Aime: Towards Fully-Autonomous Multi-Agent Framework
Abstract: Multi-Agent Systems (MAS) powered by LLMs are emerging as a powerful paradigm for solving complex, multifaceted problems. However, the potential of these systems is often constrained by the prevalent plan-and-execute framework, which suffers from critical limitations: rigid plan execution, static agent capabilities, and inefficient communication. These weaknesses hinder their adaptability and robustness in dynamic environments. This paper introduces Aime, a novel multi-agent framework designed to overcome these challenges through dynamic, reactive planning and execution. Aime replaces the conventional static workflow with a fluid and adaptive architecture. Its core innovations include: (1) a Dynamic Planner that continuously refines the overall strategy based on real-time execution feedback; (2) an Actor Factory that implements Dynamic Actor instantiation, assembling specialized agents on-demand with tailored tools and knowledge; and (3) a centralized Progress Management Module that serves as a single source of truth for coherent, system-wide state awareness. We empirically evaluated Aime on a diverse suite of benchmarks spanning general reasoning (GAIA), software engineering (SWE-bench Verified), and live web navigation (WebVoyager). The results demonstrate that Aime consistently outperforms even highly specialized state-of-the-art agents in their respective domains. Its superior adaptability and task success rate establish Aime as a more resilient and effective foundation for multi-agent collaboration.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, phrased to be concrete and actionable for future research.
- Reproducibility details are insufficient: the exact LLM(s) used, versions, temperature/top‑p settings, tool APIs, environment configs, prompt templates, and code are not specified, making results hard to replicate and compare.
- No ablation studies disentangle the contributions of the Dynamic Planner, Actor Factory, and Progress Management Module; quantify each component’s marginal impact and interactions.
- Lack of cost/efficiency analysis: token consumption, latency per task/subtask, concurrent actor overhead, and end‑to‑end runtime are not measured or optimized.
- Scalability limits are untested: performance with large numbers of simultaneous actors/tasks, high branching factor, long task hierarchies, and multi‑project orchestration remains unknown.
- Concurrency control and conflict resolution in the centralized progress list are unspecified (e.g., race conditions, write locks, versioning, merge strategies for simultaneous updates).
- The progress list’s Markdown format may be brittle under complex edits; evaluate structured alternatives (e.g., CRDTs, JSON schemas, graph databases) and their effects on robustness and parsing accuracy.
- Completion criteria are mentioned but not operationalized: how they are authored, validated, enforced, and audited; define formal schemas and verification procedures.
- Trust and validation for actor‑reported progress are unaddressed: detect false, premature, or inconsistent updates; design cross‑checks or external validators.
- Dynamic Planner re‑planning may oscillate or thrash; no mechanisms (e.g., hysteresis, cooldowns, confidence thresholds) or analysis to prevent instability.
- Formal guarantees are absent: no proofs or empirical evaluation of convergence, bounded regret, or correctness of the planner–executor loop under uncertainty.
- Actor Factory selection policy is opaque: how personas, tool bundles, and knowledge modules are chosen; measure selection accuracy and misconfiguration rates; learnable vs rule‑based policies.
- Tool bundle curation is manual and static; explore automatic tool discovery, tool selection learning, and bundle evolution with coverage metrics and safety checks.
- Knowledge base integration lacks detail: sources, retrieval methods, freshness, grounding quality, and safeguards against stale or biased knowledge; measure retrieval precision/recall.
- Memory design is underspecified: how local actor memory (M_t) and global progress memory interact; strategies for long‑term memory, compression, forgetting, and cross‑actor knowledge transfer.
- Error handling for tool failures and noisy observations is not studied: design retry policies, fallbacks, uncertainty modeling, and error propagation mitigation.
- Coordination quality is not measured: quantify redundancy reduction, handoff fidelity, context loss, and communication efficiency beyond success rates.
- Safety and security are not addressed: sandboxing for code execution, permissioning for tools, web agent compliance (robots.txt, rate limits), and prevention of harmful actions or data leakage.
