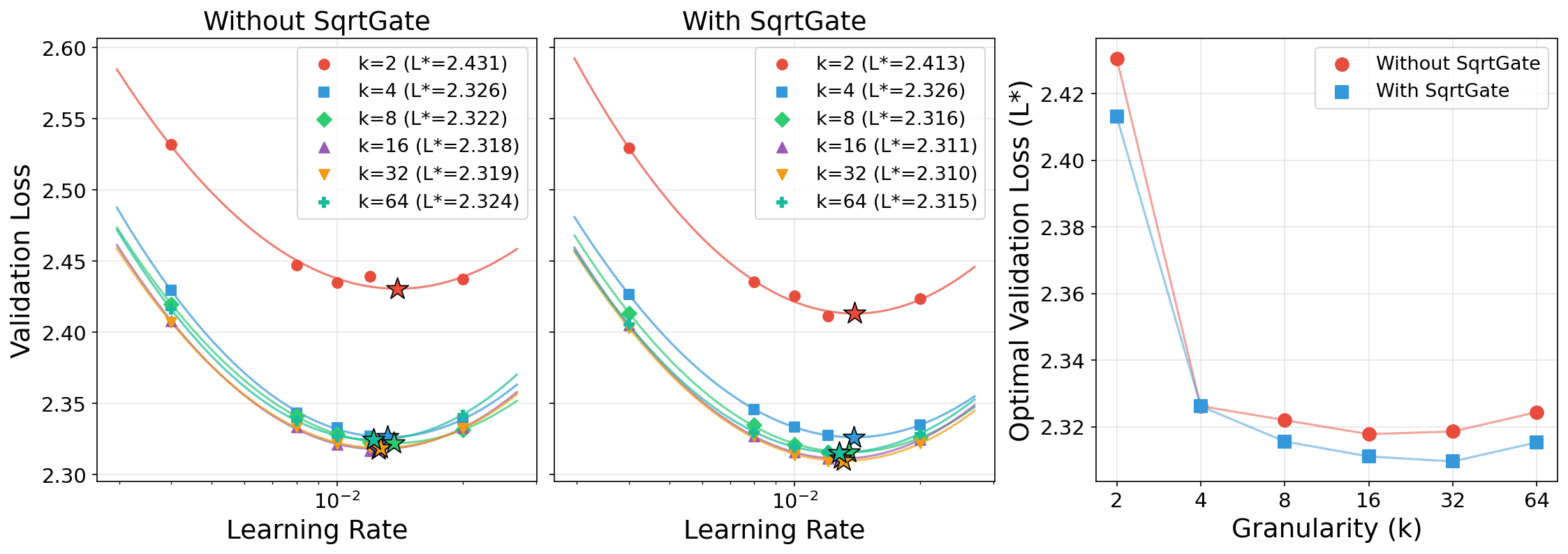
They also introduce SqrtGate for MoE: usually, a router picks the top k experts and mixes their outputs using weights that sum to 1. SqrtGate instead uses the square root of those weights to keep the output’s typical size (RMS) steady when you change k. This makes scaling across different MoE settings smoother and more stable.
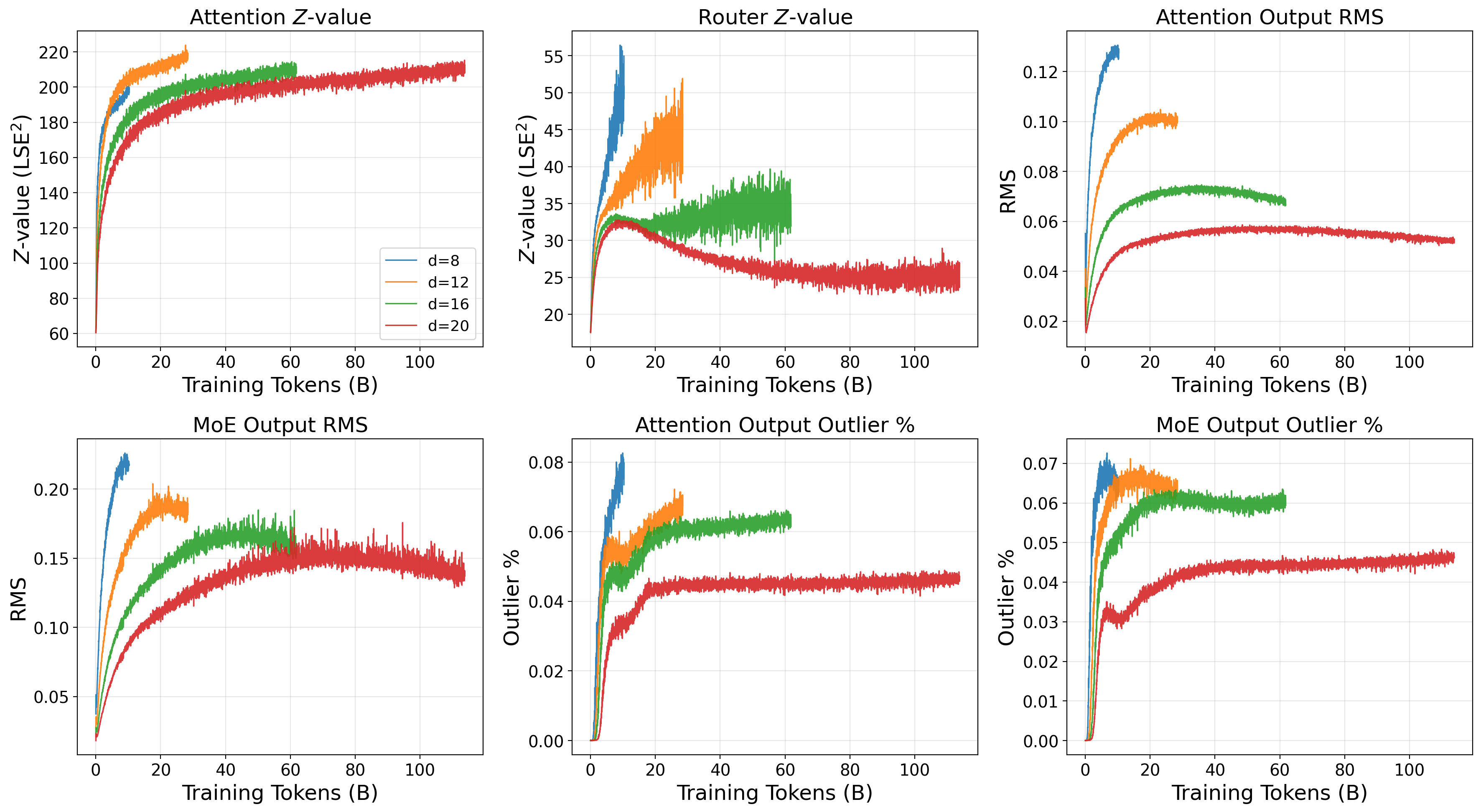
Finally, they check stability with simple signals:
- Z-values (a measure tied to how large logits are before the softmax),
- Output RMS (typical magnitude),
- Activation outliers (rare, very large values that can hurt training and quantization).
What did they find, and why does it matter?
Here are the main results, explained in everyday terms:
- One learning rate rule to scale them all:
- Data scaling: The best learning rate follows a clean power law as you train on more tokens:
- η* ≈ constant × T-0.32, where T is the total number of training tokens.
- This same exponent (0.32) was seen before with a different optimizer, suggesting it might be a general rule of thumb.
- Weight decay becomes unnecessary:
- Under the Frobenius-sphere constraint, “weight decay” (a common nudge that shrinks weights) doesn’t really act at first order—it’s basically a no-op. In practice, they set weight decay to zero and don’t lose quality. This removes a tricky hyperparameter from tuning.
- Depth still needs care (Depth-μP matters):
- Even with hypersphere optimization, simply stacking more layers changes how updates add up. You still need to adjust learning rates with depth (Depth-μP) to keep training balanced. The optimizer isn’t “automatically” depth-transferable.
- Built-in stability as you scale:
- Keeping weights on the sphere naturally limits how big logits can get. As they scale models and training FLOPs up, Z-values, output RMS, and activation outliers stay bounded or even improve. That means fewer loss spikes and less risk of training collapse.
- This leads to “transferable stability”: the same hyperparameters that are safe at small scale remain safe at large scale.
- Better, simpler MoE scaling:
- SqrtGate keeps the MoE output size steady across different numbers of active experts (k), making it easier to change MoE settings without re-tuning.
- With hypersphere optimization, they can use a larger load-balancing weight (a term that encourages even use of experts) without hurting language modeling quality. This yields both strong performance and better expert balance.
- Real efficiency gains:
- Using HyperP (their hypersphere-based transfer framework), a single base learning rate tuned at the smallest scale works across all tested scales.
