- The paper introduces GenSplat, a feed-forward 3D Gaussian Splatting framework that synthesizes novel, geometrically consistent views to improve visuomotor policy robustness under camera perturbations.
- It leverages permutation-equivariant transformers and 3D-prior distillation to stabilize reconstruction and create metrically consistent 3D scene representations from sparse, uncalibrated observations.
- Empirical evaluations on manipulation tasks demonstrate up to 13.3% absolute and 56% relative gains in policy success under challenging camera pose shifts.
Efficient Camera Pose Augmentation for Robust View Generalization in Robotic Policy Learning
Introduction
The paper proposes GenSplat, a feed-forward 3D Gaussian Splatting (3DGS) framework engineered to enable robust viewpoint generalization in visuomotor policy learning. GenSplat systematically augments the observational manifold by synthesizing geometrically consistent novel views from sparse, uncalibrated expert demonstrations. In contrast to conventional 2D-centric policies that are brittle under extrinsic SE(3) perturbations, GenSplat forces policy learning to be anchored to underlying 3D structure. The key technical innovation lies in leveraging a permutation-equivariant transformer architecture in conjunction with a 3D-prior distillation objective—importing geometric knowledge from a foundation model to stabilize the reconstruction process.
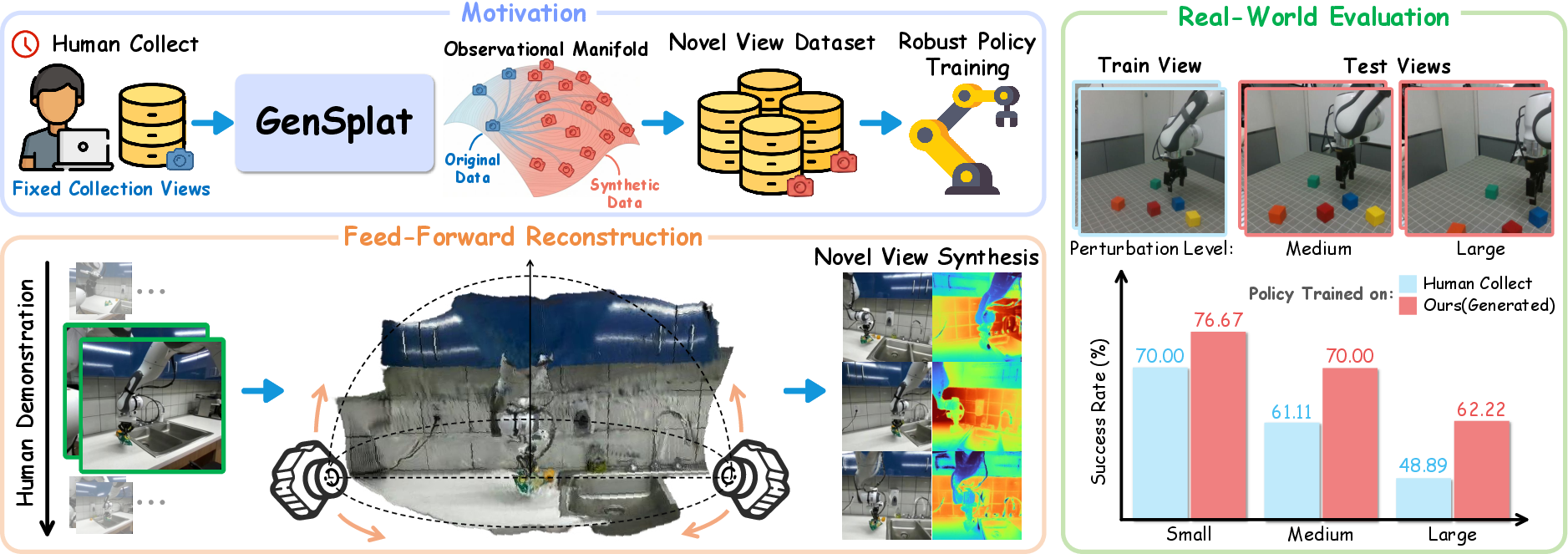
Figure 1: GenSplat pipeline augments camera pose diversity through explicit 3D reconstruction and novel-view rendering, substantially outperforming policies trained solely on human-collected demonstrations.
