- The paper introduces the Mimosa framework that uses evolving, DAG-structured multi-agent workflows to overcome static orchestration bottlenecks.
- It demonstrates significant performance improvements via iterative workflow mutations, achieving up to 43.1% SR in challenging scientific tasks.
- The framework’s modular design enables tool-agnostic integration and structured execution logging, enhancing reproducibility and auditability.
Evolving Multi-Agent Systems for Autonomous Scientific Research: The Mimosa Framework
Motivation and Context
The expansion of high-throughput experimentation and data-driven methodologies in scientific discovery introduces significant bottlenecks in analytical scalability, reproducibility, and efficient adaptation to evolving experimental conditions. Existing agentic frameworks built atop LLMs and Self-Driving Lab paradigms continue to rely on static orchestration logic, fixed toolsets, and rigid workflow topologies, thereby imposing severe limitations in long-horizon scientific tasks, adaptability to instrumentation changes, and auditability of agent decisions. The Mimosa framework (2603.28986) directly addresses these systemic limitations via a multi-layer modular architecture integrating meta-level orchestration, automated workflow topology evolution, tool-agnostic integration via MCP (Model Context Protocol), and structured execution logging.
System Architecture and Evolutionary Workflow Optimization
Mimosa decomposes the pipeline into five sequential layers: (0) hierarchical goal decomposition (optional planner), (1) automated tool discovery, (2) meta-orchestration with memory-augmented workflow retrieval, (3) execution by specialized code-generating agents, and (4) structured workflow evaluation with feedback-driven topology mutation.