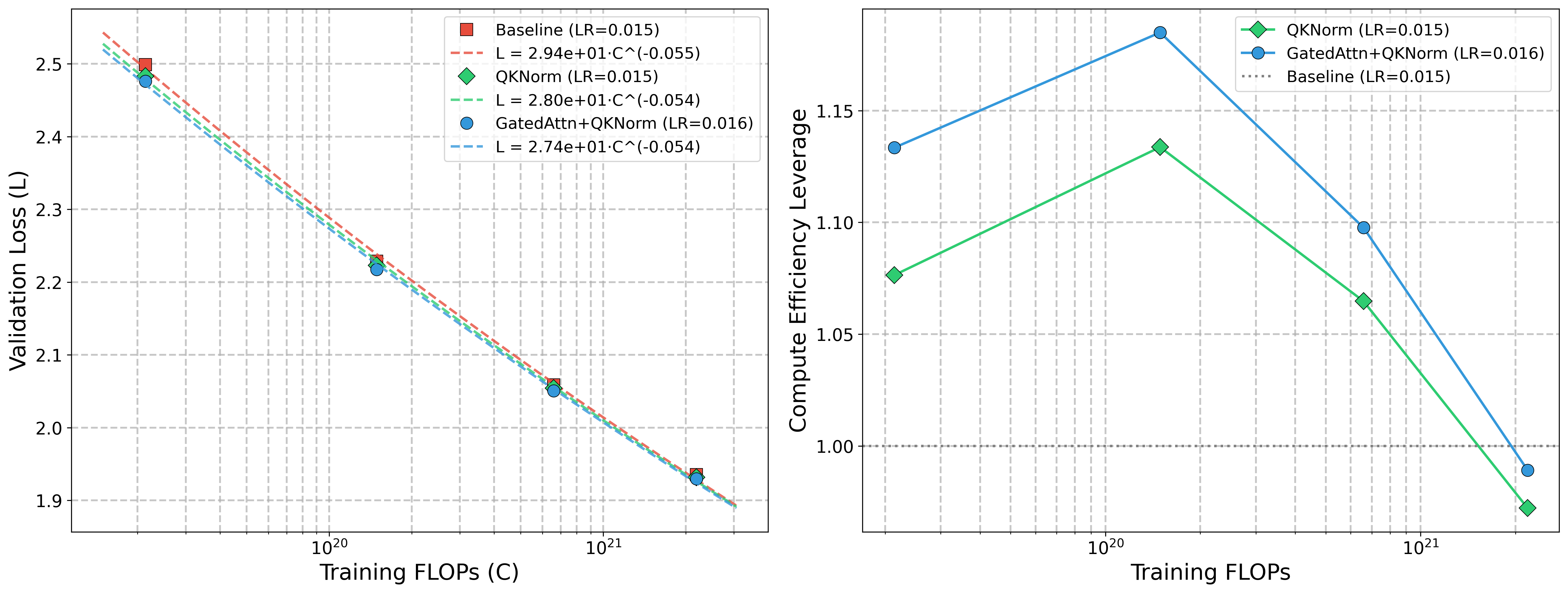
- At their largest run (~6×1021 FLOPs), HyperP gets about 1.58× compute efficiency over a strong baseline for dense models. With MoE (S=8, k=8), they reach about 3.38× over dense baselines. In plain terms: you get the same quality with much less compute—or better quality with the same compute.
Why is this important?
- Fewer knobs to turn: Removing weight decay and using one learning-rate recipe across many scales makes training large models much simpler and cheaper to set up.
- Safer scaling: The sphere constraint limits dangerous number growth inside the model, reducing crashes and spikes as you train longer and build bigger models.
- Fair comparisons: If everyone can use a shared, robust scaling recipe, it becomes easier to compare new architectures fairly (because they’re all trained near their best settings).
- Stronger MoE: Smoother scaling across different MoE settings (like how many experts you use) opens the door to more efficient, reliable sparse models.
A quick mental picture
- Hypersphere optimization: Picture every weight matrix living on the surface of a ball. Training nudges it around the surface, but never lets it fly away or collapse to the center. That keeps a lot of numbers from exploding.
- SqrtGate: If you mix the voices of k experts, taking the square root of their mix weights keeps the overall loudness steady, no matter how many experts are talking.
Bottom line
The paper provides a practical, principled way to scale LLMs:
- Pick learning rates once at small scale,
- Follow simple rules to adjust for more data, more layers, and MoE settings,
- Keep training stable by constraining weights to a hypersphere,
- Get better compute efficiency and balanced MoE experts.
This can make building future large models faster, safer, and less expensive—while helping the community compare new ideas on equal footing. The authors also release code, making it easier for others to try these methods.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains uncertain, underexplored, or unaddressed in the paper, organized to help guide concrete follow-up studies.
Theoretical assumptions and generality
- The “weight decay is a first-order no-op” result holds only to first order on the Frobenius sphere; it remains unknown whether second-order effects or long-horizon accumulation make weight decay beneficial in practice over long trainings or at frontier scale. A rigorous bound on the cumulative second-order bias is missing.
- Width-transfer arguments assume approximately isotropic spectra (flat singular values). There is no quantitative analysis of how much anisotropy (or evolving rank) can be tolerated before width transfer or stability degrades, nor empirical characterization of singular value dynamics under MuonH.
- The depth-scaling theorem relies on local Jacobians being and small-step assumptions; there is no proof or diagnostic for when these assumptions break at larger depths or under different residual/normalization designs (e.g., RMSNorm, ReZero, alibi-style positional schemes).
- Claims of bounded logits are per-layer and norm-based; there is no analysis of how residual accumulation, LayerNorm re-centering, and multiple projections across depth interact with these bounds to control end-to-end logit growth.
- The “magic exponent” of $0.32$ for data scaling is purely empirical and obtained on one dataset/architecture regime. A theoretical explanation and cross-architecture/dataset validation of the exponent’s universality are missing.
Optimizer and parameterization scope
- Results focus on MuonH with Frobenius-norm projection. It is unclear whether the transfer laws and stability properties hold for other hypersphere methods (e.g., spectral-norm SSO/MuonSphere), or for different second-order or adaptive optimizers.