- Fairness of baseline comparison is unclear: confirm identical LLMs, prompts, tool access, and compute budgets; include statistical significance tests, confidence intervals, and multiple seeds.
- Generalization across LLM backbones is unexplored: sensitivity of Aime’s performance to different models, sizes, and instruction‑tuning regimes.
- Multi‑modal capability is not detailed, despite GAIA’s multimodal tasks: specify how images, PDFs, or visual context are handled within actors and planner.
- Resource management and scheduling policies are absent: actor lifecycle (spawn, reuse, GC), prioritization, preemption, and resource quotas under load.
- Persistence and recovery are not discussed: checkpointing the global state, crash recovery for planner/actors, and resilience under partial system failures.
- Interpretability and auditability are unaddressed: mechanisms to trace decisions, attribute outcomes to agents, and inspect reasoning chains for debugging.
- Emergent behaviors and social dynamics are not explored: conflict resolution strategies, consensus protocols, and goal alignment mechanisms for heterogeneous agents.
- Evaluation breadth is limited to three benchmarks; test in additional domains (robotics/control, data science pipelines, enterprise workflows) to assess external validity.
- Real‑world web evaluation reproducibility is questionable: live site variability, session states, captchas, and UI changes; propose controlled replay or simulator‑backed tests.
- The ReAct choice is not compared against alternatives (Tree of Thoughts, Reflexion, tool‑learning agents); perform method comparisons and hybrid designs.
- Progress update timing policy is implicit (LLM decides); study policies/training to optimize when and what to report to balance overhead vs situational awareness.
- Data privacy and compliance considerations for shared state and external tools are not discussed; define governance, access control, and audit trails.
- Equation and formalism clarity issues (e.g., malformed parentheses in planner and factory formulas) hinder precise understanding; provide corrected, executable specifications and pseudocode.
- Learning is absent: the system does not adapt its policies/tools over time; investigate online learning, reward models, and meta‑optimization of workflows and actor configurations.
- Benchmark‑specific failure analysis is missing: categorize error modes on GAIA/SWE‑bench/WebVoyager to target improvements (e.g., mis‑tooling vs planning vs observation parsing).