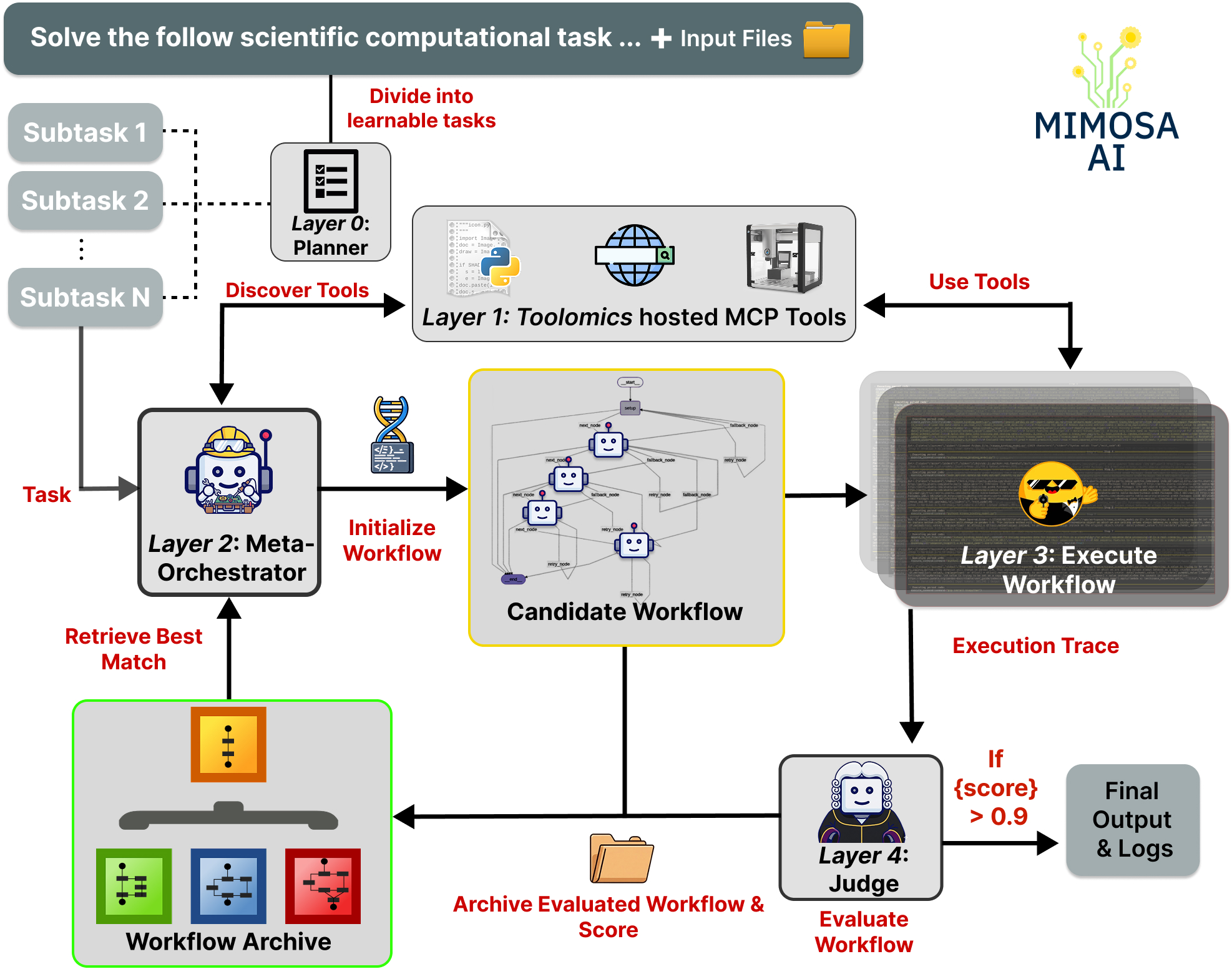
Figure 1: The Mimosa framework comprises sequential layers for planning, tool discovery, workflow initialization, specialized code agent execution, and judge-based evaluation with evolutionary workflow improvement.
The explicit modeling of workflow evolution as local search over the discrete space of directed acyclic graphs (DAGs) of agent-tool assignments fundamentally diverges from prior art in two respects. First, rather than agent composition being pre-specified or evolved in unconstrained latent code space, the problem is recast into DAG structures with explicit roles, tool allocations, and communication topology. Second, adaptation to environmental dynamism is handled via MCP-powered service discovery and containerized tool registration, decoupling orchestration from underlying tool persistence.
Workflow initialization leverages a case-based retrieval mechanism: the meta-orchestrator encodes task specifications and queries an archive of workflow-topology—task pairs for high-similarity matches. Absent a match (as in the diverse ScienceAgentBench evaluation regime), the system synthesizes novel workflows.
The evolutionary mutation loop is strictly single-incumbent, greedy local search. At each iteration, the meta-orchestrator proposes a minimal edit (prompt refinement, agent insertion/deletion, edge modification) to the current incumbent workflow, executes all agents across the new topology, and retains the candidate if the judge reward improves. Iteration halts on reward threshold or exhaustion of the iteration budget.
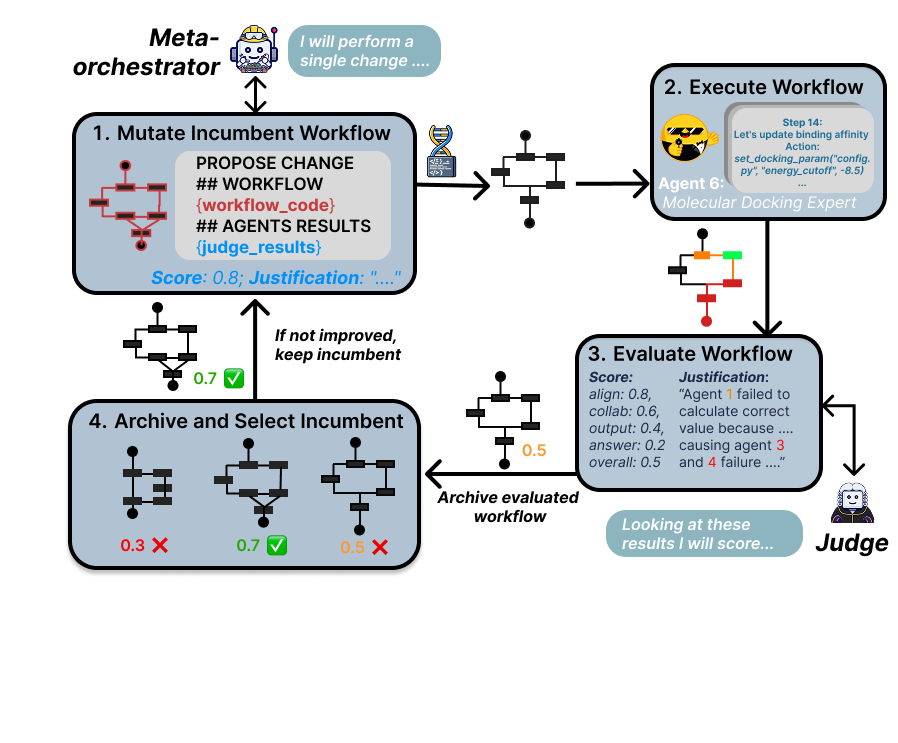
Figure 2: Iterative workflow refinement proceeds via meta-orchestrator-led mutation, execution by code agents, judge-based scoring, and incumbent archive selection.