- The framework still mixes optimizers: hidden weights use MuonH, while LM head and vector-like parameters use AdamH/AdamW-like variants. The paper does not analyze whether the learned scaling/transfer properties degrade due to this heterogeneity or whether a unified hypersphere treatment of all parameter types is feasible.
- The constants and (weight and update norms) are treated as fixed but they implicitly shape effective step sizes and layerwise conditioning. There is no study of how their choices (or scheduling) impact transferability, stability, or optimality.
Scope of empirical validation
- Experiments are confined to SlimPajama, a single pretraining corpus, with evaluation via validation loss only. Transferability and stability under different datasets (multilingual, code-heavy, noisy web), domain shifts, or downstream tasks (zero-/few-shot benchmarks, instruction tuning, RLHF) remain untested.
- Architectural coverage is narrow: Transformer-Next with GQA, QK-Norm, and Gated Attention. It is unclear whether HyperP’s benefits persist without these design choices or in alternative architectures (e.g., vanilla attention, RMSNorm-only, Llama-like stacks, Mamba/linear-attention, convolutional mixers).
- Depths are modest () and aspect ratio is fixed (). There is no evidence that the depth/width transfer laws and residual scaling remain stable for much deeper () or differently shaped networks (very wide, narrow, or non-constant aspect ratio).
- The robustness of findings across training seeds is not reported. Variance estimates or confidence intervals for scaling exponents, fitted optima, and CEL are missing.
- The batch-size scaling result (exponent ≈ 0.56) is given for a single token budget and architecture; the relationship between critical batch size and total tokens (or model size) is left explicitly as future work.
Scaling laws and fitting methodology
- Compute efficiency leverage (CEL) depends on power-law fits to limited-scale data; the paper does not provide uncertainty estimates (confidence intervals, sensitivity to fit ranges) or ablations on alternative fit forms.
- The stability of the data-scaling LR fit (Eq. ) is evaluated with leave-one-out within a narrow token range; robustness at substantially larger/smaller token budgets is untested.
- The interaction between LR schedule shape (no warmup, linear decay to 10%) and transfer laws is not examined. It is unknown whether the same exponent or transferability holds for cosine, triangular, or adaptive schedules, or with longer warmups.
MoE-specific gaps (Sparsity and granularity)
- SqrtGate’s -invariance relies on equal-RMS and weak-correlation assumptions across expert outputs—conditions that may not hold later in training as experts specialize. There is no empirical measurement of inter-expert correlations vs. training time or analysis of the impact when assumptions fail.
- Theoretical analysis of gradients is missing for SqrtGate (e.g., how weighting alters gradient magnitudes to experts and router, and whether it biases specialization, collapse, or gradient variance).
- SqrtGate’s effects on calibration, uncertainty, and downstream behavior are unknown. Its departure from probability-linear mixing could affect interpretability or calibration of the routed mixture.
- Load balancing is evaluated with MaxVio and a global-batch auxiliary loss at , but other metrics of specialization/utilization (entropy of routing, expert overlap, capacity saturation), per-rank balancing strategies, and high-/ scalability with capacity constraints are not studied.
- System considerations for MoE (throughput, communication overhead, memory footprint) are not evaluated under HyperP and SqrtGate, especially at higher or .
Stability and safety considerations
- Stability metrics (Z-values, RMS, outliers) are proxies; the paper does not link them to downstream robustness (e.g., sensitivity to long context, catastrophic spikes under rare tokens, or adversarial prompts).
- While the paper claims transferable stability, failure modes (if any) and boundary conditions (e.g., peak LR beyond which divergence appears at larger scales, sensitivity to momentum) are not mapped.
- The interaction of hypersphere constraints with quantization (post-training or QAT) is not evaluated, despite the stated relevance of outliers for quantization.
Design and training choices left unexplored
- Initialization: Only PyTorch’s Kaiming uniform is used. It is unknown whether HyperP requires re-tuning or different constants under alternative inits (e.g., orthogonal, scaled Xavier) or learned rescaling (e.g., μParam init variants).
- Normalization: Results use Pre-Norm; the theory states the same depth exponent for Post-Norm, but the paper does not test Post-Norm empirically nor examine RMS/LN statistics under both.
- Momentum is fixed at 0.95; the sensitivity of HyperP to momentum values or adaptive damping is not explored.
- Context length is fixed at 4K; the effect of longer contexts on stability (attention logits, -values), scaling exponents, and LR transfer is untested.
Comparative baselines and external validity
- Baselines exclude widely used optimizers beyond Muon (e.g., AdamW, Adafactor, Lion, Sophia). Whether HyperP’s advantages persist relative to stronger AdamW scaling rules or second-order preconditioners is unknown.
- The weight-decay-free claim is benchmarked against a “strong Muon baseline,” but not against state-of-the-art AdamW schedules where LR/WD co-tuning and cosine decay are carefully optimized. External validity across optimizers remains open.
Practical deployment and reproducibility
- The paper does not report multi-seed robustness, hardware variability, or reproducibility artifacts (e.g., deterministic kernels, mixed precision settings), which can affect conclusions about stability transfer.