GenSplat Framework
Feed-Forward 3DGS from Sparse, Uncalibrated Observations
GenSplat parametrizes 3D scenes by predicting Gaussian primitives directly from sparse robot-centric camera observations, bypassing the slow and brittle per-scene optimization characteristic of classical 3DGS and NeRF-style pipelines. The system comprises three decoders: a camera pose predictor, a dense point map regressor, and a rendering attribute head.
A permutation-equivariant transformer aggregates multi-view embeddings extracted from DINOv2, ensuring robust geometric reasoning regardless of input ordering and obviating the need for reliable camera intrinsics or extrinsics. The camera pose decoder estimates relative SE(3) transforms, the point map decoder yields a local 3D geometry proxy, and the rendering head predicts per-primitive color, opacity, rotation, scale, and illumination coefficients.
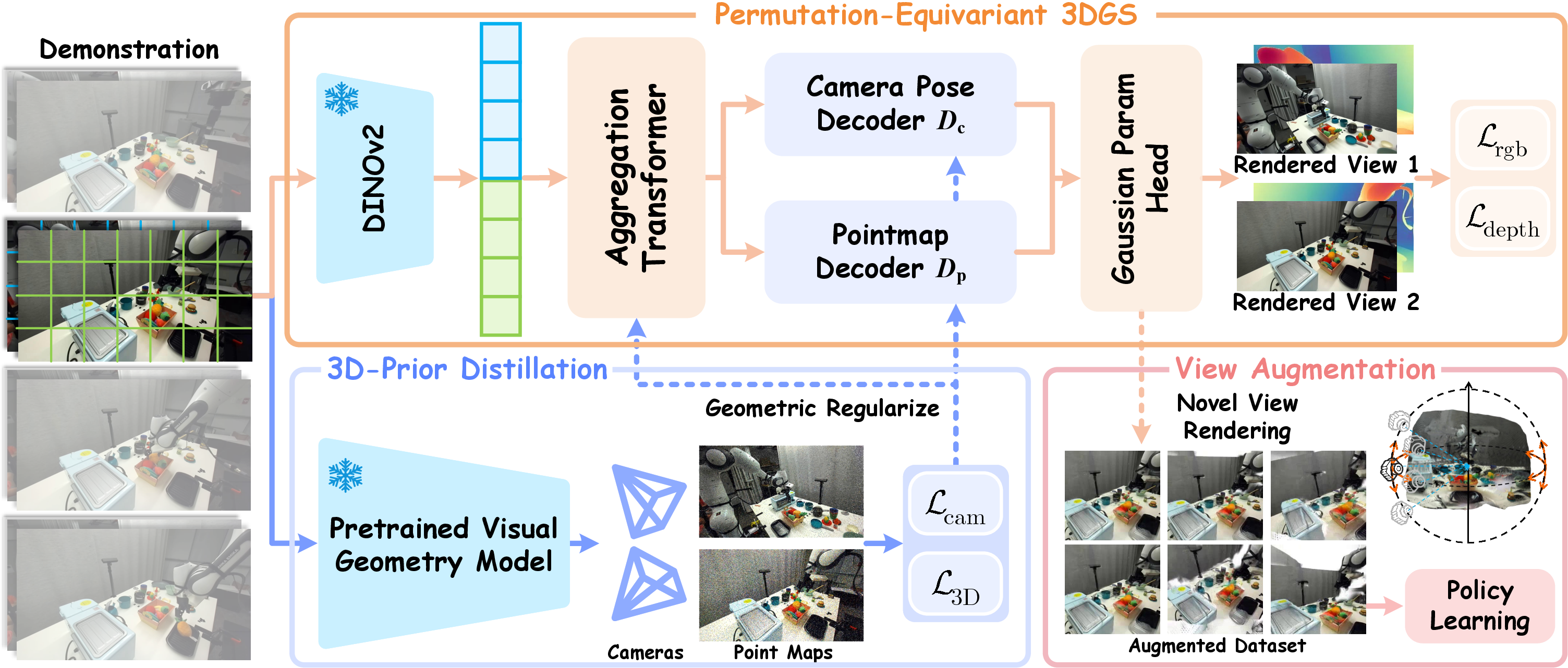
Figure 2: GenSplat feed-forward 3DGS structure enabling joint pose, geometry, and appearance estimation from sparse, unposed observations.