- Human factors are not considered: user‑in‑the‑loop interventions, interactive re‑planning, and UI/UX for monitoring large agent teams.
- Ethical and bias implications of persona prompts are unexamined: measure their impact on decisions, stereotyping, and outcome fairness; develop mitigation strategies.
Glossary
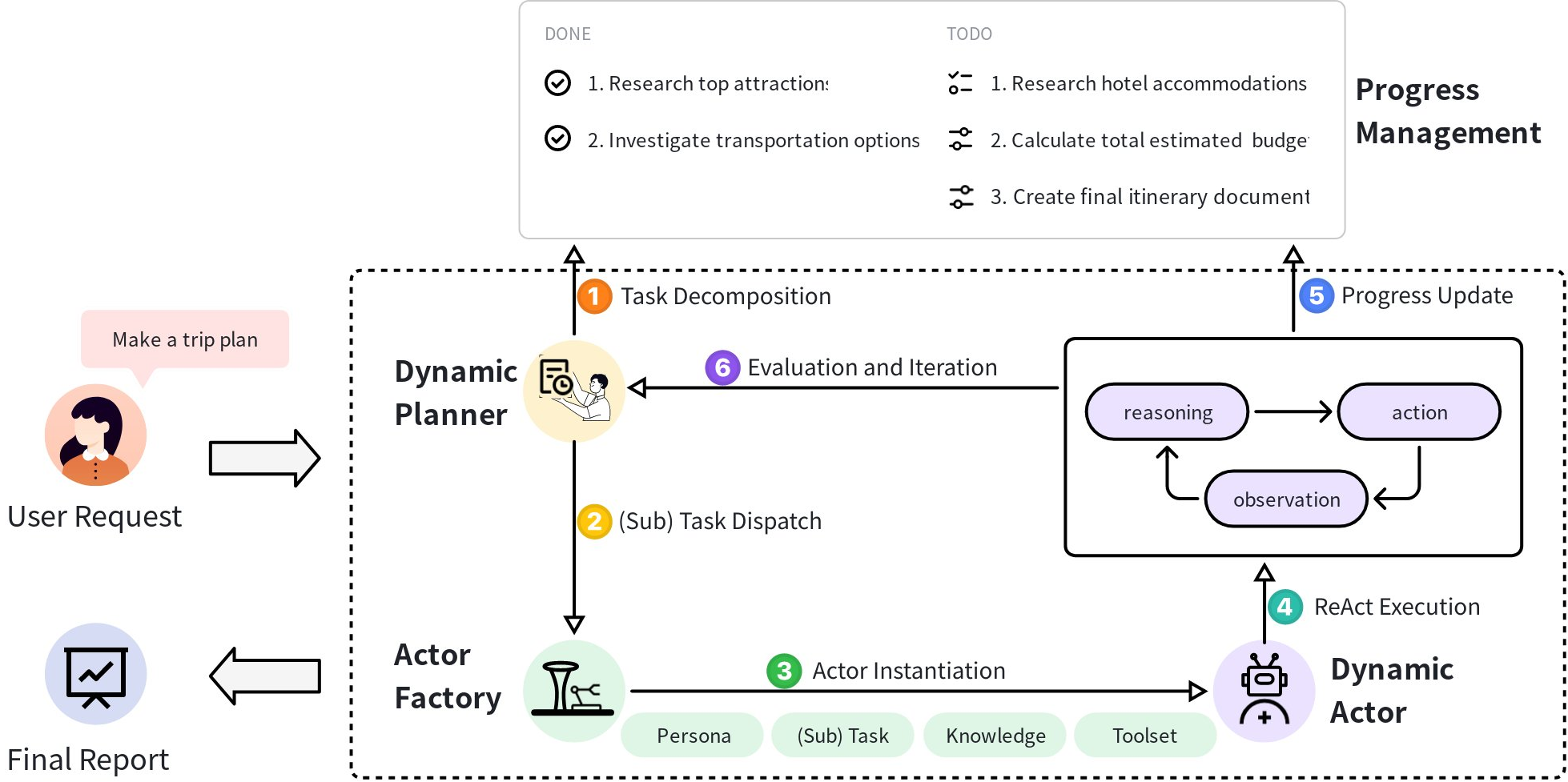
- Actor Factory: A system component that assembles specialized agents on-demand with tailored personas, tools, and knowledge for a specific subtask. "The Actor Factory is responsible for instantiating specialized actors tailored to specific subtask requirements."
- Agent-Oriented Planning (AOP): A planning approach that decomposes tasks and evaluates agent workflows using a reward model before execution. "For example, AOP investigates an agent-oriented planning method that leverages fast task decomposition and a reward model for efficient evaluation."
- Agentic Supernet: A method that learns to generate agent workflows from predefined agentic operators rather than fixing them upfront. "More advanced approaches such as Agentic Supernet and FlowReasoner even learn to generate these workflows from predefined agentic operators."
- AgentVerse: A multi-agent framework that enables flexible communication patterns between agents. "Other frameworks like AutoGen and AgentVerse offer more flexible communication patterns, but the definition of agent roles and their capabilities often remains fixed."
- AutoGen: A multi-agent conversation framework that supports flexible agent communication and coordination. "Other frameworks like AutoGen and AgentVerse offer more flexible communication patterns, but the definition of agent roles and their capabilities often remains fixed."
- CodeR: A software-agent framework that predefines multiple SOPs and selects one based on the task requirements. "CodeR extends this by predefining multiple SOPs and selecting one based on the task at hand."
- Dynamic Actor: An autonomous agent instantiated for a specific subtask that executes via iterative reasoning and action. "A Dynamic Actor is an autonomous agent that executes specific subtasks assigned by the Dynamic Planner."
- Dynamic Actor Instantiation: A mechanism to create specialized agents on-the-fly with the exact capabilities needed for a subtask. "We introduce Dynamic Actor Instantiation, a mechanism implemented via an Actor Factory."