- The reliance on capping training to ≈ FLOPs leaves open whether the gains grow, saturate, or reverse at frontier budgets and datasets.
These gaps suggest a number of concrete next steps: prove or falsify universality of the law across datasets/architectures; quantify singular-value anisotropy tolerances for width transfer; extend depth tests to much deeper models; analyze SqrtGate’s gradient dynamics and calibration; evaluate HyperP across optimizers, schedules, and normalizations; and validate stability and efficiency on diverse corpora and longer contexts with multi-seed confidence intervals.
Practical Applications
Immediate Applications
The following applications can be deployed with existing tools and practices, directly leveraging the paper’s findings and released codebase (https://github.com/microsoft/ArchScale).
- Compute-efficient LLM training via HyperP + MuonH
- Sectors: software/AI platforms, cloud/compute providers, foundation model labs, finance (modeling), healthcare (domain LLMs), education (research labs).
- What to do now:
- Adopt MuonH for matrix-like parameters and AdamH for vectors/embeddings.
- Eliminate weight decay (set to 0) and tune a single base learning rate at the smallest model; transfer it across width, depth, tokens, and MoE configurations using HyperP rules.
- Apply Depth-μP scaling (e.g., residual multiplier 1/√(2d), LR multiplier 1/√d for vectors/unembedding where specified).
- Use data-scaling rule η ∝ T-0.32 when changing training tokens.
- Expected impact: fewer hyperparameter sweeps, fewer training restarts, and up to ~1.58× compute efficiency over strong baselines for dense models; larger gains for MoE.
- Dependencies/assumptions: Frobenius-sphere normalization (MuonH), update normalization, Pre-/Post-Norm Transformer stacks with standard LN, similar schedules (linear decay to 10%), and momentum settings as in the paper.
- Reduced hyperparameter search and faster model iteration
- Sectors: MLOps/AutoML, cloud cost optimization (FinOps), SMEs and academic labs with limited budgets.
- What to do now:
- Perform a small LR sweep (3–5 points) at the smallest scale and fit a quadratic in log(LR) to estimate the optimum; transfer with HyperP.
- Standardize LR discovery into CI pipelines (e.g., nightly 3-point sweeps) and roll over to larger configurations with computed multipliers.
- Expected impact: 10–100× fewer tuning runs, predictable training timelines, reduced cost/variance in experimental results.
- Dependencies/assumptions: Smooth LR–loss curves and sufficiently similar data distribution to the pretest setup.
- Stability-first training practices (“transferable stability” dashboards)
- Sectors: AI platform ops, reliability engineering (SRE for ML), regulated industries requiring robust training runs.
- What to do now:
- Monitor Z-values (log-sum-exp squared), output RMS, and outlier% for attention and MoE layers.
- Add alerts if metrics deviate upward with scale; use HyperP to adjust LR consistently across sizes.
- Expected impact: fewer loss spikes/logit explosions, earlier anomaly detection, more reliable long-run training.
- Dependencies/assumptions: The Frobenius-sphere constraint bounds logits per Proposition; instrumentation added to training loops.
- MoE training made simpler and more robust with SqrtGate
- Sectors: large-scale LLM providers, distributed training teams, recommendation/ads systems using sparse experts, enterprise multitask models.
- What to do now:
- Replace classical softmax gating contribution y = Σ g_i E_i(x) with SqrtGate y = Σ sqrt(g_i) E_i(x).
- When using a shared expert, scale final output by 1/√2 to preserve RMS.
- Increase auxiliary load-balancing weight (e.g., γ = 0.1) and compute it over global batches (all-reduce) for improved balance without hurting loss.
- Expected impact: improved granularity scaling (k up to 32), lower router Z-peaks (≈5× reduction), better expert utilization, and state-of-the-art balance-quality tradeoff.
- Dependencies/assumptions: Equal-RMS and weakly correlated expert outputs (encouraged by hypersphere optimization), global balance loss computation.
- Quantization- and inference-friendly training
- Sectors: edge/on-device AI, inference serving, hardware-aware ML, robotics (resource-constrained).
- What to do now:
- Train with HyperP to reduce activation outliers and stabilize RMS; downstream, apply INT8/FP8 quantization more safely.
- Use stability metrics as pre-quantization gates (e.g., outlier% thresholds).
- Expected impact: higher quantization success rates, fewer accuracy regressions, more stable low-precision inference.
- Dependencies/assumptions: Similar activation distributions as those observed in experiments; quantization pipelines in place.
- Fairer and more reproducible architecture comparisons at small scale
- Sectors: academia, benchmarking consortia, internal R&D governance.
- What to do now:
- Use HyperP to transfer a single tuned LR across configurations and scales so scaling curves reflect architectural merit, not tuning variance.
- Report CEL (Compute Efficiency Leverage) relative to a strong baseline for transparent efficiency accounting.
- Expected impact: cleaner ablations, more reliable decisions on architecture changes, less overfitting to small-scale quirks.
- Dependencies/assumptions: Consistent token allocation per Chinchilla-like rules (TPP), same data, and evaluation metrics across runs.