This architecture makes GenSplat immediately extensible to the challenge domains prevalent in manipulation data: severe observation sparsity, missing calibration, and domain shifts.
3D-Prior Distillation
The most critical component in GenSplat is the introduction of geometric priors distilled from a large-scale visual geometry foundation model. By employing dense 3D point maps rather than depth supervision, GenSplat offers explicit spatial regularization, thus suppressing local minima associated with pure photometric objectives (i.e., ghosting, floaters, and tearing). Supervision combines photometric losses, point-map regularization, and affine-invariant pose constraints computed using pseudo ground-truth. This synergistic objective yields metrically consistent reconstructions even in the absence of extrinsic input annotation.
Densifying the Observational Manifold
By rendering large numbers of novel, geometrically plausible views from each demonstration—each consistent with action labels—GenSplat performs data augmentation in a physically meaningful manner. This expansion of the support in SE(3) directly induces policy robustness to novel viewpoints, eliminating the need for manual re-collection and teleoperation under new extrinsics.
Empirical Evaluation
Manipulation Tasks and Real-World Setup
Experiments are performed on a Franka Research 3 platform across six standard manipulation tasks, encompassing workspace diversity (object types, positions, colors) and controlled spatial perturbations of camera pose. All baselines are carefully matched on observation and action space, and all policies are trained both with and without GenSplat-augmented data.
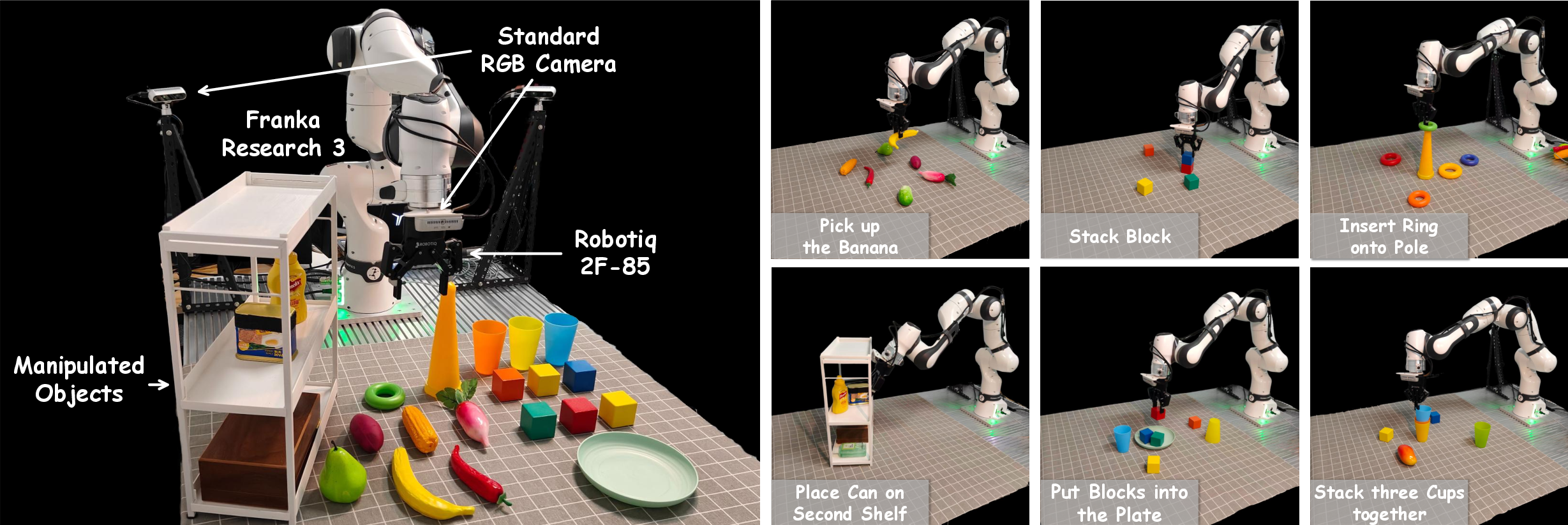
Figure 3: Experimental hardware and task setup for evaluating viewpoint generalization in manipulation.