Empirical Evaluation and Numerical Results
Experiments on ScienceAgentBench, encompassing 102 data-driven tasks from four scientific domains, evaluate Mimosa across three regimes: single-agent baseline, static multi-agent (one-shot) workflow, and iterative-evolved multi-agent workflows. Results confirm architecture-dependent, heterogeneous model responses to decomposition and meta-level refinement. For Claude Haiku 4.5 and GPT-4o, static multi-agent configurations yield ∼4x SR improvement over single-agent baselines, while DeepSeek-V3.2, with a 38.2% SR single-agent baseline, initially degrades under static multi-agent routing (32.4%) but surpasses both baselines via iterative evolution (43.1% SR).
Iterative refinement achieves consistent positive reward gains per evolution cycle up to iteration 8, with a downturn at iteration 10, indicating a performance plateau inherent to incumbent-only search (Figure 3 and Figure 4).
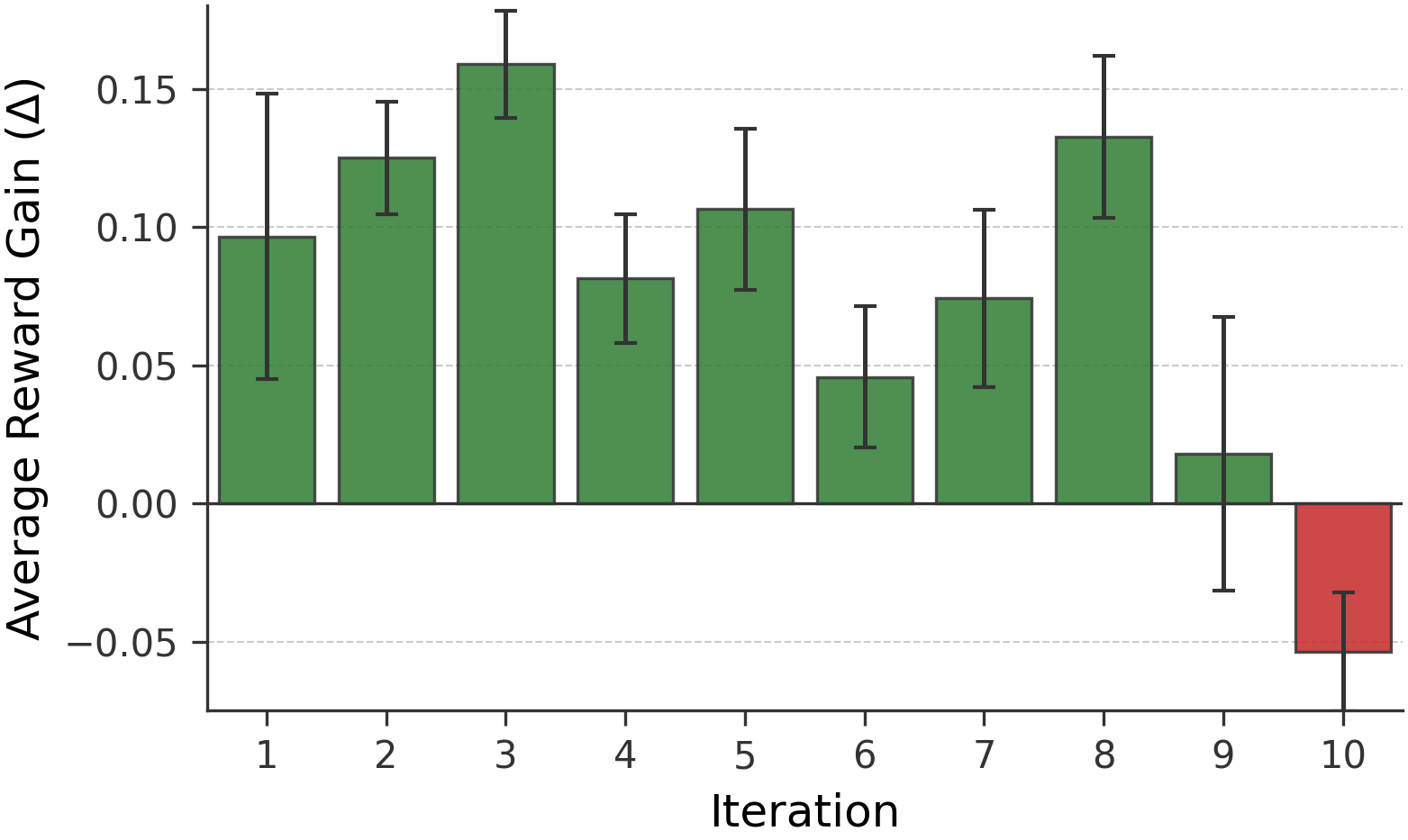
Figure 3: Average reward gains across workflow evolution iterations, highlighting the persistent improvement in early cycles and subsequent convergence.