- FinOps planning with compute efficiency leverage (CEL)
- Sectors: cloud cost management, PMO for AI programs, procurement.
- What to do now:
- Use CEL estimates to forecast budget for targeted validation loss and choose between dense and MoE roadmaps (e.g., 1.58× CEL for dense HyperP and ~3.38× CEL for MoE HyperP).
- Integrate CEL into portfolio planning, budgeting, and ROI models.
- Expected impact: reduced cost to hit accuracy targets; improved capacity planning and sustainability reporting.
- Dependencies/assumptions: CEL transfers robustly to your data/architecture; baseline appropriately chosen.
- Safer, more predictable large-scale runs
- Sectors: AI safety and reliability, mission-critical deployments (e.g., finance, healthcare triage assistants).
- What to do now:
- Prefer HyperP configurations to reduce training-collapse risks caused by unbounded logits.
- Maintain tighter numerical stability margins (e.g., stable FP16/BF16 training) due to bounded RMS and Z-values.
- Expected impact: fewer catastrophic failures mid-run, better utilization of long schedules, less operator intervention.
- Dependencies/assumptions: Similar numerical ranges and layer normalizations; consistent data preprocessing.
- Ready-to-use training components from ArchScale
- Sectors: PyTorch-based training stacks, OSS integrators, internal ML platforms.
- What to do now:
- Import MuonH/AdamH optimizers, SqrtGate module, HyperP paramization utilities from the provided codebase.
- Create internal templates (YAML/config) that encode HyperP defaults and reporting hooks (stability metrics).
- Expected impact: quicker adoption and lower integration risk; reproducible pipelines.
- Dependencies/assumptions: Alignment with your model code (Transformer-Next-like); compatibility with your distributed setup.
- Batch-size and LR coupling for practical sweeps
- Sectors: experimentation/training ops.
- What to do now:
- If batch size must change, adjust LR with the empirically observed ~B0.56 rule of thumb and confirm with a short sweep.
- Expected impact: fewer failed runs when scaling batch size; consistent convergence behavior.
- Dependencies/assumptions: Similar optimizer dynamics and schedules; confirm on your workload.
Long-Term Applications
These opportunities are high-impact but require further research, validation on broader workloads, or ecosystem development.
- Universal data-scaling law across optimizers and modalities
- Sectors: optimizer research, multi-modal AI (vision, speech, code), academic theory.
- Vision: Verify the “magic exponent” ~0.32 across optimizers (AdamW, Lion, Shampoo), domains, and large corpora; develop theory predicting the exponent.
- Dependencies/assumptions: May vary with schedules, momentum, noise scale, and data heterogeneity.
- Hardware–algorithm co-design for hypersphere optimization
- Sectors: AI accelerators, compiler/runtime stacks, HPC.
- Vision: Add native “project-to-Frobenius-sphere” and update normalization primitives; exploit bounded dynamic ranges to push lower precision and higher throughput.
- Dependencies/assumptions: Consistent performance wins at frontier scale; stable numerical kernels for sphere reprojection.
- Auto-tuning and hyperparameter-free training stacks
- Sectors: AutoML, managed ML platforms.
- Vision: Wrap HyperP into an AutoLR module that infers LR from tokens/depth/width and continuously adapts during curriculum/data-mixing changes.
- Dependencies/assumptions: Robustness under non-stationary data and complex training regimes (RLHF, DPO).
- Large-scale MoE systems with principled granularity scaling
- Sectors: foundation models, multilingual/multitask systems.
- Vision: Use SqrtGate to scale k and S substantially (e.g., k∈[32,128], S≫32) while maintaining RMS and balance; dynamic expert pools and routing policies for production traffic.
- Dependencies/assumptions: Communication and memory bandwidth challenges; refined load-balancing metrics and capacity constraints.
- Training stability standards and auditability
- Sectors: policy, standardization bodies, regulatory compliance, sustainability programs.
- Vision: Establish reporting standards for stability metrics (Z-values, RMS, outlier%), CEL, and explicit LR transfer rules in publications and model cards.
- Dependencies/assumptions: Community and vendor buy-in; alignment with compute governance initiatives.
- Domain-specialized, energy-aware model development
- Sectors: healthcare, finance, public sector, scientific computing.
- Vision: Normalize on HyperP-like scaling to bring down energy/compute costs for domain models (e.g., clinician assistants, compliance analysis LLMs) and improve access for smaller institutions.
- Dependencies/assumptions: Regulatory constraints, domain-specific data availability, and validation.
- Edge and on-device continual learning with bounded updates
- Sectors: mobile, robotics, IoT.
- Vision: Use hypersphere constraints to perform small-scale on-device fine-tuning or adaptation with reduced risk of weight-norm drift and catastrophic instability.
- Dependencies/assumptions: Efficient on-device reprojection/normalization; light-weight schedulers.
- Safer RLHF and post-training phases
- Sectors: alignment and safety research.
- Vision: Apply hypersphere constraints and HyperP to preference optimization and reinforcement-style fine-tuning to mitigate instability and logit blow-up during reward-driven updates.