Policy Robustness under Camera Perturbations
Policies trained on GenSplat-augmented data consistently maintain high success rates under increasing camera rotation and translation perturbations, compared to severe degradation observed in source-view-only policies. For π0 and Diffusion Policy, GenSplat provides absolute gains up to 13.3% and relative gains up to 56% under large perturbations—while remaining competitive in the original (unperturbed) setting.
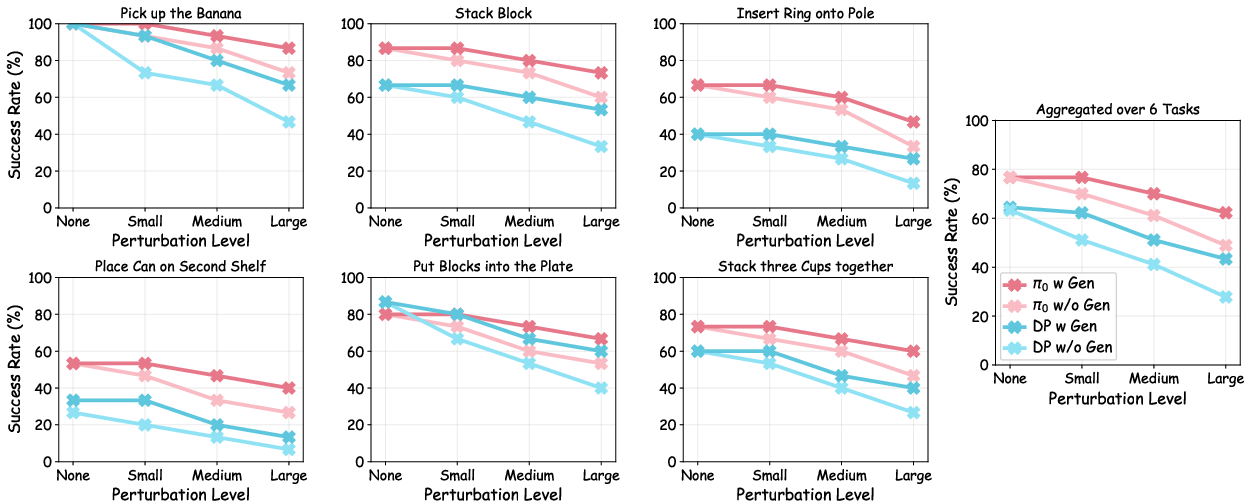
Figure 4: Robustness of policy success rates under increasing camera pose perturbations—the GenSplat-augmented policies are consistently more robust.
Rendering Quality and Comparison to Baselines
Qualitative and quantitative comparisons confirm that GenSplat reconstructions maintain sharp object boundaries, high-frequency details, and strict spatial alignment in both RGB and normal/depth channels. In contrast, state-of-the-art diffusion-based NVS methods systematically break geometric constraints, introducing global metric errors and occlusion artifacts that are catastrophic for policy transfer. Competing Gaussian-based methods fare better, but without 3D-prior distillation, are plagued by surface collapse and floaters.

Figure 5: Qualitative geometry recovery—GenSplat retains both global topology and fine details, without camera calibration.

Figure 6: Comparison with diffusion and Gaussian-based NVS—GenSplat eliminates floaters and spatial artifacts, preserving scene structure necessary for policy learning.
Ablations indicate that permutation-equivariance and point map distillation contribute orthogonally to architectural robustness and geometric fidelity, respectively.

Figure 7: Scene reconstruction comparison with AnySplat—GenSplat reconstructs planar surfaces without geometric irregularities, directly addressing topological collapse.
Data Efficiency and Augmentation Density
Increasing the number of rendered novel views per trajectory monotonically improves policy generalization, with the primary improvements saturating at N=3−4. Excessive rendering beyond this density yields diminishing returns.
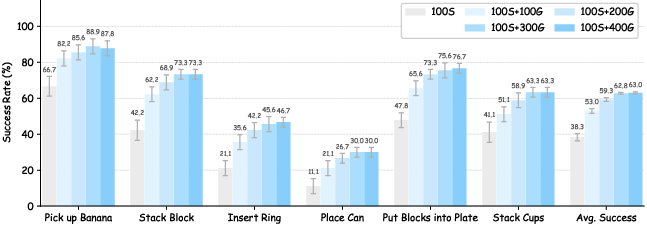
Figure 8: Viewpoint robustness as a function of rendered view augmentations—performance saturates after moderate densification.