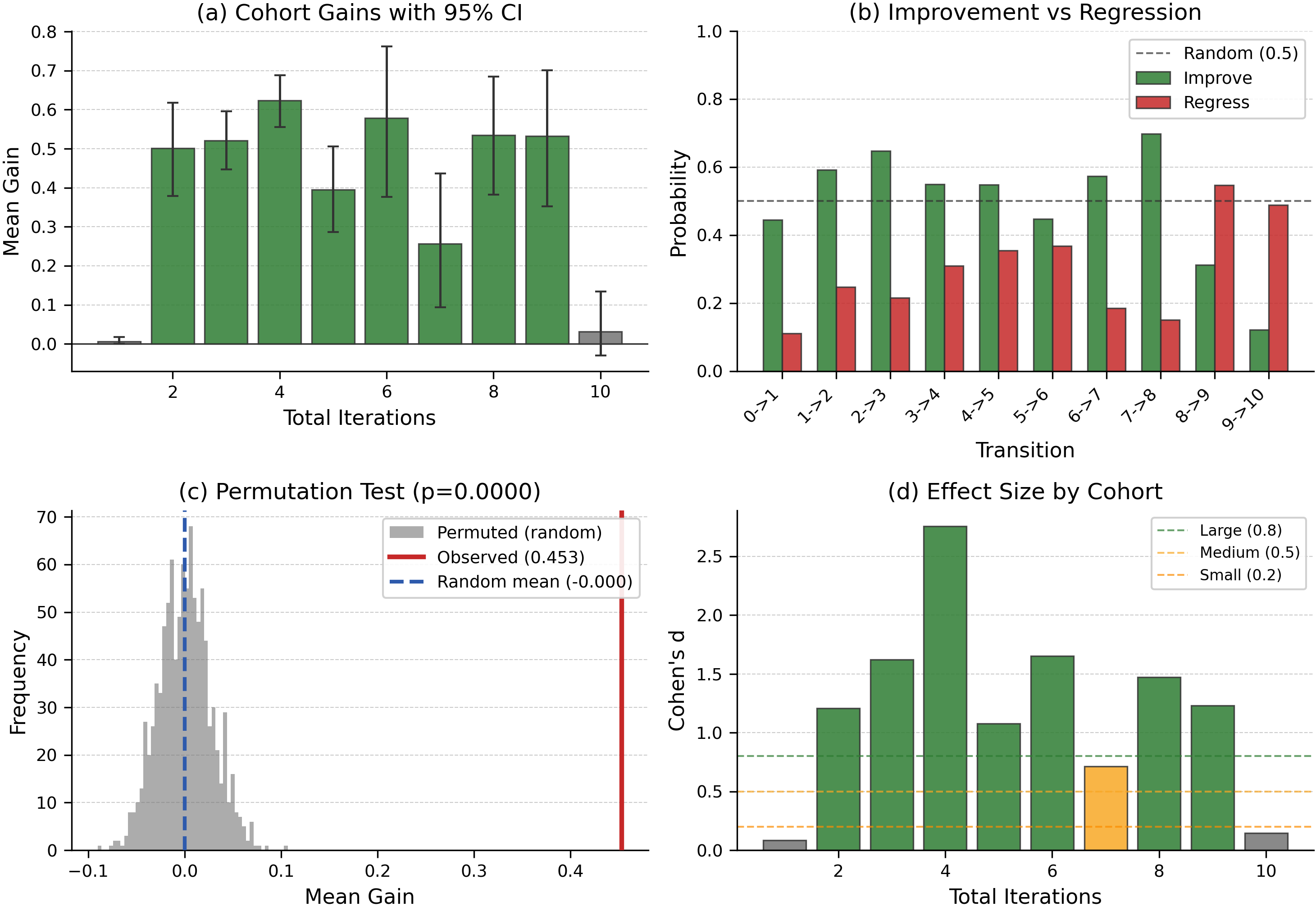
Figure 4: Statistical analyses confirm the non-random, significant improvement in reward over successive cohorts, with large effect sizes sustained across most of the local search trajectory.