- Dependencies/assumptions: Interaction between hypersphere constraints and off-policy gradients; reward hacking dynamics.
- New evaluation protocols for fair architecture scaling
- Sectors: benchmarking, open science consortia.
- Vision: Mandate hyperparameter transfer via standardized parameterizations (like HyperP) when comparing architectures; decouple tuning from architectural merit.
- Dependencies/assumptions: Agreement on parameterization schemas; tooling to enforce/verify compliance.
- Cross-domain application (CV, speech, diffusion, graph models)
- Sectors: multimodal model builders, scientific ML.
- Vision: Extend Frobenius-/spectral-sphere parameterization and transfer rules to CNNs/ViTs, ASR/TTS, diffusion U-Nets, and GNNs; investigate domain-specific gating analogs of SqrtGate.
- Dependencies/assumptions: Architecture-specific normalization and residual paths; data/optimization regimes differ significantly.
Notes on Assumptions and Dependencies That May Affect Feasibility
- Results are grounded in Transformer-Next-style LLMs, SlimPajama data, linear-decay-to-10% LR schedule, momentum 0.95, and specific architectural norms (e.g., QK-Norm, Pre-/Post-Norm). Different stacks may need minor re-tuning.
- “Weight decay is a first-order no-op” holds under Frobenius-sphere projection; second-order effects or other norms (e.g., spectral sphere) may behave differently.
- The η ∝ T-0.32 law is empirical; confirm on your data/task. It may shift with optimizer, schedule, or data mixing.
- SqrtGate’s invariance relies on roughly equal-RMS and weakly correlated expert outputs, conditions encouraged—but not guaranteed—by hypersphere optimization.
- CEL gains are relative to specific baselines; reproduce them with your infrastructure and cost model.
- Batch-size scaling exponent (~0.56) is an empirical finding; verify under your optimizer and gradient accumulation strategy.
By adopting these practices now and investing in the longer-term directions, organizations can lower training cost and risk, improve fairness and reproducibility of research, and enable more stable, scalable model development across sectors.
Glossary
- AdamH: A variant of AdamW used here that applies the same weight and update normalization as hypersphere methods to the LM head matrix. "AdamW with the same weight and update normalization schemes (denoted as AdamH) is used for the weight matrix of the language-model head"
- AdamW: An Adam optimizer variant with decoupled weight decay commonly used for training deep networks. "find that the optimal learning rate follows the same data-scaling power law with the ``magic exponent'' 0.32 previously observed for AdamW."
- aspect ratio (α): The fixed ratio between model width and depth used to co-scale the architecture. "aspect ratio (i.e. model width )"
- auxiliary balance loss: An auxiliary objective to balance token loads across experts in MoE, weighted by γ. "we sweep the auxiliary balance loss weight "
- Chinchilla Law: An empirical rule linking optimal tokens to parameter count for compute-efficient training. "according to Chinchilla Law \cite{chinchilla} with a measure of Tokens Per Parameter (TPP) "
- Compute Efficiency Leverage (CEL): A metric comparing how many FLOPs a method saves to reach a given loss relative to a baseline. "Compute Efficiency Leverage (CEL) relative to the Muon baseline."
- critical batch size: The batch threshold above which larger batches start to hurt the best achievable loss. "to identify the critical batch size, the threshold above which increasing batch size significantly degrades the achievable loss"
- Depth-P: A depth-aware parameterization/learning-rate scaling scheme that keeps function updates stable as depth changes. "Depth-P keeps the optimal LR stable at -- $0.016$ across all depths"
- Frobenius norm: The square root of the sum of squared entries of a matrix; used here to constrain weight magnitudes. "MuonH \cite{wen2025hyperball_part1} uses the Frobenius norm with the Muon optimizer"
- Frobenius-sphere constraint: Constraining a weight matrix to lie on a manifold of constant Frobenius norm. "under the Frobenius-sphere constraint with the Muon optimizer"
- Gated Attention: An attention mechanism augmented with per-head gating controlling contributions of heads. "and headwise gated attention \cite{qiu2025gated}"
- GQA (Grouped-Query Attention): An attention variant that groups queries to share keys/values and reduce cost. "dense Transformers with GQA (4 KV heads)"
- HyperP (Hypersphere Parameterization): The proposed framework of transfer laws enabling a single base learning rate to transfer across scales under hypersphere constraints. "We introduce HyperP (Hypersphere Parameterization), the first framework for transferring optimal learning rates across model width, depth, training tokens, and Mixture-of-Experts (MoE) granularity"
- hypersphere optimization: Optimization that re-projects weights onto a fixed-norm hypersphere after each update for stability. "Recent hypersphere optimization methods constrain weight matrices to a fixed-norm hypersphere"
- isotropic (approximately isotropic): Having nearly uniform singular values; not dominated by any one direction. "assume further that is approximately isotropic on its input space"
- Kaiming uniform distribution: A weight initialization scheme designed for deep networks with ReLU-like activations. "The PyTorch \cite{paszke2019pytorch} default initialization from Kaiming uniform distribution \cite{resnet} is adopted."