- Dynamic Planner: The central orchestrator that maintains the global task structure and continuously adapts plans based on real-time feedback. "The Dynamic Planner serves as the central orchestrator for task management."
- Exact string matching metric: An evaluation metric that checks whether an agent’s answer exactly matches the expected string. "We evaluate on the public test set using the official exact string matching metric."
- Flow: A workflow-generation approach that automatically produces graph-based agent workflows. "AFlow and Flow automatically generate graph-based workflows, though often with the simplifying assumption of homogeneous agent capabilities."
- FlowReasoner: A framework that learns to generate agent workflows from predefined operators. "More advanced approaches such as Agentic Supernet and FlowReasoner even learn to generate these workflows from predefined agentic operators."
- GAIA: A benchmark for general AI assistants requiring multi-step reasoning, tool use, and multimodal understanding. "GAIA is a challenging benchmark for general AI assistants, comprising questions that require multi-step reasoning, tool use, and comprehension of multi-modal content."
- LLM: A neural model trained on vast text corpora for language understanding, reasoning, and generation. "The recent emergence of LLMs represents a significant milestone in artificial intelligence."
- LLM Agent: An autonomous entity that uses an LLM as its cognitive core and augments it with tools, memory, and prompts to act in the environment. "An LLM Agent utilizes an LLM not merely as a text generator, but as its central cognitive core for reasoning, planning, and decision-making."
- MAGIS: A multi-agent framework that designs dedicated SOPs for software development tasks. "Similarly, MAGIS and MarsCode Agent design dedicated Standard Operating Procedures (SOPs) for software development."
- MarsCode Agent: A specialized agent system that employs SOPs for structured software development workflows. "Similarly, MAGIS and MarsCode Agent design dedicated Standard Operating Procedures (SOPs) for software development."
- MetaGPT: A role-based multi-agent framework that simulates a software company to structure collaboration. "Frameworks like MetaGPT and ChatDev simulate a software company, where agents playing roles like \"product manager\" or \"engineer\" follow structured protocols to achieve their objectives."
- Multi-Agent Systems (MAS): Collections of autonomous agents collaborating in a shared environment to solve complex tasks beyond a single agent’s capability. "Building upon the capabilities of individual LLM Agents, Multi-Agent Systems (MAS) represent the next frontier in collaborative AI."
- Plan-and-execute framework: An architecture where a planner produces a static sequence of subtasks for executors to carry out. "Among the various architectures, the plan-and-execute framework has become a dominant approach."
- Progress list: A globally accessible hierarchical structure that tracks task and subtask statuses for coordination. "a globally accessible, hierarchical data structure we call the progress list"
- Progress Management Module: The centralized state manager and shared memory ensuring consistent, system-wide progress awareness. "The Progress Management Module functions as the shared memory and central state for system-wide coordination."
- ReAct framework: An execution paradigm that interleaves explicit reasoning and action in iterative cycles. "Each actor employs the ReAct framework, operating through iterative cycles of “Reasoning” and “Action\"."
- Regression (software testing): An unintended breakage introduced by a code change, detected via tests. "Success is rigorously evaluated by running unit tests to ensure the provided fix is correct and introduces no regressions."
- Standard Operating Procedures (SOPs): Predefined, structured protocols that guide agent behavior for specific tasks. "design dedicated Standard Operating Procedures (SOPs) for software development."
- SWE-bench Verified: A benchmark evaluating agents on real-world software bug fixing, validated by unit tests. "SWE-bench Verified is a curated subset of SWE-bench for assessing an agent's ability to resolve real-world software engineering problems."
- Update_Progress: A system-provided tool that agents invoke to report real-time progress and issues to the shared state. "the actor's toolkit T_t is augmented with a special system-provided tool: ."
- WebVoyager: A benchmark for end-to-end web agents operating on live websites, evaluated by task success rate. "WebVoyager is an end-to-end benchmark for web agents that interact with live websites."
Collections
Sign up for free to add this paper to one or more collections.