Notably, cost analyses reveal significant model-architecture disparities. DeepSeek-V3.2 delivers the highest SR at a modest per-task expenditure relative to GPT-4o and Claude, but only when deployed with evolutionary workflow learning. Workflow evolution yields demonstrable benefit over static orchestration, but overhead is only justified for models with sufficient instruction-following robustness to utilize hierarchical orchestration and judge feedback.
Theoretical and Practical Implications
Mimosa's design advances the practical deployment of ASR by instantiating the workflow as a mutable, evolvable computational artifact governed by structured empirical feedback. The discretization of workflow and tool configuration enables meaningful auditability (critical for reproducibility and compliance) and facilitates workflow transfer in semantically similar tasks. The strict separation between judge-based search feedback (LLM-as-a-Judge) and ground-truth programmatic validation addresses a major critique in recent benchmarks regarding the misalignment of internal heuristic rewards and extrinsic success criteria.
The results indicate that universal adoption of multi-agent orchestration is suboptimal: model-specific capabilities and instruction parsing robustness must be considered when choosing decomposition depth and workflow complexity. Furthermore, the observed iterative refinement plateau confirms findings of open-ended self-evolving systems: population-based or diversity-maintaining search is required for escaping local minima in search spaces richer than simple supervised tasks.
On the practical front, Mimosa already demonstrates auditability, tool-agnostic adaptation, and full open-source deployability—all prerequisites for real-world scientific adoption beyond proprietary black-box solutions.
Limitations and Future Directions
Several limitations are identified:
- The judge feedback signal, while directionally useful, is coarse and subject to LLM-based scoring biases. Correlation between judge reward and true SR warrants further calibration.
- The single-incumbent search strategy is sample inefficient and induces rapid reward saturation. Population-based search and open-ended exploration are required to fully exploit the workflow topology and mutation space.
- The workflow archive mechanism, although implemented, was not empirically exercised, as ScienceAgentBench tasks had insufficient prompt overlap.
- Multi-seed replication, failure mode dissection, and model-specific analysis remain outstanding, as does a rigorous isolation of environment-setup versus orchestration structure effects.
- Workflow generalization and meta-learning capacity (abstract design pattern extraction, transferable skill acquisition) are not yet deployed.
Key future research axes include meta-orchestrator/judge cross-model configuration ablation, open-ended workflow population management, domain-knowledge-augmented skill bootstrapping, and persistent failure-knowledge encoding. Large-scale benchmarking with lighter open-source models will be critical for establishing the envelope of workflow decomposition with respect to throughput, cost, and energy efficiency.
Conclusion
The Mimosa framework represents a comprehensive architectural rethinking of agentic autonomy and workflow evolution for computational scientific research. By combining evolutionary refinement of explicit, DAG-structured multi-agent workflows, tool-agnostic execution via MCP, and judge-driven local search, it demonstrates robust improvements in SR over single-agent and static baselines and exposes critical architecture-model interaction effects. Its formal structuring and complete open-source release position it as a reference platform for both empirical and theoretical investigations into scalable, auditable, and adaptive ASR.
The findings in (2603.28986) reinforce the necessity of model-aware, audit-ready, and evolution-capable agentic systems for the next generation of autonomous scientific computing. Systematic integration of population-based search, judge robustness calibration, and persistent memory modules will further advance the capability frontier for ASR systems in high-impact domains.