Practical and Theoretical Implications
GenSplat formally dissociates robust visuomotor policy learning from the intractable cost of viewpoint-diverse manual data collection. The framework delivers high-fidelity, physically valid synthetic augmentations compatible with imitation and vision-language-action models. Critically, its architecture-agnostic approach means it can serve as a plug-in augmentation engine for existing large-scale policy frameworks (e.g., π0, Diffusion Policy), as well as more specialized architectures requiring spatial or egocentric grounding.
Theoretically, GenSplat provides strong evidence for the impact of expanding the SE(3) support of the observational manifold in addressing spatial distributional shifts—a key bottleneck in scalable Embodied AI. The analysis of geometric priors also foregrounds the value of dense 3D structure, rather than 2.5D proxies (depth), for spatial reasoning under partial observability and camera noise.
Future Directions
There is scope to extend GenSplat with dynamic multi-camera fusion, fine-grained object-centric priors, and integration of policy gradients that are sensitive to the synthetic data geometry. The zero-shot capabilities can be enhanced through attention mechanisms that allow the policy to reason about uncertainty in the augmented samples. Combining GenSplat with recently proposed scene graph or compositional world models may further improve sim-to-real transfer, robustness to occlusion, and continual adaptation.
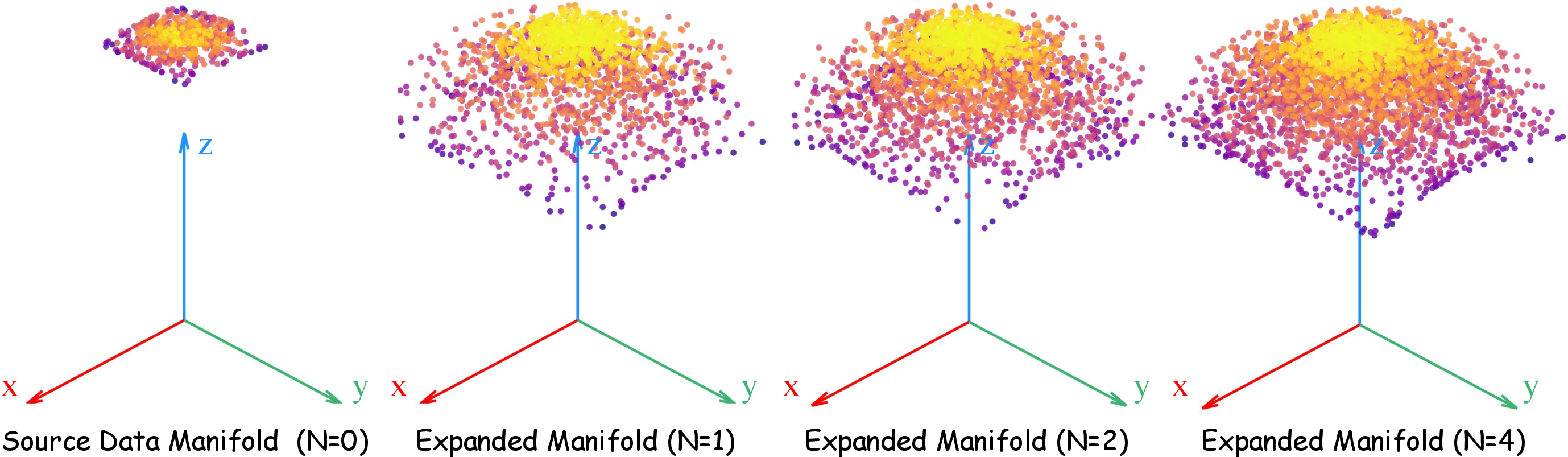
Figure 9: Visualization of densified camera extrinsics in the observational manifold, enabled by GenSplat’s physically-consistent augmentation.
Conclusion
GenSplat provides an efficient, scalable pathway to robust viewpoint generalization in robotic policy learning by combining feed-forward 3DGS with prior-guided distillation. Its technical contributions address core open research problems in Embodied AI: reliable policy execution under pose variation, physically meaningful synthetic data augmentation, and learning high-fidelity scene representations from sparse, uncalibrated data. The framework offers practical applicability to real-world deployments and opens up further research into geometry-aware policy learning and sample-efficient imitation.