- LayerNorm: A normalization layer that normalizes features per token to stabilize training. "since the standard deviation of the input of LayerNorm \cite{ba2016layer} is with depth."
- log-sum-exp (LSE): The function log(∑exp(·)), used to summarize logit scale and define Z-values. "where is the log-sum-exp of the pre-softmax logits."
- logit explosion: The phenomenon where logits grow to very large magnitudes, destabilizing training. "scaling up training FLOPs routinely triggers logit explosion"
- magic exponent: The empirically consistent exponent 0.32 relating optimal learning rate to training tokens. "find that the optimal learning rate follows the same data-scaling power law with the ``magic exponent'' 0.32"
- MaxVio: A load-imbalance metric for MoE measuring how much the most loaded expert exceeds the mean. "we use the MaxVio (maximal violation) metric"
- Mixture-of-Experts (MoE): A layer that routes tokens to a subset of experts and combines their outputs via a gate. "In a Mixture-of-Experts (MoE) \cite{DBLP:conf/iclr/ShazeerMMDLHD17} layer, the output is formed by combining the Top- routed experts"
- Muon optimizer: An optimizer that orthogonalizes updates to reduce spectral anisotropy in weight updates. "MuonH (Muon-Hyperball) \cite{wen2025hyperball_part1} instantiates hypersphere optimization with the Muon optimizer \cite{jordan2024muon}"
- MuonH (Muon-Hyperball): A hypersphere optimizer that normalizes both weights and updates on the Frobenius sphere. "MuonH (Muon-Hyperball) \cite{wen2025hyperball_part1} instantiates hypersphere optimization with the Muon optimizer \cite{jordan2024muon} and Frobenius norm"
- MuonSphere: A hypersphere optimization method that constrains weights by spectral norm. "Both MuonSphere \cite{xie2026controlled} and SSO \cite{xie2026controlled} use the spectral norm"
- orthogonalized update: An update step adjusted to be orthogonal to current weights, helping avoid anisotropic spectra. "When the update is orthogonalized, as in Muon"
- post-norm residual block: A residual architecture where LayerNorm is applied after the residual addition. "The same exponent holds for post-norm residual blocks"
- power law: A scaling relation of the form y ∝ xa; used to describe how optimal LR scales with tokens. "showing a clean power-law relationship with exponent $0.32$"
- Pre-Norm: A residual architecture where normalization is applied before each sublayer. "and apply Pre-Norm \cite{prenorm} for residual connections."
- QK-Norm: A normalization applied to queries and keys in attention to stabilize dot-product scales. "QK-Norm \cite{pmlr-v202-dehghani23a}"
- residual scaler: The depth-dependent factor α_L multiplying residual branch outputs to stabilize deep networks. "where denotes the depth-dependent residual scaler."
- RMS (root-mean-square): A scale statistic used to track signal magnitudes of outputs and logits. "preserves output RMS across MoE granularities"
- shared expert: An MoE expert that is always active in addition to routed experts. "and $E_{\text{shared}$ is an optional shared expert \cite{deepseek-ai2024deepseekv2}."
- SqrtGate: A proposed MoE gating mechanism that uses square roots of routing weights to preserve routed-branch RMS across different k. "We also propose SqrtGate, an MoE gating mechanism derived from the hypersphere constraint that preserves output RMS across MoE granularities"
- spectral norm: The largest singular value of a matrix; used as a constraint in spectral-sphere methods. "Both MuonSphere \cite{xie2026controlled} and SSO \cite{xie2026controlled} use the spectral norm"
- spectral sphere: The set of matrices with a fixed spectral norm used as a constraint manifold for optimization. "SSO further applies the steepest descent on the spectral sphere."
- SSO: A hypersphere method that performs steepest descent constrained to the spectral sphere. "SSO further applies the steepest descent on the spectral sphere."
- SwiGLU: A gated MLP activation variant combining GLU structure with a smooth nonlinearity. "We use SwiGLU \cite{shazeer2020glu} with $4w$ intermediate size \cite{ren2025decoderhybriddecoder,openai2025gpt0oss0120b} for MLP"
- Tokens Per Parameter (TPP): The ratio of total training tokens to parameter count used to scale data with model size. "with a measure of Tokens Per Parameter (TPP) "
- Top- routing: Selecting the k highest-scoring experts per token in an MoE layer. "Top- routed experts selected from a larger expert pool"
- weight decay: L2-like regularization decoupled in AdamW; under Frobenius projection it has no first-order effect. "We prove that weight decay is a first-order no-op"
- weight normalization: Techniques that constrain or normalize weight magnitudes along specific axes or as a whole. "Previous works have explored column- and row-wise weight normalization"
- z-loss regularization: A penalty on the log-sum-exp of logits to control their magnitude and prevent instability. "mitigations such as z-loss regularization"
- Z-values: Squared log-sum-exp statistics of logits used as instability indicators. "including -values, output RMS, and activation outliers"
Collections
Sign up for free to add this paper to one or more collections.

